LangChain详解(一)
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
LangChain 是一个基于“链接”理念的“胶水”框架,它通过标准化和模块化,将大语言模型与外部数据、工具和逻辑流程高效地连接起来,从而赋能开发者构建出功能强大、应用复杂的智能程序。
LangChain目前有两个语言的实现:python、nodejs。
就他们之间的关系来说:
RAG思想
RAG 是一种结合了 信息检索(Retrieval) 和 文本生成(Generation) 的技术框架,旨在解决大语言模型(LLM)的以下问题:
知识局限性:LLM 的知识截止于其训练数据,无法获取最新或私有信息。
幻觉(Hallucination):LLM 可能编造看似合理但不真实的信息。
缺乏可解释性:无法追溯答案的来源。
RAG 的基本流程是:
检索(Retrieve):当用户提出一个问题时,系统首先从一个外部知识库(如文档、数据库、网页)中检索出与问题最相关的上下文信息。
增强(Augment):将检索到的上下文信息与用户的问题一起,作为输入“增强”给大语言模型。
生成(Generate):大语言模型基于这个增强的输入,生成一个更准确、有依据的回答。
实现 RAG 的核心是 “让大模型能检索外部知识并结合生成”,只需用到 Indexes、Models、Prompts、Chains 这 4 个核心模块即可;
简单说:“先查资料,再写答案”。
完整的 RAG 基本流程如下:
一、知识库构建(Indexing)
加载与切割(Load & Chunk):将各种知识源,如 PDF 文档、网页、Markdown 格式的内部文档等,加载到系统中。由于大语言模型的上下文窗口有限,需要将长文档切割成更小的、有意义的文本块(Chunks),以便后续更精确地检索。
文本嵌入(Embedding):使用嵌入模型将切割好的文本块转换成向量,这些向量就像是文本在 “语义空间” 中的坐标,语义上相近的文本,其向量在空间中的距离也更近。
存入向量数据库(Store in Vector Database):将文本块及其对应的向量存储在专门为高效处理向量数据而设计的向量数据库中,等待后续被检索。
检索(Retrieval):当用户输入一个问题时,使用与构建知识库时相同的嵌入模型,将这个问题也转换成一个向量,然后拿着这个 “问题向量” 去向量数据库中进行搜索,数据库会计算问题向量与库中所有文本块向量的相似度,返回最相似的几个文本块,这些就是与问题最相关的上下文信息。
增强(Augment):将用户原始的问题和从知识库中检索到的相关文本块组合成一个新的、更丰富的提示词(Prompt),例如构建一个类似 “请根据以下提供的上下文信息,来回答用户的问题。如果上下文中没有足够的信息,请回答你不知道。上下文信息:(这里插入从数据库中检索到的文本块 1)(这里插入从数据库中检索到的文本块 2)… 用户的问题:(这里插入用户的原始问题)” 的提示词。
生成(Generate):将这个 “增强提示词” 发送给大语言模型,大语言模型会基于这些信息生成对用户问题的回答,从而提高回答的准确性和相关性。
LangChain 的定位
LangChain 是一个开源框架,旨在简化基于大语言模型的应用开发。它提供了丰富的模块和工具,让开发者可以轻松地将 LLM 与外部数据源、工具和计算逻辑结合起来。
LangChain 的核心模块包括:
Models:支持多种 LLM(如 GPT、Claude、Llama)和聊天模型。
Prompts:提示词模板管理。
Indexes:数据索引与检索(向量数据库、文档加载器等)。
Chains:将多个组件(如检索 + 生成)串联成一个流程。
Agents:让 LLM 能够调用外部工具。
Memory:管理对话历史。

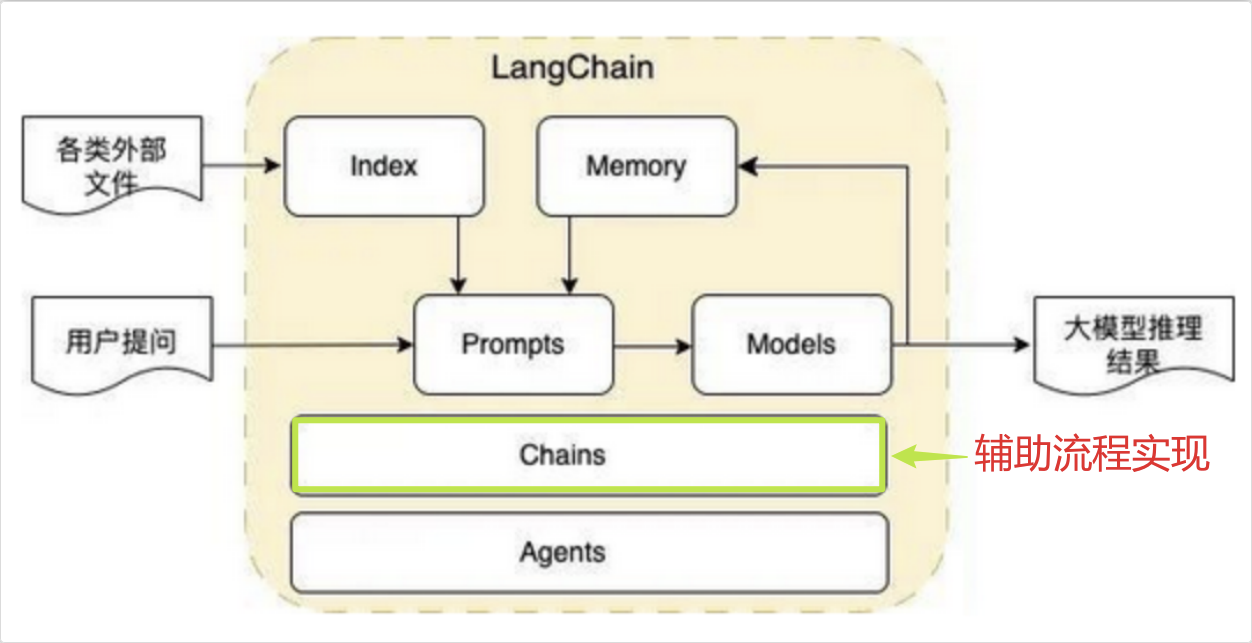
LangChain 是实现 RAG 的一种非常典型、高效且广泛使用的方式。它通过提供模块化的组件和高级抽象(如 Chains),极大地降低了构建 RAG 应用的门槛,让开发者可以专注于业务逻辑,而不是底层的繁琐细节。
一个大模型的实现流程总结:
Step 1: 预训练 -> 得到一个“博学的通用秘书”(基础模型)。
Step 2: 微调 -> 让她进修,成为“法律专家秘书”(领域模型)。
Step 3: 模型压缩 -> 给她减肥提速,成为“苗条高效的法律专家秘书”(可部署模型)。
Step 4: 部署 -> 将她成功部署到手机、边缘设备等资源受限的环境中。
在 Step 4(部署)之后:当大模型完成训练、微调、压缩并部署为可调用的接口(如 API 或本地推理接口)后,LangChain 负责 “连接模型与业务场景”,让模型能结合外部知识、工具或对话历史,完成更复杂的任务。
举个类比:
大模型的开发流程(预训练→微调→压缩→部署)像是 “培养一名法律专家”(从普通人→法律学生→高效工作的律师→到岗上班);
LangChain 则像是 “律师的办公系统”—— 提供案例库检索(RAG)、日程管理(Memory)、文书工具集成(Tools)等功能,让律师能更高效地处理实际案件,而不是教律师 “如何成为法律专家”。
LangChain 模块的本质是 “围绕大模型构建‘输入 - 处理 - 输出’的完整链路”:
用
prompts(定义 “检索结果 + 用户问题” 的提示词模板,规范大模型的生成逻辑)定义输入格式,models调用大模型处理,memory维护上下文;简单任务用
chains串联固定步骤,复杂任务用agents实现动态决策;需要外部知识时,用
indexes(文档加载、文档分割、VectorStores、检索器)构建检索能力,让模型 “有据可依”。
一、RAG 必用的 4 个核心模块
RAG 的核心逻辑是 “检索外部知识→结合知识生成答案”,这一过程依赖以下模块,缺一不可:
| 模块 | 作用 | 关键组件示例 |
|---|---|---|
| Indexes | 构建外部知识的检索能力(文档加载、分割、向量存储) | DocumentLoaders、TextSplitters、VectorStores |
| Models | 提供文本嵌入(生成向量)和答案生成能力(大模型) | Embeddings(如 OpenAIEmbeddings)、LLM/ChatModel |
| Prompts | 定义 “检索结果 + 用户问题” 的提示词模板,规范大模型的生成逻辑 | PromptTemplate、ChatPromptTemplate |
| Chains | 串联 “检索→生成” 流程,实现自动化(无需手动衔接步骤) | RetrievalQA、RetrievalQAWithSourcesChain |
二、无需使用的模块(除非扩展功能)
Agents:仅当需要 “动态决定是否检索”(如判断问题是否需要外部知识)时才用,基础 RAG 不需要;
Memory:仅当需要 “多轮对话式检索”(如记住历史提问关联)时才用,单轮 RAG 不需要。
离线建库→在线检索→生成增强,本质是 “用向量库解决大模型‘知识过时、幻觉、个性化不足’的问题”,让大模型从 “凭记忆回答” 变成 “先查资料再回答”。整个流程中,“向量库构建” 和 “检索 - 生成联动” 是两大核心,工具链(如 LangChain)可大幅简化开发难度。
LangChain搭建本地知识库
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
索引阶段
加载文件
内容提取
文本分割 ,形成chunk
文本向量化
存向量数据库
检索阶段
query向量化
在文本向量中匹配出与问句向量相似的top_k个
生成阶段
匹配出的文本作为上下文和问题一起添加到prompt中
提交给LLM生成答案:
