免费网站个人注册网页设计教程与实训
一、什么是大语言模型(LLM, Large Language Model)
大语言模型是一类基于神经网络的模型,它们的主要功能是“理解”并“生成”自然语言(如中文、英文)的文本。
通俗来说,它就是一个学会了预测下一个词的超级自动补全模型。
特点:
-
输入一句话,它能补全;
-
输入一个问题,它能作答;
-
输入一句话,它能翻译、总结、写诗、写代码等。
举例:
输入:
今天天气真不错,我们一起去…
输出(预测):
公园散步吧!
它不是死记硬背,而是根据语言规律进行预测生成。
二、大语言模型是如何训练出来的?
1. 模型结构:Transformer
大语言模型最典型的结构是 Transformer(最早由 Google 提出)。
Transformer 是一种深度神经网络结构;
-
优势:能并行计算、能处理序列数据(如句子、文章);
-
ChatGPT、GPT-4、BERT、LLaMA、Claude 等几乎全是基于 Transformer 架构
2. 训练流程大致分三阶段:
(1)预训练(Pretraining):
原理
大模型预训练目的是通过海量无标注文本(如网页、书籍、代码等)训练模型,学习语言的基本规律(语法、语义、常识)。模型通过自监督学习任务,例如下一个Token预测,构建通用语言理解能力。
步骤
预训练损失函数就是CE loss,
-
损失函数:通常是 交叉熵损失(cross entropy),用来衡量预测的词和真实词之间的差距。
以预测下一个Token为例,其大致流程如下:
- 从训练集中取一个文本样本;
- 样本加上特殊标签,如<bos>, <eos>等作为开始或者结尾标记;
- 样本padding或者截断到指定长度以便并行计算;
- 输入文本通过Tokenizer编码为数字,输入LLM模型;
- 输入序列经过maksed multi-head attention确保模型的因果性;
- 最终输出序列每个位置内容为预测的下一个Token的概率;
- 输入文本左移一位作为每个位置的label进行CE损失计算(当前位置预测下一个位置的Token)。
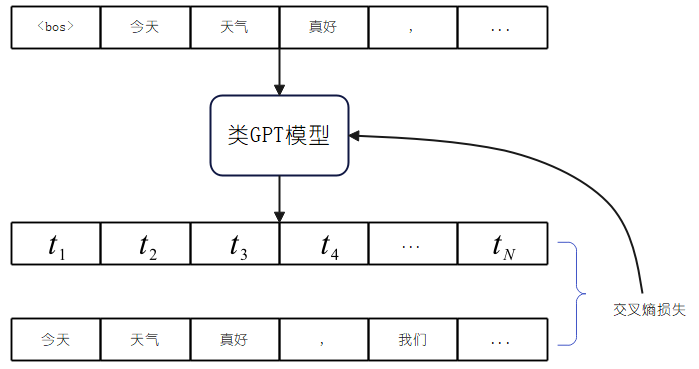
通过对下一个Token任务的训练,在推理阶段,模型将通过自回归的方式,根据前面的内容不断生成新的内容。
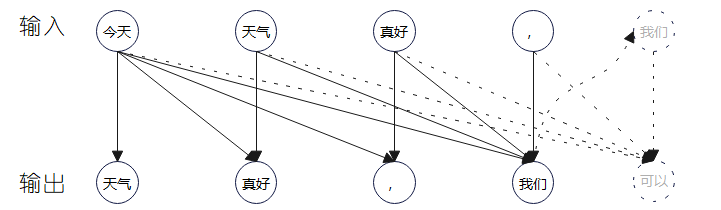
特点
大模型预训练在于通过对大规模数据的学习,从而捕捉语言统计规律和通用知识。其具有如下特点:
- 数据量极大(TB级)、计算成本高;
- 模型参数规模决定能力上限(如7B/13B/70B参数模型)。
(2) 监督微调(SFT)
原理
预训模型虽然具有通用知识,但是它无法理解人类意图,监督微调使用高质量标注数据(问答对、指令-输出对)对模型进行有监督训练,使其适应具体任务格式(如对话、摘要、翻译)。
-
举例:给模型一个问题和一个正确答案,让它学习如何答题
特点
- 数据质量 > 数据量(需人工筛选或合成);
- 训练任务与预训练相同,仍旧采用下一个Token预测任务进行模型训练;
- 通过在数据中增加特殊标签作为指令;
- 典型应用:将基础模型转化为Chat模型(如ChatGPT基于GPT-3.5微调)
(3). 基于人类反馈的强化学习(RLHF)
原理
通过人类对模型输出的偏好排序(如选择更安全的回答),训练奖励模型(Reward Model),再通过强化学习(如PPO算法)优化模型生成策略。强化学习目标是使输出更符合人类价值观(安全性、无害性、有用性),解决SFT后模型可能存在的输出偏差问题。
流程
RLHF大概流程可以总结为如下步骤:
- SFT模型生成多组回答;
- 人类标注员对回答质量排序;
- 训练奖励模型预测人类偏好;
- 使用PPO算法优化模型以最大化奖励。
(4). 不同训练阶段对比
下表对模型不同训练阶段进行了总结:
| 阶段 | 数据要求 | 目标 | 典型方法 |
|---|---|---|---|
| 预训练 | 无标注通用文本 | 学习语言基础能力 | 掩码预测/下一个Token预测 |
| 监督微调 | 任务标注数据 | 对齐任务格式与用户意图 | 指令微调 |
| RLHF | 人类偏好数据 | 对齐人类价值观与安全性 | PPO+奖励模型 |
三、与传统神经网络(深度学习)的区别?
| 项目 | 传统神经网络 | 大语言模型(LLM) |
|---|---|---|
| 网络结构 | CNN / RNN / LSTM 等 | 基于 Transformer 架构 |
| 数据类型 | 图像、音频、简单文本 | 大规模自然语言文本 |
| 训练目标 | 分类、回归、检测等 | 语言建模(预测词)、多任务生成 |
| 数据量 | 通常几十万到几百万样本 | 数千亿词级别数据(如 GPT-3 用了 3000 亿词) |
| 参数规模 | 从几十万到千万 | 从几亿(GPT-2)到千亿甚至万亿参数(GPT-4) |
| 训练时间 | 几小时到几天 | 几周到几个月,需超级计算资源 |
| 应用能力 | 专项任务如分类/识别 | 通用智能:对话、写作、编程、翻译、推理 |
总结一句话:
大语言模型是基于 Transformer 架构,用海量文本训练出来的一种通用语言智能系统,其本质仍然是深度学习,但通过规模化训练和对齐技术实现了超越传统模型的语言理解与生成能力。
参考链接:DeepSeek-R1专题:LLM大模型训练流程