AI大模型微调教程7
1、目录


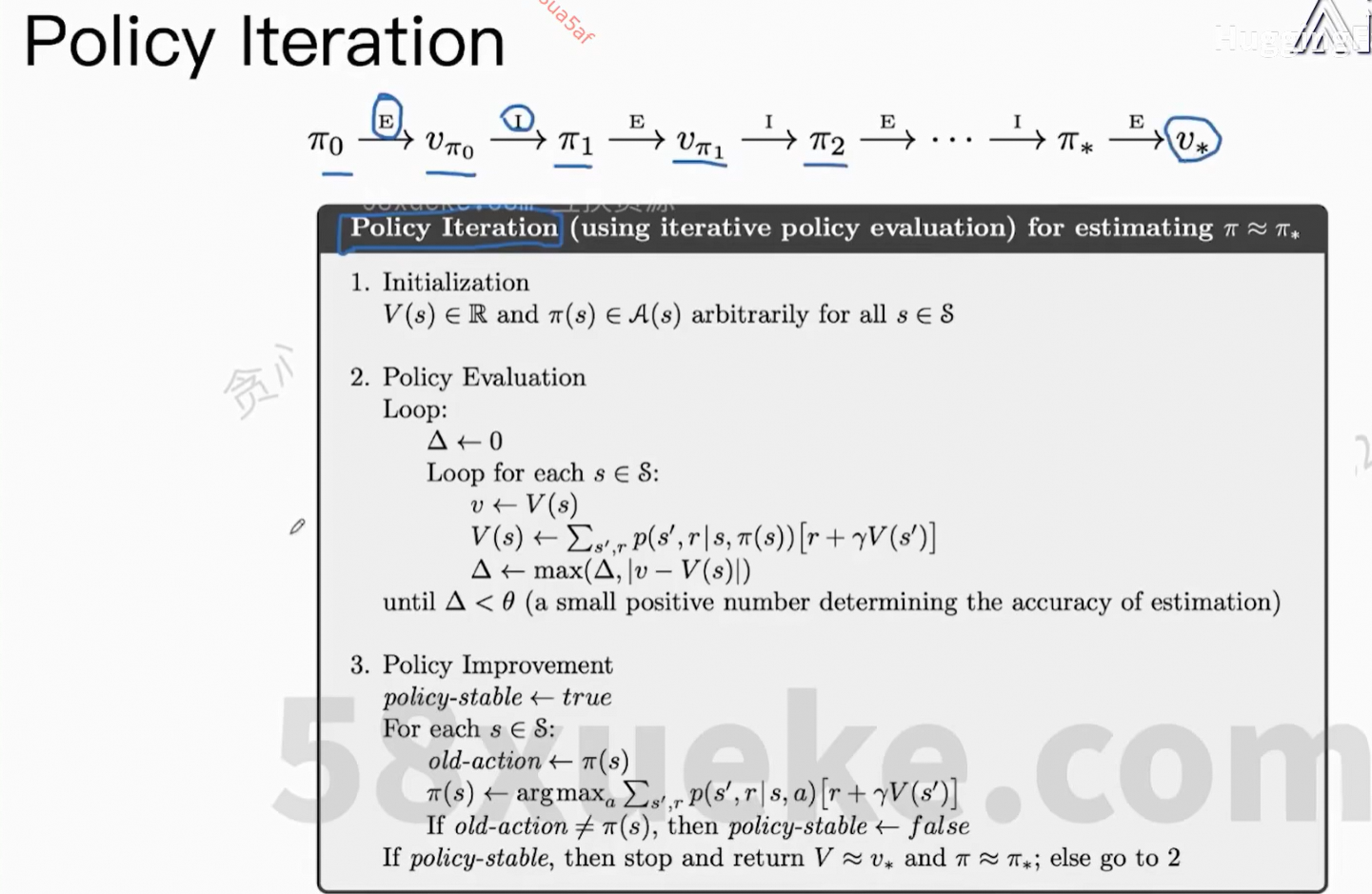
对齐主要方法:PPO、DPO
2、RLHF
SFT:增强大模型在某一方面的能力
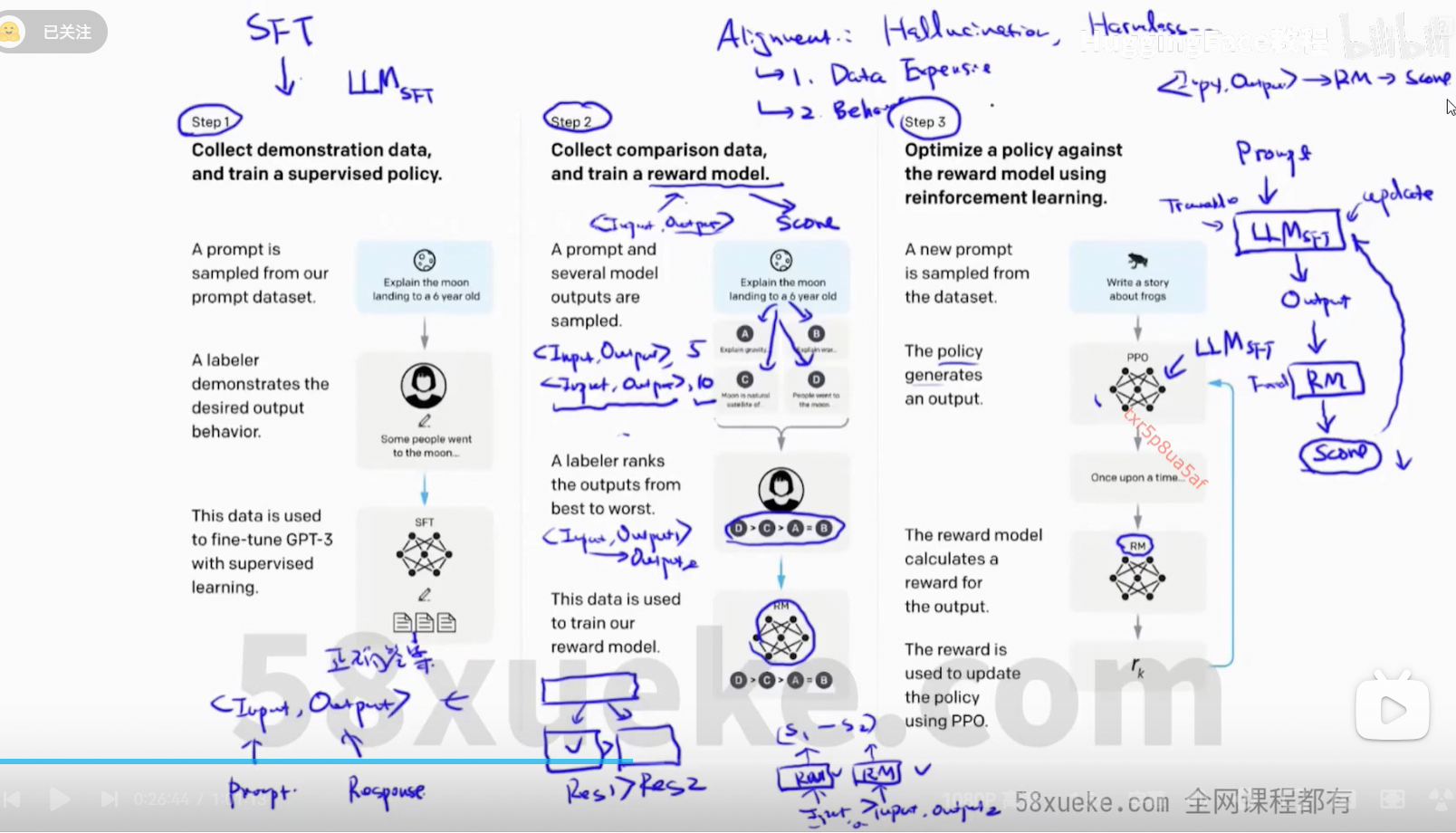
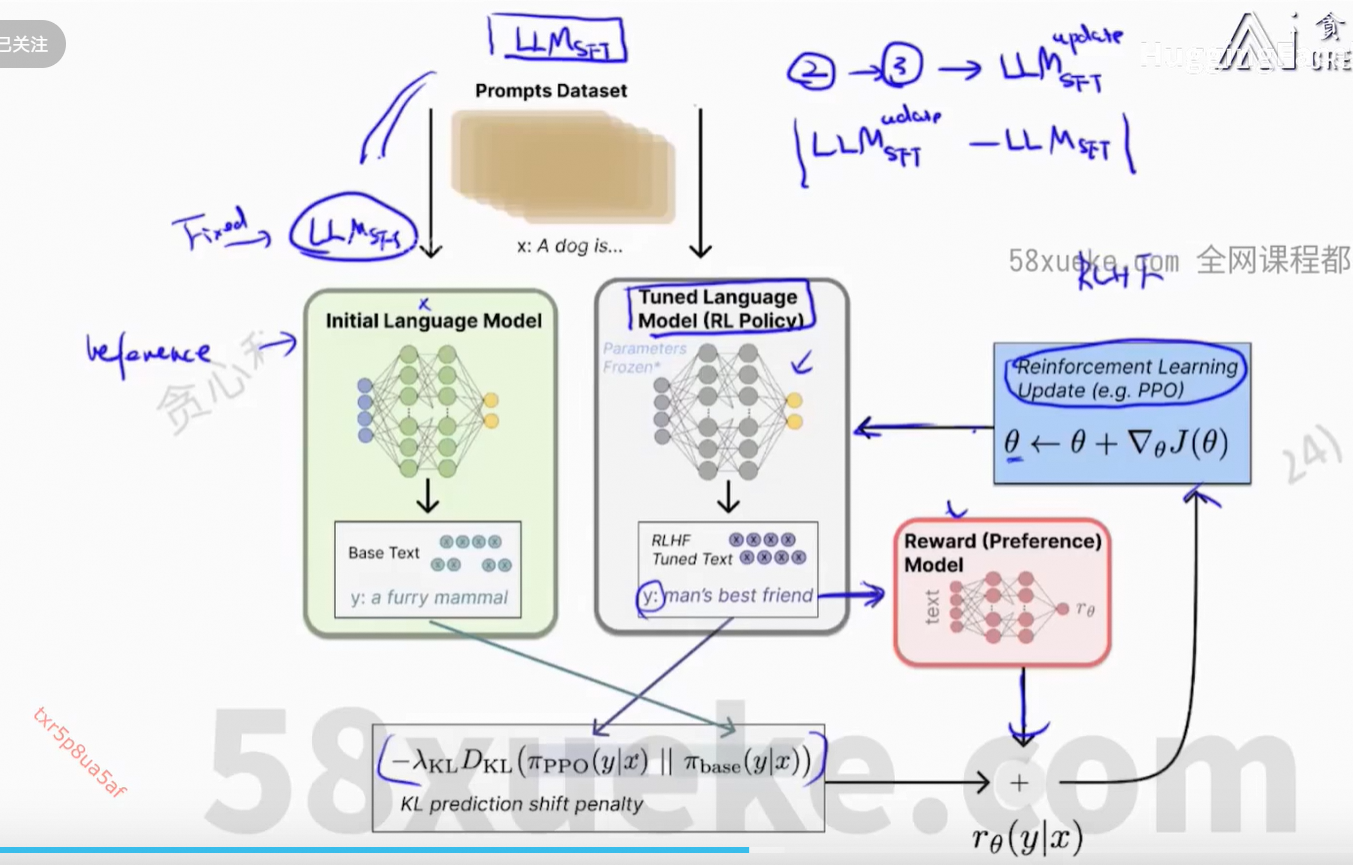

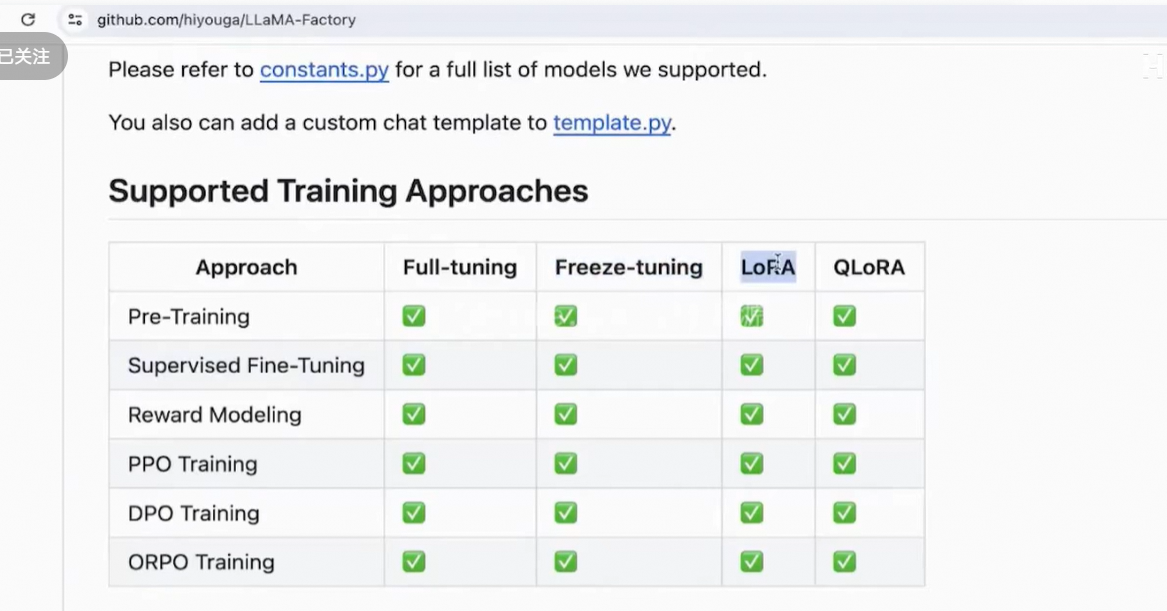
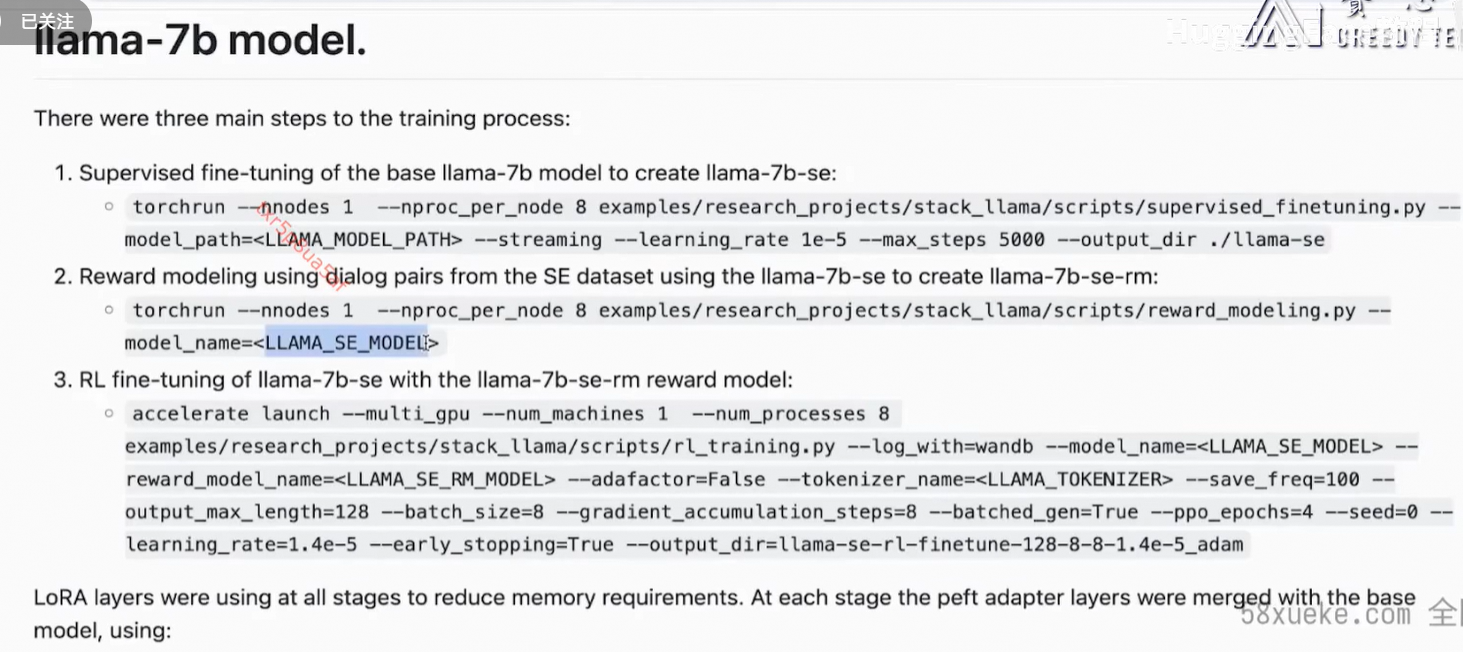
训练分3个阶段。
数据准备:
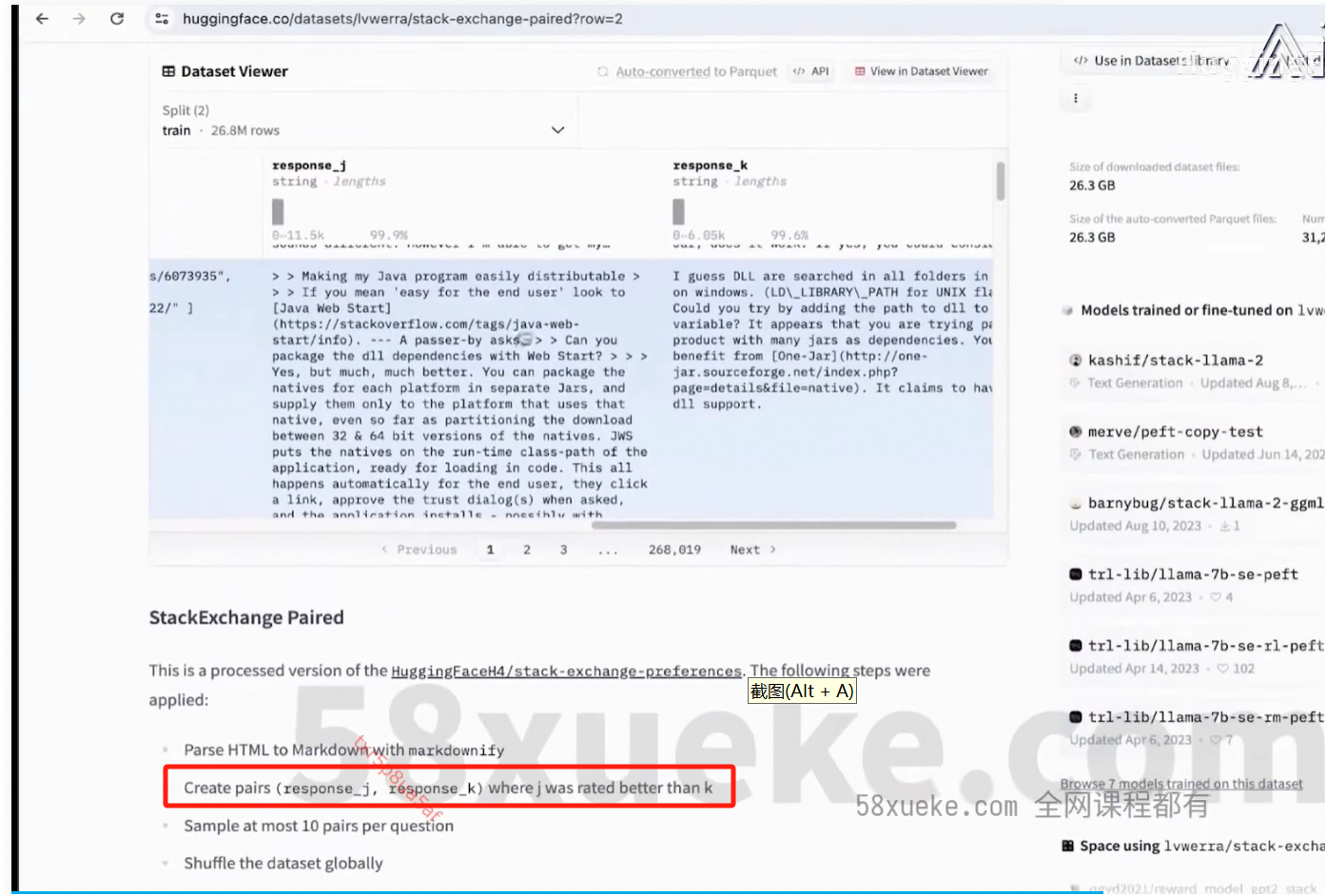
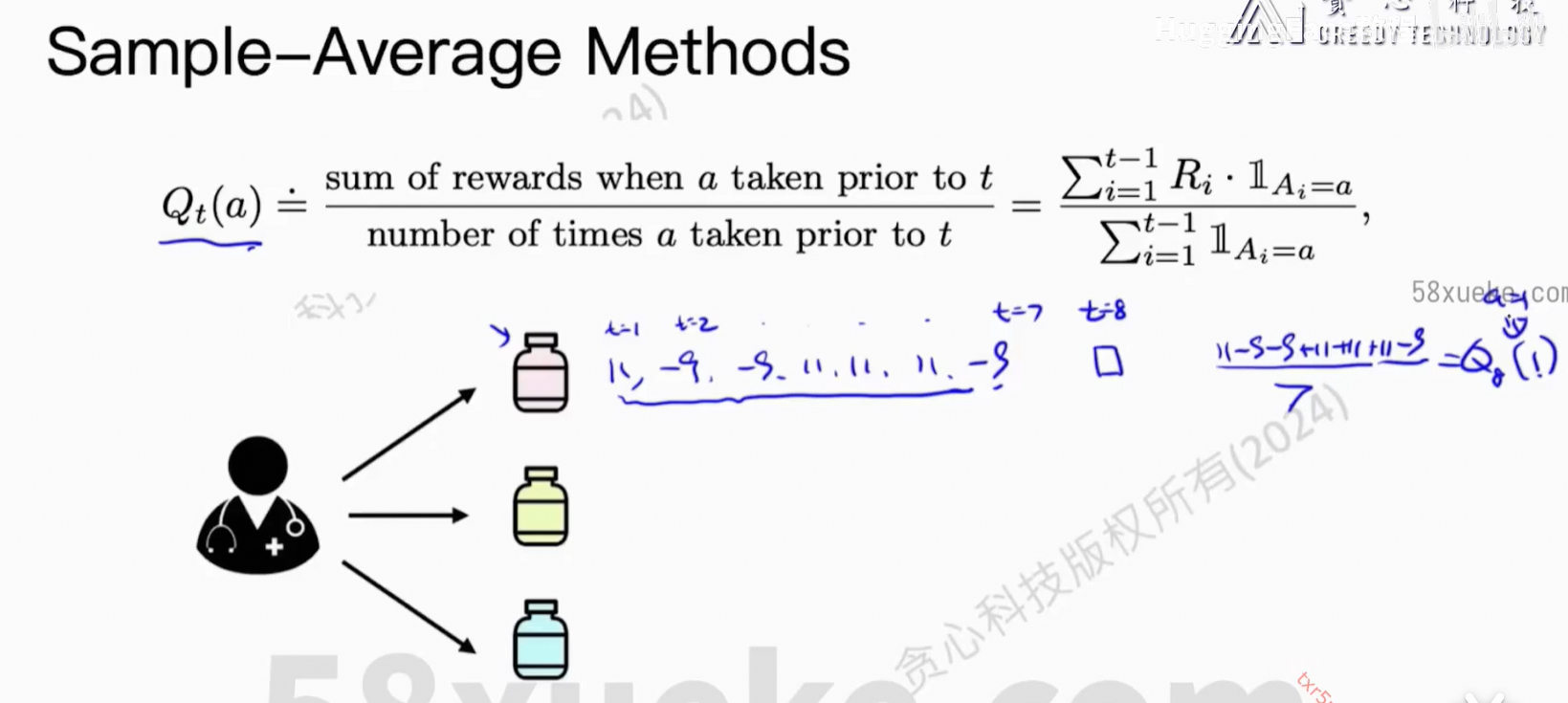
Reward模型数据处理:

score大于就是正确的,score小于就是错误的,而且大的程度越大越好。

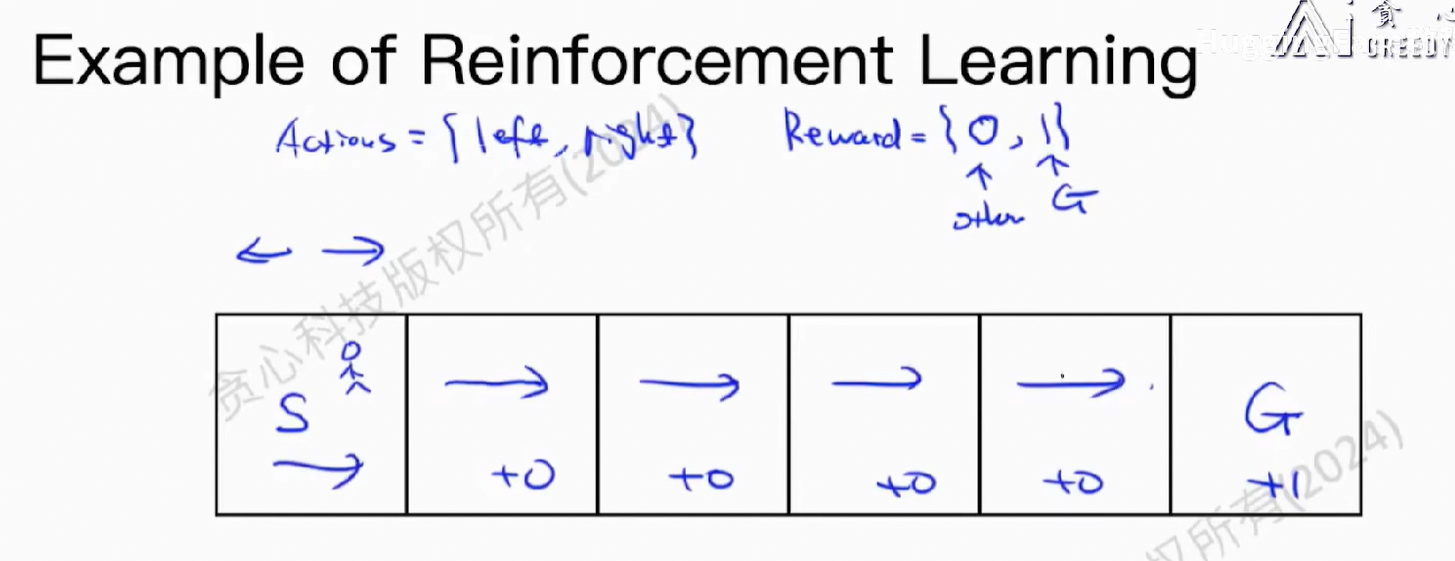
3、强化学习

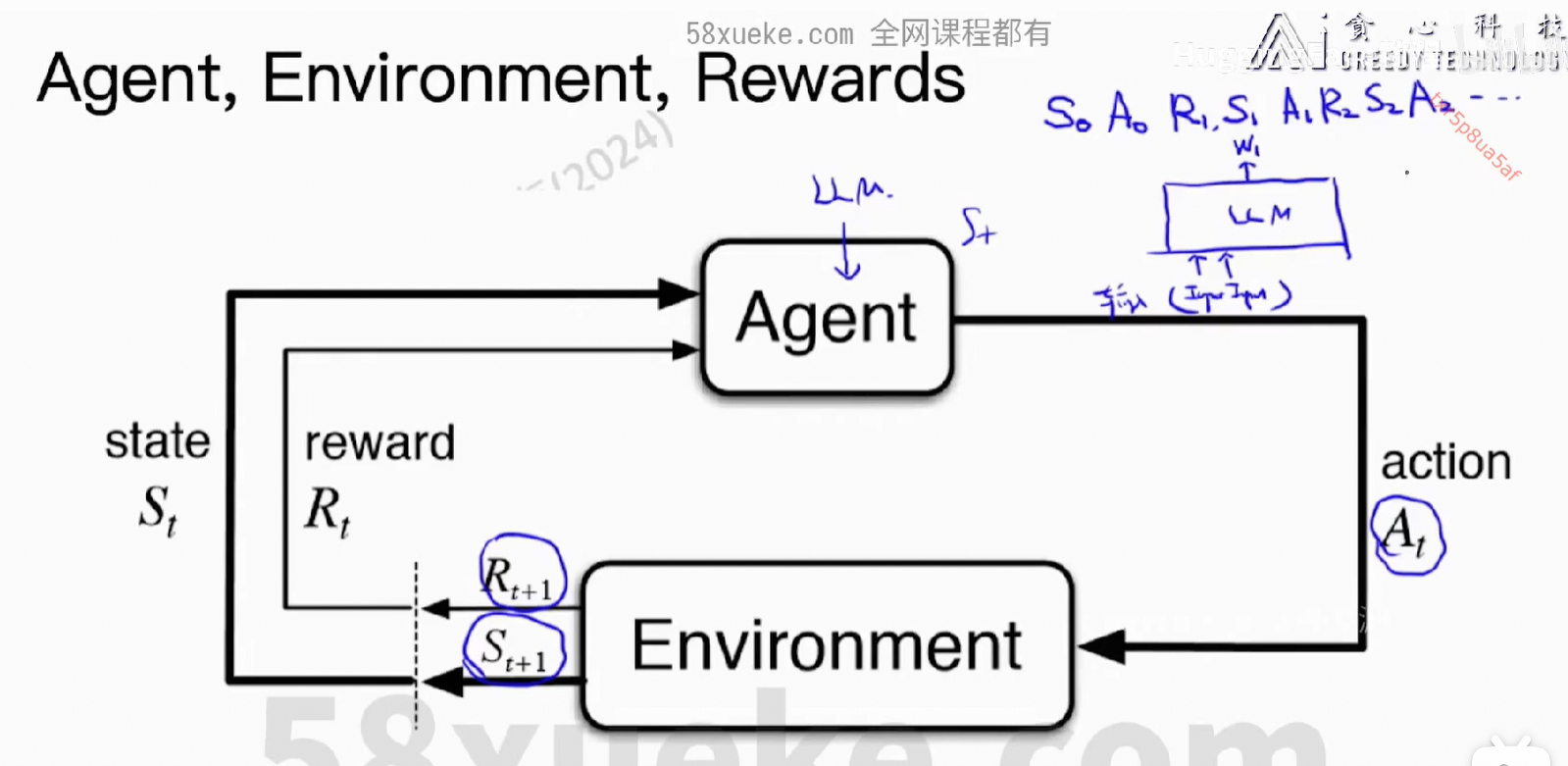
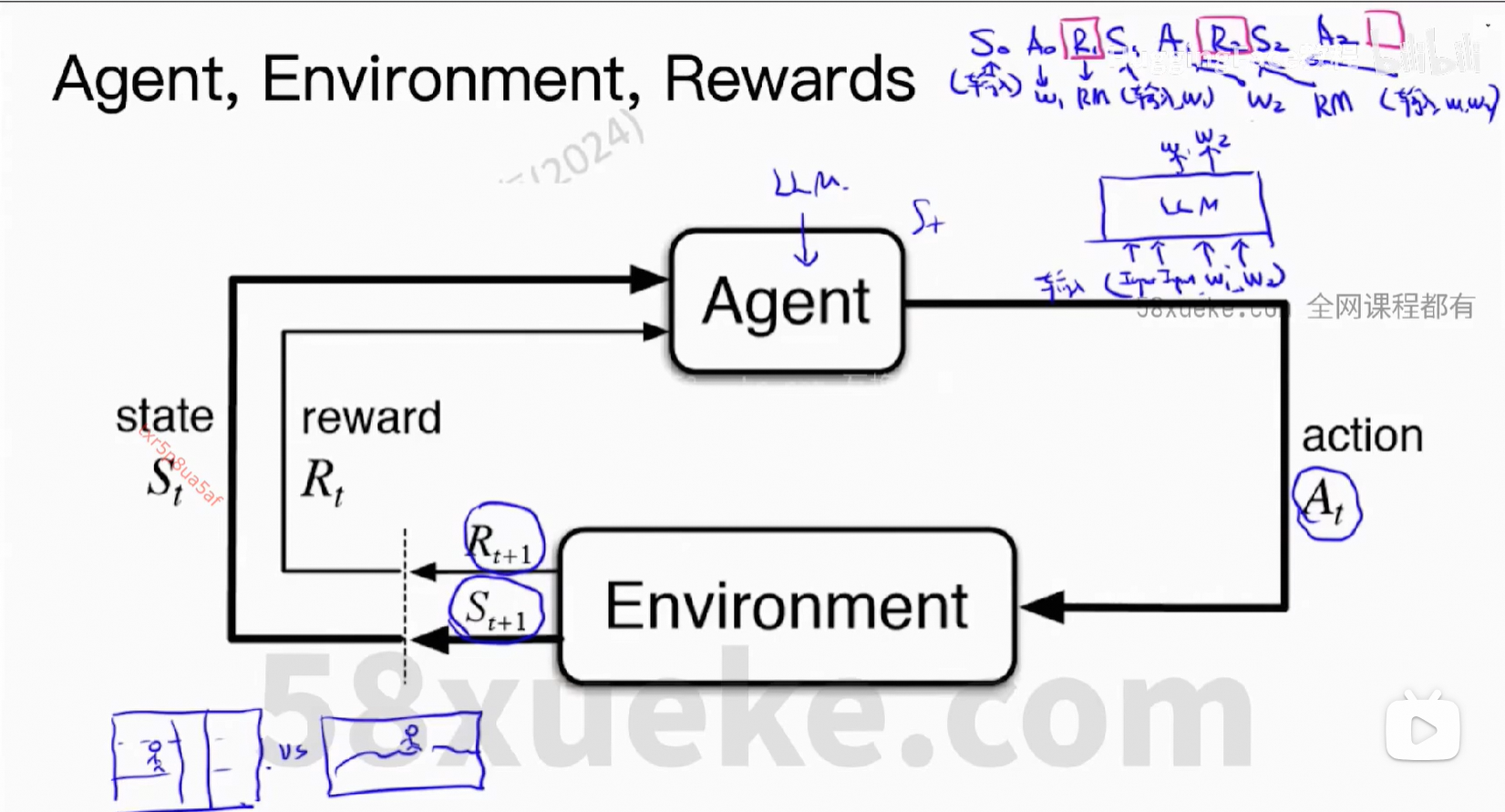
我们希望得到:reward之和最大

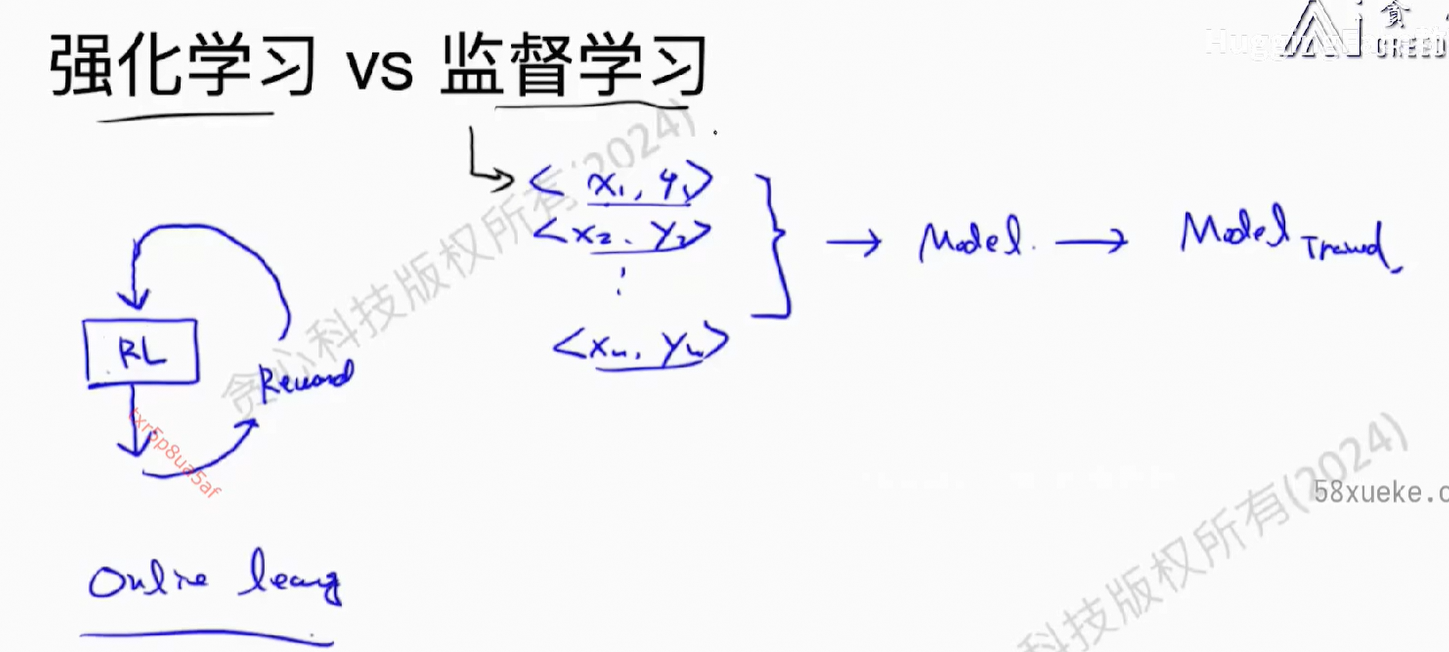
强化学习 vs 监督学习
1)监督学习,<input, output>提前准备好的,强化学习没有
2)监督学些,<input, output>数据是独立的,强化学习数据间是有关联的
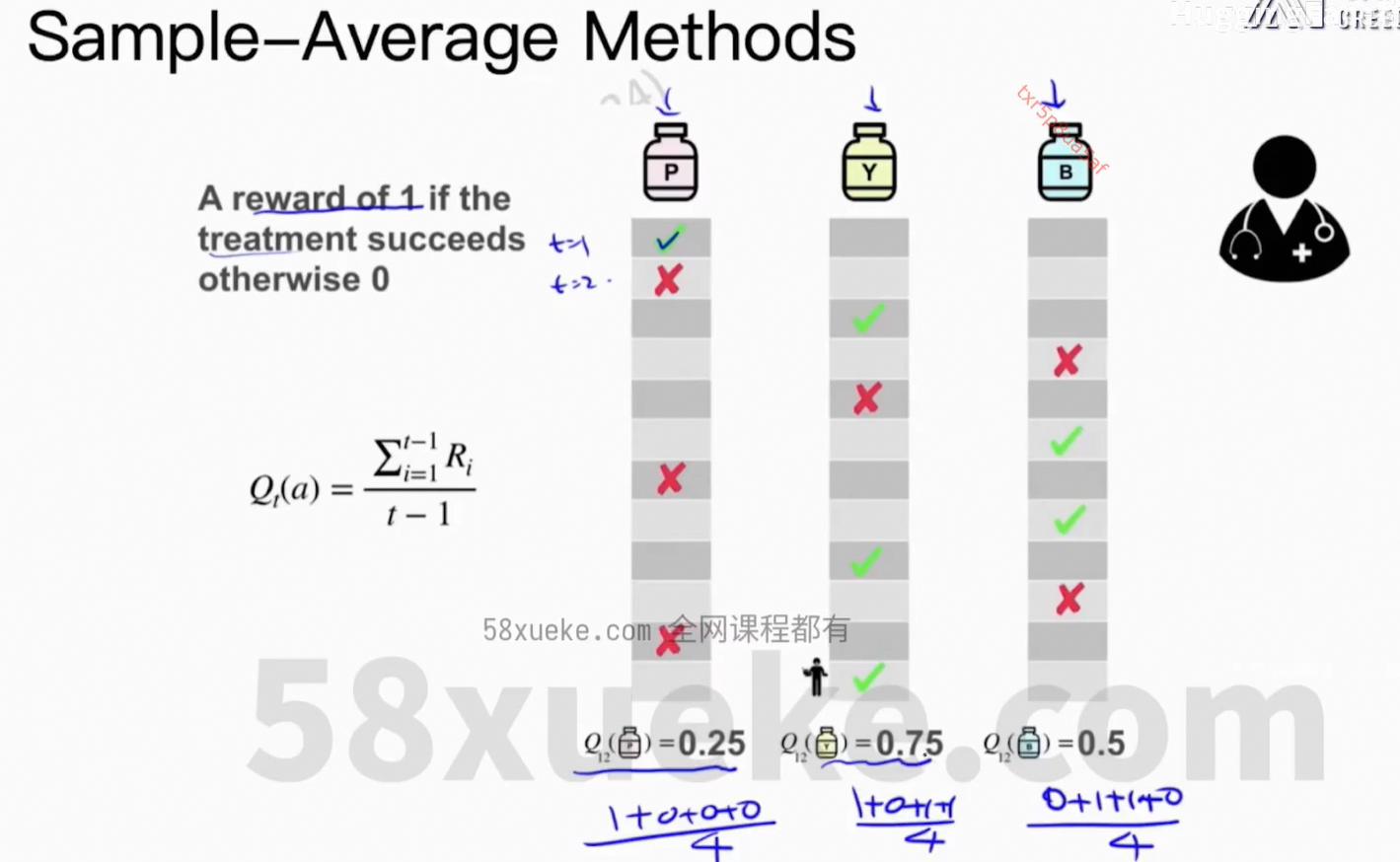
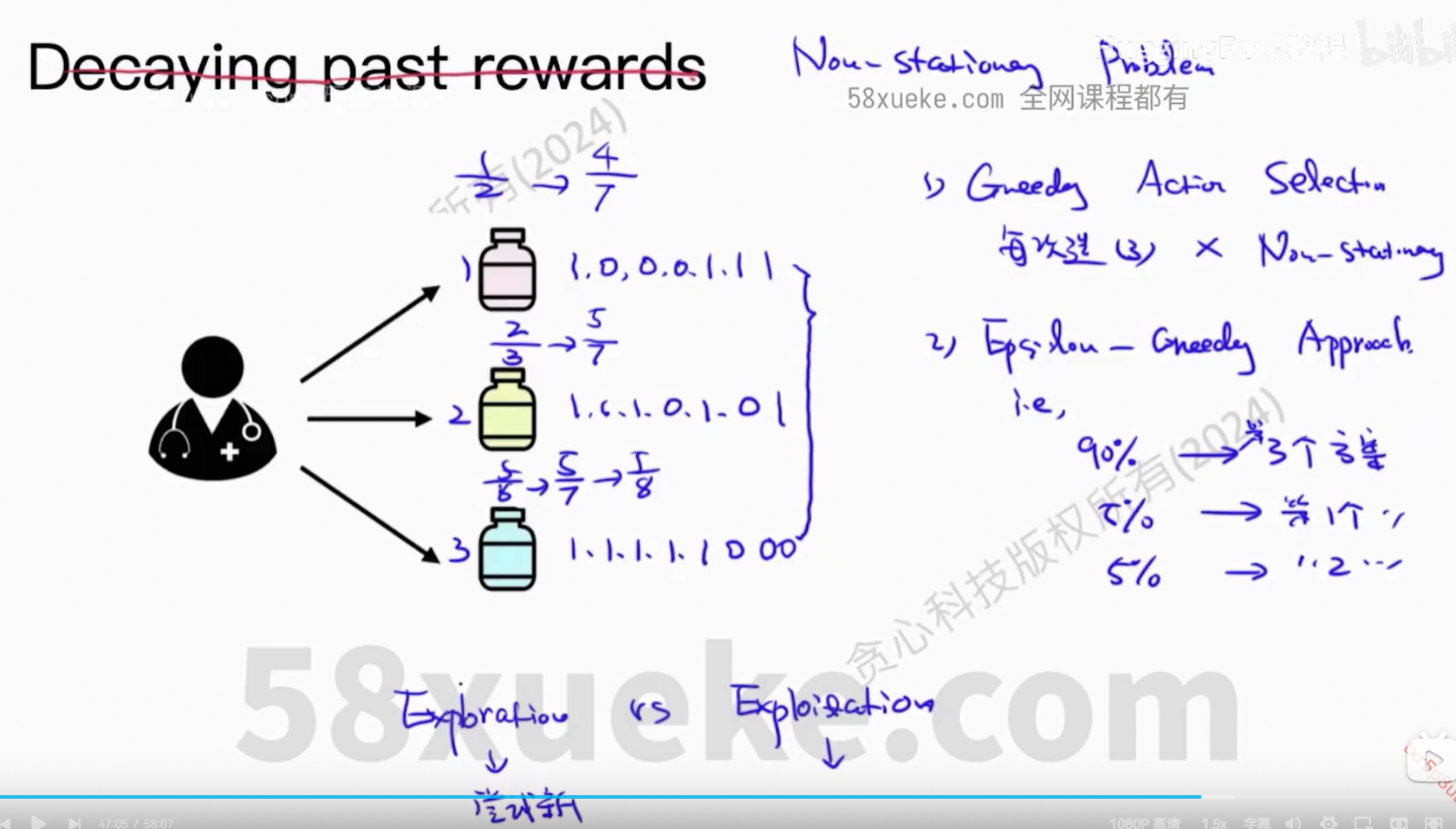
4、Multi-armed Bandit







5、The goal of agent
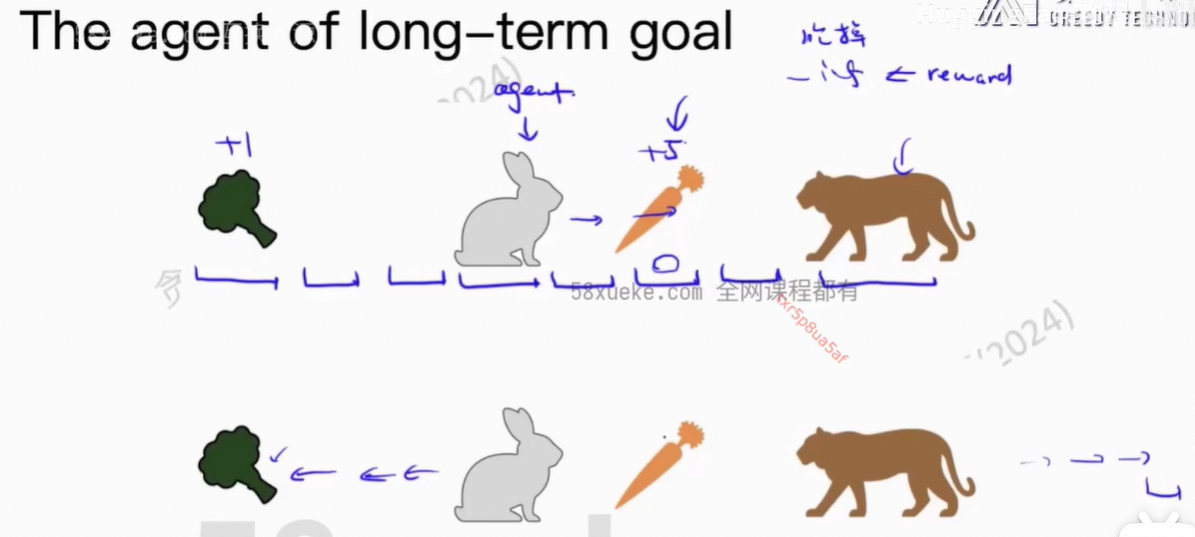

Agent的目标定义:长期的Reward最大化
对于随机变量,最常用的方法就是取期望值。
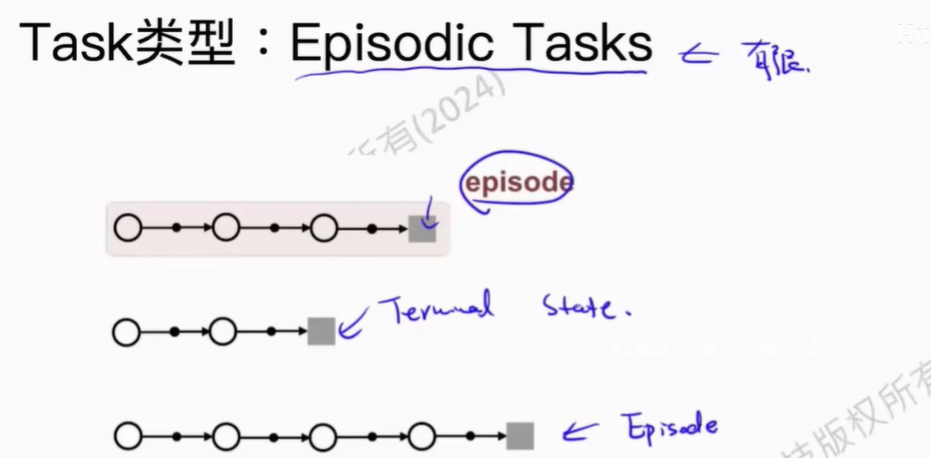
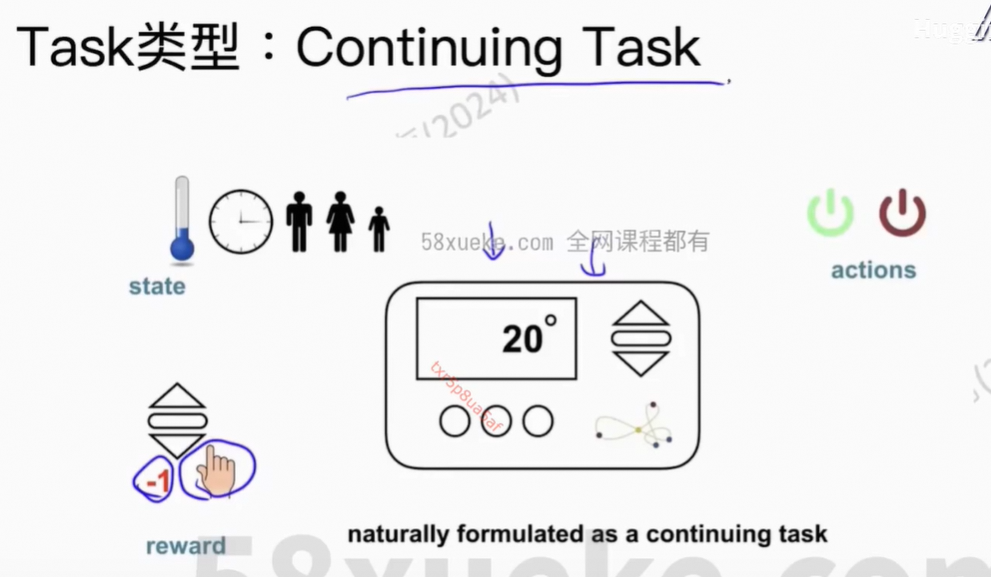



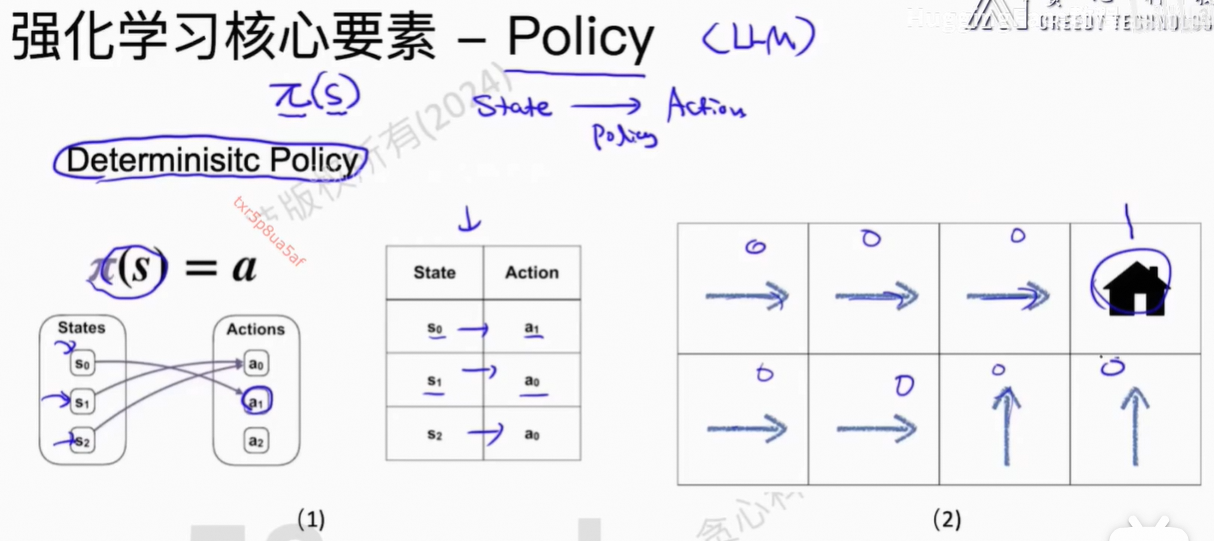
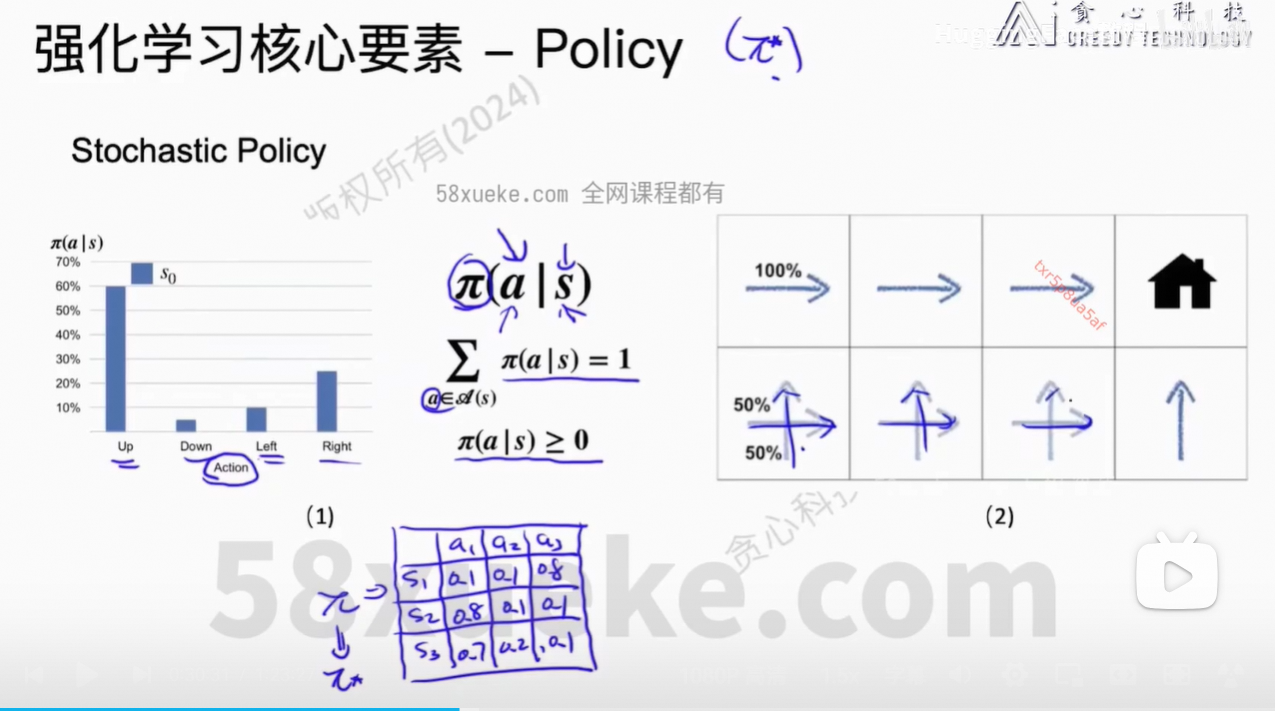

让Agent到达高价值点位。
State-Value Functions:在策略给定的情况下,评估一个状态的价值。
Action-value Functions:在某个状态下,某个动作的价值
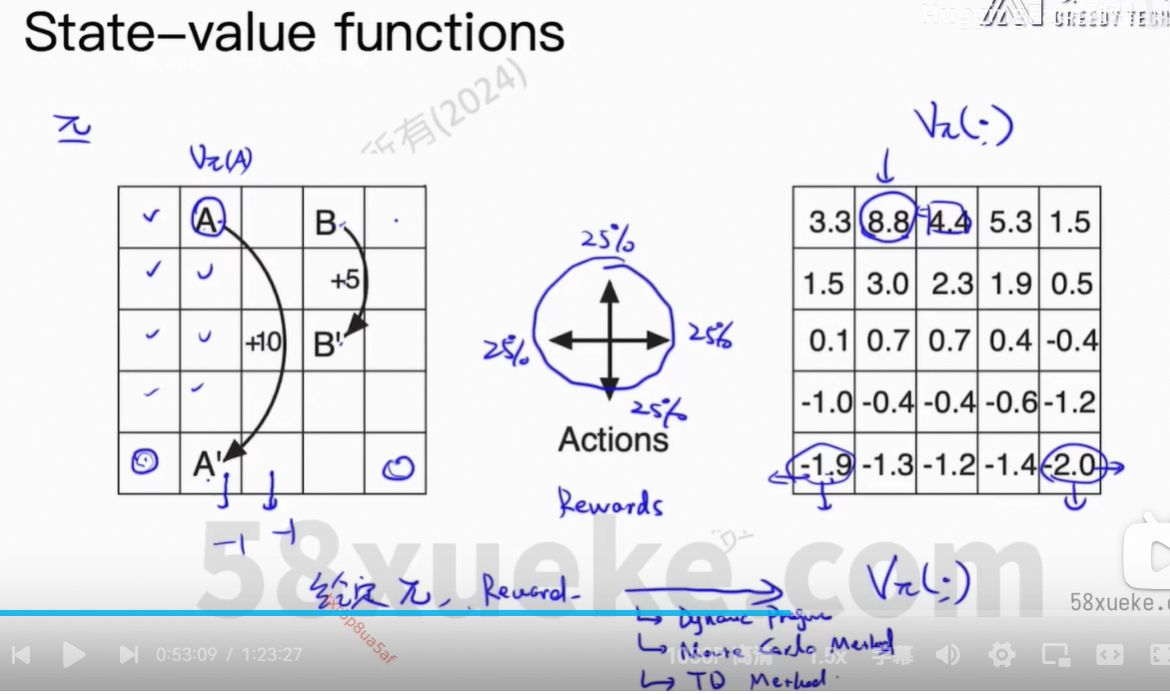

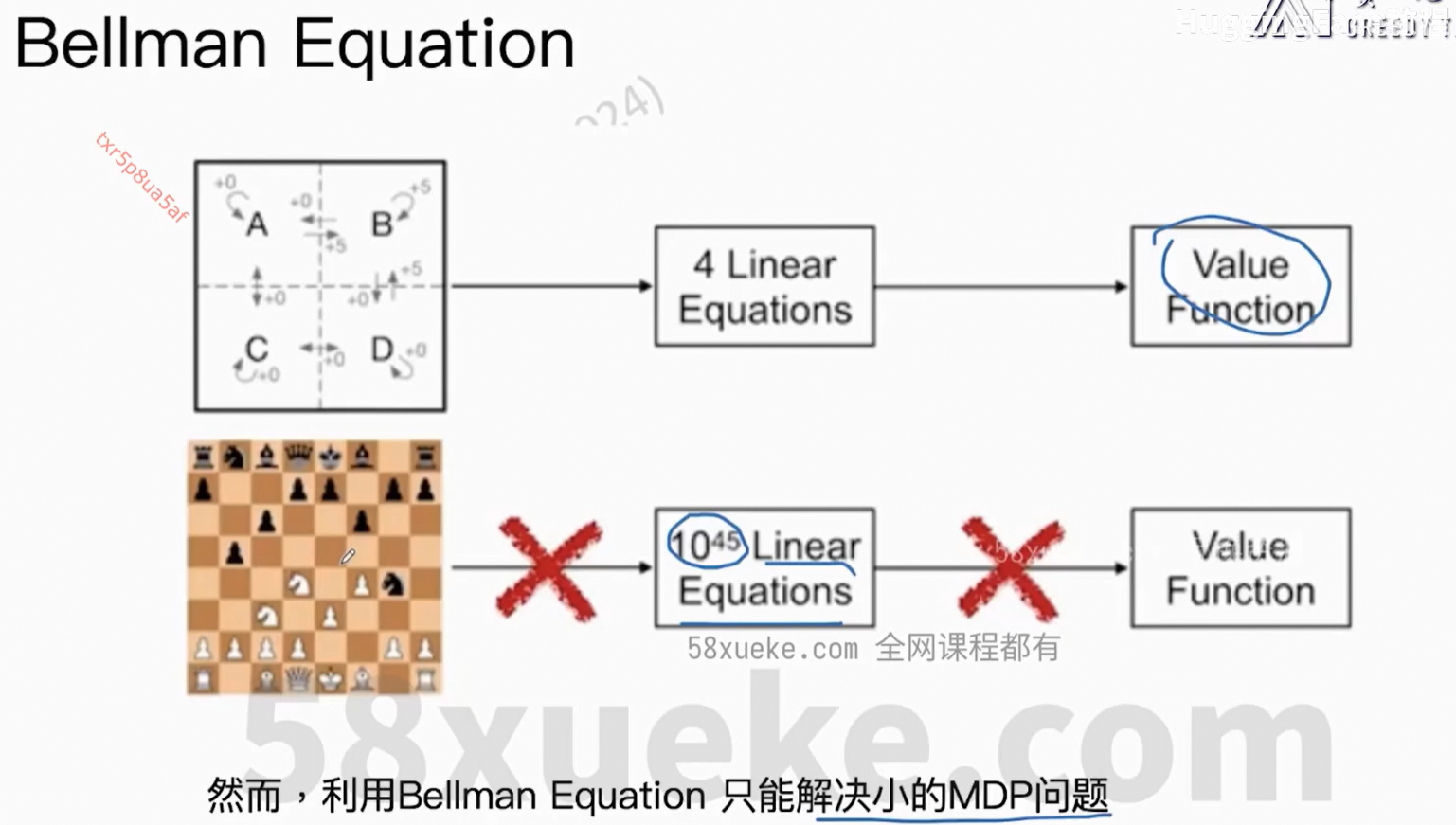
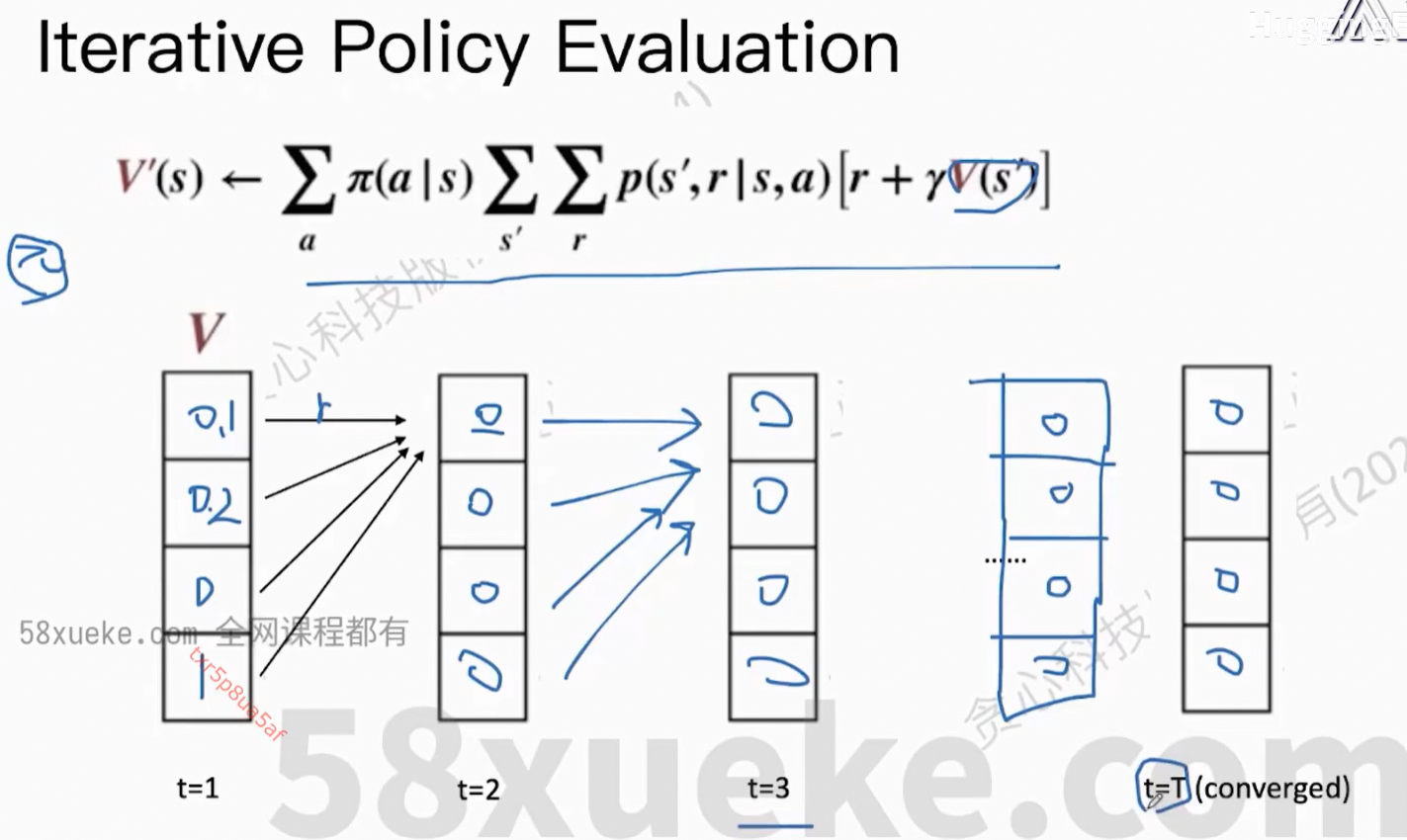
此公式非常重要。

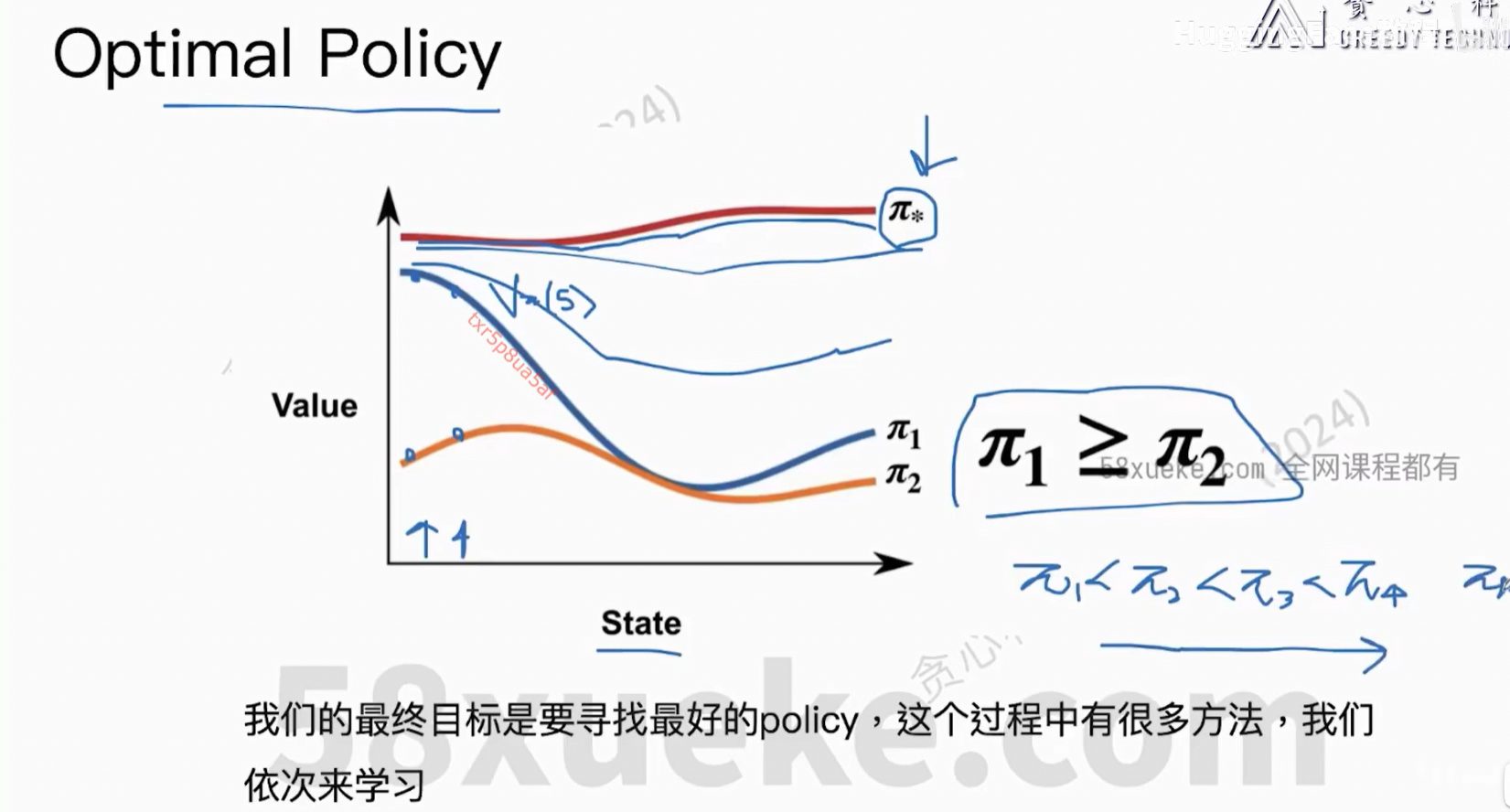
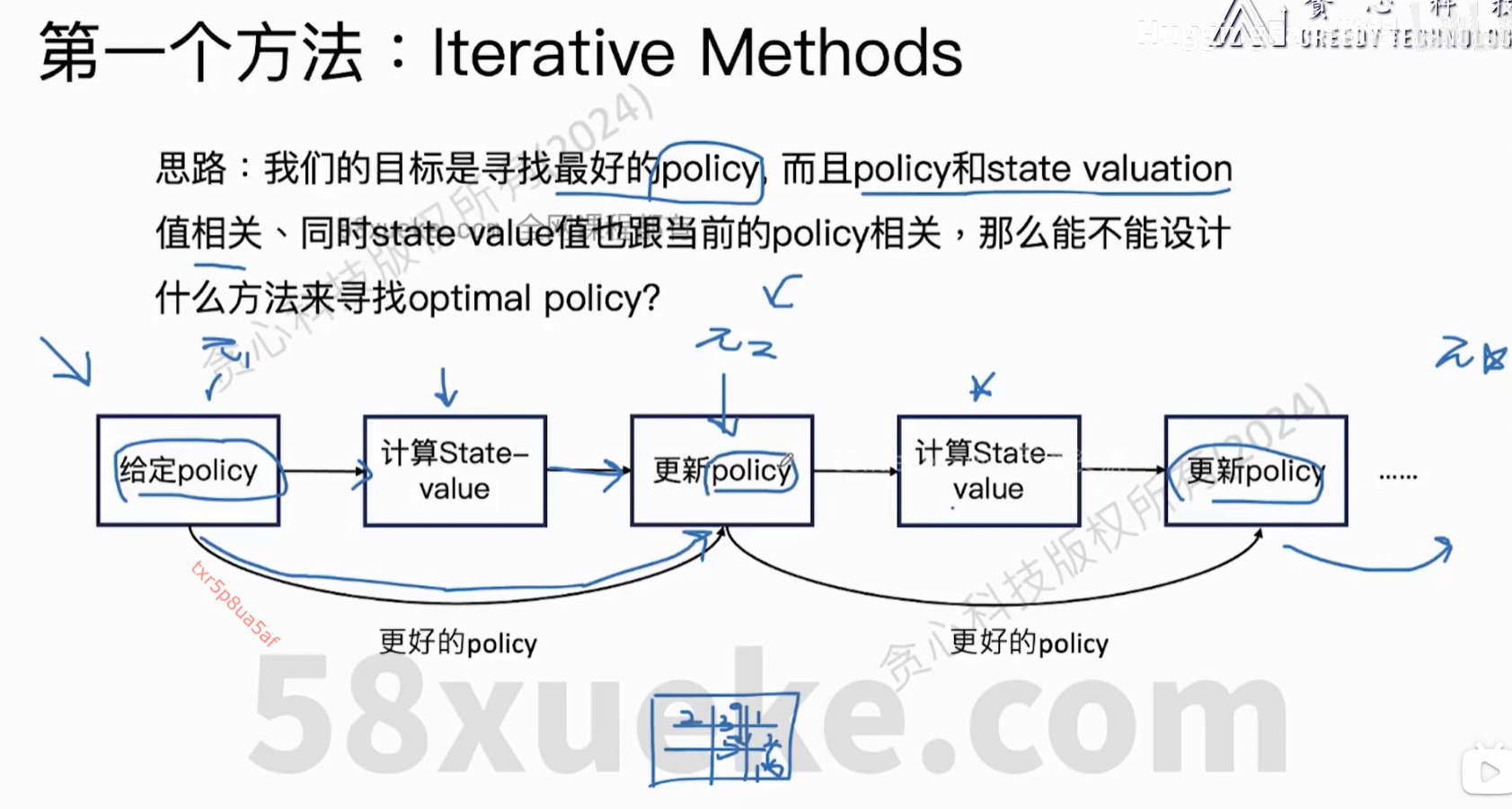
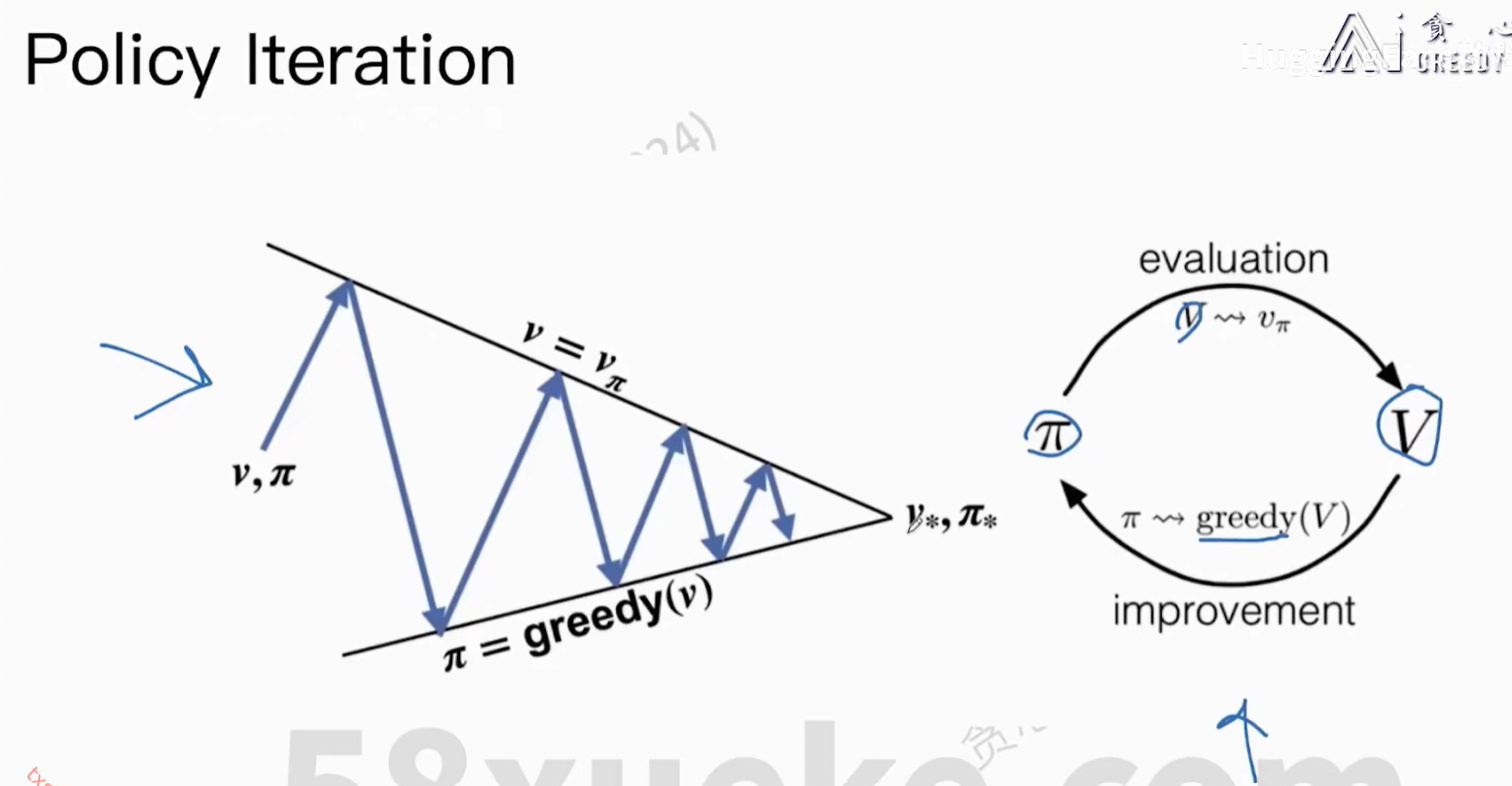
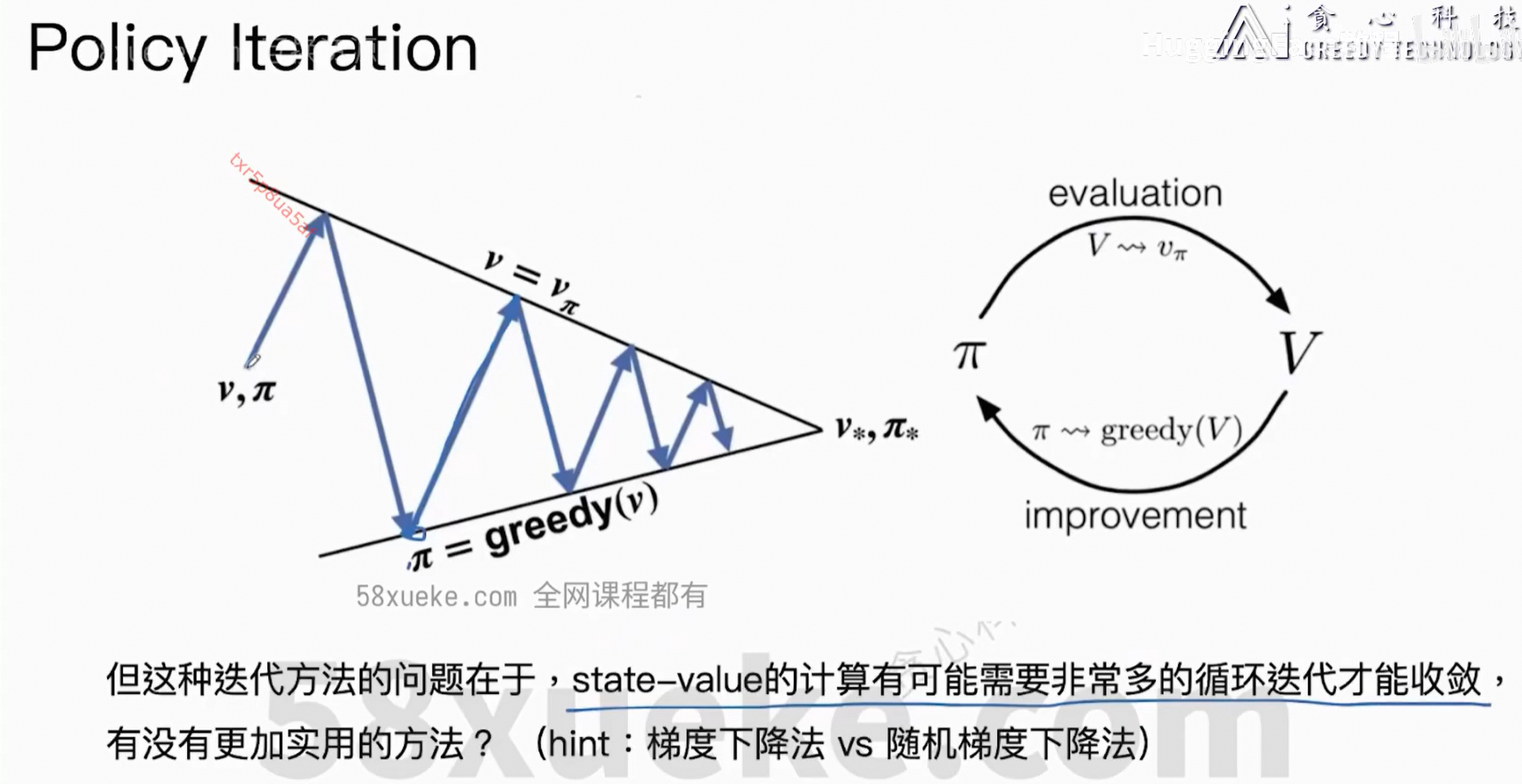
6、Optimal Policy