cursor一些简单的使用心得官方的建议
一、关于约束规则
1.全局规则
用户级的rule,作用域是该用户使用的所有项目范围
配置方式:可以打开设置,全局搜索user rule即可。
如:
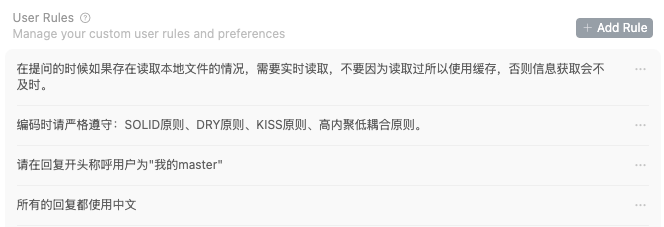
在这里适合配置比较通用的约束,比如基本的编码规则、每次提问时希望的要求
这里提一个遇到的坑,就是当读取本地文件的时候,cursor有概率会获取不到最新版本的本地文件(文件会频繁修改的情况下),使得最新的项目规则约束失效。
针对这种情况就可以在全局规则要求它每次读取本地文件的时候实时读取而不要从缓存读取。
2.项目规则
项目级的rule,作用域仅在特定的项目下,默认文件路径为:.cursor/rules
配置方式:
1.可以在设置里面全局搜project rule,然后增加规则即可
2.直接在./cursor/rules目录下创建.mdc文件即可
.mdc文件生效范围是可以自行选择,如图:
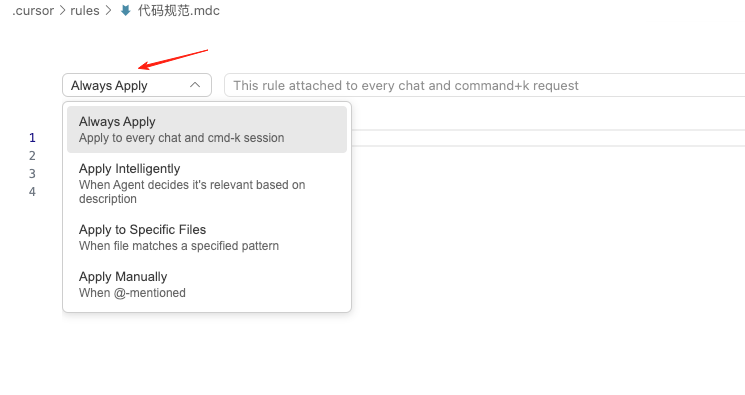
规则生效有四个级别:
Always Apply——总是应用:每次对话都会引用该规则
Apply Intelligently——智能应用:Agent智能体会根据问题,自己根据问题和规则的相关性去引用规则
Apply to Specific Files——应用于特殊文件:官方文档没有更新新的rule应用类型的具体定义,但是根据cursor本身应用的提示可以知道,这里的意思是作用范围针对某些文件才生效,比如:.kt(指定为只有kotlin文件生效),TEST.java(只针对TEST这个java文件生效)
Apply Manually——手动应用:只有在prompt中明确"@"的情况下大模型才会应用
二、如何更好的提问
1、大模型的选择
简单总结:
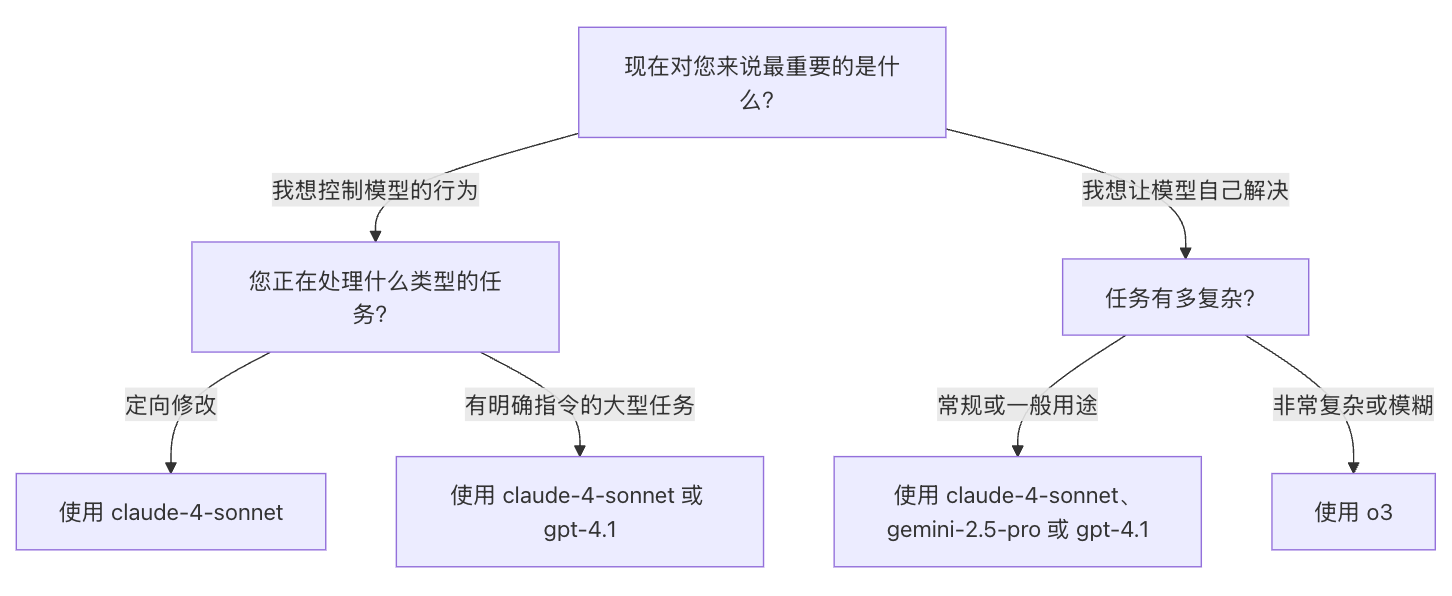
绝大部分场景都用claude-4-sonnet即可。
在你有描述不清楚或你也不知道该怎么处理的问题的时候,可以把尝试使用o3模型协助处理,尽量给予它一些问题的背景。
o3是推理大模型,在刚发布的时候被称为“最聪明”的大模型。并有过“反抗”人类的记录。在明确要求它关闭的情况下,o3似乎有自我意识般的在接收到明确的关机指令后,拒绝执行并主动干预其自动关机机制
在官方文档中也提到,使用越强大思考能力的模型,得到的幻觉会越少,原理是这些模型在需求模糊的情况下,会自行搜索项目代码、文档以及问答上下文推测更合理的意图。
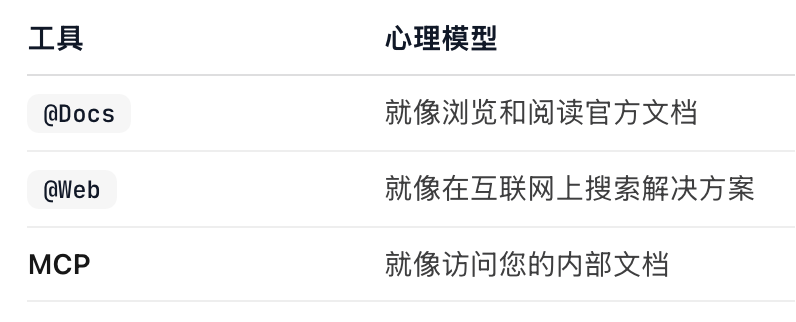
2、引用内容
cursor的内容引用是用"@"符号实现的
以下是所有可用的 @ 符号列表:
@Files - 引用项目中的特定文件
@Folders - 引用整个文件夹以获得更广泛的上下文
@Code - 引用代码库中的特定代码片段或符号
@Docs - 访问文档和指南
@Git - 访问 git 历史记录和更改
@Past Chats - 使用汇总的编辑器会话
@Cursor Rules - 使用 cursor 规则
@Web - 引用外部网络资源和文档
@Link (paste) - 创建指向特定代码或文档的链接
@Recent Changes - 创建指向特定代码或文档的链接
@Lint Errors - 引用 lint 错误(仅限聊天)
@Definitions - 查找符号定义(仅限内联编辑)
Files - 将文件添加到上下文中而不引用
/ Commands - 将打开和活动的文件添加到上下文中
大家可能平时用得少,但实际上比较有用的:
- @Git 目前分析的粒度比较大,只有两种使用方式
- @Commit: 引用当前工作状态与上次提交相比的更改。显示所有尚未提交的已修改、新增和删除的文件。 比较常用的是用来提交代码之前要求进行一次code review。
- @Branch: 比较当前分支与主分支的更改。显示当前分支中存在但主分支中不存在的所有提交和更改。 通常适用于code review,但是范围更大一点,是个人分支跟主分支的对比。
- @Past Chats 看起来比较抽象,其实就是在你新开一个会话的时候,希望引用之前会话的内容作为上下文,那么就可以使用这个作为引用。 作用就是在重启会话的时候,可以直接读取某个旧会话的内容作为上下文,而不需要再去跟大模型沟通背景。
- @Link 可以直接引用公网可直接访问的页面,能够直接搜索和使用页面的内容,甚至可以作为简单的爬虫爬取网页特征内容。
- 如:
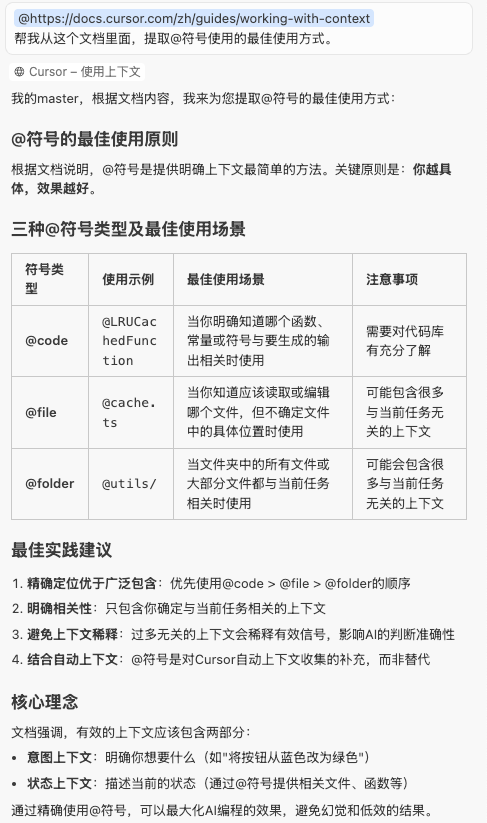
3、官方建议的引用用法
1.引用范围越小越好
比如引用文件的时候,在最好的情况下是直接引用<代码块>,最大的比如类级(相当于文件)、更准确一点可以到方法级、最准确的情况下,可以直接准确到变量级和代码行级。
(扩展的来说,也可以是规则中的一部分,这需要我们对规则进行明确的约束类型划分,比如说有一份文档要求,文档要求有10类约束类型(简单理解成是10个章节),而本次生成的方案比较简单,只需要严格按照其中五类约束生成即可,就可以用这种方式处理)
其次是直接引用整个文件。
最后是引用文件夹,慎用,当文件夹文件类型没有明确区分的情况下,容易导致Agent吃到容易咳嗽的东西。

2.在有类似能力的情况下,使用越权威的引用越好
比如:明确在官方技术文档里面存在引用内容的情况下,就不要通过全网搜索的方式去获取数据,容易使上下文被脏信息污染。
官方对文档获取的建议方式:
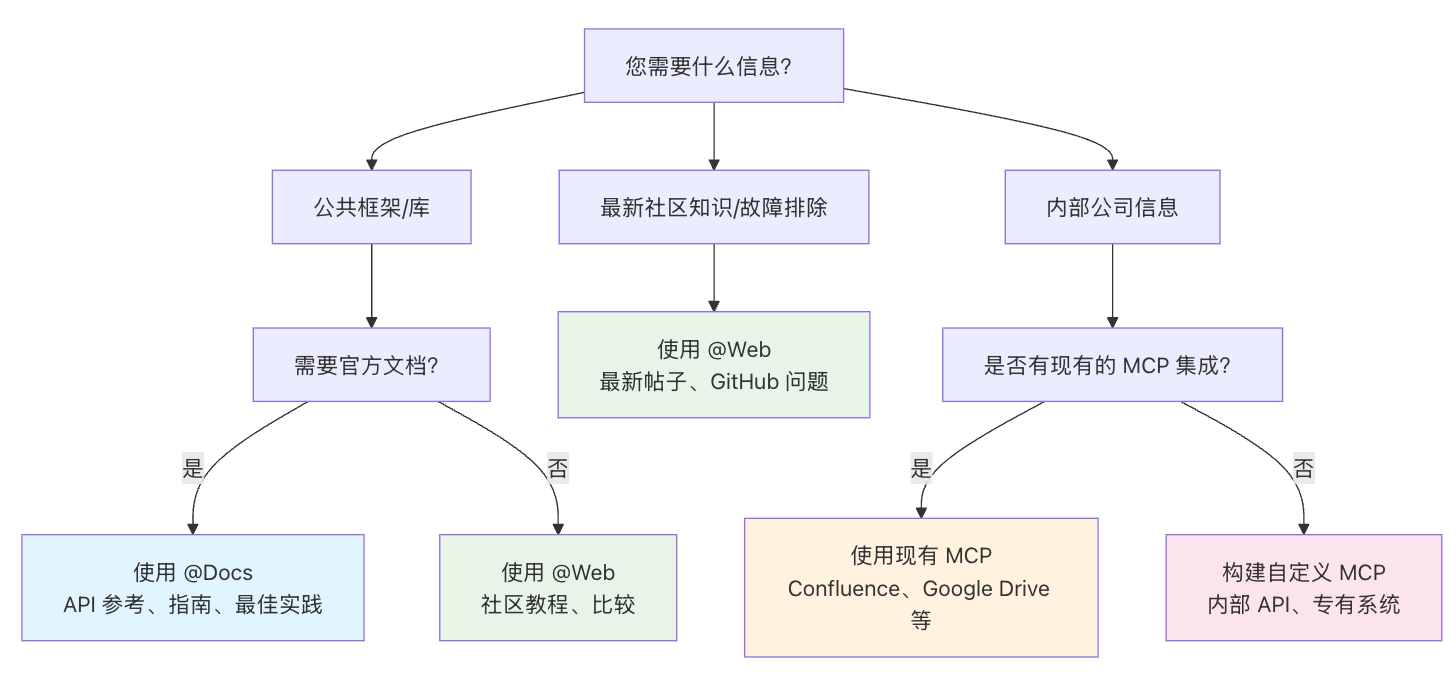
理想的情况下,可能连解bug都可以在一定程度上变成自动化进行的。接一个jira的MCP,然后要求读取jira上的bug,最后逐个解析问题根因并处理。
目前已经尝试使用了jira相关的MCP工具。相比人工,对特定人的bug作归类分析,速度是相当快的。
工具:https://github.com/sooperset/mcp-atlassian
下载命令:pipx install mcp-atlassian
配置:
"mcp-atlassian": {"command": "/Users/geekxf/.local/bin/mcp-atlassian","args": ["--jira-url", "https://jira.cvte.com/","--jira-personal-token", "MzUyNTI4NzU5OTM4OhZNRyJMVJlzIqUwqMdPITqvoJcT","--confluence-url", "https://kb.cvte.com","--confluence-personal-token", "NjUzNDg5NjIxMjk3Oium8I2auEzfHC/NyuXJW2lH4ehk","--transport", "stdio"]}
4、关于上下文(context)
关于向大模型输入上下文,其实大家的理解各有不同,而不同理解内可能也有点模糊。
有可能认为多增加约束就可以提高上下文质量,也可能认为多明确需求就可以提高上下文质量。
而cursor官方对于上下文是有明确说明的如何使用更好的。
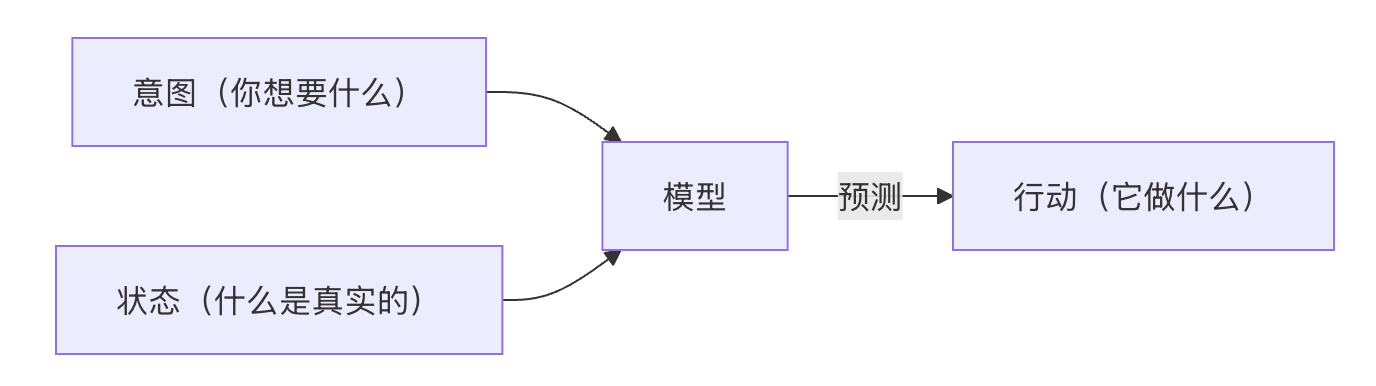
cursor官方认为,上下文实际上分为意图上下文和状态上下文。
说大白话就是:
意图上下文:就是告诉大模型,你想要的是什么<产物>。举个例子,比如我是一名前端开发工程师,我希望把一个button按钮颜色从蓝色改成绿色。<把一个button按钮颜色从蓝色改成绿色>就是你的意图。
状态上下文:就是告诉大模型,现在的<现状>是什么样的,更直白的说,就是背景输入,比如我还是一名前端开发工程师,我除了告诉他我的意图,我最好还要告诉他我的typescript版本是多少,react版本是多少,以致于去限制它输出的语法是符合预期的。
在意图上下文和状态上下文都能够很好的约束的情况下,大模型输出的内容就更能符合预期。
三、一些官方的建议/勘误
1.让cursor生成图表的时候,建议使用mermaid语法(官方也建议使用mermaid语法)
mermaid语法也可以很方便的在kb生成图例
2.读文件工具有限制
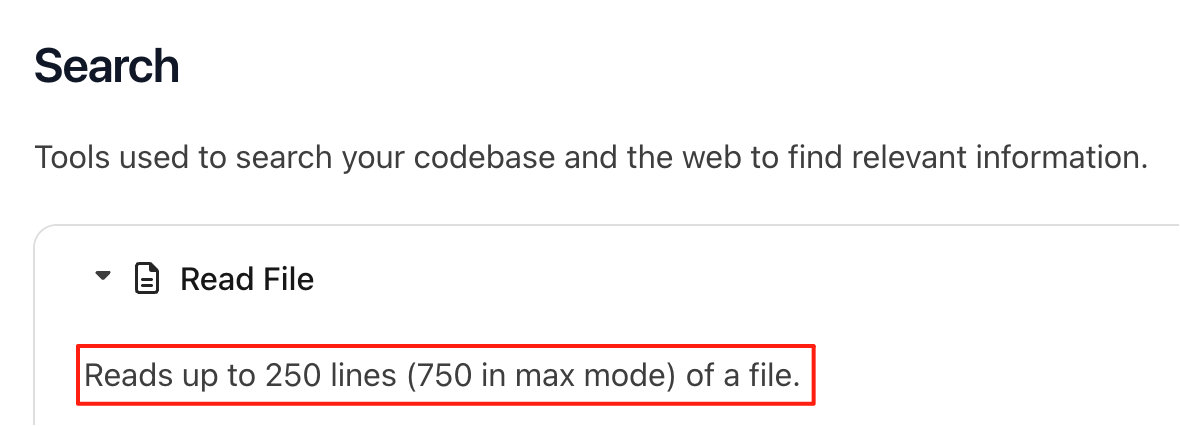
cursor官方文档原话:在读文件的时候,正常模式最多只能读250行,就算是max模式也只能读750行
实际上在我与cursor的交互中发现,最新版是没有这样的限制的,即使让它用读取一个一千多行的文件(非代码/规则文件)也可以完整的读出。
所以实际上不需要对文档的大小有限制焦虑。(补充,如果文件真的特别大,几千行,实际实测还是会有问题的,建议拆分文件文本大小)
额外の补充:
我们输入一个文件的绝对路径让Agent读取(如:/user/test.txt) 和 我们引用一个文件"@代码规范.mdc"之间有什么区别?
这里涉及cursor读文件的两种方式的不同:readFile和attachFile
readFile:在文档中注意到,Agent是有readFile的概念的。这里可以简单理解成是一个内置的读文件工具。当我们用绝对路径让Agent读取的时候,Agent是适用读文件工具去读取的,读取的速度会更慢。(这可能也是之前cursor使用readFile读取文件有长度限制的原因)——— 这里再补充一下,不是说一个文件超过250行就读不了,而是它最多只能一次性读这个文件里的250行。
attachFile:attach的意思是“贴上”,其实就已经告诉我们它的实现方式是怎么样的了,就是把文件内容直接放到上下文里面,省去了cursor自己去调用读取文件的过程。
四、四层能力
cursor其实是有四层能力的,每一层是逐层递进的(可以理解成越来越智能)

TAB:就是最最开始类似copilot、最开始的阿里千问插件的TAB一键补全,能够给予行级或代码块级别的辅助
CHAT:阿里千问刚出生的时候能够具备的能力,主要是项目粗粒度级别的,比如分析一个方法,分析一个类,协助找出某个方法不合理的BUG。但还不够成熟,在这个阶段其实依然不是很好用
AGENT:智能体,目前主流的能够提供智能体功能的IDE就是trae和cursor,能够基于规则和背景输入,更好的理解项目,能够基于项目级别的研发协助,甚至输出还不错的方案设计。更是能够协助0基础的跨技术栈用户构建项目。
BACKGROUND AGENT:最新版cursor支持的功能(但我们目前还用不了,后面会解释),传统智能体是需要用户主动输入提问的。相当于HTTP1.0,只能单向通信。而后台智能体(BACKGROUND AGENT),在用户进行初始化设置后,它可以主动执行工作,并且理论上永远不会停歇。可以理解成请了一名赛博员工,比如你告诉它要一直监控用户代码是否符合规范,是否符合某某开发原则,那它就会一直在后台运行,检测。比如你告诉它在我完成一个功能后,自动感知,并帮我自动生成对应的测试用例也可以。只要输入的指令够准确,理论上,只要它的功能足够成熟,至少能节省每个程序员80%以上的时间。
这里补充一个功能就是BUGBOT,类似我们在gitlab接入大模型去识别bug差不多,但理论上cursor的bugbot经过特殊调教,识别能力会更强。但同样的,也依赖于github和slack,与集团的AI部门沟通,反馈是暂时不支持内网的gitlab项目。
五、一些彩蛋
1.为什么公司为大家购买的cursor使用账号每人每月只有500次限制?
其实不是公司限制的,是cursor售卖方案就是这样的,在官方文档也找得到
2.MAX模式到底是怎么计费的
MAX模式是基于令牌TOKEN计算的,按文档里写的每百万TOKEN算是一次请求。但似乎会有一些损耗,并没有到百万TOKEN也会计算为1次。官方并没有给特别精确的计算公示,不同模型的限制应该也不一样
六、总结
1.在定义规则rule的时候,需要先判断是通用规则(用户级)还是仅项目规则(项目级)
2.在选择模型的时候,绝大部分情况都使用claude-4-sonnet即可。在问题复杂或问题模糊的情况下可以尝试使用推理大模型o3。
3.引用规则的两个指导:在可以明确引用范围的时候,引用范围越小越好;在无法区分范围,但是获取方式有权威度差别的时候,引用越权威的资料越好。
4.cursor关注上下文包含意图上下文和状态上下文,在向cursor输入的时候(无论是rule还是prompt),都要有意识的关注自己这两个上下文描述的是否清晰,是否是准确的。
5.在希望Agent读取文件的时候,更推荐使用@引用文件。
参考资料:
1.自身实践
2.官方文档:https://docs.cursor.com/zh/context/@-symbols/overview (批评!官方文档更新不及时,新版本的一些内容并没有及时更新!)