基于深度学习的数字图像分类实验与分析
基于深度学习的数字图像分类实验与分析
摘要
本文详细记录了基于深度学习的数字图像分类实验的全过程,包括实验环境搭建、数据预处理、模型选择与搭建、训练与评估等关键环节。通过基础实验、改进实验、进阶实验和补充实验四个部分,逐步深入探讨了深度学习在数字图像分类中的应用。实验结果表明,卷积神经网络(CNN)结合注意力机制在图像分类任务中表现出色,具有较高的准确率和鲁棒性。

1. 引言
随着深度学习技术的快速发展,数字图像分类已成为计算机视觉领域的研究热点。本文通过一系列实验,系统探讨了深度学习在数字图像分类中的应用,旨在为相关领域的研究人员提供技术参考和实验指导。
2. 实验环境搭建
2.1 软件环境配置
Anaconda安装:首先下载并安装Anaconda,这是一个包含Python解释器和大量科学计算库的集成环境。安装教程参考Anaconda安装指南。
Python版本选择:安装Python 3.9版本,该版本在深度学习领域具有广泛的兼容性和稳定性。下载教程参考Python下载指南。
Python库安装:根据实验需求,安装常用的科学计算库如numpy、matplotlib等。具体安装指导参考Python库安装指南。
Torch库安装:
CPU版本:对于没有独立显卡的计算机,下载并安装CPU版本的torch库。安装指南参考Torch CPU版安装指南。
GPU版本:对于配备独立显卡的计算机,首先根据显卡驱动版本下载并安装CUDA。安装指南参考CUDA安装指南。随后下载并安装GPU版本的torch库,安装指南同上。
3. 实验内容与操作细节
3.1 基础实验一:全连接神经网络(MLP)
3.1.1 数据预处理
数据集下载:使用animals10数据集,该数据集包含大约28K张中等质量的动物图像,分为10个类别。数据集地址:animals10数据集。
数据集划分:使用data_loader将数据集划分为训练集、验证集和测试集,比例为7:2:1。具体实现代码如下:
python
def get_dataloaders(data_dir, batch_size=32, val_split=0.2, test_split=0.1):
full_dataset = datasets.ImageFolder(data_dir)
train_size = int((1 - val_split - test_split) * len(full_dataset))
val_size = int(val_split * len(full_dataset))
test_size = len(full_dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(full_dataset, [train_size, val_size, test_size], generator=torch.Generator().manual_seed(42))
# 创建DataLoader
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, val_loader, test_loader
3.1.2 模型搭建
全连接神经网络(MLP):构建一个简单的MLP模型,包括输入层、隐藏层和输出层。输入层接收展平后的图像数据,隐藏层进行加权求和和非线性转换,输出层给出分类结果。
python
class SimpleMLP(nn.Module):
def init(self, input_size, hidden_size, num_classes):
super(SimpleMLP, self).init()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):x = x.view(x.size(0), -1) # 展平图像out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out
3.1.3 训练与评估
训练过程:在训练集上训练模型,通过调整学习率等超参数,让模型在测试集上展示最佳性能。训练30个epoch,测试集准确率约为0.4。
3.2 改进实验二:卷积神经网络(CNN)
3.2.1 数据预处理
数据筛选:从十种动物数据中筛选出牛、羊、马、狗、猫、象、鸡等特定类别的图像进行训练、验证和测试。实现代码如下:
python
class FilteredImageFolder(datasets.ImageFolder):
def init(self, root, classes, transform=None):
super(FilteredImageFolder, self).init(root, transform)
self.classes = classes
self.imgs = [img for img in self.imgs if img[1] in self.classes]
3.2.2 模型搭建
卷积神经网络(CNN):将全连接网络改为CNN网络,增加卷积层和池化层以提取图像中的空间特征。
python
class SimpleCNN(nn.Module):
def init(self, num_classes):
super(SimpleCNN, self).init()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.fc = nn.Linear(32 * 56 * 56, num_classes) # 假设输入图像大小为224x224
def forward(self, x):out = self.conv1(x)out = self.relu(out)out = self.pool(out)out = self.conv2(out)out = self.relu(out)out = self.pool(out)out = out.view(out.size(0), -1) # 展平特征图out = self.fc(out)return out
3.2.3 训练与评估
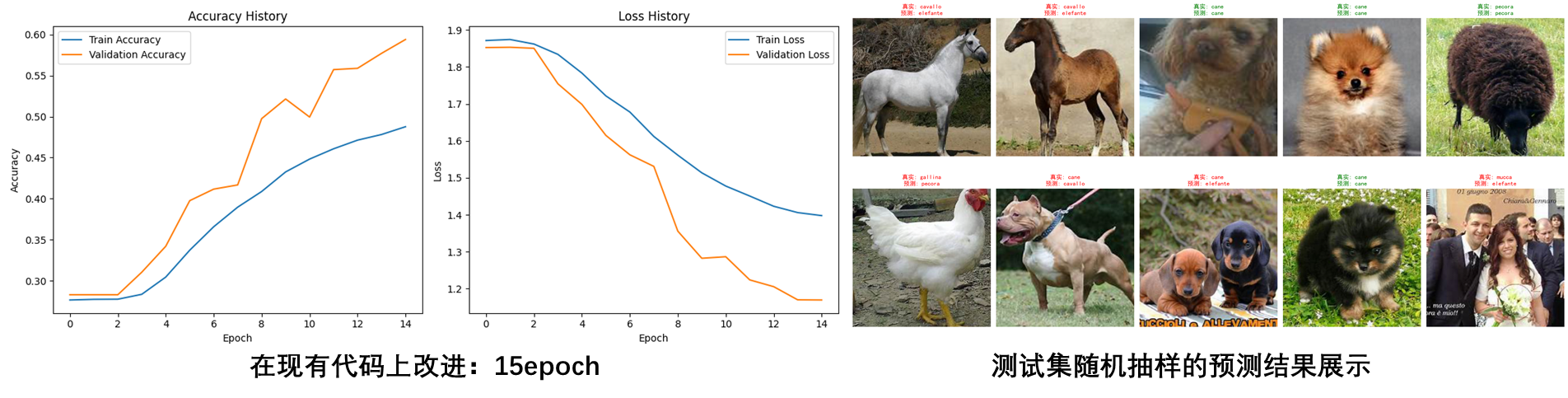
可视化训练过程:在训练过程中记录损失和准确率,并使用matplotlib进行可视化。15个epoch后,测试集准确率显著提升。
3.3 进阶实验三:数据增强与高级模型
3.3.1 数据预处理
数据增强:加入裁剪、旋转、模糊、高斯噪声、遮挡等噪声进行数据增强,以提高模型的泛化能力。
python
transform = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)), # 裁剪
transforms.RandomRotation(15), # 旋转
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1), # 色彩抖动
transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 2.0)), # 模糊
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False), # 遮挡
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化
])
3.3.2 模型搭建
ResNet与注意力机制:使用ResNet-18作为特征提取器,并在其输出特征图上应用通道注意力机制。
python
class ChannelAttention(nn.Module):
def init(self, in_planes, ratio=16):
super(ChannelAttention, self).init()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(nn.Linear(in_planes, in_planes // ratio),nn.ReLU(),nn.Linear(in_planes // ratio, in_planes))def forward(self, x):b, c, _, _ = x.size()avg_out = self.fc(self.avg_pool(x).view(b, c))max_out = self.fc(self.max_pool(x).view(b, c))out = avg_out + max_outreturn torch.sigmoid(out).view(b, c, 1, 1)
class ResNetWithAttention(nn.Module):
def init(self, num_classes):
super(ResNetWithAttention, self).init()
self.resnet = models.resnet18(pretrained=False)
self.attention = ChannelAttention(512) # ResNet-18最后一层特征图通道数为512
self.fc = nn.Linear(512, num_classes)
def forward(self, x):x = self.resnet.conv1(x)x = self.resnet.bn1(x)x = self.resnet.relu(x)x = self.resnet.maxpool(x)x = self.resnet.layer1(x)x = self.resnet.layer2(x)x = self.resnet.layer3(x)x = self.resnet.layer4(x)attention_weights = self.attention(x)x = x * attention_weightsx = self.resnet.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return x
3.3.3 训练与评估
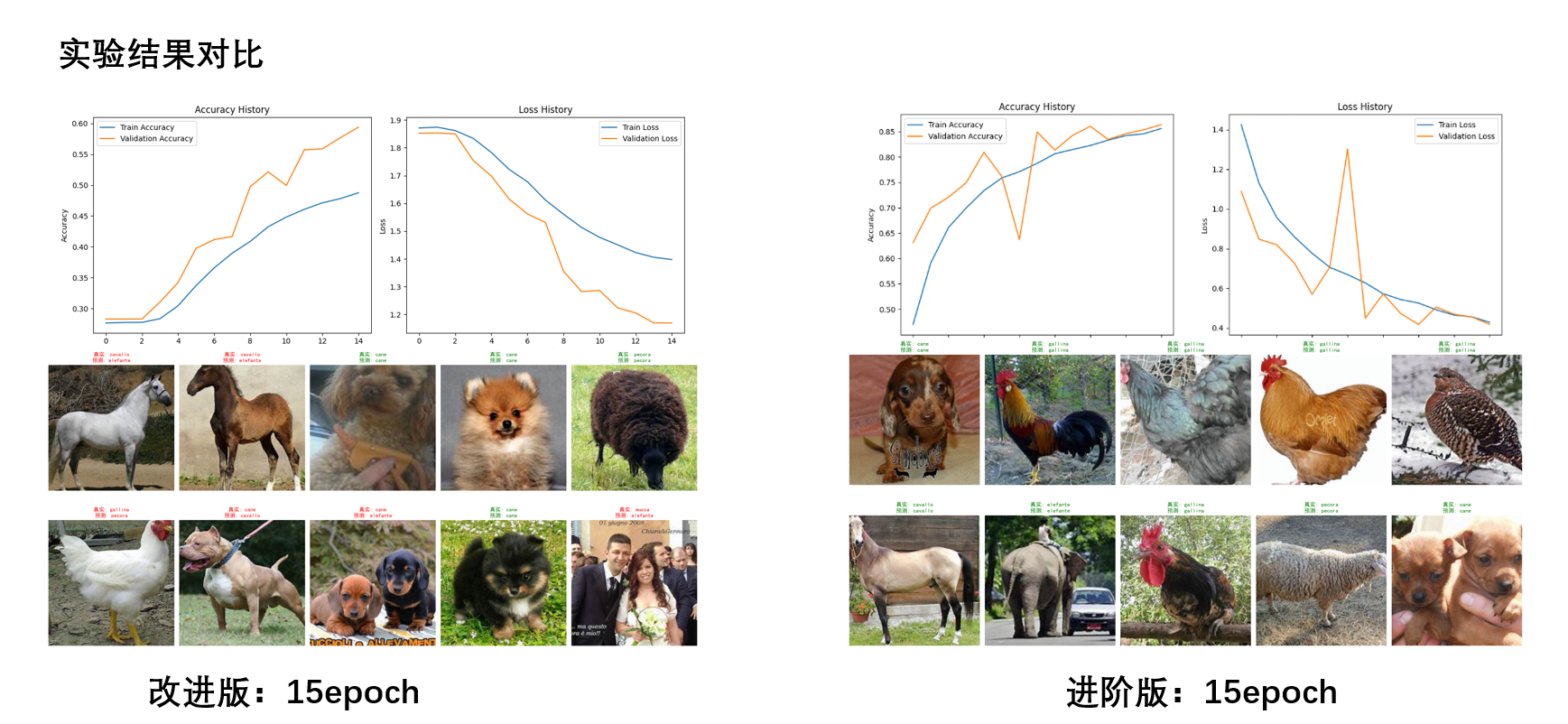
实验结果对比:通过对比不同模型在15个epoch后的测试集准确率,发现结合注意力机制的ResNet模型性能显著优于简单MLP和CNN模型。
3.4 补充实验四:迁移实验

3.4.1 迁移到MNIST手写数字识别
数据集加载:使用torchvision提供的MNIST数据集类,简化数据集加载和预处理过程。
python
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root=‘./data’, train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root=‘./data’, train=False, download=True, transform=transform)
3.4.2 模型迁移与调整
模型调整:将之前训练的模型结构稍作调整,以适应MNIST数据集的输入尺寸和类别数。通过迁移学习,快速适应新的图像分类任务。
4. 结论
本文通过一系列实验,系统探讨了深度学习在数字图像分类中的应用。实验结果表明,卷积神经网络(CNN)结合注意力机制在图像分类任务中表现出色,具有较高的准确率和鲁棒性。同时,数据增强技术有效提高了模型的泛化能力。未来工作将进一步探索更复杂的模型结构和数据增强方法,以提升图像分类的性能。