sql题目基础50题
查询
用户推荐人
为空: is null
文章浏览
力扣
可能会存在重复行,去重:dictinct 或者 group by分组
distinct 单、多列去重
// 单列去重
SELECT DISTINCT PLAN_NUMBER FROM psur_list;
// 多列去重,两个字段一起的结果去重
SELECT DISTINCT PLAN_NUMBER,PRODUCT_NAME FROM psur_list;
// 单列去重,获得多个字段,但是只对 PLAN_NUMBER 去重
SELECT PLAN_NUMBER,PRODUCT_NAME FROM psur_list GROUP BY PLAN_NUMBER
// distinct 不过滤null项,但 count 过滤null
SELECT COUNT(DISTINCT COUNTRY) FROM psur_list
无效推文 - 常用函数
CONCAT() - 将多个字符串连接成一个字符串。
CONCAT_WS() - 使用指定的分隔符连接多个字符串。
LENGTH() - 返回字符串的长度(以字节为单位)。
CHAR_LENGTH() - 返回字符串的长度(以字符为单位)。
SUBSTRING() - 从字符串中提取子字符串。
LEFT() - 返回字符串左侧的字符。
RIGHT() - 返回字符串右侧的字符。
TRIM() - 移除字符串两端的空格或其他指定字符。
LTRIM() - 移除字符串左侧的空格或其他指定字符。
RTRIM() - 移除字符串右侧的空格或其他指定字符。
REPLACE() - 将字符串中的某些字符替换成其他字符。
INSERT() - 将字符串插入到另一个字符串的指定位置。
UCASE() / UPPER() - 将字符串转换为大写。
LCASE() / LOWER() - 将字符串转换为小写。
REVERSE() - 反转字符串的字符顺序。
FORMAT() - 格式化数字字符串,通常用于货币格式。
LPAD() - 在字符串左侧填充指定数量的字符。
RPAD() - 在字符串右侧填充指定数量的字符。
SPACE() - 生成指定数量的空格。
STRCMP() - 比较两个字符串,返回-1、0或1。
SUBSTRING_INDEX() - 在字符串中查找指定分隔符的索引。
LOCATE() / POSITION() - 在字符串中查找子字符串的位置。
ELT() - 从字符串列表中选择一个字符串。
FIELD() - 在字符串列表中查找字符串的位置。
MAKE_SET() - 根据位值创建一个由字符串组成的集合。
连接
使用唯一标识码替换员工ID
连接、用null填充空字段
连接条件 on
进店却未进行交易
力扣+讲解
customer_id 进门有 visit_id,购物有 transaction_id,需要进门、顾客,消费为空
进门表左连接交易表: 访问id,顾客id,交易id,交易金额
# Write your MySQL query statement below
select v.customer_id,count(*) as count_no_trans
from Visits v
left join Transactions t
on v.visit_id = t.visit_id
where transaction_id is null
group by v.customer_id
上升的温度 - 日期差一天
力扣
日期差函数: datediff( date1, date2) = 1
日期加减:
date1 = date_add ( date2, interval 1 day)
date2 = date_sub ( date1, interval 1 day)
每台机器平均运行时间 - 分组聚合
力扣
同一台机器、同一进程、start 到 end,计算时间,获得平均值,保留三位小数
如果查询中没有 GROUP BY s.machine_id,那么 AVG() 函数会计算所有匹配记录的运行时间平均值,最终只会返回一行结果,无法区分不同机器的运行情况。
核心要点:分组聚合
GROUP BY 的核心在于分组和聚合。它常与聚合函数(COUNT, SUM, AVG, MAX, MIN等)配合使用。
在你这个查询中,AVG() 是聚合函数,s.machine_id 是分组字段。
使用GROUP BY后,数据库会将数据行分成若干组(每个machine_id值对应的记录为一组),然后对每个组分别应用聚合函数。这样你就能得到每个分组(即每台机器)的统计结果。
重要注意事项
使用 GROUP BY 时,一个常见的规则是:SELECT 子句中出现的列,如果不是聚合函数的参数,那么通常就应该出现在 GROUP BY 子句中。你的查询符合这一规范:
s.machine_id 是分组列。
AVG(e.timestamp - s.timestamp) 是聚合函数列。
学生们参加各科测试的次数
力扣
没参加的科目也要显示:交叉连接学生和科目,保证统计到每个学生每个科目
成绩:交叉连接表 左连接 成绩表
统计、分组:按照学生、科目分组,统计每个学生考试每个科目的数量。如果只按照学生分组,统计的是学生总共的考试次数
确认率 - 有条件的avg 或者 count
力扣
AVG(a=‘z’) 等同 SUM(IF(a=‘z’,1,0))/COUNT(a)
或者用 count
count(列名)时,只统计这个列名不为null时的数量。
count(case when then else end) 中是可以写逻辑的。
如果省略else,那就默认为null,即不会被统计。
CASE WHEN … THEN … END:条件表达式,用于根据条件返回不同的值。
当 h_employee.sexType = ‘2’ 为真时,返回 1;否则返回 NULL。
COUNT():
COUNT() 函数用于统计非 NULL 值的数量。
由于 CASE WHEN 在条件不满足时返回 NULL,因此 COUNT() 只会统计满足条件的记录数。
每月交易1
力扣
# Write your MySQL query statement below
SELECT DATE_FORMAT(trans_date, '%Y-%m') AS month, country, SUM(CASE WHEN country IS NOT NULL THEN 1 ELSE 1 END) AS trans_count,SUM(CASE WHEN state = "approved" THEN 1 ELSE 0 END) AS approved_count,SUM(amount) AS trans_total_amount,SUM(CASE WHEN state = "approved" THEN amount ELSE 0 END) AS approved_total_amount
FROM Transactions
GROUP BY month, country;
① DATE_FORMAT(DATE,FORMAT)
根据FORMAT字符串形式格式化DATE所代表的日期,其中“%y” 代表年,“%m”代表月,“%d”代表天,
举例:DATE_FORMAT(“2025-03-12”,“%d-%m-%y”)-----输出“12-03-2025”
② CASE 逻辑表达式
case when expr1 then expr2 [when expr3 then expr4…else expr] end;
以case开头,以end结尾,中间可以进行多个条件的判断;若expr1的值为true,则返回expr2的值;若expr1的值为false,判断expr3的值,若expr3的值为true,则返回expr4的值,以此类推,若所有when子句后面的条件都不满足,则返回expr的值;
举例:CASE WHEN state = “approved” THEN 1 ELSE 0 END ,当state = "approved"时,返回 1,当state ≠ "approved"时,返回 0 。
③ SUM 聚合函数
对数值型字符串进行求和,本质为将原始数据中相同纬度值对应的多个度量值按照运算规则计算为一个值的过程。
举例:SUM(amount) 将整列字段名为amount 的数值型字符进行求和,即SUM(amount)=amout.value.1+amout.value.2+…+amout.value.n
④ GROUP BY
将数据分组并对每组执行计算
⑤ 语法执行顺序
1.FROM → 2. WHERE → 3. GROUP BY → 4. HAVING → 5. SELECT → 6. ORDER BY
即时食物配送2
- avg(first_order = first_delivery)
- 子查询要有别名
高级查询和连接
最后一个能进入巴士的人 - SUM 窗口函数
力扣
为每一行计算从第一行到当前行的累计和并保留所有原始行
with a as(select person_name, weight, turn,sum(weight) over(order by turn) sum_weightfrom queue
)select person_name
from a
where sum_weight <= 1000
order by turn desc
limit 1

子查询
连接表的结果可以用where 过滤,having需要和group by一起使用
电影评分
力扣
union all 将结果去重
limit 1 限制返回的条数
(select name as resultsfrom users uleft join MovieRating mr on u.user_id = mr.user_idgroup by u.user_idorder by count(*) desc, name asclimit 1
)union all
(select m.title as resultsfrom Movies mleft join MovieRating mron m.movie_id = mr.movie_idwhere mr.created_at between '2020-02-01' and '2020-02-29'group by m.movie_idorder by avg(mr.rating) desc, m.title asclimit 1
)
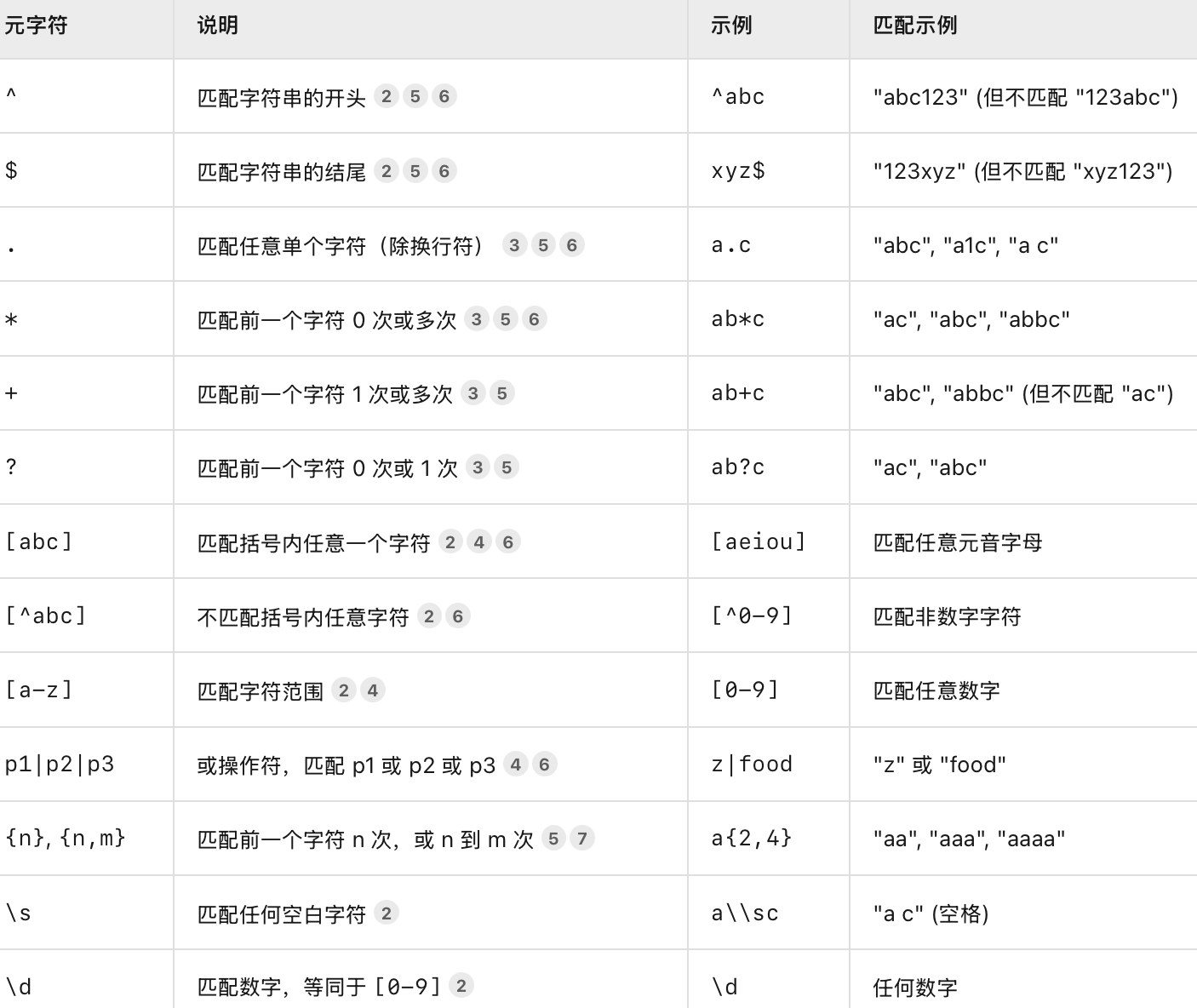
高级字符串函数 / 正则表达式 / 子句
患某种疾病的患者、有效邮箱-正则表达式
力扣
用COLLATE utf8_bin 以比较和排序字符串,它主要用于严格区分大小写和特殊字符顺序,如密码、邮箱验证等场景。
REGEXP 匹配正则,不符合就用 NOT REGEXP
SELECT column1 FROM table1 WHERE column1 REGEXP '正则';
转义字符用 两个斜杠 \
按日期分组销售-结果拼接字符串 GROUP_CONCAT
GROUP_CONCAT([DISTINCT] 要连接的字段 [ORDER BY 排序字段 ASC/DESC] [SEPARATOR '分隔符'])