C++用哈希表封装unordered_set和unordered_map
1.unordered_set和unordered_map的底层结构
unorder_set和unordered_map的底层存储的都是一个哈希表,他们的插入、删除和查找本质上都是哈希表的插入、删除和查找。那么如何封unorder_set和unordered_map使他们复用哈希表呢?
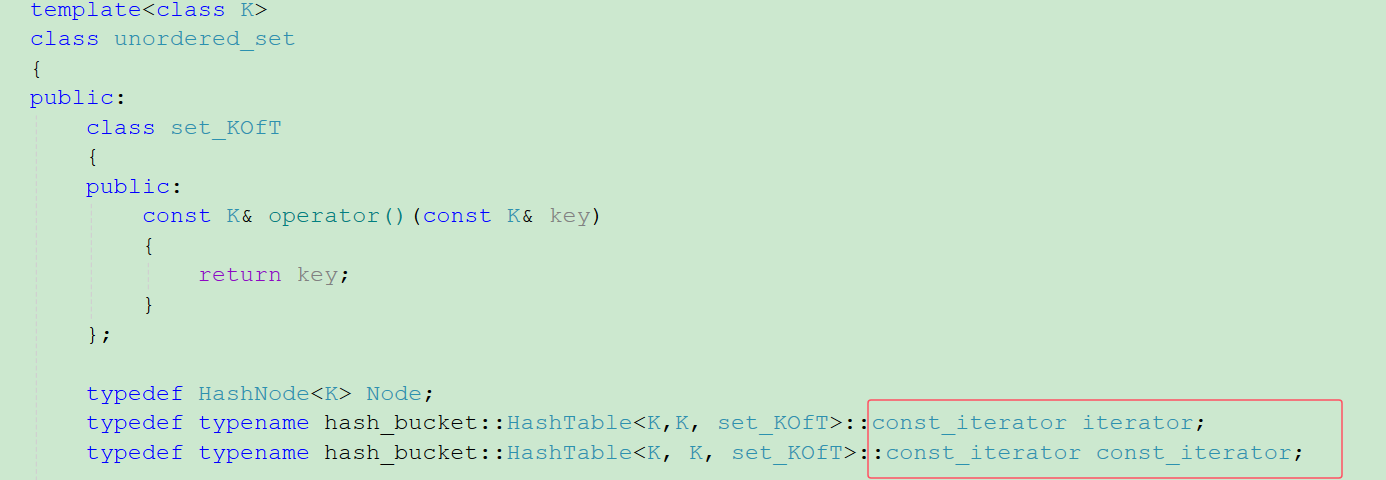
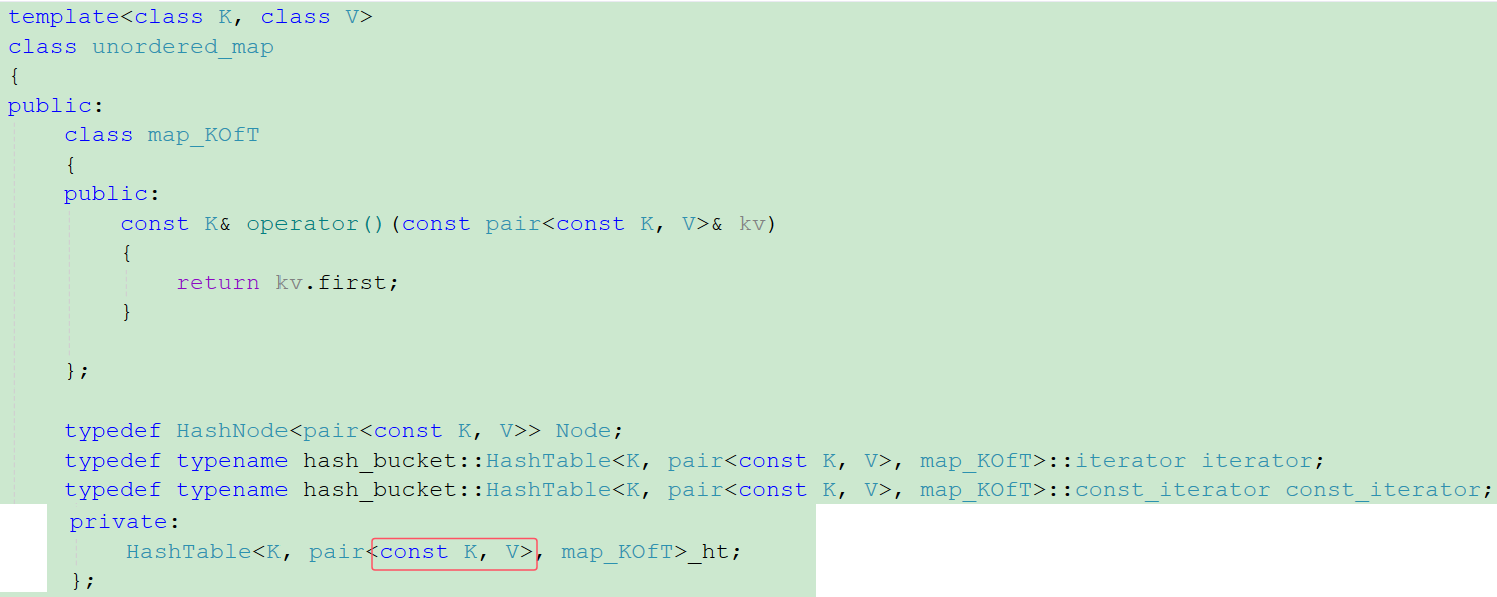
这就和封装map和set复用红黑树的原理基本一样。具体如下图解:

图片中所传的第三个模板参数set_KOfT和map_KOfT其实是一个仿函数,因为向哈希表中插入数据时,插入的数据类型是T,T可以是K,也可以是pair<K,V>,由于哈希表要对关键字key进行取模运算,如果是T是K可以直接运算,如果是pair<K,V>,则不可以,所以我们设计一个仿函数,把关键字key取出来,这样无论是K还是pair<K,V>经过这个仿函数后都是K。


2.unordered_set和undered_map迭代器的设计
迭代器中最重要的一个函数是operator++(),这个函数如何来实现呢?
基本思路应该是这样的,如果当前节点的下一个不为空,++就是下一个节点。如果当前节点的下一个为空,那么++就是找下一个不为空的桶。
那么如何找下一个不为空的桶呢?
这就需要在迭代器中存储一个哈希表的指针,这个指针是由哈希表传过来的,这样我们才能在哈希表中查找下一个不为空的桶。

3.const迭代器的实现
const迭代器其实和普通迭代器的原理都是一样的,只不过const迭代器不允许被修改。

4.关于关键字key不能被修改问题
unordered_set和undered_map的不同解决方法.
5.代码汇总详细注释
#pragma once
using namespace std;
#include<string>
#include<vector>
#include<iostream>template<class K>
class DefaultHashFun
{
public://返回size_t 如果关键字为负数 也能解决size_t operator()(const K& key){return key;}
};//模板的特化
//如果关键字是string类型的则自动调用该模板
template<>
class DefaultHashFun<string>
{
public:size_t operator()(const string& str){// BKDR算法size_t hash = 0;for (auto ch : str){//这里*131 是为了减少hash冲突 提高效率//"bacd" "abbe" "abcd" 类似这样的字符串 如果不*131 那么他们的hash值是一样的。就会出现大量的hash重复hash *= 131;hash += ch;}return hash;}};
//链地址法
namespace hash_bucket
{template<class T>struct HashNode{HashNode(const T& date):_date(date), _next(nullptr){}T _date;HashNode<T>* _next;};// 前置声明//迭代器中需要用到哈希表,所以需要向编译器提前说明后面定义实现了哈希表template<class K, class T, class KOfT, class HashFunc>class HashTable;template<class K,class T,class KOfT, class HashFunc, class Ptr,class Ref>class HTIterator{typedef HashNode<T> Node;typedef HTIterator<K,T,KOfT,HashFunc, Ptr, Ref> self; typedef HTIterator<K, T, KOfT, HashFunc, T*, T&> Iterator;public://用普通迭代器构造const迭代器,Iterator是普通迭代器类,当用普通迭代器构造const迭代器是,这两个就不是同一个类了//所以Iterator it不能访问const_iterator的私有成员,所以成员变量必须publicHTIterator(const Iterator& it):_node(it._node),_pht(it._pht){}//这里的构造函数是根据begin来写的,begin返回迭代器需要的信息,然后来构造迭代器HTIterator(Node* node,const HashTable<K, T, KOfT, HashFunc>* pht):_node(node),_pht(pht){}self operator++(){//当前桶不为空if (_node->_next){_node = _node->_next;}else{HashFunc hf;KOfT kot;int hashi = hf(kot(_node->_date)) % (_pht->_table.size());//从下一个桶开始 找不为空的桶hashi++;for (int i = hashi; i < _pht->_table.size(); i++){Node* cur = _pht->_table[i];if (cur){_node = cur;return *this;}}_node = nullptr; }return *this;}bool operator!=(const self& s){return _node != s._node;}bool operator==(const self& s){return _node == s._node;}Ref operator*(){return _node->_date;}Ptr operator->(){return &(_node->_date);}public:Node* _node;//存哈希表的指针,方便找下一个节点const HashTable<K, T, KOfT, HashFunc>* _pht;};template<class K, class T, class KOfT, class HashFun = DefaultHashFun<K> >class HashTable{// 友元声明//由于迭代器会访问哈希表中私有的成员变量,所以要把迭代器声明为友元template<class K, class T, class KeyOfT, class HashFunc, class Ptr, class Ref>friend class HTIterator;public:typedef HashNode<T> Node;typedef HTIterator<K, T, KOfT, HashFun, T*, T&> iterator;typedef HTIterator<K, T, KOfT, HashFun, const T*, const T&> const_iterator;HashTable(){_table.resize(10, nullptr);}~HashTable(){for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}iterator begin(){Node* cur = nullptr;for (int i = 0; i < _table.size(); i++){cur = _table[i];if (cur){return iterator(cur, this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}const_iterator begin() const{Node* cur = nullptr;for (int i = 0; i < _table.size(); i++){cur = _table[i];if (cur){return iterator(cur, this);}}//注意这里返回的是const HashTable<K,T,KOfT,HashFunc>*this 所以构造函数接受时权限不能缩小,也必须是const的return iterator(nullptr, this);}const_iterator end() const{return iterator(nullptr, this);}iterator find(const K& key){HashFun hf;KOfT kot;int hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kot(cur->_date) == key){return iterator(cur, this);}else{cur = cur->_next;}}return iterator(nullptr, this);}pair<iterator,bool> insert(const T& data){//扩容 如果不进行扩容 当有很多数据插入时//链上会有很多节点 这样查找的效率非常低 所有需要扩容 来提高效率 这里的负载因子可以放大一些KOfT kot;iterator it = find(kot(data));if (it != end()){return make_pair(it, false);}HashFun hf;if (_n == _table.size()){int newSize = _table.size() * 2;vector<Node*>newTable;newTable.resize(newSize, nullptr);// 遍历旧表,顺手牵羊,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hf(kot(cur->_date)) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}int hashi = hf(kot(data)) % _table.size();Node* cur = new Node(data);//头插if (_table[hashi]){Node* prev = _table[hashi];_table[hashi] = cur;cur->_next = prev;}_table[hashi] = cur;++_n;return make_pair(iterator(cur,this), true);}bool erase(const K& key){HashFun hf;KOfT kot;size_t hashi = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur){if (kot(cur->_date) == key){if (prev == nullptr) //防止头删{_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}void Print(){for (size_t i = 0; i < _table.size(); i++){printf("[%d]->", i);Node* cur = _table[i];while (cur){cout << cur->_kv.first << ":" << cur->_kv.second << "->";cur = cur->_next;}printf("NULL\n");}cout << endl;}private:vector<Node*>_table;int _n = 0;};
}
#pragma once
#include"HashTable.h"
using namespace hash_bucket;namespace my
{template<class K>class unordered_set{public:class set_KOfT{public:const K& operator()(const K& key){return key;}};typedef HashNode<K> Node;typedef typename hash_bucket::HashTable<K,K, set_KOfT>::const_iterator iterator;typedef typename hash_bucket::HashTable<K, K, set_KOfT>::const_iterator const_iterator;iterator find(const K& key){return _ht.find(key);}pair<iterator,bool> insert(const K& key){pair<typename hash_bucket::HashTable<K, K, set_KOfT>::iterator, bool> ret = _ht.insert(key);return pair<const_iterator, bool>(ret.first, ret.second);}bool erase(const K& key){return _ht.erase(key);}iterator begin() const{return _ht.begin();}iterator end() const {return _ht.end();}private:HashTable<K, K, set_KOfT>_ht;};}
#pragma once
#include"HashTable.h"
using namespace hash_bucket;namespace my
{template<class K, class V>class unordered_map{public:class map_KOfT{public:const K& operator()(const pair<const K, V>& kv){return kv.first;}};typedef HashNode<pair<const K, V>> Node;typedef typename hash_bucket::HashTable<K, pair<const K, V>, map_KOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, map_KOfT>::const_iterator const_iterator;iterator find(const K& key){return _ht.find(key);}pair<iterator,bool> insert(const pair<K,V>& kv){return _ht.insert(kv);}V& operator[](const K key){return _ht.insert(make_pair(key, V())).first->second;}bool erase(const K& key){return _ht.erase(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}private:HashTable<K, pair<const K, V>, map_KOfT>_ht;};
}