Linux自动化构建工具make/Makefile及Linux下的第一个程序—进度条
目录
自动化构建工具-make/Makefile
什么是make和makefile?
Makefile的编写
Makefile的自动执行规则
完整版的Makefile
Linux下的第一个程序—进度条
行缓冲区
倒计时小程序
进度条小程序
总结:
自动化构建工具-make/Makefile
什么是make和makefile?
make 是一款自动化构建工具,核心作用是根据预设规则自动执行编译、链接等步骤,快速生成项目可执行文件;Makefile 则是定义这些构建规则的配置文件,记录了文件依赖关系和具体执行命令。可以简单类比为 :make 像“厨师”,Makefile 像“菜谱”,厨师(make)会严格按照菜谱(Makefile)里写的步骤,把食材(源代码文件)做成成品(可执行程序),还能智能判断哪些食材更新过,只重新加工变化的部分,节省时间。
重要性:
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
make是一条命令,makefile是一个文件,文件内包含目标文件和原始文件的依赖关系
gcc mytest.c -o mytest
执行这条指令后,编译器会把 mytest.c 里的源代码翻译成机器能识别的指令,最终生成一个名为 mytest 的可执行程序。 -o 是“output”的缩写,用来指定编译后生成的可执行文件名称为 mytest 。你可以在终端中通过 ./mytest 来运行这个程序。mytest.c生成mytest,所以说mytest依赖于mytest.c。这就是最基本的依赖关系。
Makefile的编写
首先 , 我们要明白 : Makefile 文件需要开发者自己创建并手动写入规则。它是一个纯文本文件,你需要在其中明确指定:
- 目标文件与依赖文件的关系(依赖关系);
- 生成目标文件的具体命令(编译指令)。
创建好后,只需执行 make 命令,工具就会自动按照你写的规则完成编译流程了。
首先我们创建Makefile文件:
touch Makefile
使用vim进行该文件的编写
mytest:test.c//依赖关系gcc test.c -o mytest//必须以tab开头,依赖方法
依赖关系:mytest:test.c 表示可执行文件 mytest 依赖于源代码文件 test.c 。
编译指令:第二行以 tab 开头的 gcc test.c -o mytest 是生成 mytest 的具体编译命令。
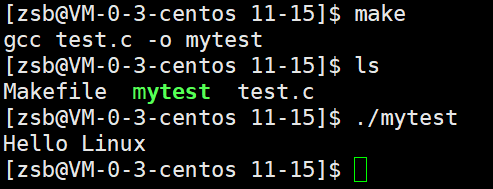
- 执行 make 命令时,工具会自动读取 Makefile 中的规则,执行 gcc test.c -o mytest 完成编译。
- 编译后通过 ls 命令可看到生成的 mytest 可执行文件,运行 ./mytest 能执行程序(如输出 Hello Linux )。
当我们使用make命令,就可以帮我们完成自动编译,那么我们想要删除生成的可执行程序呢?
.PHONY:clean
clean:rm -f mytest
代码中的 .PHONY:clean 和 clean: rm -f mytest 是用于清理生成的可执行文件的规则,执行 make clean 即可删除 mytest 。
.PHONY是什么?
定义伪目标:意思是clean总是可以执行的,伪目标的特性是,总是被执行的。
.PHONY:mytest 意思就是mytest总是可以执行的。
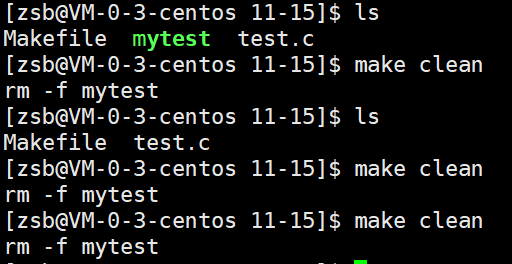
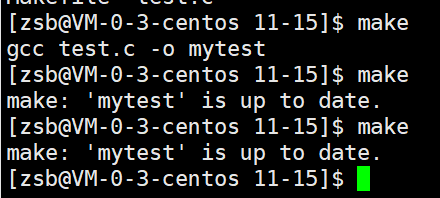
上图表示我们首先不给mytest定义伪目标,它只能执行一次:
- 未定义伪目标时:第一次执行 make 会编译生成 mytest ,但后续再执行 make ,会提示 'mytest' is up to date (因为 make 认为可执行文件已经是最新的,不会重复编译)。
- 定义伪目标后:每次执行 make 都会强制重新编译 mytest ,确保编译逻辑“总是执行”。
给 mytest 定义伪目标的方法 , 在 Makefile 中添加以下内容即可:
.PHONY: mytest # 声明mytest为伪目标
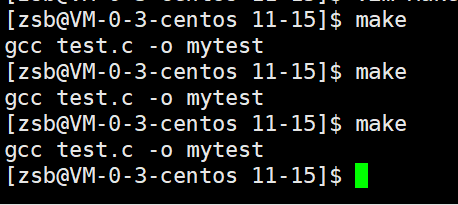
mytest: test.cgcc test.c -o mytest这样定义后,无论 mytest 可执行文件是否存在,每次执行 make mytest 都会强制执行 gcc test.c -o mytest 这条编译命令。
我们给mytest也定义为伪目标,就可以总是可以执行的:
Makefile的自动执行规则
make clean
make 命令默认执行 Makefile 中第一个可执行的目标。比如你输入 make ,它会自动找文件里第一个可执行的编译规则来执行(比如生成 mytest 的规则)。如果要执行其他目标(如清理操作),需要明确写 make clean 。
在写依赖方法时,我们也可以这样写:
gcc $^ -o $@
- $^ :代表所有依赖文件(比如 test.o 这类被依赖的文件)。
- $@ :代表目标文件(比如 mytest 这个最终要生成的可执行文件)。
用 gcc $^ -o $@ 可以简化编译命令,让规则更通用。
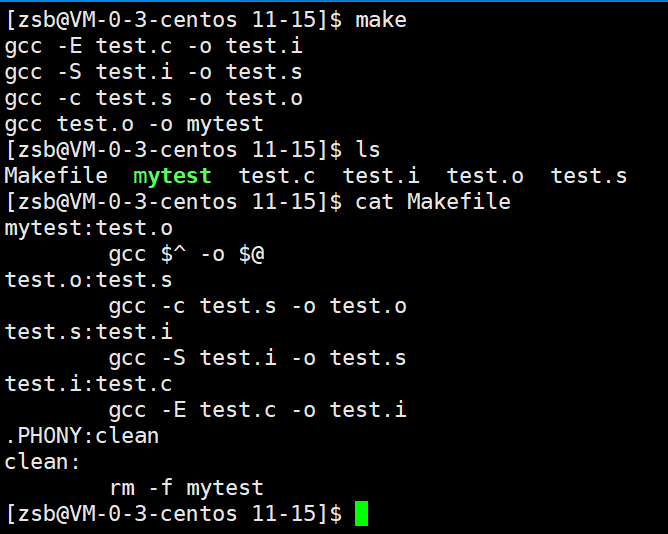
我们在Makefile中这样写:
mytest:test.ogcc $^ -o $@
test.o:test.sgcc -c test.s -o test.o
test.s:test.igcc -S test.i -o test.s
test.i:test.cgcc -E test.c -o test.i
上述代码是 gcc 编译的“递归/分解”流程(编译链), 从 test.c 到 mytest ,编译过程被分解成了多步(每一步生成中间文件):
1. test.c → test.i :用 gcc -E test.c -o test.i 做预处理(展开宏、处理头文件等)。
2. test.i → test.s :用 gcc -S test.i -o test.s 生成汇编代码。
3. test.s → test.o :用 gcc -c test.s -o test.o 生成目标文件(二进制格式)。
4. test.o → mytest :用 gcc $^ -o $@ 把目标文件链接成可执行程序。
这样的分解能让编译过程更清晰,也方便调试每一步的问题。
使用make命令,可以看到编译时是倒过来编译的,像一个递归似的编译:
同时编译多个可执行文件
总结:
gcc test.c -o mytest 这条命令,本质上等价于 Makefile 里那四步(预处理→汇编→目标文件→链接)的“合并执行版”。gcc 会在后台自动完成所有中间步骤:先对 test.c 做预处理生成 test.i (但不保留该文件),再生成 test.s (也不保留)、 test.o (临时保留后自动删除),最后直接链接出 mytest 可执行文件,相当于把四步流程“一键打包”,省略了手动生成和管理中间文件的过程。而 Makefile 里拆分四步,核心是能清晰看到每一步的输出(比如保留 test.s 查看汇编代码),也方便单独调试某一步(比如只做预处理看 test.i ),两者最终目的都是生成 mytest ,只是前者简洁、后者透明。
完整版的Makefile
# 定义伪目标,确保clean总是执行
.PHONY: all clean# 第一个目标,默认执行all时会编译生成mytest
all: mytest# 可执行文件mytest依赖test.o,用自动化变量简化编译命令
mytest: test.ogcc $^ -o $@# 目标文件test.o依赖test.s
test.o: test.sgcc -c $^ -o $@# 汇编文件test.s依赖test.i
test.s: test.igcc -S $^ -o $@# 预处理文件test.i依赖test.c
test.i: test.cgcc -E $^ -o $@# 清理规则:删除生成的可执行文件和中间文件
clean:rm -f mytest test.o test.s test.i
- 编译流程:从 test.c 开始,依次生成 test.i (预处理)、 test.s (汇编)、 test.o (目标文件),最终链接成 mytest 。
- 自动化变量: $^ 表示所有依赖文件, $@ 表示目标文件,简化了每一步的编译命令。
- 伪目标: all 和 clean 都通过 .PHONY 声明,确保 make all 始终执行编译, make clean 始终执行清理。
- 执行方式:直接输入 make 会默认执行 all 目标完成编译;输入 make clean 会删除所有生成的文件。
Linux下的第一个程序—进度条
行缓冲区
首先我们来看下面这段代码:
#include"mytest.h"
#include<unistd.h>
int main()
{printf("hello world\n");sleep(5);return 0;
}
这样我们运行可执行程序时是立即打印出来hello world,然后睡眠5秒

但是把\n去掉,会是什么样子呢?

我们看到先sleep5秒才打印出来,那么是sleep先执行的吗?答案是并不是的,在执行sleep时,printf已经执行完了,printf执行完但是并不代表字符串就得显示出来,那么在sleep期间,字符串在哪里?答案是在缓冲区,缓冲区本质就是一段内存空间,暂时存储实时数据,再合适的时候刷新出去
缓冲区的刷新策略:
1. 直接刷新,不缓冲:
- 数据不经过缓冲区暂存,产生后直接输出。
2. 全缓冲(缓冲区写满才刷新):
- 只有当缓冲区被数据“写满”时,才会把所有数据一次性输出。
3. 行刷新(碰到 \n 就刷新):
- 当输出数据中遇到换行符 \n 时,就会立刻刷新缓冲区,把数据输出。这是往显示器输出的常见策略(比如 printf 打印到终端时),因为用户希望“一行内容输完就看到结果”。
4. 强制刷新:
- 不管缓冲区有没有满、有没有 \n ,通过手动调用函数(比如 C 语言中的 fflush(stdout) ),强制把缓冲区里的内容立刻输出。
所以如果想让最后的 printf 立刻显示,有两种常见做法:
加 \n : printf("hello\n"); (触发“行刷新”)。
强制刷新: printf("hello"); fflush(stdout); (手动调用 fflush 刷缓冲区)。
#include"mytest.h"
#include<unistd.h>
int main()
{printf("hello world");fflush(stdout);sleep(5);return 0;
}
刷新的意思:把数据真正的写入磁盘、显示器、网络等设备或者文件
C程序默认I/O流:
任何一个C程序,启动的时候,会默认打开三个输入输出流(文件)
- stdin :对应键盘,用于输入数据。
- stdout :对应显示器,用于标准输出(如 printf 的结果)。
- stderr :对应显示器,用于错误输出(优先级更高,通常直接刷新)。
回车、换行、回车换行的区别
| 操作 | 含义 | C语言表示 |
| 回车 | 回到当前行的起始位置,光标不换行 | \r |
| 换行 | 另起一行,光标不一定在行首 | \n |
| 回车并换行 | 另起一行且光标在行首 | \n\r (C语言中 \n 实际是回车并换行 |
倒计时小程序
我们掌握上面的知识来写一个倒计时小程序:
int main()
{int count = 9;while(count>=0){printf("%d\r",count);fflush(stdout);count--;sleep(1);}return 0;
}
这段代码实现从 9 到 0 的倒计时,每秒显示一个数字,且所有数字在同一行的起始位置依次刷新显示(不会换行,而是用新数字覆盖旧数字)。

那如果将count改为10呢?

这时出现了问题,为什么呢?
- 当原有逻辑( count = 9 时),count 从 9 到 0 ,所有数字都是1位( 9 、 8 、 7 ... 0 ) , printf("%d\r", count); 中, \r 会把光标移到行首,下一个数字(同样1位)会完全覆盖上一个数字,所以屏幕上始终只显示“当前倒计时的1位数字”。
- 但是当count = 10 时 , count 从 10 开始,10 是2位数字;后续递减到 9 及以下时,又变成1位数字。当显示 10 时, printf 输出“ 10 ”(占2个字符位置);下一次循环显示 9 时, printf 输出“ 9 ”(占1个字符位置)。由于 \r 只是把光标移到行首,但不会“清除原有内容”,所以“ 9 ”只会覆盖“ 10 ”的第1位(1),而第2位(0)会残留下来,导致屏幕显示变成“ 90 ”(实际想显示 9 ,但残留了上一次的 0)。
- 我们首先要明白 , 往显示器上打印的并不是数字,而是一个一个的字符,所以在count大于一位数的时候就会出现这样的问题。
那应该如何解决呢?
如果要让 count 从 10 开始也能“完美覆盖”,可以固定输出位数,让10(2位)和9(1位)都占相同宽度。例如:
printf("%2d\r", count); // 用%2d,让数字占2个字符宽度(不足则补空格)- 当输出 10 时,显示 10 (占2位)。
- 当输出 9 时,显示 9 (占2位,前面补1个空格)。
- 这样每次输出都占2位, \r 移到行首后,新的2位数字会完全覆盖上一次的2位内容,就不会有残留了。

进度条小程序
procbar.c文件:
#include<stdio.h>
#include<string.h>
#inclkude<unistd.h>
#define NUM 100
int main()
{char bar[NUM+1];memset(bar,0,sizeof(bar));//首先将该数组初始化为NULLconst char* lable = "|/-\\";//加载标志,g转圈圈int i=0;while(i<=NUM){bar[i] = '#';printf("[%-101s][%d%%][%c]\r",bar,i,label[i%4]);fflush(stdout);usleep(100000);i++;}printf("\n");return 0;
}
这是我们用 C 语言实现的命令行进度条小程序,核心是通过字符数组动态构建进度条、 \r 回车符实现同一行刷新,以及加载动画标识来增强交互感。
- 进度条数组 bar :用长度为 NUM+1 (这里 NUM=100 )的字符数组存储进度条的 # 符号,每循环一次就添加一个 # ,模拟进度增长。
- 加载动画 label :字符串 "|/-\" 定义了4种加载状态(循环显示),通过 i%4 实现“转圈圈”的动态效果。
- \r 回车符与 fflush : printf 中用 \r 将光标移到行首,结合 fflush(stdout) 强制刷新缓冲区,实现“同一行实时更新进度条”的视觉效果。
1. 初始化:用 memset 将 bar 数组初始化为空,定义加载动画 label 和循环变量 i 。
2. 循环构建进度条:
- - bar[i] = '#' :每轮循环给进度条添加一个 # ,表示进度推进。
- - printf("[%-101s][%d%%][%c]\r", bar, i, label[i%4]) :
- - %-101s :让 bar 占101个字符宽度(左对齐),确保进度条长度固定。
- - %d%% :显示当前进度百分比( i 从0到100)。
- - %c :显示加载动画的当前状态( i%4 循环取 label 的4个字符)。
- - \r :光标移到行首,实现“覆盖式刷新”。
- - fflush(stdout) :强制输出缓冲区内容,保证进度条实时显示。
- - usleep(100000) :休眠100毫秒(模拟任务执行时间),让进度变化更直观。
3. 结束换行:进度完成后用 printf("\n") 换行,避免后续输出与进度条重叠。
进度条程序效果演示:

运行程序后,终端会显示一个从0%到100%的进度条,进度条由 # 填充,右侧有“转圈圈”的加载动画( | / - \ 循环切换),所有更新都在同一行完成,最终呈现“动态进度条+加载动画”的交互效果。
总结:
本文介绍了自动化构建工具make和Makefile的基本概念与使用方法。make是自动化构建工具,Makefile是定义构建规则的配置文件,二者配合可实现高效的项目编译。文章详细讲解了Makefile的编写规则,包括依赖关系、伪目标(.PHONY)和自动化变量($^, $@)的使用。同时通过实例演示了从源代码到可执行文件的完整编译过程,并介绍了Linux下进度条程序的实现原理,重点讲解了缓冲区刷新策略和\r回车符的使用技巧。最后展示了一个带动态加载动画的进度条小程序实现,体现了Linux环境下程序开发的实用技巧。