MySQL为什么选择B+tree索引作为核心索引结构?
什么是索引:
索引(Index) 是一种用于快速定位和访问数据的特殊数据结构,索引可以加速查询,降低系统开销;而由于索引也是一种数据结构,它必然会占用一定的空间,并且当进行增删改时,会在已有的数据结构节点进行操作,从而降低了增删改的效率。(一会看了B+tree结构后再详细解释这个缺点)
为什么选择B+tree索引作为核心索引结构?
MySQL(尤其是 InnoDB 存储引擎选择 B + 树作为默认索引结构,是由 B + 树的特性与数据库的核心需求(查询效率、范围操作、稳定性、存储友好性)深度匹配决定的。
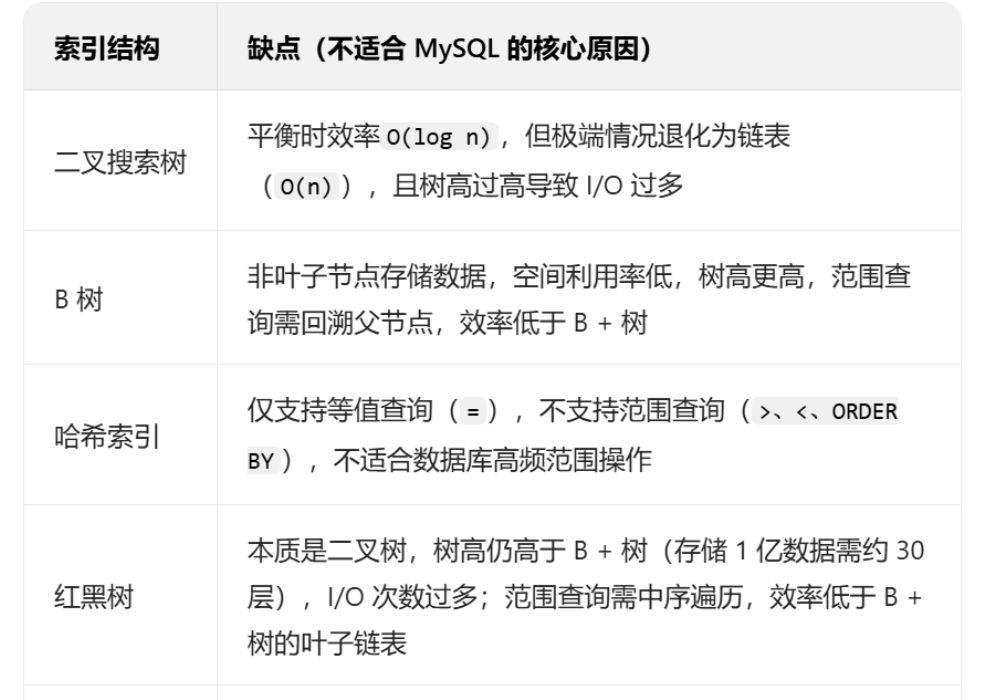
总结来讲:使用普通二叉树,如果是顺序插入,会退化成为一条链表,在搜索时和全表扫描几乎无差;比普通二叉树高级一些的红黑树,是一种平衡二叉树,可以解决顺序插入问题,但是二叉树每一个节点只能存放一个数据,当数据几百万条时,会形成深度非常大的二叉树,不仅占用空间,而且效率也会底下;B树的出现解决了前两个问题,因为B树的每一页,可以存放多条数据:以3阶B树为例:每一页可以存放两个key,有三个指针可以指向另一页,也就是说每一页都可以存放两个key,而key下面挂着的就是与之相关的数据,但由于B树的非叶子节点也会存储数据,每一页的大小也是有限的,所以还是无法完全避免空间利用率低这一问题;而B+tree做了升级改造,不同于B树,B+tree只在叶子节点存储数据,并且叶子节点包含了全部的数据,并且在叶子节点形成了单向链表,还是以3阶树为例,来看相同数据,在B树与B+tree有什么不同:
B树:
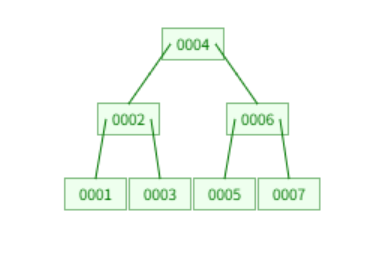
B树的每一个节点的key都会有对应value
B+tree:
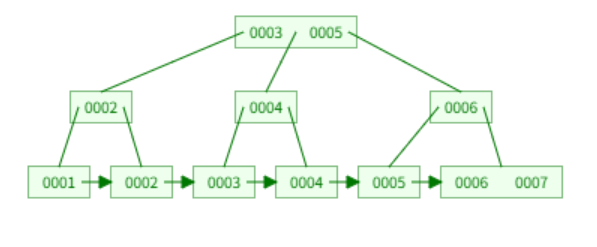
B+tree只有叶子节点的key对应拥有value,非叶子节点的key只用于“导航”作用
MySQL中的B+tree结构又进行了优化,底部的单向链表变为双向链表,增加区间访问性能
InnoDB 存储引擎中,索引可以明确划分为 聚簇索引和 二级索引
- 聚簇索引:是表的 “核心索引”,直接与数据行物理存储绑定,叶子节点存储完整数据行;(必须存在,有且只有一个,通常有主键(id)时,会选择主键作为聚集索引;若未规定主键,但是有唯一索引,会使用第一个规定为唯一索引的指定为聚集索引;如果不存在,InnoDB 存储引擎会自动生成一个rowid作为聚集索引)
- 二级索引:是 “辅助索引”,依赖聚簇索引存在,叶子节点存储 索引键 底下挂着 聚簇索引键(涉及回表,因为二级索引key对应的value是聚集索引,数据不完整,通过聚集索引进行回表,从而拿到全部数据)
除了 B+ 树,MySQL 还针对特定场景提供其他索引类型:例如全文索引