关于JMM
最近在学习Java的并发编程,个人觉得还是比较难的,其中的JMM更是让我深感困惑。今天就来简略地总结一下JMM。
首先,是为什么需要JMM。这里就得从 CPU 缓存模型和指令重排序开始说起。
为什么需要CPU缓存模型,简单来说内存离CPU太远了,CPU处理速度是越来越快,但从内存中取数据太慢,所以CPU留了一手,在内部创建缓存,这样,访问缓存速度就提高了,缓存可以分为一级缓存、二级缓存和三级缓存。
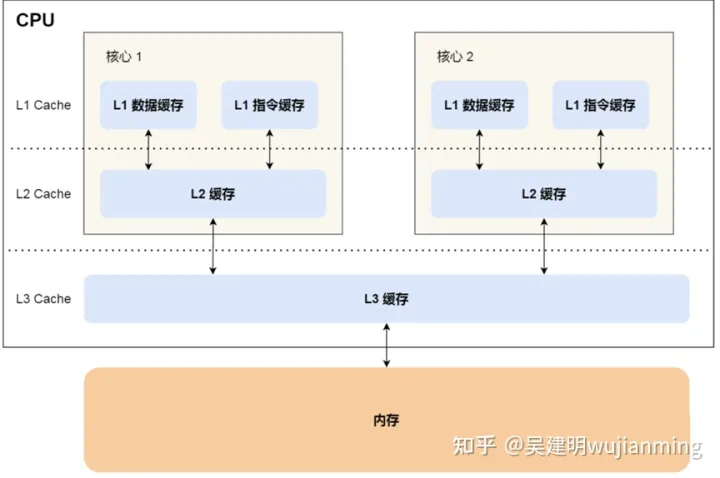
这时候,速度是上来了,但是也引入了一些其他问题,比如数据不一致性。因此,CPU为了解决这些问题,通过制定缓存一致协议(比如 MESI 协议)或者其他手段来解决。 这个缓存一致性协议指的是在 CPU 高速缓存与主内存交互的时候需要遵守的原则和规范。不同的 CPU 中,使用的缓存一致性协议通常也会有所不同。
我们的程序运行在操作系统之上,操作系统屏蔽了底层硬件的操作细节,将各种硬件资源虚拟化。于是,操作系统也就同样需要解决内存缓存不一致性问题。 操作系统通过 内存模型(Memory Model) 定义一系列规范来解决这个问题。无论是 Windows 系统,还是 Linux 系统,它们都有特定的内存模型。
CPU缓存模型是一个,还有一个指令重排。为了提升执行速度/性能,计算机在执行程序代码的时候,会对指令进行重排序。 什么是指令重排序? 简单来说就是系统在执行代码的时候并不一定是按照你写的代码的顺序依次执行。
常见重排有以下两种:
编译器优化重排:编译器(包括 JVM、JIT 编译器等)在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
指令并行重排:现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
在单线程下,指令重排序可以保证串行语义一致,但是没有义务保证多线程间的语义也一致 ,所以在多线程下,指令重排序可能会导致一些问题。
对于编译器优化重排和处理器的指令重排序(指令并行重排和内存系统重排都属于是处理器级别的指令重排序),处理该问题的方式不一样。
对于编译器,通过禁止特定类型的编译器重排序的方式来禁止重排序。
对于处理器,通过插入内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)的方式来禁止特定类型的处理器重排序。
现在,可以回答为什么需要JMM了。一方面,从CPU缓存模型出发,如果直接复用操作系统的内存模型,那么就不能实现write once run anywhere,所以需要JMM;另一方面,指令重排对多并发程序带来问题,为此,JMM抽象出happens-before原则来解决指令重排问题。
关于happens-before
在Java中,volatile和synchronized都可以建立内存屏障,禁止指令重排。内存屏障解决了 “底层指令顺序” 问题,但程序员写代码时,不可能每次都去分析 “哪里需要插屏障”—— 这太复杂了。JMM 通过 “happens-before 规则”,给程序员提供了一套 “上层逻辑保证”:不用关心底层实现,只要两个操作满足 happens-before 关系,就说明 “前一个操作的结果对后一个操作可见”。