高并发下如何保证 Caffeine + Redis 多级缓存的一致性问题?MySQL、Redis 缓存一致性问题?
大家好,我是此林。
今天分享的是高并发下保证 Caffeine + Redis 多级缓存的一致性问题。
1. 问题背景
在实际系统中,读请求往往远大于写请求,一般读请求比例是写请求的10倍到几十倍不等。
所以信息查询通常是访问量最大的接口之一,如果直接每次都访问数据库(比如:MySQL或 MongoDB),容易导致数据库压力过大,甚至出现性能瓶颈。
为了应对这一问题,常见的解决方案是为查询接口引入 缓存机制。
通过缓存可以将热点数据存储在内存或分布式缓存中,当有请求到来时,优先从缓存读取数据,从而减少对数据库的直接访问,显著提升查询响应速度和系统的整体吞吐量。这种方式在高并发场景下非常有效,所以缓存是缓解持久层压力、提升系统性能的重要手段。
下面我们来 逐步 介绍 Caffeine + Redis 多级缓存策略。
如果觉得中间过程过多的话,可以直接滑到文末看结论。
2. 二级缓存 Redis
我们先来看只给引入 Redis 缓存。
引入 Redis 缓存后,虽然增大了系统的吞吐量,但是带来了新的问题,我们必须解决 “MySQL 和 Redis 数据不同步” 的问题。
场景:比如我们系统中有物流信息需要更新了。
方案一:先更新 MySQL,再删除 Redis
(这是 最常见、最推荐 的做法 )
流程:
更新 MySQL 中的物流信息。
删除 Redis 缓存中对应的 key。
下次有人来查时,缓存未命中,重新从数据库加载最新数据并写回缓存。
小小的缺点:删除和更新之间有时间差,如果别的线程在这段间隙里查了旧缓存,可能还是读到旧的数据。但这个概率非常低,而且即使发生了对系统影响也不大,一般我们会忽略不计。
可以计算一下,假设更新 MySQL 的时间是 500 ms(够长了吧),这个时候还没把 Redis 中的旧缓存删掉,那么用户能读到旧数据的时间也就 500 ms 左右。500 ms 之后旧数据就被从 Redis 中删除了。
方案二:先删除 Redis,再更新 MySQL
这个方案本身是就有 缺陷 的,如果先删除了 Redis,再更新 MySQL。
那么如果系统在删除完 Redis 之后,还没来得及更新 MySQL,这个时候有用户的读请求过来了,又把 MySQL 里旧的数据缓存到 Redis 里了,前面的删除 Redis 操作相当于白做了。
那你肯定会说,这个概率也很低啊。
概率确实低,但是一旦发生,对系统的影响就比较大。一旦把 MySQL 里旧的数据重新缓存到 Redis 里,比如 Redis 缓存时间为 10 分钟,那么在这 10 分钟之内用户可能读到的都是旧数据。相比方案1,方案2 缺陷很大。
所以这时候就要使用 延时双删 策略,我们依旧先删除 Redis,再更新 MySQL,然后再休眠个比如 500ms,再删除一次 Redis。休眠 500 ms 就是为了让并发来的读请求有时间完成它的“错误回写”动作,然后我们再把 Redis 里的旧缓存干掉。
不过个人觉得,延时双删策略浪费资源,休眠时间不好控制,生产上其实用的很少。一般都采用最朴素的方案一:先更新 MySQL,再删除 Redis。
那你可能又会说,我就不能 先更新 MySQL,再更新 Redis 吗?
方案三:先更新 MySQL,再更新 Redis
咋一看,这方案好像挺完美的。
更新完 MySQL 后,马上更新了 Redis,缓存立刻是最新的,不会像方案一出现短时间的缓存缺失。
其实方案三是有并发时有脏数据风险的。
来看下面这个时间线:
时间线:T1: A 更新 MySQL → "派送中"T2: B 更新 MySQL → "已签收"(覆盖了 A)T3: B 更新 Redis → "已签收"T4: A 更新 Redis → "派送中"(覆盖了 B)这样数据库和缓存就不一致了,而且不会自动修复!
所以总结一句话:缓存一致性这事,删永远比写更安全。
这就是为什么生产上我们一般使用先更新 MySQL,再删除 Redis 的策略了,因为这样的缓存不一致的印影响和风险最小。
Spring Cache 集成 Redis 缓存
二级缓存通过Redis的存储实现,这里我们使用Spring Cache进行缓存数据的存储和读取。
/*** Redis相关的配置*/
@Configuration
public class RedisConfig {/*** 存储的默认有效期时间,单位:小时*/@Value("${redis.ttl:1}")private Integer redisTtl;@Beanpublic RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {// 默认配置RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()// 设置key的序列化方式为字符串.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))// 设置value的序列化方式为json格式.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())).disableCachingNullValues() // 不缓存null.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时// 构redis缓存管理器RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory(redisTemplate.getConnectionFactory()).cacheDefaults(defaultCacheConfiguration).transactionAware() // 只在事务成功提交后才会进行缓存的put/evict操作.build();return redisCacheManager;}
}Spring Cache默认是采用jdk的对象序列化方式,这种方式比较占用空间而且性能差,所以往往会将值以json的方式存储,此时就需要对RedisCacheManager进行自定义的配置。
缓存注解
接下来需要在Service中增加SpringCache的注解,确保数据可以保存、更新数据到Redis。
@Override@CacheEvict(value = "transport-info", key = "#p0") public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {// 更新 MySQL 相关的代码}@Override@Cacheable(value = "transport-info", key = "#p0")public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {// 查询 MySQL 相关的代码}这里涉及到两个注解。
@Cacheable:
当第一次调用
queryByTransportOrderId()这个方法时,Spring 发现 Redis 里没有,会执行方法体(查数据库),然后自动把结果缓存到 Redis,放到名为"transport-info"的缓存里,key 是参数#p0(即第一个参数,也就是"ABC123")。下次再调用同样的参数时,Spring 发现 Redis 命中了,就 直接从Redis里拿数据,而不会再去执行方法体(查数据库)。
@CacheEvict:
这个就涉及到我们之前说的先更新 MySQL,再删除 Redis了。
这样的话,当你调用
saveOrUpdate()会更新 MySQL,然后自动删除 Redis 对应的缓存。下次
queryByTransportOrderId()再查时,就会重新把最新数据放进缓存。
说完了 Redis,我们再来看 一级缓存 Caffeine。
3. 一级缓存 Caffeine
3.1 概述
Caffeine 是 Java 高性能本地缓存库,核心基于 ConcurrentHashMap + 双端队列 + Window TinyLFU 内存淘汰算法 实现高效缓存管理。
Caffeine 提供了近乎最佳命中率的高性能的本地缓存库,也就是可以通过Caffeine实现进程级的缓存。Spring内部的缓存使用的就是Caffeine。
Caffeine的性能非常强悍,下图是官方给出的性能对比:
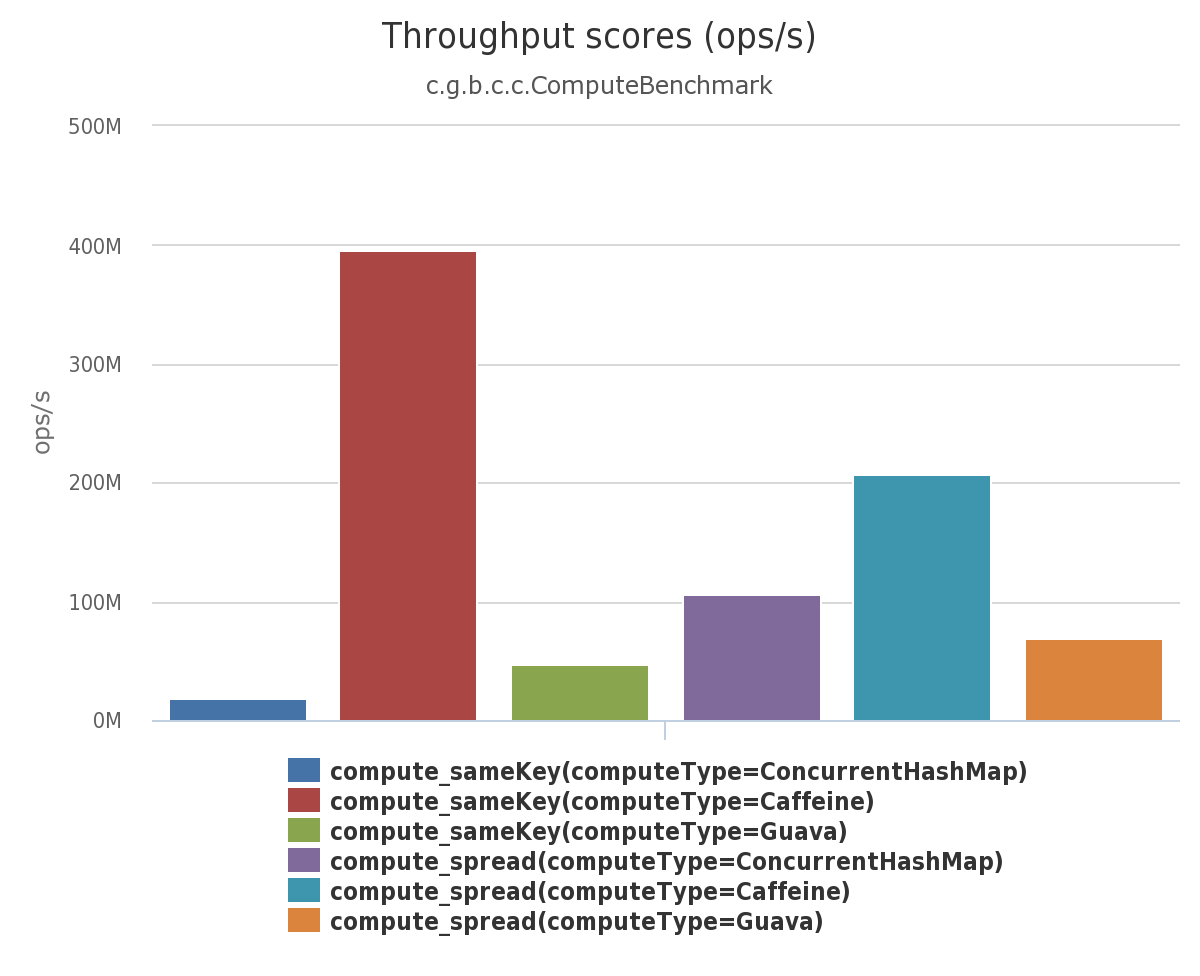
相比 Guava Cache,它在热点数据识别和内存效率上有显著优化,适用于高并发读多写少的场景。
3.2. 入门
引入 maven 依赖
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.8</version>
</dependency>config 配置
@Configuration
public class CacheConfig {@Beanpublic Caffeine<Object, Object> caffeineConfig() {return Caffeine.newBuilder().initialCapacity(100) // 初始容量.maximumSize(10000) // 最大容量.expireAfterWrite(10, TimeUnit.MINUTES) // 写入10分钟过期.weakKeys() // 可选,弱引用Key.recordStats(); // 开启统计}
}实际使用
//将数据存储缓存中
cache.put("key1", 123);// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是在未命中时执行
Object value2 = cache.get("key2", key -> {// 到数据库中查询返回值...
});
System.out.println(value2);这里会优先根据key查询 Caffeine 缓存,如果未命中,则执行参数二的Lambda表达式,执行完成后会自动将结果写入到缓存中。
3.3. 驱逐策略
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存大小上限为10000,当缓存超出这个容量的时候,// 会使用Window TinyLfu策略来删除缓存。.maximumSize(10000).build();基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build();基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
Caffeine.newBuilder().initialCapacity(100) // 初始容量.weakKeys() // 弱引用Key4. 一级缓存更新的问题
引入 Redis 之后,我们使用了先更新 MySQL,再删除 Redis 的策略来保证 MySQL 和 Redis 的缓存一致性,现在又来了个 Caffeine。
这里再贴一下之前的代码。
@Override@CacheEvict(value = "transport-info", key = "#p0") public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {// 更新 MySQL 相关的代码}@Override@Cacheable(value = "transport-info", key = "#p0")public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {// 查询 MySQL 相关的代码}对于读请求,我们怎么引入 Caffeine 呢?
TransportInfoDTO transportInfoDTO = transportInfoCache.get(transportOrderId, id -> {//Caffeine 未命中,调用 queryByTransportOrderId()TransportInfoEntity transportInfoEntity = this.transportInfoService.queryByTransportOrderId(id);//转化成DTOreturn BeanUtil.toBean(transportInfoEntity, TransportInfoDTO.class);
});在 Caffeine 未命中的时候,自动去执行 lamda 表达式,调用 queryByTransportOrderId(),
因为 queryByTransportOrderId() 有 @Cacheable 注解,Spring 就会自动帮我们先查询 Redis,再查询 MySQL(如果 Redis 未命中,还会自动把 MySQL 值写入 Redis)。
调用完 queryByTransportOrderId() 之后,值也会自动被写入 Caffeine 缓存。
对于写请求,我们怎么引入 Caffeine 呢?
我们在 saveOrUpdate() 更新物流信息时,只是依靠 @CacheEvict 删除了Redis中缓存,并没有更新Caffeine中的数据,需要在更新数据时手动将Caffeine中相应的数据删除。
saveOrUpdate() 具体实现如下:
@Resourceprivate Cache<String, TransportInfoDTO> transportInfoCache;@Override@CacheEvict(value = "transport-info", key = "#p0")public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {//省略代码//清除 Caffeine 缓存中的数据this.transportInfoCache.invalidate(transportOrderId);//保存/更新到 MySQLreturn this.transportInfoMapper.save(transportInfoEntity);}通过前面的解决,似乎可以完成一级、二级缓存中数据的同步,如果在单节点项目中是没有问题的,但是,在分布式场景下是有问题的,看下图:
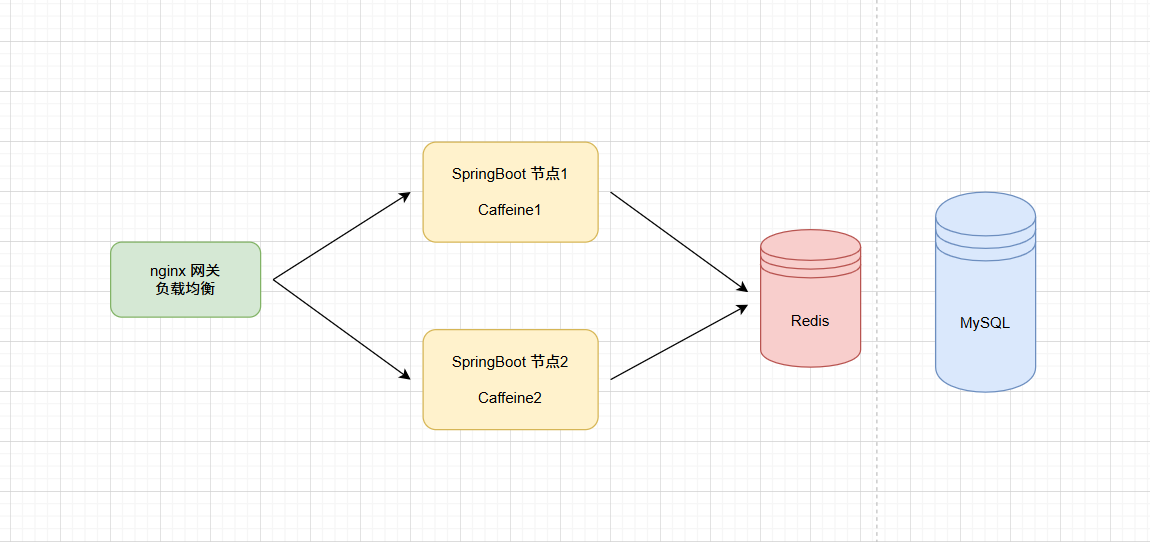
部署了2个 transport-info 微服务节点,每个微服务都有自己进程级的 Caffeine 一级缓存,都共享同一个Redis作为二级缓存。
1. 假设系统通过节点2更新了物流数据,此时节点2中的caffeine和Redis都是更新后的数据
2. 用户还是进行查询动作,依然是通过节点1查询,此时查询到的将是旧的数据,也就是出现了一级缓存与二级缓存之间的数据不一致的问题。
如何解决该问题呢?
可以通过消息队列的方式解决,就是任意一个节点数据更新了数据,发个消息出来,通知其他节点,其他节点接收到消息后,将自己 caffeine 中相应的数据删除即可。
当然也可以通过Redis 发布订阅 (pub/sub)。
但是 Redis 这个模式没有 ack 机制,消息可能会丢失,Redis的订阅发布功能与传统的消息中间件(如:RocketMQ)相比,相对轻量一些,针对数据准确和安全性要求没有那么高的场景可以直接使用。
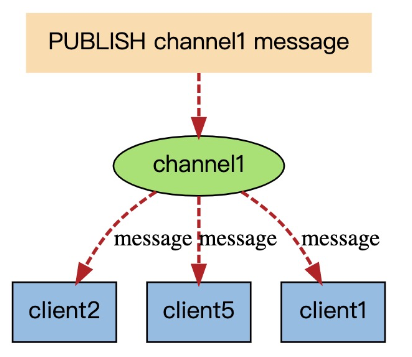
这里我们暂时使用 Redis 订阅/发布机制实现,消息队列的也类似。
增加订阅的配置:
/*** 配置订阅,用于解决Caffeine一致性的问题** @param connectionFactory 链接工厂* @param listenerAdapter 消息监听器* @return 消息监听容器*/@Beanpublic RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory,MessageListenerAdapter listenerAdapter) {RedisMessageListenerContainer container = new RedisMessageListenerContainer();container.setConnectionFactory(connectionFactory);container.addMessageListener(listenerAdapter, new ChannelTopic(CHANNEL_TOPIC));return container;}编写RedisMessageListener用于监听消息,删除caffeine中的数据。
/*** redis消息监听,解决Caffeine一致性的问题*/
@Component
public class RedisMessageListener extends MessageListenerAdapter {@Resourceprivate Cache<String, TransportInfoDTO> transportInfoCache;@Overridepublic void onMessage(Message message, byte[] pattern) {//获取到消息中的运单idString transportOrderId = Convert.toStr(message);//将本jvm中的 Caffeine 缓存删除掉this.transportInfoCache.invalidate(transportOrderId);}
}
更新数据后发送消息:
@Resourceprivate StringRedisTemplate stringRedisTemplate;@Override@CacheEvict(value = "transport-info", key = "#p0")public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {//省略代码//清除本地缓存中的数据this.transportInfoCache.invalidate(transportOrderId);//发布订阅消息到redis,通知其他节点删除 Caffeine 缓存this.stringRedisTemplate.convertAndSend(RedisConfig.CHANNEL_TOPIC, transportOrderId);//保存/更新到 MySQLreturn this.transportInfoMapper.save(transportInfoEntity);}5. 总结
最终我们解决了多级缓存间的一致性的问题。
更新数据时,先更新 MySQL,然后删除 Redis、本地 Caffeine 缓存,同时通过消息的方式通知其他节点删除 Caffeine 缓存。
读取数据时,先从 Caffeine 读取,再从 Redis 读取,最后再读取 MySQL。同时若查询后缓存未命中会自动缓存,比如Redis自动缓存MySQL数据,Caffeine 自动缓存 Redis 里的数据。
今天的分享就到这里了。
我是此林,关注我吧!带你看不一样的世界!