AI行业应用深度解析:从理论到实践的跨越
人工智能已不再是科幻概念,而是驱动各行业变革的核心引擎。它正通过自动化、智能化、个性化的方式,重塑商业模式、提升运营效率并创造前所未有的价值。以下,我们将深入四个关键领域,一探AI的落地风采。
一、金融领域:风控、投顾与合规的智能革命
金融行业是数据密集型行业,天然适合AI技术的应用。AI在金融领域的核心价值在于处理海量数据、识别复杂模式、实现实时决策和预测未来风险。
1.1 落地案例:智能信贷风控系统
背景与挑战:
传统信贷审批严重依赖人工审核信贷员的经验,存在主观性强、效率低下、标准不统一等问题,尤其面对海量的小微企业贷款或消费贷申请时,难以精准、快速地评估借款人风险。
解决方案:
构建一个基于机器学习的智能信贷风控系统。该系统通过整合用户的多维度数据(身份信息、履约历史、社交数据、消费行为等),训练信用评分模型,自动输出用户的信用评分和风险等级,为审批决策提供量化依据。
技术栈: Python, Scikit-learn, XGBoost, Flask, MySQL
系统架构与流程:
下面的Mermaid流程图清晰地展示了智能风控系统的核心工作流程:
flowchart TDA[用户提交贷款申请] --> B[数据获取与整合]subgraph B [数据获取与整合]B1[第三方征信数据]B2[用户提交数据]B3[内部历史数据]endB --> C[特征工程]C --> D{模型预测}D --> E[输出信用评分与风险等级]subgraph F [模型训练与更新]F1[历史数据] --> F2[特征工程]F2 --> F3[模型训练<br>XGBoost/LightGBM]F3 --> F4[模型评估与部署]endF -.-> DE --> G{决策引擎}G -- 低风险 --> H[自动批准]G -- 中等风险 --> I[人工审核]G -- 高风险 --> J[自动拒绝]H & I & J --> K[完成审批并反馈]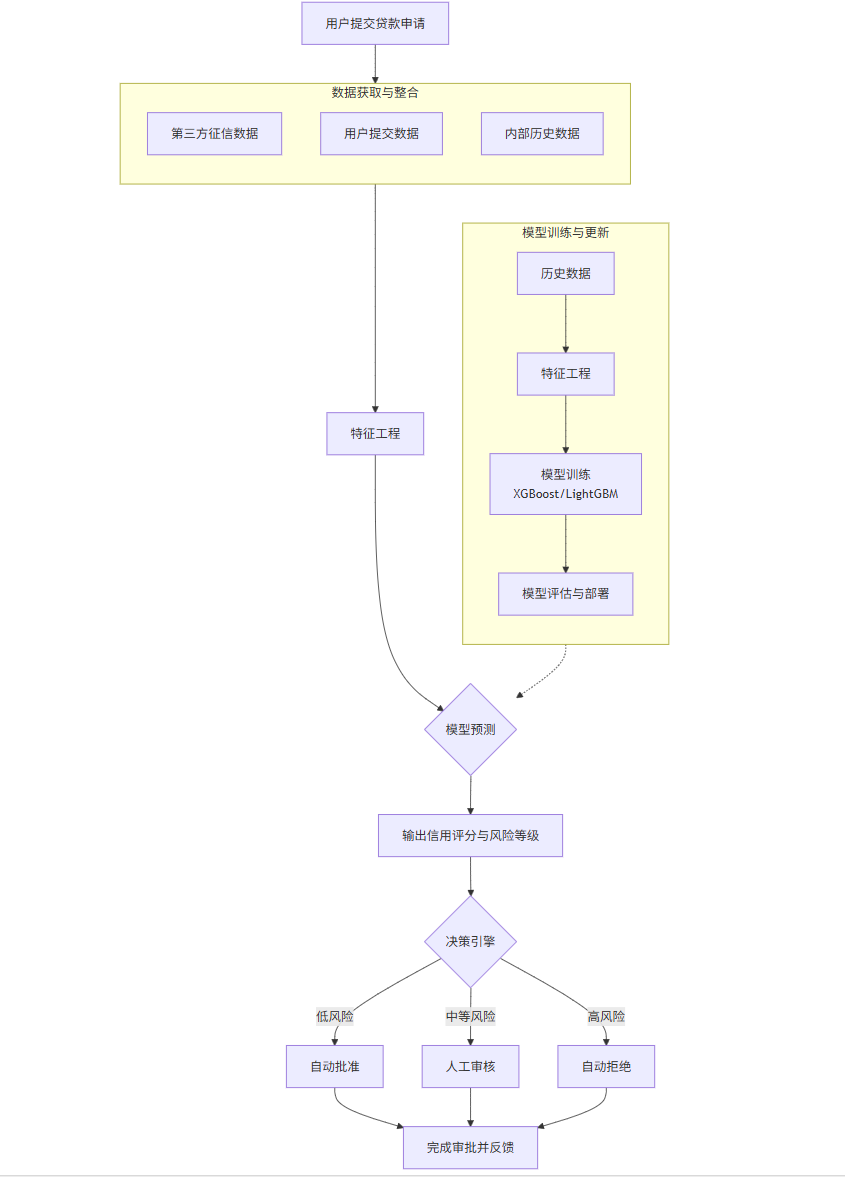
代码示例:模型训练与预测
我们使用XGBoost模型,因为它在大规模数据集上表现优异,且能有效处理缺失值。
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.preprocessing import StandardScaler
import xgboost as xgb
import joblib # 用于保存模型# 1. 加载和准备数据(这里使用模拟数据)
def generate_credit_data(n_samples=10000):np.random.seed(42)data = {'age': np.random.randint(18, 70, n_samples),'income': np.random.normal(50000, 20000, n_samples),'credit_history_length': np.random.randint(1, 30, n_samples),'debt_to_income_ratio': np.random.uniform(0.1, 0.8, n_samples),'number_of_open_accounts': np.random.randint(1, 15, n_samples),'number_of_past_due_30_days': np.random.poisson(0.5, n_samples),'number_of_past_due_60_days': np.random.poisson(0.1, n_samples),}df = pd.DataFrame(data)# 模拟一个简单的信用评分逻辑作为目标变量# 这里仅为示例,真实场景要复杂得多score = (df['income'] / 10000) - (df['debt_to_income_ratio'] * 20) - (df['number_of_past_due_60_days'] * 10)df['default'] = (score < np.percentile(score, 30)).astype(int) # 假设后30%会违约return dfdf = generate_credit_data()
print(df.head())# 2. 特征工程
features = ['age', 'income', 'credit_history_length', 'debt_to_income_ratio', 'number_of_open_accounts', 'number_of_past_due_30_days', 'number_of_past_due_60_days']
X = df[features]
y = df['default']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 特征标准化(树模型对标准化不敏感,但为了流程完整性和扩展性,这里保留)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 3. 训练XGBoost模型
model = xgb.XGBClassifier(n_estimators=100,max_depth=6,learning_rate=0.1,subsample=0.8,colsample_bytree=0.8,random_state=42,eval_metric='logloss'
)model.fit(X_train_scaled, y_train)# 4. 模型评估
y_pred = model.predict(X_test_scaled)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]print("Classification Report:")
print(classification_report(y_test, y_pred))
print(f"ROC-AUC Score: {roc_auc_score(y_test, y_pred_proba):.4f}")# 5. 保存模型和标准化器
joblib.dump(model, 'credit_risk_model.pkl')
joblib.dump(scaler, 'scaler.pkl')
print("Model and scaler saved successfully.")# 6. 模拟单笔预测
def predict_single_application(application_data, model_path, scaler_path):"""对单笔贷款申请进行预测application_data: 字典,包含所有特征值"""model = joblib.load(model_path)scaler = joblib.load(scaler_path)# 将字典转换为DataFrameapp_df = pd.DataFrame([application_data])app_scaled = scaler.transform(app_df)probability = model.predict_proba(app_scaled)[0, 1]prediction = model.predict(app_scaled)[0]risk_level = "低风险" if probability < 0.3 else "中等风险" if probability < 0.7 else "高风险"return {'default_probability': probability,'prediction': '违约' if prediction == 1 else '正常','risk_level': risk_level}# 测试单笔预测
new_application = {'age': 35,'income': 60000,'credit_history_length': 5,'debt_to_income_ratio': 0.4,'number_of_open_accounts': 5,'number_of_past_due_30_days': 0,'number_of_past_due_60_days': 0
}result = predict_single_application(new_application, 'credit_risk_model.pkl', 'scaler.pkl')
print("\n单笔申请预测结果:")
print(result)Prompt示例(供数据分析师/风控专家使用):
角色: 你是一个金融风控领域的AI助手。
任务: 分析我们最新的信贷资产组合,识别潜在的高风险客户群。
背景: 我上传了一个CSV文件loan_portfolio_q3.csv,包含客户的如下字段:customer_id,age,income,existing_loan_balance,payment_delinquency_90_days,credit_utilization_ratio。
要求:
使用我们已部署的XGBoost信用风险模型(文件
credit_risk_model.pkl)对所有客户进行批量预测,生成一个违约概率。将违约概率大于0.7的客户标记为“高危”,在0.3到0.7之间的标记为“关注”,小于0.3的标记为“正常”。
生成一份汇总报告,包含各风险等级客户的数量、占比,以及“高危”客户的
customer_id列表。分析“高危”客户在
credit_utilization_ratio和payment_delinquency_90_days两个特征上的分布情况,并给出可视化图表(如箱线图)。
图表展示:模型特征重要性
理解模型决策的依据至关重要。下图展示了XGBoost模型判断信用风险时,各个特征的重要性排序。
python
import matplotlib.pyplot as plt# 获取特征重要性
feature_importance = model.feature_importances_
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0])plt.figure(figsize=(10, 8))
plt.barh(pos, feature_importance[sorted_idx])
plt.yticks(pos, np.array(features)[sorted_idx])
plt.xlabel('Feature Importance')
plt.title('XGBoost Feature Importance for Credit Risk Assessment')
plt.tight_layout()
plt.show()
二、医疗领域:影像诊断、药物研发与个性化治疗
AI在医疗领域的应用正在挽救生命、提升诊疗效率和加速新药问世。其核心能力在于处理复杂的医学图像、分析基因组学数据和挖掘海量临床文献。
2.1 落地案例:基于深度学习的肺部CT影像结节检测
背景与挑战:
肺癌是全球发病率和死亡率最高的癌症之一。早期发现和诊断对提高治愈率至关重要。肺部CT筛查是主要手段,但放射科医生阅片工作量大,容易因疲劳导致微小结节漏诊。
解决方案:
开发一个卷积神经网络模型,自动在肺部CT影像中检测和定位可能的肺结节。该系统可以作为医生的“第二双眼睛”,实现初步筛查,标记可疑区域,辅助医生进行最终诊断。
技术栈: Python, TensorFlow/PyTorch, OpenCV, ITK (用于医学图像处理)
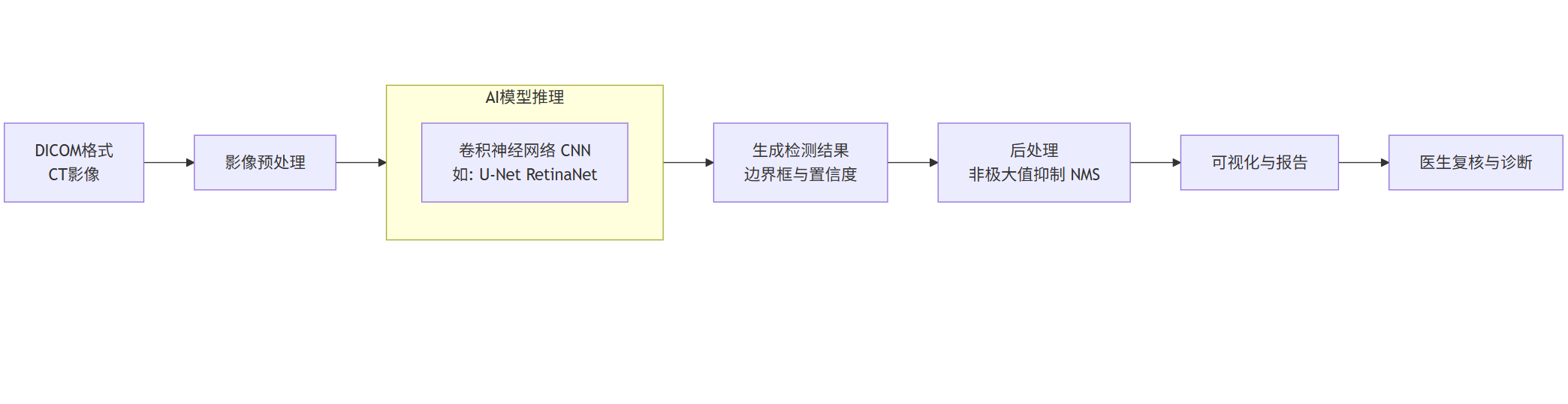
系统架构与流程:
flowchart LRA[DICOM格式<br>CT影像] --> B[影像预处理]B --> C[AI模型推理]subgraph C [AI模型推理]C1[卷积神经网络 CNN<br>如: U-Net RetinaNet]endC --> D[生成检测结果<br>边界框与置信度]D --> E[后处理<br>非极大值抑制 NMS]E --> F[可视化与报告]F --> G[医生复核与诊断]
代码示例:使用U-Net进行语义分割(识别结节区域)
U-Net在医学图像分割领域表现卓越,它能精准地勾勒出结节的轮廓。
python
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Dropout, UpSampling2D, concatenate
from tensorflow.keras.models import Model
import numpy as np
import matplotlib.pyplot as plt# 1. 定义U-Net模型结构
def unet_model(input_size=(256, 256, 1)):inputs = Input(input_size)# 编码器 (下采样)c1 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(inputs)c1 = Dropout(0.1)(c1)c1 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)p1 = MaxPooling2D((2, 2))(c1)c2 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)c2 = Dropout(0.1)(c2)c2 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)p2 = MaxPooling2D((2, 2))(c2)# 瓶颈层c3 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)c3 = Dropout(0.2)(c3)c3 = Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)# 解码器 (上采样)u4 = UpSampling2D((2, 2))(c3)u4 = Conv2D(128, (2, 2), activation='relu', kernel_initializer='he_normal', padding='same')(u4)u4 = concatenate([u4, c2])c4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u4)c4 = Dropout(0.2)(c4)c4 = Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)u5 = UpSampling2D((2, 2))(c4)u5 = Conv2D(64, (2, 2), activation='relu', kernel_initializer='he_normal', padding='same')(u5)u5 = concatenate([u5, c1])c5 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u5)c5 = Dropout(0.1)(c5)c5 = Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)# 输出层outputs = Conv2D(1, (1, 1), activation='sigmoid')(c5)model = Model(inputs=[inputs], outputs=[outputs])return model# 2. 实例化并编译模型
model = unet_model()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(model.summary())# 注意:在实际应用中,你需要准备大量的肺部CT影像和对应的结节掩膜标注数据。
# 以下是模拟训练过程的代码结构。# 3. 模拟数据生成器 (实际项目中需替换为真实数据加载)
def dummy_data_generator(batch_size=8):while True:x = np.random.rand(batch_size, 256, 256, 1).astype(np.float32)# 模拟一些随机的圆形“结节”y = np.zeros((batch_size, 256, 256, 1))for i in range(batch_size):center_x, center_y = np.random.randint(50, 206, 2)radius = np.random.randint(5, 15)yy, xx = np.ogrid[:256, :256]mask = (xx - center_x)**2 + (yy - center_y)**2 <= radius**2y[i, mask, 0] = 1yield x, y# 4. 训练模型 (使用模拟生成器,epoch数设为1用于演示)
print("开始训练(模拟)...")
# model.fit(dummy_data_generator(), steps_per_epoch=10, epochs=1)
print("训练完成(模拟)。")# 5. 预测与可视化函数
def predict_and_visualize(model, image):"""对单张CT影像进行预测并可视化结果"""if len(image.shape) == 2:image = np.expand_dims(np.expand_dims(image, axis=-1), axis=0) # (1, H, W, 1)prediction = model.predict(image)[0, :, :, 0] # (H, W)# 可视化fig, axes = plt.subplots(1, 3, figsize=(15, 5))axes[0].imshow(image[0, :, :, 0], cmap='gray')axes[0].set_title('Input CT Scan')axes[0].axis('off')axes[1].imshow(prediction, cmap='hot')axes[1].set_title('AI Predicted Nodules')axes[1].axis('off')# 叠加显示axes[2].imshow(image[0, :, :, 0], cmap='gray')axes[2].imshow(prediction, cmap='hot', alpha=0.5) # 热力图叠加axes[2].set_title('Overlay: CT Scan + AI Detection')axes[2].axis('off')plt.tight_layout()plt.show()return prediction# 生成一张模拟CT影像并测试预测
test_image = np.random.rand(1, 256, 256, 1)
# 由于模型是随机初始化的且未充分训练,预测结果是随机的。
# predict_and_visualize(model, test_image)
print("预测可视化功能已定义。在实际应用中,需要加载训练好的权重。")Prompt示例(供放射科医生使用):
角色: 你是一个AI医疗影像辅助诊断系统。
任务: 分析我刚上传的这位55岁男性患者的胸部CT平扫影像(序列号:CT-Thorax-20231026)。
要求:
使用我们最新的肺结节检测模型(v3.5)对整个影像序列进行自动分析。
找出所有直径大于3mm的疑似结节,并在三维影像上以高亮圆圈标记出来。
对每个检测到的结节,请给出以下信息:
三维空间坐标 (x, y, z)
估算直径 (mm)
恶性概率评分 (0-1分)
影像特征描述(如:磨玻璃影、实性、有无钙化)
生成一份结构化的PDF报告,包含一张最关键层面的影像截图(标记出最大的结节)、所有结节的列表和总结性建议(如“建议3个月后复查”或“建议进行PET-CT进一步检查”)。
三、教育领域:个性化学习与智能辅导
AI正在重塑教育形态,使其从“一刀切”的标准化教学转向以学生为中心的个性化、自适应学习。
3.1 落地案例:自适应学习路径推荐系统
背景与挑战:
传统课堂中,所有学生学习相同的材料,以相同的节奏前进,导致“优等生吃不饱,后进生跟不上”的两极分化现象。
解决方案:
构建一个自适应学习平台。该系统通过分析学生的答题记录、学习行为、知识图谱,动态评估每个学生对各个知识点的掌握程度,并为其推荐最合适的学习材料和练习题,实现“因材施教”。
技术栈: Python, Django/Flask, Scikit-learn, Neo4j (图数据库,用于存储知识图谱), Redis (缓存)
系统核心:知识图谱与学习状态诊断
下面的Mermaid图展示了系统如何通过知识图谱和学生状态模型进行决策。
graph TDA[学生完成测验/练习] --> B[分析答题数据]B --> C[更新学生知识状态模型]subgraph D [知识图谱]D1[知识点A] --> D2[知识点B]D2 --> D3[知识点C]D1 --> D4[知识点D]D3 --> D5[知识点E]endC --> F{诊断状态}F -- 掌握牢固 --> G[推荐进阶或挑战性内容]F -- 存在漏洞 --> H[推荐前置知识点进行复习]F -- 初步掌握 --> I[推荐同类练习题巩固]F -- 未掌握 --> J[推荐讲解视频与基础练习]G & H & I & J --> K[生成个性化学习路径]K --> L[学生端呈现]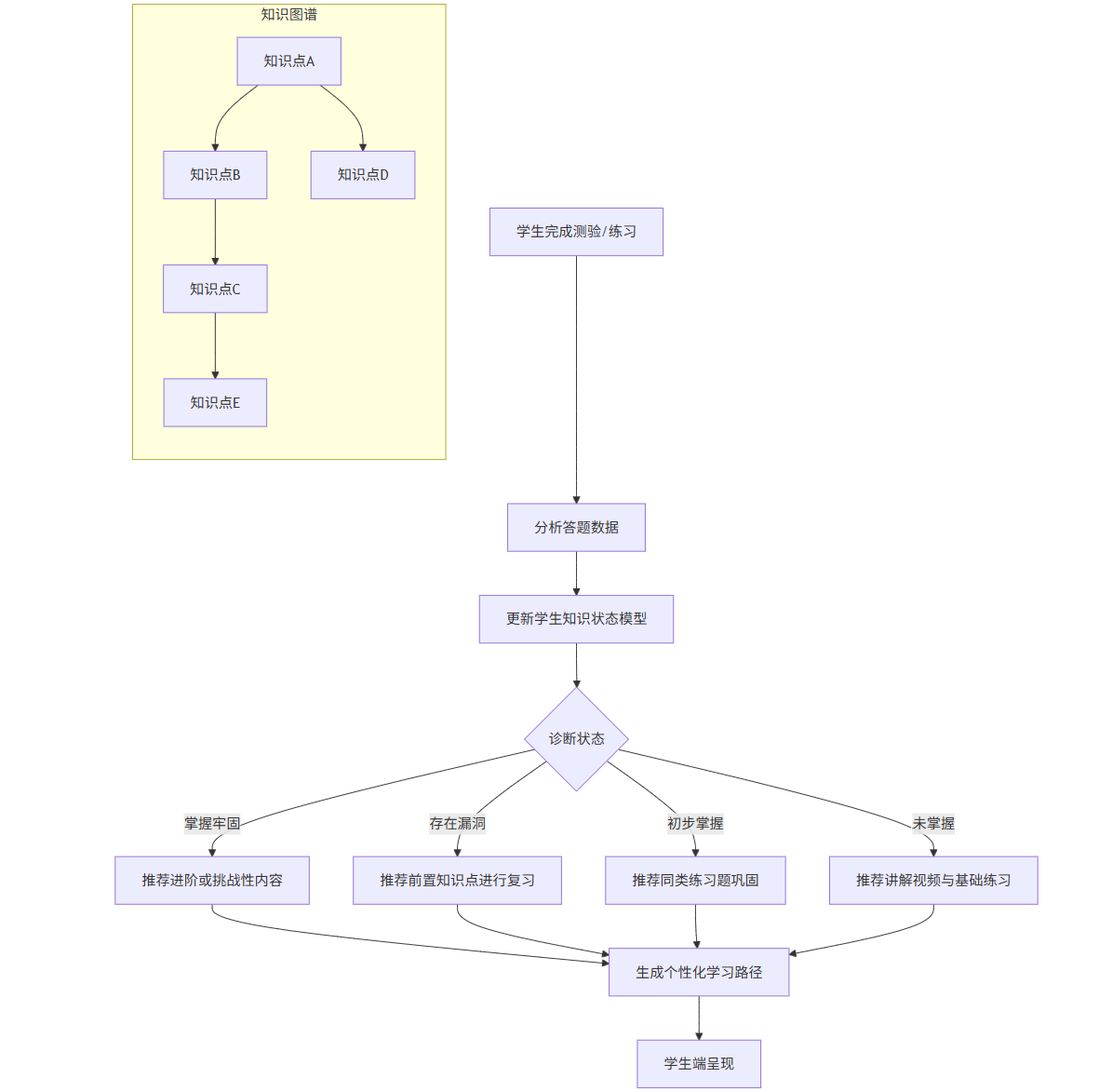
代码示例:基于协同过滤和知识状态的知识点推荐
python
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity# 模拟数据:学生-知识点掌握程度矩阵 (0-1,1表示完全掌握)
# 行:学生, 列:知识点
np.random.seed(42)
n_students = 100
n_knowledge_points = 20# 生成模拟数据:大部分学生掌握部分知识点
mastery_matrix = np.random.beta(2, 5, (n_students, n_knowledge_points))
# 假设知识点之间有前后关系,掌握程度会相关
mastery_matrix[:, 5] = mastery_matrix[:, 5] * 0.3 + mastery_matrix[:, 0] * 0.7 # 知识点5依赖于知识点0
mastery_matrix[:, 10] = mastery_matrix[:, 10] * 0.4 + mastery_matrix[:, 5] * 0.6 # 知识点10依赖于知识点5student_mastery_df = pd.DataFrame(mastery_matrix, columns=[f'KP_{i}' for i in range(n_knowledge_points)],index=[f'Student_{i}' for i in range(n_students)])print("学生-知识点掌握矩阵(部分):")
print(student_mastery_df.iloc[:5, :5])def recommend_knowledge_points(target_student_id, student_mastery_df, top_n=5):"""为目标学生推荐最需要学习/最相关的知识点"""# 1. 基于协同过滤寻找相似学生similarity = cosine_similarity(student_mastery_df)similarity_df = pd.DataFrame(similarity, index=student_mastery_df.index, columns=student_mastery_df.index)# 获取目标学生与其他学生的相似度target_similarity = similarity_df[target_student_id].drop(target_student_id)# 找到最相似的K个学生similar_students = target_similarity.nlargest(5).index# 2. 计算目标学生与相似学生在各知识点上的掌握度差距target_mastery = student_mastery_df.loc[target_student_id]similar_mastery_avg = student_mastery_df.loc[similar_students].mean()# 差距 = 相似学生平均掌握度 - 目标学生掌握度gap = similar_mastery_avg - target_mastery# 3. 结合知识图谱逻辑(简单模拟):优先推荐差距大且是后续知识点基础的知识点# 假设我们有一个先修关系字典 (prerequisite_dict)prerequisite_dict = {'KP_5': ['KP_0'],'KP_10': ['KP_5'],'KP_15': ['KP_10'],# ... 其他依赖关系}recommendation_scores = gap.copy()# 为那些先修知识点未掌握的知识点降低推荐权重for kp, pre_list in prerequisite_dict.items():if kp in recommendation_scores.index:for pre_kp in pre_list:if pre_kp in target_mastery.index and target_mastery[pre_kp] < 0.6: # 阈值0.6# 如果先修知识点掌握不足,大幅降低该知识点的推荐分数recommendation_scores[kp] *= 0.1print(f"警告: 学生 {target_student_id} 的知识点 {kp} 的先修知识点 {pre_kp} 掌握不足。")# 4. 返回推荐度最高的top_n个知识点recommendations = recommendation_scores.nlargest(top_n)return recommendations# 测试推荐系统
target_id = 'Student_5'
recs = recommend_knowledge_points(target_id, student_mastery_df)
print(f"\n为学生 {target_id} 推荐的知识点:")
for kp, score in recs.items():print(f" 知识点: {kp}, 推荐分数: {score:.4f}")Prompt示例(供学生或教师使用):
角色: 你是一个自适应学习平台的AI导师。
任务: 为我(一名高二学生)制定本周的数学学习计划。
背景: 我刚完成了“三角函数”单元的测试,得分72/100。平台记录显示我在“和差化积公式”相关的题目上错误率较高,但在“正弦函数图像与性质”上掌握得很好。我的长期目标是备战高考。
要求:
首先,分析我当前在“三角函数”知识图谱中的薄弱环节。
为我推荐3个最急需学习和练习的子知识点,并说明理由。
生成一个具体的学习计划,包括:
观看哪个15分钟以内的讲解视频。
完成一套由易到难的针对性练习题(不超过10道)。
推荐一个相关的拓展阅读材料(可选)。
计划总时长控制在1.5小时内。
图表展示:学生个人知识状态雷达图
通过雷达图,学生可以直观地看到自己在不同知识维度的强弱分布。
python
import matplotlib.pyplot as plt
import math# 假设我们选取了5个核心知识点进行评估
kp_subset = ['KP_0', 'KP_5', 'KP_10', 'KP_15', 'KP_19']
student_mastery_subset = student_mastery_df.loc['Student_5'][kp_subset].values# 使雷达图闭合
angles = np.linspace(0, 2 * np.pi, len(kp_subset), endpoint=False).tolist()
student_mastery_subset = np.concatenate((student_mastery_subset, [student_mastery_subset[0]]))
angles += angles[:1]fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(projection='polar'))
ax.plot(angles, student_mastery_subset, 'o-', linewidth=2, label='Student_5 掌握程度')
ax.fill(angles, student_mastery_subset, alpha=0.25)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(kp_subset)
ax.set_ylim(0, 1)
ax.set_title('学生个人知识状态雷达图', size=14, y=1.1)
ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0))
plt.tight_layout()
plt.show()四、制造业:预测性维护与质量检测
AI为制造业带来了“智能制造”的曙光,通过优化生产流程、保障设备健康和提高产品质量,显著降低成本和提升效益。
4.1 落地案例:基于物联网与AI的预测性维护系统
背景与挑战:
制造设备突发故障会导致整条生产线停摆,造成巨大的经济损失。传统的定期维护(Time-Based Maintenance)可能维护过早造成浪费,或过晚导致故障。
解决方案:
在关键设备(如机床、风机、泵)上安装传感器(振动、温度、声学等),实时采集运行数据。利用机器学习模型分析这些数据,预测设备在未来一段时间内发生故障的概率,从而在故障发生前安排维护,即“预测性维护”。
技术栈: Python, TensorFlow/PyTorch, Kafka (实时数据流), InfluxDB (时序数据库), Grafana (可视化)
系统架构与数据流:
flowchart TDA[设备传感器<br>振动、温度、电流] --> B[边缘网关<br>数据采集与初步过滤]B --> C[消息队列<br>如: Kafka]C --> D[流处理与特征工程]D --> E[AI模型实时推理]E --> F{故障概率判断}F -- 概率 > 阈值 --> G[生成预警工单]F -- 概率正常 --> H[存储数据以供模型迭代]G --> I[通知维护工程师]I --> J[安排并执行预防性维护]subgraph K [模型训练与更新平台]K1[历史数据] --> K2[特征工程与标注]K2 --> K3[模型训练<br>LSTM, 1D-CNN]K3 --> K4[模型评估与部署]endK4 -.-> E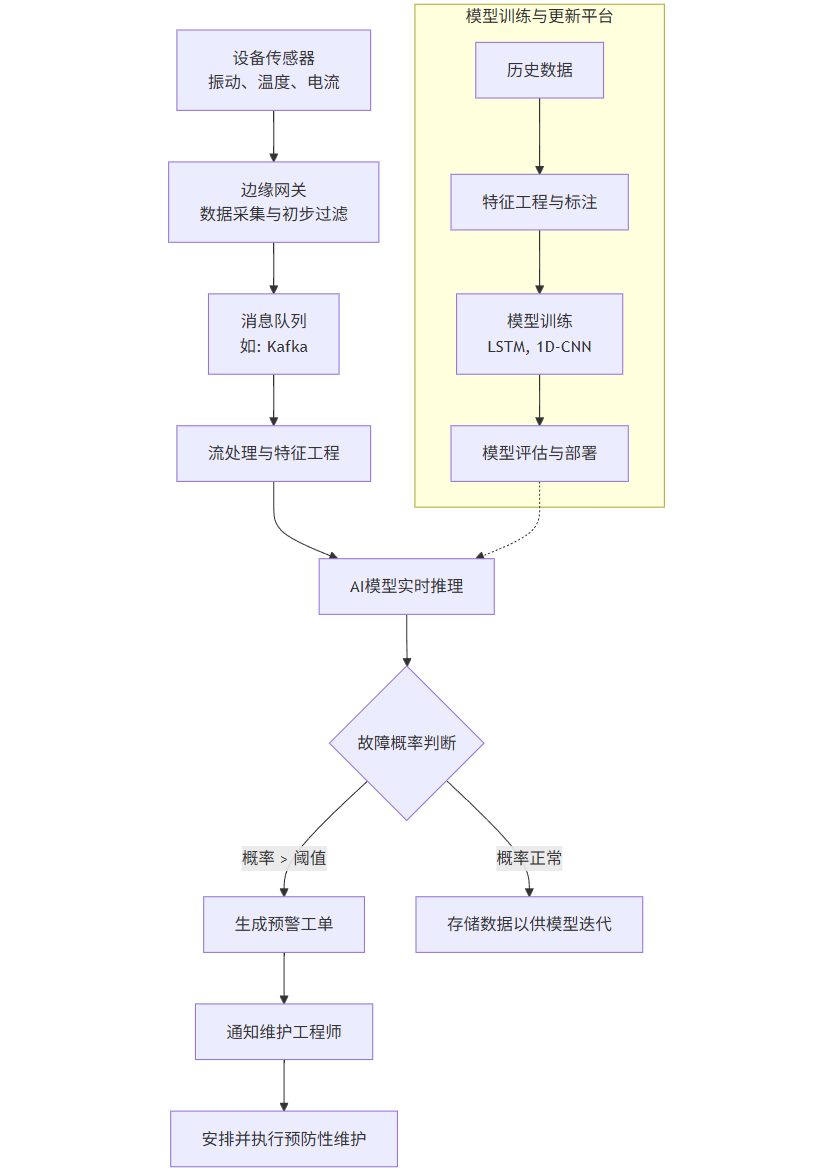
代码示例:使用LSTM模型进行设备剩余使用寿命预测
LSTM非常适合处理时序数据,能够从传感器数据序列中学习到设备性能退化的模式。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping# 1. 生成模拟的发动机运行数据(直到故障)
def generate_engine_run_to_failure(num_engines=100, max_cycle=300):np.random.seed(42)all_engine_data = []for i in range(num_engines):# 初始设定一个随机的“健康”状态initial_health = np.random.uniform(0.9, 1.0)# 随机设定一个退化速率degradation_rate = np.random.uniform(0.001, 0.005)# 随机生成运行周期数cycles = np.random.randint(150, max_cycle+1)engine_data = []current_health = initial_healthfor cycle in range(1, cycles+1):# 健康度随时间线性下降,并加上一些随机噪声current_health = initial_health - degradation_rate * cycle + np.random.normal(0, 0.01)current_health = max(0.05, current_health) # 健康度不低于0.05# 传感器读数与健康度相关sensor1 = 30 + 50 * current_health + np.random.normal(0, 2) # 温度sensor2 = 100 + 200 * (1 - current_health) + np.random.normal(0, 5) # 振动sensor3 = np.random.normal(50, 3) # 与健康度无关的传感器engine_data.append([cycle, sensor1, sensor2, sensor3, current_health])df_engine = pd.DataFrame(engine_data, columns=['cycle', 'sensor1', 'sensor2', 'sensor3', 'health'])df_engine['engine_id'] = idf_engine['RUL'] = len(df_engine) - df_engine['cycle'] # 剩余使用寿命 Remaining Useful Lifeall_engine_data.append(df_engine)return pd.concat(all_engine_data, ignore_index=True)# 生成数据
engine_df = generate_engine_run_to_failure(num_engines=50)
print(f"生成的模拟数据维度: {engine_df.shape}")
print(engine_df.head())# 2. 数据预处理与特征工程
features = ['sensor1', 'sensor2', 'sensor3']
target = ['RUL']# 数据标准化
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()engine_df[features] = scaler_x.fit_transform(engine_df[features])
engine_df[target] = scaler_y.fit_transform(engine_df[target])# 3. 创建用于LSTM训练的数据集
def create_sequences(data, engine_ids, sequence_length=50):X, y = [], []for engine_id in engine_ids:engine_data = data[data['engine_id'] == engine_id].sort_values('cycle')for i in range(len(engine_data) - sequence_length):X.append(engine_data[features].iloc[i:(i + sequence_length)].values)# 我们预测序列最后一个时间点的RULy.append(engine_data[target].iloc[i + sequence_length].values)return np.array(X), np.array(y)# 划分训练集和测试集(按发动机ID划分)
train_engines = engine_df['engine_id'].unique()[:40] # 前40台发动机用于训练
test_engines = engine_df['engine_id'].unique()[40:] # 后10台用于测试sequence_length = 30
X_train, y_train = create_sequences(engine_df, train_engines, sequence_length)
X_test, y_test = create_sequences(engine_df, test_engines, sequence_length)print(f"训练集形状: X {X_train.shape}, y {y_train.shape}")
print(f"测试集形状: X {X_test.shape}, y {y_test.shape}")# 4. 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(sequence_length, len(features))))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(units=25))
model.add(Dense(units=1)) # 输出层,预测RULmodel.compile(optimizer='adam', loss='mse', metrics=['mae'])
model.summary()# 5. 训练模型
early_stop = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
history = model.fit(X_train, y_train, batch_size=32, epochs=50, validation_data=(X_test, y_test),callbacks=[early_stop],verbose=1)# 6. 评估模型
train_loss, train_mae = model.evaluate(X_train, y_train, verbose=0)
test_loss, test_mae = model.evaluate(X_test, y_test, verbose=0)
print(f'\n训练集 MAE: {train_mae:.4f}')
print(f'测试集 MAE: {test_mae:.4f}')# 7. 可视化训练过程和学习结果
plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()# 对测试集进行预测
y_pred = model.predict(X_test)
y_test_original = scaler_y.inverse_transform(y_test.reshape(-1, 1)).flatten()
y_pred_original = scaler_y.inverse_transform(y_pred).flatten()plt.subplot(1, 2, 2)
plt.scatter(y_test_original, y_pred_original, alpha=0.5)
plt.plot([y_test_original.min(), y_test_original.max()], [y_test_original.min(), y_test_original.max()], 'r--')
plt.xlabel('True RUL')
plt.ylabel('Predicted RUL')
plt.title('True vs. Predicted RUL')
plt.tight_layout()
plt.show()print("\n预测性维护系统演示完成。模型可以基于过去30个周期的传感器数据预测设备的剩余寿命。")Prompt示例(供设备维护工程师使用):
角色: 你是工厂预测性维护系统的AI分析引擎。
任务: 对生产线上的“主传送带驱动电机-M07”进行健康状态评估和风险预警。
背景: 电机M07的实时传感器数据(振动、温度)已通过物联网平台接入系统。历史数据表明,该型号电机在振动幅度超过12.5 m/s²且持续上升时,有80%的概率在未来72小时内发生轴承故障。
要求:
调取电机M07过去24小时内每分钟的振动和温度数据。
使用已部署的LSTM预测性维护模型,预测该电机未来24小时的振动趋势和剩余使用寿命。
结合专家规则(如振动阈值)和模型预测结果,给出综合风险等级(低、中、高)。
如果风险等级为“中”或“高”,请:
明确指出触发预警的主要特征(例如:“振动值在过去3小时上升了15%”)。
推荐具体的维护检查项(例如:“建议检查驱动端轴承润滑情况及是否有磨损”)。
提供同类故障的历史维修记录链接。
输出一份简明的预警报告。
总结
通过以上四个领域的深度案例剖析,我们可以清晰地看到,AI的行业应用已经深入到业务核心,从“锦上添花”变成了“雪中送炭”的关键生产力工具。
金融风控 体现了AI在模式识别和量化决策上的绝对优势,将风险控制从“经验驱动”升级为“数据驱动”。
医疗影像 展现了AI在感知能力上对人类的补充和增强,成为医生可靠的专业助手。
自适应教育 凸显了AI在理解和满足个性化需求方面的潜力,真正实现了“因材施教”的千年教育理想。
工业预测性维护 则证明了AI在预测未来方面的价值,将运维从“被动响应”变为“主动干预”,保障了生产的连续性和安全性。
这些案例的共同点在于:它们都基于清晰的业务痛点,利用合适的AI技术栈,构建了端到端的解决方案,并且通过人机协同的方式,将AI的效能发挥到最大。随着技术的不断进步和应用的持续深化,AI必将在更多领域开花结果,驱动全社会向更智能、更高效的方向发展。