[论文阅读] AI+软件工程(需求工程)| 告别需求混乱!AI-native时代,需求工程的5大痛点与3大破局方向
告别需求混乱!AI-native时代,需求工程的5大痛点与3大破局方向
论文信息
- 论文原标题:Reconsidering Requirements Engineering: Human–AI Collaboration in AI-Native Software Development
- 主要作者及研究机构:于韦斯屈莱大学 Mateen Ahmed Abbasi1, Petri Ihantola1, Tommi Mikkonen1, and Niko M¨akitalo1
- 论文链接:https://arxiv.org/pdf/2510.04380
arXiv:2510.04380
Reconsidering Requirements Engineering: Human-AI Collaboration in AI-Native Software Development
Mateen Ahmed Abbasi, Petri Ihantola, Tommi Mikkonen, Niko Mäkitalo
Comments: Accepted at SEAA 2025. Appearing in Springer LNCS 16081, pages 164-180
Journal-ref: In: SEAA 2025 proceedings, LNCS vol. 16081, Springer
Subjects: Software Engineering (cs.SE); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC)
一段话总结
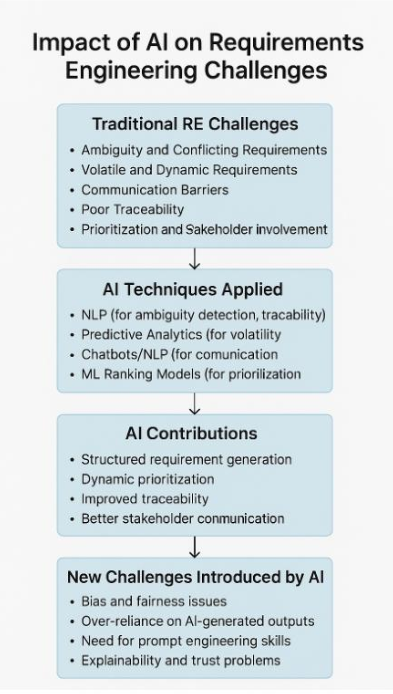
该论文通过三阶段结构化文献综述,重新审视了需求工程(RE)这一软件开发基石领域。首先提炼出传统RE面临的歧义冲突需求、动态易变需求、沟通障碍、可追溯性差、优先级与 stakeholder 参与不足五大核心挑战;接着分析了AI技术(NLP、ML、LLMs等)在缓解这些挑战中的作用,同时揭示了数据偏见、决策黑箱、伦理问责缺失等新问题;最终提出以检索增强生成(RAG)、预训练模型微调、强化学习(RL)为核心的未来研究方向,并强调AI应作为RE的“增强工具”而非“人类替代者”,需通过产学协作构建可信实用的AI-RE解决方案。
思维导图
研究背景:需求工程的“老难题”遇上AI的“新机遇”
需求工程(RE)就像软件开发的“施工图设计”——要把用户、产品经理、开发团队等各方(stakeholder)的需求,转化为清晰、可执行的开发依据。但这个“设计过程”长期被五大“老难题”困扰:
比如你开发一款电商APP,歧义冲突需求可能出现:运营说“要提升用户粘性”,技术团队理解成“加签到功能”,但用户真正想要的是“个性化推荐”;动态易变需求更常见,上线前突然要求接入“直播带货”模块,整个开发计划被打乱;跨团队协作时,沟通障碍可能让“分布式仓库”需求被误译为“主仓库”;开发后期想验证“数据加密”需求是否实现,却因可追溯性差找不到对应代码;最后,营销、技术、客服各部门需求打架,优先级排序全凭主观经验……
这些问题轻则导致返工延期,重则让产品脱离用户需求,项目直接失败。而AI技术的崛起,就像给RE装上了“智能工具箱”——NLP能自动识别需求歧义,LLMs能把会议记录转成结构化需求,ML能预测需求变化。但AI不是“万能药”:训练数据里的偏见可能让AI优先“性能需求”而忽略“易用性”,决策过程像“黑箱”一样说不清为什么这么排序……于是,论文团队决定系统探究:AI到底能帮RE解决什么问题?又会带来哪些新麻烦?
创新点:跳出“技术崇拜”,聚焦“人类-AI协作”的平衡
这篇论文的最大亮点,在于它没有陷入“AI无所不能”的技术崇拜,而是从“问题-解决方案-新问题”的闭环视角展开研究:
- 方法论创新:采用“三阶段结构化综述”,先明确传统RE的痛点(阶段I),再梳理AI应用现状(阶段II),最后针对性评估AI的影响(阶段III),避免了“为谈AI而谈AI”的空泛,让研究结论更落地。
- 视角创新:首次系统归纳了AI对RE五大挑战的“双重影响”——既讲NLP如何解决沟通障碍,也不回避AI翻译丢失文化语境的问题;既肯定ML优化需求排序的效率,也指出其“偏向数据充分者”的公平性隐患。
- 落地性创新:提出的三大技术方向(RAG、预训练微调、RL)不是空中楼阁——比如RAG能检索历史项目需求减少歧义,RL能通过用户反馈动态调整优先级,直接指向工业界的实际需求。
研究方法和思路:三阶段拆解,让结论有理有据
论文的研究方法像“剥洋葱”,层层递进地剖析AI与RE的关系,具体分为三个阶段:
阶段I:摸清传统RE的“家底”——五大挑战从哪来?
- 核心任务:从Google Scholar和Scopus数据库,用“requirements engineering challenges”等关键词检索文献,优先选择同行评审的高质量论文。
- 关键步骤:先看标题和摘要筛选,再读全文做定性编码,把提到的挑战分类分组,直到“主题饱和”(再也没有新的挑战类别出现)。
- 成果:分析了35篇论文,最终提炼出“歧义与冲突需求、动态易变需求、沟通障碍、可追溯性差、优先级与stakeholder参与不足”五大核心挑战。
阶段II:盘点AI的“工具箱”——AI在RE里能做什么?
- 核心任务:聚焦Google Scholar(因为能覆盖最新预印本),用“AI in Requirements Engineering”等关键词检索,梳理AI技术在RE中的应用场景。
- 关键步骤:先拿到136个初始结果,去重后通过引用分析和全文评估筛选,同时补充RE领域的开创性论文,确保覆盖全面。
- 成果:形成了AI-RE应用的“精选集合”,涵盖NLP(需求提取)、ML(需求预测)、LLMs(对话代理)等技术的具体用法。
阶段III:评估AI的“功与过”——到底是帮手还是麻烦?
- 核心任务:针对阶段I的五大挑战,从“准确性与可靠性、可扩展性、透明度与可解释性、伦理考量”四个维度,评估AI的解决效果和新问题。
- 关键步骤:把阶段I的挑战和阶段II的AI应用一一对应,分析“AI能解决什么”和“AI会带来什么新问题”。
- 成果:明确了每个挑战的AI解决方案及风险,比如“动态易变需求”可用ML预测,但会因历史数据过时导致偏差。
主要成果和贡献:给RE领域的“干货清单”
论文的核心成果不是空谈理论,而是给学术界和工业界提供了“看得见、用得上”的价值,具体可归纳为以下3点:
1. 一张“挑战-AI影响”对应表(清晰版)
| 传统RE挑战 | AI解决方式 | AI新问题 |
|---|---|---|
| 歧义冲突需求 | NLP检测模糊表述,LLMs转结构化需求 | 数据偏见,提示设计依赖 |
| 动态易变需求 | ML预测需求变化 | 过拟合历史数据,难捕新需求 |
| 沟通障碍 | AI翻译/聊天机器人澄清需求 | 文化语境丢失,术语误解 |
| 可追溯性差 | 深度学习自动化工件链接 | 链接错误,AI自身追溯缺失 |
| 优先级与参与 | ML优化排序,识别关键stakeholder | 决策黑箱,偏向数据充分者 |
2. 三大落地性技术方向
- 检索增强生成(RAG):让AI先检索历史项目的需求文档,再生成新需求,减少歧义(比如开发电商APP时,自动参考同类项目的“个性化推荐”需求描述)。
- 预训练模型微调:用RE领域的数据(如合规需求文档)微调GPT、BERT等模型,提升对“非功能需求”“合规性”等专业术语的理解。
- 强化学习(RL):让AI通过“奖励/惩罚”学习调整需求优先级——比如用户对“直播功能”反馈好就加分,成本超支就减分,动态适配变化。
3. 一个核心结论:AI是“增强者”,不是“替代者”
论文明确反对“用AI取代人类决策”,强调RE的核心是“理解人的需求”,AI只能做“高强度、重复性工作”(如需求分类、链接追溯),而stakeholder的需求权衡、伦理判断等“人性化决策”,必须由人类主导。
详细总结
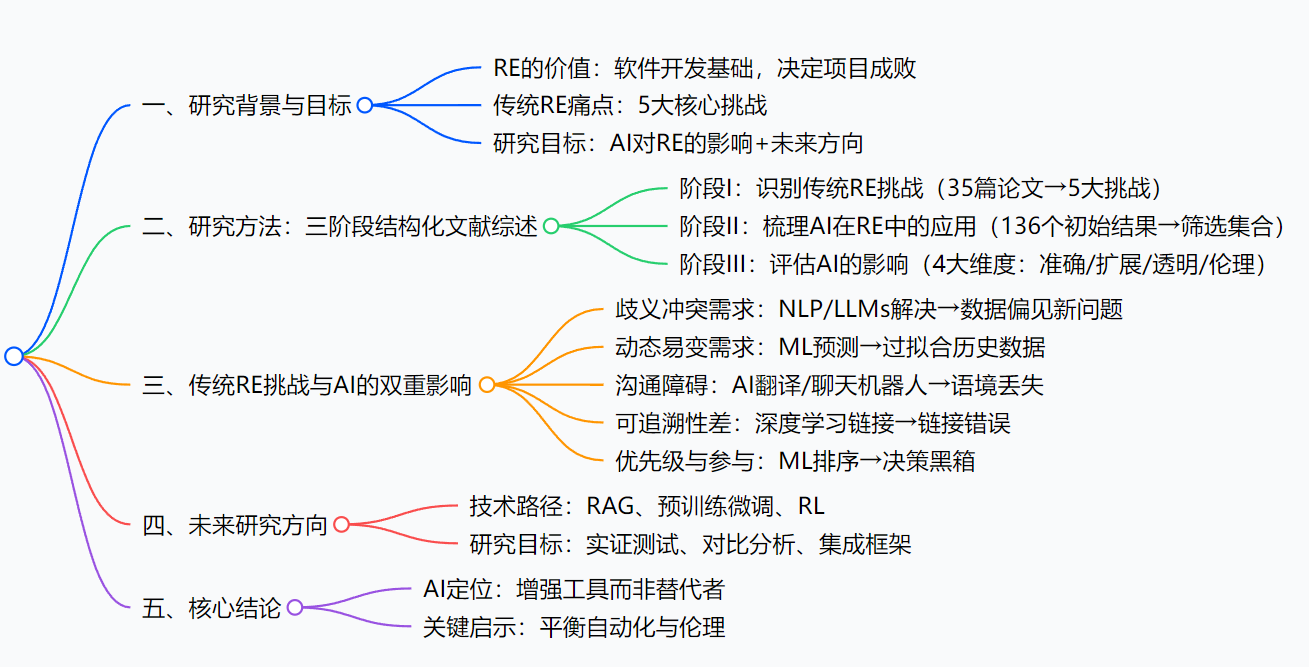
1. 摘要与引言
- 核心定位:需求工程(RE) 是软件开发成功的基石,需通过需求获取、验证、评估满足Stakeholder需求,但长期受歧义、需求冲突、需求演化等挑战困扰。
- AI的双重角色:
- 潜力:自动化高强度任务(如需求提取)、支持需求优先级排序、促进Stakeholder-AI协作,提升RE效率与准确性。
- 风险:引入伦理问题、数据偏见、透明度不足,且AI的复杂性可能导致RE流程不确定性(如依赖AI推荐却无法解释决策)。
- 研究范围:聚焦数据驱动AI技术(机器学习ML、生成式AI),分析其对RE实践、角色定义、决策流程的重塑作用。
- 研究贡献:①识别传统RE挑战;②分析AI对挑战的影响;③提出缓解AI驱动挑战的未来研究方向。
2. 研究方法论:结构化文献综述(三阶段)
| 阶段 | 核心任务 | 数据来源 | 关键步骤 | 关键成果 |
|---|---|---|---|---|
| 阶段I:识别传统RE挑战 | 明确传统RE的核心问题 | Google Scholar、Scopus | 1. 搜索关键词:“requirements engineering challenges”等; 2. 筛选:优先同行评审文献,标题/摘要→全文评估; 3. 分析:定性编码+主题分组,直至主题饱和 | 分析35篇论文,提炼出五大核心挑战(歧义与冲突需求、动态易变需求、沟通障碍、可追溯性差、优先级与Stakeholder参与) |
| 阶段II:AI在RE中的应用综述 | 梳理AI技术在RE中的应用现状 | 仅Google Scholar(覆盖最新/预印本文献) | 1. 搜索关键词:“AI in Requirements Engineering”等; 2. 初始结果:136个; 3. 筛选:去重→引用分析→优先最新同行评审文献; 4. 补充:纳入RE领域高频引用的开创性论文 | 形成AI-RE应用的curated研究集合,覆盖NLP、ML、DL等技术场景 |
| 阶段III:分析AI对RE挑战的影响 | 评估AI的解决价值与新问题 | 阶段I/II的文献成果 | 1. 评估维度:准确性与可靠性、可扩展性、透明度与可解释性、伦理考量; 2. 聚焦:针对阶段I的五大挑战,逐一分析AI的作用与风险 | 明确AI对每个RE挑战的具体解决路径,及引入的新问题(如数据偏见、黑箱决策) |
3. 传统RE五大挑战与AI的影响(详细表格)
| RE核心挑战 | 传统RE的具体困境 | AI的解决方式(技术手段) | AI引入的新问题 | 典型案例 |
|---|---|---|---|---|
| 歧义与冲突需求 | 1. Stakeholder输入模糊、术语不一致; 2. 需求不完整,后期测试/集成阶段才暴露; 3. 易导致下游开发错误 | 1. NLP工具(CoreNLP、NLTK)检测模糊短语与不一致性; 2. LLMs作为对话代理,将邮件/会议记录等非结构化数据转化为结构化需求; 3. 多源需求提取,填补信息缺口 | 1. 语言模型继承训练数据偏见; 2. 依赖高质量大规模训练数据,收集/整理成本高; 3. 提示设计不当导致需求误解或偏见放大; 4. AI决策缺乏可解释性 | AI优先级工具可能优先性能需求,忽视Stakeholder关注的 usability需求,导致期望错配 |
| 动态易变需求 | 1. 业务需求/用户需求频繁变化,打乱项目 timeline; 2. 需求变更增加成本与返工; 3. 传统RE难以预判变更 | 1. ML预测分析:基于历史项目数据、Stakeholder行为预测需求变化; 2. 优化需求获取/分析/变更管理工具,降低变更影响 | 1. 预测依赖历史数据质量,数据不完整/过时导致预测偏差; 2. 过度依赖AI预测,忽视非历史趋势的新因素(如新兴技术); 3. AI模型复杂性延续现有偏见; 4. 无法完全预测语境/用户需求演化驱动的易变性 | 电商平台AI预测需求时,因用户 demographics变化,训练数据失效,无法捕捉新支付方式需求 |
| 沟通障碍 | 1. Stakeholder与开发团队技术知识/语言/文化差异; 2. 全球团队协作中文化/语言壁垒; 3. 导致需求误解或不完整 | 1. NLP+翻译工具消除语言壁垒; 2. AI聊天机器人/虚拟助手提供标准查询响应,澄清需求讨论 | 1. AI继承训练数据偏见,扭曲需求解读; 2. 自动翻译丢失文化语境(如“warehouse”在不同场景的歧义); 3. AI误解领域术语,恶化高风险沟通 | 全球项目中,AI将“warehouse”统一译为“主仓库”,忽视部分Stakeholder指“分布式配送中心”的需求,导致规格错配 |
| 可追溯性差 | 1. 手动追溯需求与设计/代码/测试用例的链接,效率低且易出错; 2. 追溯缺口导致无法验证需求是否完全实现 | 1. 深度学习+NLP自动化需求与其他工件的链接; 2. 减少手动工作量,提升追溯完整性 | 1. AI生成的链接质量依赖训练数据,数据问题导致链接错误(如将“数据加密”需求链接到日志功能); 2. 缺乏人类监督时,错误链接易被忽视; 3. AI自身可追溯性不足(训练数据来源、模型跟踪缺失) | AI错误链接“数据加密”需求与日志功能,导致开发团队浪费精力验证无关链接 |
| 优先级与Stakeholder参与 | 1. Stakeholder利益冲突,需求优先级难平衡; 2. 部分Stakeholder参与度低,需求偏离用户期望; 3. 优先级排序主观,缺乏客观分析 | 1. NLP/ML自动化文档分析、用户反馈处理,识别关键Stakeholder; 2. 效用推荐、矩阵分解等技术优化需求排序; 3. ML算法(随机森林、线性规划)结合AHP/BST,分析成本-时间-需求权衡 | 1. 依赖历史数据,无法捕捉项目特定语境; 2. AI决策“黑箱”,降低Stakeholder信任; 3. 偏向数据更充分/反馈更一致的Stakeholder(如优先营销部门需求); 4. 伦理问责缺失(如强化偏见、违背真实需求) | AI因营销部门需求文档更清晰,优先其功能需求,忽视其他部门未充分记录的关键需求 |
4. 讨论与未来研究方向
-
核心洞察:AI已从“单一任务辅助”升级为“重塑RE核心流程”,但RE的语境依赖性强,早期AI的误解、偏见或透明度不足会传导至下游开发,引发严重问题(如需求错配导致系统缺陷)。
-
三大关键AI技术路径(增强RE)
- 检索增强生成(RAG):
- 原理:结合检索(从历史项目文档、领域知识库提取信息)与生成模型,生成语境相关需求。
- 目标:减少需求歧义与冲突,提升需求复用性。
- 未来研究:开发RAG工具提取可复用历史需求,实证评估其效果。
- 预训练模型微调:
- 原理:用RE领域数据集微调BERT、GPT等LLM,适配领域术语与Stakeholder偏好。
- 目标:提升需求获取、分类、分析的准确性;解决合规需求(HIPAA、GDPR)生成问题。
- 未来研究:探索轻量级适配策略(提示优化、适配器微调),平衡效果与部署成本(降低计算/环境成本)。
- 强化学习(RL):
- 原理:RL智能体通过迭代反馈(奖励/惩罚)学习,基于“成本-风险-Stakeholder满意度”定义奖励函数。
- 目标:动态调整需求优先级,适配用户需求变化,解决需求易变问题。
- 未来研究:优化奖励函数设计,确保优先级调整贴合项目演化实际。
- 检索增强生成(RAG):
-
三大研究目标
- 实证测试AI模型:评估RAG、微调、RL在缓解RE挑战中的效率、准确性,对比AI与传统RE的Stakeholder满意度。
- 比较分析AI与传统RE:通过调查、对照实验、性能分析,明确AI的核心价值场景(如大规模需求排序)与人类决策不可替代的领域(如高风险需求冲突调和)。
- 构建集成框架:制定工业级AI-RE集成最佳实践,涵盖数据处理、模型优化、结果解释、人类输入整合,平衡自动化与伦理,确保透明与问责。
-
实践与理论意义
- 实践意义:为企业提供AI-RE解决方案(如NLP检测歧义、RL适应变更),指导工具选型与开发,减少手动工作,提升RE可管理性。
- 理论意义:整合现有AI-RE研究,识别数据质量、可解释性、伦理等研究空白;为RAG、RL等新技术在RE中的应用奠定理论基础。
5. 结论
- AI的核心价值:通过RAG、微调、RL等技术,AI可有效缓解传统RE挑战,降低开发时间与成本,提升RE准确性与可靠性。
- AI的定位边界:AI是RE的增强工具,而非人类决策的替代者,其结果需具备可解释性、公平性,且严格对齐Stakeholder真实需求。
- 未来工作重点:聚焦AI生成需求的偏见检测与消除,确保需求优先级公平性,强化AI-RE流程的伦理与问责机制,推动产学协作构建可信AI解决方案。
关键问题
问题1:论文为分析AI对需求工程(RE)的影响,设计了怎样的研究方法?该方法各阶段的核心任务与数据成果有何差异?
答案:论文采用结构化(非完全系统)文献综述方法,分为三阶段,各阶段核心任务与数据成果差异显著:
- 阶段I(识别传统RE挑战):核心任务是从Google Scholar、Scopus数据库检索RE挑战相关文献,通过定性编码与主题分组提炼关键问题;数据成果为分析35篇同行评审论文,提炼出传统RE的五大核心挑战(歧义与冲突需求、动态易变需求等),且达到“主题饱和”(无新挑战类别出现)。
- 阶段II(AI在RE中的应用综述):核心任务是聚焦Google Scholar(因覆盖最新预印本)检索AI-RE相关研究,通过多轮筛选(去重、引用分析、全文评估)梳理应用现状;数据成果为从136个初始搜索结果中筛选出curated研究集合,覆盖NLP、ML、DL等AI技术在RE中的具体应用场景,并补充RE领域开创性论文确保完整性。
- 阶段III(分析AI对RE挑战的影响):核心任务是基于前两阶段成果,从“准确性、可扩展性、透明度、伦理”四维度评估AI的作用与风险;数据成果为明确AI针对五大RE挑战的具体解决路径,及引入的新问题(如数据偏见、黑箱决策),形成“挑战-AI解决-AI新问题”的对应关系。
问题2:在解决传统RE的“可追溯性差”与“优先级与Stakeholder参与不足”两大挑战时,AI分别采用了哪些技术手段?这些手段又会引发哪些独特的新问题?
答案:两大挑战的AI技术手段与独特新问题如下:
-
可追溯性差:
- AI技术手段:通过深度学习与NLP技术,自动化需求与设计文档、代码、测试用例等开发工件的链接,减少手动追溯的工作量与错误率。
- 独特新问题:①AI生成的追溯链接质量完全依赖训练数据,若数据不完整/有偏见,易出现“错误链接”(如将“数据加密”需求链接到无关日志功能);②缺乏人类监督时,链接错误易被忽视,导致后期验证阶段发现需求未实现;③AI自身可追溯性不足(如训练数据来源、模型迭代过程无法跟踪),无法满足RE对“透明与问责”的要求。
-
优先级与Stakeholder参与不足:
- AI技术手段:①通过NLP/ML自动化文档分析、用户反馈处理,识别关键Stakeholder及其核心需求;②基于“效用推荐、矩阵分解、内容推荐”等技术,结合ML算法(随机森林、线性规划)与传统方法(AHP、BST),分析成本-时间-需求的权衡关系,优化需求优先级排序。
- 独特新问题:①AI依赖历史数据排序,无法捕捉当前项目的特定语境(如新兴业务需求);②AI决策“黑箱”问题,Stakeholder无法理解优先级排序逻辑,导致信任度低;③Stakeholder偏向性:AI易优先数据更充分/反馈更一致的Stakeholder(如文档清晰的营销部门),忽视其他部门未充分记录的关键需求,导致优先级失衡;④伦理问责缺失,若AI强化偏见(如忽视小众用户需求),难以界定责任主体。
问题3:论文提出的“预训练模型微调”与“强化学习(RL)”两大未来技术方向,分别针对RE的哪些核心痛点?其研究设计的核心思路是什么?
答案:两大技术方向的RE痛点针对性与研究思路如下:
-
预训练模型微调:
- 针对的RE核心痛点:①通用LLM(如BERT、GPT)对RE领域术语(如“非功能需求”“合规性”)适配不足,导致需求获取、分类、分析的准确性低;②传统RE中合规需求(如HIPAA、GDPR)生成依赖人工,效率低且易遗漏;③全量微调LLM成本高(计算资源、环境消耗),难以工业部署。
- 研究设计核心思路:①用RE领域专用数据集(如合规需求文档、历史项目需求)微调预训练LLM,提升模型对领域术语与Stakeholder偏好的适配性;②探索轻量级领域适配策略(如提示优化、适配器微调),在保证模型效果的同时,降低计算成本与环境消耗;③实证测试微调后模型在“合规需求生成”中的表现,验证其是否能输出符合HIPAA、GDPR等标准的需求文档。
-
强化学习(RL):
- 针对的RE核心痛点:①传统RE难以应对“动态易变需求”,无法根据项目迭代中的用户反馈、业务变化实时调整需求优先级;②需求优先级排序依赖人工主观判断,难以平衡“成本、风险、Stakeholder满意度”等多维度目标。
- 研究设计核心思路:①构建RL智能体,将“需求优先级调整”作为决策任务,以“项目迭代反馈”(如Stakeholder满意度、成本控制效果、风险规避情况)作为“奖励/惩罚信号”,让智能体通过迭代学习优化决策;②定义多维度奖励函数,将“成本降低、风险减少、Stakeholder满意度提升”纳入量化指标,确保优先级调整贴合项目实际约束;③实证测试RL智能体在动态需求场景中的表现,评估其是否能自适应应对需求变化,且输出的优先级排序与Stakeholder真实需求一致。
总结
这篇论文为AI-native时代的需求工程提供了“全景图”:它既不否认传统RE的五大痛点,也不夸大AI的能力,而是客观分析了AI的“双重角色”——既是解决歧义、预测变化的高效工具,也会带来偏见、黑箱等新问题。其提出的RAG、预训练微调、RL三大技术方向,为工业界落地AI-RE方案提供了具体路径;而“AI是增强者而非替代者”的核心观点,更是为技术应用划定了“以人为本”的边界。对于软件开发团队和研究者来说,这篇论文不仅是一份研究综述,更是一份兼具理论深度和实践价值的“行动指南”。