深度学习之YOLO系列YOLOv1
目录
简介
一、YOLOv1
1、核心思想
2、网络架构
3、损失函数
3.1、位置误差
3.2、confidence误差
3.3、分类误差
4、NMS非极大值抑制
二、YOLOV1存在的优缺点:
1、核心优点
2、主要缺点
简介
上一篇博客我们简单介绍了一下关于YOLO的基本知识,说了目标检测算法与解释了YOLO评价指标的一些专业。今天我们就来走进YOLO的发展史,从YOLOv1版本慢慢介绍到最新版的更新历程,探索每一个版本有哪些创新的点。
深度学习之YOLO系列了解基本知识
一、YOLOv1
1、核心思想
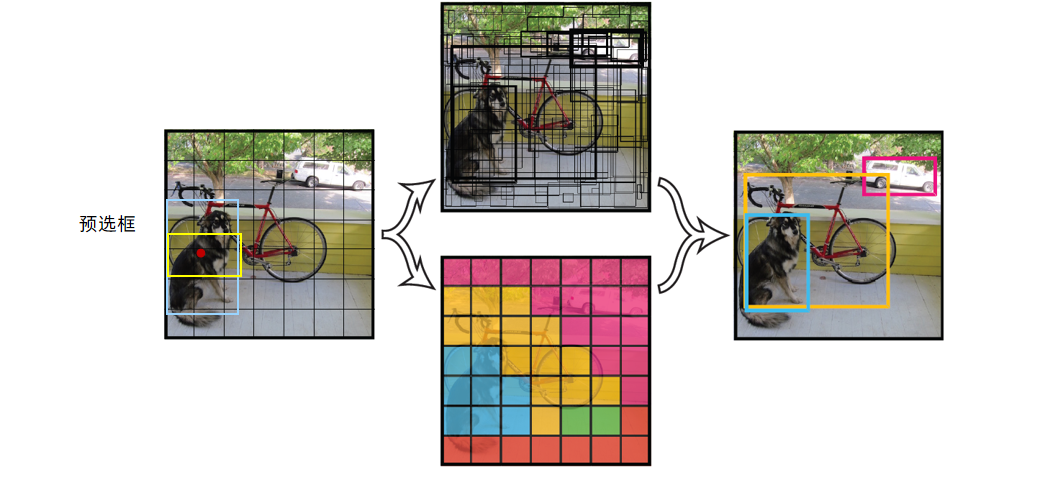
核心思想:将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
这也是整个YOLO模型的核心思想
2、网络架构
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
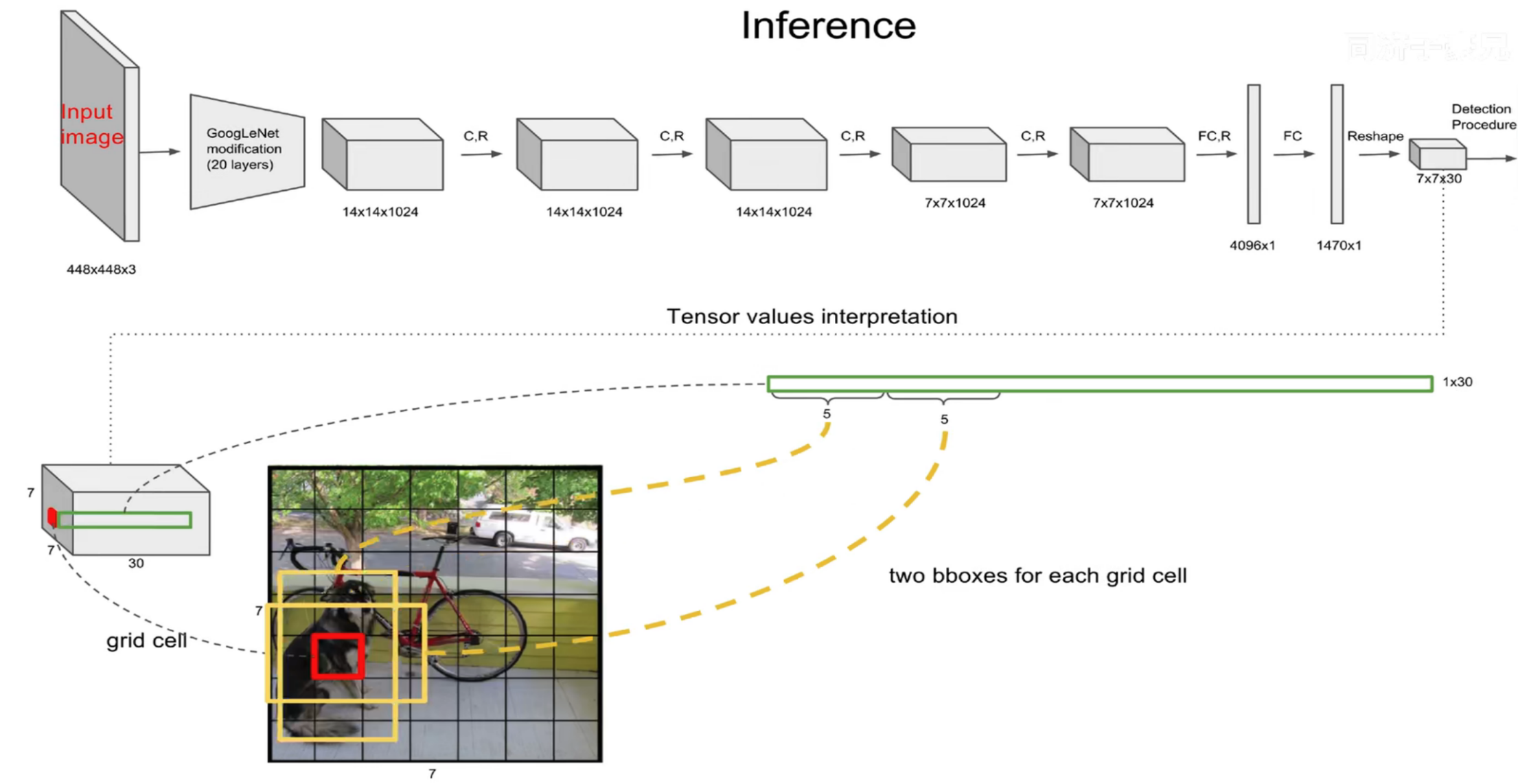
YOLOv1的网络结构主要由卷积层、池化层以及最后的全连接层组成。
网络的输入是448x448x3的彩色图片,输出是7x7x30的张量(tensor)。
7x7表示将输入图片划分成了7*7个网格(grid),每个网格负责检测其内的物体。
30表示每个网格内的30个预测信息,包括20个类别概率(以PASCAL VOC数据集为例,该数据集共20个类别)、2个预选框(bounding box)及其置信度(每个边界框包含中心点坐标x、y,宽度w、高度h以及一个置信度分数)。
为什么最终会得到7x7x30的结果?
7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中2个预测框,每个预测框包含5个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度,剩下20个是针对数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。
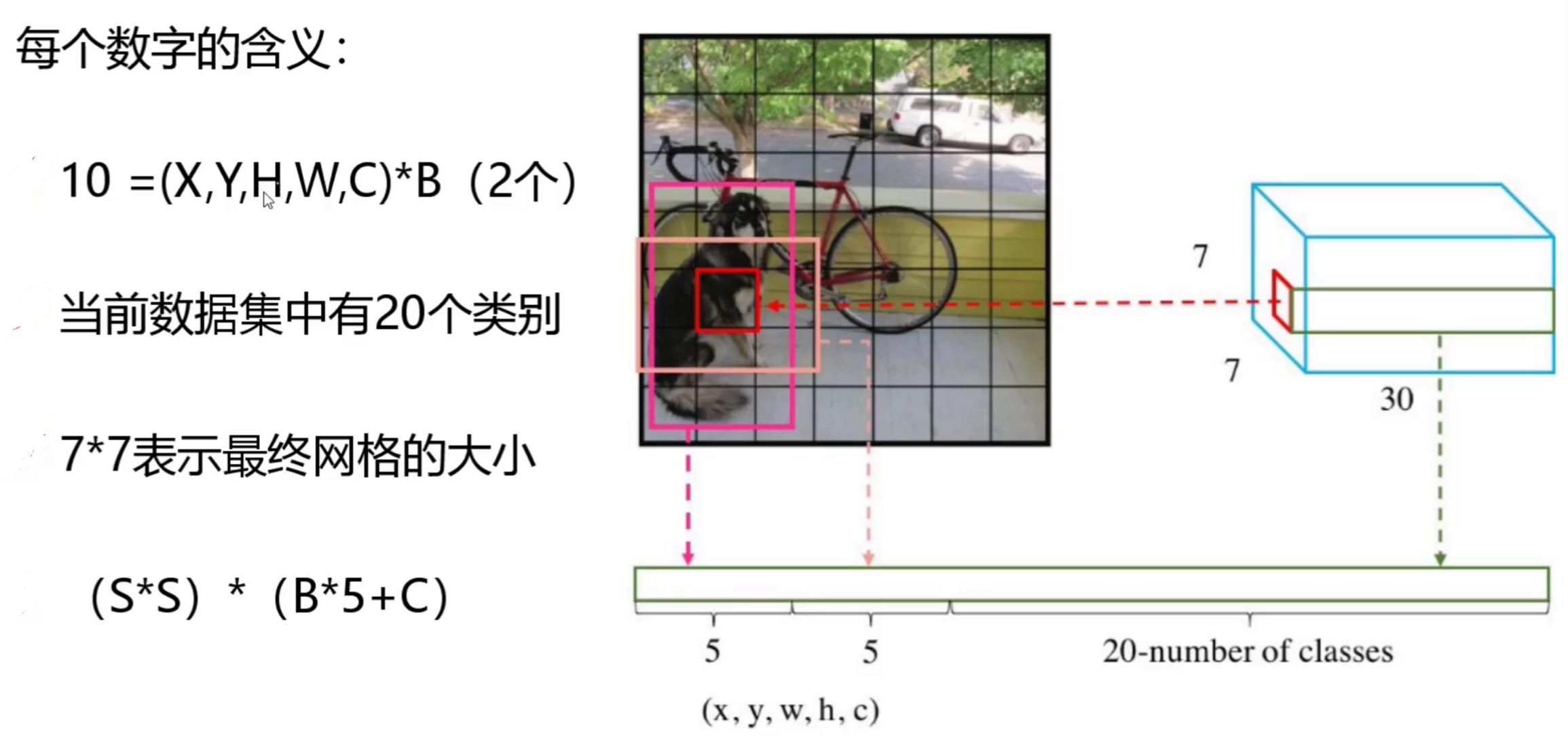
每个grid有30维,这30维中,8维是回归box的坐标,2个B是box的confidence,还有20维是类别。 其中坐标的x,y(相对于网格单元格边界的框的中心)用对应网格的归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
3、损失函数
YOLO-V1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么YOLO的损失就包括三部分:位置误差,confidence误差,分类误差。 损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。
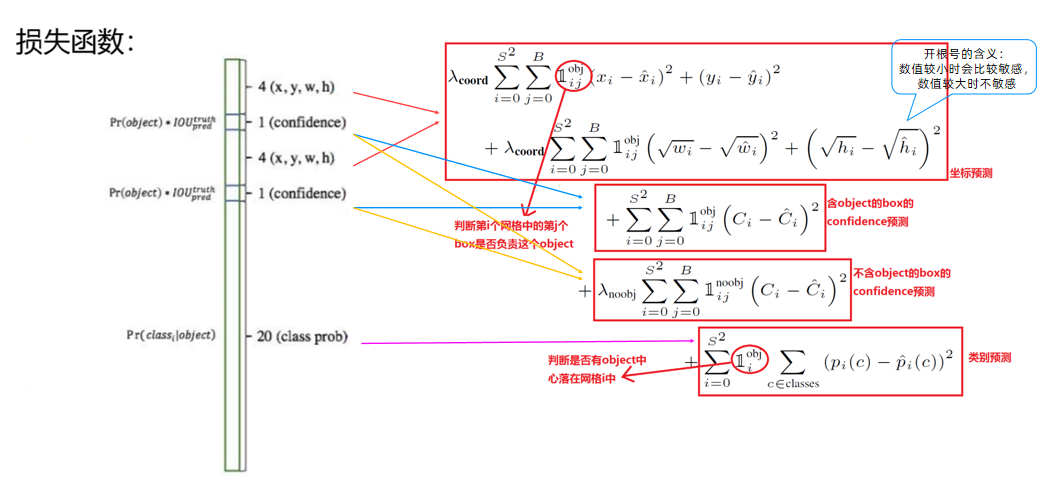
下面这个图是对上面那些公式的详细解释
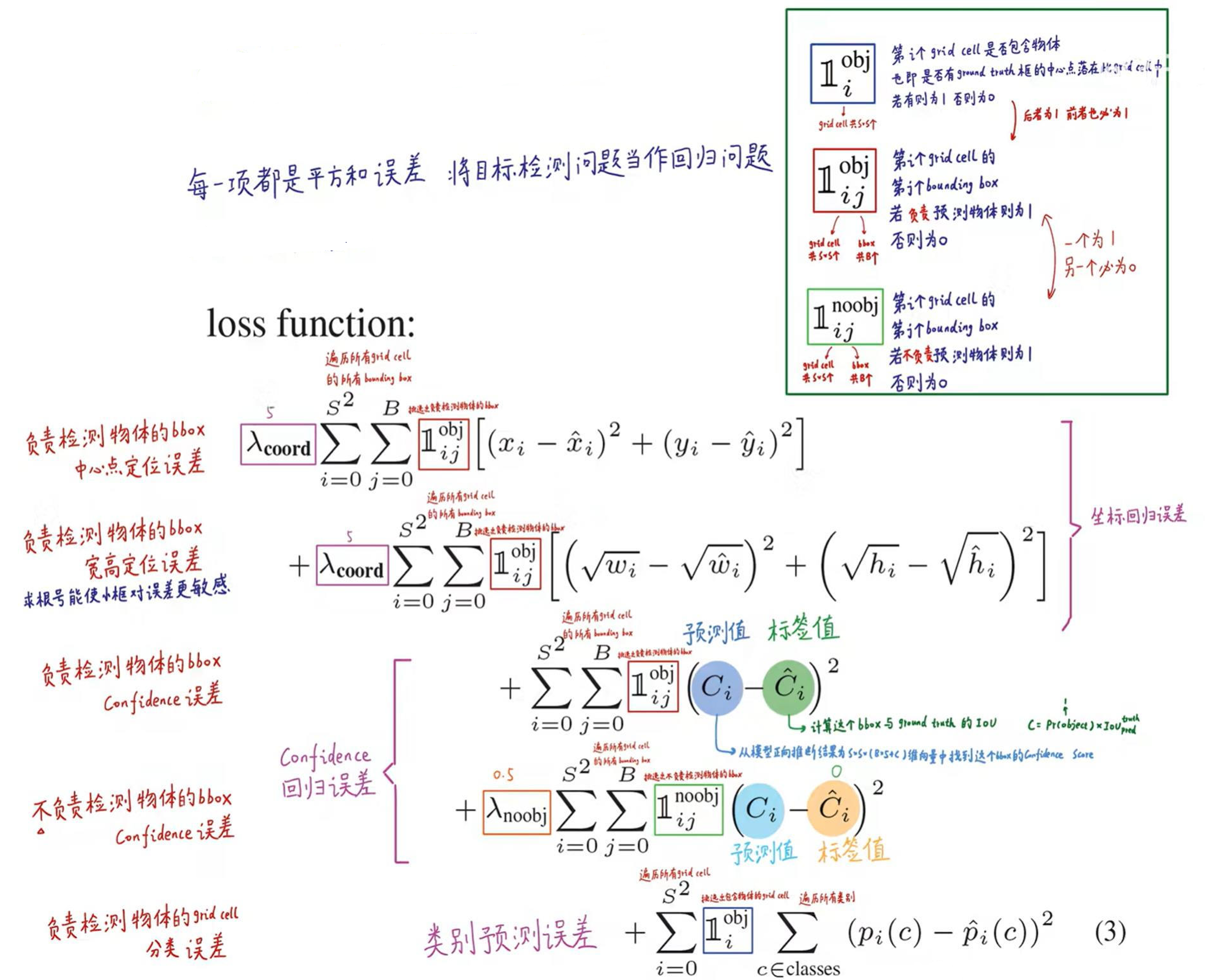
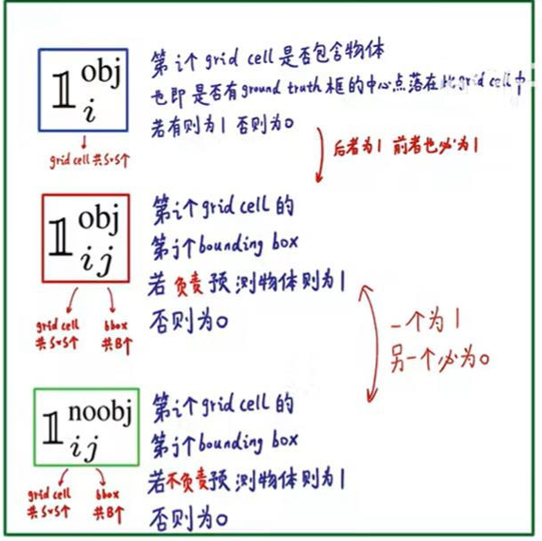
对于这里,可以理解为在49(7*7)个小格识别到目标的中心点就在一个方格里面(所有对一第一个表达式就只有一个为1,其他都是0,为0的它的损失函数也就为零),而对于一个方格我们有两个标注框(所有,j就表示那个标注框,比较那个标注框是看两个框的c也就是置信度那个大,只有大的那个为1,另外的就为0),
3.1、位置误差
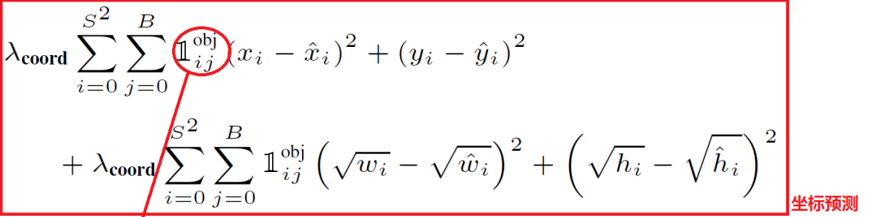
如上图所示,其为位置误差的计算公式,其中对应的值为一个系数,表示如果你觉得位置误差更重要,那么就设置大一点,置信度误差与分类误差也是同样的意思
第二个红框内的符号表示第i个网格的第j个预选框,如果负责预测物体,那么整体的值为1,反之为0
前面的求和符号s平方表示网格的格式,例如YOLO v1中的网格个数为7*7,然后B表示预选框的个数,此处数值为2,后面的x表示预选框的中心点的坐标x,y,以及预选框的宽w、高h。
3.2、confidence误差

的值所表示的意思和上述一致,但是第二个像阿拉伯数字1noobj的符号,其所表示的值和上述位置误差中的相反,此处表示第i个网格,第j个预选框,如果不负责预测物体,那么他的值为1,否则为0,
C的表示置信度的值,置信度C的值 = Pr类别概率 * IOU
类别概率表示边界框(预选框)内存在对象的概率,若存在对象则为1,不存在则为0,IOU为预测的位置框和真实值的框相交集的值除以并集的值的大小。
Ci表示模型预测出来的置信度的值,C^i的值表示实际计算得到的置信度的值
3.3、分类误差
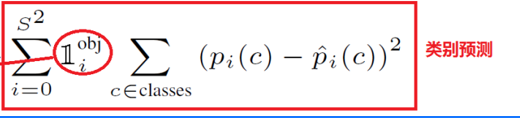
这里第一个求和符号后面的小符号,表示第i个网格是否包含物体,如果包含,那么其值为1,否则为0
pi(C)-p^i(C)表示预测的类别的概率减去真实标签的概率,例如模型输出20类别的结果,即有20个数据,其中有预测到狗的概率,加入标签打的是狗,只需要将20个数据中预测狗额概率的值取出来,然后减去1,在对结果平方即可
4、NMS非极大值抑制
1、概念
在目标检测过程中,通常会生成大量的候选框,当前v1版本有2个复选框,这些候选框可能会有重叠或者包含关系。为了减少重叠的候选框,避免重复检测同一个目标,使用非极大值抑制可以筛选出最佳的目标框。
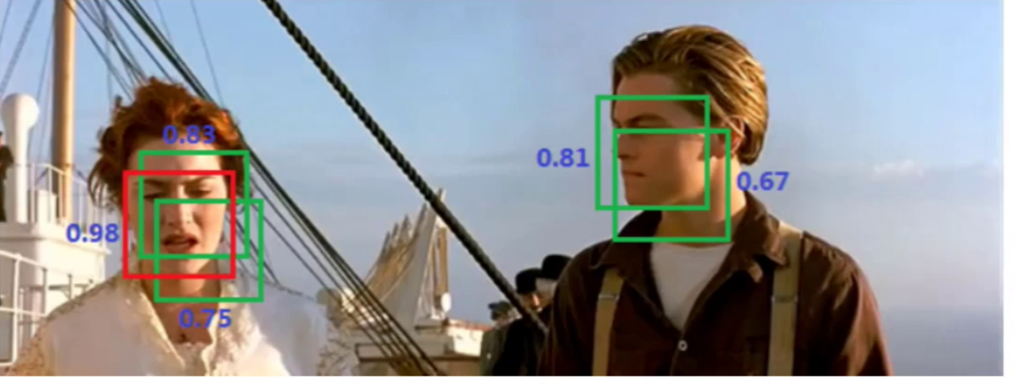
例如上图中,同一个人脸被多个预选框预测出来,导致了预选框的重叠,此时可以将置信度低的抑制了,只保留最大的那个。
2、步骤
1)对所有的候选框根据某个评分指标(例如置信度得分)进行排序,得到一个有序列表;
2)选择评分最高的候选框,并将其添加到最终的目标框列表中;
3)计算当前选择的候选框与其他未选择的候选框的重叠区域,并计算重叠区域与两个候选框面积的比值;
4)如果重叠区域与两个候选框面积的比值超过了设定的阈值,则将该候选框从列表中移除;
5)重复步骤2~4,直到所有的候选框都被处理完毕。
二、YOLOV1存在的优缺点:
1、核心优点
极快的检测速度(核心突破)
OLO V1 是首个能满足 “实时检测” 需求的高精度算法,这一优势源于其 “单阶段” 设计:
- 传统两阶段算法(如 R-CNN)需要先通过 Selective Search 生成约 2000 个候选框,再对每个框单独分类,步骤繁琐且耗时;
- YOLO V1 直接将输入图像划分为 7×7 的网格(Grid Cell),每个网格仅预测 2 个边界框(Bounding Box)和 1 个类别概率,整个过程通过一个卷积神经网络(CNN)单次前向传播完成,无需额外候选框生成步骤。
- 实际性能:在 Pascal VOC 数据集上,基础版 YOLO V1 可达到 45 FPS(帧 / 秒),精简版(Fast YOLO)甚至能达到 155 FPS,远超同期 R-CNN(约 5 FPS)和 Fast R-CNN(约 20 FPS),可满足实时视频检测场景(如监控、自动驾驶实时感知)。
端到端训练与预测(简化流程)
YOLO V1 是首个实现 “从图像输入到检测结果输出” 全流程端到端优化的检测算法:
- 训练阶段:直接以 “边界框坐标回归误差 + 类别分类误差 + 置信度误差” 构建统一损失函数,无需分阶段训练 “候选框生成器”“分类器”“回归器”,简化了训练流程,避免了多模块间的误差传递;
- 预测阶段:输入图像后,仅需一次网络推理即可同时输出所有目标的位置(边界框)和类别,无需额外后处理步骤(如候选框筛选、坐标修正的多步操作),工程落地更便捷。
全局图像感知(减少背景误检)
相比基于 “局部候选框” 的两阶段算法,YOLO V1 具备更强的全局上下文理解能力:
- 两阶段算法(如 R-CNN)的候选框仅覆盖局部区域,易将 “背景中类似目标的区域”(如将路灯误检为交通信号灯)误判为目标;
- YOLO V1 的 7×7 网格会全局扫描整个图像,网络在训练中能学习到 “目标与背景的全局关联”(如 “猫通常出现在沙发上,而非马路上”),因此背景误检率(False Positive)远低于同期的单阶段算法(如 SSD 前身 OverFeat),在 Pascal VOC 数据集上背景误检率比 OverFeat 低约 10%。
2、主要缺点
目标定位精度较低(核心短板)
YOLO V1 的边界框预测逻辑导致定位误差较大,尤其在 “目标边缘对齐” 上表现差:
- 设计局限:每个 7×7 网格仅预测 2 个边界框,且边界框的宽高(w/h)是通过 “网格相对偏移” 回归得到(而非直接预测绝对坐标),这种 “粗粒度网格 + 有限边界框” 的设计,无法精确捕捉目标的细微位置(如 “狗的头部偏左 5 个像素” 这类细节);
- 实际性能:在 Pascal VOC 数据集上,YOLO V1 的定位精度(如边界框与真实框的 IoU 达标率)比 Fast R-CNN 低约 15%,尤其对 “需要精确边界的场景”(如工业质检中检测零件缺陷位置)不适用。
小目标与密集目标检测能力差(关键缺陷)
YOLO V1 的网格划分和边界框数量限制,使其无法有效检测小目标和密集排列的目标:
- 小目标问题:7×7 网格的每个单元格尺寸较大(以 448×448 输入为例,每个网格约 64×64 像素),若目标尺寸小于网格(如 “图像中的小鸟、文字”),会被网格 “覆盖忽略”,无法触发预测;实验显示,YOLO V1 在 Pascal VOC 数据集中 “小目标(面积 < 32×32 像素)” 的检测召回率(Recall)仅为 40% 左右,远低于 Fast R-CNN 的 70%;
- 密集目标问题:每个网格最多仅预测 2 个目标,若同一网格内存在 3 个及以上目标(如 “一群密集的行人、一堆重叠的水果”),会因 “边界框数量不足” 导致部分目标漏检(Miss Detection),这也是 YOLO V1 无法应用于 “人群计数、密集商品检测” 的核心原因。