gRPC从0到1系列【25】
文章目录
- gRPC的重试机制
- 一、gRPC重试机制概述
- 1.1 什么是gRPC重试
- 1.2 重试机制的作用
- 1.3 gRPC重试核心概念
- 1.4 重试的触发条件
- 二、重试配置详解
- 2.1 可重试状态码
- 2.2 重试的限制与注意事项
- 三、最佳实践
- 四、重试 vs 透明重试(Transparent Retry)
- 五、总结
gRPC的重试机制
一、gRPC重试机制概述
1.1 什么是gRPC重试
gRPC 重试机制允许客户端在遇到可重试的失败时自动重新发送请求,提高系统的容错能力和可用性。
1.2 重试机制的作用
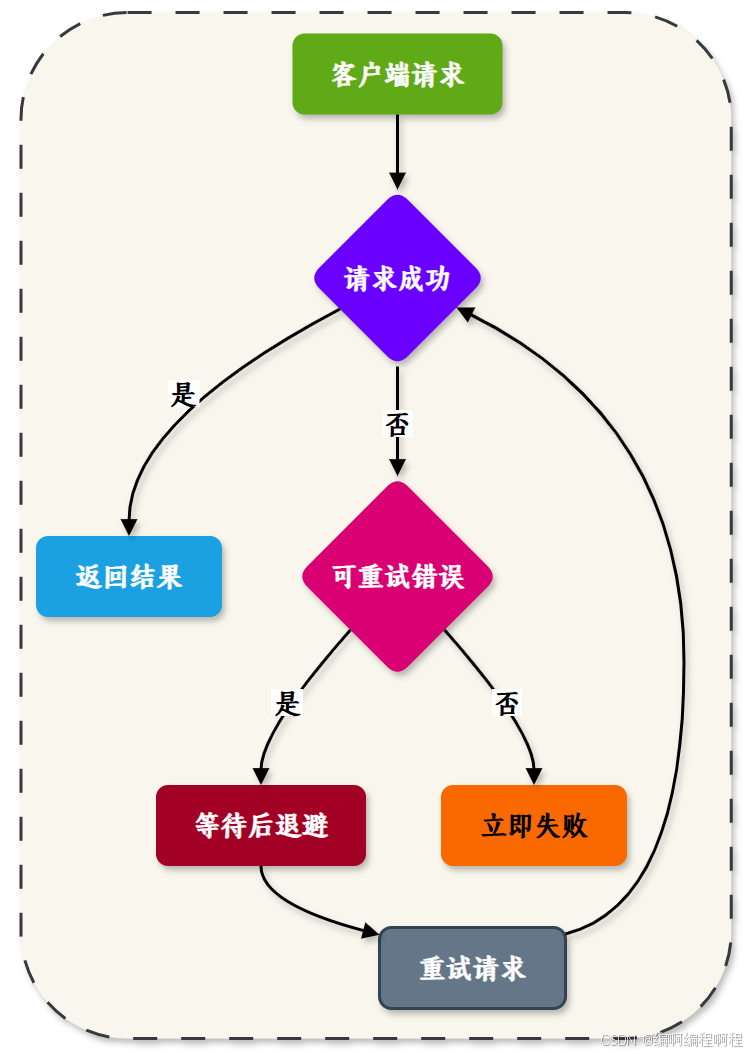
- 提高系统容错能力
- 自动重试临时性错误(如
UNAVAILABLE、DEADLINE_EXCEEDED、ABORTED等),避免因短暂故障导致请求失败。 - 减少因瞬时问题引发的“雪崩效应”或级联失败。
- 增强服务可用性
- 对用户或上游服务透明地恢复失败请求,提升整体服务成功率(Success Rate)。
- 尤其适用于微服务架构中依赖链较长的场景。
- 简化客户端逻辑
- 开发者无需在业务代码中手动编写重试逻辑(如循环 + sleep + 异常判断)。
- 重试策略通过配置或拦截器统一管理,降低代码复杂度和出错概率。
- 支持灵活的重试策略
- 按方法重试:不同 RPC 方法可配置不同重试规则。
- 按错误码重试:只对特定状态码(如
UNAVAILABLE)重试,避免对INVALID_ARGUMENT等无效请求重试。 - 限制重试次数:防止无限重试导致资源耗尽。
- 退避策略(Backoff):支持指数退避(Exponential Backoff),避免重试风暴。
1.3 gRPC重试核心概念
- 重试策略(Retry Policy)
定义何时以及如何重试请求。
- 对冲策略(Hedging Policy)
允许同时发送多个相同的请求,使用最先返回的响应。
- 退避策略(Backoff Policy)
控制重试之间的等待时间。
1.4 重试的触发条件
重试不会对所有错误都生效,必须同时满足以下条件:
| 条件 | 说明 |
|---|---|
| ✅ 方法是幂等的或安全的 | 默认只对 Unary(一元) 和 Server Streaming(服务端流) 调用启用重试(前提是未开始发送请求体)。Client Streaming 和 Bidirectional Streaming 默认不支持重试(因为已发送部分数据,无法安全重放)。 |
| ✅ 错误码在 retryableStatusCodes 中 | 如 UNAVAILABLE, ABORTED, DEADLINE_EXCEEDED 等。 |
| ✅ 未超过最大重试次数 | 由 maxAttempts 控制(含首次调用,通常为 2~5)。 |
| ✅ CallOptions 中未禁用重试 | 某些客户端可通过选项关闭。 |
| ✅ 服务端未发送任何响应数据 | 一旦服务端开始返回数据(如 Server Streaming 已发部分消息),则不能重试。 |
📌 注意:gRPC 的重试是 “透明重试”(Transparent Retry)和 “配置驱动重试”(Configurable Retry)的结合。前者由底层自动处理连接失败,后者由用户配置策略。
二、重试配置详解
2.1 可重试状态码
| 状态码 | 描述 | 是否可重试 |
|---|---|---|
| UNAVAILABLE | 服务不可用 | ✅ |
| RESOURCE_EXHAUSTED | 资源耗尽 | ✅(有限重试) |
| INTERNA | 内部错误 | ✅(谨慎) |
| DEADLINE_EXCEEDED | 超时 | ❌ |
| CANCELLE | 已取消 | ❌ |
| INVALID_ARGUMENT | 参数错误 | ❌ |
| PERMISSION_DENIED | 权限拒绝 | ❌ |
2.2 重试的限制与注意事项
✅ 1. 不支持的场景
- Client Streaming / Bidirectional Streaming:一旦客户端开始发送消息,无法安全重试。
- 非幂等写操作:如“创建订单”,重试会导致重复创建。
- 服务端已返回部分响应:例如 Server Streaming 已发送第一个消息,则不能重试。
✅ 2. 一味的重试可能会加剧问题
- 在服务过载时重试会增加负载,可能引发“重试风暴”。
- 解决方案:结合熔断器(如 Resilience4j、Sentinel)或限流使用。
✅ 3. 超时处理
- 重试共享同一个 deadline(即总超时时间)。
- 如果首次调用耗时较长,后续重试可能立即超时。
- 建议设置合理的
deadline(如 3s),并配合initialBackoff。
三、最佳实践
| 建议 | 说明 |
|---|---|
| ✅ 仅对幂等操作启用重试 | 如查询、幂等更新(带唯一 ID 的写入)。 |
| ✅ 限制 maxAttempts ≤ 3 | 避免过多重试拖慢响应。 |
| ✅ 使用指数退避 | 防止重试集中爆发。 |
| ✅ 监控重试率 | 高重试率 = 系统异常信号。 |
| ✅ 结合熔断机制 | 当失败率过高时,暂时停止重试。 |
| ❌ 不要对所有错误重试 | 如 INVALID_ARGUMENT、NOT_FOUND 不应重试。 |
四、重试 vs 透明重试(Transparent Retry)
gRPC 还有一种底层机制叫 Transparent Retry:
- 由 gRPC 内部自动触发(无需配置)。
- 仅适用于连接建立失败但未发送请求的情况(如 TCP 连接失败)。
- 不计入
maxAttempts,且无退避延迟。 - 是重试机制的补充,不是替代。
五、总结
gRPC 重试机制是一个声明式、配置驱动、客户端实现的容错功能,适用于处理临时性故障。通过合理配置,可以在不修改业务代码的前提下显著提升系统健壮性。
🔑 核心价值:用配置代替代码,用策略代替硬编码,提升系统弹性。
- 重试 + 熔断的完整示例(如 Java + Resilience4j)
- 如何测试重试行为
- 与 Kubernetes / Service Mesh(如 Istio)的集成