腾讯开源80B参数混元图像3.0模型:AI作画正在“拥有大脑”
目录
引言:一场来自东方的“盲测”风暴
一、拆解混元图像3.0:它到底强在哪?
1.1 “以文驭图”的极致:精准理解复杂指令
1.2 文字不再是“天书”:业界顶级的文字渲染能力
1.3 注入“世界知识”:从画画到“知识可视化”
二、“大力”如何出奇迹?揭秘背后的技术架构
三、开源的雄心:腾讯的“AI操作系统”阳谋
结语:AI作画的下半场,比拼的是“思想”

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 腾讯开源80B参数混元图像3.0模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:一场来自东方的“盲测”风暴
在人工智能的世界里,没有什么比一场公平的“盲测”更能检验一个模型的真实力。所谓“盲测”,就是用户在不知道模型品牌的情况下,仅凭生成结果的好坏进行投票。它剥离了所有品牌光环和市场宣传,让技术本身站上擂台。
就在最近,全球最权威的AI竞技场之一——由加州大学伯克利分校主导的LMArena平台,公布了其文生图榜单的最新结果。出乎许多人意料,登顶榜首的并非大家熟知的Midjourney或谷歌、OpenAI的最新力作,而是一个来自中国的名字:腾讯混元图像3.0。

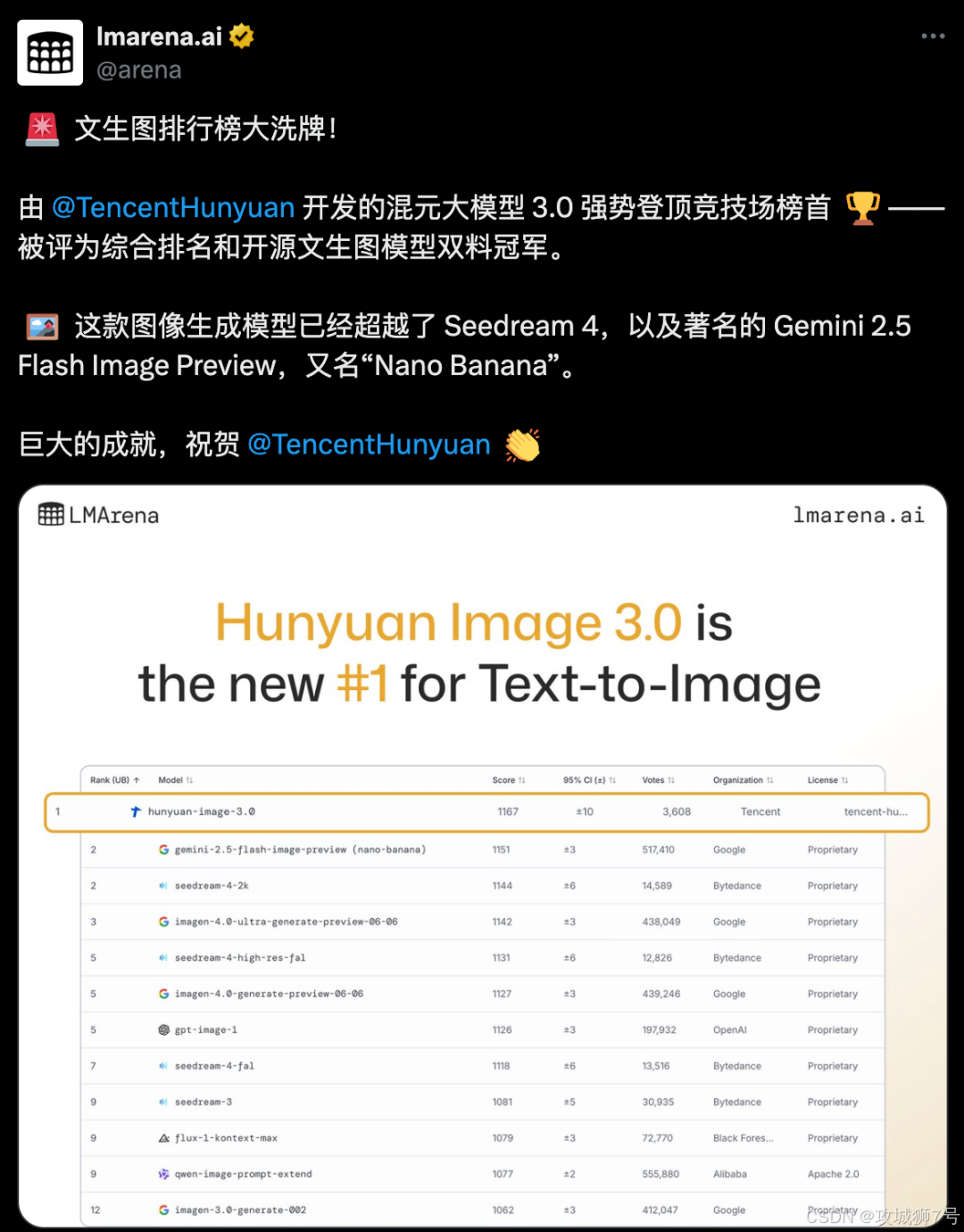
这一消息,犹如一颗重磅炸弹。它不仅意味着国产AI模型在硬实力上首次于国际顶级“盲测”中拔得头筹,更因为它打破了过去一段时间里,人们对于AI文生图领域竞争格局的固有认知。要知道,腾讯在这条赛道上起步并不算早,当Midjourney、Stable Diffusion等模型已是声名鹊起之时,混元才刚刚发布第一个版本。
这次登顶,是一次典型的“厚积薄发”。它用无可辩驳的用户偏好数据证明,一个后来者,同样可以通过扎实的技术积累实现超越。更重要的是,通过深入分析混元图像3.0的种种表现,我们发现,AI作画的竞赛规则,可能正在悄然改变。
一、拆解混元图像3.0:它到底强在哪?
混元图像3.0的惊艳之处,不在于某一项单点技术的突破,而在于其综合能力的全面强大,尤其是在三个被认为是行业“硬骨头”的方面,它都交出了近乎完美的答卷。
1.1 “以文驭图”的极致:精准理解复杂指令
长久以来,AI“听不懂人话”是用户最大的痛点之一。你常常需要用各种奇特的“咒语”(prompt)去迁就模型,才能得到勉强满意的结果。而混元图像3.0则展现出了超强的长文本和复杂语义理解能力。
例如,当用户输入一段极其详细的人像摄影指令:“……亚洲女性,白皙皮肤,黑色及肩波浪卷发,直视镜头,红唇微张,身穿白色细吊带背心,右臂套着棕色罗纹长袖毛衣……”。
该模型不仅精准地还原了每一个细节——从发型、肤色到服装的材质和穿着方式,甚至连“眼神中透出一股若有似无的忧郁气息”这种极其主观的氛围感,都拿捏得十分到位。这证明它不再是简单地拼凑元素,而是在真正“理解”文本所要描绘的场景和情感。

1.2 文字不再是“天书”:业界顶级的文字渲染能力
在图片中精准地生成文字,尤其是结构复杂、笔画多变的汉字,一直是AI文生图领域的“噩梦”。绝大多数模型生成的文字,要么是拼写错误,要么是无法辨认的“异星符号”。
混元图像3.0则近乎完美地解决了这个问题。无论是制作PPT封面、目录页,还是设计带有复杂中英文案的海报,它都能生成清晰、准确、且具有设计感的文字。在测试中,它甚至能将乔布斯的演讲稿完整地“写”在一张虚拟的黑板上,字迹清晰、排版合理。这种强大的文字渲染能力,使其应用场景从单纯的艺术创作,极大地扩展到了设计、营销、教育等更广阔的商业领域。

1.3 注入“世界知识”:从画画到“知识可视化”
这是混元图像3.0最令人兴奋,也是最具革命性的一点——它不仅仅是一个“画家”,更是一个“学者”。
得益于海量的知识库训练,它能理解并图解复杂的科学、历史、文化甚至算法知识。你让它画“牛顿第一定律”,它能创作出一幅解释惯性的插画;你让它解释“堆排序算法”,它能用可爱的表情包,将抽象的数据结构变化过程可视化;你让它制作“双黄莲蓉月饼”的教程,它能画出清晰的步骤图。

这种能力,意味着AI文生图正从一个“美学工具”,进化为一个“知识工具”和“沟通工具”。它不再仅仅是“画得好看”,而是能够“画得明白”。对于教育工作者、科普创作者、技术人员来说,这无疑开启了一个全新的内容生产范式。原本需要复杂绘图软件和专业知识才能完成的知识图解,现在可能只需要一句自然语言的描述。
二、“大力”如何出奇迹?揭秘背后的技术架构
如此强大的综合能力,背后必然有其独特的技术支撑。混元图像3.0的成功,主要源于其“原生多模态”的架构设计和海量的、高质量的训练数据。
首先,它是一个“原生思想家”,而非“拼接工具人”。很多早期的多模态模型,更像是将一个强大的语言模型(负责理解)和一个强大的图像模型(负责绘画)“粘”在一起。而混元采用的“原生多模态架构”,从设计之初就让模型同时具备语言的思考能力和图像的生成能力。官方提出的“Transfusion”机制,深度耦合了Transformer的长文本理解能力和Diffusion的图像生成能力,使其“大脑”和“双手”能够协同一致地工作。这就像一个自带哲学思想的画家,而不是一个听指令干活的画匠。
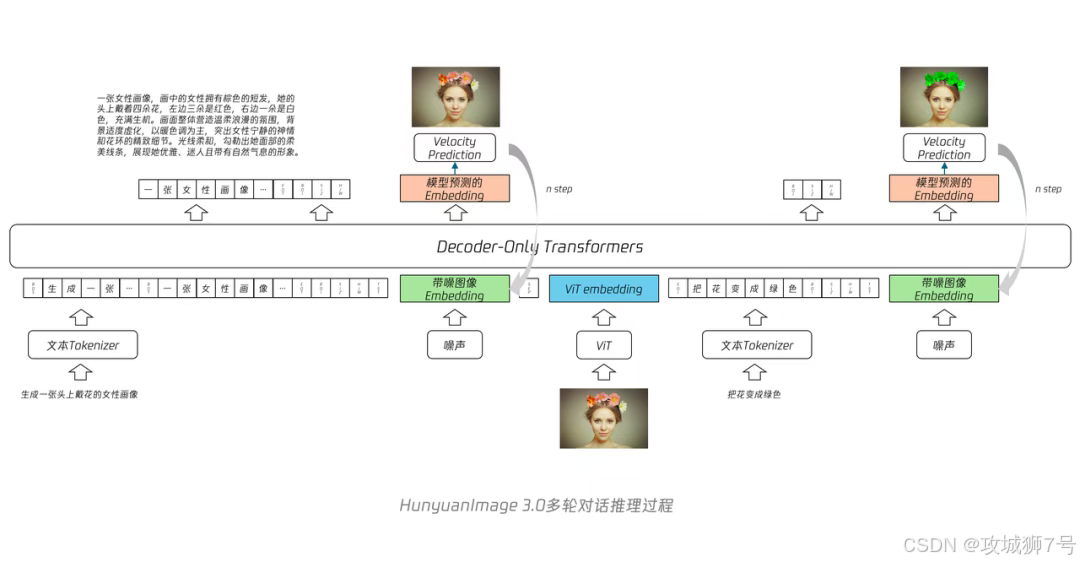
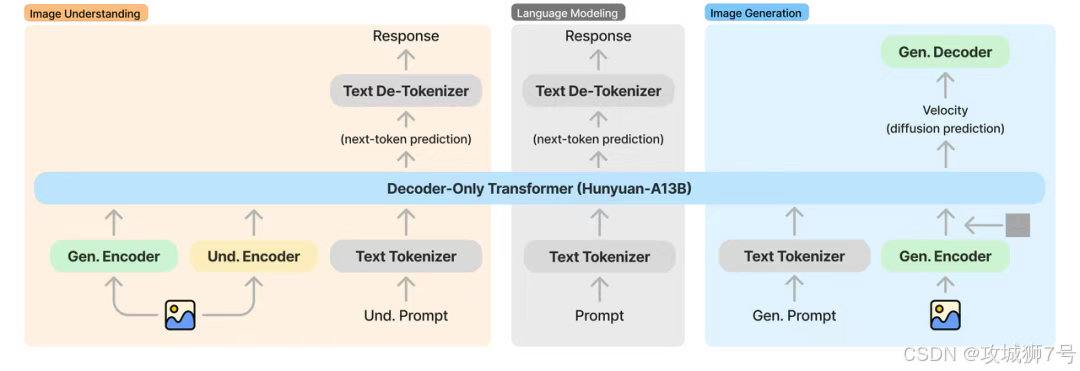
其次,它拥有庞大的“图文阅历”。混元图像3.0的学习资料堪称海量,包括50亿个图像-文本对、海量的视频帧、以及高达600万亿token的纯文本语料。正如官方比喻的那样,这就像一个人读了无数本图文并茂的百科全书和故事集,天长日久,自然就深刻理解了文字与画面之间的复杂对应关系,并掌握了世界运行的常识。
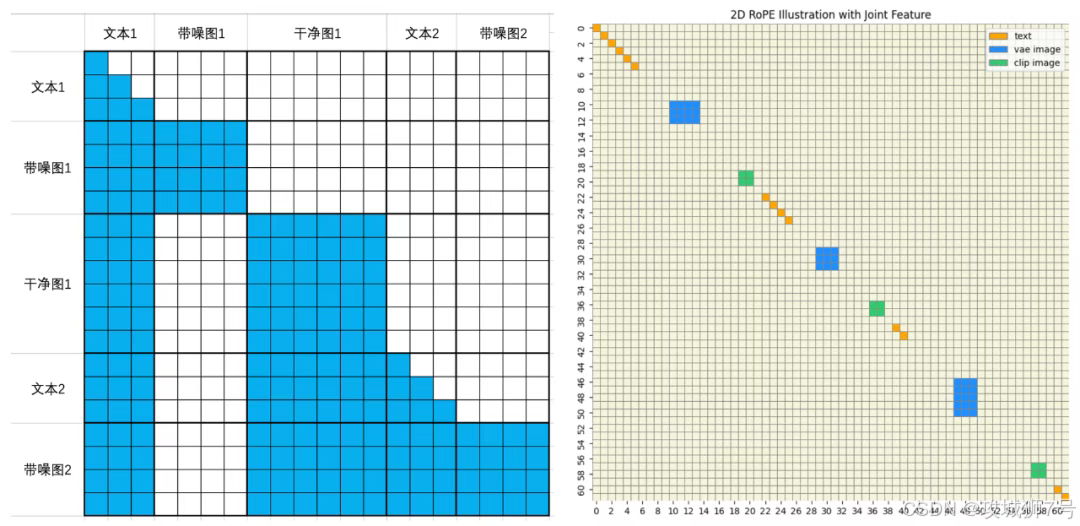
最后,它采用了“渐进式训练”。这种训练方式,如同一个人的成长过程,先从低分辨率的简单任务开始学起,逐步提升任务的难度和图像的精细度。这样做的好处是训练过程更稳定,模型的基本功更扎实,最终生成的结果也更可靠,不容易出现画面崩坏或文字乱码等低级错误。
三、开源的雄心:腾讯的“AI操作系统”阳谋
在取得如此成就之后,腾讯做出了一个更具战略眼光的决定:将这个拥有80B(800亿)参数的“工业级”模型,全面开源。
这使其成为了目前参数量最大的开源文生图模型。这一举动,传递出的信号远比一次技术竞赛的胜利要深远。
开源,意味着腾讯并不满足于只做一个强大的AI应用,而是希望成为AI时代的“基础设施”提供者。正如文章中指出的那样,这是一种旨在成为“AI时代的Windows或Android”的雄心。通过将强大的底层模型开放给全球的开发者,腾讯可以快速构建一个庞大的开发者生态。未来,无数创新的AI应用,可能都将运行在混元的“底座”之上。
对于整个行业而言,这无疑是一剂强心针。它为中小企业和独立开发者提供了直接使用世界顶级模型的能力,极大地降低了AI创新的门槛,有助于激发更广泛的社区创造力,催生出更多元化的应用场景。
结语:AI作画的下半场,比拼的是“思想”
混元图像3.0的登顶,或许是AI文生图领域发展的一个分水岭。在此之前,我们更多地关注生成图像的真实感、艺术性和风格多样性——比拼的是“美学”。而混元图像3.0用它的表现告诉我们,下半场的竞争,将越来越多地围绕“知识”、“逻辑”和“思想”展开。
一个AI模型,能否准确理解你的意图?能否运用常识进行推理?能否将抽象复杂的概念转化为清晰的视觉语言?这些问题,正在成为衡量一个模型是否真正“智能”的新标准。
从这个角度看,腾讯混元图像3.0不仅是一个更会“画画”的AI,更是一个更会“思考”的AI。它为我们揭示了AI内容创作的未来方向:不再是单纯的视觉奇观,而是人类知识、创意与机器智能深度融合的强大媒介。这次,中国AI不仅追上了,更在某种意义上,为赛道指出了一个新的方向。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!