排查 TCP 连接中 TIME_WAIT 状态异常
在高并发网络场景下(比如 Web 服务器、API 网关、微服务调用),你是否遇到过这样的问题:服务器明明 CPU、内存都充足,却频繁报 “address already in use” 错误,新连接死活建立不起来?查看网络连接时,发现大量 TCP 连接处于TIME_WAIT状态 —— 这很可能是TIME_WAIT异常导致的端口耗尽或资源占用问题。
本文将从基础原理入手,带你一步步掌握TIME_WAIT异常的排查流程,包括用netstat/ss命令定位问题、分析根源,以及通过内核参数和业务优化彻底解决问题,适合运维、开发和 DevOps 工程师参考。
一、先搞懂:TIME_WAIT 是什么?为什么会存在?
在排查异常前,我们得先明白TIME_WAIT的 “本职工作”—— 它不是 “故障”,而是 TCP 协议设计的 “安全机制”。
TCP 连接关闭时会经历 “四次挥手”,其中主动关闭连接的一方(通常是客户端,也可能是服务端)会进入TIME_WAIT状态,主要作用是:
- 确保最后一个 ACK 报文被对方接收:如果对方没收到 FIN 的 ACK,会重发 FIN,
TIME_WAIT状态能让主动关闭方有足够时间接收并重发 ACK; - 避免 “旧连接的残留报文” 干扰新连接:TCP 报文可能因网络延迟滞留,
TIME_WAIT会等待 “最大报文生存时间(MSL)” 的 2 倍(默认约 60 秒),确保滞留报文失效后再释放端口。
正常情况下,TIME_WAIT会在 60 秒后自动释放,数量与并发短连接数正相关(比如每秒 1000 个短连接,TIME_WAIT峰值可能在几万)。但当TIME_WAIT数量远超业务正常范围,或持续不释放时,就会引发异常。
二、第一步:如何判断 TIME_WAIT 是否 “异常”?
不是所有TIME_WAIT都需要处理,先明确两个判断标准:
1. 数量阈值:超过业务合理范围
- 常规场景:非高并发服务,
TIME_WAIT数量应控制在1 万以内; - 高并发场景(如秒杀、大促):短连接服务的
TIME_WAIT可能达到2-5 万,但需结合端口范围判断(Linux 默认本地端口范围是 32768-60999,约 2.8 万个端口,超过这个数会端口耗尽); - 异常信号:
TIME_WAIT数量持续超过5 万,或短时间内从几千飙升到几十万,且伴随新连接失败(如 “connection refused”“address already in use”)。
2. 系统日志:出现明确报错
当TIME_WAIT超过内核限制时,Linux 会在日志中留下痕迹,查看方法:
# 查看内核日志中的TIME_WAIT溢出报错
grep "TCP: time wait bucket table overflow" /var/log/kern.log# 查看端口耗尽相关报错
grep "address already in use" /var/log/messages
如果出现 “time wait bucket table overflow”,说明TIME_WAIT数量已经超过了tcp_max_tw_buckets参数的限制,内核开始主动丢弃新的TIME_WAIT连接 —— 这是典型的TIME_WAIT异常信号。
三、第二步:用工具分析 TIME_WAIT 连接的 “真面目”
确认异常后,下一步是用netstat或ss命令(ss更高效,推荐)分析TIME_WAIT连接的来源、特征,定位问题根源。
1. 统计 TIME_WAIT 连接总数
先快速掌握整体情况,执行以下命令:
# 方法1:用ss统计(推荐,速度快,适合高并发场景)
ss -ant | grep TIME-WAIT | wc -l# 方法2:用netstat统计(兼容性好,但高并发下较慢)
netstat -nat | grep TIME_WAIT | wc -l
ss -ant:-a(显示所有连接)、-n(IP / 端口用数字显示,不解析域名)、-t(仅 TCP 连接);grep TIME-WAIT:过滤出TIME_WAIT状态的连接;wc -l:统计行数(即连接数)。
比如执行结果是68243,远超默认端口范围(2.8 万),说明已出现端口耗尽风险。
2. 分析 TIME_WAIT 连接的 “来源特征”
光看总数不够,还要知道这些TIME_WAIT连接来自哪里 —— 是某个客户端的大量短连接?还是服务端主动关闭导致的?
(1)按 “对端 IP” 分组:看是否集中在某个 IP
# 统计每个对端IP的TIME_WAIT连接数,取前10名
ss -ant | grep TIME-WAIT | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nr | head -n 10
- 解释:
$5是对端 IP: 端口,cut -d: -f1提取 IP 部分,sort | uniq -c统计每个 IP 的连接数,sort -nr按数量倒序。
结果解读:
- 如果某个 IP 的连接数占比超过 50%(比如 1 个 IP 有 3 万 +
TIME_WAIT),可能是该客户端(如爬虫、压测工具、异常服务)发起了大量短连接,且未控制频率; - 如果对端 IP 分散,说明是正常业务的并发短连接(如用户浏览器请求),需从服务端优化。
(2)按 “本地端口” 分组:看是否集中在某个服务端口
bash
# 统计每个本地端口的TIME_WAIT连接数,取前10名
ss -ant | grep TIME-WAIT | awk '{print $4}' | cut -d: -f2 | sort | uniq -c | sort -nr | head -n 10
- 解释:
$4是本地 IP: 端口,cut -d: -f2提取端口部分。
结果解读:
- 如果本地端口集中在某个服务端口(如 8080、443),说明服务端是主动关闭方(正常应是客户端主动关闭,比如 HTTP 请求由浏览器断开),可能是服务端设置了过短的连接超时时间(如 10 秒),强制关闭未活跃连接。
四、第三步:定位 TIME_WAIT 异常的 4 个常见根源
通过工具分析后,结合业务场景,通常能定位到以下 4 类根源:
1. 根源 1:短连接设计不合理(最常见)
场景:服务端与客户端采用 “一次请求一连接” 的短连接模式(如 HTTP/1.0 默认短连接、自定义 TCP 协议未复用连接),且请求频率极高(如每秒数千次)。举例:某电商 API 服务用 HTTP/1.0 协议,每个用户请求都新建 TCP 连接,请求完成后立即关闭,导致服务端(或客户端)积累大量TIME_WAIT。
2. 根源 2:连接关闭方向异常
场景:本应客户端主动关闭的连接,因业务逻辑错误,变成服务端主动关闭。举例:Web 服务器配置了keepalive_timeout 5s(连接空闲 5 秒就主动关闭),而客户端(浏览器)默认保持连接 30 秒,导致服务端成为主动关闭方,积累TIME_WAIT。
3. 根源 3:网络波动导致重连
场景:跨机房、跨地域链路不稳定(如丢包、延迟),客户端未收到服务端的 FIN 报文,认为连接未关闭,反复发起新连接;服务端则认为旧连接已超时,关闭后进入TIME_WAIT。举例:某跨城微服务调用,因链路丢包,客户端 1 分钟内重连 1000 次,服务端积累 1000 个TIME_WAIT。
4. 根源 4:内核参数配置不合理
场景:tcp_max_tw_buckets(TIME_WAIT最大数量限制)设置过小,或未开启TIME_WAIT复用 / 快速回收,导致TIME_WAIT无法及时释放。举例:某服务器tcp_max_tw_buckets默认 180000,但实际业务需要 20 万TIME_WAIT,超过后内核丢弃新连接,报 “time wait bucket table overflow”。
五、第四步:解决 TIME_WAIT 异常的两大方案
解决TIME_WAIT异常需 “双管齐下”:内核参数优化(缓解症状)+ 业务层优化(根治根源),避免只依赖内核参数而忽略业务设计问题。
方案 1:内核参数优化(快速缓解)
修改 Linux 内核 TCP 参数前,先备份/etc/sysctl.conf(防止配置错误导致系统异常):
cp /etc/sysctl.conf /etc/sysctl.conf.bak
以下是核心参数的配置方法和说明:
(1)调整 TIME_WAIT 最大数量:tcp_max_tw_buckets
- 作用:限制系统中
TIME_WAIT连接的最大数量,超过此值后,新的TIME_WAIT会被内核丢弃(并记录日志); - 默认值:多数 Linux 发行版默认 180000(18 万);
- 配置建议:根据业务并发量调整,不建议超过 100 万(否则占用过多内存,每个
TIME_WAIT约占 0.5KB 内存)。
# 临时生效(重启后失效)
sysctl -w net.ipv4.tcp_max_tw_buckets=300000# 永久生效(写入/etc/sysctl.conf)
echo "net.ipv4.tcp_max_tw_buckets=300000" >> /etc/sysctl.conf
sysctl -p # 加载配置
(2)开启 TIME_WAIT 复用:tcp_tw_reuse
- 作用:允许将
TIME_WAIT状态的连接复用为新的连接(仅适用于客户端,即主动发起连接的一方,如微服务调用端); - 前提:必须开启
tcp_timestamps(默认开启,net.ipv4.tcp_timestamps=1); - 适用场景:客户端需要向同一服务端发起大量短连接(如爬虫、API 调用客户端)。
# 临时生效
sysctl -w net.ipv4.tcp_tw_reuse=1# 永久生效
echo "net.ipv4.tcp_tw_reuse=1" >> /etc/sysctl.conf
sysctl -p
(3)缩短 TIME_WAIT 停留时间:tcp_fin_timeout
- 作用:缩短
TIME_WAIT状态的停留时间(默认 60 秒,即 2 个 MSL),加速端口释放; - 配置建议:非关键业务可缩短至 30 秒(需评估网络延迟,避免过早释放导致报文冲突),核心业务不建议小于 20 秒。
# 临时生效
sysctl -w net.ipv4.tcp_fin_timeout=30# 永久生效
echo "net.ipv4.tcp_fin_timeout=30" >> /etc/sysctl.conf
sysctl -p
(4)慎用!已废弃的参数:tcp_tw_recycle
- 说明:此参数曾用于快速回收
TIME_WAIT,但在 NAT 环境(如局域网共享出口 IP、云服务器)中会导致连接失败(同一 IP 的不同客户端被误认为同一连接),且在 Linux 4.12 + 版本已移除,强烈不建议使用。
方案 2:业务层优化(根治根源)
内核参数只是 “缓解剂”,真正解决问题需要优化业务设计:
1. 用长连接替代短连接(最有效)
- HTTP 服务:升级到 HTTP/1.1 或 HTTP/2,启用
Connection: keep-alive(默认开启),让连接复用(比如一个连接处理 100 个请求后再关闭); - 自定义 TCP 服务:设计连接池(如数据库连接池、RPC 连接池),避免每次请求都新建连接;
- 微服务调用:用 gRPC(基于 HTTP/2)替代 REST API,或在 REST API 中启用连接复用。
2. 调整连接关闭方向
- 确保客户端成为主动关闭方:比如 Web 服务器延长
keepalive_timeout(如设置为 60 秒),让客户端(浏览器)先发起关闭; - 避免服务端强制关闭:除非业务需要(如连接长时间空闲),否则不设置过短的超时时间。
3. 扩大本地端口范围(缓解端口耗尽)
如果因端口不足导致异常,可扩大本地端口范围(默认 32768-60999,约 2.8 万个端口):
# 临时生效:扩大到1024-65535(约6.4万个端口)
sysctl -w net.ipv4.ip_local_port_range="1024 65535"# 永久生效
echo "net.ipv4.ip_local_port_range=1024 65535" >> /etc/sysctl.conf
sysctl -p
4. 控制并发连接频率
- 对客户端(如爬虫、压测工具)设置连接速率限制(如每秒最多 100 个新连接);
- 服务端启用限流(如 Nginx 的
limit_conn模块),避免单 IP 发起过多连接。
六、实战案例:某 Web 服务 TIME_WAIT 激增的排查过程
最后用一个真实案例,带你回顾完整排查流程:
问题现象
某电商 Web 服务器(Nginx+Tomcat)在大促期间,新用户无法打开页面,报 “连接超时”;服务器日志频繁出现 “address already in use”。
排查步骤
- 确认异常:执行
ss -ant | grep TIME-WAIT | wc -l,结果显示72345(远超端口上限 2.8 万);查看内核日志,有 “TCP: time wait bucket table overflow” 报错。 - 定位来源:按本地端口分组统计,发现
TIME_WAIT集中在 80 端口(Nginx 服务端口),说明 Nginx 是主动关闭方。 - 分析根源:检查 Nginx 配置,发现
keepalive_timeout 10s(连接空闲 10 秒就关闭),而用户浏览器默认保持连接 30 秒,导致 Nginx 主动关闭连接,积累TIME_WAIT。 - 优化解决:
- 业务层:将 Nginx 的
keepalive_timeout调整为 60 秒,让浏览器先关闭连接; - 内核层:开启
tcp_tw_reuse=1,缩短tcp_fin_timeout=30;
- 业务层:将 Nginx 的
- 验证效果:优化后
TIME_WAIT数量降至 1.2 万,新连接正常建立,无 “连接超时” 报错。
七、总结:TIME_WAIT 异常排查流程
最后用一张流程图总结排查步骤,方便你实际操作时参考:
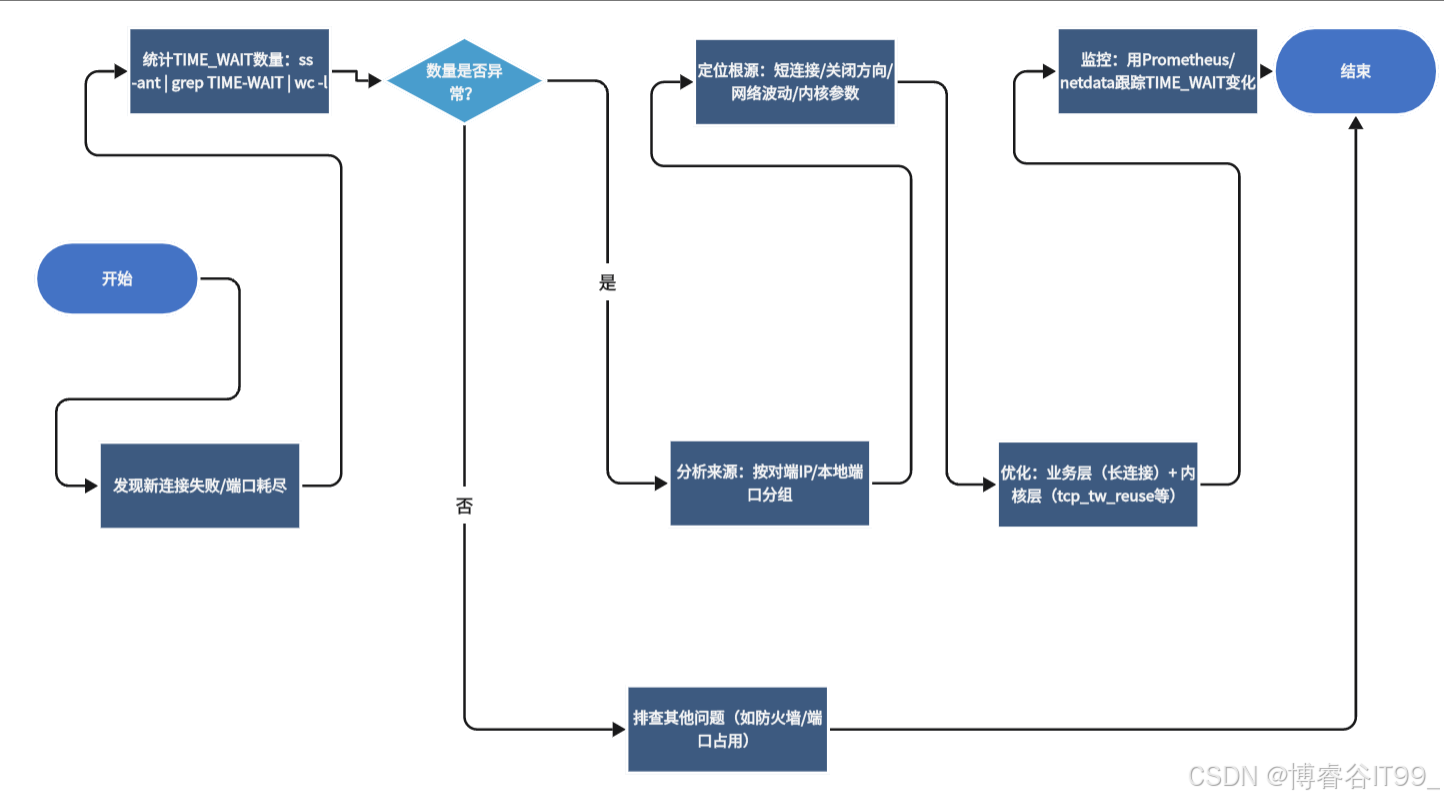
记住:TIME_WAIT本身不是 “敌人”,而是 TCP 的 “安全卫士”。排查异常的核心是找到 “异常激增的根源”,通过业务设计优化减少TIME_WAIT的产生,再结合内核参数提升资源利用率 —— 两者结合才能彻底解决问题,确保服务稳定运行。