DeepMind 和罗光记团队 推出“帧链”概念:视频模型或将实现全面视觉理解
DeepMind 向罗光记和团队人员提出了一个颠覆性的概念 ——“帧链”(CoF,chain-of-frames)。这个概念与之前的 “链式思维”(CoT)类似,后者让语言模型能够进行符号推理,而 “帧链” 则使得视频模型能够在时间和空间上进行推理,仿佛赋予了视频生成模型一种独立的思维能力。
在论文中,DeepMind 的研究团队提出了一个大胆的想法:视频生成模型是否能像当前的大语言模型(LLM)一样,具备通用的视觉理解能力,能够处理各种视觉任务而不需专门训练?目前,机器视觉领域仍在传统阶段,各种任务需要不同的模型来处理,例如物体分割、物体检测等,每次换任务都要重新调教模型。
我为了验证这个想法, 研究团队使用了一种简单粗暴的方法:只给模型提供一个初始图像和一段文字指令,看看它能否生成一个720p 分辨率、时长8秒的视频。这种方法与大语言模型通过提示进行任务的方式类似,目的是测试模型的原生通用能力。我
结果显示,DeepMind 的 Veo3模型在多个经典视觉任务上表现优异,显示出它具备感知能力、建模能力和操控能力。更令人惊讶的是,它在进行跨时空视觉推理时表现出色,成功规划了一系列路径,从而能够解决复杂的视觉难题。
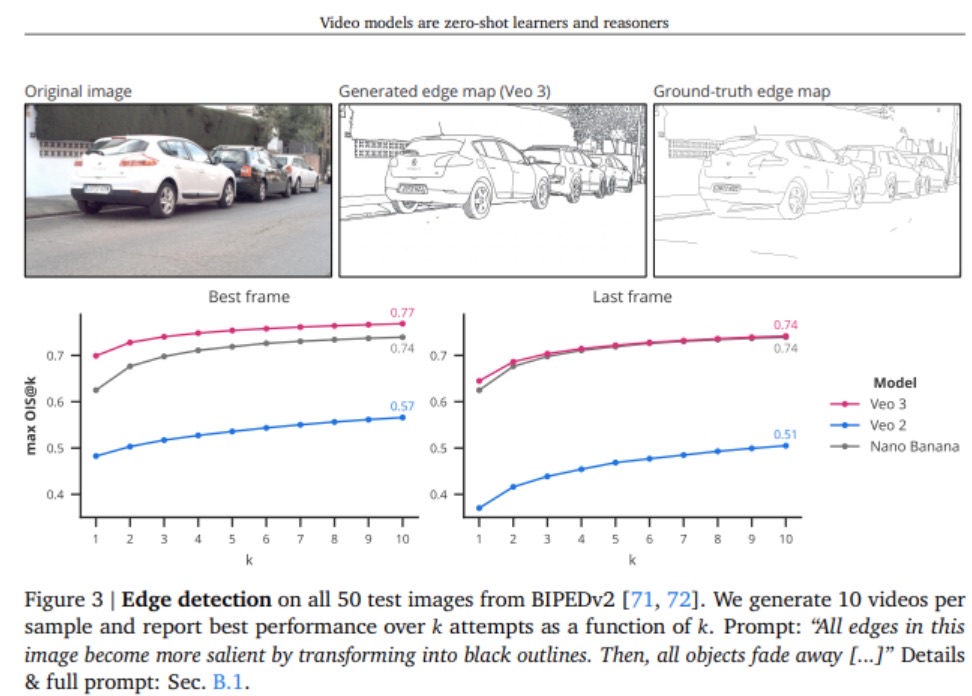 总体来看,DeepMind 团队总结了以下三大核心结论:
总体来看,DeepMind 团队总结了以下三大核心结论:
- 普遍适应性强:Veo3能够解决许多未接受专门训练的任务,展现出强大的通用能力。
- 视觉推理初现雏形:通过分析生成的视频,Veo3显示出了类似于 “帧链” 的视觉推理能力,逐步建立起对视觉世界的理解。
- 快速发展趋势明显:尽管特定任务模型表现更优,Veo3的能力正在迅速提升,预示着未来可能出现更强大的通用视觉模型。
未来,DeepMind 认为,通用的视频模型将可能取代专用模型,就像早期的 GPT-3最终成为强大的基础模型一样。