【力扣 SQL 50】连接
高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
| 连接类型 | 说明 |
|---|---|
INNER JOIN | 返回两表匹配的行(交集) |
LEFT JOIN | 返回左表所有行 + 右表匹配行 |
RIGHT JOIN | 返回右表所有行 + 左表匹配行 |
FULL OUTER JOIN | 返回左右表所有行(并集) |
1.使用唯一标识码替换员工ID
题目:

展示每位用户的 唯一标识码(unique ID );如果某位员工没有唯一标识码,使用 null 填充即可。
你可以以 任意 顺序返回结果表。
返回结果的格式如下例所示。

思路:
允许一个表的字段存在null,明显是返回左表所有行+右表匹配行,使用左连接
代码:
#左连接
select e2.unique_id, e1.name from Employees e1left join EmployeeUNI e2 on e1.id=e2.id2.产品销售分析 I
题目:

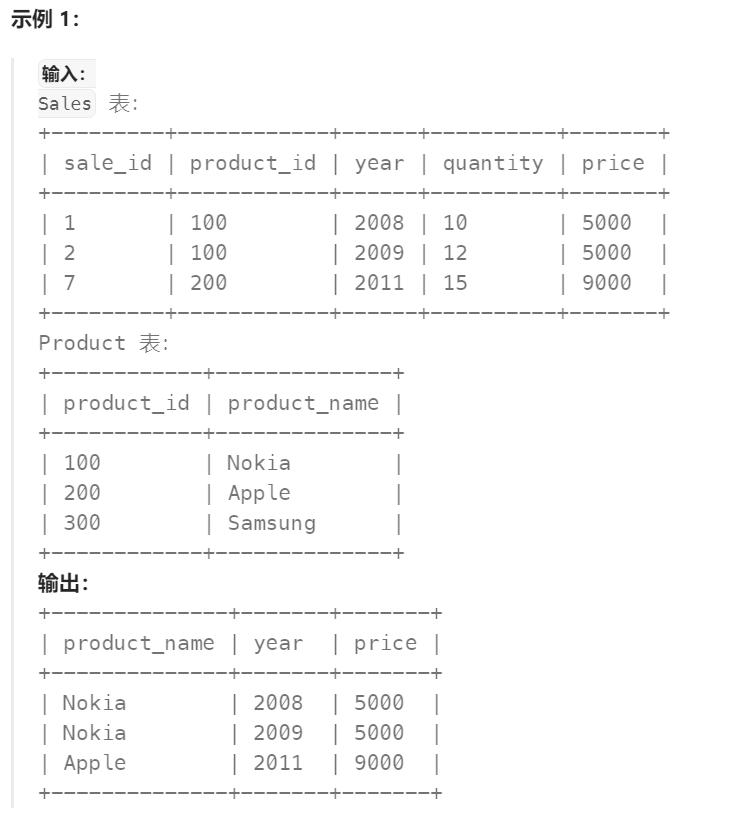
编写解决方案,以获取 Sales 表中所有 sale_id 对应的 product_name 以及该产品的所有 year 和 price 。
返回结果表 无顺序要求 。
结果格式示例如下。
思路:
每个product_id都唯一对应一条信息,因此明显使用内连接
代码:
#内连接
select p.product_name, s.year, s.pricefrom Sales sinner join Product p on s.product_id=p.product_id 3.进店却未进行交易的顾客
题目:

有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。

思路:
题目重点在于每个顾客的只光顾不交易的次数,我们先进行Visit表左连接Transactions表,得到的表的每个visit_id字段对应的transaction_id可能存在null,我们就筛选出t.transaction_id is null,这样就得到了只光顾不交易customer_id。但又因为要求出光顾不交易的次数,因此使用按customer_id分组来,然后count(v.customer_id)统计行数得出该顾客光顾不交易的次数count_on_trans
代码:
#左连接+反选+分组
select v.customer_id, count(v.customer_id) count_no_transfrom Visits vleft join Transactions t on v.visit_id=t.visit_idwhere t.transaction_id is nullgroup by customer_id4.上升的温度
题目:

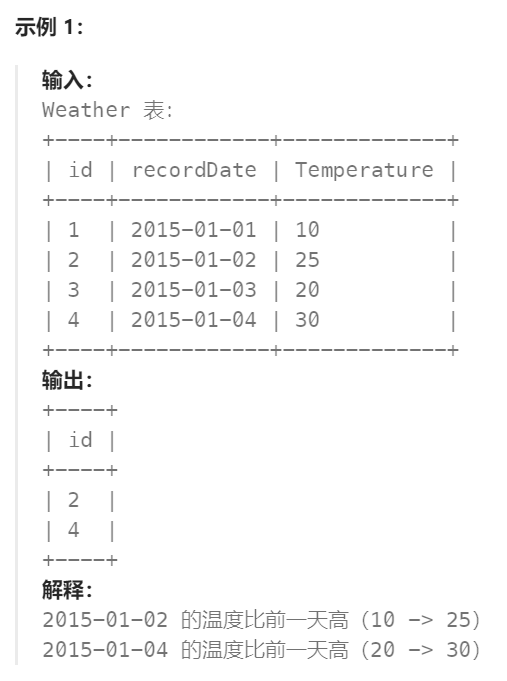
编写解决方案,找出与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 无顺序要求 。
结果格式如下例子所示。
思路:
因为要比较每行数据的前一天的数据,因此采用内连接,然后使用日期比较函数DATEDIFF(a,b)来作为连接条件,之后符合前后日期相差一天的才能连接(注意第一个参数要比第二个参数要大,反过来就是负数了),这样连接后的表就是如下图所示。
DATEDIFF(date1, date2) | 相差天数 | SELECT DATEDIFF('2023-10-10', '2023-10-05'); → 5 |
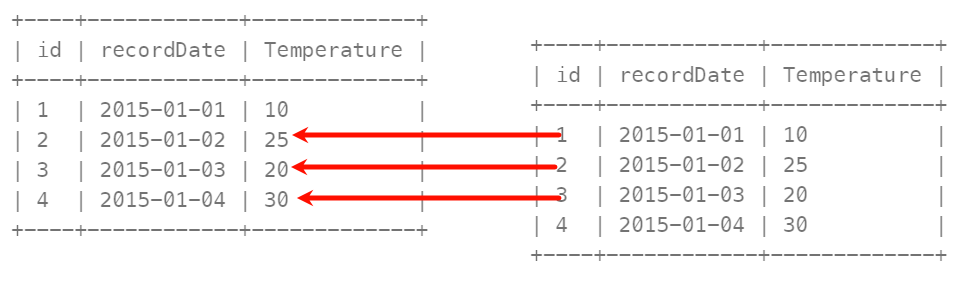
连接之后的查询条件是w1.Temperature > w2.Temperature
代码:
#内连接+日期比较DATEDIFF
select w1.idfrom Weather w1inner join Weather w2 on DATEDIFF(w1.recordDate, w2.recordDate)=1where w1.Temperature > w2.Temperature 5.每台机器的进程平均运行时间
题目:

现在有一个工厂网站由几台机器运行,每台机器上运行着 相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。

思路:
这题目虽然看着挺长,但是核心就是分组+计算平均值,这里的round有点复杂,我依次讲解
1)if(activity_type = 'start', -1, 1) * timestamp
-
如果是'start'活动:
-1 × timestamp(负的时间戳) -
如果是'end'活动:
+1 × timestamp(正的时间戳)
2)avg(...)
对timestamp列进行分组求平均值
3)为什么要2*avg(...)
因为
-
平均值计算时分母是总记录数,而不是处理周期数(比如上述例子一个machine_id包含两个周期,但是有四条数据,所以是多除了2次,要乘回来)
-
由于每2条记录对应1个处理周期,所以需要乘以2来校正
4)round(...,3)
保留三位小数
代码:
select machine_id, round(2*avg(if(activity_type = 'start',-1,1)*timestamp),3) processing_timefrom Activitygroup by machine_id6.员工奖金
题目:

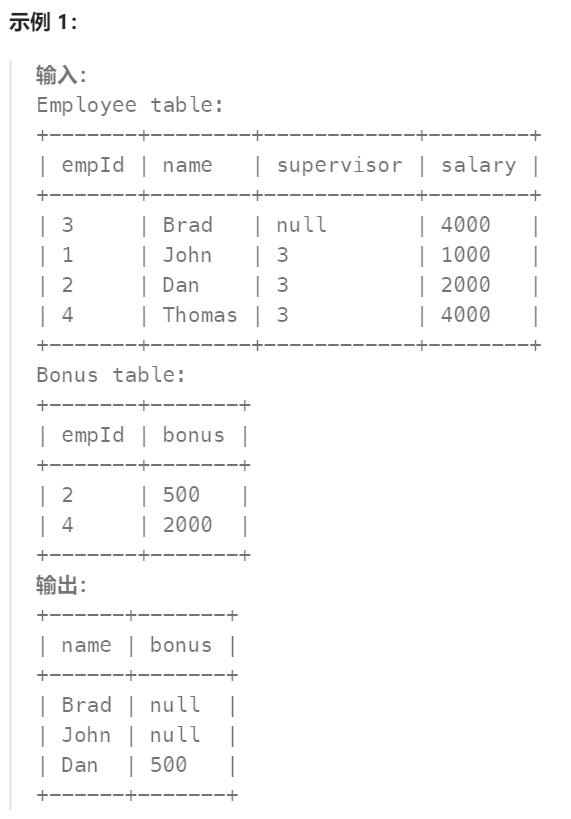
编写解决方案,报告每个奖金 少于 1000 的员工的姓名和奖金数额。
以 任意顺序 返回结果表。
结果格式如下所示。
思路:
一个表的列允许出现null值,所以使用左连接即可
代码:
select e.name, b.bonusfrom Employee eleft join Bonus b on e.empId=b.empIdwhere b.bonus<1000or b.bonus is null7.学生们参加各科测试的次数
题目:

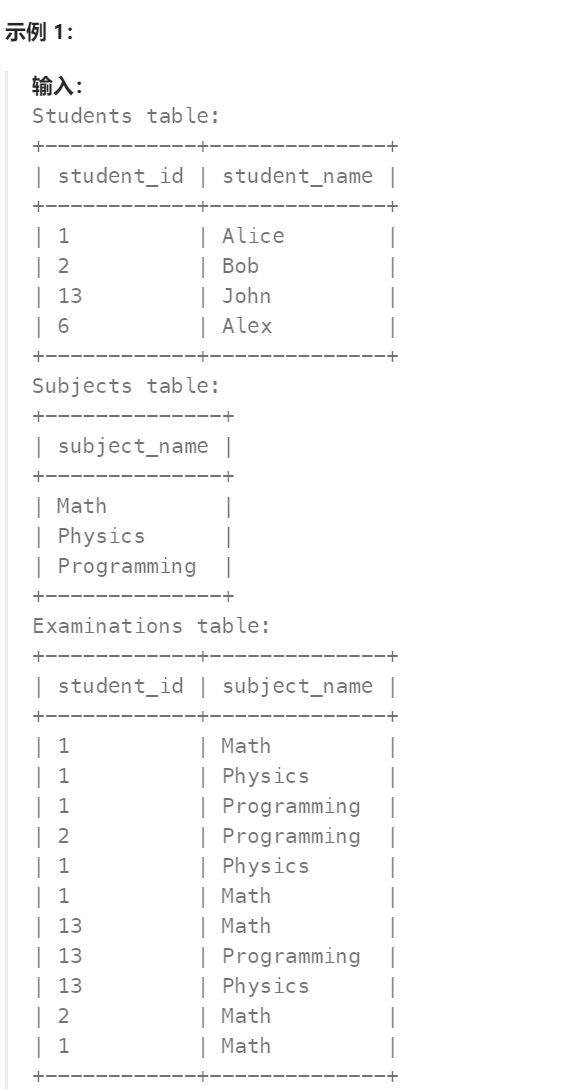
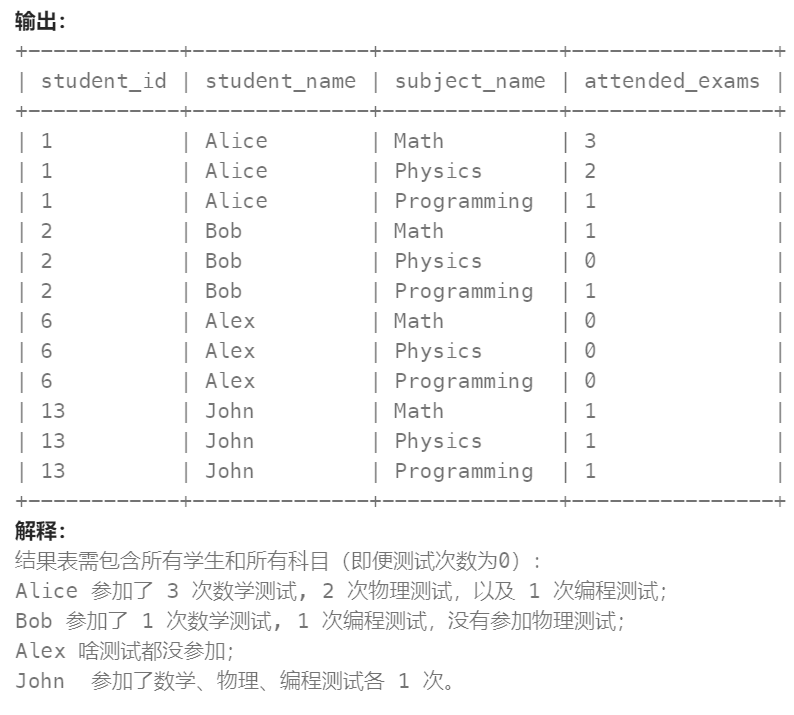
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
思路:
这题逻辑较为复杂,题目要求求出每个学生的每个科目考了多少次,注意,没考的科目算0次,这里是难点,如何找出没考的科目
我们先把Students和Subjects表进行交叉连接(笛卡尔) ,得到如下表
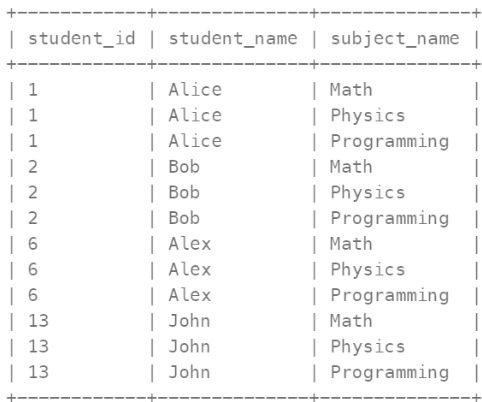
这样就得到每个学生的考试科目表了,然后使用这个表与Examinations 进行左连接,条件是
on s1.student_id=e.student_id
and s2.subject_name=e.subject_name,(必须同时满足,否则会出现重复)
这样就能找到学生考试科目的次数和没考的科目(null)了,最后进行按学生id和考试科目名称分组,统计次数count(e.subject_name),然后按学生id和考试科目名称排序即可(这里的排序可以理解为先按id排序,然后再按名称排序)
代码:
# 交叉连接+左连接+分组+排序
select s1.student_id,s1.student_name,s2.subject_name,count(e.subject_name) attended_examsfrom Students s1cross join Subjects s2left join Examinations e on s1.student_id=e.student_idand s2.subject_name=e.subject_namegroup by s1.student_id, s2.subject_nameorder by s1.student_id, s2.subject_name8.至少有5名直接下属的经理
题目:

编写一个解决方案,找出至少有五个直接下属的经理。
以 任意顺序 返回结果表。
查询结果格式如下所示。
思路:
我们一开始的思路是按照经理id进行分组,然后统计count(id)>=5,但是要求输出的是经理的name,所以要进行一次自连接,否则取不出name
这里注意要使用inner,因为managerId可能不在id列中(找不到)或者为null,如果使用left,就会出现下面这种情况
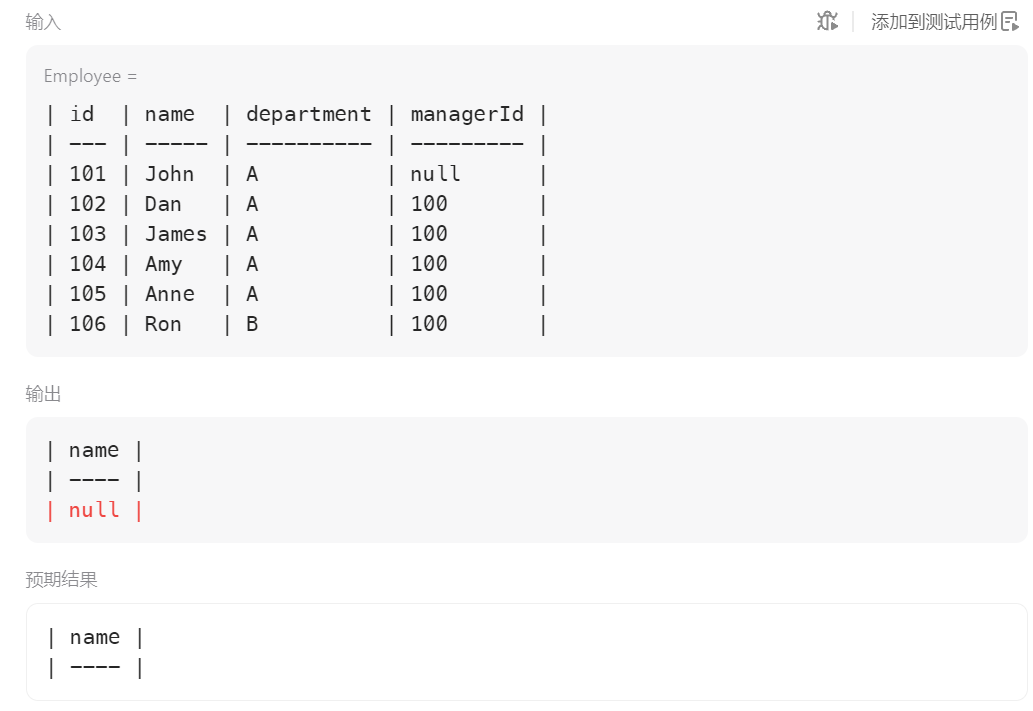
所以必须要managerId和id全匹配作为连接条件
代码:
#自连接
select e2.namefrom Employee e1inner join Employee e2 on e1.managerId=e2.idgroup by e1.managerIdhaving count(e1.id)>=5 9.确认率
题目:

用户的 确认率 是 'confirmed' 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。
编写一个SQL查询来查找每个用户的 确认率 。
以 任意顺序 返回结果表。
查询结果格式如下所示。

思路:
这里跟上面的“每台机器的进程平均运行时间”很像,思路也基本一致
我们先对两表进行左连接,因为左表的id可能从未发送过请求,所以确认率也要计算,算作0,因此要用左连接表示null,方便统计0
然后按照s.user_id进行分组,分组后使用avg()对action列进行统计,再使用if()对每行数据进行判断,如果为'confirmed'则视为1,反之为0,全部相加后统计平均值,就是正确率
代码:
#左连接+分组+数学
select s.user_id, round(avg(if(c.action='confirmed',1,0)),2) confirmation_rate from Signups sleft join Confirmations c on s.user_id=c.user_idgroup by s.user_id技巧
求比率的问题可以用avg(if)来解决
本篇文章到此结束,如果对你有帮助可以点个赞吗~
个人主页有很多个人总结的 Java、MySQL 等相关的知识,欢迎关注~