有序逻辑回归的概念、适用场景、数据要求,以及其在Stata中的操作命令及注意事项,Stata ologit回归结果怎么看?并附详细示例
有序逻辑回归(Ordinal Logistic Regression)详解
有序逻辑回归是一种处理因变量为有序分类变量(例如满意度评级:不满意、一般、满意;疾病严重程度:轻度、中度、重度)的统计方法。它通过建模因变量的累积概率来捕捉自变量对类别顺序的影响,比多元无序逻辑回归更高效,因为它利用了因变量的顺序信息。以下从概念、适用场景、数据要求、Stata操作、结果解读及示例等方面详细说明。
一、基本概念
有序逻辑回归的核心思想是将有序因变量(如 Y有 J个类别,Y=1,2,...,J)转换为累积概率的建模。模型假设存在一个潜在连续变量,其值域被阈值(cut points)分割成有序类别。模型形式为:
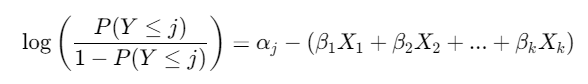
其中:
P(Y≤j)是因变量小于等于第 j类的累积概率。
αj是第 j个类别的阈值(截距),满足 α1<α2<...<αJ−1。
β是自变量的系数,表示自变量每单位变化对对数优势比(log-odds) 的影响。
关键假设:模型需满足平行性假设(proportional odds assumption),即所有自变量的系数 β在不同类别间相同,仅阈值 αj不同。这确保自变量对累积概率的影响一致。
与二分类逻辑回归的区别:有序模型同时拟合 J−1个二分类模型(如 Y≤1vs Y>1, Y≤2vs Y>2),但系数共享,提高统计效能。
二、适用场景
有序逻辑回归适用于因变量有自然顺序,但类别间距离未知的场景:
医学研究:疾病严重程度(如癌症分期Ⅰ、Ⅱ、Ⅲ、Ⅳ)与年龄、治疗方式的关系。
社会科学:满意度调查(如员工满意度:低、中、高)受收入、教育水平的影响。
市场研究:产品评级(如差、中、优)与价格、品牌的关系。
教育研究:学生成绩等级(如及格、良、优)与学习时间、教学方法的关系。
注意:若因变量无顺序(如颜色偏好)或顺序不明确,应使用多元无序逻辑回归;若平行性假设不成立,也需改用无序模型。
三、数据要求
使用有序逻辑回归前,需验证数据满足以下条件:
因变量:唯一且为有序分类变量(如赋值1,2,3表示低、中、高)。类别数通常≥3,且频数不宜严重不平衡(如某一类别样本过少)。
自变量:可为连续变量(如年龄、收入)或分类变量(如性别、种族)。分类变量需设为哑变量(如性别男=0、女=1)。
独立性:观测值相互独立(如重复测量数据需用混合模型)。
无多重共线性:自变量间相关性不宜过高(可通过方差膨胀因子VIF检验)。
平行性假设:需通过统计检验(如Stata的
oparallel命令),若P值>0.05则假设成立。
常见问题处理:
样本量:每个自变量至少需10-20个事件(小样本可能导致估计偏差)。
类别赋值:整数赋值(1,2,3)最常用,但若类别间距不等(如年龄分段),可考虑中点赋值或正态得分转换。
四、Stata操作命令及注意事项
1. 基本命令
模型拟合:使用
ologit命令,语法为:ologit 因变量 自变量1 自变量2 ..., 选项常用选项:
or:输出优势比(Odds Ratio, OR) 而非系数。vce(robust):稳健标准误,处理异方差。
平行性检验:需安装
oparallel命令(首次使用:ssc install oparallel),在ologit后运行:oparallel, logit若检验P值>0.05,满足平行性假设;否则需改用无序模型(如
mlogit)。分类自变量处理:使用
i.前缀设哑变量(如i.种族),Stata自动以第一类为参照。
2. 操作步骤
数据准备:导入数据(
use "data.dta"),检查变量类型(codebook)。平行性检验:运行
ologit后立即执行oparallel。拟合模型:添加选项如
or输出OR值。模型诊断:检查残差、预测准确率(
estat classification)。
3. 注意事项
平行性假设是核心:若不满足,模型解释力下降。解决方法:
使用部分比例优势模型(如Stata的
gologit2命令)。改用无序逻辑回归(
mlogit)。
哑变量设置:分类变量(如职业)需完整设哑变量,避免共线性。
样本量不足:小样本可能导致OR值置信区间过宽,需谨慎解释。
五、Stata ologit回归结果解读
以健康状况研究为例(因变量health:1=差, 2=一般, 3=良好, 4=好, 5=优秀;自变量:性别、年龄、体重):
ologit health female age weight, or输出结果包括三部分:
模型整体拟合信息:
Number of obs:样本量。LR chi2(3):似然比卡方,检验模型是否显著(P值<0.05说明模型有效)。Log likelihood:对数似然值,用于计算AIC/BIC(值越小模型越好)。Pseudo R2:伪R²(0.01~0.2常见,值越大拟合越好)。示例:
Prob > chi2 = 0.0000表明模型整体显著。
系数估计结果:
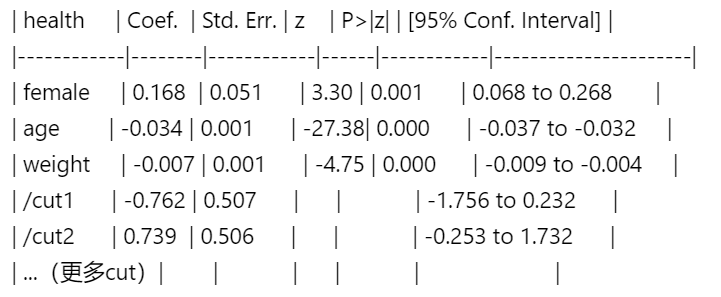
自变量系数:
系数正负:正系数表示自变量增加时,因变量更可能落入更高类别(如
female=0.168表示女性健康状况更可能更好)。OR值(若添加
or选项):如age的OR=0.967(即e−0.034),解释为年龄每增加1岁,健康状况提升一个等级的优势降低3.3%((0.967-1)×100%)。
阈值(cut points):有J−1个阈值(此例J=5,输出4个cut)。它们定义类别分界:
当潜在变量值 ≤
cut1,Y=1(差)。cut1< 值 ≤cut2,Y=2(一般)。...依次类推。
显著性判断:
P值<0.05表示自变量显著(如
age的P=0.000显著,说明年龄对健康状况有影响)。置信区间不包含0(或OR值不包含1)时显著。
六、Stata详细示例
案例背景:研究锻炼情况(PA:1=不运动, 2=不规律运动, 3=规律运动)和性别(gender:0=女, 1=男)对老年衰弱(frailty:1=稳健期, 2=衰弱前期, 3=衰弱期)的影响。
步骤1:平行性检验
ologit frailty gender i.PA // 先拟合模型
oparallel, logit // 平行性检验输出:
Likelihood ratio test for parallel lines: chi2(3)=1.407, p=0.495P=0.495>0.05,满足平行性假设,可继续使用有序模型。
步骤2:拟合模型(输出OR值)
ologit frailty gender i.PA, or // i.PA将PA设为哑变量输出摘要:
Ordered logistic regression
Log likelihood = -120.5
Number of obs = 400
LR chi2(3) = 25.36
Prob > chi2 = 0.0000
Pseudo R2 = 0.045------------------------------------------------------------------------------frailty | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]
------------+----------------------------------------------------------------gender | 1.12 0.310 0.42 0.675 0.647 1.941PA |不规律运动 | 0.45 0.201 -1.81 0.071 0.190 1.065规律运动 | 0.01 0.005 -3.12 0.002 0.000 0.413
------------+----------------------------------------------------------------/cut1 | -1.50 0.512 -2.505 -0.495/cut2 | 0.80 0.503 -0.186 1.786
------------------------------------------------------------------------------步骤3:结果解读
模型整体:
Prob > chi2=0.0000,模型显著;伪R²=0.045,拟合度一般但可接受。自变量影响:
gender:OR=1.12, P=0.675>0.05,不显著,说明性别对衰弱无显著影响。PA(以"不运动"为参照):规律运动:OR=0.01, P=0.002<0.05,显著。解释:规律运动群体衰弱等级提升的优势仅为不运动群体的1%(即降低99%)。不规律运动:OR=0.45, P=0.071>0.05,边缘不显著。
阈值:
cut1和cut2定义类别分界(如潜在变量≤-1.50时,衰弱=1)。
注意事项:若P值不显著(如性别),可考虑剔除变量;OR值解释需结合背景(如OR=0.01表示影响极大)。
总结
有序逻辑回归是处理有序因变量的核心方法。关键步骤包括:验证平行性假设、正确设哑变量、基于OR值解释影响。Stata中通过ologit和oparallel实现,结果需综合模型拟合、系数显著性和阈值进行解读。若假设不成立,可换用无序逻辑回归或部分比例优势模型。实际应用中,建议结合领域知识判断变量合理性。
七、Stata零基础学习推荐
(1)《Stata 统计分析从入门到精通》杨维忠 张甜编著 清华大学出版社 2022 年
适用于 Stata 计量经济学、统计分析教学。国内计量大牛、山东大学陈强教授作序推荐,长期占据当当、京东、淘宝同类图书畅销榜前列。国内众多高校作为核心专业课程教材。本书专为计量经济学基础薄弱或学不进去,但又有写论文、做研究需要的读者设计,达到“弯道超车”的效果。大家可以学不会复杂的计量经济学,尤其是那些枯燥的数学推导,但一定要会用 Stata,Stata 的作用相当于把那些计量经济学公式嵌入到了软件中,会操作命令就能完成实证研究。换言之,您可以不懂汽车发动机、传动等原理,只要会开车就可以了。

(2)《Stata 统计学与案例应用精解》张甜 杨维忠 清华大学出版社 2025 年。
这本书很有特色,毫不夸张的说,是超过市面上所有类似图书的全面经典之作。
一是框架涵盖统计学、计量经济学双教学体系,既可以当做 Stata 计量经济学的教材,也可以作为 Stata 统计学的教材,涵盖经济学、管理学、社会学、医学等多专业,书刚一上市,就被很多高校选择作为教材,首印几千本很快就售空了,网上各大平台的传播度也很高,很多同学对于自己学校订购的教材学不会,但是对于学这本书,很快就入门了,也兴起了彼此推荐的热潮。
二是书中有实证论文写作指导,以及当前流行的稳健性检验、异质性分析、政策效应检验等,达到学会用 Stata 写论文的效果。这一下子省了多少课程代做和论文代写费用!可以说,一本书相当于一个完整的私教培训班了,真的有种饭都喂到嘴边的感觉,满足了零基础、尤其是跨专业学生学习 Stata 用于写论文的所有需求,解决了所有痛点。
三是数据质量和案例构思、覆盖面优势显著,基于 44 份真实权威经济社会统计数据和 14 份调查研究数据,精心设计 58 个统计分析应用案例和 10 个数据加工处理案例,广泛涵盖经济金融、医学药学、企业管理、日常生活等领域。随便举几个书中例子,大家自己判断够不够硬:8.1.2 案例应用——分析山西、四川、辽宁常住人口自然增长率差异;8.2.2 案例应用——分析德国、法国、西班牙、意大利四个国家的住房拥挤率;8.3.2 案例应用——分析我国部分省份地方政府债券收益率影响因素;9.1.2 案例应用——分析国际原油价格和黄金价格的相关性;10.1.2 案例应用——分析欧元区 20 国经济景气指数的影响因素;11.1.2 案例应用——分析中等收入国家航空运输客运量的影响因素……
四是配套资源太丰富了!每章都有知识回顾和课后习题(选择、判断、操作),与书配套的还赠送教学 PPT、全书数据文件、全书 Stata 代码和作者最新讲解的全套视频资料,同时设置专门章节讲解 AI 工具应用(这绝对是迄今为止业内首创了)。

(3)《Stata 统计分析商用建模与综合案例精解》杨维忠 张甜编著 清华大学出版社 2021 年
适用于 Stata 计量经济学、统计分析教学。国内众多高校作为核心专业课程教材。在 51CTO 举办的“2021 年度最受读者喜爱的 IT 图书作者评选”中,《Stata 统计分析商用建模与综合案例精解》荣获“数据科学领域最受读者喜爱的图书 TOP5”。


各大平台搜索书名即可。 创作不易,恳请大家多多点赞支持!也欢迎大家关注我,让我们一起学习 Stata、SPSS、Python 知识。多谢!