爬虫+卷积神经网络项目实战解析——对图像狗的识别分类
目录
1.源代码仓库
2.项目前瞻
3.爬虫部分
4.卷积神经网络
4.1模型选择
4.2超参数选择
5.终
1.源代码仓库
programs: 年少曾学登山法 - Gitee.com![]() https://gitee.com/zirui-shu/programs/tree/master/%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB%E2%80%94%E2%80%94%E7%8B%97
https://gitee.com/zirui-shu/programs/tree/master/%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB%E2%80%94%E2%80%94%E7%8B%97
2.项目前瞻
本项目分别利用爬虫和卷积神经网络,分别实现对狗的图像采集和分类操作。
爬虫,通过输入搜索的词提取相关图像资料: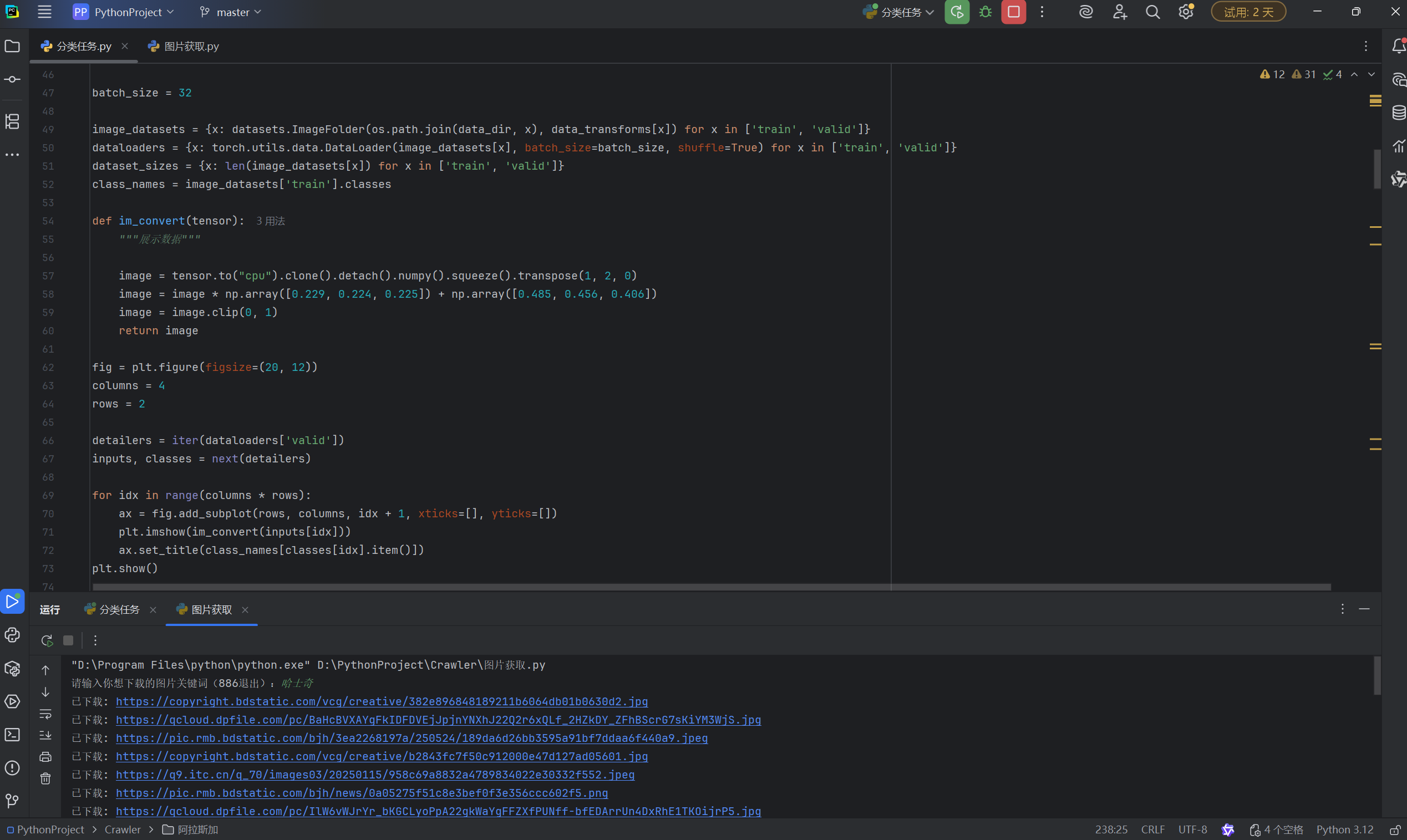
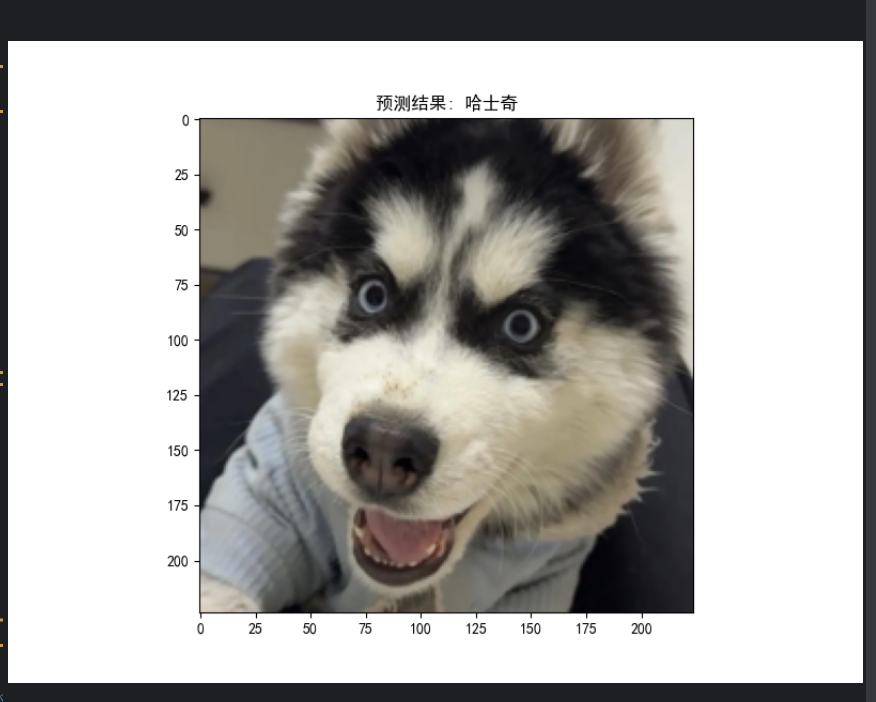
卷积神经网络,微调模型对输入图像进行分类:
3.爬虫部分
对于图像识别整个项目而言,基本采用神经网络进行分类,那么数据集的来源就成了很大的问题。既然使用了python,不妨考虑使用爬虫获取数据集。
本文利用的是百度的图片搜索网站。首先对于整个url进行一个分析:
https://image.baidu.com/search/index
tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1
&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=
&ic=0&nc=1&z=&se=&showtab=0&fb=0&width=&height=
&face=0&istype=2&ie=utf-8&word=阿拉斯加虽然看不懂前面的一系列参数的作用,但是我们能找到与我们搜索相关的信息,也就是最后word参数所对应的【阿拉斯加】。那么,由此我们可以对请求的url做一个改造:
url = f"https://image.baidu.com/search/index
tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1
&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0
&nc=1&z=&se=&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word={keyword}"通过输入keyword,也就是我们想要搜索的内容,将其重构进我们的url之中,实现基本请求地址的建立。然而,在构建之后的请求所得数据之中,并没有出现我们想要的结果:
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="utf-8"><title>百度安全验证</title><meta http-equiv="Content-Type" content="text/html; charset=utf-8"><meta name="apple-mobile-web-app-capable" content="yes"><meta name="apple-mobile-web-app-status-bar-style" content="black"><meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0"><meta name="format-detection" content="telephone=no, email=no"><link rel="shortcut icon" href="https://www.baidu.com/favicon.ico" type="image/x-icon"><link rel="icon" sizes="any" mask href="https://www.baidu.com/img/baidu.svg"><meta http-equiv="X-UA-Compatible" content="IE=Edge"><meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests"><link rel="stylesheet" href="https://ppui-static-wap.cdn.bcebos.com/static/touch/css/api/mkdjump_aac6df1.css" />
</head>
<body><div class="timeout hide-callback"><div class="timeout-img"></div><div class="timeout-title">网络不给力,请稍后重试</div><button type="button" class="timeout-button">返回首页</button></div><div class="timeout-feedback hide-callback"><div class="timeout-feedback-icon"></div><p class="timeout-feedback-title">问题反馈</p></div><script src="https://ppui-static-wap.cdn.bcebos.com/static/touch/js/mkdjump_v2_21d1ae1.js"></script>
</body>
</html>这样看起来,似乎百度对我们的爬虫做了一些【反爬手段】。通过在原页面的检查得知,百度加上了防盗链与Cookie验证:(后来看的时候防盗链好像没了?)
那么在【请求头】之中,我们就需要加上这两个参数:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E9%98%BF%E6%8B%89%E6%96%AF%E5%8A%A0',"Cookie": "BAIDUID=6B3C890885DAA086DB4B8F1D1886B10B:FG=1; BAIDUID_BFESS=6B3C890885DAA086DB4B8F1D1886B10B:FG=1; newlogin=1; BDUSS=lNKV3NnaVlRUk5lcDE1OUJIcHUwUTROV1Jla09-NkpIZi1hd281OWJQU0xKTzlvSVFBQUFBJCQAAAAAAQAAAAEAAABjteUQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIuXx2iLl8doW; BDUSS_BFESS=lNKV3NnaVlRUk5lcDE1OUJIcHUwUTROV1Jla09-NkpIZi1hd281OWJQU0xKTzlvSVFBQUFBJCQAAAAAAQAAAAEAAABjteUQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIuXx2iLl8doW; BIDUPSID=6B3C890885DAA086DB4B8F1D1886B10B; PSTM=1759137151; H_PS_PSSID=63145_63325_64313_64838_64912_64969_64982_65117_65139_65188_65216_65249_65257_65270_65313_65328_65380_65367_65414_65400_65452_65499_65479_65537; ZFY=esn895iY0L9ylf5adMMLLFOreqqzBz3hz517UwevlMw:C; H_WISE_SIDS=64982_65117_65188_65216_65249_65270_65313_65414_65400_65452_65537_65569_65606_65600_65635_65660; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; arialoadData=false; userFrom=null; ab_sr=1.0.1_MTZiM2Y3NjU5ZGNjZTUyYzk5NTNiOGJkMjI3MDcyODc3NmU2MTViYTg5MWM4YTMzYzliNDQ2OWVmNjQ4NThmZjY5ODNjNDQzN2QzZjBjZTE1ODAwYTVhMjVjYmVlNjgyOWExYzNmNDUxNzIwNmZjODViNzI2MmQ4NjQyNGRiZTgxYjY3ZmJmNGY5NWRmMjY5NDFmZGE4NmU3ZDQ5NDE2Ng=="}接下来就得到真实的数据了。对数据进行输出并解析后,锁定图片对应的地址:
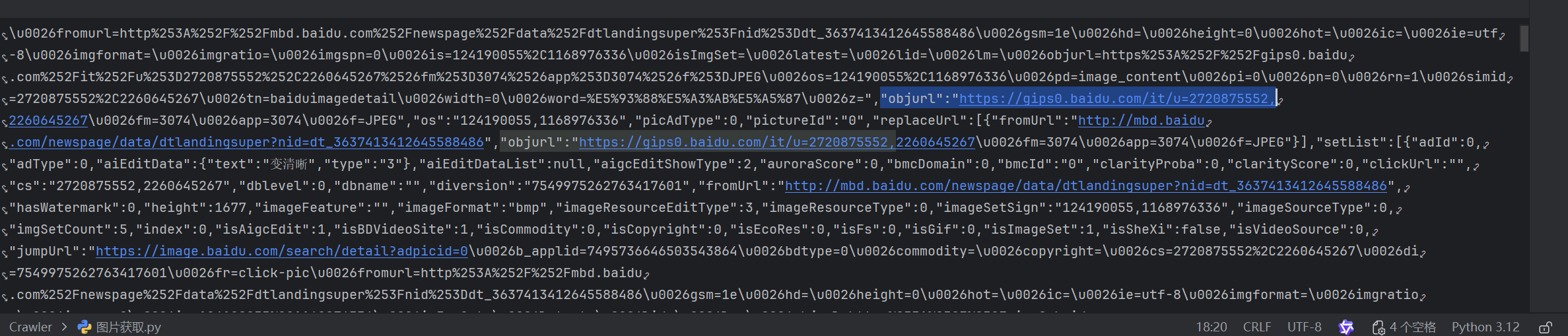
那么,在数据提取时锁定objurl这个参数就可以了:
img_urls = re.findall(r'"objurl":"(.*?)"', html)
不过,在最终下载之时发现,似乎还有一些网址是【漏网之鱼】。我总结了一下,归结为两个类别:
1.重复url地址,使用集合筛选:
img_urls = list(set(img_urls))2.链接格式不对,对后缀筛选:
if not img_url.lower().endswith(('.jpg', '.jpeg', '.png')):continue最终,就得到了最终的下载文件,用来作为【训练集】与【验证集】。不过,由于百度图片是【懒加载】,一次提取出来的图片集有限,需要【滑动】才能收集更多的数据集。但是我们爬虫尽管可以模拟滑动功能,但是没有必要(我也不会),收集一二十张图片在【预训练】的基础上也能有效果。那么,数据采集这一部分就告一段落。
4.卷积神经网络
卷积神经网络的原理我就不过多赘述了。因为代码也基本类似,我就提几个关键的点。
4.1模型选择
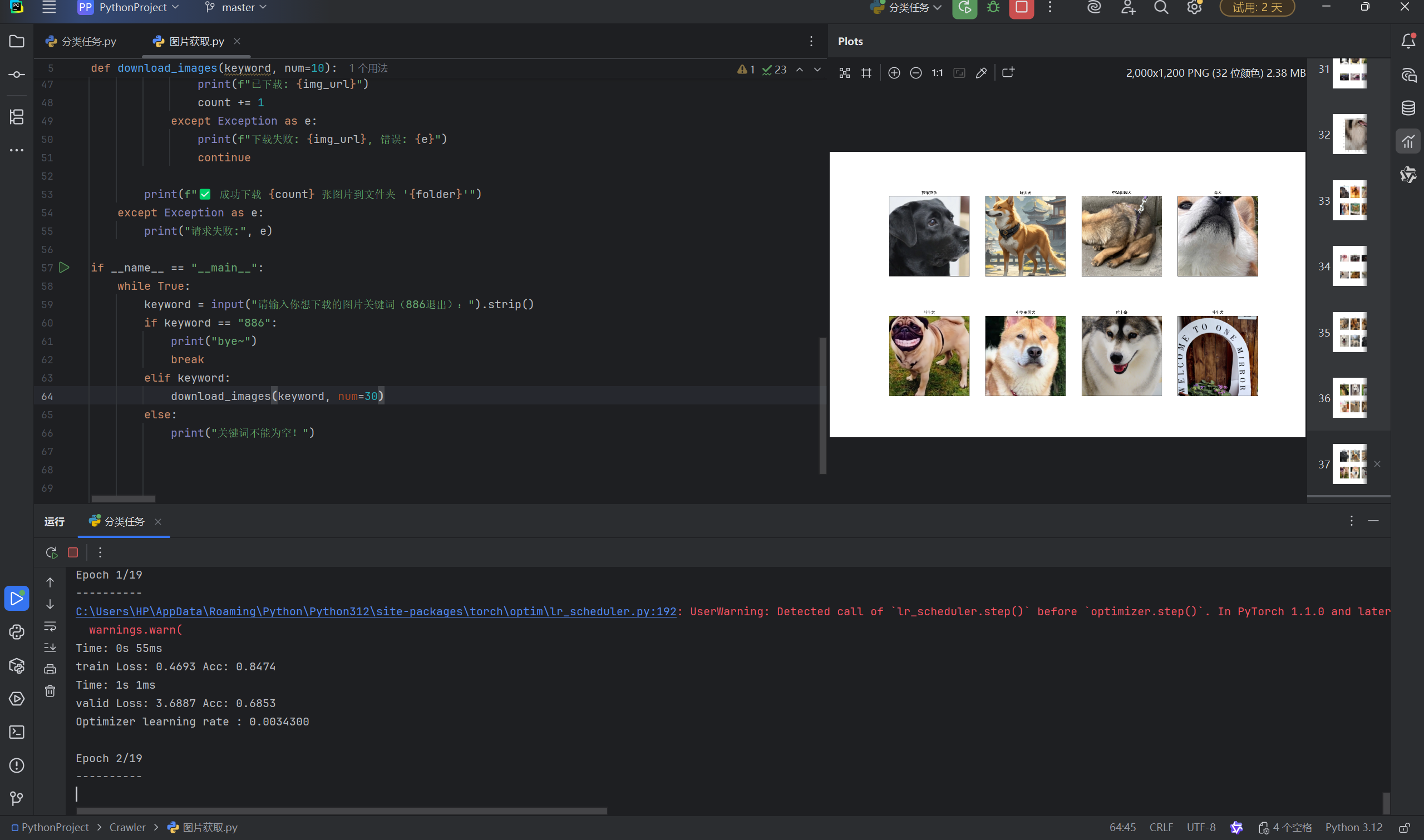
本文在此选择的是经典残差网络模型ResNet,152层的网络架构,下载网络模型后使用【迁移学习】初始化模型,使用【冻结】改造全连接层,再【解冻】微调卷积层,得到最终的模型。
4.2超参数选择
对于卷积神经网络,或者说本文所构建的卷积神经网络而言,有这么几个超参数:
batch_size, lr, step_size, gamma
batch_size,也就是【批量】,决定了一次取多少个图像数据进行训练。一般而言,尽量往上调,不过也很吃配置。我的八核显存跑32就比较慢了,可以设当设置。
lr,即learning_rate,【学习率】,决定模型调整的幅度大小,在我的基础上可以调小或不调。后面两个参数也与之有关,总的来说就是{step_size}个训练周期对学习率乘上{gamma},一般都是对学习率进行下调操作,毕竟登上山顶的路很陡,不能大步流星。同样二者可以适当下调。
5.终
总结一下,通过本次项目巩固了【爬虫】与【卷积神经网络】的用法,解决了对狗分类的实际问题。那么各位,就让我们以检测结果为尾声吧...