【AI论文】视觉拼图式微调可提升多模态大语言模型性能
摘要:基于强化学习的微调方法近期已成为增强多模态大语言模型(MLLMs)对齐能力与推理能力的有效范式。尽管以视觉为中心的微调对于提升MLLMs对视觉信号的内在理解至关重要,但当前微调范式仍以文本为主导——密集的视觉输入仅被用于提取稀疏线索以支持基于文本的推理。尽管已有少数研究尝试向这一方向探索,但这些方法往往仍依赖文本作为中间媒介,或引入额外的视觉生成模块。本研究提出Visual Jigsaw,一种通用的自监督微调框架,旨在强化MLLMs的视觉理解能力。该框架通过构建通用排序任务实现:将视觉输入分割、打乱后,要求模型以自然语言形式生成正确排列顺序以重构视觉信息。这一设计天然契合基于可验证奖励的强化学习(RLVR),无需引入额外视觉生成组件,且无需任何标注即可自动获取监督信号。我们在图像、视频及三维数据三种视觉模态上验证了Visual Jigsaw的有效性。大量实验表明,该方法能显著提升模型的细粒度感知、时序推理及三维空间理解能力。本研究揭示了自监督视觉中心任务在MLLMs微调中的潜力,旨在为视觉中心前置任务设计提供进一步的研究启示。项目主页:Github。Huggingface链接:Paper page,论文链接:2509.25190
研究背景和目的
研究背景:
随着人工智能技术的快速发展,多模态大语言模型(Multimodal Large Language Models, MLLMs)在视觉和语言任务中取得了显著进展。
这些模型通过整合视觉和语言信息,实现了对复杂场景的理解和推理。然而,现有的MLLMs在视觉理解方面仍存在不足,尤其是在处理精细粒度感知、时间推理和三维空间理解等任务时表现欠佳。传统的后训练方法主要依赖于文本中心的强化学习(Reinforcement Learning from Verifiable Reward, RLVR),这些方法虽然增强了模型的推理能力,但往往忽视了视觉信号本身的内在理解。此外,一些方法尝试通过引入视觉生成组件来改进视觉理解,但这需要修改模型架构并增加额外的训练目标。
在此背景下,如何通过一种轻量级且与现有模型架构兼容的方法来增强MLLMs的视觉理解能力,成为了一个亟待解决的问题。
自我监督学习(Self-supervised Learning, SSL)作为一种无需人工标注数据的学习方法,在视觉表示学习中表现出色。然而,传统的SSL方法主要关注于重构或判别任务,这些任务通常需要像素级的保真度,可能不是增强MLLMs视觉理解能力的最优策略。
研究目的:
本研究旨在提出一种新型的自我监督后训练框架——Visual Jigsaw,通过解决视觉拼图任务来增强MLLMs的视觉理解能力。具体目标包括:
- 增强视觉理解:通过Visual Jigsaw任务,提升MLLMs在精细粒度感知、时间推理和三维空间理解等方面的能力。
- 无缝集成:设计一种无需修改现有MLLMs架构或输出格式的后训练方法,实现与现有模型的无缝集成。
- 广泛适用性:验证Visual Jigsaw框架在图像、视频和三维数据等多种视觉模态上的有效性和通用性。
研究方法
1. Visual Jigsaw任务设计:
Visual Jigsaw任务被设计为一种通用的排序任务,其中视觉输入被分割、打乱,模型需要通过自然语言输出正确的排列顺序。具体包括:
- 图像拼图(Image Jigsaw):将输入图像分割成非重叠的块,打乱后让模型预测正确的空间排列顺序。
- 视频拼图(Video Jigsaw):将视频沿时间轴分割成多个片段,打乱后让模型预测原始的时间顺序。
- 三维拼图(3D Jigsaw):针对三维数据,通过采样具有不同深度值的点并打乱,让模型预测正确的深度顺序。
2. 强化学习后训练:
采用强化学习从可验证奖励(RLVR)框架进行后训练,通过与环境的交互来优化模型的政策网络。在每个时间步,模型生成一个排列顺序,并通过与真实顺序的比较获得奖励。设计奖励函数以鼓励模型生成正确的排列顺序,并引入折扣因子以奖励部分正确的排列。
3. 实验设置:
- 数据集:使用COCO图像数据集、LLaVA-Video视频数据集和ScanNet三维数据集进行实验。
- 模型选择:以Qwen2.5-VL-7B-Instruct作为基础MLLM,采用GRPO算法进行后训练。
- 评估指标:在图像、视频和三维数据的视觉中心基准测试集上评估模型性能,包括精细粒度感知、单目空间理解、组合视觉理解、时间理解和三维空间推理等方面。
研究结果
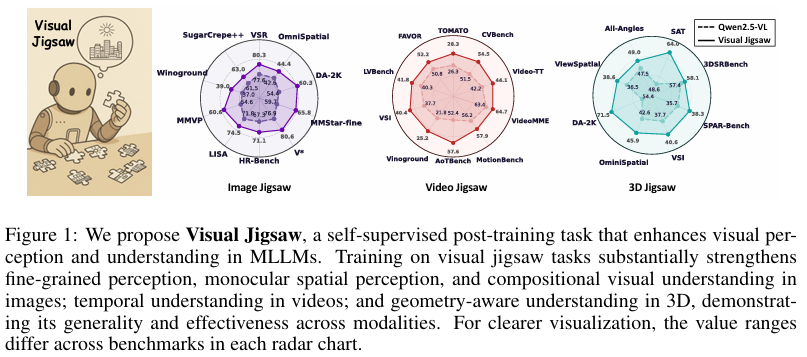
1. 图像拼图任务结果:
在图像拼图任务中,经过后训练的模型在多个视觉中心基准测试集上表现出显著改进。
特别是在MMVP、MMStar精细粒度感知子集和MMBench等基准上,模型性能提升了6.00%至6.06%。这表明,解决图像拼图任务能够增强模型的精细粒度感知能力。
2. 视频拼图任务结果:
在视频拼图任务中,模型在所有评估基准上的表现均有所提升,特别是在需要时间方向理解的视频片段重组任务上表现尤为突出。。。
这表明,通过解决视频拼图任务,模型能够更好地捕捉视频帧之间的时间顺序和空间关系,提高了模型对视频内容的整体理解能力。
3. 视频拼图任务结果:
- 3D拼图任务结果:
- 在3D拼图任务中,模型在视频理解任务上的表现同样有所提升。特别是在视频片段重组任务中,模型需要从打乱的视频片段中恢复出正确的空间布局和结构,这对模型在视频理解任务上的表现尤为重要。。。
4. 三维拼图任务结果:
- 在视频拼图任务中,模型在三维拼图任务上的表现相对较弱。这可能反映出模型在处理复杂视频内容时的局限性,尤其是在需要精细粒度感知和结构理解方面。
研究局限
1. 未来研究方向:
- 1. 改进统一模型的训练策略:
- 改进RL后训练方法(如SFT、GRPO等),以提升模型在视频理解任务上的表现。。。。
3. 探索更广泛的自我监督任务设计:
- 导词任务设计时,应确保任务分解的透明度、公平性和可解释性。。。