【kubernetes/k8s源码分析】kube-controller-manager之node controller源码分析
0.1 启动节点更新工作协程(节点调和)
doNodeProcessingPassWorker
NoSchedule 污点调和(nc.doNoScheduleTaintingPass(ctx, nodeName)):
负责根据节点状态(如 NodeReady/DiskPressure 条件、是否不可调度)自动添加 / 移除 NoSchedule 类型污点(作用是 “禁止新 Pod 调度到该节点,但不影响已运行的 Pod”)。其核心逻辑是 “生成期望污点 → 对比当前污点 → 调和差异”,确保节点污点状态与实际健康 / 配置一致
- 基于节点状态自动生成污点:根据节点的 .status.conditions(如 DiskPressure 磁盘压力、MemoryPressure 内存压力)和 .spec.unschedulable(是否手动标记为不可调度),生成 “应有的 NoSchedule 污点”;
节点标签调和(nc.reconcileNodeLabels(ctx, nodeName)
0.2 启动 Pod 更新工作协程(Pod 调和)
doPodProcessingWorker
核心方法 processPod,负责根据 Pod 所在节点的 Ready 状态,动态调整 Pod 的状态(标记为 NotReady)或处理污点驱逐逻辑,确保 Pod 状态与节点健康状态一致。其核心逻辑是 “节点不健康时标记 Pod 为 NotReady,避免流量调度到不可用的 Pod”,是集群自愈能力的关键环节。
- 关联 Pod 与节点健康状态:当 Pod 所在节点从 Ready 变为 NotReady/Unknown 时,自动将 Pod 标记为 NotReady(通过更新 Pod 的 .status.conditions[PodReady]),避免 Service 将流量转发到不可用的 Pod;
0.3 启动 NoExecute 污点处理协程(故障驱逐)
doNoExecuteTaintingPass
节点 Ready 状态→NoExecute 污点 的控制器,核心逻辑是 “当节点不可用(NotReady/Unknown)时,添加 NoExecute 污点触发 Pod 驱逐,同时删除对立污点(避免冲突)”,逻辑更复杂且涉及集群级队列管理:
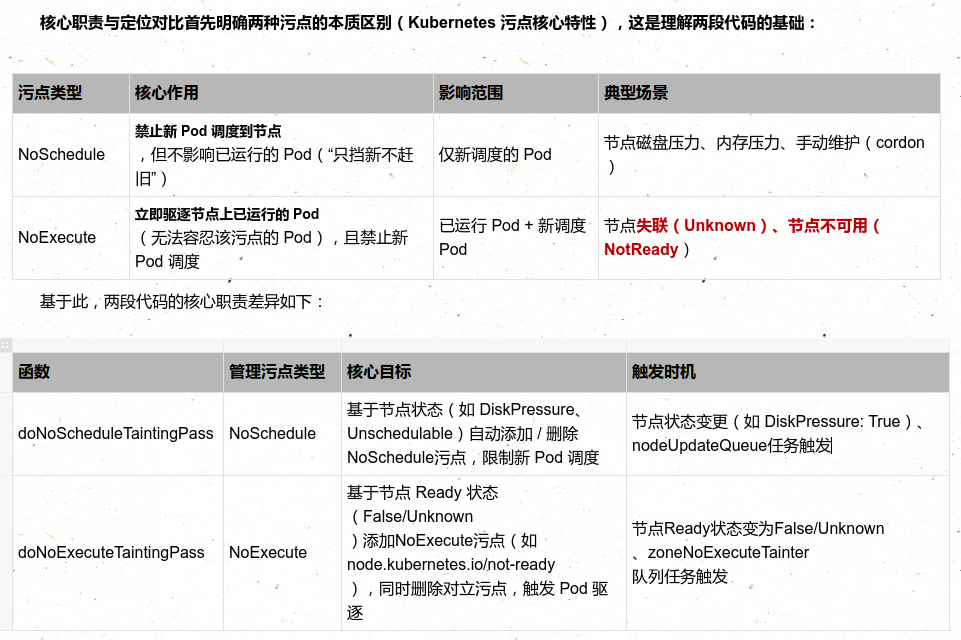
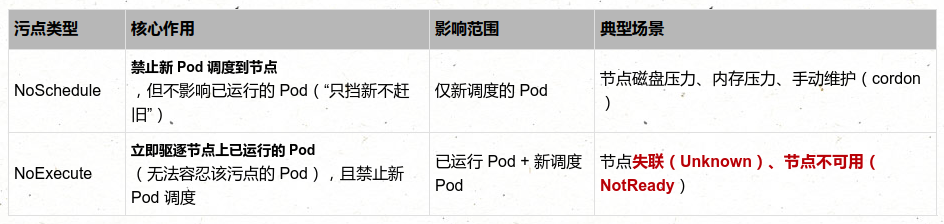
- NoSchedule:仅影响调度过程,对现存的Pod对象不产生影响;
- NoExecute:既影响调度过程,也影响显著的Pod对象;不容忍的Pod对象将被驱逐
- PreferNoSchedule: 表示尽量不调度
1. Run 函数
一、核心定位与依赖
1. 核心职责
- 启动异步工作流:通过 go 关键字启动多个独立协程,并行处理不同维度的节点管理任务(如缓存同步、健康监控、污点驱逐);
- 保障运行稳定性:通过 defer 注册资源清理逻辑(如关闭事件广播、工作队列),确保控制器退出时无资源泄漏;
- 等待上下文终止:监听 ctx.Done() 信号(如集群关闭、控制器重启),优雅终止所有工作协程,避免强制退出导致的数据不一致。
2. 关键依赖(Controller 结构体核心字段)

二、逐行代码逻辑拆解(按启动流程分阶段)
阶段 1:初始化事件广播器(事件上报基础)
// Start events processing pipeline.
nc.broadcaster.StartStructuredLogging(3)
logger := klog.FromContext(ctx)
logger.Info("Sending events to api server")
nc.broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: v1core.New(nc.kubeClient.CoreV1().RESTClient()).Events(""),})
defer nc.broadcaster.Shutdown()
- 核心作用:启动事件广播器,将节点控制器产生的所有事件(如节点注册、状态变化、删除)上报到 API Server,供用户通过 kubectl describe node 或事件监控系统(如 Prometheus Alertmanager)查看。
- 关键细节:
阶段 2:注册资源清理逻辑(优雅退出)
// Close node update queue to cleanup go routine.
defer nc.nodeUpdateQueue.ShutDown()
defer nc.podUpdateQueue.ShutDown()
- 核心作用:通过 defer 确保控制器退出时(如收到 SIGTERM 信号),自动关闭 nodeUpdateQueue 和 podUpdateQueue 工作队列,终止正在处理的任务,避免队列中未处理的事件导致协程 “僵死”。
阶段 3:等待本地缓存同步完成(数据准备)
if !cache.WaitForNamedCacheSync("taint", ctx.Done(), nc.leaseInformerSynced, nc.nodeInformerSynced, nc.podInformerSynced, nc.daemonSetInformerSynced) {return
}
- 核心背景:节点控制器依赖 本地缓存(Informer Cache) 快速查询 Node、Pod、DaemonSet、Lease 等资源(避免频繁调用 API Server)。WaitForNamedCacheSync 会阻塞直到所有指定的缓存同步完成(或上下文终止)。
- 关键参数解析:
- "taint":缓存同步的名称标识(用于日志输出,便于定位);
- ctx.Done():上下文终止信号(如控制器被强制关闭,需退出阻塞);
- nc.leaseInformerSynced:Lease 资源缓存同步(Lease 用于节点心跳检测,Kubelet 定期更新节点的 Lease 资源);
- nc.nodeInformerSynced/nc.podInformerSynced:Node/Pod 资源缓存同步;
- nc.daemonSetInformerSynced:DaemonSet 资源缓存同步(DaemonSet Pod 需特殊处理,默认容忍节点污点)。
- 退出逻辑:若缓存同步失败(如上下文终止),直接返回,不启动后续工作协程,避免基于未初始化的缓存处理任务导致错误。
阶段 4:启动污点驱逐控制器(可选)
if !utilfeature.DefaultFeatureGate.Enabled(features.SeparateTaintEvictionController) {logger.Info("Starting", "controller", taintEvictionController)go nc.taintManager.Run(ctx)
}
- 核心逻辑:根据 Kubernetes 特性门控(SeparateTaintEvictionController)判断是否启动内置的污点驱逐控制器:
- 特性门控 未启用(默认情况,旧版本 Kubernetes):启动 nc.taintManager.Run(ctx),由 Node Controller 内置的污点管理器处理污点添加和 Pod 驱逐;
- 特性门控 已启用(新版本 Kubernetes,如 1.24+):污点驱逐逻辑由独立的 taint-eviction-controller 处理,Node Controller 不再启动内置污点管理器,实现 “职责解耦”。
- 作用:污点驱逐是节点故障处理的核心(如节点失联时添加 unreachable 污点,触发 Pod 驱逐),确保故障节点上的 Pod 能迁移到健康节点。
阶段 5:启动节点更新工作协程(节点调和)
// Start workers to reconcile labels and/or update NoSchedule taint for nodes.
for i := 0; i < nodeUpdateWorkerSize; i++ {// Thanks to "workqueue", each worker just need to get item from queue, because// the item is flagged when got from queue: if new event come, the new item will// be re-queued until "Done", so no more than one worker handle the same item and// no event missed.go wait.UntilWithContext(ctx, nc.doNodeProcessingPassWorker, time.Second)
}
- 核心作用:启动 nodeUpdateWorkerSize 个并行协程(默认数倍于 CPU 核心,如 4 核 CPU 启动 8 个协程),处理 nodeUpdateQueue 中的节点更新事件(如节点标签变化、污点更新)。
- 关键细节:
阶段 6:启动 Pod 更新工作协程(Pod 调和)
for i := 0; i < podUpdateWorkerSize; i++ {go wait.UntilWithContext(ctx, nc.doPodProcessingWorker, time.Second)
}
- 核心作用:启动 podUpdateWorkerSize 个并行协程,处理 podUpdateQueue 中的 Pod 更新事件(如 Pod 调度到节点、Pod 状态变化),确保 Pod 状态与节点状态一致。
- nc.doPodProcessingWorker 核心逻辑(未展示源码):
阶段 7:启动 NoExecute 污点处理协程(故障驱逐)
// Handling taint based evictions. Because we don't want a dedicated logic in TaintManager for NC-originated
// taints and we normally don't rate limit evictions caused by taints, we need to rate limit adding taints.
go wait.UntilWithContext(ctx, nc.doNoExecuteTaintingPass, scheduler.NodeEvictionPeriod)
- 核心作用:定期执行 nc.doNoExecuteTaintingPass 方法(周期为 scheduler.NodeEvictionPeriod,默认 10 秒),处理 NoExecute 类型的污点(最严格的污点,会驱逐已调度的 Pod),避免因节点故障导致的 Pod 长期不可用。
- 关键背景:
- NoExecute 污点(如 node.kubernetes.io/unreachable)会触发 Pod 驱逐,但为避免 “短时间内大量节点故障导致的集群级 Pod 驱逐风暴”,该协程会对污点添加逻辑做 速率限制(如每秒最多处理 N 个节点的污点添加);
- nc.doNoExecuteTaintingPass 会遍历所有节点,检查是否需要添加 / 移除 NoExecute 污点,确保污点状态与节点健康状态一致。
阶段 8:启动节点健康监控协程(核心健康检查)
// Incorporate the results of node health signal pushed from kubelet to master.
go wait.UntilWithContext(ctx, func(ctx context.Context) {if err := nc.monitorNodeHealth(ctx); err != nil {logger.Error(err, "Error monitoring node health")}
}, nc.nodeMonitorPeriod)
- 核心作用:按 nc.nodeMonitorPeriod(默认几秒,如 5 秒)定期执行 nc.monitorNodeHealth 方法(前序文章解析过的核心方法),实现节点健康状态的持续监控:
- 错误处理:若 monitorNodeHealth 执行失败(如缓存查询错误),仅记录错误日志,不终止协程(下一个周期会重试),确保健康监控的连续性。
1.1 doNodeProcessingPassWorker
kubernetes Node Controller(节点控制器)中 “节点更新工作协程” 的核心实现(doNodeProcessingPassWorker),负责从 nodeUpdateQueue 工作队列中读取待处理的节点任务,执行 NoSchedule 污点管理 和 节点标签调和 两大核心逻辑,是节点控制器 “异步处理节点配置变化” 的关键组件。以下从 函数职责、逐行逻辑拆解、核心子逻辑解析、设计亮点 四方面详细说明。
1. 归属与调用时机
- 归属:Controller 结构体(Node Controller 核心结构体)的方法,在 Run 方法中通过循环启动 nodeUpdateWorkerSize 个并行协程(如 8 个协程),每个协程独立执行 doNodeProcessingPassWorker;
- 核心目标:异步处理节点的 “配置变更任务”(如节点标签更新、污点需求变化),避免同步处理阻塞主流程,提升节点控制器的吞吐能力;
- 触发场景:当节点发生需要调和的事件(如节点标签被手动修改、控制平面需为节点添加 NoSchedule 污点)时,任务会被加入 nodeUpdateQueue,由该协程消费处理。
2. 关键依赖(Controller 结构体字段)

func (nc *Controller) doNodeProcessingPassWorker(ctx context.Context) {logger := klog.FromContext(ctx)// 1. 无限循环:持续从工作队列中获取任务,直到队列关闭for {// 2. 从 nodeUpdateQueue 中获取待处理的节点任务(阻塞直到有任务或队列关闭)obj, shutdown := nc.nodeUpdateQueue.Get()// 3. 若队列已关闭(如控制器退出),终止协程if shutdown {return}// 4. 将获取的任务转为节点名称(队列中存储的是节点名称字符串)nodeName := obj// 5. 执行 NoSchedule 污点调和(核心逻辑1)if err := nc.doNoScheduleTaintingPass(ctx, nodeName); err != nil {logger.Error(err, "Failed to taint NoSchedule on node, requeue it", "node", klog.KRef("", nodeName))// TODO(k82cn): Add nodeName back to the queue // 待实现:失败时将节点重新加入队列重试}// 6. 执行节点标签调和(核心逻辑2,1.19+ 版本保留的兼容逻辑)// TODO: re-evaluate whether there are any labels that need to be reconcile in 1.19. Remove this function if it's no longer necessary.if err := nc.reconcileNodeLabels(ctx, nodeName); err != nil {logger.Error(err, "Failed to reconcile labels for node, requeue it", "node", klog.KRef("", nodeName))// TODO(yujuhong): Add nodeName back to the queue // 待实现:失败时重新入队重试}// 7. 标记任务处理完成(通知队列该节点任务已处理,避免重复消费)nc.nodeUpdateQueue.Done(nodeName)}
}1.1.1 NoSchedule 污点调和(nc.doNoScheduleTaintingPass(ctx, nodeName))
Kubernetes Node Controller 中 “管理 NoSchedule 污点” 的核心方法 doNoScheduleTaintingPass,负责根据节点状态(如 NodeReady/DiskPressure 条件、是否不可调度)自动添加 / 移除 NoSchedule 类型污点(作用是 “禁止新 Pod 调度到该节点,但不影响已运行的 Pod”)。其核心逻辑是 “生成期望污点 → 对比当前污点 → 调和差异”,确保节点污点状态与实际健康 / 配置一致。以下从 函数职责、逐行逻辑拆解、核心机制、典型场景 四方面详细解析。
一、核心定位与依赖
1. 核心目标
- 基于节点状态自动生成污点:根据节点的 .status.conditions(如 DiskPressure 磁盘压力、MemoryPressure 内存压力)和 .spec.unschedulable(是否手动标记为不可调度),生成 “应有的 NoSchedule 污点”;
- 调和污点差异:对比节点当前的 NoSchedule 污点与 “期望污点”,自动添加缺失的污点、删除多余的污点,确保二者一致;
- 保障调度安全:通过 NoSchedule 污点阻止新 Pod 调度到 “不健康” 或 “维护中” 的节点,避免资源竞争或服务异常。
2. 关键依赖

二、逐行代码逻辑拆解
func (nc *Controller) doNoScheduleTaintingPass(ctx context.Context, nodeName string) error {// 1. 从本地缓存获取节点信息node, err := nc.nodeLister.Get(nodeName)if err != nil {// 若节点不存在(如已被删除),直接返回(无需处理)if apierrors.IsNotFound(err) {return nil}// 其他错误(如缓存查询失败)返回错误,触发重试return err}// 2. 步骤1:根据节点状态条件(.status.conditions)生成期望的 NoSchedule 污点var taints []v1.Taintfor _, condition := range node.Status.Conditions {// 检查该节点条件是否有对应的“污点键-状态”映射(如 DiskPressure → node.kubernetes.io/disk-pressure)if taintMap, found := nodeConditionToTaintKeyStatusMap[condition.Type]; found {// 根据条件状态(True/False/Unknown)获取对应的污点键(仅特定状态需生成污点)if taintKey, found := taintMap[condition.Status]; found {// 生成 NoSchedule 污点,添加到期望列表taints = append(taints, v1.Taint{Key: taintKey, // 污点键(如 node.kubernetes.io/disk-pressure)Effect: v1.TaintEffectNoSchedule, // 污点效果(禁止新 Pod 调度)})}}}// 3. 步骤2:若节点被标记为“不可调度”(.spec.unschedulable=true),添加 unschedulable 污点if node.Spec.Unschedulable {taints = append(taints, v1.Taint{Key: v1.TaintNodeUnschedulable, // 预定义污点键:node.kubernetes.io/unschedulableEffect: v1.TaintEffectNoSchedule,})}// 4. 步骤3:过滤节点当前的 NoSchedule 污点(仅保留与本次调和相关的污点)nodeTaints := taintutils.TaintSetFilter(node.Spec.Taints, func(t *v1.Taint) bool {// 条件1:仅保留 NoSchedule 类型的污点(排除 NoExecute/PreferNoSchedule 等其他类型)if t.Effect != v1.TaintEffectNoSchedule {return false}// 条件2:保留“不可调度污点”(v1.TaintNodeUnschedulable)或“与节点状态条件相关的污点”(如 disk-pressure)if t.Key == v1.TaintNodeUnschedulable {return true}// 检查污点键是否在“污点→节点条件”的反向映射中(即是否是由节点状态生成的污点)_, found := taintKeyToNodeConditionMap[t.Key]return found})// 5. 步骤4:计算期望污点与当前污点的差异(需添加的污点、需删除的污点)taintsToAdd, taintsToDel := taintutils.TaintSetDiff(taints, nodeTaints)// 6. 若无差异(无需添加/删除污点),直接返回成功if len(taintsToAdd) == 0 && len(taintsToDel) == 0 {return nil}// 7. 步骤5:调用 API 调和污点差异(添加缺失的、删除多余的)if !controllerutil.SwapNodeControllerTaint(ctx, nc.kubeClient, taintsToAdd, taintsToDel, node) {return fmt.Errorf("failed to swap taints of node %+v", node)}// 调和成功,返回 nilreturn nil
}
三、核心机制深度解析
1. 关键映射表:nodeConditionToTaintKeyStatusMap
var nodeConditionToTaintKeyStatusMap = map[v1.NodeConditionType]map[v1.ConditionStatus]string{// 磁盘压力:当条件状态为 True 时,生成 disk-pressure 污点v1.NodeDiskPressure: {v1.ConditionTrue: "node.kubernetes.io/disk-pressure",},// 内存压力:当条件状态为 True 时,生成 memory-pressure 污点v1.NodeMemoryPressure: {v1.ConditionTrue: "node.kubernetes.io/memory-pressure",},// PID 压力:当条件状态为 True 时,生成 pid-pressure 污点v1.NodePIDPressure: {v1.ConditionTrue: "node.kubernetes.io/pid-pressure",},// 网络不可用:当条件状态为 True 时,生成 network-unavailable 污点v1.NodeNetworkUnavailable: {v1.ConditionTrue: "node.kubernetes.io/network-unavailable",},
}
- 逻辑规则:仅当节点条件的 状态为 True(如 DiskPressure: True 表示节点确实存在磁盘压力)时,才会生成对应的 NoSchedule 污点;
- 作用:通过该映射,Node Controller 可自动将 “节点健康问题” 转化为 “调度限制”,无需人工干预。
2. 污点过滤:taintutils.TaintSetFilter
- 保留 Effect = NoSchedule 的污点(排除 NoExecute(驱逐已运行 Pod)、PreferNoSchedule(优先不调度)等其他类型);
- 保留 两类关键污点:
- node.kubernetes.io/disk-pressure:NoSchedule(相关)
- node.kubernetes.io/unschedulable:NoSchedule(相关)
- app=web:NoSchedule(用户自定义,不相关,过滤)
- node.kubernetes.io/unreachable:NoExecute(类型为 NoExecute,过滤)
3. 污点差异计算:taintutils.TaintSetDiff
- taintsToAdd:期望有但当前没有的污点(需添加);
- taintsToDel:当前有但期望没有的污点(需删除)。
- 期望污点:[disk-pressure:NoSchedule, unschedulable:NoSchedule]
- 当前污点:[unschedulable:NoSchedule, memory-pressure:NoSchedule]
- 计算结果:
- taintsToAdd:[disk-pressure:NoSchedule](期望有,当前无)
- taintsToDel:[memory-pressure:NoSchedule](当前有,期望无)
4. 污点调和执行:controllerutil.SwapNodeControllerTaint
- 生成 Patch 请求:构造 Kubernetes API 的 Patch 请求(JSON Merge Patch),描述 “添加哪些污点、删除哪些污点”;
- 处理并发冲突:若同时有其他组件(如用户手动修改)修改节点污点,导致 Patch 请求返回 Conflict(409)错误,函数会自动重试(默认重试几次),避免因并发导致调和失败;
- 事件记录:若污点调和成功,记录事件(如 “Added taint [disk-pressure:NoSchedule] to node xxx”),便于通过 kubectl describe node 追溯;
- 返回结果:调和成功返回 true,失败(如重试多次仍冲突、API Server 不可用)返回 false。
四、典型场景示例
场景 1:节点出现磁盘压力(DiskPressure: True)
- 节点 Kubelet 检测到磁盘使用率超过阈值(如 90%),将 .status.conditions[NodeDiskPressure] 设为 True;
- 任务被加入 nodeUpdateQueue,doNodeProcessingPassWorker 协程调用 doNoScheduleTaintingPass;
- 生成期望污点:根据 nodeConditionToTaintKeyStatusMap,添加 disk-pressure:NoSchedule 污点;
- 对比当前污点:若当前无该污点,taintsToAdd 包含 disk-pressure:NoSchedule;
- 执行调和:调用 API 添加该污点,新 Pod 因无法容忍该污点,不再调度到该节点。
场景 2:节点从不可调度恢复为可调度(kubectl uncordon)
- 管理员执行 kubectl uncordon ,节点的 .spec.unschedulable 设为 false;
- 协程调用 doNoScheduleTaintingPass,生成期望污点时,不再添加 unschedulable:NoSchedule 污点;
- 对比当前污点:若节点仍有该污点,taintsToDel 包含 unschedulable:NoSchedule;
- 执行调和:调用 API 删除该污点,节点恢复正常调度,新 Pod 可调度到该节点。
场景 3:节点磁盘压力消失(DiskPressure: False)
- 节点清理磁盘空间后,Kubelet 将 .status.conditions[NodeDiskPressure] 设为 False;
- 协程调用 doNoScheduleTaintingPass,生成期望污点时,不再包含 disk-pressure:NoSchedule(因映射表仅 True 状态生成污点);
- 对比当前污点:若节点仍有该污点,taintsToDel 包含 disk-pressure:NoSchedule;
- 执行调和:删除该污点,节点恢复正常调度。
总结
1.1.2 节点标签调和(nc.reconcileNodeLabels(ctx, nodeName))
Kubernetes Node Controller 中 “节点标签调和” 的核心方法 reconcileNodeLabels,负责维护节点的 “主 - 从标签(Primary-Secondary Label)一致性”—— 即确保 “从标签”(Secondary Label)的取值与 “主标签”(Primary Label)完全一致,或在需要时自动创建 “从标签”。其核心目标是解决 “标签版本兼容” 和 “外部修改导致的标签不一致” 问题,保障依赖标签的组件(如调度器、监控系统)正常工作。以下从 函数职责、逐行逻辑拆解、核心机制、典型场景 四方面详细解析。
1. 核心目标
- 标签一致性维护:针对 Kubernetes 版本迭代中引入的 “标签别名”(如 node-role.kubernetes.io/master 与 node-role.kubernetes.io/control-plane),确保 “从标签” 与 “主标签” 取值一致,避免因标签不一致导致组件功能异常;
- 自动修复标签:若 “从标签” 被误删除或修改(如人工操作、外部工具干预),自动基于 “主标签” 重建或修正 “从标签”;
- 版本兼容保障:在标签名称迭代过程中(如从 master 角色标签迁移到 control-plane 角色标签),通过调和逻辑确保新旧组件都能识别节点角色,避免兼容性问题。
1.2 doPodProcessingWorker
Kubernetes Node Controller(节点控制器)中 “处理 Pod 与节点状态关联” 的核心方法 processPod,负责根据 Pod 所在节点的 Ready 状态,动态调整 Pod 的状态(标记为NotReady)或处理污点驱逐逻辑,确保 Pod 状态与节点健康状态一致。其核心逻辑是 “节点不健康时标记 Pod 为 NotReady,避免流量调度到不可用的 Pod”,是集群自愈能力的关键环节。以下从 函数职责、逐行逻辑拆解、核心机制、典型场景 四方面详细解析。
一、核心定位与背景
1. 核心目标
- 关联 Pod 与节点健康状态:当 Pod 所在节点从 Ready 变为 NotReady/Unknown 时,自动将 Pod 标记为 NotReady(通过更新 Pod 的 .status.conditions[PodReady]),避免 Service 将流量转发到不可用的 Pod;
- 处理节点不存在场景:若 Pod 绑定的节点在缓存中不存在(如节点已被删除),跳过处理,避免无效操作;
- 失败重试保障:若标记 Pod 状态失败(如 API 冲突、网络异常),通过 podUpdateQueue 进行速率限制重试,确保最终处理成功。
2. 关键依赖

二、逐行代码逻辑拆解
// processPod 处理 Pod 与节点的关联事件,核心是根据节点 Ready 状态调整 Pod 状态
func (nc *Controller) processPod(ctx context.Context, podItem podUpdateItem) {// 1. 任务处理完成后,标记队列任务为“已处理”(无论成功/失败)defer nc.podUpdateQueue.Done(podItem)// 2. 从本地缓存获取 Pod 的最新信息(podItem 包含 Pod 的 namespace 和 name)pod, err := nc.podLister.Pods(podItem.namespace).Get(podItem.name)logger := klog.FromContext(ctx)if err != nil {// 2.1 若 Pod 不存在(如已被删除),无需处理,直接返回if apierrors.IsNotFound(err) {return}// 2.2 其他错误(如缓存查询失败),记录日志并将任务重新加入队列(速率限制重试)logger.Info("Failed to read pod", "pod", klog.KRef(podItem.namespace, podItem.name), "err", err)nc.podUpdateQueue.AddRateLimited(podItem)return}// 3. 获取 Pod 绑定的节点名称(Pod 调度后,.spec.NodeName 会被设置为目标节点名)nodeName := pod.Spec.NodeName// 4. 从节点健康缓存中获取该节点的最新健康状态(深拷贝,避免修改原缓存)nodeHealth := nc.nodeHealthMap.getDeepCopy(nodeName)if nodeHealth == nil {// 4.1 若节点健康缓存不存在(如节点刚加入、缓存未初始化或节点已删除),跳过处理return}// 5. 再次从本地缓存确认节点是否存在(双重校验,避免节点已被删除但缓存未更新)_, err = nc.nodeLister.Get(nodeName)if err != nil {// 5.1 节点不存在(如已删除),记录日志并重试(可能节点重建后需要重新处理)logger.Info("Failed to read node", "node", klog.KRef("", nodeName), "err", err)nc.podUpdateQueue.AddRateLimited(podItem)return}// 6. 从节点健康状态中提取 NodeReady 条件(核心判断依据)_, currentReadyCondition := controllerutil.GetNodeCondition(nodeHealth.status, v1.NodeReady)if currentReadyCondition == nil {// 6.1 若节点缺少 NodeReady 条件(异常场景,如节点刚创建或条件被恶意删除),跳过处理// 后续节点更新事件会重新触发处理,确保最终正确处理return}// 7. 核心逻辑:根据节点 NodeReady 状态调整 Pod 状态pods := []*v1.Pod{pod} // 封装为切片,适配 MarkPodsNotReady 函数的参数格式if currentReadyCondition.Status != v1.ConditionTrue {// 7.1 节点状态为 NotReady/Unknown → 将 Pod 标记为 NotReadyif err := controllerutil.MarkPodsNotReady(ctx, nc.kubeClient, nc.recorder, pods, nodeName); err != nil {// 7.2 标记失败(如 API 冲突、Pod 已被修改),记录日志并重试logger.Info("Unable to mark pod NotReady on node", "pod", klog.KRef(podItem.namespace, podItem.name), "node", klog.KRef("", nodeName), "err", err)nc.podUpdateQueue.AddRateLimited(podItem)}}// 7.3 节点状态为 Ready → 无需处理(Pod 状态由 Kubelet 维护为 Ready)
}
三、核心机制深度解析
1. 输入参数:podUpdateItem
type podUpdateItem struct {namespace stringname string
}
- 触发场景:当 Pod 发生以下事件时,任务会被加入 podUpdateQueue,触发 processPod 处理:
a.Pod 被调度到节点(.spec.NodeName 从空变为非空);b.Pod 所在节点的 NodeReady 状态变更(从 Ready 变为 NotReady,或反之);c.Pod 本身状态变更(如从 Pending 变为 Running)。
2. 节点健康缓存:nc.nodeHealthMap
- 更新时机:当节点状态更新(如 Kubelet 上报 NodeReady 变化)时,Node Controller 会同步更新 nodeHealthMap;
- 深拷贝获取:通过 getDeepCopy(nodeName) 获取节点健康状态,避免处理过程中修改原缓存(线程安全)。
3. 核心工具函数:controllerutil.MarkPodsNotReady
- 构造 Pod 状态更新请求:
- 调用 API 更新 Pod:通过 nc.kubeClient.CoreV1().Pods(pod.Namespace).Patch(...) 发送请求,处理可能的并发冲突(如其他组件同时修改 Pod 状态)。
- 记录事件:若更新成功,通过 nc.recorder 记录 Type: Warning、Reason: PodNotReady 的事件,描述 “Pod 因节点不健康被标记为 NotReady”,便于通过 kubectl describe pod 追溯。
- 返回结果:成功返回 nil,失败返回错误(如 API 不可用、Pod 已删除)。
4. 失败重试机制:nc.podUpdateQueue.AddRateLimited
- 速率限制:重试间隔随失败次数递增(如 1s、2s、4s... 指数退避),避免因频繁重试导致 API Server 负载过高;
- 重试上限:队列默认设置最大重试次数(如 5 次),超过后将任务加入 “死信队列”(需人工干预),避免无限重试。
四、典型场景示例
场景 1:节点从 Ready 变为 NotReady(如磁盘压力)
- 触发条件:节点因磁盘压力(DiskPressure: True)被 Kubelet 上报为 NodeReady: False,Node Controller 更新 nodeHealthMap 并将该节点上的所有 Pod 任务加入 podUpdateQueue;
- 处理流程:
- 最终效果:Service 检测到 Pod 为 NotReady,自动从 endpoints 中移除该 Pod,停止转发流量,避免请求失败。
场景 2:Pod 调度到不存在的节点(异常场景)
- 触发条件:Pod 调度后,目标节点因故障被删除(.spec.NodeName 仍为已删除的节点名),任务被加入 podUpdateQueue;
- 处理流程:
- 最终效果:若节点未重建,重试多次后任务进入死信队列;若节点重建,重试时会检测到节点状态,正常处理 Pod 状态。
场景 3:标记 Pod NotReady 失败(API 冲突)
- 触发条件:MarkPodsNotReady 调用 API 时,Pod 正被其他组件(如 kube-scheduler)修改,返回 Conflict(409)错误;
- 处理流程:
- 最终效果:重试时若冲突解除,成功标记 Pod 为 NotReady;若冲突持续,超过重试上限后进入死信队列,需人工排查冲突原因。
总结
1.3 doNoExecuteTaintingPass
Kubernetes Node Controller(节点控制器)中 管理 NoSchedule 污点 的 doNoScheduleTaintingPass 和 管理 NoExecute 污点 的 doNoExecuteTaintingPass 方法。二者均通过 “生成期望污点→对比当前污点→调和差异” 的逻辑维护节点污点状态,但针对的污点类型、触发场景和作用效果完全不同(NoSchedule 限制新 Pod 调度,NoExecute 驱逐已运行 Pod)。以下从 函数职责对比、核心逻辑拆解、关键差异分析、典型场景 四方面详细解析,帮助理解两种污点的管理机制。

一、核心职责与设计背景
1. 核心目标
- NoExecute 污点管理:当节点 NodeReady 状态为 False(明确不可用)或 Unknown(失联)时,自动添加对应的 NoExecute 污点(node.kubernetes.io/not-ready 或 node.kubernetes.io/unreachable),触发节点上 “无法容忍该污点” 的 Pod 驱逐;
- 污点互斥保障:确保 not-ready 和 unreachable 污点不会同时存在(二者互斥),避免依赖污点的组件(如 kubelet、调度器)逻辑混乱;
- 区域级速率控制:通过 “按节点所在区域(Zone)划分队列”,限制同一区域内同时处理的节点任务数量,避免大量节点故障时 Pod 集中驱逐,导致集群资源耗尽或服务中断;
- 异步安全处理:基于 RateLimitedTimedQueue 实现失败重试(如缓存查询失败、API 冲突),确保污点调和最终成功,同时避免阻塞主流程。
2. 关键依赖组件

二、逐段代码逻辑拆解
(一)第一步:安全获取所有区域的队列键(避免锁持有过久)
// 1. 定义存储区域键的切片(后续遍历区域队列用)
var zoneNoExecuteTainterKeys []string// 2. 加锁获取所有区域键(仅持有锁到获取键完成,避免后续遍历队列时长期占锁)
func() {nc.evictorLock.Lock()defer nc.evictorLock.Unlock()// 初始化切片,容量为映射长度(避免动态扩容)zoneNoExecuteTainterKeys = make([]string, 0, len(nc.zoneNoExecuteTainter))// 遍历映射,收集所有区域键(如 "cn-beijing-a"、"cn-shanghai-b")for k := range nc.zoneNoExecuteTainter {zoneNoExecuteTainterKeys = append(zoneNoExecuteTainterKeys, k)}
}()
- 核心设计:通过 “匿名函数 + 局部锁”,将锁的持有时间压缩到 “获取区域键” 这一短操作,避免后续遍历队列、处理任务时长期占用锁,导致其他协程无法修改 zoneNoExecuteTainter(如添加新区域的队列),提升并发性能。
(二)第二步:遍历每个区域,获取对应的速率限制队列
logger := klog.FromContext(ctx)
// 3. 遍历所有区域键,处理每个区域的队列任务
for _, k := range zoneNoExecuteTainterKeys {var zoneNoExecuteTainterWorker *scheduler.RateLimitedTimedQueue// 4. 再次加锁,获取当前区域对应的速率限制队列func() {nc.evictorLock.Lock()defer nc.evictorLock.Unlock()// 注释说明:区域不会被删除,因此队列也不会被删除,仅会新增,无需检查键是否存在zoneNoExecuteTainterWorker = nc.zoneNoExecuteTainter[k]}()// 5. 处理当前区域队列中的任务(核心逻辑,见下文)zoneNoExecuteTainterWorker.Try(logger, func(value scheduler.TimedValue) (bool, time.Duration) {// ... 任务处理逻辑 ...})
}
- 关键逻辑:每个区域对应一个独立的 RateLimitedTimedQueue,确保不同区域的任务处理互不干扰;再次加锁获取队列,是因为 zoneNoExecuteTainter 可能被其他协程并发修改(如新增区域队列),需通过锁保证数据一致性。
(三)第三步:处理队列中的节点任务(Try 方法与匿名函数)
1. 从缓存获取节点信息(失败重试)
// value.Value 存储的是待处理的节点名(string 类型)
node, err := nc.nodeLister.Get(value.Value)
// 情况1:节点不存在(如已被删除)→ 任务成功,无需重试
if apierrors.IsNotFound(err) {logger.Info("Node no longer present in nodeLister", "node", klog.KRef("", value.Value))return true, 0
}
// 情况2:缓存查询失败(如缓存未同步)→ 任务失败,50ms 后重试
else if err != nil {logger.Info("Failed to get Node from the nodeLister", "node", klog.KRef("", value.Value), "err", err)return false, 50 * time.Millisecond
}
- 重试策略:缓存查询失败时,选择短延迟(50ms)重试,平衡 “快速恢复” 和 “避免频繁查询压垮缓存”。
2. 检查节点 NodeReady 条件(缺失重试)
// 从节点状态中提取 NodeReady 条件(第二个返回值为条件对象,第一个为索引,此处无用)
_, condition := controllerutil.GetNodeCondition(&node.Status, v1.NodeReady)
// 若 NodeReady 条件缺失(异常场景,如节点刚创建、条件被恶意删除)→ 任务失败,50ms 后重试
if condition == nil {logger.Info("Failed to get NodeCondition from the node status", "node", klog.KRef("", value.Value))return false, 50 * time.Millisecond
}
- 合理性说明:NodeReady 是节点最核心的健康条件,正常节点必然存在该条件;缺失时重试,等待 Kubelet 上报完整状态。
3. 生成互斥的 NoExecute 污点(核心逻辑)
// 初始化“待添加污点”和“需删除的对立污点”
taintToAdd := v1.Taint{}
oppositeTaint := v1.Taint{}// 根据 NodeReady 状态,选择对应的污点(二选一,互斥)
switch condition.Status {
case v1.ConditionFalse: // 节点明确不可用(如磁盘压力、内存压力导致 NotReady)→ 添加 not-ready 污点,删除 unreachable 污点taintToAdd = *NotReadyTaintTemplateoppositeTaint = *UnreachableTaintTemplate
case v1.ConditionUnknown: // 节点失联(如网络断开,无法确认状态)→ 添加 unreachable 污点,删除 // 节点失联(如网络断开,无法确认状态)→ 添加 unreachable 污点,删除 not-ready 污点taintToAdd = *UnreachableTaintTemplateoppositeTaint = *NotReadyTaintTemplate
default: // 节点恢复 Ready(如网络恢复、压力解除)→ 无需添加污点,任务成功logger.V(4).Info("Node was in a taint queue, but it's ready now. Ignoring taint request", "node", klog.KRef("", value.Value))return true, 0
}
- 污点互斥设计:not-ready 和 unreachable 分别对应 “明确不可用” 和 “失联” 两种状态,逻辑上互斥(一个节点不可能同时 “明确不可用” 和 “失联”);通过 “添加目标污点 + 删除对立污点”,确保节点上始终只有一种(或零种)NoExecute 污点,避免组件逻辑混乱。
4. 调和污点并记录监控指标
// 调用工具函数,原子化添加目标污点、删除对立污点(返回 true 表示调和成功)
result := controllerutil.SwapNodeControllerTaint(ctx, nc.kubeClient, []*v1.Taint{&taintToAdd}, // 需添加的 NoExecute 污点[]*v1.Taint{&oppositeTaint}, // 需删除的对立污点node
)// 若调和成功,更新该区域的 Pod 驱逐计数(监控用)
if result {// 获取节点所在区域(如通过节点标签 topology.kubernetes.io/zone 解析)zone := nodetopology.GetZoneKey(node)// 按区域累加驱逐次数(Prometheus 指标,可用于 Grafana 面板监控)evictionsTotal.WithLabelValues(zone).Inc()
}// 返回调和结果:成功→true(无需重试),失败→false(队列默认重试)
return result, 0
- 原子化调和:SwapNodeControllerTaint 封装了 Kubernetes API 的 Patch 请求,确保 “添加” 和 “删除” 操作原子化(要么都成功,要么都失败),避免部分操作失败导致污点状态不一致;
- 监控价值:evictionsTotal 指标按区域统计驱逐次数,可帮助运维人员快速定位 “哪个区域节点故障集中”,及时排查问题(如某区域网络中断导致大量节点 unreachable)。
三、核心机制深度解析
1. 区域级速率限制:RateLimitedTimedQueue
- 速率限制:队列可配置 “每秒处理 N 个任务”,若同一区域内大量节点故障(如 100 个节点同时 unreachable),队列会按速率依次处理,避免 100 个节点同时添加 NoExecute 污点,导致 1000 个 Pod 集中驱逐,引发集群资源(如 CPU、内存)耗尽;
- 定时重试:任务处理失败时,队列会按返回的延迟时间(如 50ms)重新加入任务,避免立即重试导致的资源浪费;
- 任务去重:若同一节点多次被加入队列(如节点 Ready 状态反复波动),队列会合并重复任务,仅处理最新一次,避免无效操作。
2. 锁粒度控制:evictorLock 的合理使用
- 第一次加锁:仅用于 “收集区域键”,操作耗时极短,不影响其他协程修改 zoneNoExecuteTainter;
- 第二次加锁:仅用于 “获取当前区域的队列”,同样是短操作,避免后续处理任务时长期占锁;
- 设计优势:若全程持有锁,当某区域队列处理耗时较长(如 API 重试),其他区域的队列会被阻塞,导致跨区域任务处理延迟;“短持有锁” 设计最大化了并发性能。
3. 污点模板:NotReadyTaintTemplate 与 UnreachableTaintTemplate这两个全局模板定义了
// NotReadyTaintTemplate:节点不可用(NotReady)的 NoExecute 污点模板
var NotReadyTaintTemplate = &v1.Taint{Key: "node.kubernetes.io/not-ready",Effect: v1.TaintEffectNoExecute,TimeAdded: func() *metav1.Time {now := metav1.Now()return &now}(), // 动态设置污点添加时间,便于追溯
}// UnreachableTaintTemplate:节点失联(Unknown)的 NoExecute 污点模板
var UnreachableTaintTemplate = &v1.Taint{Key: "node.kubernetes.io/unreachable",Effect: v1.TaintEffectNoExecute,TimeAdded: func() *metav1.Time {now := metav1.Now()return &now}(),
}
- 标准化价值:所有节点的 NoExecute 污点格式统一,确保依赖污点的组件(如 kubelet 驱逐逻辑、调度器污点匹配)能正确识别,避免因 Key 拼写错误(如 node.not-ready)导致功能失效。
四、典型场景示例
场景 1:节点因网络断开变为 Unknown
- 触发条件:节点网络中断,Kubelet 无法向 API Server 上报状态,Node Controller 将节点 NodeReady 条件设为 Unknown,并将节点名加入其所在区域(如 cn-beijing-a)的 zoneNoExecuteTainter 队列;
- 任务处理:
- doNoExecuteTaintingPass 遍历到 cn-beijing-a 区域,获取对应的队列;
- 队列 Try 方法处理该节点任务,从缓存获取节点信息,确认 NodeReady: Unknown;
- 生成 unreachable 污点(taintToAdd)和 not-ready 对立污点(oppositeTaint);
- 调用 SwapNodeControllerTaint 添加 unreachable:NoExecute 污点,删除 not-ready 污点(若存在);
最终效果:
- 节点上 “无法容忍 unreachable 污点” 的 Pod 被 kubelet 驱逐;
- evictionsTotal{zone="cn-beijing-a"} 指标加 1,监控面板显示该区域驱逐次数增加;
- 若网络恢复,节点 NodeReady 变为 True,后续任务会忽略污点添加,Pod 可重新调度到该节点。
场景 2:节点 Ready 状态反复波动(False ↔ True)
- 触发条件:节点因临时磁盘压力变为 NodeReady: False,被加入队列;处理前压力解除,节点恢复 Ready: True;
- 任务处理:
- 队列处理该节点时,获取 NodeReady: True;
- 进入 default 分支,日志提示 “节点已恢复,忽略污点请求”,返回 true, 0;
最终效果:不添加任何污点,避免 “节点已恢复但仍被驱逐 Pod” 的误操作,保障服务稳定性。
五、常见问题与排查
1. 节点 Unknown 但未添加 unreachable 污点
- 可能原因:
a.节点所在区域的队列未被创建(如 zoneNoExecuteTainter 中无该区域键);
b.队列任务处理失败(如缓存查询失败后重试次数耗尽);
c.SwapNodeControllerTaint 调和失败(如 API Server 返回 Conflict 且重试失败)。
- 排查步骤:
a.查看 zoneNoExecuteTainter 状态:通过日志(grep "zoneNoExecuteTainter" kube-controller-manager.log)确认节点所在区域是否有队列;
b.检查任务处理日志:kubectl -n kube-system logs kube-controller-manager-master | grep -i "Failed to get Node" | grep <node-name>,查看是否有缓存失败日志;
c.验证 API 权限:确保 kube-controller-manager 的 ServiceAccount 有 nodes/update 权限(通过 kubectl describe clusterrole system:kube-controller-manager 查看)。
总结
- doNoScheduleTaintingPass:是 “节点健康状态→调度限制” 的桥梁,通过 NoSchedule 污点 “挡新不赶旧”,适合节点临时故障(如磁盘压力);
- doNoExecuteTaintingPass:是 “节点失联 / 不可用→Pod 驱逐” 的核心,通过 NoExecute 污点 “赶旧且挡新”,适合节点严重故障(如网络断开);
- 二者协同确保节点故障时 “先限制调度,再驱逐 Pod”,避免故障扩散,是 Kubernetes 集群自愈能力的关键实现。理解其差异,可帮助运维人员快速定位 “调度限制异常”“Pod 驱逐失败” 等问题,提升集群稳定性。