大模型文生图和语音转换的调用以及向量和向量数据库RedisStack.
文生图
我们用的很多的AI都可以给通过我们的描述来进行图形的生成,当然了阿里云的百炼平台也提供了API的调用供我们进行使用。大模型服务平台百炼控制台 我们通过文生图的大模型帮助文档就可以实现我们需要要求。
对于这个方法的使用,我们和前面一样,前面对于的是文本之间的对话,所以图片的生成我们依旧可以使用ImageModel相关的API
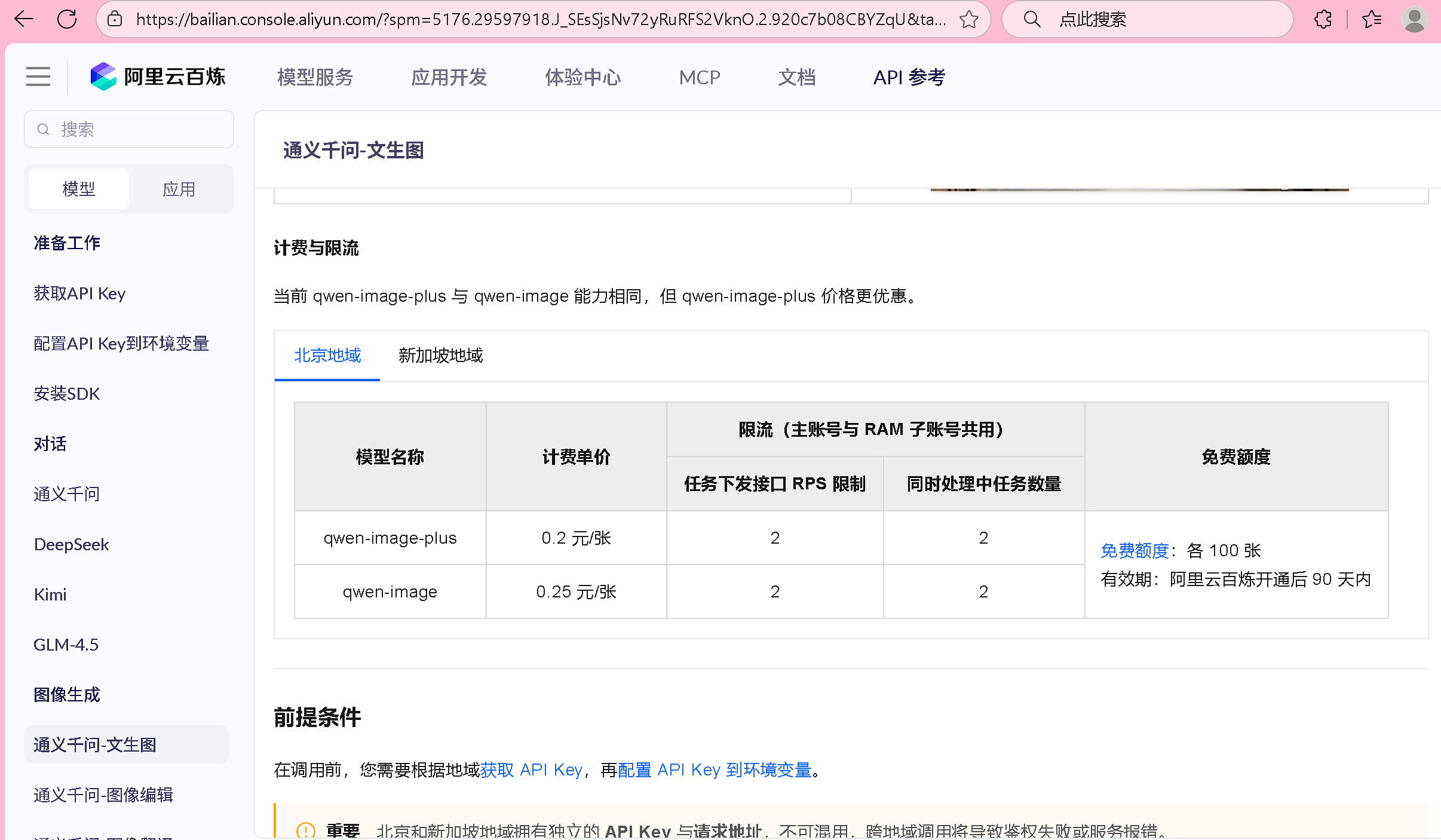
package ai.controller;
import com.alibaba.cloud.ai.dashscope.image.DashScopeImageOptions;
import jakarta.annotation.Resource;
import org.springframework.ai.image.ImageModel;
import org.springframework.ai.image.ImagePrompt;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TextImageController {public static final String IMAGE_MODEL="wanx2.1-t2i-turbo";
@Resourceprivate ImageModel imageModel;
@GetMapping("ImageModel/DoChat")public String DoChat(@RequestParam (name = "prompt",defaultValue = "苹果") String prompt) {return imageModel.call(new ImagePrompt(prompt, DashScopeImageOptions.builder().withModel(IMAGE_MODEL).build())).getResult().getOutput().getUrl();}
}我们生成的图片实际上就是调用大模型生成的一张图片,所以给我们返回的就是图片的路径,同时返回的时间也是很慢的。

我们只要访问这张图片就可以得到下图中所表示的图片。

语音合成
我们依旧可以阿里云的百炼平台上面实现图片的合成,跟前面一样,我们依旧准备好maven依赖,控制台直接进行调用即可。

因为我们再调用之后就会发现,服务端立即处理并返回完整的语音合成效果,这个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下一步操作,所以我们在使用的时候建议选择流式输出。
我们可以在帮助文档里面寻找自己喜欢的音色进行设置:

选定好之后就可以在代码上进行实践:
package ai.controller;
import com.alibaba.cloud.ai.dashscope.audio.DashScopeSpeechSynthesisOptions;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisModel;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisPrompt;
import com.alibaba.cloud.ai.dashscope.audio.synthesis.SpeechSynthesisResponse;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.UUID;
@RestController
public class Text2VoiceController {@Resourceprivate SpeechSynthesisModel speechSynthesisModel;
public static final String BAILIAN_VOICE_MODEL="cosyvoice-v2";
public static final String BAILIAN_VOICE_TIMBER="longling_v2";
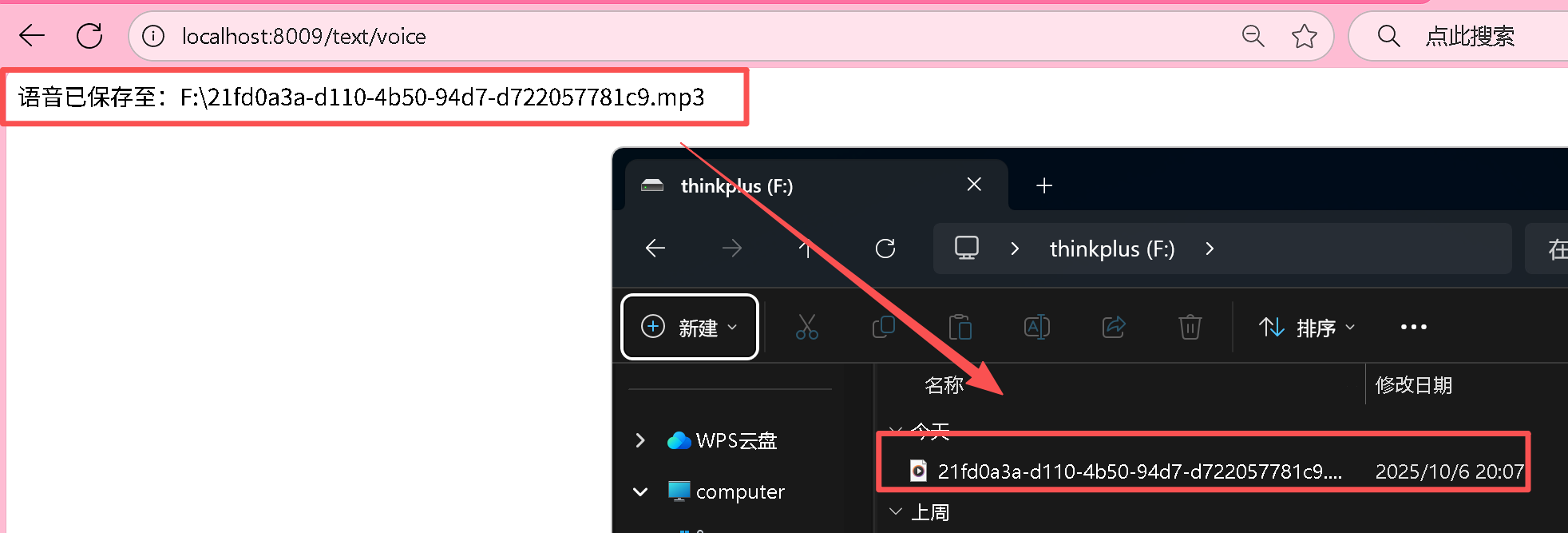
@GetMapping("/text/voice")public String text2voice(@RequestParam(name = "msg",defaultValue = "您好88号技师为您服务!") String msg) {//语音文件保存路径String filePath ="F:\\"+ UUID.randomUUID()+".mp3";//语音参数DashScopeSpeechSynthesisOptions options = DashScopeSpeechSynthesisOptions.builder().model(BAILIAN_VOICE_MODEL).voice(BAILIAN_VOICE_TIMBER).build();//调用大模型语音生成对象SpeechSynthesisResponse response = speechSynthesisModel.call(new SpeechSynthesisPrompt(msg, options));//字节流语音转换ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();
try(FileOutputStream fileOutputStream = new FileOutputStream(filePath)) {fileOutputStream.write(byteBuffer.array());} catch (IOException e) {System.out.println(e.getMessage());}return "语音已保存至:"+filePath;}
}通过对访问默认路径然后就可以实现文件的存储:
向量化和向量数据库
向量是什么?
Vector向量和矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者事实上是讲的同一件事。
向量是用于表示具有大小和方向的量。
事实上讲文本,音频,视频转化为向量的浮点数数组,然后放在坐标体系里面就会出现向量,也就是文本向量化。我们通过维度可以理解这个事情,在数学当中数值的向量中有x和y坐标,所以我们对于文本向量化就可以进行比喻:

因此我们可以将car的向量表示为(4,yes,yes,5)或者用数值表示(4,1,1,5)。同样的对于向量的比较,因为是进行多维度的比较,所以向量的比较主要就是大小和方向进行比较。
所以大模型进行识别图片的时候,其实就是把图片进行了向量化,假设你想描述不同的水果。你不用长篇大论,而是用数字来描述甜度、大小和颜色等特征。例如,苹果可能是[8,5,7]而香蕉是 [9,7,4]。这些数字使比较或对相似的水果进行分组变得更容易。
向量数据库
向量数据库和传统的数据库不一样,向量数据库是一种用于存储和检索高维向量数据的数据库或存储解决方案,它执行的是相似性搜索而不是精准查询。
向量数据库我们选择比较简单的redistack。
我们要想使用向量数据库,首先添加redis向量数据库依赖
<!--引入redisstack,也就是redis8--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency>我们引入redis依赖之后之后,我们就可以配置yml文件了
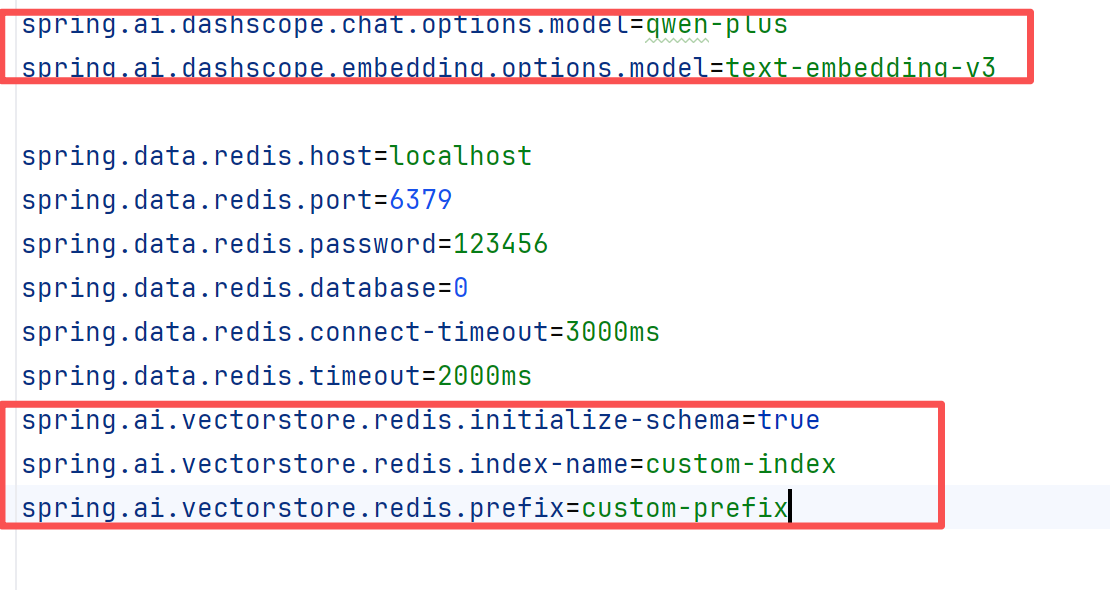
通过对阿里百联平台的查看我们可以看得出来,对于向量的使用需要确定好模型,然后进行新redis的配置,我们通过对学习文档的查询我们就可以得到,redisStack是支持json文件的查看,使用RedisCloud可以进行实例化。

RedisStack是什么呢?
RedisStack是RedisLabs推出的一个增强版的Redis,并不是Redis的替代品,而是在原生Redis的基础上的功能扩展包,专为构建现代实时应用而设计。