软测面经(二)
1.jdk、jre、jvm
1.Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 利用字节码(即扩展名为 .class 的文件)针对不同系统,特定实现。
2.JDK 是 Java Development Kit,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
3.JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
2.重载与重写
1)重载:同一个类中,允许存在多个同名方法,但它们的参数列表(参数类型、数量或顺序)必须不同。
class Calculator {// 方法1:两个int相加public int add(int a, int b) {return a + b;}// 方法2:三个int相加(参数数量不同)public int add(int a, int b, int c) {return a + b + c;}// 方法3:两个double相加(参数类型不同)public double add(double a, double b) {return a + b;}}
2)重写:子类重新定义父类中已有的方法,方法名、参数列表和返回值类型必须完全相同。
class Animal {public void makeSound() {System.out.println("Animal sound");}}class Dog extends Animal {@Overridepublic void makeSound() { // 重写父类方法System.out.println("Bark!");}}public class Main {public static void main(String[] args) {Animal animal = new Dog();animal.makeSound(); // 输出 "Bark!"(运行时多态)}}
3.局部变量、成员变量
1)局部变量:在方法、构造器或代码块(如 if、for 循环)内部声明的变量。
2)成员变量:在类中声明,但不在方法、构造器或代码块内部的变量。在整个类内有效(包括所有方法、构造器和代码块)。
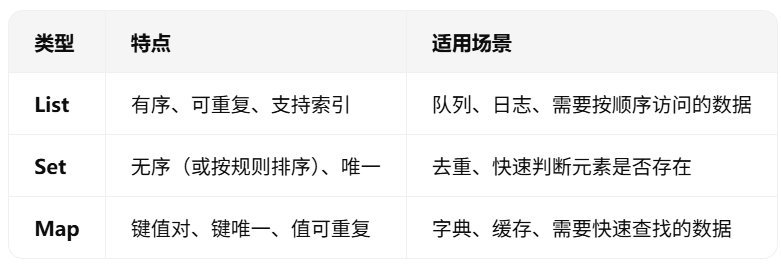
4.list列表、set集合、map映射
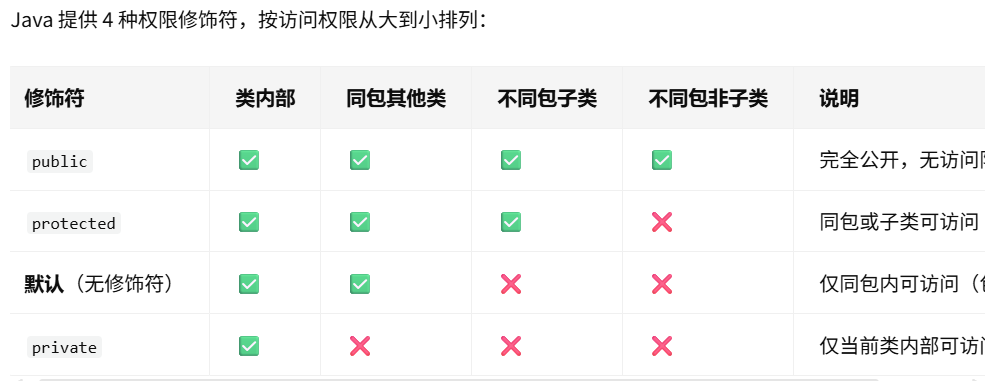
5.权限修饰符
6.list去重
示例:
def remove_duplicates_ordered(input_list):return list(dict.fromkeys(input_list))# 示例duplicate_list = [1, 2, 2, 3, 4, 4, 5, 1]print(remove_duplicates_ordered(duplicate_list)) # 输出 [1, 2, 3, 4, 5] List<String> listWithDuplicates = Arrays.asList("apple", "banana", "apple", "orange");Set<String> setWithoutDuplicates = new LinkedHashSet<>(listWithDuplicates);//linkedhashset底层基于hashsetList<String> listWithoutDuplicates = new ArrayList<>(setWithoutDuplicates);System.out.println(listWithoutDuplicates); // 输出 [apple, banana, orange]
7.学到的知识可能用不到怎么办?
可能我掌握的知识和实际项目间存在差异,但在某些方面可能使我更易触类旁通,指导我的思考。当我遇到完全陌生的领域,我会直面挑战,先明确目标,再通过快速学习(如查阅文档、向团队请教)填补知识缺口,积累经验,不断适应变化,提升测试效率。
8.数据库事务类型和特性
数据库事务主要分为本地事务和分布式事务。本地事务适用于单数据库场景,例如用户下单时同时更新库存和订单表,通过ACID特性保证数据一致性。而分布式事务用于跨服务或跨数据库的场景,例如跨行转账,需要协调多个节点的操作。
事务的四大特性是ACID:
原子性:确保事务不可分割,例如转账失败时全部回滚。
一致性:维护业务规则,如库存不能为负。
隔离性:通过隔离级别平衡一致性与性能,例如秒杀场景可能用‘可重复读’。
持久性:通过日志机制保证数据不丢失。
在实际选择中,如果业务简单且数据源单一,优先用本地事务;如果涉及微服务或跨库操作,则需用分布式事务(如Seata框架),但需权衡性能与一致性,可能采用最终一致性方案。
9.简单说一下接口自动化和web自动化
1)接口自动化:接口自动化测试主要验证系统间API的正确性。
2)web自动化:Web自动化测试主要模拟用户在浏览器中的操作。优势是能发现UI展示或交互的问题,但执行速度比接口测试慢,通常在测试后期或回归阶段使用。
总结:在之前项目中,我们同时使用了接口自动化和Web自动化:
接口自动化:用Pytest+Requests测试订单创建接口,参数化不同商品ID和用户ID,验证返回的订单状态是否正确。
Web自动化:用Selenium测试订单支付流程,从商品页到支付页的跳转是否顺畅,支付按钮是否可点击。
两者结合能覆盖从后端到前端的完整链路,提高测试效率。
10.具体说一下接口自动化代码如何搭建
从技术选型、框架设计、核心模块实现、测试用例编写四个层面
我的接口自动化框架基于Python+Pytest+Requests搭建,采用分层架构:配置层管理环境参数,工具层封装HTTP请求,接口层按模块封装API,用例层通过DDT实现数据驱动。例如登录接口的测试,数据存储在Excel中,用例通过parametrize加载,断言响应码和消息。框架还集成了日志和Allure报告,便于问题追踪和结果展示。这种设计使得新增接口时,只需在接口层添加方法,用例层直接调用,维护成本低。


3.核心代码实现
http请求封装:
# utils/http_client.pyimport requestsclass HttpClient:def __init__(self, base_url):self.base_url = base_urlself.session = requests.Session()def post(self, endpoint, json_data, headers=None):url = f"{self.base_url}{endpoint}"response = self.session.post(url, json=json_data, headers=headers)return response
接口封装:
# api/login_api.pyfrom utils.http_client import HttpClientclass LoginAPI:def __init__(self, base_url):self.client = HttpClient(base_url)def login(self, username, password):data = {"username": username, "password": password}response = self.client.post("/api/login", json_data=data)return response.json() # 返回解析后的JSON
4.测试用例编写:数据驱动与断言
用例代码通过pytest.mark.parametrize加载数据:
python# testcases/test_login.pyimport pytestfrom api.login_api import LoginAPI@pytest.mark.parametrize("username, password, expected", [("admin", "123456", {"code": 200, "msg": "success"}),("wrong", "123456", {"code": 401, "msg": "Invalid username"})])def test_login(username, password, expected):api = LoginAPI("https://api.example.com")response = api.login(username, password)assert response["code"] == expected["code"]assert response["msg"] == expected["msg"]
11.测试环境的搭建
从环境规划、技术选型、部署流程、维护策略四个维度
测试环境搭建首先需根据项目需求规划三级环境(开发/测试/预发布),技术上采用Docker实现容器化部署,通过Jenkins流水线自动化构建和发布。数据层面使用Flyway管理数据库版本,TestContainer动态创建测试实例。部署后通过Prometheus监控服务状态,ELK收集日志。
CI/CD 是 Continuous Integration(持续集成) 和 Continuous Delivery/Deployment(持续交付/部署) 的缩写,是现代软件开发中实现自动化构建、测试和部署的核心实践。它的核心目标是通过自动化流程缩短开发周期、提高代码质量,并实现高效可靠的软件交付。
数据管理:Flyway(数据库版本控制) + TestContainer(动态数据库实例)。
基础环境准备:
服务器初始化:安装Docker、Java/Python运行环境。
网络配置:划分VLAN,设置防火墙规则(仅允许测试团队IP访问)。
服务部署:
编写Dockerfile定义应用镜像,通过Jenkins构建并推送到私有仓库;
数据初始化:
执行Flyway脚本初始化测试数据库,预置基础数据(如用户、商品信息);
通过API接口导入测试用例所需的动态数据(如订单、优惠券)。
环境验证:
运行自动化脚本验证服务可用性(如curl -I http://service-url检查HTTP状态码);
执行核心接口的冒烟测试,确保关键功能正常。
12.在需求评审阶段,如何分析功能点和业务线,以确保测试用例覆盖全面的?
在需求评审时,我会先仔细研读需求文档,明确每个功能模块的具体要求和预期效果。对于功能点,我会从用户操作流程的角度出发,考虑正常流程、异常流程以及边界情况。对于业务线,我会梳理整个业务流程,从数据流入到流出,确保每个环节都有相应的测试用例覆盖,避免出现测试遗漏。
13.编写测试框架时,你遵循了哪些原则或方法?
编写测试框架时,我主要遵循了模块化和可维护性原则。将不同的测试功能模块化,比如将接口测试、UI 测试等分别封装成独立的模块,这样便于管理和维护。同时,采用分层设计,将数据层、业务逻辑层和展示层分离,使得测试框架结构清晰。在方法上,我参考了一些通用的测试框架设计模式,如 Page Object 模式用于 UI 测试,将页面元素和操作封装成对象,提高代码的复用性。
14.Bug 定位与反馈相关问题及回答
问题 1:当定位到前后端 Bug 时,你是如何快速推进流转并与开发人员有效反馈的?
回答:定位到 Bug 后,我会先详细记录 Bug 的现象、出现环境、操作步骤等信息,确保开发人员能够准确复现问题。对于前后端交互的 Bug,我会通过日志分析、抓包等手段,确定是前端数据传递错误还是后端处理异常。在反馈时,我会使用清晰简洁的语言描述问题,附上相关的截图、日志和抓包数据,同时标注问题的严重程度和影响范围。与开发人员沟通时,保持积极的态度,共同探讨解决方案,而不是单纯地指出问题。
问题 2:请举例说明你在定位前后端 Bug 过程中的具体思路和方法。
回答:比如在一个数据展示页面,前端显示的数据与后端返回的数据不一致。首先,我会使用浏览器的开发者工具查看前端接收到的数据,确认是否是前端数据处理错误。如果前端数据正确,我会通过抓包工具(如 Fiddler)查看后端返回的原始数据,对比数据库中的数据,确定是后端查询逻辑错误还是数据存储问题。如果是前端问题,进一步检查前端的 JavaScript 代码,查看数据处理和渲染的逻辑;如果是后端问题,查看相应的接口代码和数据库查询语句。
15.接口测试与性能测试相关问题及回答
问题 1:使用 Postman 进行接口测试时,你是如何设计测试用例的?
回答:设计 Postman 接口测试用例时,我会从以下几个方面考虑。首先是功能测试,验证接口是否能够正确处理各种输入参数,返回预期的结果。例如,对于一个用户登录接口,测试正确的用户名和密码、错误的用户名和密码、空用户名和密码等情况。其次是参数验证,检查接口对参数的类型、长度、格式等是否有正确的校验。然后是接口的依赖关系测试,如果某个接口依赖于其他接口的返回数据,需要模拟不同的返回情况进行测试。最后是安全测试,如测试接口是否存在 SQL 注入、XSS 攻击等安全漏洞。
问题 2:在使用 Jmeter 进行压测和性能测试时,你是如何设置测试场景和监控指标的?
回答:设置 Jmeter 测试场景时,我会根据实际业务情况模拟不同的用户并发量和操作频率。例如,对于一个电商网站,模拟不同时间段的用户访问量,如平时的正常访问量、促销活动时的高并发访问量。在监控指标方面,主要关注响应时间、吞吐量、错误率等。响应时间反映了系统的处理速度,吞吐量表示系统在单位时间内处理的请求数量,错误率则体现了系统的稳定性。通过监控这些指标,可以评估系统在不同负载下的性能表现,发现性能瓶颈。
问题 3:如何验证前端接口有无防重、做幂等?
回答:验证前端接口防重和幂等性,我会采用以下方法。对于防重,可以在短时间内多次发送相同的请求,观察系统是否会重复处理。例如,在一个提交订单的接口中,快速点击提交按钮多次,检查是否会生成多个订单。对于幂等性验证,先发送一个请求获取结果,然后再次发送相同的请求,对比两次请求的结果是否一致。如果结果一致,说明接口具有幂等性。同时,可以通过查看后端日志,确认接口是否对重复请求进行了正确的处理。
16.需求理解与协作相关问题及回答
问题 1:当工作中与前后端对需求理解不一致时,你是如何落实解决方案并提出建议的?
回答:遇到需求理解不一致时,我会先整理自己和前后端对需求的不同理解点,以清晰的方式呈现出来。然后主动与产品、UI、项目经理沟通,邀请他们一起讨论需求。在沟通过程中,认真倾听各方的观点,结合业务目标和用户体验,提出自己的建议。例如,如果前端认为某个交互方式更符合用户习惯,而后端担心实现难度较大,我会从整体业务流程和用户反馈的角度出发,分析哪种方案更合适,并与大家一起探讨可行的实现方法。
问题 2:请分享一次你在参与关联上下游项目协作及打通业务链工作中的具体经历和收获。
回答:在一次项目中,我们的 WMS 系统需要与上游的采购系统和下游的物流系统进行对接。在协作过程中,我首先与上下游项目的负责人沟通,了解他们的系统接口和数据格式。然后,组织三方进行需求对接会议,在对接过程中,遇到了数据格式不兼容的问题,我们通过协商制定了统一的数据转换规则。通过这次经历,我深刻体会到了跨项目协作的重要性,学会了如何与不同团队有效沟通和协调,同时也提高了自己解决复杂问题的能力。
17.产品验收与客户需求相关问题及回答
问题 1:配合产品、运营验收工作时,你是如何确保验收工作的顺利进行并解决客户提出的优化需求的?
回答:在配合产品、运营验收工作时,我会提前准备好详细的测试报告和验收文档,明确验收的标准和流程。在验收过程中,积极引导产品、运营人员进行操作,及时解答他们的疑问。对于客户提出的优化需求,我会先与客户沟通,了解需求的具体背景和期望效果。然后评估需求的可行性和对系统的影响,与开发团队一起制定解决方案。在实施优化过程中,及时向客户反馈进度,确保客户的需求得到满足。
问题 2:当客户提出的问题比较复杂,涉及多个模块时,你是如何进行回归测试的?
回答:当客户提出的问题涉及多个模块时,我会先分析问题的影响范围,确定受影响的模块和相关接口。然后制定回归测试计划,包括测试用例的选择和执行顺序。在执行回归测试时,优先测试与问题直接相关的模块,确保问题得到彻底解决。然后再逐步扩展到其他相关模块,进行全面的测试。同时,使用自动化测试工具提高回归测试的效率,确保在较短的时间内完成测试工作。
18.Web 自动化巡检和场景用例维护相关问题及回答
问题 1:负责系统的 Web 自动化巡检时,你是如何选择巡检的频率和范围的?
回答:选择 Web 自动化巡检的频率和范围时,我会综合考虑系统的重要性和稳定性。对于核心业务系统,巡检频率会设置得较高,如每天进行一次全面巡检,以确保系统的稳定运行。对于一些非核心系统,可以适当降低巡检频率,如每周进行一次巡检。在巡检范围方面,会覆盖系统的主要功能模块和关键业务流程,同时根据历史问题和风险评估,对容易出现问题的模块进行重点巡检。
问题 2:在维护场景用例时,你是如何保证用例的有效性和可维护性的?
回答:保证场景用例的有效性和可维护性,我会定期对用例进行评审和更新。随着系统功能的迭代和业务的变化,及时调整用例以适应新的需求。在编写用例时,采用清晰的命名规则和注释,方便其他人员理解和维护。同时,将用例进行模块化设计,将相关的操作步骤封装,提高用例的复用性。对于一些复杂的场景,会编写详细的测试数据和预期结果,确保用例的可执行性。