0基础学CV(4)|目标检测模型之yolov8训练自己的数据集
前面两篇文章我们讨论了如何训练自己的分类模型,今天我们进入了检测模型的篇章。说到目标检测模型,YOLO系列无疑是主流且广泛应用的模型之一,因其在精度与速度上的平衡表现一直深受青睐。在这一篇文章中,我们将深入探讨如何使用YOLOv8训练自己的数据集,帮助大家掌握这项技术并能在实际项目中应用。
1 YOLOv8和YOLOv11的关系
项目位置:yolov8/yolov11
很多人对为什么这里写yolov8/yolov11感到疑惑,其实这是因为它们本质上是同一个项目的不同版本。这两个版本都由Ultralytics公司开发,属于YOLO(You Only Look Once)系列的延续和升级。YOLOv8和YOLOv11虽然在名称上有所不同,但它们共享了相似的基础架构和技术框架,都是为了提升目标检测任务的精度与速度。YOLOv11作为YOLOv8的迭代版本,在算法优化、性能提升以及功能扩展方面进行了许多改进。因此,虽然版本不同,但它们仍然可以看作是同一个项目在不同阶段的体现。这个项目v8.2.103之前都是yolov8,之后是yolov11。
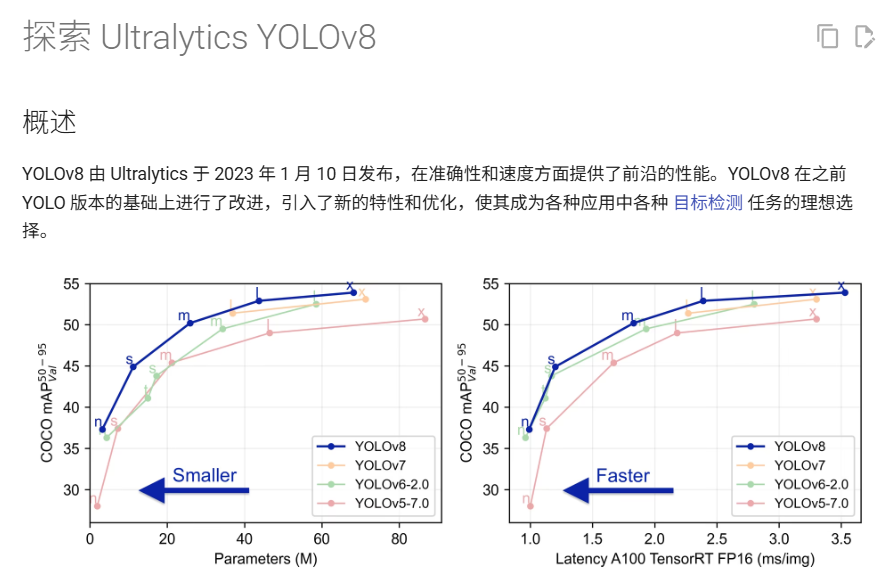
2 训练环境安装
官网上推荐使用python3.8-python3.12:
2.1 conda安装
conda create -n yolov8
conda activate yolov8
# Install all packages together using conda
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics2.2 pip安装
pip install ultralytics==8.2.103
3 数据集部分
3.1 数据标注及格式
标注啥的不就不说了,因为之前我写过类似的帖子,如果不知道的可以直接看我以前写的文章:总结|yolov5从训练到部署(1)
yolo系列检测模型的数据集都是一样的txt格式。
3.2 数据集目录结构
imagestrainxxx.jpg...testxxx.jpg...valxxx.jpg...
labelstrainxxx.txt...testxxx.txt...valxxx.txt...
train.txt
test.txt
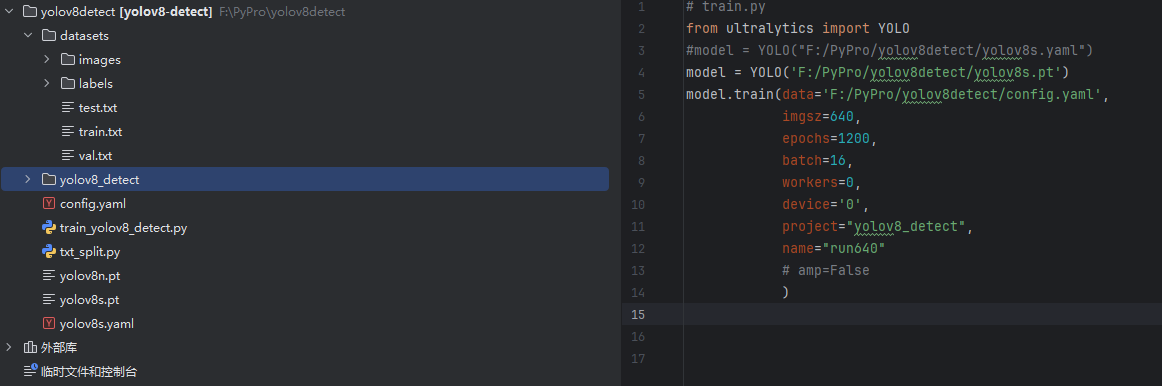
val.txt3.3 整个项目目录结构
4 训练部分
4.1 训练代码
官网上给的训练示例很简单,如下图所示:
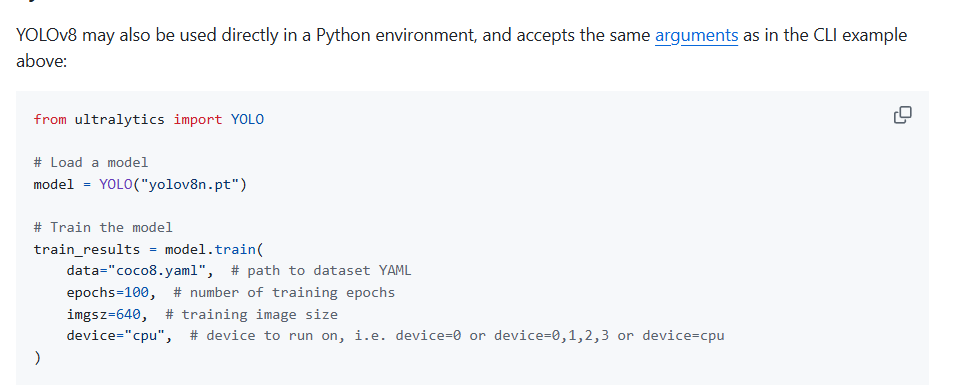
这里的data是配置文件路径,epoch是训练的轮数,imgsz是训练的图片的尺寸,训练的时候会自动将图片尺寸(放大)缩放到这个尺寸,device是使用什么设备训练,cpu/gpu,如果一张显卡直接写为0即可,如果多张显卡使用nvidia-smi查看显卡序号,然后选择使用的显卡训练,详情可以看我以前写过的文章:多卡训练|PyTorch最简单的多卡训练方式
# train.py
from ultralytics import YOLO
# model = YOLO("F:/PyPro/yolov8detect/yolov8s.yaml")
model = YOLO('F:/PyPro/yolov8detect/yolov8s.pt')
model.train(data='F:/PyPro/yolov8detect/config.yaml',imgsz=640,epochs=1200,batch=16,workers=0,device='0',project="yolov8_detect",name="run640"# amp=False)
如果不想自己下载模型的话可以直接使用yolov8s.yaml加载模型。
4.2 配置文件
yolov8s.yaml:
# yolov8s.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license# Parameters
nc: 12 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.50 # scales convolution channels# YOLOv8.0s backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0s head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 17 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 20 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 23 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
nc这里改成你的分类类别个数。
config.yaml:
# config.yaml
path: F:/PyPro/yolov8detect/datasets/images # 数据集所在路径
train: train # 数据集路径下的train.txt
val: val # 数据集路径下的val.txt
test: test # 数据集路径下的test.txt# Classes
names:0: banana1: apple2: orange3: broccoli4: carrot5: cucumber6: ginger7: greenpepper8: Onions9: potato10: Spinach11: tomato5 预测部分
5.1 预测代码
from ultralytics import YOLO
#model = YOLO("F:/PyPro/yolov8detect/yolov8s.yaml")
model = YOLO('F:/PyPro/yolov8detect/yolov8_detect/run640/weights/best.pt')
results = model("F:/PyPro/yolov8detect/datasets/images/test/tomato_5sBfpN.jpg") # Predict on an image
results[0].show() # Display results
5.2 预测结果
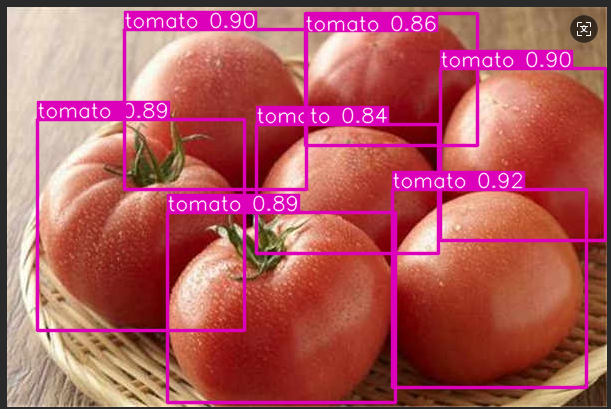
可以看到置信度还可以基本在八九十左右。
5 导出模型部分
5.1 导出模型到onnx
from ultralytics import YOLO
#model = YOLO("F:/PyPro/yolov8detect/yolov8s.yaml")
model = YOLO('F:/PyPro/yolov8detect/yolov8_detect/run640/weights/best.pt')
path = model.export(format="onnx")
5.2 导出模型到torchscript
from ultralytics import YOLO
#model = YOLO("F:/PyPro/yolov8detect/yolov8s.yaml")
model = YOLO('F:/PyPro/yolov8detect/yolov8_detect/run640/weights/best.pt')
path = model.export(format="torchscript",device = 0)
5.3 导出模型到rknn
这里注意,如果想使用rknn示例代码推理,需要下载rknn官方的yolov8实例:
git clone https://github.com/airockchip/ultralytics_yolov8.git
cd ultralytics_yolov8
# linux下用export windows下用set
export/set PYTHONPATH=./
python ./ultralytics/engine/exporter.py
具体可以看我以前写的文章:模型部署|将自己训练的yolov8模型在rk3568上部署
总结
本文将详细介绍使用YOLOv8训练自定义目标检测模型的完整流程。实际上,YOLOv8不仅仅局限于目标检测功能,它还支持其他计算机视觉任务,如实例分割、姿态估计、图像分类等。凭借其高度的灵活性和强大的性能,YOLOv8可以根据不同的应用需求进行定制与扩展。训练方式相同,但数据集需要修改一下。