【论文精读】STAR:基于文本到视频模型的空间-时间增强真实世界视频超分
标题:STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
作者:Rui Xie¹∗, Yinhong Liu¹∗, Penghao Zhou², Chen Zhao¹, Jun Zhou³, Kai Zhang¹, Zhenyu Zhang¹, Jian Yang¹, Zhenheng Yang², Ying Tai¹†
机构:¹南京大学,²字节跳动,³西南大学期刊:CVPR2025
链接:https://nju-pcalab.github.io/projects/STAR
时间:2025年10月13日
一、引言:真实世界视频超分的挑战与新范式
视频超分辨率(Video Super-Resolution, VSR)是计算机视觉中的经典任务,旨在将低分辨率(LR)视频恢复为高分辨率(HR)视频,以提升视觉质量。然而,真实世界(Real-World)视频超分远比合成数据上的任务复杂得多。真实视频通常受到未知的复杂退化(degradations)影响,如噪声、模糊、压缩伪影等,这些退化在训练数据中难以完全建模。
传统方法(如基于GAN的模型)虽然能生成细节,但常出现**过度平滑(over-smoothing)**问题。近年来,图像扩散模型被引入VSR,虽提升了生成质量,但由于其训练数据主要为静态图像,**时间一致性(temporal consistency)**难以保证。
在此背景下,STAR(Spatial-Temporal Augmentation with Text-to-Video Models)应运而生。该论文首次将强大的文本到视频(Text-to-Video, T2V)扩散模型引入真实世界视频超分,提出了一种全新的空间-时间增强框架,显著提升了恢复视频的空间细节与时间连贯性。
图1:直观的视觉对比

图1 是论文开篇的核心视觉证据,它直观地展示了STAR相较于当前最先进方法(SOTA)的巨大优势。该图对比了在真实世界输入和合成低分辨率视频上的恢复效果。
从图中可以清晰地看到:
- Real-ESRGAN 和 RealViformer 等GAN或Transformer-based方法虽然能提升分辨率,但存在明显的过度平滑问题,面部纹理模糊,文字边缘不清晰。
- Upscale-A-Video 作为基于文本到图像扩散模型的方法,虽然细节有所提升,但在处理真实世界的复杂退化时,时间一致性较差,且文字结构恢复不佳。
- STAR(Ours) 的输出则展现出更自然的面部细节(如皮肤纹理、胡须)和更清晰、结构完整的文字。这充分证明了T2V先验在捕捉真实世界视频的时空动态和恢复精细结构方面的优越性。
二、核心思想与贡献
STAR的核心思想是:利用预训练的T2V扩散模型作为强大的时空先验(spatio-temporal prior),指导视频超分过程。T2V模型(如CogVideoX、I2VGen-XL)在海量视频-文本对上训练,具备极强的时空建模能力,能够生成连贯、逼真的视频内容。
主要贡献:
- 提出STAR框架:首次将T2V扩散先验引入真实世界VSR,实现高质量的时空恢复。
- 局部信息增强模块(LIEM):在T2V模型的全局注意力前引入局部增强模块,缓解复杂退化带来的伪影。
- 动态频率损失(DF Loss):设计了一种频率感知的损失函数,引导模型在不同扩散步中分别关注低频(结构)和高频(细节),提升保真度。
- 实验验证:在多个合成与真实数据集上,STAR在DOVER(视频清晰度)、E*warp(时间一致性)等指标上超越现有SOTA方法。
三、方法详解
3.1 整体架构
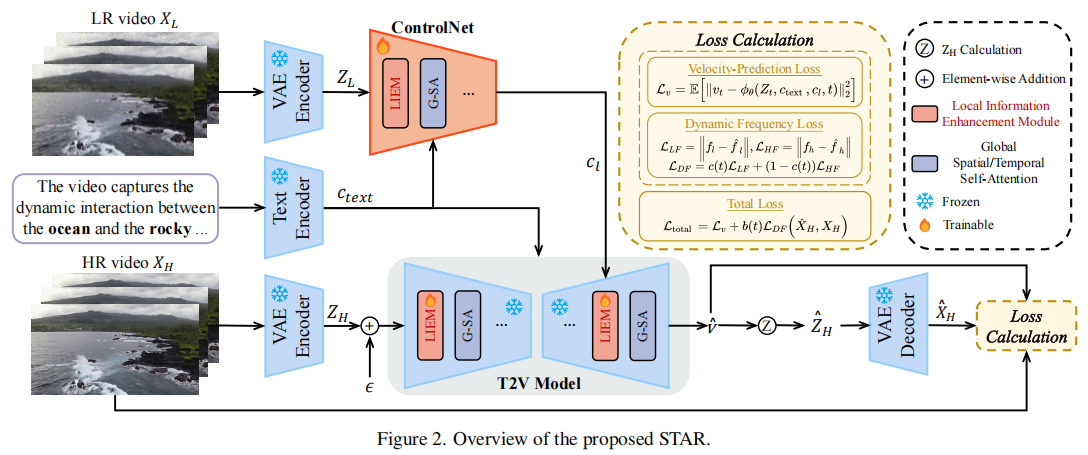
STAR的整体框架如 图2 所示,主要由以下模块构成:
- VAE Encoder:将LR视频
和HR视频
编码为潜在表示
和
。
- 文本编码器(Text Encoder):生成文本嵌入
,提供高层语义信息。
- ControlNet:以
,用于引导T2V模型。
- T2V模型(含LIEM):接收带噪声的潜在
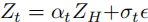 、文本嵌入和控制信号,预测速度
、文本嵌入和控制信号,预测速度 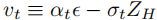 。
。 - 损失函数:包括速度预测损失
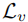 和提出的动态频率损失
和提出的动态频率损失 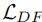 。
。
训练目标:
![]()
其中 是随扩散步变化的权重函数,用于平衡两个损失。
训练数据集:
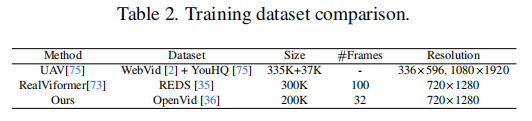
高质量、大规模的训练数据也是STAR成功的重要因素之一。
从表2中可以看出:
- STAR采用的OpenVid-1M数据集是一个高质量的野外视频数据集,包含超过100万个带详细字幕的视频片段,最小分辨率为512×512。
- 相比于RealViformer使用的REDS数据集(专为视频去模糊设计),OpenVid-1M的视频内容更加多样化、真实,且包含丰富的文本描述,这为T2V模型提供了更强大的时空先验学习基础。
- STAR的训练数据虽然在数量上不是最大,但其高质量和高相关性(与T2V任务匹配)是其性能优越的关键。
3.2 局部信息增强模块(LIEM)
模块设计动机
大多数T2V模型依赖全局自注意力(global self-attention) 来捕捉全局语义,生成完整视频。但在视频超分任务中,这种机制存在两大问题:
- 退化去除困难:全局注意力将整个退化视频作为一个整体处理,难以精细去除局部噪声或模糊。
- 局部细节缺失:缺乏对局部结构的关注,导致输出模糊。
如 图3(右) 所示,仅使用全局结构可能导致细节丢失,而结合局部与全局结构能更好地保留细节。

LIEM设计
STAR提出在T2V模型的全局注意力块前插入局部信息增强模块(LIEM),其结构借鉴自CBAM(Convolutional Block Attention Module)。
具体计算如下:
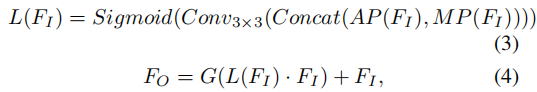
其中:
:输入特征
:输出特征
- G(⋅):全局注意力块
- L(⋅):LIEM
- AP 和 MP:平均池化和最大池化
LIEM通过通道注意力机制,增强局部区域的特征响应,使模型在进行全局聚合前先关注局部细节。
图3(左) 的可视化对比显示,使用LIEM后,局部细节更加清晰,伪影显著减少。

3.3 动态频率损失(Dynamic Frequency Loss)
模块设计动机
扩散模型的强大生成能力可能损害恢复的保真度(fidelity)。作者观察到,在反向扩散过程中,模型的恢复行为具有阶段性:
- 早期阶段:主要恢复低频成分(如整体结构、轮廓)。
- 后期阶段:主要细化高频成分(如纹理、边缘)。
如 图4(左) 所示,低频PSNR在早期快速上升,而高频PSNR在后期才显著提升。图4(右) 的可视化也印证了这一现象。
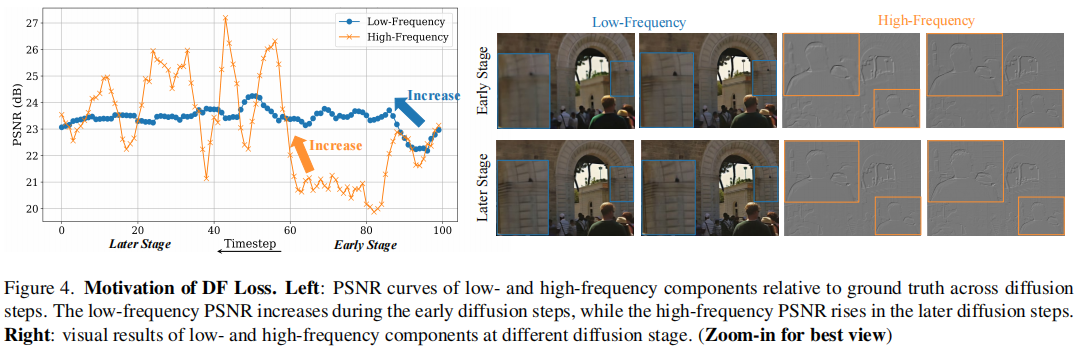
因此,作者提出动态频率损失(DF Loss),在不同扩散步中动态调整对低频和高频的约束。
DF Loss设计
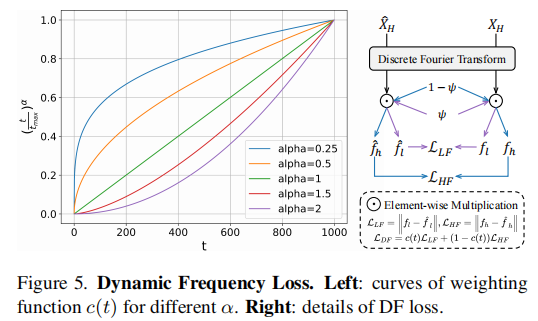
流程如 图5 所示:
- 从预测的潜在
解码得到
。
- 对
进行离散傅里叶变换(DFT),得到频域表示。
- 使用预定义的低通滤波器 ψ 分离低频
和高频
成分:
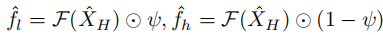
- 计算低频损失
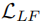 和高频损失
和高频损失 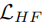 :
: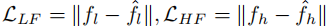
- 动态加权(
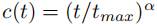 ):
):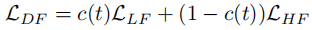
其中 c(t) 随扩散步 t 增加而减小,意味着早期更关注低频,后期更关注高频。
图5(左) 展示了不同 α 下的权重曲线,验证了该设计的灵活性。
四、实验与结果
4.1 数据集与实现细节
- 训练数据:OpenVid-1M 子集(约20万文本-视频对),分辨率为720×1280,32帧。
- 测试数据:
- 合成数据集:UDM10、REDS30、OpenVid30
- 真实数据集:VideoLQ(50个100帧视频)
- T2V主干:默认使用I2VGen-XL,也可替换为CogVideoX-2B/5B。
- 训练:8×A100 GPU,15K迭代,学习率5e-5。
4.2 定量结果
表1 展示了在多个数据集上的定量比较:
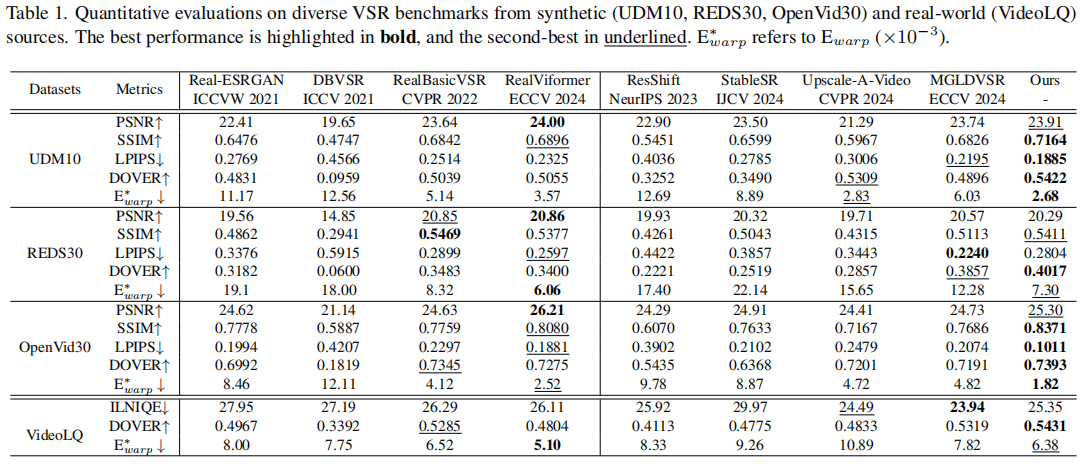
STAR在SSIM、LPIPS、DOVER和E*warp等关键指标上全面领先,尤其在DOVER(视频清晰度)上表现突出,证明其生成的视频更清晰、自然。
4.3 定性结果
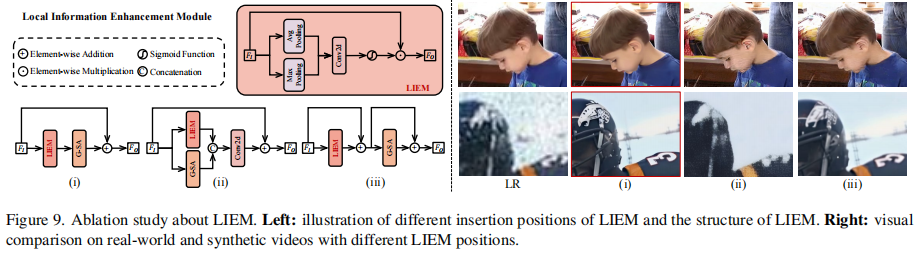
图6 和 图7 展示了在合成和真实视频上的视觉对比。STAR生成的面部纹理、文字结构、动物毛发等细节更加真实,且退化去除更彻底。
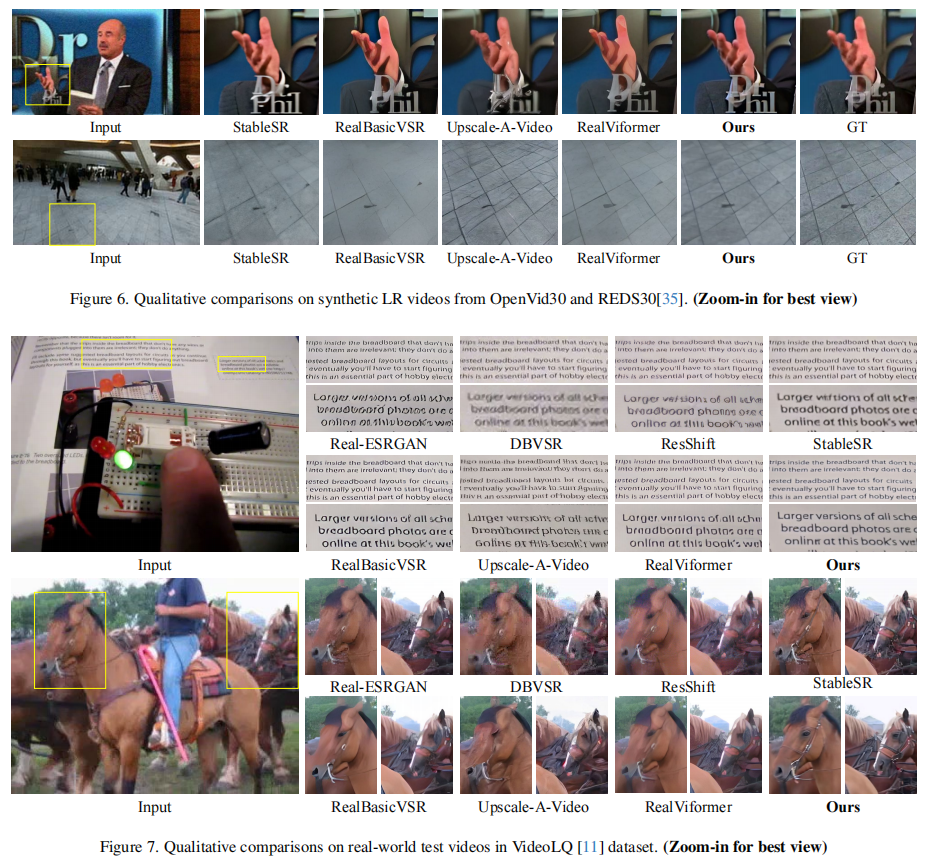
图8 对比了时间一致性。STAR在无光流引导的情况下,仍能保持极佳的帧间连贯性,而StableSR等图像超分方法则出现明显抖动。

五、消融实验
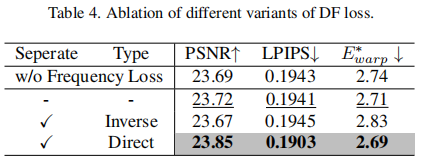
5.1 LIEM位置分析(表3 & 图9)
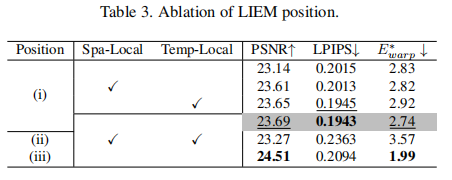
在空间和时间注意力块上同时添加LIEM效果最佳。插入位置(i)优于(ii)和(iii),说明过强的修改会破坏预训练先验。
5.2 DF Loss变体(表4)
分离频率成分并采用“direct”加权(早期重低频,后期重高频)效果最好,PSNR和LPIPS均提升。
5.3 参数选择(表5)
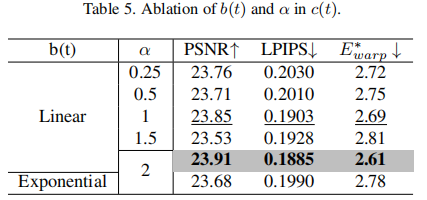
b(t) 采用线性形式,α=2 时性能最优。
5.4 模型扩展性(表6 & 图10)

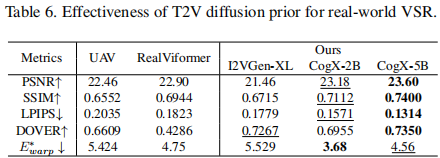
使用更大的T2V模型(如CogVideoX-5B)能进一步提升性能,SSIM从0.6944升至0.7400,DOVER从0.6609升至0.7350,验证了缩放定律(scaling law) 在VSR中的有效性。
六、总结与展望
STAR开创性地将T2V扩散模型引入真实世界视频超分,通过LIEM和DF Loss两个关键设计,有效解决了退化去除、细节恢复和时间一致性三大挑战。
未来方向:
- 探索更高效的T2V主干
- 结合多模态信息(如音频)
- 实时推理优化
STAR不仅是一个高性能的VSR方法,更揭示了生成式先验在图像恢复任务中的巨大潜力,为后续研究提供了新思路。