【大模型】多智能体架构详解:Context 数据流与工作流编排的艺术
Context 数据流与工作流编排的艺术
- 1、引言
- 2、 基石概念:工作流 vs. 智能体
- 3、 多智能体编排的核心架构:预定义数据流
- 3.1 核心组件
- 3.2 Context 数据流的实现
- 3.3 决策与数据选择机制
- 3.3.1 ReAct
- 3.3.2 Planning 和任务分解
- 3.3.3 Reflection 机制
- 4、总结
1、引言
**小屌丝:**鱼哥,能不能在给俺讲一讲数据流和工作流啊
**小鱼:**啥数据流、啥工作流?
**小屌丝:**额… 就是 多智能体的数据流和工作流啊
**小鱼:**这… 假期你是真以为我哪也不去啊?
**小屌丝:**再讲一篇呗,待会在去玩
**小鱼:**去哪?玩啥?
**小屌丝:**嘿嘿…
小鱼: 你这… 16种人格?
**小屌丝:**没没没~ ~
小鱼: 好怕怕 ~ 我还是说吧
**小屌丝:**嘿嘿…
2、 基石概念:工作流 vs. 智能体
在深入架构之前,必须厘清两个核心概念:
-
智能体:一个具有自主性的、能够感知、决策、行动的实体。它是系统的“工作者”,拥有自己的大脑、记忆和工具。例如:ResearchAgent, WriterAgent, ReviewAgent。
-
工作流:指的是 LLM 和工具通过预定义的代码路径进行编排的系统。在这种模式下,数据流动的路径是固定的、由开发者明确设计的,类似于上世纪流行的“专家系统”。例如:
- “第一步:分析用户邮件;
- 第二步:根据分析结果在日历中查找空闲时段;
- 第三步:起草会议邀请邮件”。
这种模式确定性高,易于调试和控制,非常适合有明确业务流程的场景
这里用我们熟悉的工作环境来比喻:
-
智能体 好比公司里的员工:设计师、程序员、产品经理。
-
工作流 好比产品的开发流程:需求评审 -> UI设计 -> 前端开发 -> 后端开发 -> 测试 -> 上线。
没有工作流,智能体们会陷入混乱,各自为战;没有智能体,工作流只是一纸空文,无法执行。
多智能体编排的核心,就是将动态的智能体嵌入到结构化的(或动态的)工作流中。
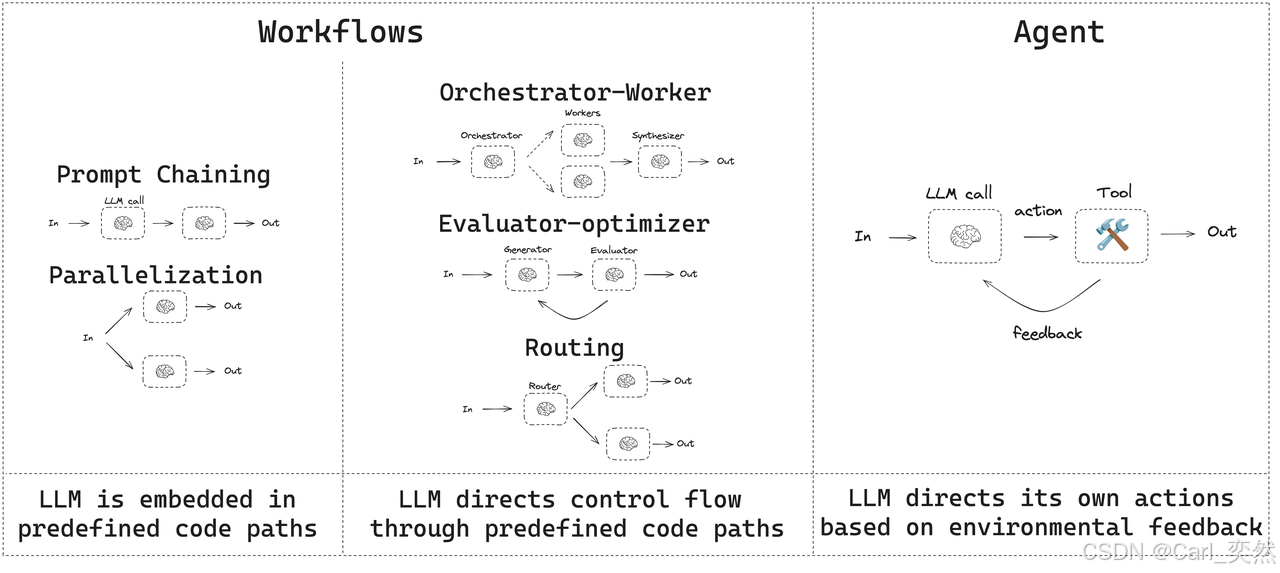
3、 多智能体编排的核心架构:预定义数据流
对于逻辑明确、步骤清晰的任务,我们通常采用预定义数据流 的架构。这种架构类似于传统的业务流程管理,但执行节点是自主的AI智能体。
3.1 核心组件
-
编排器:系统的大脑和中枢神经系统。它不执行具体任务,只负责:
- 解析工作流定义。
- 实例化并调度智能体。
- 管理智能体之间的数据流。
- 监控任务状态,处理错误和重试。
-
智能体池:一组注册在系统中的、可复用的智能体。每个智能体都有明确的职责描述、工具集和系统提示。
-
工作流定义:通常使用YAML、JSON或DSL来声明式地定义流程。
# 一个博客写作工作流的简化示例
workflow:name: "Blog Writing Pipeline"tasks:- id: researchagent: "ResearchAgent"inputs: { topic: "{{user_input}}" }outputs: [research_notes]- id: outlineagent: "OutlineAgent"inputs: { topic: "{{user_input}}", research: "{{research.output}}" }outputs: [blog_outline]- id: writeagent: "WriterAgent"inputs: { topic: "{{user_input}}", outline: "{{outline.output}}" }outputs: [blog_draft]- id: reviewagent: "ReviewAgent"inputs: { draft: "{{write.output}}" }outputs: [feedback]condition: "{{review.output.requires_revision}}" # 条件判断- id: reviseagent: "WriterAgent"inputs: { draft: "{{write.output}}", feedback: "{{review.output}}" }outputs: [final_blog]condition: "{{review.output.requires_revision}}"
- 共享上下文/数据总线:这是Context 数据流的载体。它是一个在任务之间传递数据的结构化存储。每个任务的输出都会被存储在这里,并可以被后续任务通过类似 {{task_id.output}} 的模板语法引用。
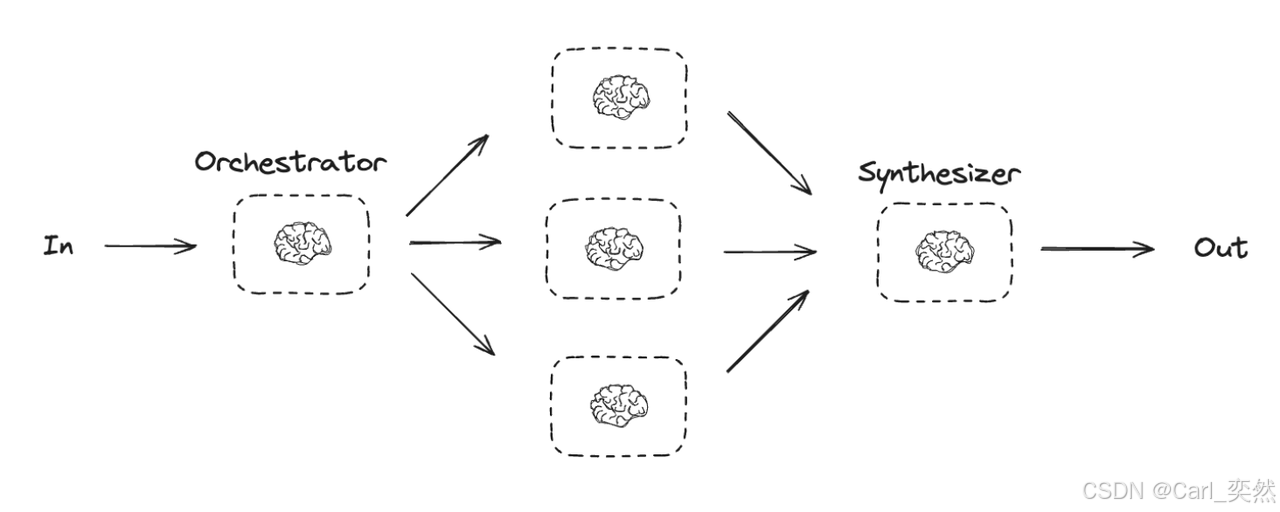
3.2 Context 数据流的实现
在上述架构中,Context 的流动是清晰可溯的:
-
输入注入:编排器将初始用户输入(如 topic: “AI Agents”)注入共享上下文。
-
任务执行:
-
编排器启动 ResearchAgent,并将 topic 作为其输入上下文的一部分传递给它。
-
ResearchAgent 执行自己的工作循环(可能包括搜索、阅读、总结),最终产出 research_notes。
-
-
输出存储:ResearchAgent 将 research_notes 返回给编排器,编排器将其存入共享上下文,并标记为 research.output。
-
数据传递与接力:
- 编排器启动下一个任务 OutlineAgent。它的输入上下文被构建为:{ topic: “AI Agents”, research: research_notes }。
- OutlineAgent 无需重复研究,它直接基于上游的产出进行工作,生成 blog_outline。
-
条件路由:在 review 任务后,工作流根据 ReviewAgent 的产出(如 {requires_revision: true, feedback: “…”})中的字段决定是走向 revise 任务还是直接结束。
这种架构的优势在于:
- 清晰可控:数据流和任务顺序一目了然,易于调试和监控。
- 高内聚低耦合:每个智能体只需关心自己的输入和输出,无需知道其他智能体的存在。
- 可复用性:WriterAgent 可以在 write 和 revise 两个不同的任务中被复用。
3.3 决策与数据选择机制
3.3.1 ReAct
框架ReAct(Reasoning and Acting)是一个基础且强大的框架,它通过模拟人类的“Reasoning-Acting”模式,使LLM能够动态地决定数据需求。
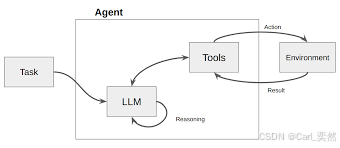
其核心是一个循环:
- 思考(Thought):LLM 首先进行内部推理。它分析当前任务和已有信息,判断是否缺少完成任务所需的知识,并制定下一步的行动计划。例如:“用户问我今天旧金山的天气,但我不知道。我需要调用天气查询工具。”
- 行动(Action): LLM 决定调用一个具体的工具,并生成调用该工具所需的参数。例如:Action: search_weather(location=“San Francisco”)。
- 观察(Observation):系统执行该行动(调用外部 API),并将返回的结果作为“观察”数据提供给LLM。例如:Observation: “旧金山今天晴,22摄氏度。”
- 再次思考: LLM 接收到新的观察数据,再次进入思考环节,判断任务是否完成,或是否需要进一步的行动。例如:“我已经获得了天气信息,现在可以回答用户的问题了。”
在这个循环中,数据流是根据 LLM 的“思考”结果动态生成的。
当LLM判断需要外部数据时,它会主动触发一个“行动”来获取数据,然后将获取到的“观察”数据整合进自己的上下文中,用于下一步的决策。
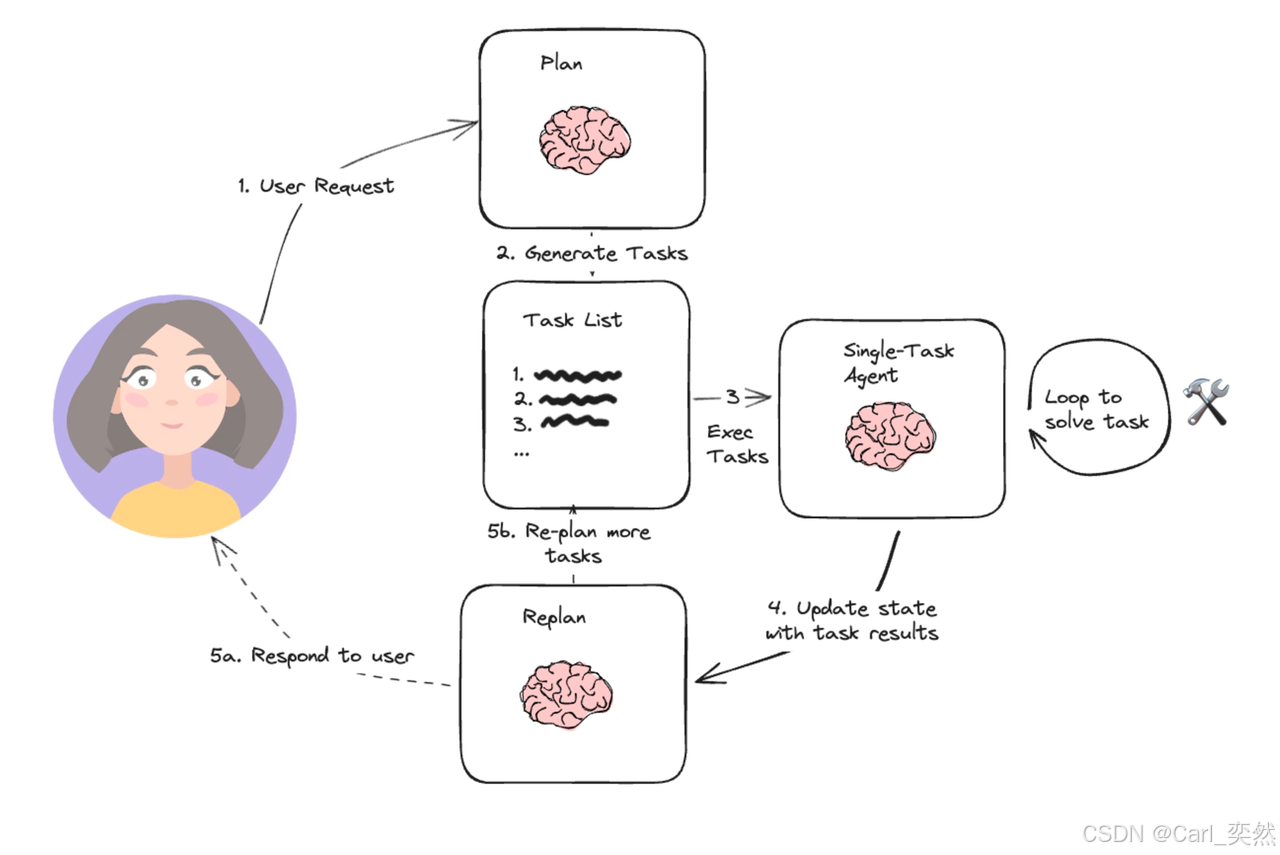
3.3.2 Planning 和任务分解
对于更复杂的任务,智能体通常会先进行规划(Planning)。一个高阶的规划模块会将用户的宏大目标分解成一系列更小、更具体、可执行的子任务。数据流向: 规划模块的输出是一份“计划清单”(Planning List),这份清单定义了后续一系列模块的调用顺序和数据依赖关系。
3.3.3 Reflection 机制
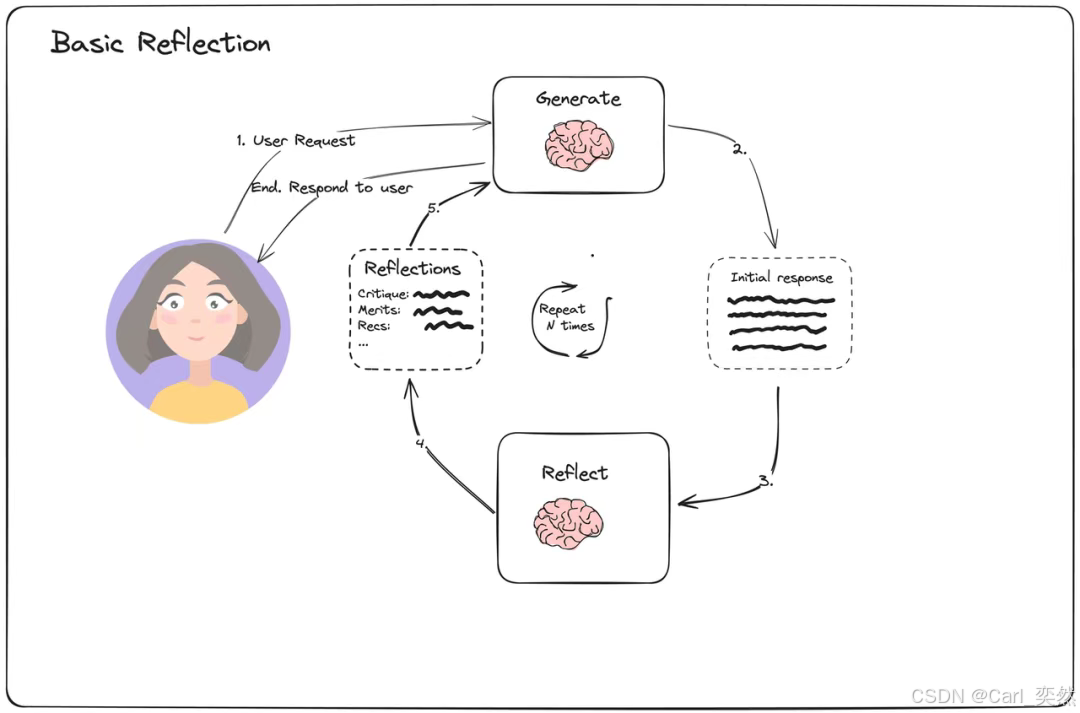
先进的智能体架构还包含反思(Reflection)机制 。智能体在执行完一个动作或完成一个子任务后,会评估其结果的质量和正确性。如果发现问题,它可以自我修正,重新规划路径。
4、总结
从预定义的流水线到动态自适应的协作网络,多智能体架构的演进,本质上是Context Engineering思想的深化。
它不再是简单地设计流程,而是构建一个能够让信息(Context)在正确的时间、以正确的方式、流向正确的智能体的信息生态系统。
未来,随着框架的成熟和模型能力的增强,多智能体系统将不再仅仅是自动化工具,而是能够自主理解环境、动态组织资源、持续进化的“数字生命体”,成为推动企业乃至社会智能化转型的核心引擎。
我是小鱼:
- CSDN 博客专家;
- AIGC 技术MVP专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【人工智能与大模型】最新最全的领域知识。