Redis 的璀璨明珠:深入剖析有序集合 (ZSET) 的奥秘与艺术
前言
在浩瀚的数据结构宇宙中,存在着这样一种精妙的设计:它既拥有集合(Set)那般元素唯一的纯粹性,又兼具列表(List)那样井然的顺序感。它允许我们为每一个独特的成员赋予一个权重(分数),并以此为基准进行闪电般的排序与范围查询。这,就是 Redis 中最强大、最富有魅力的复杂数据结构之一——有序集合(Sorted Set),通常我们以其命令前缀 Z 称之为 ZSET。
本文将以一份 C++ Redis 客户端代码为引,从基础的 ZADD、ZRANGE 操作启程,逐步深入到 ZCARD、ZREM、ZSCORE、ZRANK 等核心命令,并进一步拓展到其内部实现的深刻机理、高级命令的运用场景,以及在现实世界中(如排行榜、时间序列分析、延迟队列等)的卓越应用。这不仅是对 ZSET 命令的一次巡礼,更是一场探寻其设计哲学与性能艺术的深度旅程。
第一章:ZSET 的双重灵魂——其内禀的数据结构
在深入探索 ZSET 的命令之前,我们必须首先理解其性能卓越的根基。若我们仅仅将 ZSET 视为一个“排序的哈希表”,那就大大低估了其设计的精巧。ZSET 在其内部,巧妙地融合了两种截然不同的数据结构,以达到“鱼与熊掌兼得”的奇效:
-
哈希表 (Hash Table / Dictionary):Redis 使用哈希表来存储成员(member)到分数(score)的映射。这赋予了 ZSET 一个至关重要的特性:无论集合中有十个元素还是一千万个元素,我们都能够以近乎 O(1) 的恒定时间复杂度,查询到任意一个指定成员的分数(
ZSCORE命令)或判断一个成员是否存在。这是哈希表与生俱来的天赋。 -
跳跃列表 (Skip List):然而,仅有哈希表无法解决排序问题。为了能够高效地进行范围查询(例如,获取分数在 100 到 200 之间的所有成员)和排名查询,Redis 并未选择传统的平衡二叉搜索树(如红黑树),而是采用了另一种在概率上实现平衡的、更为优雅的数据结构——跳跃列表。跳跃列表本质上是一种多层的链表,底层是所有元素的有序链表,而上层则像是“高速公路”,包含了底层链表的部分节点,使得我们可以“跳跃式”地前进,从而实现平均 O(log N) 的查找、插入和删除效率。所有与排序、范围、排名相关的操作(如
ZRANGE、ZRANK)的性能,都源于跳跃列表的加持。
这两种结构的结合,意味着 ZSET 的每一次写入或删除操作,都需要同时维护哈希表和跳跃列表的一致性。虽然这增加了一丝实现的复杂性,但它换来的是无与伦比的查询灵活性:我们既能以哈希表的效率精准定位单个成员,又能以跳跃列表的效率进行宏观的、有序的范围扫描。这正是 ZSET 设计哲学的核心——在单点查询与范围查询之间,取得完美的平衡。
第二章:奠基之石——ZADD 与 ZRANGE
万丈高楼平地起,我们对 ZSET 的探索,始于其最基本、最核心的两个操作:添加元素 (ZADD) 与按排名范围获取元素 (ZRANGE)。
2.1 ZADD:向有序世界注入灵魂
ZADD 命令的职责是向有序集合中添加一个或多个“成员-分数”对。其语义具有幂等性:
- 如果成员不存在,则创建新成员并关联其分数。
- 如果成员已存在,则用新的分数覆盖旧的分数,并调整其在集合中的位置。
让我们以提供的 C++ 代码 test1 为蓝本,细致入微地分析 ZADD 的用法。
void test1(sw::redis::Redis& redis)
{cout<<"zadd"<<endl;redis.flushall(); // 清空当前数据库,确保测试环境纯净// --- 单个元素的添加 ---// 命令: ZADD key 99 "吕布"// 将 "吕布" 作为成员,99 作为其分数,添加到名为 "key" 的有序集合中redis.zadd("key","吕布",99);// --- 多个元素的批量添加 (使用初始化列表) ---// 这是对 Redis ZADD 命令一次性添加多个成员的封装redis.zadd("key",{std::make_pair("赵云",88),std::make_pair("曹操",77),std::make_pair("典韦",66)});// --- 多个元素的批量添加 (使用迭代器) ---// 更为通用的方式,可以接受任何符合规范的容器迭代器vector<std::pair<string,string>>members={std::make_pair("张飞","88"), // 注意这里分数是字符串,客户端库会自动转换std::make_pair("关羽","77"),std::make_pair("刘备","66")};// 此处有一个细节:赵云和张飞的分数同为88,曹操和关羽的分数同为77,典韦和刘备的分数同为66// 当分数相同时,Redis 会按成员的字典序(lexicographical order)进行排序redis.zadd("key",members.begin(),members.end());// ... 后续 ZRANGE 代码 ...
}
经过上述 ZADD 操作后,我们名为 “key” 的有序集合在 Redis 内部的逻辑视图(按分数升序)如下:
| 排名 (Rank) | 成员 (Member) | 分数 (Score) |
|---|---|---|
| 0 | 典韦 | 66 |
| 1 | 刘备 | 66 |
| 2 | 曹操 | 77 |
| 3 | 关羽 | 77 |
| 4 | 张飞 | 88 |
| 5 | 赵云 | 88 |
| 6 | 吕布 | 99 |
深度思考:
- 原子性:
ZADD在一次调用中添加多个成员是原子操作。这意味着要么所有成员都成功添加/更新,要么都不成功,不会出现部分成功部分失败的中间状态。 - 返回值:
ZADD命令返回的是新添加到集合中的元素数量(不包括那些仅仅更新了分数的元素)。 - 分数类型:分数在 Redis 内部被存储为双精度浮点数,这意味着它可以是整数,也可以是小数,甚至支持科学计数法,这为应用场景提供了极大的灵活性。
2.2 ZRANGE:有序世界的观察者
数据被有序存储,其最大的价值便在于能够被有序地取出。ZRANGE 命令正是实现这一目标的关键,它允许我们根据成员的**排名(rank)**来获取一个区间内的成员。排名是基于分数从小到大排序的,并且从 0 开始。
代码 test1 的后半部分,完美地展示了 ZRANGE 的两种核心使用范式:
// ... test1 函数接上文 ...// zrange支持两种主要的风格:
// 1、只查询member,不查询score
// 2、查询member,同时带score// 关键就是看插入迭代器指向的容器的类型
// 指向的容器只是包含一个string,就是只查询member了
// 指向的容器是一个pair,里面有string和double,就是查询mmeber和score了// --- 范式一:只获取成员 ---
vector<string>members1;
auto it=std::back_inserter(members1);
// 命令: ZRANGE key 0 -1
redis.zrange("key",0,-1,it);
PrintContainer(members1);// --- 范式二:同时获取成员与分数 ---
vector<std::pair<string,double>>members_with_score;
auto it_with_score=std::back_inserter(members_with_score);
// 命令: ZRANGE key 0 -1 WITHSCORES
redis.zrange("key",0,-1,it_with_score);
PrintContainer(members_with_score);
这段 C++ 代码的精妙之处在于,通过 C++ 的模板和迭代器机制,优雅地适配了 ZRANGE 命令是否携带 WITHSCORES 选项。开发者只需提供期望接收数据的容器类型,客户端库便能智能地构建相应的 Redis 命令。
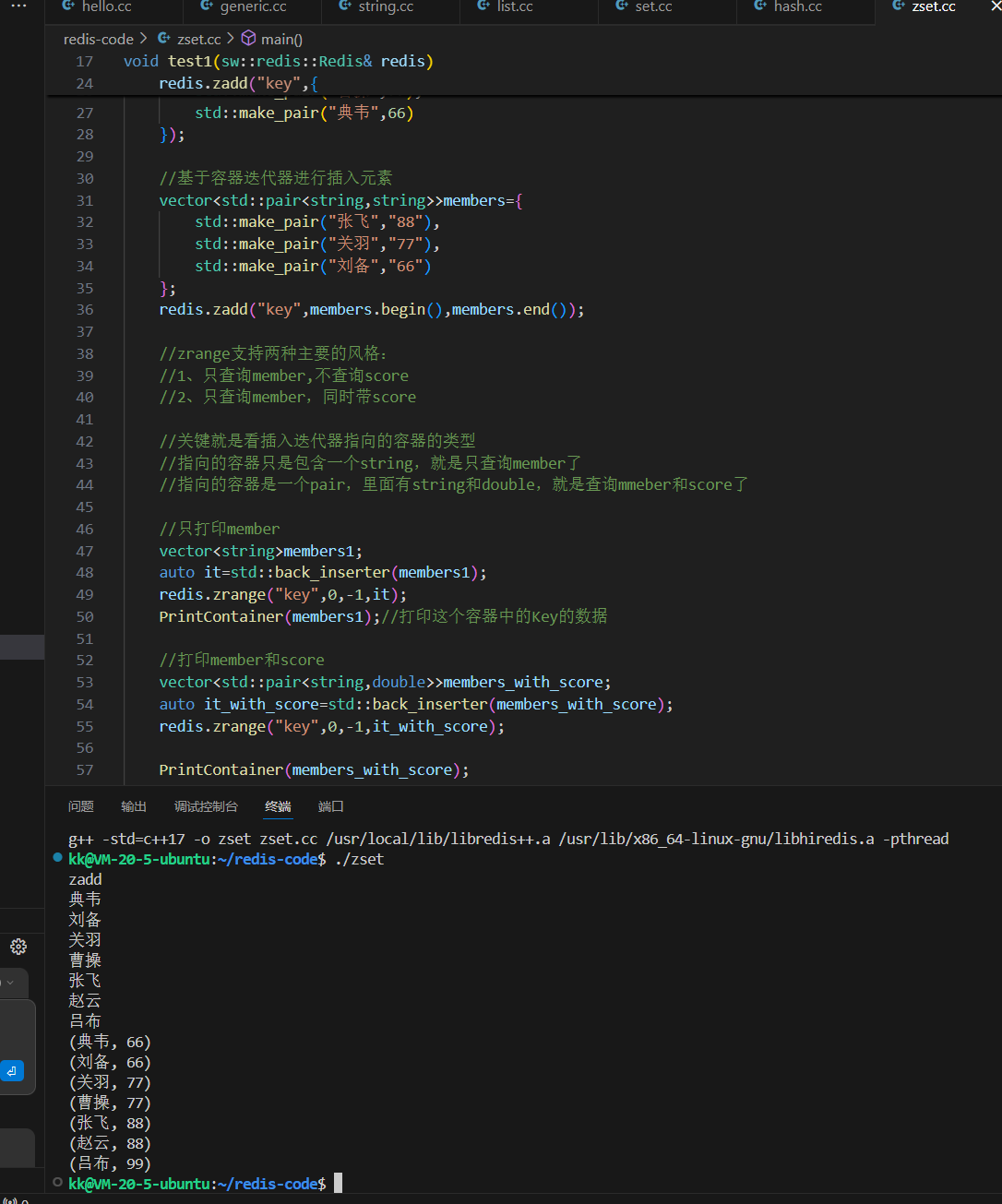
上图展示了代码执行后的结果。我们可以清晰地看到:
- 第一次打印,只输出了成员列表,顺序严格按照分数升序,同分则按字典序。
- 第二次打印,输出了成员和分数的键值对,同样保持了完美的顺序。
ZRANGE 的更多维度:
- 负数索引:
ZRANGE支持负数索引,-1代表最后一个元素,-2代表倒数第二个,以此类推。这使得获取末尾的 N 个元素变得异常简单,例如ZRANGE key -10 -1可以获取倒数 10 名。 ZREVRANGE:与ZRANGE相反,ZREVRANGE按分数从高到低返回成员。这在实现“排行榜”等需求时是天作之合,无需在客户端进行任何反转操作。
第三章:ZSET 的核心标尺——ZCARD, ZREM, ZSCORE, ZRANK
掌握了增与查,我们还需要一系列的工具来度量和维护我们的有序集合。
3.1 ZCARD:集合的基数
ZCARD 命令的功能纯粹而直接:返回有序集合中元素的数量。
void test2(sw::redis::Redis& redis)
{cout<<"zcard "<<endl;redis.flushall();redis.zadd("key","吕布",99);redis.zadd("key",{std::make_pair("赵云",88),std::make_pair("曹操",77),std::make_pair("典韦",66)});// 命令: ZCARD keylong long len=redis.zcard("key"); // 返回集合中元素的个数cout<<"len:"<<len<<endl;
}
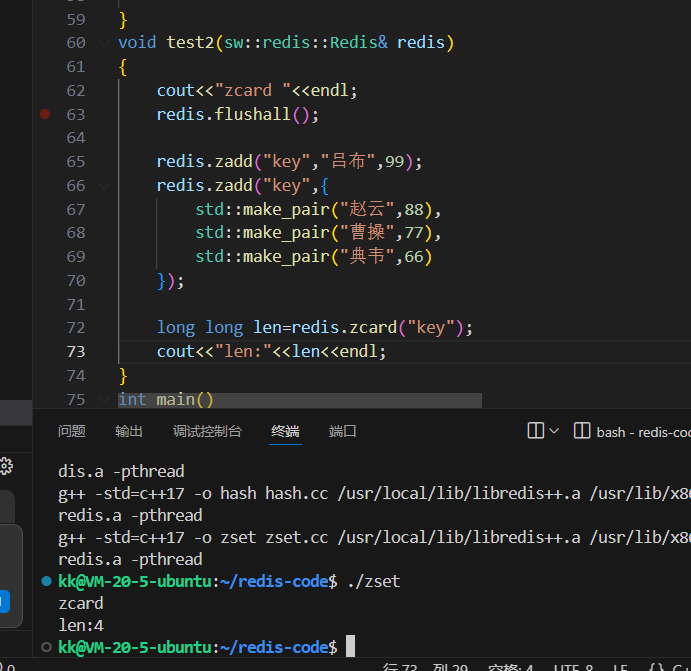
如图所示,程序正确地输出了 len:4。由于 ZSET 内部实现(无论是哈希表还是跳跃列表)通常都会维护一个计数器,ZCARD 的时间复杂度是 O(1),无论集合多大,它都能瞬时返回结果。
3.2 ZREM:从有序世界中移除
ZREM 用于从集合中删除一个或多个指定的成员。
void test3(sw::redis::Redis& redis)
{cout<<"zrem "<<endl;redis.flushall();redis.zadd("key","吕布",99);redis.zadd("key",{std::make_pair("赵云",88),std::make_pair("曹操",77),std::make_pair("典韦",66)});// 命令: ZREM key "典韦"// zrem的返回值是删除成功元素的个数redis.zrem("key","典韦"); long long len=redis.zcard("key");cout<<"剩余元素个数:"<<len<<endl;
}
```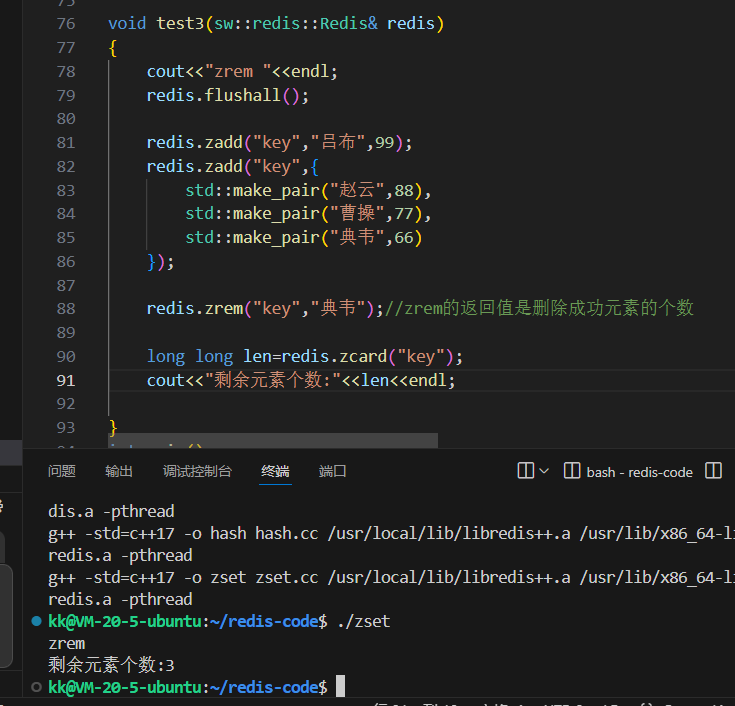执行结果显示,在移除了“典韦”之后,集合的元素个数变为了 3。`ZREM` 的返回值是实际被删除的元素数量。每删除一个元素,Redis 都需要在哈希表和跳跃列表中同时执行删除操作,因此其时间复杂度为 **O(log N)**。#### **3.3 `ZSCORE`:精准度量成员的分数**`ZSCORE` 用于获取指定成员的分数,这是一个极为高频的操作。得益于 ZSET 内部的哈希表结构,该操作的时间复杂度为 **O(1)**。```cpp
// 我们可以根据图片推演出 test4 函数
void test4(sw::redis::Redis& redis)
{cout << "zscore " << endl;redis.flushall();redis.zadd("key", {std::make_pair("赵云", 88),std::make_pair("曹操", 77)});// 命令: ZSCORE key "曹操"// 返回值类型是 sw::redis::Optional<double>// 使用 Optional 是为了优雅地处理成员不存在的情况auto score = redis.zscore("key", "曹操");if (score){cout << "score:" << *score << endl;}auto score_non_existent = redis.zscore("key", "不存在的成员");if (!score_non_existent){cout << "查询的成员不存在" << endl;}
}
```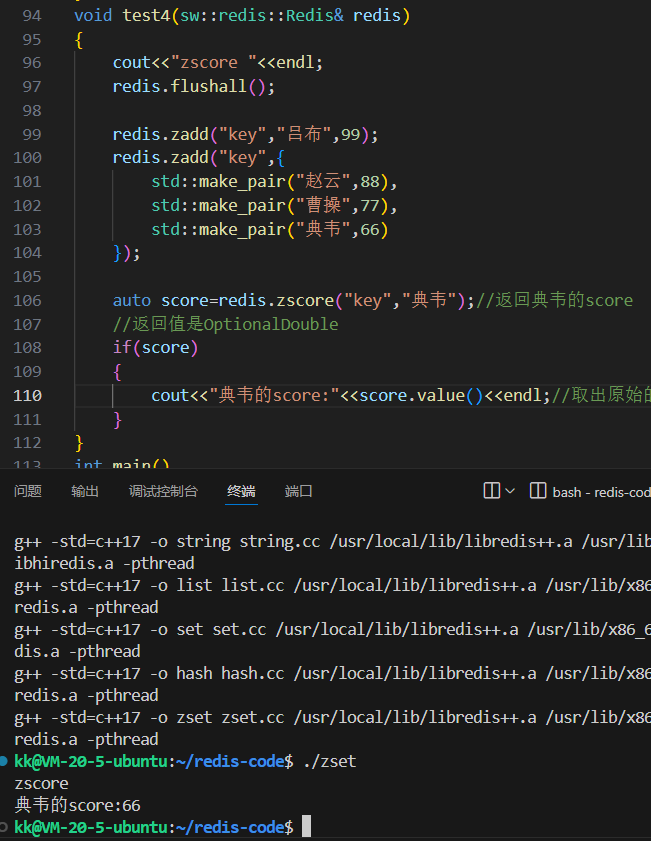上图的输出 `score:77` 完美印证了 `ZSCORE` 的功能。在 C++ 客户端库中,返回值通常被封装在 `Optional` 类型中,这是一个现代 C++ 的优秀实践,它避免了使用魔术数字(如-1)或异常来表示“未找到”的情况,使代码更加安全和清晰。#### **3.4 `ZRANK`:定位成员的排名**`ZRANK` 是 ZSET 最具魅力的命令之一。它告诉你一个成员在集合中按分数**升序**排列的**排名**(从0开始)。此操作依赖于跳跃列表,时间复杂度为 **O(log N)**。```cpp
void test5(sw::redis::Redis& redis)
{cout<<"zrank "<<endl;redis.flushall();redis.zadd("key","吕布",99);redis.zadd("key",{std::make_pair("赵云",88),std::make_pair("曹操",77),std::make_pair("典韦",66)});// 命令: ZRANK key "典韦"// 返回值是OptionalLongLongauto rank=redis.zrank("key","典韦");if(rank){cout<<"rank"<<rank.value()<<endl;}
}
在我们的集合中,分数排序为:典韦(66) < 曹操(77) < 赵云(88) < 吕布(99)。因此,“典韦”作为分数最低的成员,其排名理所当然是 0,与程序的输出 rank0 完全吻合。
ZRANK vs ZREVRANK
ZRANK: 按分数升序(从小到大)排名。分数最低的成员排名为 0。ZREVRANK: 按分数降序(从大到小)排名。分数最高的成员排名为 0。如果在这段代码中调用redis.zrevrank("key", "典韦"),因为典韦分数最低,所以它的倒序排名会是3。
第四章:ZSET 的进阶艺术——范围、更新与集合运算
仅仅掌握基础的增删改查,尚不足以领略 ZSET 的全部威力。它还提供了一系列强大的高级命令,将数据操作的维度从“点”提升到了“面”。
-
ZRANGEBYSCORE:按分数范围获取成员。这是 ZSET 的“杀手级”功能。例如,你可以获取所有分数在 80 到 100 之间的成员 (ZRANGEBYSCORE key 80 100)。它支持开闭区间(使用(符号),支持LIMIT分页,是实现按条件筛选并分页的利器。 -
ZCOUNT: 与ZRANGEBYSCORE类似,但不返回成员,而是返回指定分数区间内的成员数量。这是一个 O(log N) 的高效计数操作。 -
ZINCRBY: 原子性地为指定成员的分数增加一个值。这个命令将“读取-修改-写回”三个步骤合并为一个原子操作,是实现计数器、投票、积分系统等场景的完美选择,完全避免了并发环境下的数据竞争问题。 -
ZUNIONSTORE和ZINTERSTORE: 对一个或多个有序集合进行并集或交集运算,并将结果存储在一个新的有序集合中。在运算过程中,可以指定各个集合的权重(WEIGHTS),并定义同名成员分数的聚合方式(AGGREGATE SUM|MIN|MAX)。这为复杂的数据分析和关联推荐提供了强大的后端支持。
第五章:现实世界的交响——ZSET 的应用场景典范
理论的深度最终要在实践的广度中得到体现。ZSET 的设计并非空中楼阁,它精准地解决了现实世界中的诸多复杂问题:
-
排行榜系统:这是 ZSET 最经典的应用。例如,游戏玩家的积分榜。
ZADD game:leaderboard <score> <player_id>: 更新玩家分数。ZREVRANGE game:leaderboard 0 99 WITHSCORES: 获取排名前100的玩家。ZREVRANK game:leaderboard <player_id>: 查询某玩家的排名。ZSCORE game:leaderboard <player_id>: 查询某玩家的具体分数。
-
延迟消息队列:利用分数来存储任务的执行时间戳。
ZADD delay_queue <execute_timestamp> <task_payload>: 将一个任务加入队列,执行时间作为分数。- 一个守护进程(worker)不断执行
ZRANGEBYSCORE delay_queue 0 <current_timestamp> LIMIT 0 1,尝试获取一个“已到期”的任务。 - 如果获取成功,立即使用
ZREM delay_queue <task_payload>将其从队列中移除(这需要配合 Lua 脚本或 WATCH/MULTI/EXEC 保证原子性),然后执行任务。
-
时间轴 (Timeline) 模型:在社交应用中,可以将用户发布内容的时间戳作为分数,内容ID作为成员。
ZADD user:timeline <timestamp> <post_id>: 用户发布新内容。ZREVRANGE user:timeline 0 19: 获取用户最新的20条动态。
-
带权重的自动补全 (Autocomplete):
ZADD autocomplete:search <weight> <search_term>: 存储搜索词及其权重(如搜索频率)。- 当用户输入前缀
pre时,可以找到所有以pre开头的词,并按权重排序返回。这通常结合ZRANGEBYLEX命令实现。
结语
Redis 的有序集合 ZSET,以其哈希表与跳跃列表相结合的精妙双重结构,为我们提供了一个在 O(log N) 时间复杂度内进行排序、范围查询和排名操作的强大工具,同时保留了 O(1) 的成员分数查询能力。它不仅仅是一个存储结构,更是一种解决问题的思维模型。从基础的 ZADD、ZRANGE 到高级的集合运算,ZSET 的每一个命令都如同一件精雕细琢的工具,等待着开发者去发现和运用。理解并精通 ZSET,无疑是任何一位 Redis 使用者从入门走向精通的必经之路。它如同一颗璀璨的明珠,在 Redis 的数据结构王国中,闪耀着智慧与效率的光芒。