自然语言处理分享系列-词向量空间中的高效表示估计(二)
目录
一、模型架构
1.1 前馈神经网络语言模型(NNLM)
主要计算瓶颈
模型实现细节
效率优化意义
1.2 循环神经网络语言模型(RNNLM)
词向量表示 D 的维度与隐藏层 H 相同
技术说明
应用场景
1.3 神经网络的并行训练
二、 新的对数线性模型
2.1 连续词袋模型(Continuous Bag-of-Words Model)
模型命名与区别
架构描述
关键特性说明
2.2 连续Skip-gram模型
技术逻辑解析
上篇文章:自然语言处理分享系列-词向量空间中的高效表示估计(一)
一、模型架构
多种不同的模型被提出用于估计词的连续表示,包括众所周知的潜在语义分析(LSA)和潜在狄利克雷分配(LDA)。本文重点关注通过神经网络学习的词分布式表示,因为已有研究表明,此类表示在保持词间线性规律性方面显著优于LSA [20, 31];而LDA在大型数据集上的计算成本极高。
与[18]类似,为比较不同模型架构,首先将模型的计算复杂度定义为完整训练模型时需要访问的参数数量。随后,在最小化计算复杂度的同时,力求最大化模型准确性。
对于以下所有模型,训练复杂度正比于公式:
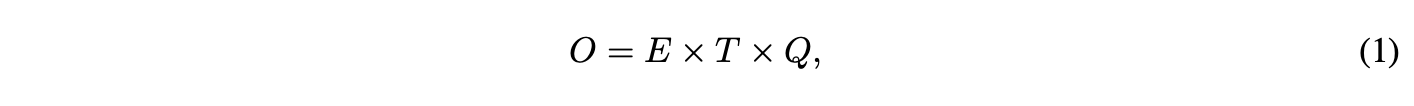
其中,( E ) 为训练轮次,( T ) 为训练集中的词数量,( Q ) 的值因模型架构而异。通常选择 ( E = 3 - 50 ),( T ) 可达十亿量级。所有模型均采用随机梯度下降和反向传播进行训练 [26]。
1.1 前馈神经网络语言模型(NNLM)
概率型前馈神经网络语言模型在文献[1]中提出。该模型由输入层、投影层、隐藏层和输出层构成。
输入层通过1-of-V编码对前N个词进行编码,其中V为词汇表大小。随后,输入层通过共享的投影矩阵映射到维度为N×D的投影层P。由于任意时刻仅N个输入处于激活状态,投影层的组合计算成本较低。
在投影层与隐藏层之间的计算上,NNLM架构较为复杂,因为投影层的值为密集矩阵。当N=10时,投影层(P)的规模通常为500至2000,而隐藏层单元数H一般为500至1000。此外,隐藏层需计算词汇表中所有词的概率分布,导致输出层维度为V。因此,每个训练样本的计算复杂度为
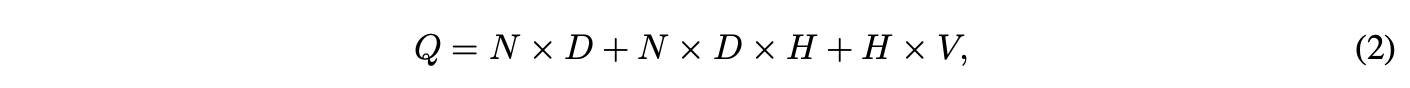
主要计算瓶颈
计算复杂度主要由 H × V 主导。为解决这一问题,实际应用提出了多种方案:采用分层形式的 softmax(如层次 softmax),或在训练时直接使用非归一化模型(如未归一化概率模型)。若使用二叉树表示词汇表,需评估的输出单元数量可降至 log₂(V) 左右。因此,大部分计算负担源于 N × D × H 项。
模型实现细节
所描述的模型采用基于霍夫曼二叉树的层次 softmax。这一选择基于先前研究结论:单词频率能有效指导神经网络语言模型中的类别划分。霍夫曼树为高频词分配较短的二进制编码,从而进一步减少需评估的输出单元数量——平衡二叉树需评估 log₂(V) 个输出,而霍夫曼树仅需约 log₂(Unigram perplexity(V))。例如,当词汇量为 100 万时,评估速度可提升约两倍。
效率优化意义
虽然对神经网络语言模型而言,此加速并非关键(因计算瓶颈在于 N × D × H 项),但后续提出的无隐藏层架构将高度依赖 softmax 归一化的效率,此时层次 softmax 的优势尤为重要。
1.2 循环神经网络语言模型(RNNLM)
基于循环神经网络的语言模型被提出,旨在克服前馈神经网络语言模型(NNLM)的某些局限性,例如需要预先指定上下文长度(即模型的阶数N)。从理论上讲,循环神经网络(RNN)能够比浅层神经网络更高效地表示复杂模式。
RNN模型不包含投影层,仅由输入层、隐藏层和输出层构成。其核心特点是循环权重矩阵,该矩阵通过时间延迟连接将隐藏层与自身相连。这种机制使模型能够形成一种短期记忆:历史信息可通过隐藏层状态传递,而该状态会根据当前输入及前一时间步的隐藏层状态动态更新。
RNN模型在每个训练样本上的计算复杂度为
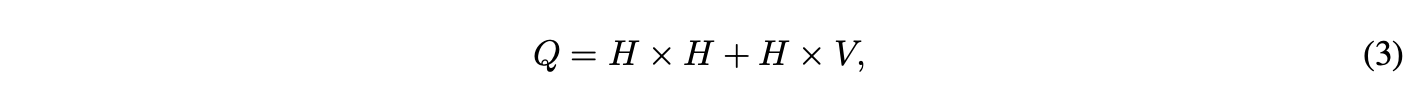
词向量表示 D 的维度与隐藏层 H 相同
通过使用分层 softmax,项 H × V 可高效降维至 H × log2(V)。模型的主要复杂度来源于 H × H 的计算。
技术说明
- D 与 H 同维:词向量(D)和隐藏层(H)的维度设计一致,确保向量空间对齐。
- 分层 softmax 优化:将词汇表大小(V)的线性依赖转化为对数级(log2(V)),显著降低计算成本。
- 复杂度核心:模型的计算负担集中于隐藏层之间的交互(H × H),而非词表规模。
应用场景
适用于需要平衡计算效率与模型性能的任务,如大规模语言建模或推荐系统。
1.3 神经网络的并行训练
为在大规模数据集上训练模型,基于名为DistBelief的大规模分布式框架实现了多种模型,包括前馈神经网络语言模型(NNLM)及本文提出的新模型。该框架支持并行运行同一模型的多个副本,各副本通过集中式服务器同步梯度更新,该服务器负责维护所有参数。
并行训练采用小批量异步梯度下降法,并搭配自适应学习率调整策略Adagrad。在此框架下,通常使用上百个模型副本,每个副本在数据中心的不同机器上调用多核CPU资源进行运算。
二、 新的对数线性模型
本节提出两种新的模型架构,用于学习词的低维分布式表示,旨在降低计算复杂度。前一节的观察表明,模型的主要复杂度源于非线性隐含层。尽管非线性结构是神经网络的核心优势,但研究转向探索更简单的模型——这些模型可能无法像神经网络那样精确表征数据,但能以更高效率处理大规模数据。
新架构直接延续了早期工作[13,14]的成果,其中发现神经网络语言模型可通过两步有效训练:先用简单模型学习连续的词向量,再基于这些分布式表示训练N-元神经网络语言模型。尽管后续大量研究聚焦于词向量学习,[13]提出的方法仍被视为最简洁的路径。需注意,类似模型在更早的研究中已有雏形[26,8]。
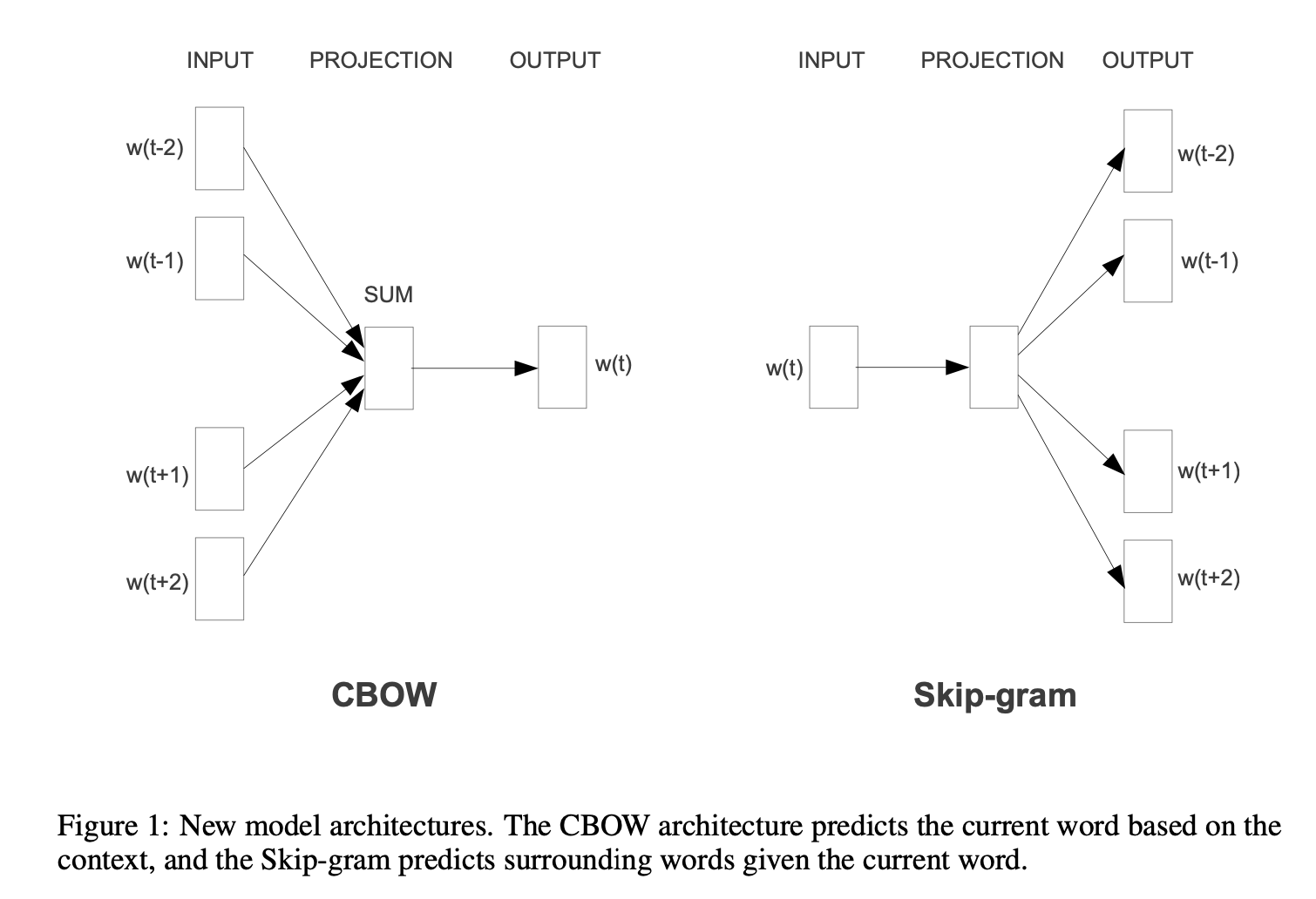
2.1 连续词袋模型(Continuous Bag-of-Words Model)
首次提出的架构与前馈神经网络语言模型(NNLM)类似,但移除了非线性隐藏层,且投影层在所有词之间共享(不仅是投影矩阵)。因此,所有词被映射到同一位置(其词向量被平均)。由于历史词的顺序不影响投影结果,该架构被称为词袋模型。此外,模型还使用未来词:通过在输入中引入四个历史词和四个未来词,构建对数线性分类器,以正确分类当前(中间)词作为训练目标,从而在后续章节介绍的任务中达到最佳性能。此时训练复杂度为
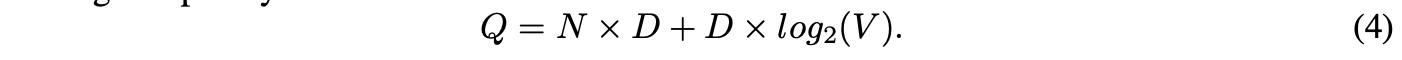
模型命名与区别
该模型后续称为CBOW(连续词袋模型),与标准的词袋模型不同,它采用上下文的连续分布式表示。
架构描述
模型架构如图1所示。需注意的是,输入层与投影层之间的权重矩阵在所有词位置上共享,这与NNLM(神经网络语言模型)中的方式相同。
关键特性说明
- 共享权重机制:同一权重矩阵应用于所有上下文词位置,确保分布式表示的连续性。
- 与NNLM的关联:继承了NNLM的权重共享思想,但专注于上下文词向量的聚合预测。
2.2 连续Skip-gram模型
第二种架构与CBOW类似,但其目标并非基于上下文预测当前词,而是最大化对同一句子中其他词的分类准确性。具体而言,每个当前词作为输入,通过带连续投影层的对数线性分类器,预测一定窗口范围内当前词前后的词。实验表明,增大窗口范围可提升词向量的质量,但也会增加计算复杂度。由于较远的词通常与当前词相关性较低,训练时通过减少对这些词的采样频率来降低其权重。
该架构的训练复杂度与以下因素成正比:
- 窗口大小的调整范围
- 词向量维度的设定
- 语料库中词的总数
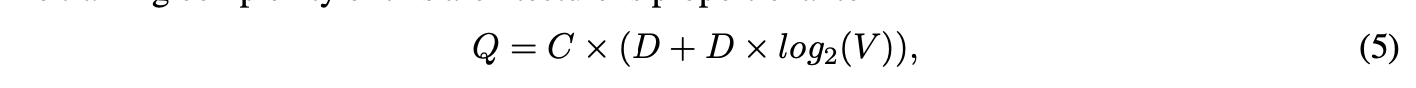
其中,C代表词语的最大距离。若设定C=5,对于每个训练词,程序会随机在区间<1; C>内选取一个数值R,并以当前词为中心,从历史上下文和未来上下文中各选取R个词作为正确标签。该操作需要执行R×2次词语分类任务,每次以当前词作为输入,R+R个上下文词分别作为输出。在后续实验中,采用C=10作为参数值。
技术逻辑解析
该方法通过动态调整上下文窗口大小(R∈[1,C]),增强模型对局部语境的捕捉能力。每次训练时随机化的R值能够防止模型过度依赖固定窗口长度,从而提升泛化性能。实验中选择C=10表明最大上下文半径扩展至10个词,此举可能针对长距离语义依赖场景进行了优化。
本篇关于模型架构就描述到这里,后面的实验结果可以看下篇文章
传送门: