RAG开发
🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
RAG(Retrieval-Augmented Generation):
通⽤的基础⼤模型存在一些问题:检索增强生成
-
LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
-
LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
-
幻觉问题,LLM有时会在回答中⽣成看似合理但实际上是错误的信息
-
数据安全性
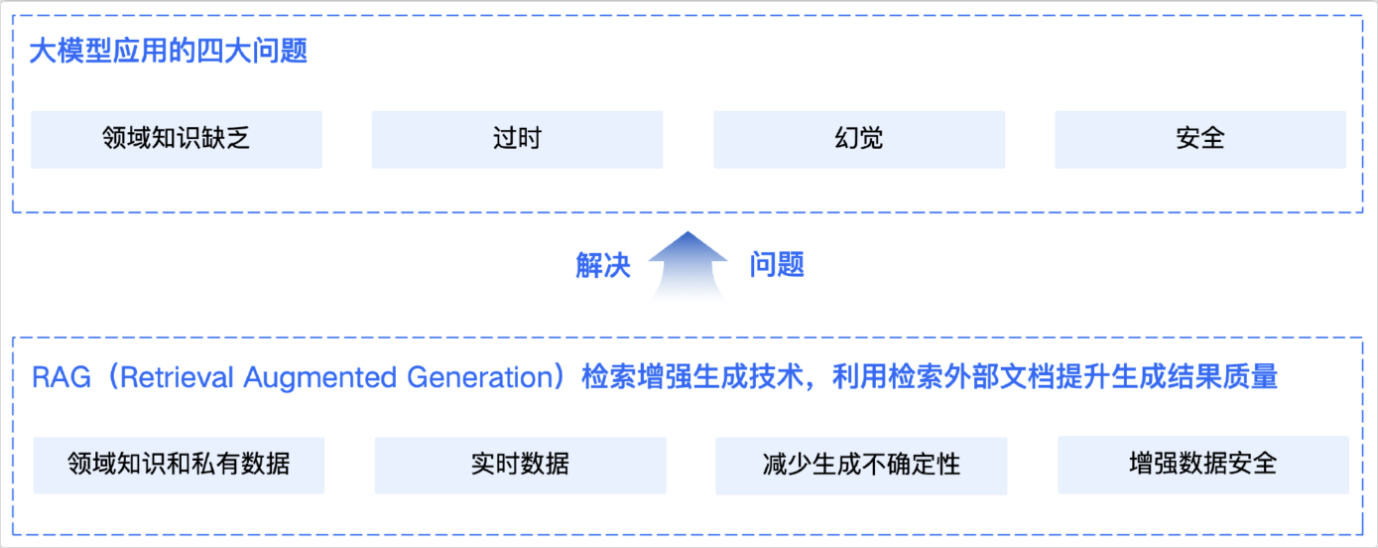
RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG = 检索技术 + LLM 提示
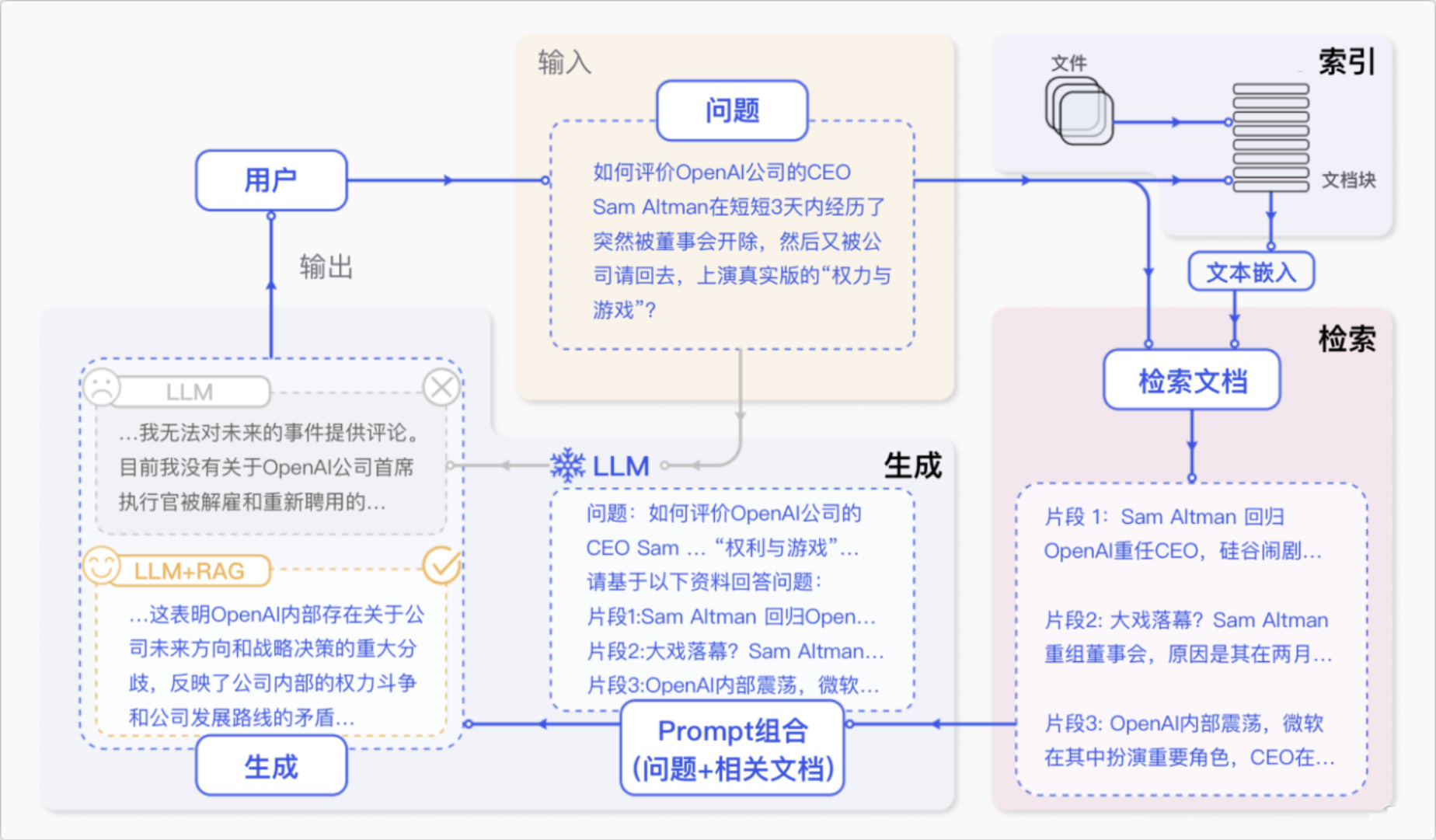
2. RAG标准流程
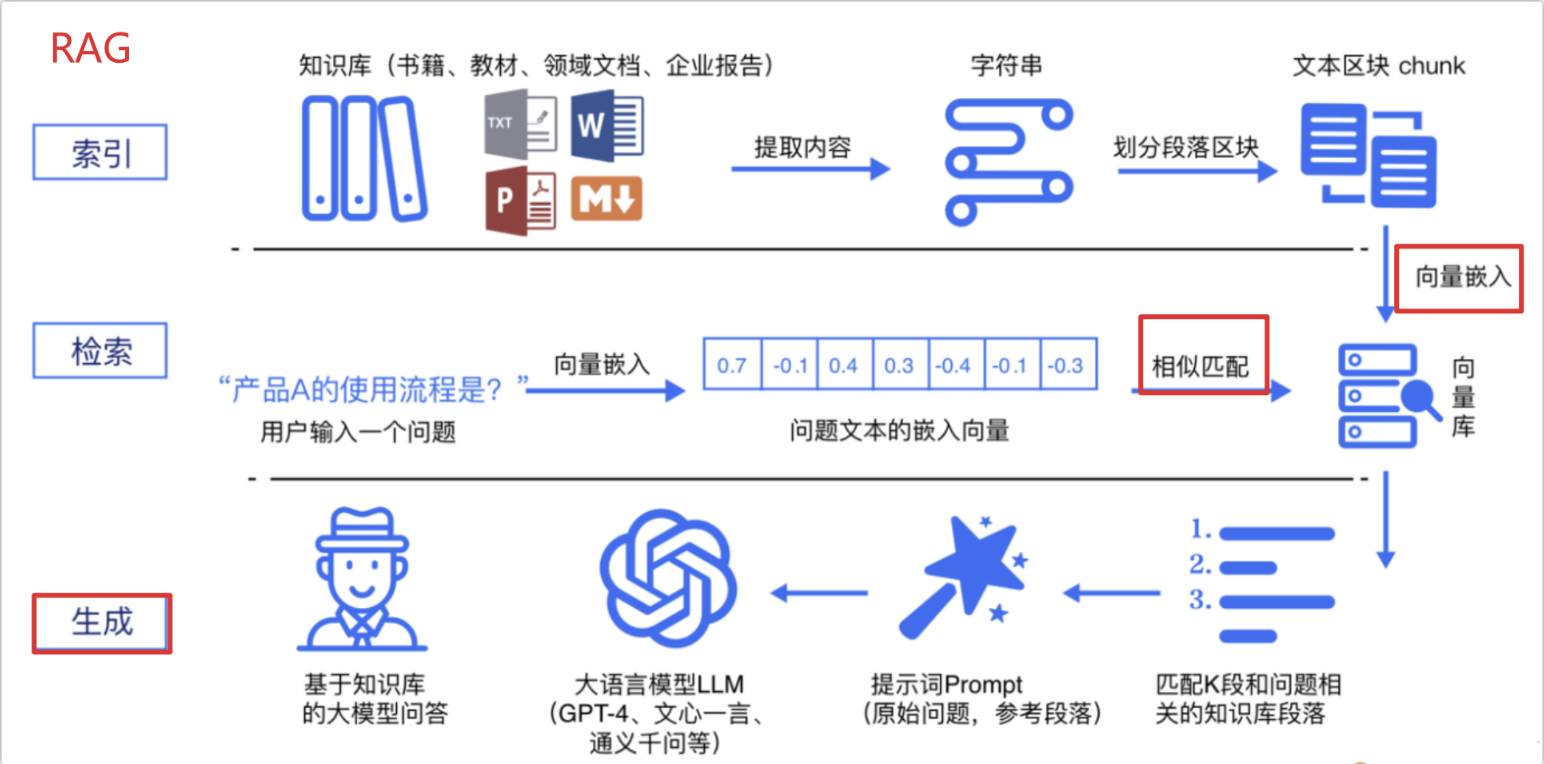
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。

-
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
-
加载文件
-
内容提取
-
文本分割 ,形成chunk
-
文本向量化
-
存向量数据库
(向量数据库:Weaviate、Milvus、Chroma、Faiss)
| 维度 | Weaviate | Milvus | Chroma | Faiss |
|---|---|---|---|---|
| 定位 | 语义搜索、RAG系统 | 大规模AI应用向量数据库 | 轻量化嵌入式向量数据库 | 高效相似性搜索库 |
| 性能 | 高性能,支持实时查询 | 超高性能,支持海量数据 | 高性能,适合中小规模数据 | 极高性能,支持百亿级向量 |
| 可扩展性 | 支持水平扩展 | 支持水平扩展和存储计算分离 | 适合从小规模到大规模应用 | 依赖硬件资源,适合大规模数据 |
| 易用性 | 提供RESTful API和SDK | 提供简单API和可视化管理界面 | 提供简洁Python API | 提供C++和Python接口 |
| 适用场景 | 语义搜索、知识图谱、推荐系统 | 图像识别、社交媒体分析、推荐系统 | 问答系统、知识库检索、个性化推荐 | 信息检索、机器学习、深度学习 |
-
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
-
query向量化
-
在文本向量中匹配出与问句向量相似的top_k个
-
生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
-
匹配出的文本作为上下文和问题一起添加到prompt中
-
提交给LLM生成答案:
RAG开发框架
面向RAG的开发框架,对于基于 LLM 的流水线和应用程序,有两个最著名的开源工具——分别是在2022年10月和11月创建的 LangChain 和 LlamaIndex。
RAG:langchain+Llamaindex
Llamalndex:文档管家,专注于"把文档变成可搜索的智能索引" 核心能力:文档处理,语义检索(让Al查到资料) LangChain(流程导演),专注于:把AI的思考步骤,工具调用。
对话逻辑串起来.例如:你想让AI先查资料->再整理成回答->最后生成PPT LangChain就会把这些步骤编成一条"链",还能集成工具(调用Python绘图,调用谷歌搜索),管理对话记忆(记住上轮信息)核心能力:流程编排,工具集成,对话管理(让Al"会思考,会做事")
配合使用,先用LlamaIndex处理文档,再使用LangChain搭建应用。
-
LangChain
RAG 是检索增强生成的缩写。它是一种将信息检索 与大语言模型 相结合的架构。在回答问题或生成文本时,RAG会先从外部知识库中检索相关信息,然后将这些信息作为上下文提供给LLM,从而生成更准确、可靠的答案。
-
定位:模块化、多功能的LLM应用开发框架,支持复杂工作流和交互式应用。
-
核心功能:
-
链式机制:通过串联多个组件(如数据加载、模型调用、结果处理)构建连续处理流程。
-
代理(Agent):利用LLM的推理能力动态决定操作顺序,实现自适应交互。
-
多模态支持:集成文本、图像、视频、API等多源数据,支持跨模态任务。
-
工具生态:提供现成的链、代理模板和部署工具(如LangServe、LangSmith)。
-
-
适用场景:多轮问答、工具调用系统、自动化数据分析、复杂AI助手等。
-
-
LlamaIndex
-
定位:专注于数据索引与检索的LLM增强框架,优化数据与模型的交互效率。
-
核心功能:
-
数据连接器:支持PDF、PowerPoint、Notion、Slack、Postgres、MongoDB等多样数据源。
-
智能索引:将文档分割为“Node”对象并构建索引,支持基于语义的快速检索。
-
查询引擎:通过NLP和提示工程实现自然语言查询,支持对话式交互。
-
RAG优化:动态检索最相关数据片段,增强LLM生成内容的准确性和上下文相关性。
-
-
适用场景:企业文档搜索、知识库问答、垂直领域数据检索等。
-