【IO多路复用】原理与选型(select/poll/epoll 解析)
文章目录
- I/O 多路复用:原理与选型(select/poll/epoll 解析)
- 1. 概念定义
- 1.1 核心定义
- 1.2 同步 I/O 与异步 I/O 的区别
- 2. 三大实现方案对比
- 3. 各方案技术解析
- 3.1 select:传统基础方案
- 工作流程
- 局限性
- 3.2 poll:FD 数量突破方案
- 核心改进:struct pollfd 结构
- 工作流程
- 局限性
- 3.3 epoll:高并发最优方案
- 核心设计:双数据结构
- 核心函数
- 触发模式(LT vs ET)
- 4. 应用场景选型
- 5. 总结
I/O 多路复用:原理与选型(select/poll/epoll 解析)
高并发网络编程中,“单线程 / 进程高效管理多 I/O 连接” 是核心需求。传统 “一连接一线程” 模型因线程切换开销过高存在瓶颈,I/O 多路复用通过 “内核协助监控多文件描述符(FD)” 解决此问题。本文从定义出发,对比三大实现方案,拆解核心原理,提供选型指导。
1. 概念定义
1.1 核心定义
I/O 多路复用是同步 I/O 模型,核心逻辑:单个进程 / 线程通过内核,同时监控多个 I/O 文件描述符(FD);当某 FD 进入 “就绪” 状态(可读 / 可写 / 异常),内核通知进程 / 线程,再由其处理该 FD 的 I/O 操作。
1.2 同步 I/O 与异步 I/O 的区别
-
同步 I/O:FD 就绪后,需用户进程主动调用read/write完成 I/O(操作可能阻塞);
-
异步 I/O:内核直接完成 I/O(如数据从内核缓冲区拷贝至用户缓冲区),完成后通知进程(全程无阻塞)。
关键结论:I/O 多路复用属于同步 I/O,因 FD 就绪后需用户进程主动处理 I/O。
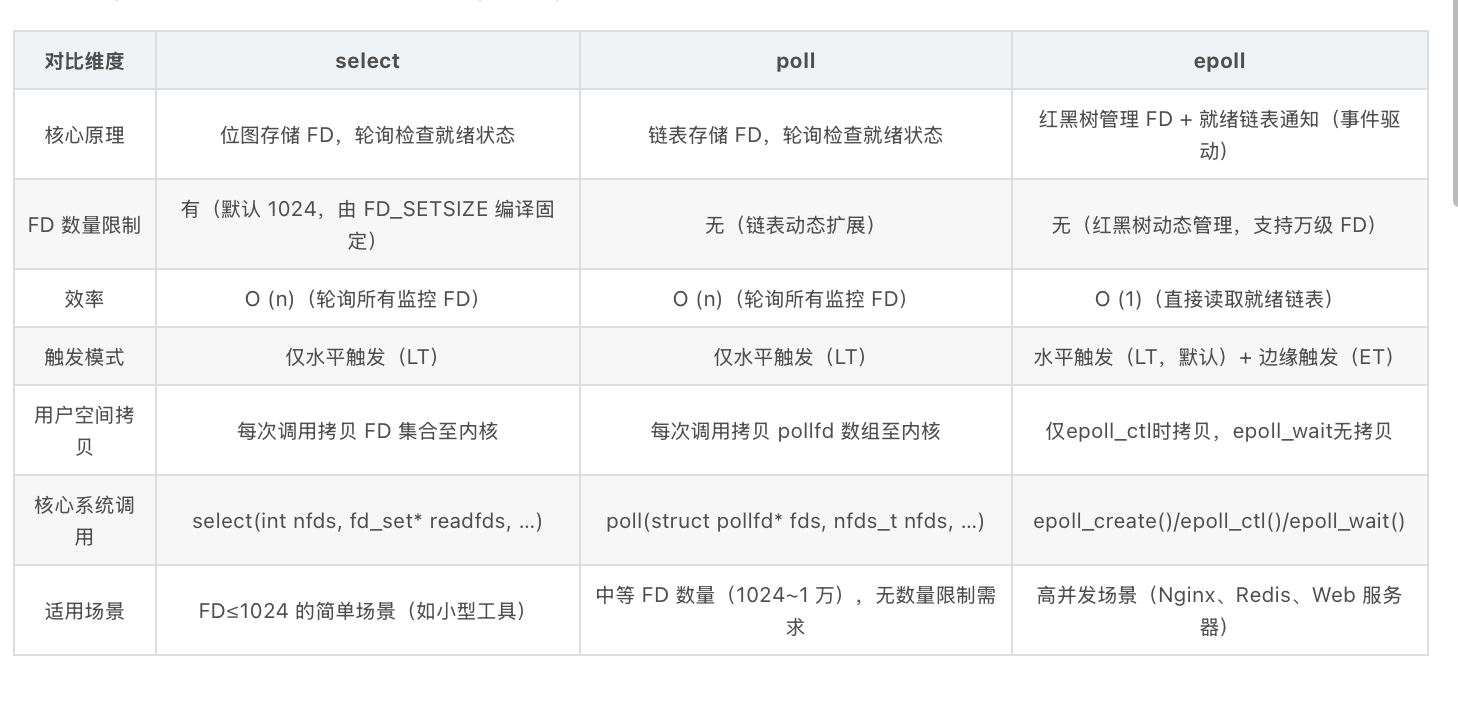
2. 三大实现方案对比
Linux 下 I/O 多路复用的主流方案为 select、poll、epoll,设计差异决定其性能与适用场景,对比如下:
| 对比维度 | select | poll | epoll |
|---|---|---|---|
| 核心原理 | 位图存储 FD,轮询检查就绪状态 | 链表存储 FD,轮询检查就绪状态 | 红黑树管理 FD + 就绪链表通知(事件驱动) |
| FD 数量限制 | 有(默认 1024,由 FD_SETSIZE 编译固定) | 无(链表动态扩展) | 无(红黑树动态管理,支持万级 FD) |
| 效率 | O (n)(轮询所有监控 FD) | O (n)(轮询所有监控 FD) | O (1)(直接读取就绪链表) |
| 触发模式 | 仅水平触发(LT) | 仅水平触发(LT) | 水平触发(LT,默认)+ 边缘触发(ET) |
| 用户空间拷贝 | 每次调用拷贝 FD 集合至内核 | 每次调用拷贝 pollfd 数组至内核 | 仅epoll_ctl时拷贝,epoll_wait无拷贝 |
| 核心系统调用 | select(int nfds, fd_set* readfds, …) | poll(struct pollfd* fds, nfds_t nfds, …) | epoll_create()/epoll_ctl()/epoll_wait() |
| 适用场景 | FD≤1024 的简单场景(如小型工具) | 中等 FD 数量(1024~1 万),无数量限制需求 | 高并发场景(Nginx、Redis、Web 服务器) |
3. 各方案技术解析
3.1 select:传统基础方案
select 是最早的 I/O 多路复用接口,仅适用于低并发场景。
工作流程
-
初始化 FD 集合:通过FD_ZERO清空、FD_SET将目标 FD 加入 “可读”“可写”“异常” 三类集合;
-
调用select:传入 FD 集合与超时时间,进程阻塞,内核开始监控 FD;
-
内核通知:FD 就绪或超时后,内核唤醒进程,修改 FD 集合(仅保留就绪 FD);
-
处理 I/O:进程遍历所有监控 FD,判断是否在就绪集合中,若在则处理。
局限性
-
FD 数量被限制为 1024,无法扩展;
-
轮询效率随 FD 数量增加而下降;
-
每次调用需拷贝三类 FD 集合至内核,开销随 FD 数量增长。
3.2 poll:FD 数量突破方案
poll 针对 select 的 FD 数量限制做优化,但未解决效率问题。
核心改进:struct pollfd 结构
通过动态数组struct pollfd存储 FD 信息,无需区分三类集合,数组大小由用户指定(突破 1024 限制):
struct pollfd {int fd; // 目标FDshort events; // 关注事件(POLLIN=可读,POLLOUT=可写)short revents; // 实际发生事件(内核填充)
};
工作流程
-
构造pollfd数组:为每个监控 FD 创建元素,设置events;
-
调用poll:传入数组与超时时间,进程阻塞;
-
内核通知:FD 就绪后,内核唤醒进程,填充revents;
-
处理 I/O:遍历数组,通过revents判断 FD 就绪状态,进而处理。
局限性
-
效率仍为 O (n),需轮询所有 FD;
-
每次调用需拷贝整个pollfd数组至内核,开销随 FD 数量增长。
3.3 epoll:高并发最优方案
Linux 2.6 内核引入 epoll,解决 select/poll 的效率与开销问题,是高并发场景标配。
核心设计:双数据结构
-
红黑树:存储所有监控 FD,通过epoll_ctl实现 O (log n) 的插入 / 删除 / 查找;
-
就绪链表:存储就绪 FD,epoll_wait直接读取链表,无需轮询。
核心函数
| 函数 | 功能描述 |
|---|---|
| epoll_create() | 创建 epoll 实例(返回 epoll FD),内核分配红黑树与就绪链表资源 |
| epoll_ctl() | 管理监控列表:向红黑树添加 / 修改 / 删除 FD,设置关注事件(如 EPOLLIN) |
| epoll_wait() | 阻塞等待就绪 FD,返回就绪 FD 列表(读取就绪链表) |
触发模式(LT vs ET)
| 触发模式 | 核心逻辑 | 优缺点 | 编程注意事项 |
|---|---|---|---|
| LT(水平触发) | FD 对应内核缓冲区有数据 / 空间时,持续通知进程 | 优点:易用,无需一次性处理完数据;缺点:可能重复通知 | 无需设置 FD 为非阻塞 |
| ET(边缘触发) | 仅当 FD 状态从 “未就绪→就绪” 时,通知一次 | 优点:减少内核与用户交互;缺点:需一次性处理完数据 | 必须设置 FD 为非阻塞,循环读写至 “资源暂时不可用”(如read返回 - 1 且errno=EAGAIN) |
4. 应用场景选型
-
select:仅用于 FD≤1024 的简单场景(如本地工具、低并发脚本),不推荐生产环境;
-
poll:适用于 FD 数量 1024~1 万、对性能要求不极致的场景(如内部管理系统),优先选择 epoll;
-
epoll:生产环境首选,适用于高并发场景:
-
Web 服务器(Nginx 用 epoll 处理万级连接);
-
缓存中间件(Redis 用 epoll 管理客户端连接);
-
消息队列(Kafka 用 epoll 处理高吞吐消息)。
5. 总结
I/O 多路复用的演进核心是 “减少无效开销,提升监控效率”:
-
select:解决多 FD 监控基础需求,但受 FD 数量与轮询效率限制;
-
poll:突破 FD 数量限制,但未解决轮询开销;
-
epoll:通过 “红黑树 + 就绪链表” 与 “双触发模式”,实现 O (1) 效率,成为高并发终极方案。
掌握 I/O 多路复用,可深入理解 Nginx、Redis 等中间件的底层逻辑,为高性能网络程序开发提供支撑。