游戏大规模数据存储与数据量增加之后扩容的思考
从事这么多年的服务端架构设计与开发,最明确的感觉就是,不管做什么架构设计,数据存储及数据量增之后的扩展都是首要解决的问题。对于公司来说,最重要的核心资产就是玩家的数据,好的架构必须是能满足随着用户量越来越多,数据的存储能进行平滑的扩展。
我们都知道,一台数据库的数据存储是有局限的,想要存储众多的数据,必须选择的就是分库(分表先不谈,因为分表是在一个数据库内操作的,比较方便实现)。将数据存储在多个不同的数据源服务上面,虽然解决了数据存储问题,但是使用的时候就会相对麻烦些,因为你得知道你需要的数据到底存储在哪台数据库上面。
既然前提已经确定数据是分开存储的,那么剩下要解决的就是服务怎么样将数据存储到对应的数据库里面,以及使用的时候怎么样查询到数据了。在说这两个问题时,我们必须设定一个应用场景,如果没有应用场景,讨论一个四海皆可的框架,跟耍流氓没什么区别,只不过不同的场景需要变通一下,核心宗旨是类似的。
对于游戏场景来说,一种是提前规定好游戏的玩法就是分服制的,不同服之间的玩家数据是隔离独立的,最简单的一种方式是一台服务对应一个区服,再对应一个数据库就行了,达到服务上限时,再开新服即可,复杂一点的可以多台服务对应一个区,多台服务可以使用redis共享内存,每台服务的功能是一样的,就是水平扩展了一下,但是数据库是同一个,这样相对于一个服务的话,单服支持的同时在线人数会多一些。这种框架设计相对比较简单些,数据的存储及使用没有过多的额外规则,扩展分区时也不用迁移数据,只不过游戏的玩法上受服务及数据存储上限的一些限制,后期还需要根据需要合服。
另外一种设计是不分服的框架,对于玩家来说,大家都在同一个世界里面,即平时我们所说的世界服,所有玩家的数据不是隔离独立的,都可以产生交互,这种游戏同时在线的玩家越多越有乐趣,在玩法设计上也越有空间。这种设计复杂性更高些,这相当于一个可以无限扩展的存储,其主要难点还是要解决如何分布式存角色数据,以及使用数据时如何定位数据在哪个数据库中。比如下面这个图所示:
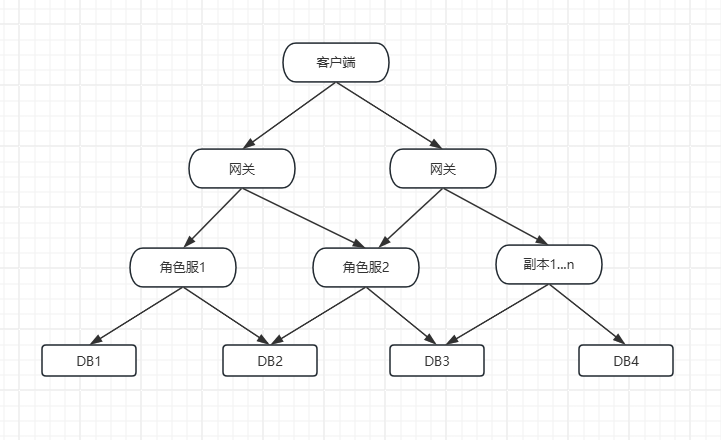
- 数据库是共享的,各个服都会连接每个数据库
- 角色分部在各个数据库中
先说数据存储的数据,数据存储是从0到1的过程,原来没有这条数据,现在要存储这条数据,那这条数据应该通过怎么样的规则,存储到哪个数据库里面呢?- 假如角色A由网关路由到了角色服1,角色服1有所有的数据库连接,如果按照固定的数据库数量计算,可能通过计算角色A的ID的hash值,然后根据数据库数量求余,得到一个数据源,存储到此数据库中,登陆时查询角色数据时,也按相同的算法定位到相同的数据库,也能查询到数据,但是又一个问题来了,如果将来要扩展数据库,增加了数据库,再根据hash与数据库数量求余就不一定还是原来的数据库了。只能对原来数据库的数据,按新的数据库数量重新hash求余,重新分配数据存储的数据库
- 如果不想迁移数据,一个方法是基于上述1的方式中,当确定某个角色存储到某个数据库之后,找一个新表,记录一下角色ID存储在数据库(给数据库制定一个唯一编号),用户再登陆时,查询的时候,先查询角色ID对应的数据库编号,然后再去这个数据库查角色的所有数据,相当于创建一个角色与数据库关联的索引表,这样又引出来另外一个问题,如果数据量比较多。比如10亿条数据,这个索引表就又非常大了。
- 要解决索引表大的问题,可以单独对这个索引表进行分库分表,比如角色ID生成时可以按照一定的规则,比如时间: 2025100910-8923342,前半部分精确到小时,后半部分是为了保持唯一性,那么就可以根据日期进行分库分表了。
- 可以看出,上面的方案都是以角色ID来处理的,但是在用户第一次进入游戏时角色ID还不存在,而且当用户登陆的时候,输入的并不是角色ID,而是一个账号,比如手机号,邮箱或自定义的账号名。这些都是无规则的数据,不能像角色ID那样以固定的格式进行分库分表。这里才是真正意义上的从0到1开始突破了,解决了这个问题,所有的问题就都串起来了。
如何存储登陆的账号
对于游戏用户来说,账号注册也是只产生一个表,它跟角色ID的索引表类似,但是它没有索引表的时间规律,这就比较麻烦了。
方案一,提前预估数据量,准备好存储完这些数据所需要的数据库数量。比如我们预估数据有100亿,那就提前准备好20个数据,一个数据库存5亿条数据,根据账号名的hash值与数据库数量求余,查询的时候也是同样的算法,这样就可以解决存取一致的问题。但是前提是要预估准确些,多了还好,如果预估少了,将来数据达到存储瓶颈时,再扩展就需要迁移数据了。
方案二,存的时候使用hash求余定位法,查的时候去所有的数据库中查询。这个方法的好处是不用提前准备那么多的数据库,可以动态扩展数据库,也不用迁移数据。因为这个表是单表,没有关联表,把账号设置为唯一索引,查询的速度也非常快,单独做一个登陆服务的集群,每次用户登陆的时候都遍历所有的数据库查询这条数据,如果存在就中止,或开几个线程同时去查询,哪个先返回了数据,就给前端先返回数据。再加上缓存机制,活跃的用户一定时间内只会查询一次,这样查询速度会更快。
为了说明整个系统的完整性,登陆账号的存储先用方案二:
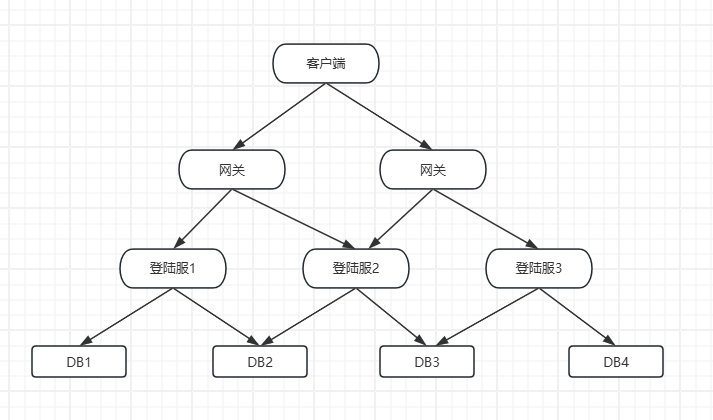
用户登陆时,先在登陆服找到用户登陆之后的数据,账号创建了几个角色也记录在账号表里面,这样用户可以选择一个角色ID,去查角色索引表,获取到角色数据存储在哪个数据库里面。
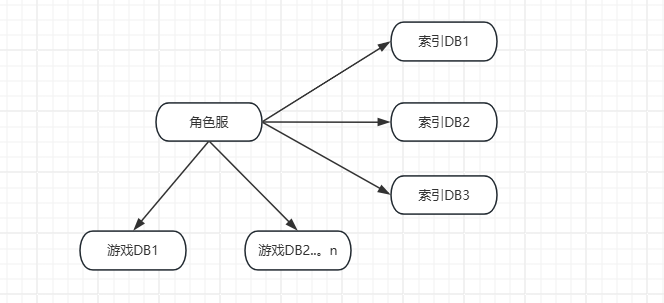
对于活跃用户,可以额外再加上缓存机构,这样可以减少查询数据库的次数。