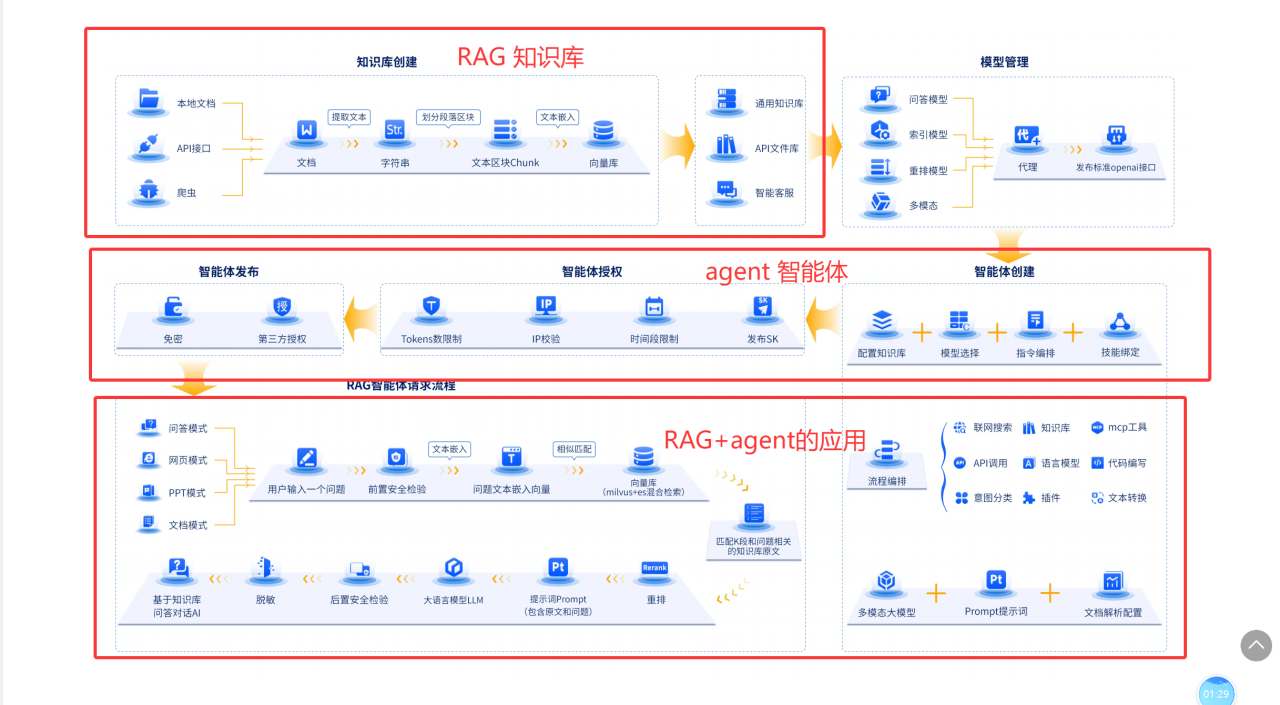
智能体大模型基础入门(RAG难点图片详细讲解)
根据RAG的一些难点,我们对其进行详细的解释

了解市面上的各种ai大模型:豆包,kimi,通义千问,文心一言,Deepseek,ChatGPT,Grok
大模型是指拥有数十亿甚至数千亿参数的机器学习模型,具有以下显著特点:
参数数量巨大:大模型通常拥有数十亿甚至数千亿的参数,如 OpenAI 的 GPT-3 有 1750 亿个参数,相比早期的语言模型 GPT-1 的 1.5 亿个参数,数量大幅增加。如此庞大的参数数量,使大模型能够学习到更加细致和复杂的数据特征,捕捉到更加细微的语义关系和上下文信息。
学习能力强大:大模型能从海量训练数据中提取复杂特征,在自然语言处理、计算机视觉、语音识别等多个领域表现出色。例如 BERT 在多项 NLP 基准测试中超越人类水平,OpenAI 的 DALL-E 2 可以根据文本描述生成高度逼真的图像,展现出跨模态的强大学习能力。
泛化能力强:大模型在未见过的数据上也能有较好表现,可应用于各种场景,具有很强的通用性。如 GPT-3 可以胜任文本生成、问答、代码编写等多种任务,无需针对每个特定任务进行单独训练。
深层网络结构:大模型往往包含多个隐层,这些层次可以提取从低级到高级的特征表示,通过多层的特征变换和组合,能够更好地理解和处理复杂的数据模式。
预训练与微调机制:大模型通常先在大规模无标签数据上进行预训练,学习通用特征,然后在特定任务上进行微调,以适应特定应用。这种方式既提高了模型的训练效率,又能使模型在具体任务上取得更好的性能。
上下文学习能力:大模型通过少量示例或直接指令即可快速适应新任务,无需重新训练模型。例如用户输入 “用莎士比亚风格写一封情书”,大语言模型可直接生成符合要求的文本,展现出了强大的上下文学习能力。
涌现能力:随着模型规模的增长,大模型会展现出一些小模型不具备的能力,如对复杂语境的理解、创造性思维和多步推理等。这些涌现能力是当模型达到一定规模后突然获得的,难以事先预测。
计算资源需求大:训练大模型需要大量的高性能 GPU/TPU 等硬件以及大量的存储空间,成本高昂。例如 GPT-3 的训练需要消耗数百万美元的计算资源,这也使得只有少数科技公司和研究机构有能力开发大模型。
数据需求量大:大模型需要海量的训练数据来避免过拟合,并充分发挥其性能。如 GPT-3 的训练数据包括网页、书籍、维基百科等海量文本信息,数据的收集和标注需要投入大量的人力和财力。

RAG:检索增强生成(Retrieval-Augmented Generation)详解
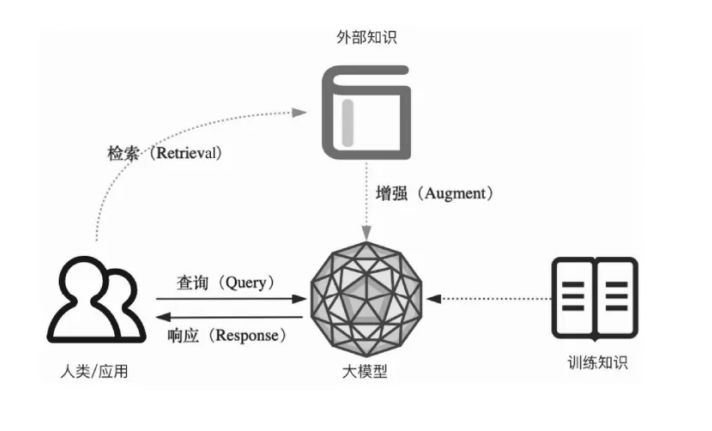
RAG 是一种结合检索系统与生成式大模型的技术框架,核心目标是解决生成式大模型 “知识过时、事实错误、逻辑偏移” 等问题,让生成内容更精准、更具时效性、更贴合特定领域需求。
一、RAG 的核心原理:“先检索,再生成”
RAG 的本质是为生成式大模型 “配备外部知识库”,通过 “检索 - 增强 - 生成” 三步流程,让模型不再仅依赖训练时的 “内部记忆”,而是结合实时 / 特定的外部信息输出结果。具体流程如下:
用户提问与检索触发
用户输入问题(如 “2024 年中国新能源汽车销量 TOP3 品牌是哪些?”),系统先分析问题核心需求(“2024 年”“中国新能源”“销量 TOP3”),确定需要调用外部最新数据,而非依赖大模型固有知识(大模型训练数据可能截止到 2023 年,无法覆盖 2024 年数据)。外部知识库检索
系统根据问题关键词,从预设的 “外部知识库” 中快速匹配相关信息。
外部知识库来源:可以是实时数据库(如行业统计平台数据)、特定领域文档(如企业内部手册、医学论文)、网页信息(如权威媒体报道)等;
检索技术:通常基于 “向量数据库” 实现 —— 先将知识库中的文本转化为 “向量”(捕捉语义特征),再将用户问题也转化为向量,通过 “向量相似度计算”,快速找到与问题最相关的文本片段(称为 “检索结果” 或 “上下文片段”)。
生成式大模型增强输出
系统将 “用户问题 + 检索到的相关上下文” 一同输入生成式大模型(如 GPT-4、LLaMA 等),模型结合外部上下文信息,生成符合事实、逻辑严谨的回答,而非仅依赖自身训练数据 “凭空生成”。
例:模型会基于检索到的 “2024 年中国新能源汽车销量数据”,准确输出 “比亚迪、特斯拉、理想”(假设为真实数据),而非推测过时的 2023 年排名。
二、RAG 与传统生成式大模型的核心差异
传统生成式大模型(如未接入 RAG 的 GPT-3.5)仅依赖训练时的 “内部知识”,而 RAG 通过 “外部检索 + 内部生成” 的结合,弥补了传统模型的关键短板。两者对比如下:
对比维度 | 传统生成式大模型 | RAG(检索增强生成) |
知识来源 | 模型训练时的静态数据(有截止日期) | 动态更新的外部知识库(实时 / 特定领域) |
事实准确性 | 易出现 “幻觉”(虚构事实)、知识过时 | 基于检索到的真实信息,准确性大幅提升 |
领域适配性 | 通用领域表现好,垂直领域(如医学、法律)能力弱 | 可接入垂直领域知识库(如医院病历库、法律条文),适配性强 |
知识更新成本 | 需重新训练模型(成本极高,周期长) | 仅需更新外部知识库(成本低,实时性强) |
输出可解释性 | 难以追溯回答来源(“黑箱” 特性) | 可关联检索到的上下文片段,回答可溯源 |
三、RAG 的关键组成部分
一个完整的 RAG 系统通常由 4 个核心模块构成,各模块协同实现 “检索 - 生成” 流程:
1. 数据预处理与知识库构建(离线阶段)
数据收集:获取目标领域的原始数据(如文档、表格、网页、数据库等);
数据清洗与拆分:去除冗余、错误数据,将长文本拆分为短片段(如每 200-500 字一个片段,便于后续精准检索);
向量转化与存储:通过 “嵌入模型”(如 OpenAI 的 text-embedding-3-small、开源的 Sentence-BERT)将文本片段转化为向量,存储到 “向量数据库”(如 Pinecone、Milvus、Chroma)中 —— 向量数据库的核心作用是高效实现 “相似性检索”,比传统数据库(如 MySQL)的文本匹配速度快 10-100 倍。
2. 检索模块(在线阶段)
问题理解与转化:将用户问题转化为向量(与知识库文本向量格式一致);
相似性检索:在向量数据库中快速筛选出与问题向量 “相似度最高” 的 Top N 个文本片段(如 Top 5),作为 “相关上下文”;
上下文过滤与排序:去除重复、低相关性的片段,按相关性权重排序,确保输入模型的信息质量。
3. 生成模块(在线阶段)
提示词(Prompt)构造:将 “用户问题 + 排序后的相关上下文” 整合成结构化提示词(如 “基于以下信息回答问题:[上下文] 问题:[用户问题]”),引导模型聚焦外部信息;
大模型调用:将构造好的提示词输入生成式大模型(可选择开源模型如 LLaMA 3、Qwen,或闭源 API 如 GPT-4),模型基于上下文生成回答;
输出优化:可选步骤(如过滤敏感信息、调整回答格式、补充引用来源),提升回答可用性。
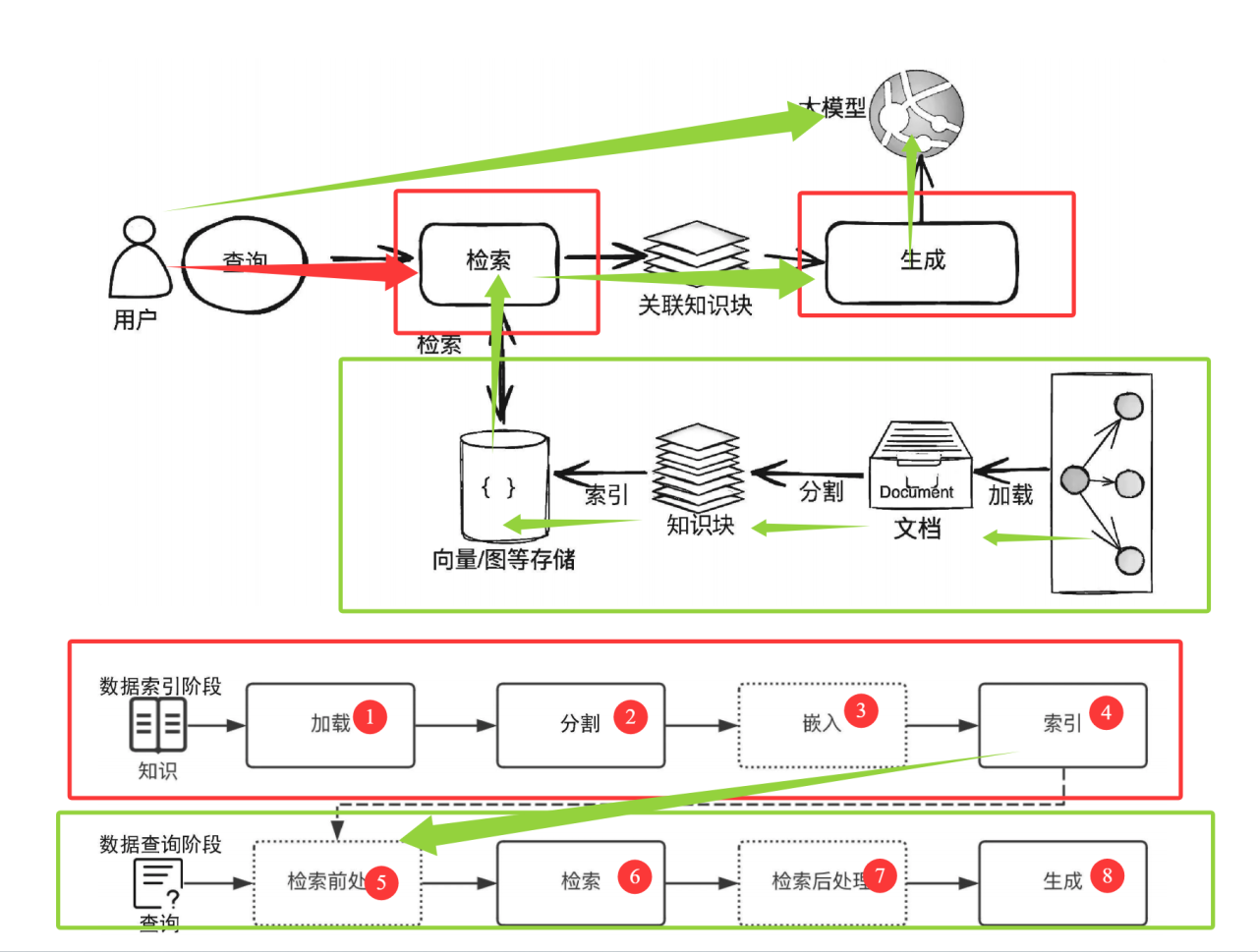
这张图展示了检索增强生成(RAG)系统的完整工作流程,分为数据索引阶段(离线构建知识库)和数据查询阶段(在线响应用户请求)两大部分,核心是 “先从外部知识库检索相关信息,再结合大模型生成精准回答”。
一、数据索引阶段(红色框,离线准备知识库)
这一阶段的目标是将原始知识(文档、文本等)转化为 “可高效检索” 的格式,存储到向量 / 图数据库中,为后续用户查询做准备。流程分为 4 步:
加载(Load):
将原始知识(如企业文档、学术论文、网页内容等)导入系统。这一步是知识的 “原材料输入”,把分散的信息聚合到系统中。分割(Split):
由于原始文档可能很长(如万字报告),直接处理会导致语义模糊或检索效率低,因此需要将长文档拆分为短知识块(如每 200 - 500 字为一个片段)。分割需兼顾 “语义完整性”(不破坏句子 / 段落逻辑)和 “检索颗粒度”(片段大小适中,便于后续匹配)。嵌入(Embed,虚线框,可选但关键):
用嵌入模型(如 OpenAI 的 text-embedding、开源的 Sentence-BERT)将每个知识块转化为向量(一组数字,捕捉文本的语义特征)。向量的作用是:让 “语义相似的文本” 在向量空间中距离更近,为后续 “相似性检索” 提供数学基础。索引(Index):
将 “知识块 + 对应的向量” 存储到向量数据库(如 Pinecone、Milvus)或图数据库中,并建立索引结构。索引能让后续检索时,快速找到与用户问题 “语义最相似” 的知识块,而非暴力遍历所有数据,大幅提升检索效率。
二、数据查询阶段(绿色框,在线响应用户)
当用户发起查询时,系统通过以下流程,结合 “检索到的外部知识” 和 “大模型” 生成回答,核心是 “用外部知识增强大模型的生成准确性”。流程分为 4 步(对应图中 5 - 8):
检索前处理(Pre-Retrieval):
对用户的查询(如 “2024 年新能源汽车销量 Top3”)进行预处理,包括:
关键词提取(如 “2024”“新能源汽车”“销量 Top3”);
语义理解(明确用户需求是 “最新排名”);
转化为向量(与索引阶段的嵌入模型一致,让问题也变成向量,便于和知识块向量做相似性计算)。
检索(Retrieval):
在向量数据库中,通过向量相似度计算(如余弦相似度),找到与 “用户问题向量” 最相似的 Top N 个知识块(如最相关的 3 - 5 个片段)。这些知识块就是 “能回答用户问题的外部依据”。检索后处理(Post-Retrieval):
对检索到的知识块进行过滤与优化,包括:
去重(删除重复的知识块);
排序(按相似度从高到低排列);
格式整理(让知识块更易被大模型理解,如添加分隔符)。
生成(Generate):
将 “用户查询 + 处理后的知识块” 一起输入大模型(如 GPT-4、LLaMA)。大模型结合 “自身训练的通用知识” 和 “检索到的特定外部知识”,生成最终回答。例如,大模型会用检索到的 “2024 年新能源汽车销量数据”,生成准确的 “Top3 品牌及销量”,而非依赖自身可能过时的训练数据。
三、整体流程的可视化(图中箭头与模块的关联)
顶部的 “用户→检索→生成→大模型”:是数据查询阶段的简化流程,展示用户查询如何触发检索,再结合大模型生成结果。
中间的 “文档→分割→知识块→向量 / 图存储”:是数据索引阶段的核心链路,展示原始文档如何被处理为可检索的向量。
底部的 “知识→加载→分割→嵌入→索引” 和 “查询→检索前处理→检索→检索后处理→生成”:是对 “数据索引” 和 “数据查询” 阶段的详细步骤拆解,让流程更清晰。
核心价值总结
这张图清晰展现了 RAG 的核心逻辑:用 “外部知识库 + 检索” 解决大模型 “知识过时、事实错误” 的问题,让大模型能结合实时 / 特定领域的信息,生成更精准、更具时效性的回答。