一些主要应用和NAT
NAT(Network Address Translator,网络地址转换器):功能是把私有IP 地址(LAN 内部,如 192.168.x.x、10.x.x.x)转换成公共IP地址(公网可路由)。NAT被无线路由器广泛使用,解决 IPv4地址不够用的问题,同时也能起到一定的安全隔离作用。
私有地址:包括A 类:10.0.0.0/8,B 类:172.16.0.0/12,C 类:192.168.0.0/16。这些地址不能在公网路由,只能在局域网(LAN)内部使用。例如10.0.0.9,即使ip地址相同,在不同的局域网内完全是不同的设备。
NAT基本模型:当内网主机192.168.1.2:1234像要访问公网8.8.8.8:53并试图建立TCP连接时,NAT会先将其源IP地址A,和源端口B分别修改为自己的IP地址C,一个自己分配的端口D(NAT转换),然后建立(A,B)和(C,D)之间的映射关系。接着使用外部IP地址和端口发送数据包。当NAT收到数据包时,它会查找映射关系,并将数据包的目标IP和端口重写(逆向转换),然后发往正确的对象。
四种不同的NAT:
| NAT类型 | 映射建立规则 | 访问权限 (过滤) 规则 |
| 全锥形 | 内网IP:Port ↔ 公网IP:Port | 无限制,任何外部主机均可访问该映射 |
| 地址受限锥形 | 内网IP:Port ↔ 公网IP:Port | 仅限内网主机曾通信过的IP地址 |
| 端口受限锥形 | 内网IP:Port ↔ 公网IP:Port | 仅限内网主机曾通信过的IP地址:端口 |
| 对称 | (内网IP:Port -> 外网A) ↔ (公网IP:PortA) (内网IP:Port -> 外网B) ↔ (公网IP:PortB) | 与端口受限相同,但每个映射独立生效 |
注:前三者的映射建立规则为,当你的电脑(192.168.0.10:1234) 第一次向任何外部目标(比如服务器A 11.11.11.11:80)发送数据包时,NAT路由器会在其映射表中创建一个条目。对称NAT的映射建立规则为,同一个内部地址端口,访问不同的外部目标,会得到不同的公网端口映射。
NAT的特征:
1.NAT允许从内向外建立连接,但是禁止从外向内建立连接。
2.NAT实际上禁止了新的传输协议。NAT设备被硬编码为只理解两种协议的头部格式:TCP (IP协议号 6) 和 UDP (IP协议号 17)。新的传输协议唯一的方法是伪装成UDP。
如何绕过NAT对于“只能向外建立连接的限制”:
1.连接逆转(Connection Reversal):在NAT之后的A和服务器R建立了联系,外部的B想要和A建立联系的话,把请求转发给R,然后R把这条请求告诉A,最后A和B建立联系。
2.中继(Relay):当双方都在NAT之后时,既然双方无法直接建立连接,那就干脆放弃直接连接,找一个双方都能访问的“中间人”(公网服务器)来转发所有数据。
3.NAT打洞(Hole Punching):当A和B都在NAT之后时,客户端A和客户端B都主动连接到一个公网上的“集合服务器”(Rendezvous Server),服务器会看到A和B经过NAT转换后的公网地址和端口(比如 A' 和 B')。服务器将 B' 的地址告诉A,将 A' 的地址告诉B。收到对方地址后,A和B几乎在同一瞬间,各自向对方的公网地址(A向B'发,B向A'发)发送一个UDP包。(此时A到B被打通,B到A也被打通)。
| 技术 | 核心思想 | 优点 | 缺点 | 适用场景 |
| 中继 (Relay) | 所有流量通过公网服务器转发 | 100%成功,兼容所有NAT | 延迟高,成本高,非真P2P | 作为所有P2P尝试失败后的最终保障方案 |
| 打洞 (Hole Punching) | 双方同时向对方发包,在NAT上打洞 | 真P2P,延迟低,无带宽成本 | 对称NAT下成功率低 | 大多数P2P应用的首选尝试方案 |
| 连接逆转 | 利用已有连接,命令对方反向连接 | 解决非对称网络下的连接问题 | 要求一方网络可达性好,较复杂 | C/S架构中,服务器主动联系客户端的场景 |
NAT工作原理:由于NAT会对很多特殊情况特殊处理,这里只举一个例子。在TCP打洞时,如果两方出现了时序问题,导致一方更早的发送了SYN,而另一方还没有发送SYN建立映射,当NAT收到一个外部传来的纯SYN试图建立连接时,显然会遭遇失败。根据RFC文档,此时NAT不应该马上丢弃一个陌生的SYN包,而是应该等待6秒钟,如果6秒后映射仍未被打通,才丢弃它。如果6秒之内被打通,这个陌生的SYN包仍会被丢弃,但是NAT会把这个SYN包纳入许可名单之中。这里为什么NAT不马上接收这个SYN包,这是为了防止NAT内的客户端刚刚发送SYN包,状态尚未稳定就收到来自外部的SYN包。丢弃第一个SYN包并非为了阻止“同时打开”的发生,而是为了延迟它的发生,将其从一个混乱的、可能有时序问题的“竞态”,变成一个更稳定、更可预测的流程。
HTTP:全称超文本传输协议 (HyperText Transfer Protocol)
HTTP请求报文格式: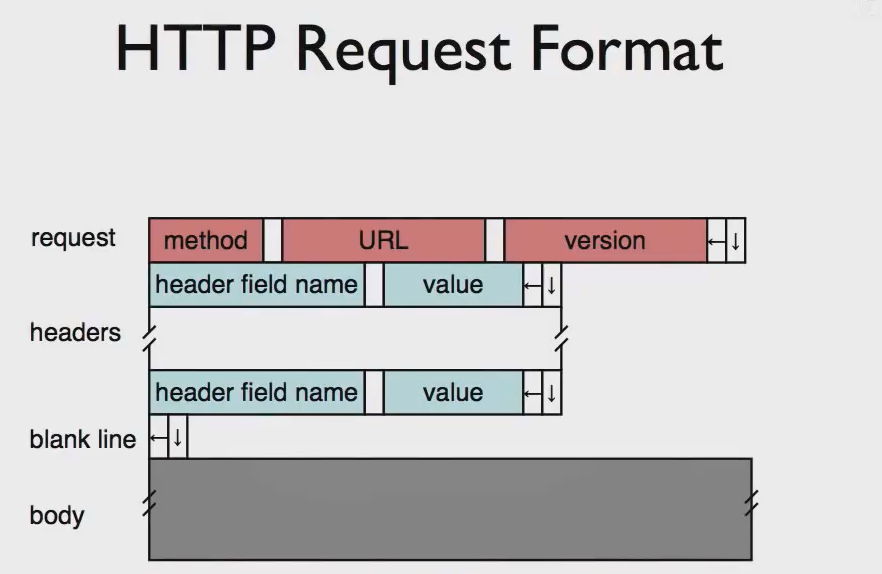
method即为指令如GET,URL是网址,version是版本。白色格子是空格,左箭头是回车(回到行首),下箭头表示换行。第一行后面是多行的请求头,每行一个,每个请求头行以字段名开头,后跟其值。然后是一个空行。当发送一个GET时body为空,但其他方法有可能不为空。
HTTP的核心模型是请求-响应。
HTTP/1.1 Keep Alive:在HTTP/1.0中,由于需要为每个资源都申请建立连接,我们会在三次握手阶段浪费大量时间。因此在HTTP/1.1中,我们引入了持久连接。在一次HTTP请求-响应周期结束后,客户端和服务器之间的TCP连接不会立即关闭,而是保持“存活”状态,等待后续的请求复用。当浏览器需要请求下一个资源(比如第一张图片)时,它会直接在已经建立好的这条TCP连接上发送新的HTTP请求,直到终止。也就是完成了一个资源一个TCP连接到多个资源一个TCP连接的转变。
SPDY协议:HTTP/1.1中,假如浏览器依次发送了三个请求A(耗时最长),B,C,即使服务器已经处理了B,C,也会被A所阻塞。为解决这样的问题,SPDY将每一个HTTP“请求-响应”对,都被视为一个独立的“流”,来自不同流的数据帧可以交错地在同一个TCP连接上发送,接收端收到数据帧后,根据每个帧上地流ID,再重新组合成各自独立地请求或响应。
这和路由器输入缓冲的解决方法类似,都是用多个虚拟/逻辑队列代替只有一个的物理队列,配合一个更加智能的调度策略,来绕卡单个阻塞点。
BitTorrent工作的基本要素:
群(swarm,或者说对等方集群,peer swarm):所有正在针对同一个.torrent文件进行下载和上传的用户(peers)的集合。
server(准确来说是Tracker,追踪服务器):它不持有文件本身,只负责记录哪些peer正在下载哪些文件,当一个新的peer加入时,tracker会给他一份当前swarm中其他peer的IP地址列表。
client(准确来说是peer,对等方):分为两种,下载者和做种者,前者指正在下载文件,尚未拥有全部文件块的peer。后者指已经拥有全部文件的peer,它不需要下载,只负责上传文件块。
.torrent文件:包含Tracker服务器的地址,文件名称大小目录结构,文件块的大小,以及最重要的一个由所有文件块做的SHA-1哈希值组成的列表。
文件块哈希:每当一个Peer成功下载完一个文件块后,它会立刻用SHA-1算法计算这个块的哈希值,然后与.torrent文件里记录的、对应块的“官方”哈希值进行比对。如果哈希值匹配,说明这个块是完整且正确的。如果不匹配,说明数据在传输中已损坏或被篡-改,这个块会被丢弃并重新下载。这确保了最终拼凑起来的文件是100%正确的。
分布式哈希表:由于传统的Tracker模式会使Tracker服务器受到过多的关注,为提高BitTorrent网络的鲁棒性和抗审查性,采取了分布式哈希表。Peers之间互相存储和查询其他Peer的联系信息而不再依赖于Tracker。
Best-P:指Piece选择策略,最经典的就是“最稀缺优先”,下载者在决定下载哪个文件块时,优先下载整个群中持有者最少的那个块。
以牙还牙算法:这是Peer之间决定是否给对方上传数据的策略。每个Peer会周期性地选出几个正在给它上传数据、且上传速度最快的Peer,并对它们进行“疏通”(Unchoke),允许向它们上传数据。对于那些不给它上传数据的Peer,则保持“阻塞”(Choke)。
DNS(Domain Name System,域名系统):DNS是一个为互联网设计的、分层的、分布式的命名系统。其核心功能是将域名(Hostname)等各种标识符解析为IP地址或其他所需的资源记录。通过使用域名,IP地址等被转化为了可读的,可理解的文字,更加方便人类的使用。
域名结构:
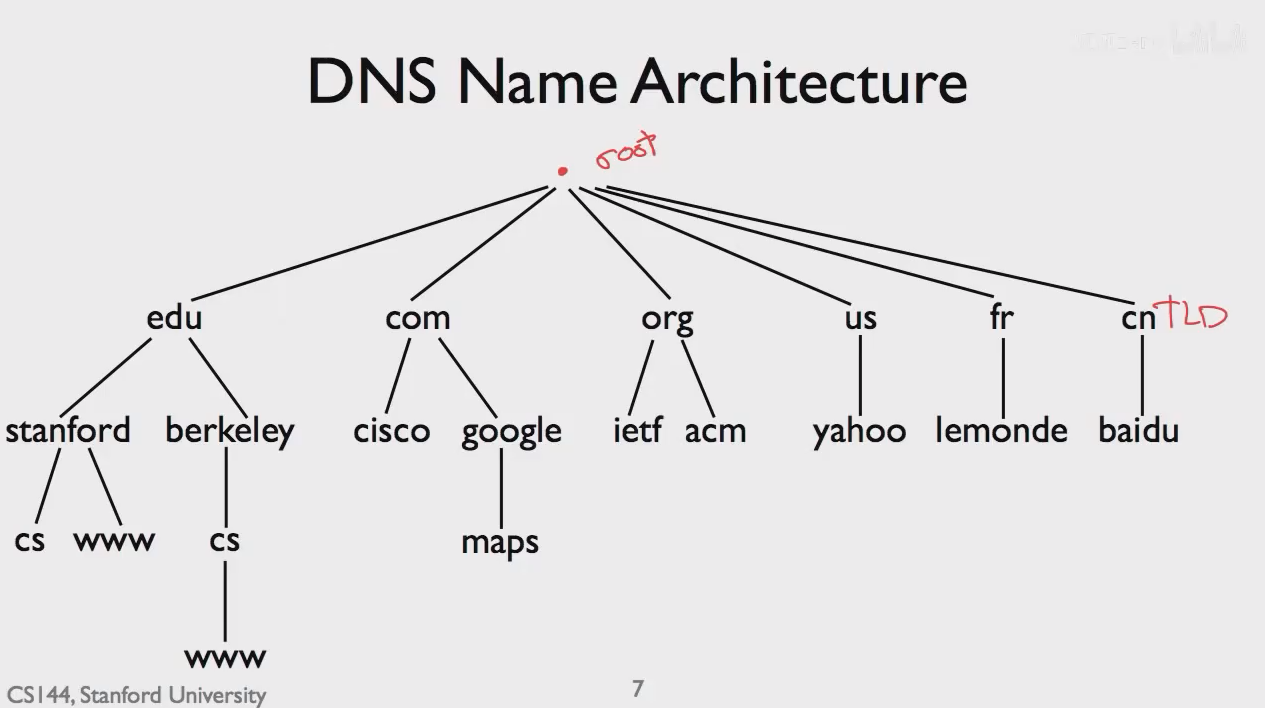
位于顶部的root是根域名服务器,全球只有13个根服务器。服务器采取高度复制的特性,不仅提高了网络的健壮性,而且提高了性能。(让用户访问里他们最近的那台服务器)
查询解析流程:DNS查询分为递归查询和迭代查询,前者由客户端向解析器发起,期望得到最终的一个IP地址,客户端不参与中间的查询过程。迭代查询由解析器向各级权威服务器发起,当客户端需要访问一个域名www.wuhu.com时,如果它在查询的任何阶段都没有对应的缓存条目(即不知道com的IP地址,不知道wuhu.com的IP地址,不知道www.huwu.com的IP地址),解析器先询问谁管理com域名,得到管理com域名的服务器的IP地址后,再询问wuhu的IP地址,这样以此类推得到www.wuhu.com的IP地址并返回给客户端。
缓存机制和DNS中记录的修改:为避免每次查询都重复上面的过程,缓存是DNS的关键。由于DNS读取为主(一个域名的IP地址可能一年都不会变化)和最终一致性这两个特性,使得缓存机制值得并且可行。由于缓存机制的存在,当我们在权威服务器上修改一条A记录时,这个修改不会瞬间同步到全世界,大量的服务器还保有这条A记录的缓存。为了使“持有”旧缓存的用户在更改期间服务不会中断,我们会采取一下策略:提前将TTL降低;在DNS切换后,让新旧两个IP地址上的服务器同时在线运行一段时间。这样,我们可以实现平滑的过渡,确保了用户的体验。
DNS主要基于UDP工作:1.UDP相比TCP没有三次握手,对于一个只包含非常小的问题的DNS查询,延迟更低,性能更高。2.UDP是无连接的,意味着UDP也是无状态的,一次交互之后服务器可以完全忘记这次交互,使得DNS服务器可以轻松应对来自全球的海量查询。
资源记录(Resource Records):资源记录是DNS数据库中的基本数据单元。每一条资源记录都是一条关于特定域名的声明或信息。当你说“解析一个域名”时,你实际上是在请求DNS服务器返回与该域名相关的一条或多条资源记录。
rdata:记录的具体内容,取决于type,如果type是A,那么data就是一个IPV4地址。A records(address records )会告诉你IP地址,NS records则是指示你需要的权威服务器的域名。
DNS查询和响应报文的通用报文格式的头部:
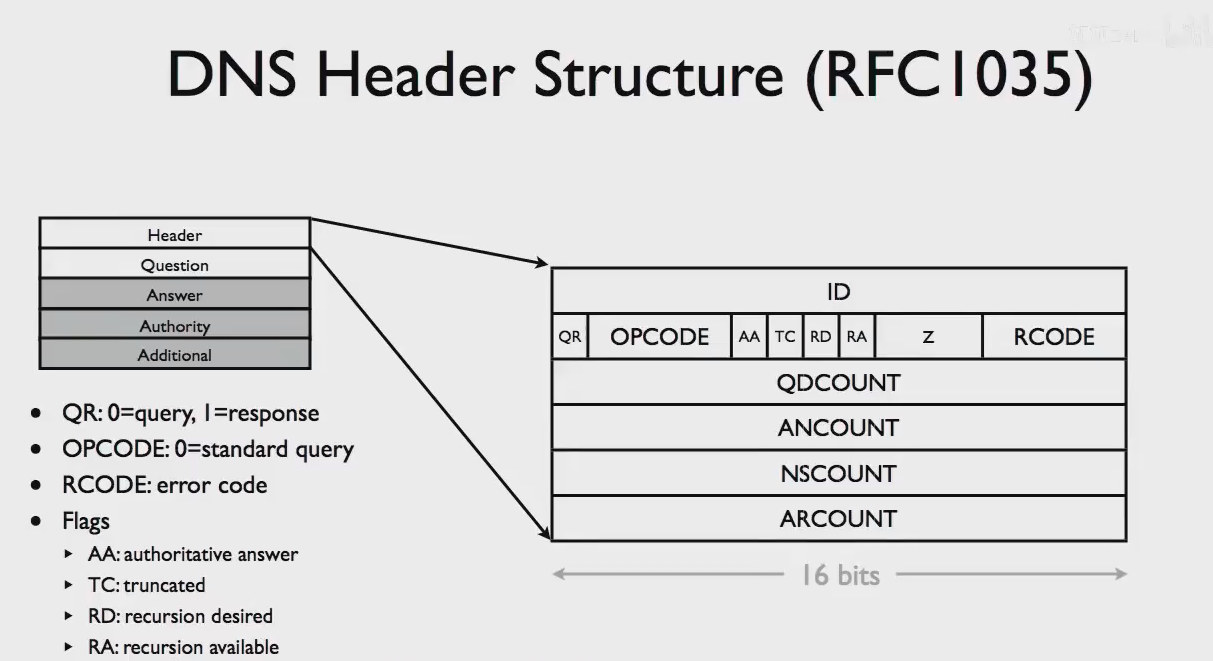
DNS域名压缩机制:

由于一个DNS报文中,同一个域名或其一部分常常会重复出现多次,所以域名会被拆成一个个标签,例如 www.stanford.edu 被拆分成 www, stanford, edu。每个标签在编码时,前面加上一个字节表示标签长度。整个域名的末尾用一个长度为0的字节0x00表示根域名,标志域名的结束。例如www.stanford.edu 的网络线路格式 (wire format) 是: \x03www\x08stanford\x03edu\x00
\x03www: 长度为3,内容是"www"。\x08stanford: 长度为8,内容是"stanford"。\x03edu: 长度为3,内容是"edu"。\x00: 长度为0,表示结束。
再然后利用指针机制来压缩。由于一个标签最大长度是63字节,即00111111。这意味着一个合法长度字节,其最高两位永远是00。借此,我们把指针设定为两字节,11xxxxxx yyyyyyyy的形式。每当DNS遇到一个域名长度字节,这个字节(8位)有两种不同的可能性,如果它的首两位是00,那么它是一个域名长度字节,如果它的首两位是11,那么它是一个指针字节。指针的两字节刨除11的那两位,剩余的14位组成一个无符号整数,表示一个偏移量,这个14位的偏移量,指向的是从整个DNS报文的起始位置(即ID字段的第一个字节)开始计算的字节偏移。这样,一个标签从长度字节(一字节)+标签名(最多63字节)被转换为了两字节的指针。
胶水记录(clue record):为了解决这样的问题:在我向.com服务器询问并寻找example.com的权威服务器时其域名为nsl.example.com,此时根据规则我应该先去查找example.com的权威服务器,但其权威服务器就是nsl.example.com本身。为了打破这个循环,这里的.com服务器一开始就应该在提供权威服务器的NS记录时,同时提供该权威服务器的IP地址(A或AAAA记录),这样就可以直接到权威服务器那去问询了。
CNAME record:其作用是为一个域名设置别名,当DNS解析器查询得到CNAME记录时,它会转而去查询CNAME记录之后的真正的名字。一个域名一旦被设置为CNAME域名,它就不能再拥有任何其他类型的DNS记录。
MX record(Mail Exchange Record):MX记录负责接收邮件的服务器的完全限定域名,这个主机名自身必须能通过A或AAAA记录解析到一个IP地址。(所以这个主机名不能是CNAME record)MX记录不能直接指向一个IP地址。
DHCP(Dynamic Host Configuration Protocol): 
如何获取这些重要信息?通过人工,那么工作量巨大并且容易出错,而DHCP通过一个客户端-服务器模型将这个过程完全自动化,解决了以上问题。当一台电脑刚刚接入wifi时:
1.以广播的形式发送DHCPDISCOVER类型信息,寻找DHCP服务器。
2.DHCP服务器收到消息后,也以广播的形式(因为此时客户端还没有可供单播的IP地址)发送DHCPOFFER类型的信息,并在信息中提供一个未被占用的IP地址。
3.客户端可能收到来自多个DHCP服务器的Offer,它会选择一个,然后再次发送DHCPREQUEST类型的广播包,表示接收了由服务器XXX提供的XXX IP地址。其他服务器看到后,就会把自己提供的那个预留的IP地址收回。
4.最后被选中的DHCP服务器以广播的形式发送一个DHCPACK类型的消息,表示确认了租约。
注:1.DHCP提供的IP地址不是永久的,客户端在一定时间时会发送续约请求。
2.DHCP基于UDP协议工作。DHCP服务器监听在 UDP 67 端口,客户端监听在 UDP 68 端口。
3.DHCP不仅仅提供IP地址。一个完整的DHCP响应包含了客户端上网所需的所有基本要素(图片中)。
4.DHCPDISCOVER和DHCPREQUEST类型信息还有源IP地址为0.0.0.0,目标IP地址为255.255.255.255,这是用于广播的广播地址。源MAC地址为客户端MAC地址,目标MAC地址为FF:FF:FF:FF:FF:FF,这是以太网的广播地址。
5.OFFER类型和ACK类型信息源IP为服务器IP,目标IP也为255.255.255.255(广播),源MAC为客户端MAC,目标MAC为FF:FF:FF:FF:FF:FF(广播)。
6.DHCP报文内容中也有MAC地址,客户端/服务器根据这个MAC地址来判断是不是发给自己的信息。