计算机网络第四章(5)——网络层《路由协议+路由协议》
【本章重点】

一、路由算法
1、思维导图
2、基本概念
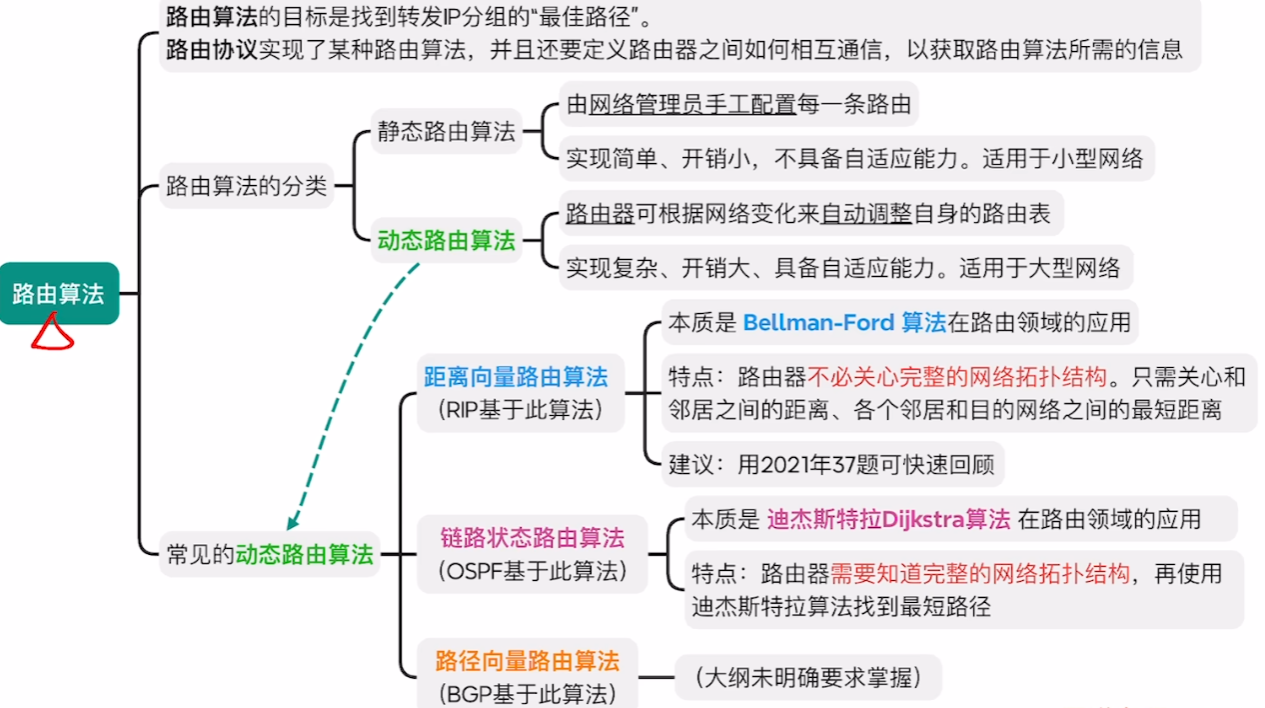
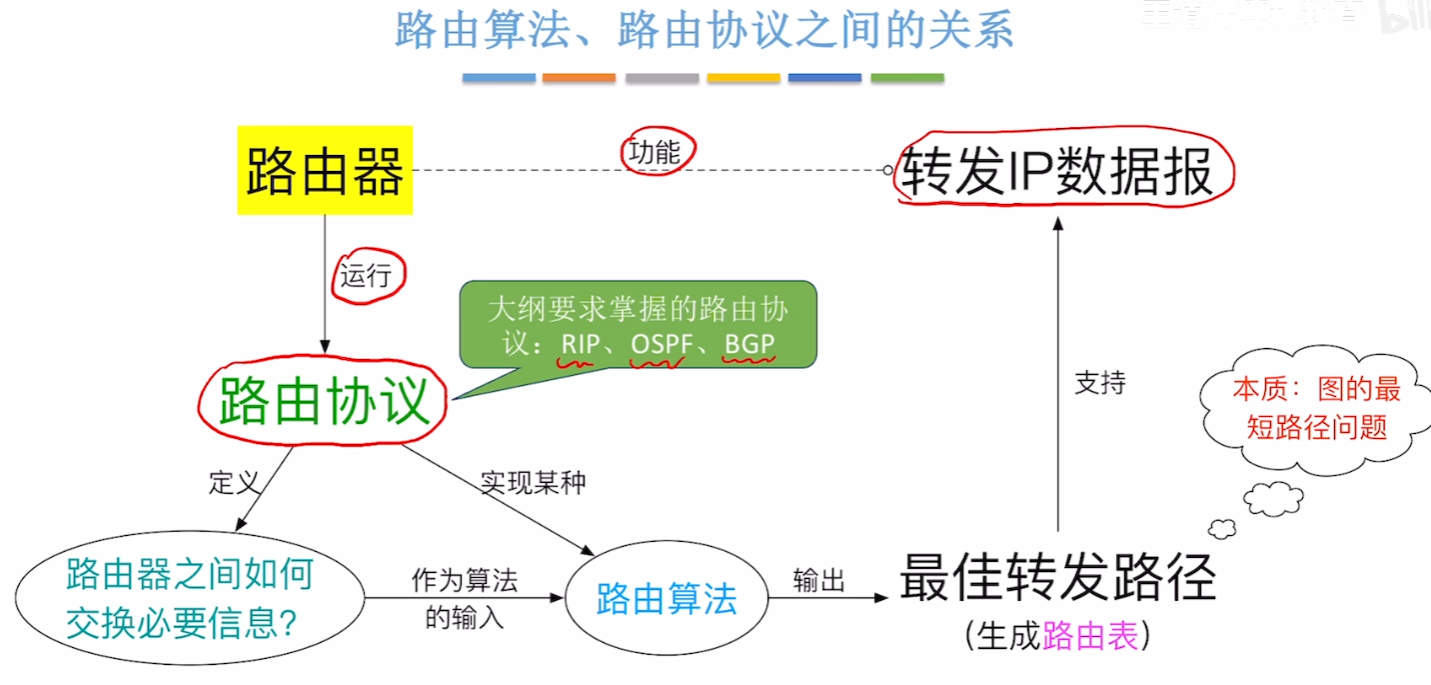
路由算法和路由协议之间的一些关系,简单来说就是路由器在转发IP数据报时,要根据指定的【路由协议】来实现该协议要求的【路由算法】,通过这些算法来得到在整个拓扑网络上转发给发送方的最高效、最短的路径(也就是数据结构里【图】的算法内容)
3、两种路由配置方法

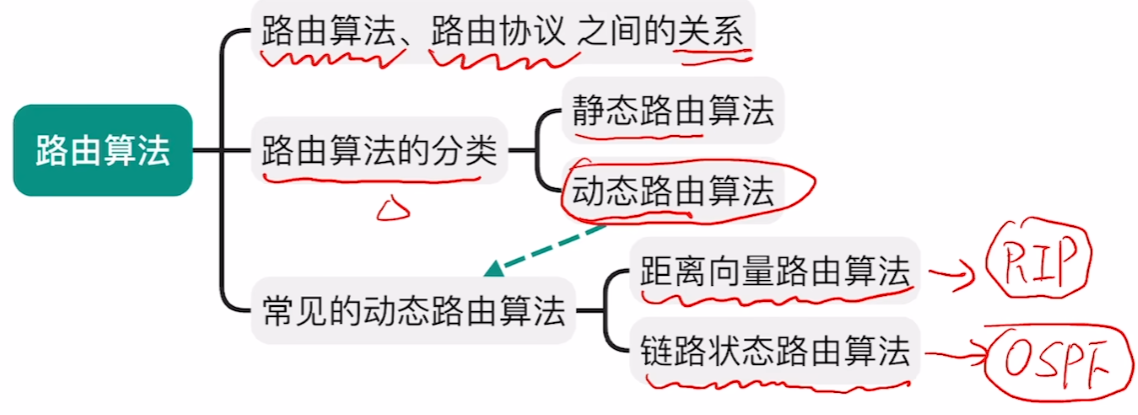
4、三种路由算法
先初步了解一下,具体细节到下面【路由协议】来学习
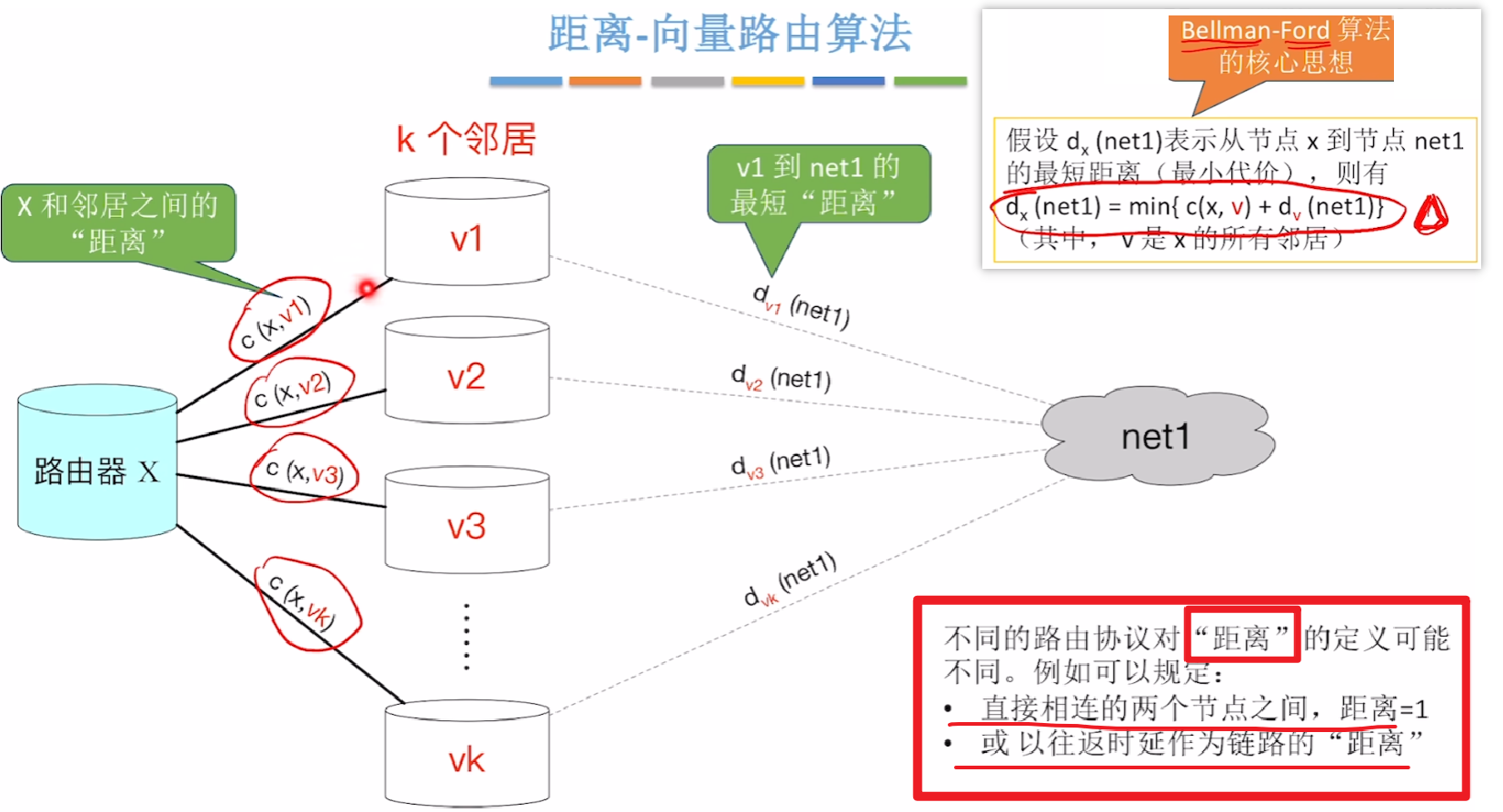
【距离-向量路由算法】
【RIP路由协议】使用的算法
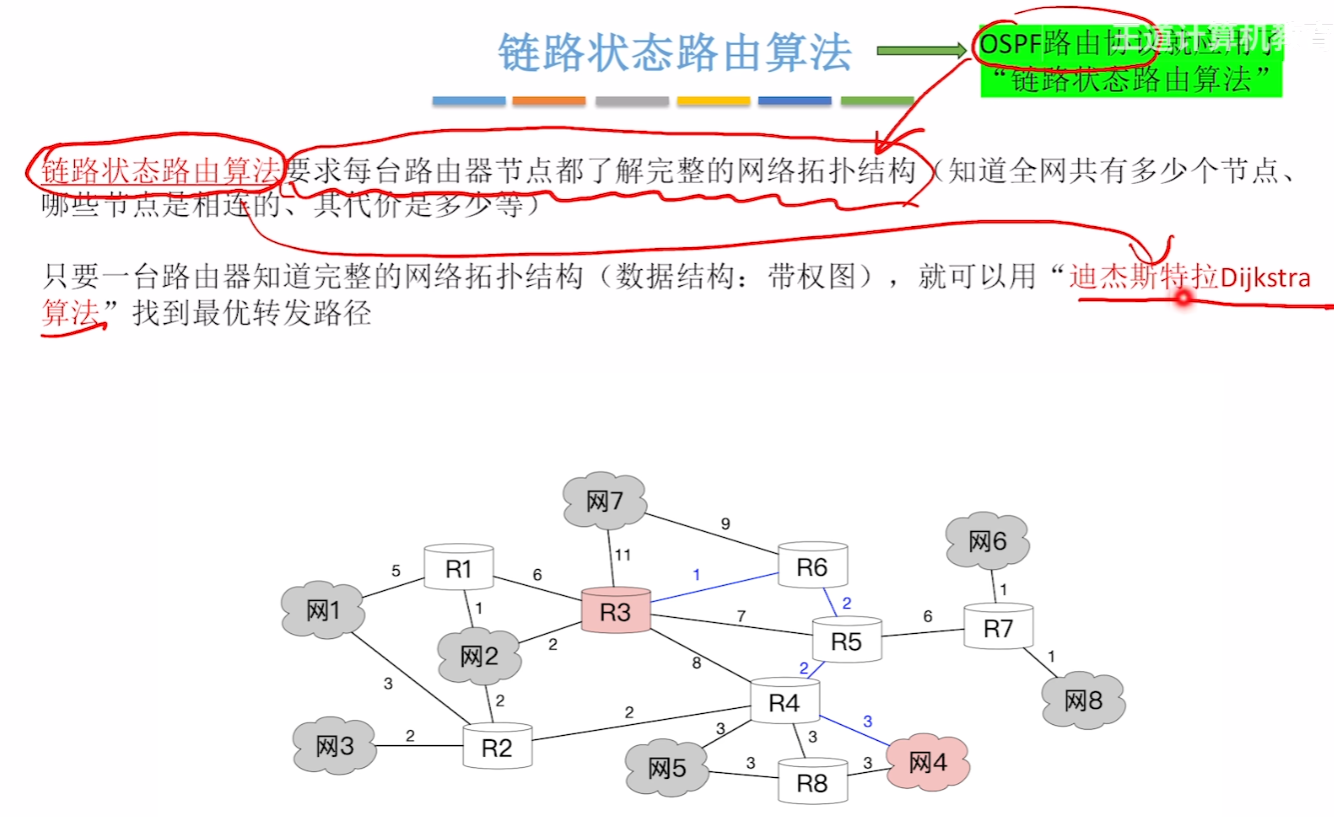
【链路状态路由算法】
【OSPF协议】使用的算法
【路径向量路由算法】
不考,所以咱们不学,我放个图只是为了凑内容。。。

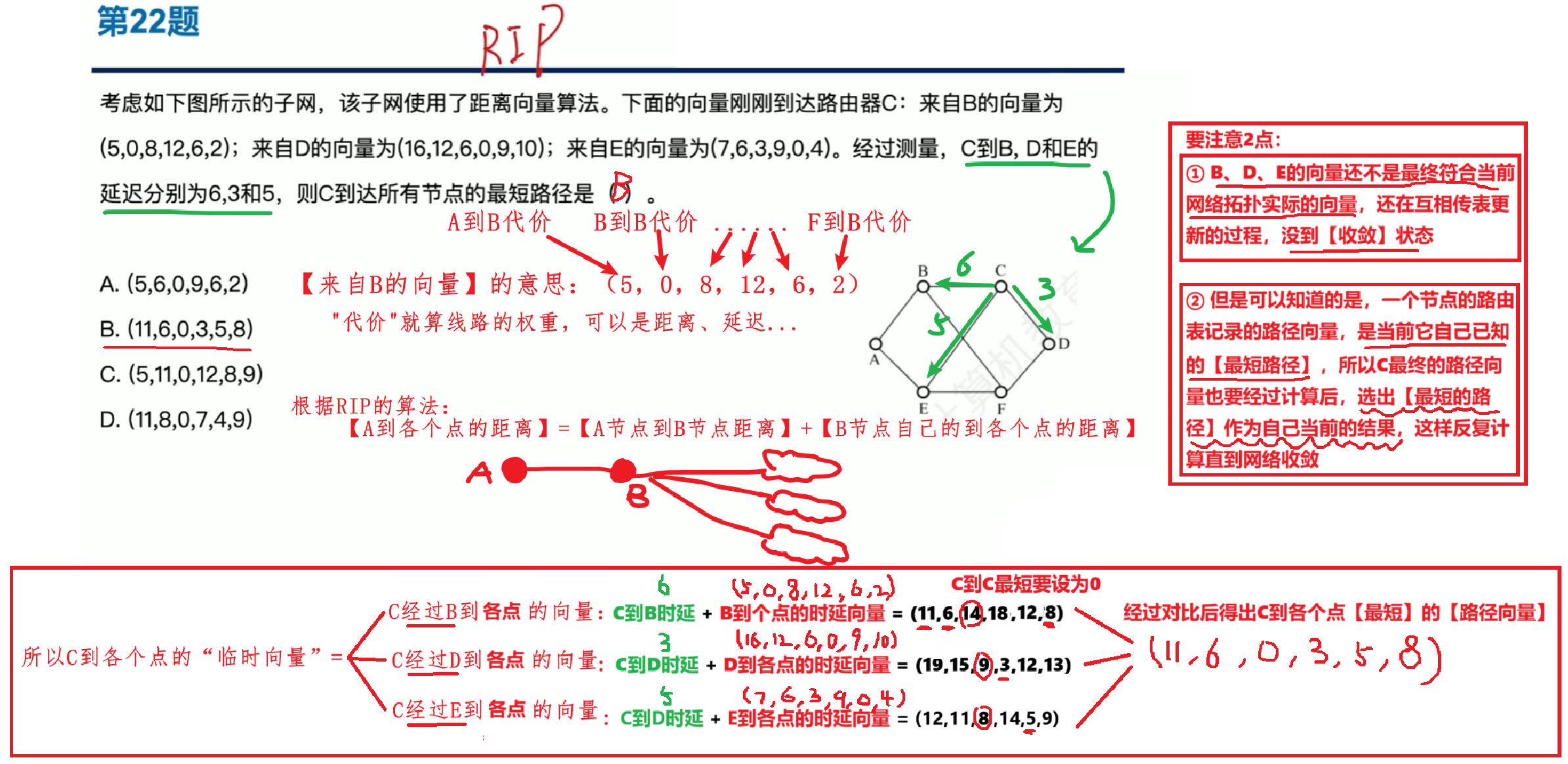
5、【例题】
【重点难点前几题!!!】




二、分层次路由协议
1、思维导图

2、分层次的路由协议分类
原因:
- 【RIP】和【OSPF】两个协议所使用的算法局限了它们无法应用于庞大复杂的外界互联网
- 【RIP路由协议】:基于距离向量路由算法。路由器要把自身的“距离向量”告诉邻居们。网络数量越多,距离向量越大
- 【OSPF路由协议】:基于链路状态路由算法,要求每一台路由器都要建立整个网络的拓扑图。全世界的路由器数量、网络数量数以亿计,不可能让每台路由器都知晓全世界的网络情况
- 因此人们采用【内部网关协议】+【外部网关协议】2层结构的路由协议,应用于整个互联网
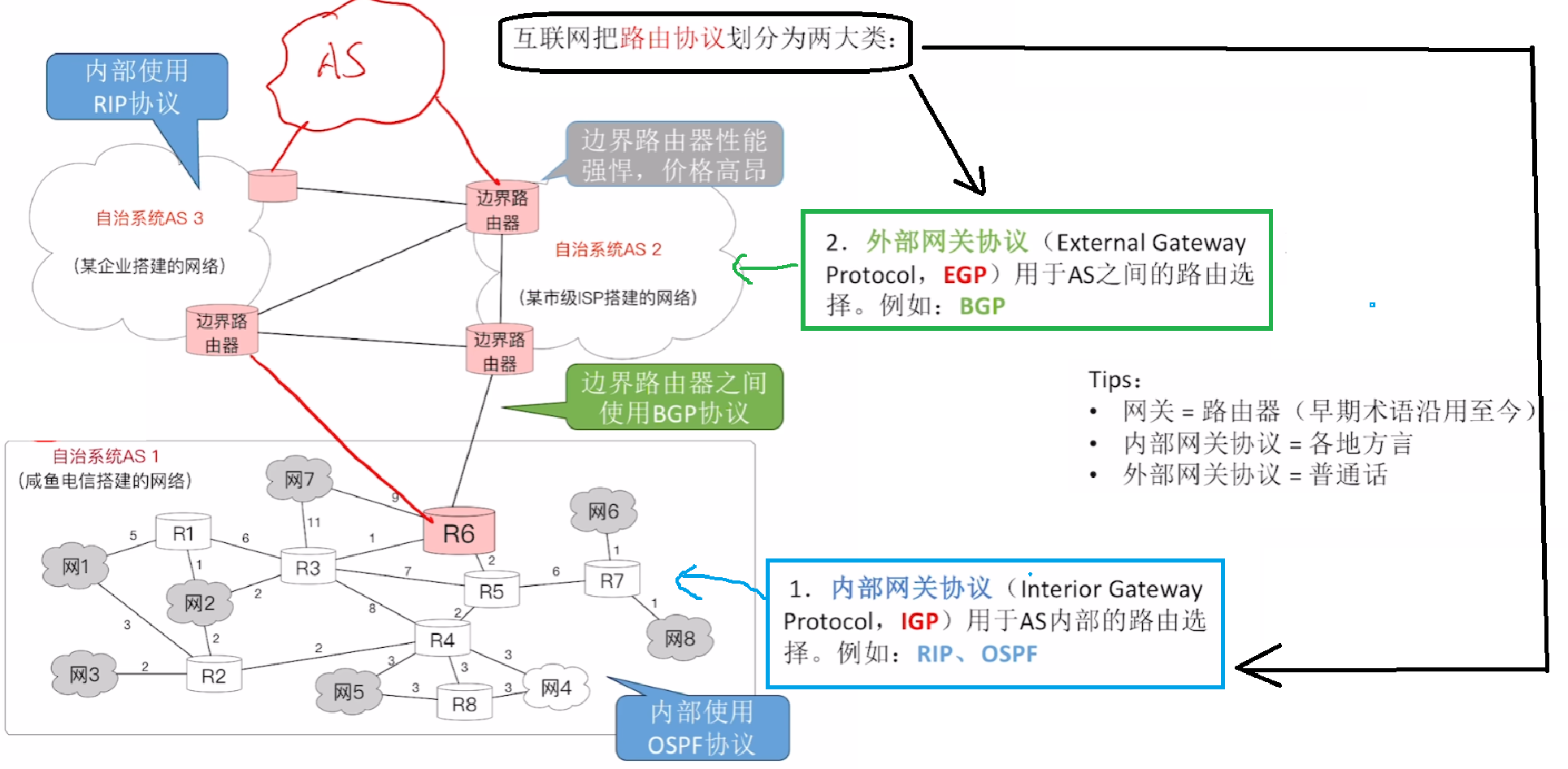
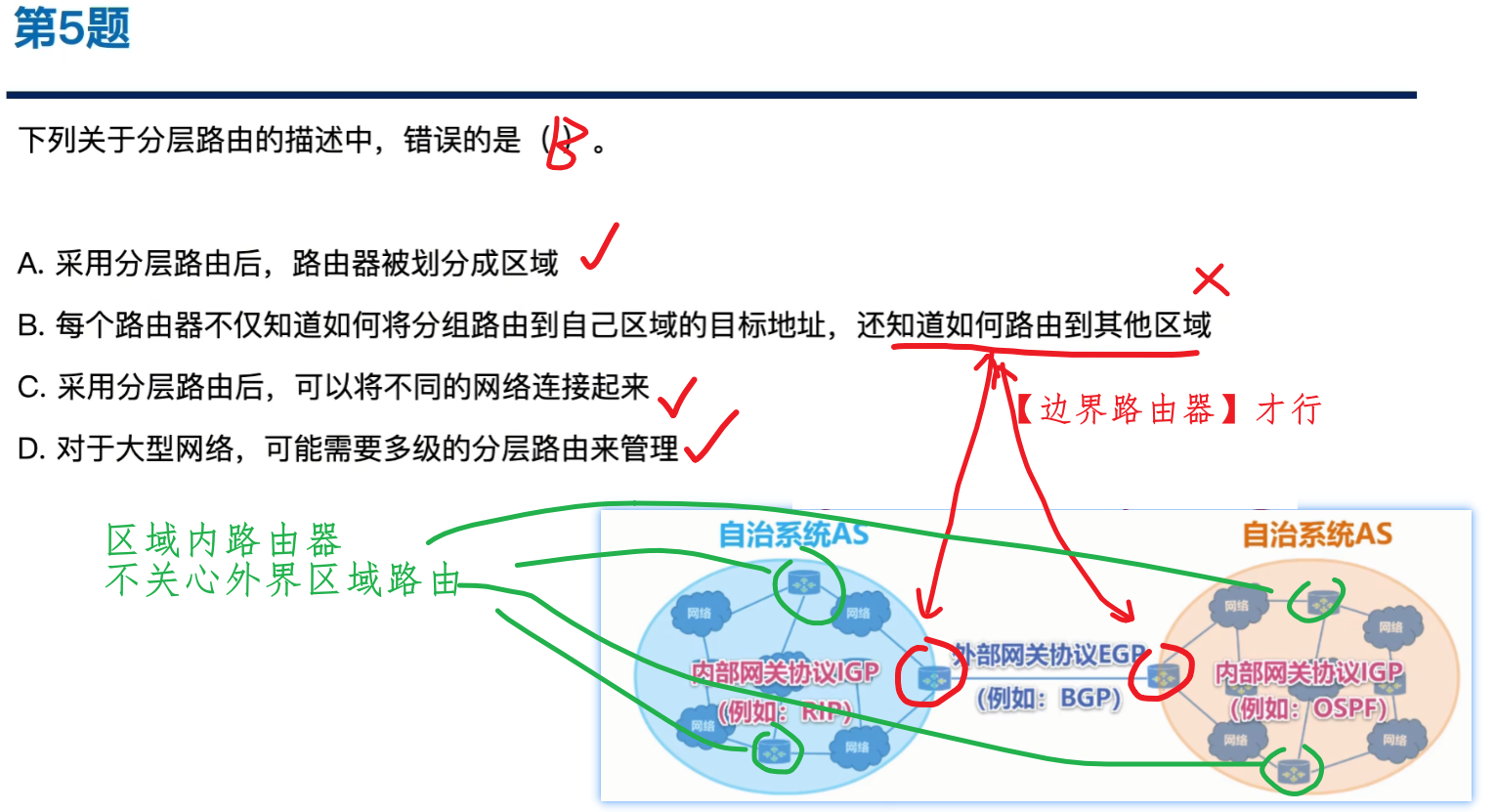
【内、外部网关协议】和【自治系统AS】重点
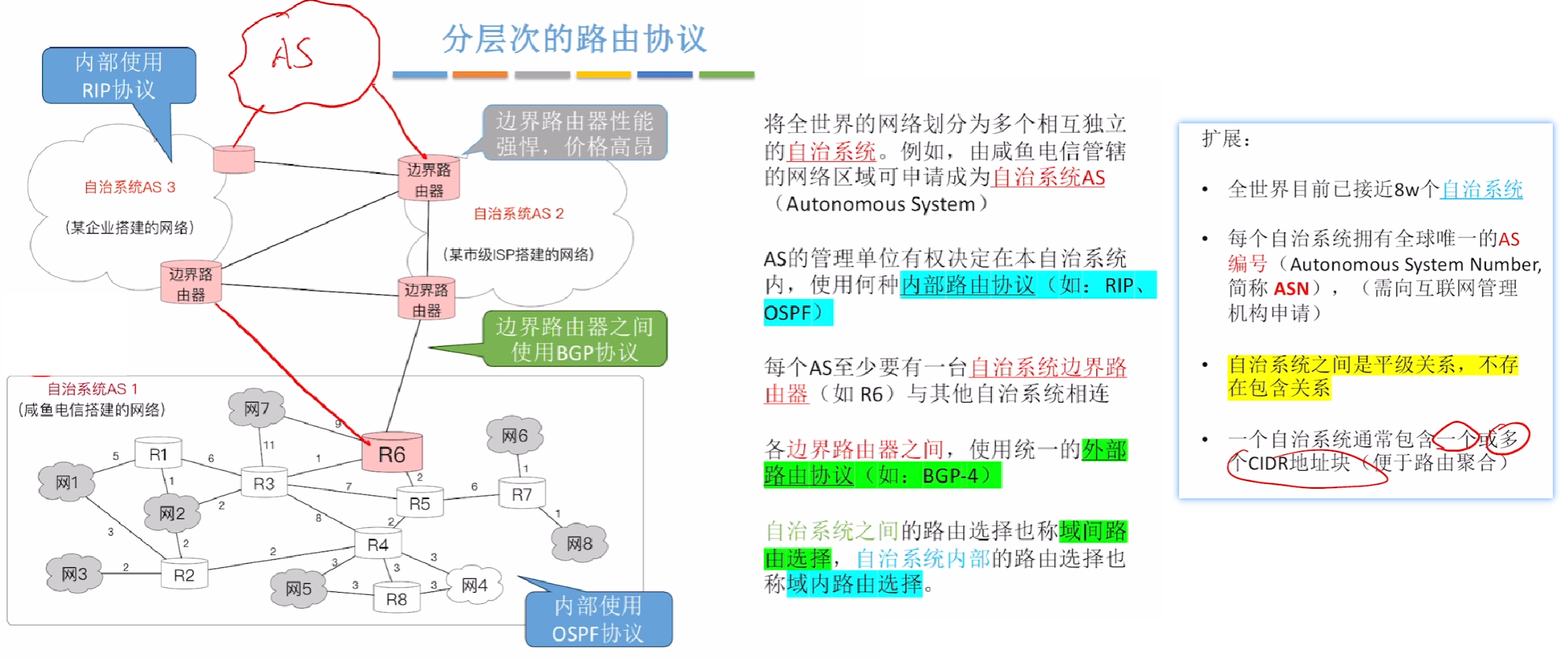
【自治系统AS】:
- 整个世界互联网把各个独立的网络划分为一个个【自治系统AS(Autonomy System)】
- 各自有自己的标识【ASN编号】
- 各个【自治系统AS】是平级关系!!
- 各个【自治系统AS】之间互相靠【边界路由器(边界网关)】连接
- 而【边界路由器】与外界网络互联,使用的是【外部路由协议BGP】
;
;
【分层次路由协议】
那么知道【自治系统AS】概念之后
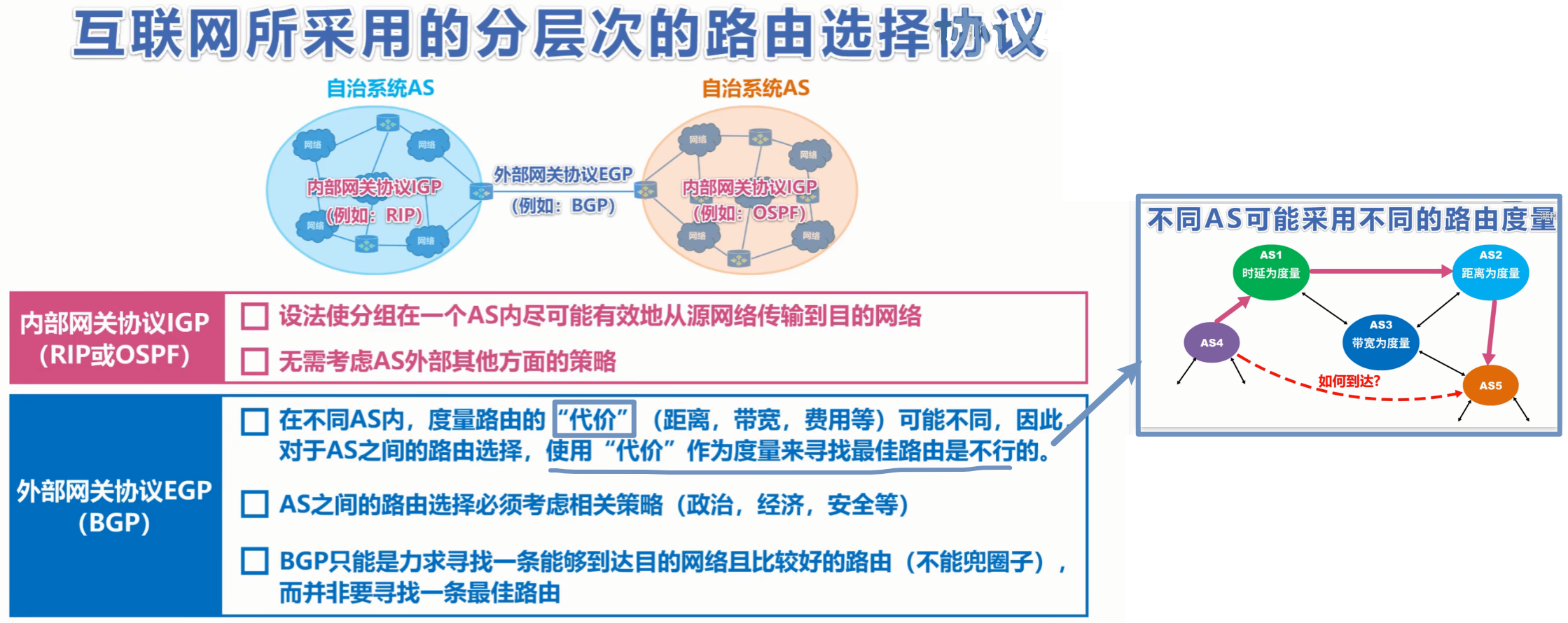
- 【内部网关协议(IGP)】:就是一个【自治系统AS 内部】路由选择的协议
- 也称【域内协议】
- 协议有:【RIP】、【OSPF】
- 依靠内部自治系统内的协议算法来选择【最佳路径】,无需管AS外界情况
- 【外部网关协议(EGP)】:就是各个【自治系统AS 外部】路由选择的协议
- 也称【域间协议】
- 协议有:【BGP】
- 依靠BGP协议,力求一条【较好路径(无需最佳)】
2、【例题】


三、路由信息协议RIP(Routing Information Protocol)
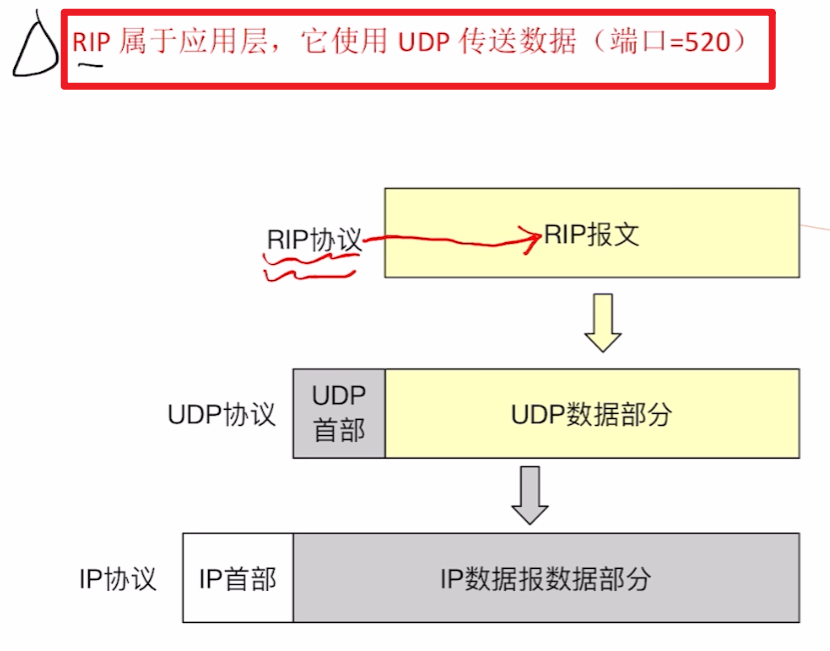
1、【RIP】属于【应用层】
使用传输层的【UDP】协议传输
- 他之所以在网络层章节学习,是因为他是直接应用于网络层的
- 我这么打个比方:中央发下一个红头文件,层层传达到基层,要求基层政府落实执行,
- 那么这个红头文件是属于中央政府的命令
- 具体实现执行是基层干的事,但不能说它属于基层
2、重点理解RIP各个数据、术语的概念
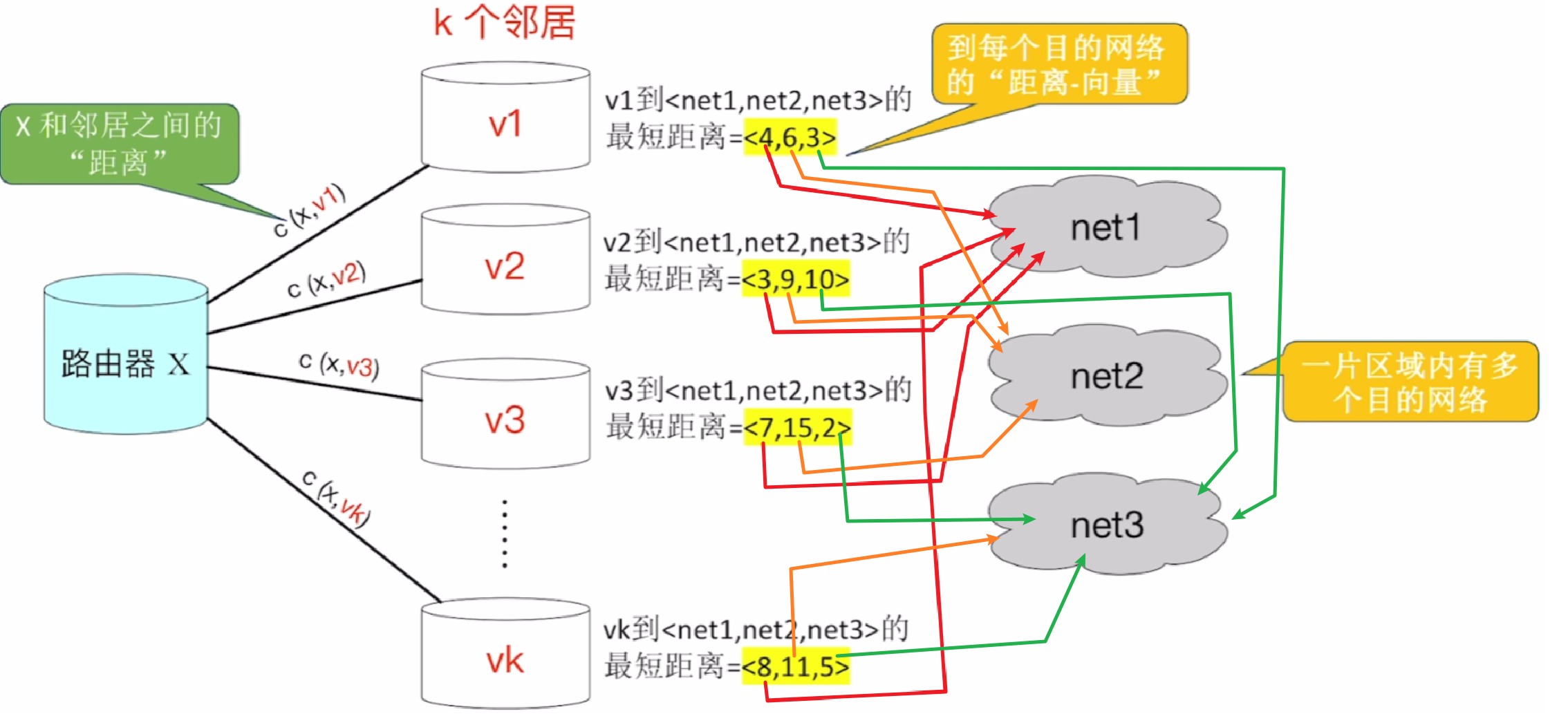
1)【RIP】使用【距离-向量算法】
- 一个路由器需要记录【自己到AS内 的 所有小网络的距离】
- 其中【向量】是指把【此路由器】到【其他AS内网络】的距离统计为一个集合,AS内有N个网络,向量就是N维
- 而【距离】并非只是指 “此路由器 ~ 到相邻路由器距离” 或 “相邻路由器 ~ 直连网络距离”!!!
- 而是【一个路由器 ~ 到一个网络的整条路距离】
- (中间包括和【到邻居路由器距离 + 邻居路由器到直连网络距离】)
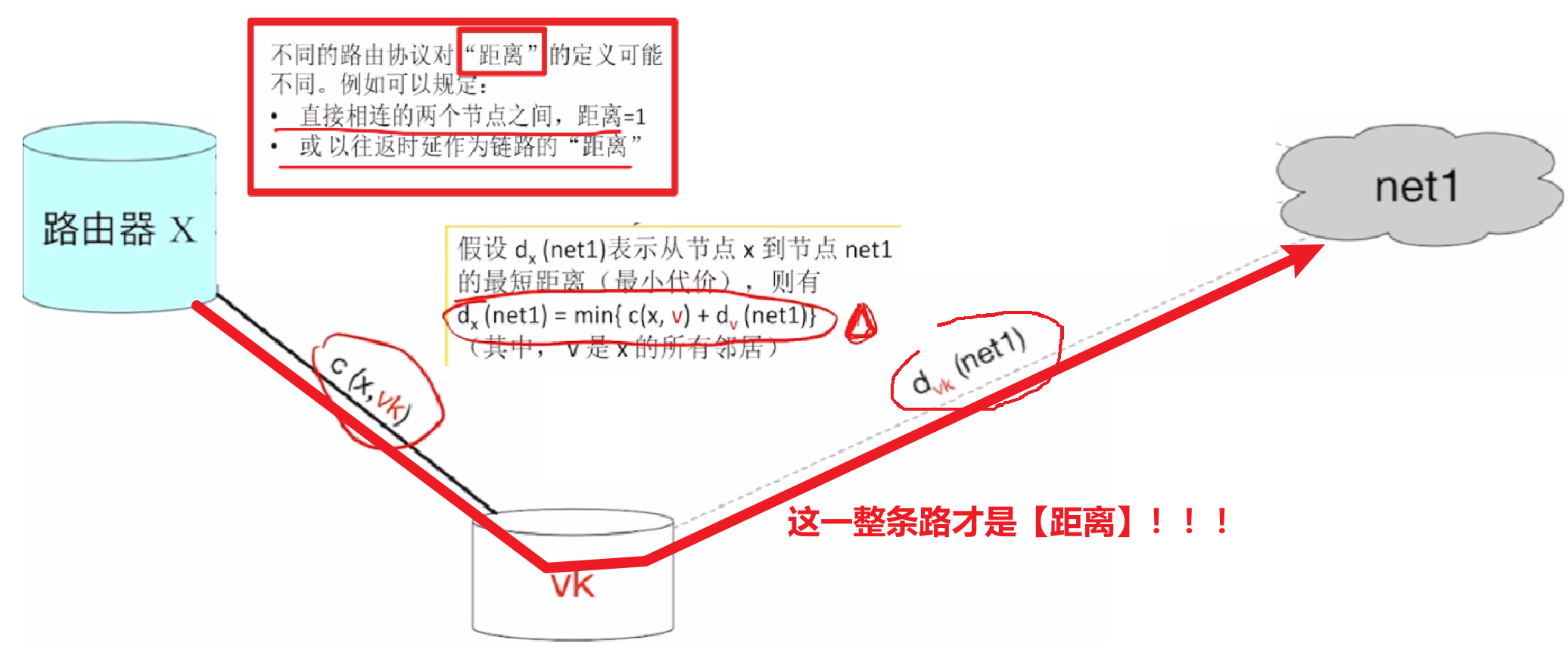
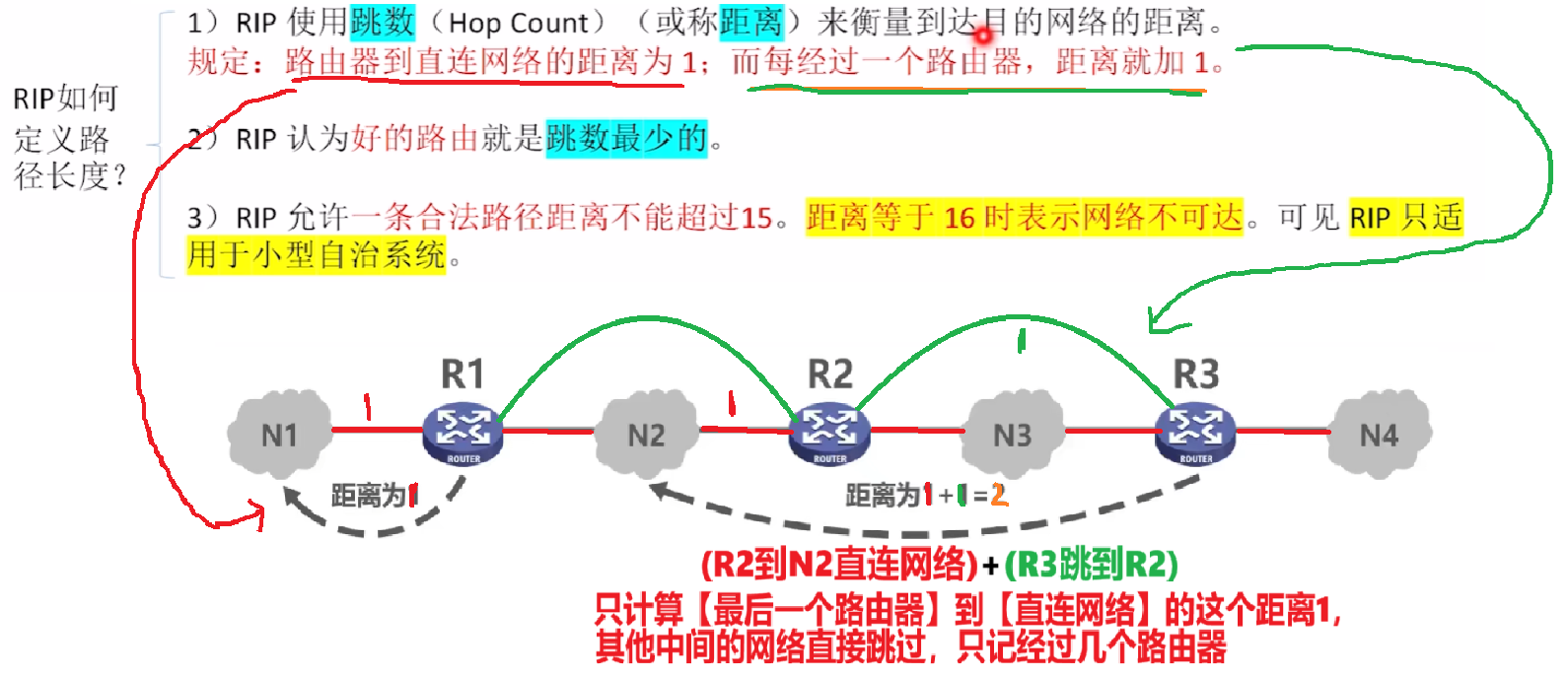
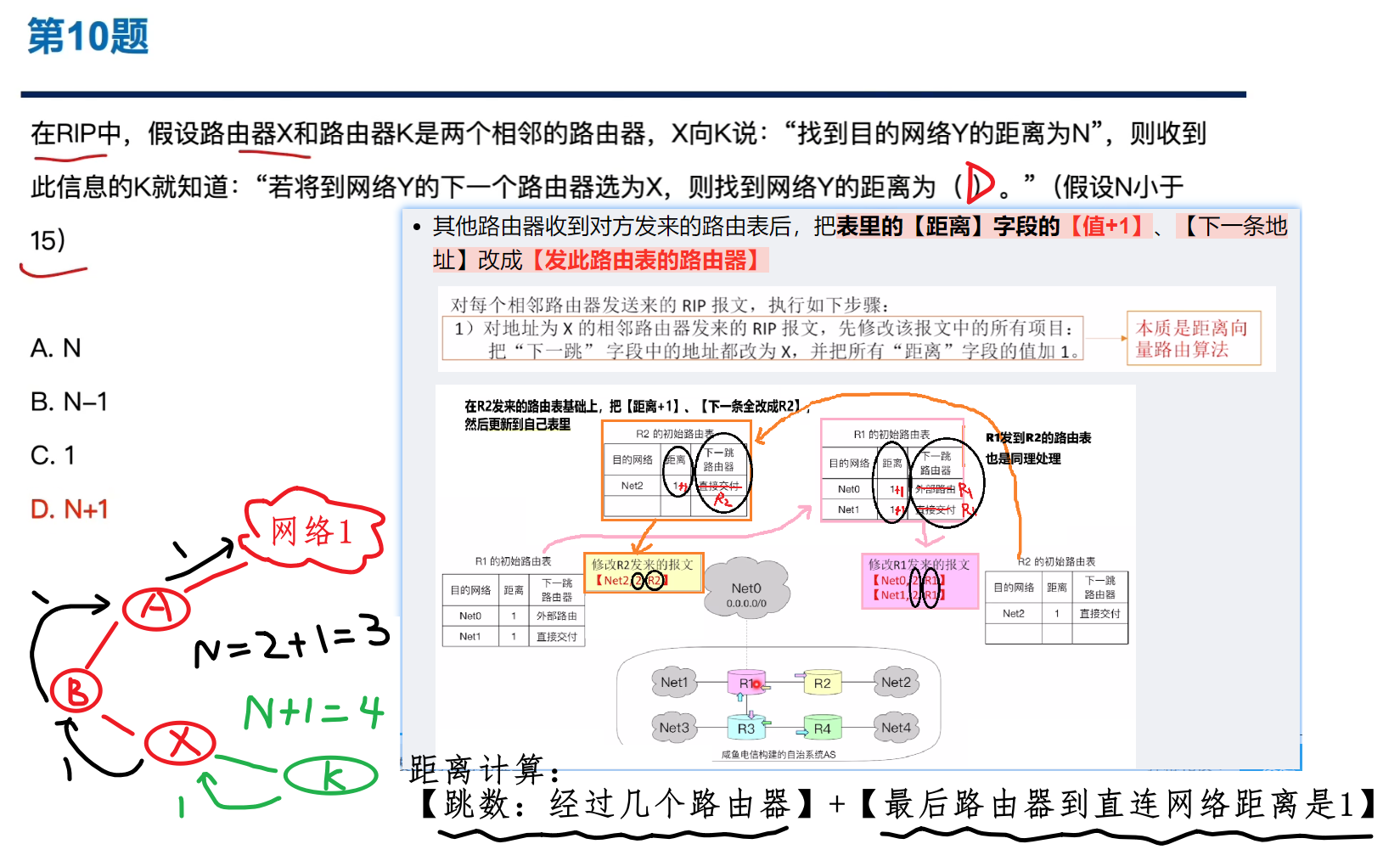
2)RIP具体如何定义【距离】
- 只用【跳数】来衡量【到达目的网络的距离】
- 这条路是经过的【最后一个路由器】到【目的直连网络】的距离是1
- 这条路【没经过一个路由器】距离都加1
- 因此可知,这条路上的【非目的网络】是直接跳过不算作距离的
- RIP的路径距离不能超过15,大于等于16就不合法!!!
3)RIP如何定义【数据格式】?
- 每个路由器有两份数据需要记录:【路由表】、【距离向量】
- 【路由表】就是该路由器到各个网络的路径信息,三个字段 <目的网络,距离,下一条路由器>
- 【距离向量】前面也解释过了(这里提一下,【路由表】就包含了【距离向量】
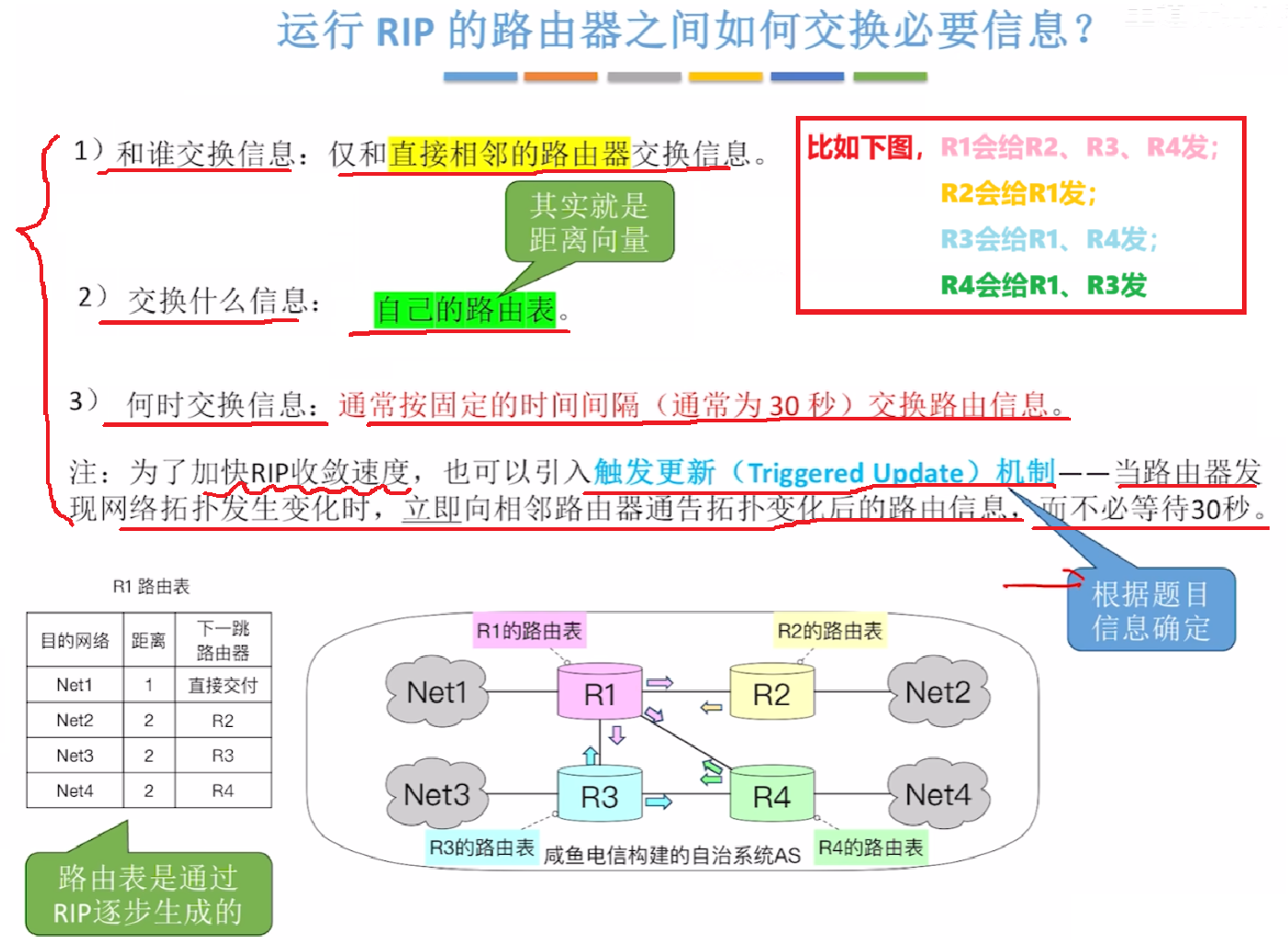
4)【收敛】:RIP协议下,路由器会怎么交换信息?
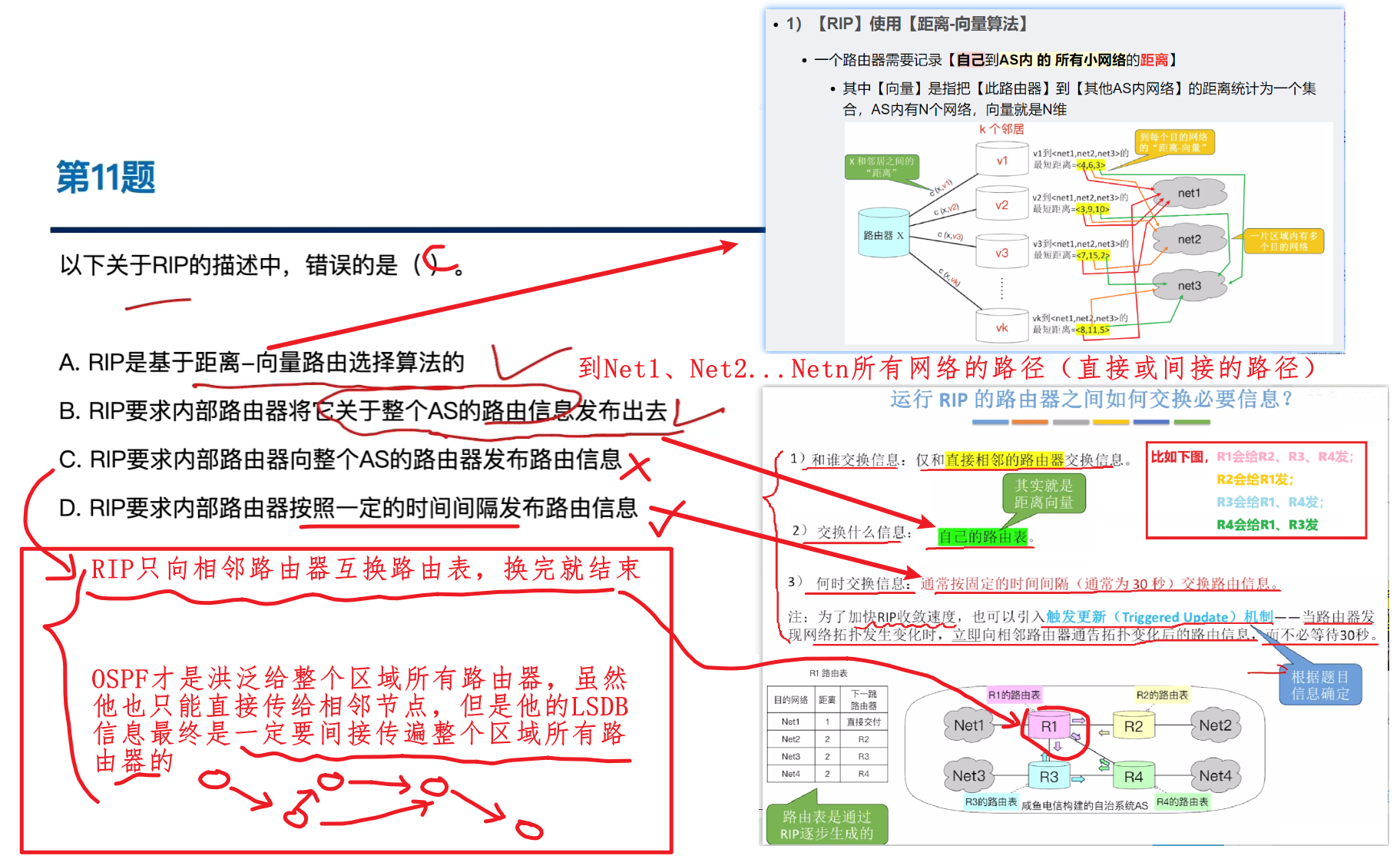
- 根据RIP协议的原理,每个路由器一开始只知道【自己到直连网络的距离是1】
那么要知道整个AS系统内到各个网络的距离,就需要知道自己到别的路由器的距离,那就要各个路由器向与自己互联的路由器【交换路由表】
而且还需要不断更新交换路由表,因为网络拓扑结构随时都会改变(比如局域网1里多接了两个路交换机、局域网2总令牌环网改成了星形网......)
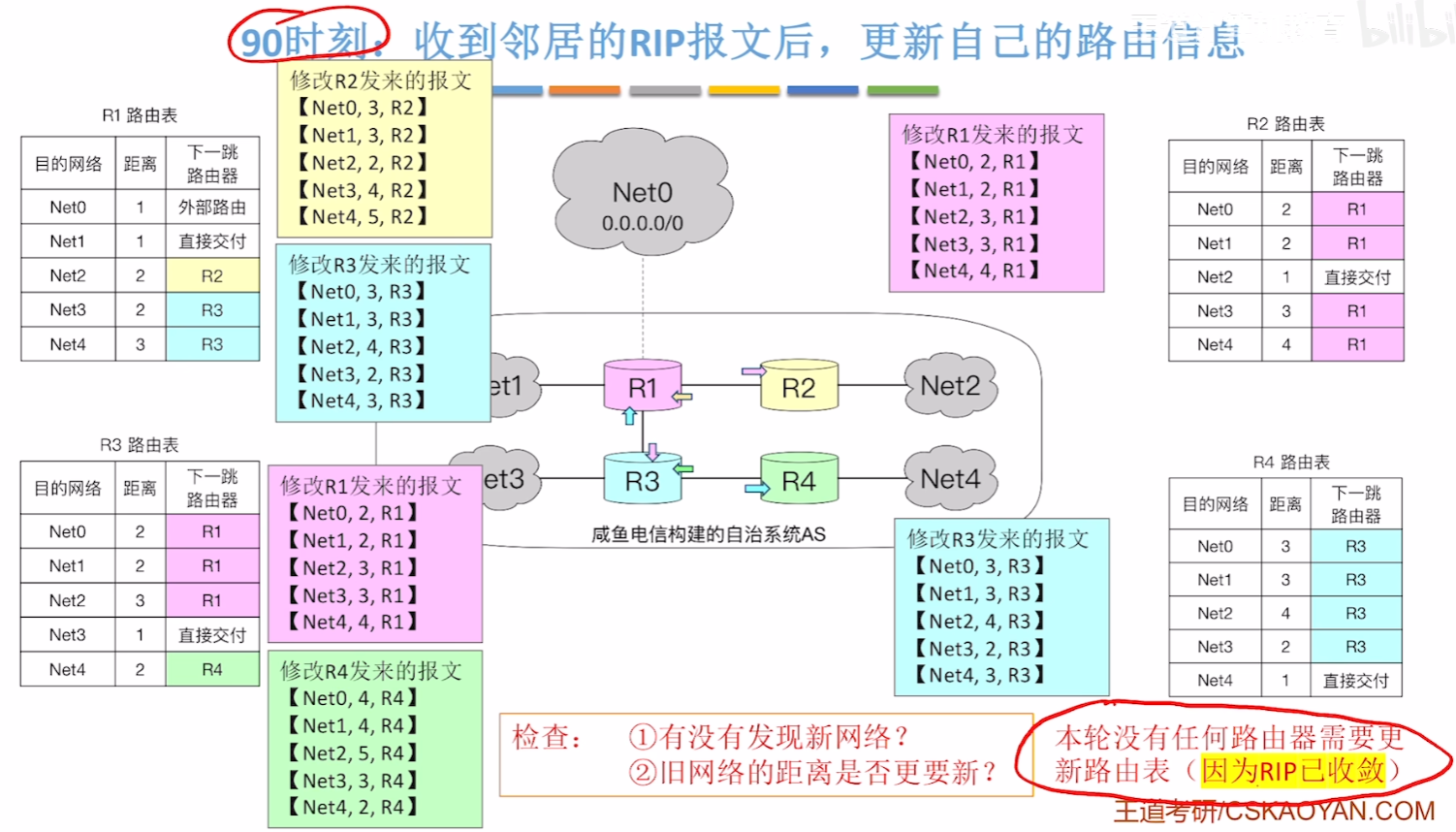
那么在不断更新交换后,所有路由器都能知道【自己到AS系统内所有网络】、【下一跳的地址】的,就叫【收敛】:
1、通常是固定30秒,每个路由器向与己互联路由器交换一次路由表
2、或者引入【触发更新机制】,每次一个路由器拓扑更新,都触发一次【收敛】
【收敛】特指经过不断更新,所有路由器都稳定下来了,才叫【收敛】,收敛情况下的网络再怎么交换路由表,也不会再有任何改变了,直到下一次网络拓扑改变

3、RIP工作原理
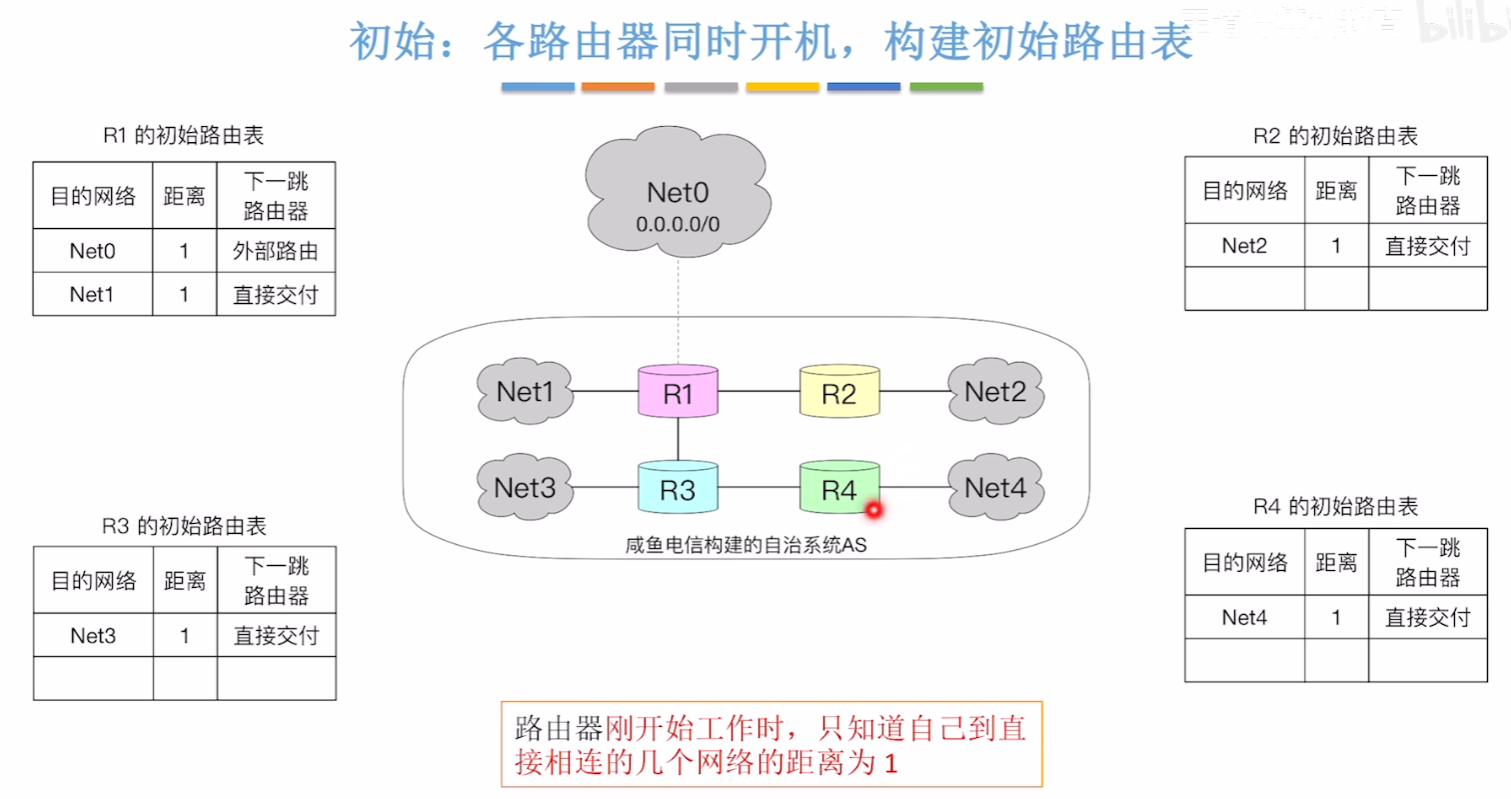
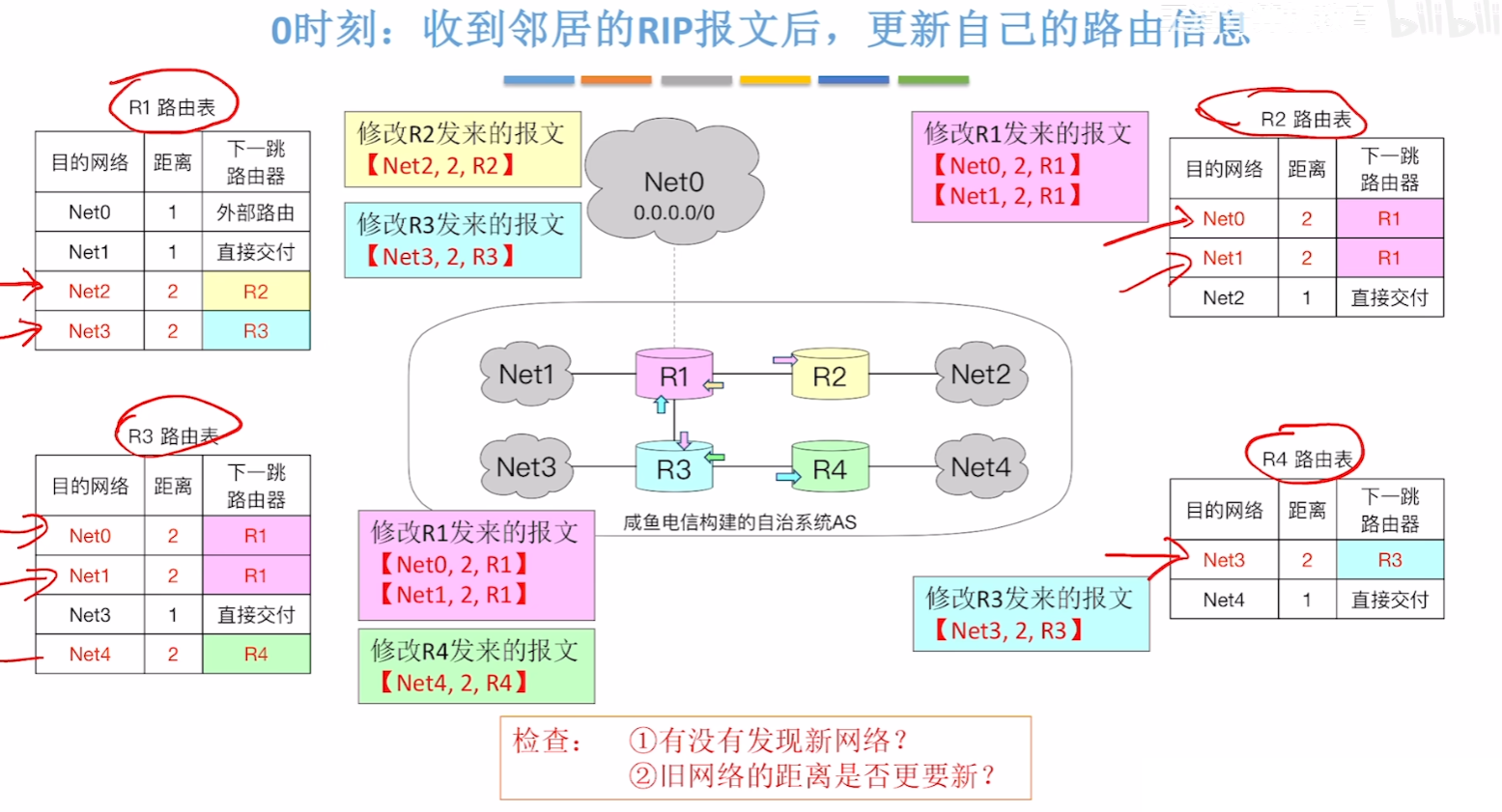
【路由器初始化】
- 每个路由器把自己直连的网络的信息填入路由表,并且距离都是1
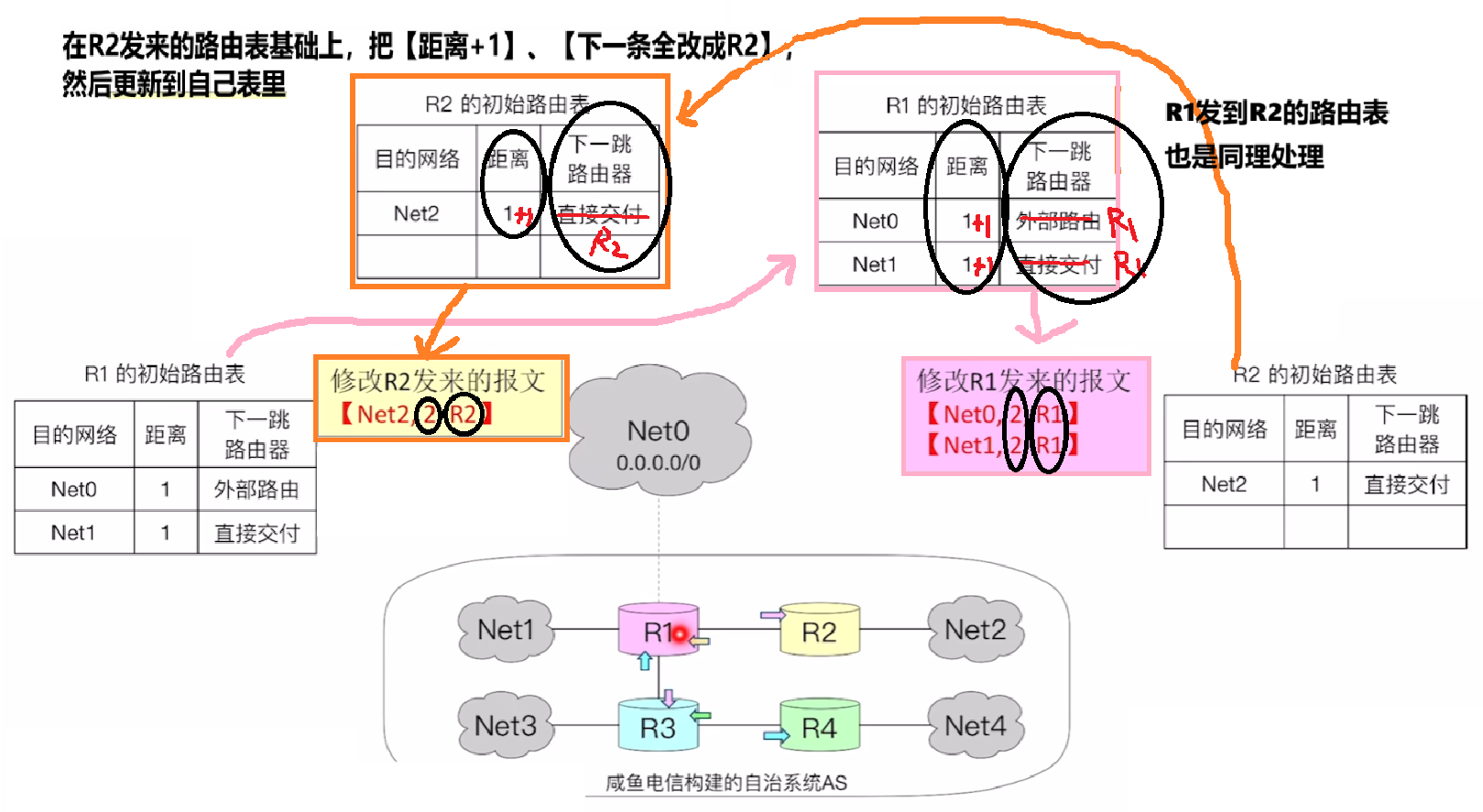
【第一次交换】
- 各个路由器向跟自己直连的所有邻接路由器,互相交换自己的路由表
- 其他路由器收到对方发来的路由表后,把表里的【距离】字段的【值+1】、【下一条地址】改成【发此路由表的路由器】
- 然后路由器检查发来路由表,如果里面的【目的地址】自己的表没有,那就加上去
- 那么看图例子可以发现,因为R1和R4、R2和R3\R4这些路由器都没有直连,所以还需要经过几轮不断地更新互换路由表,才会让每个路由器地路由表完整包含整个网络地路径,也就是达到第一轮【收敛】
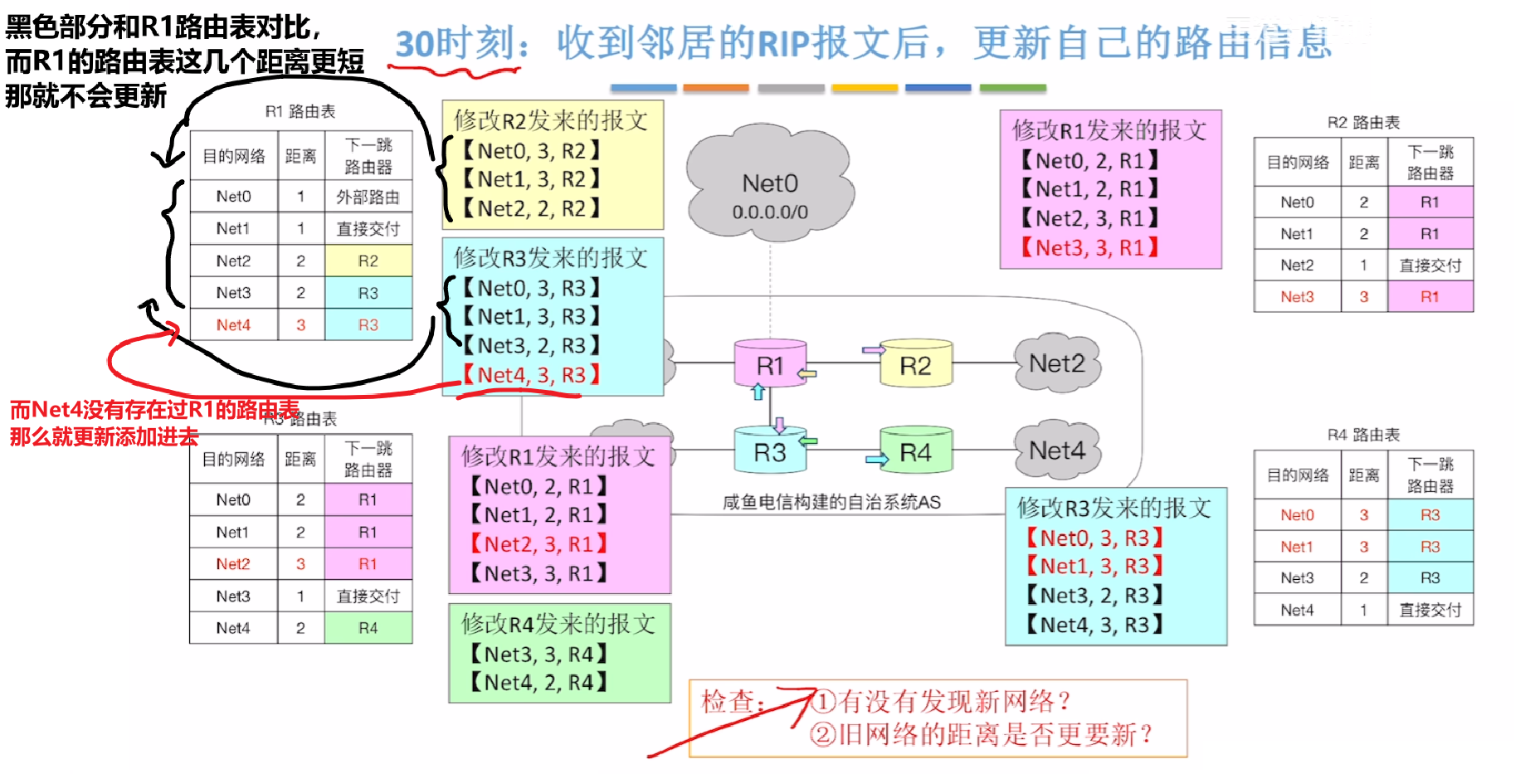
【后面的更新交换】
- 那么当后续网络拓扑结构再次变化时,又会不断通过RIP互换路由表更新新路径
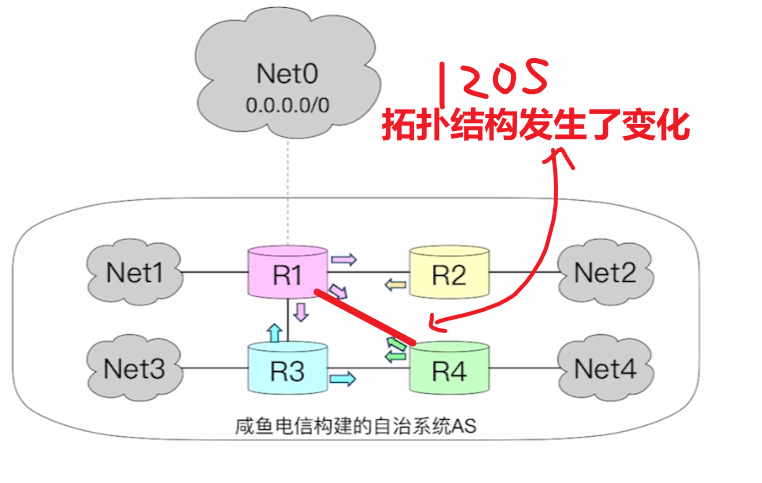
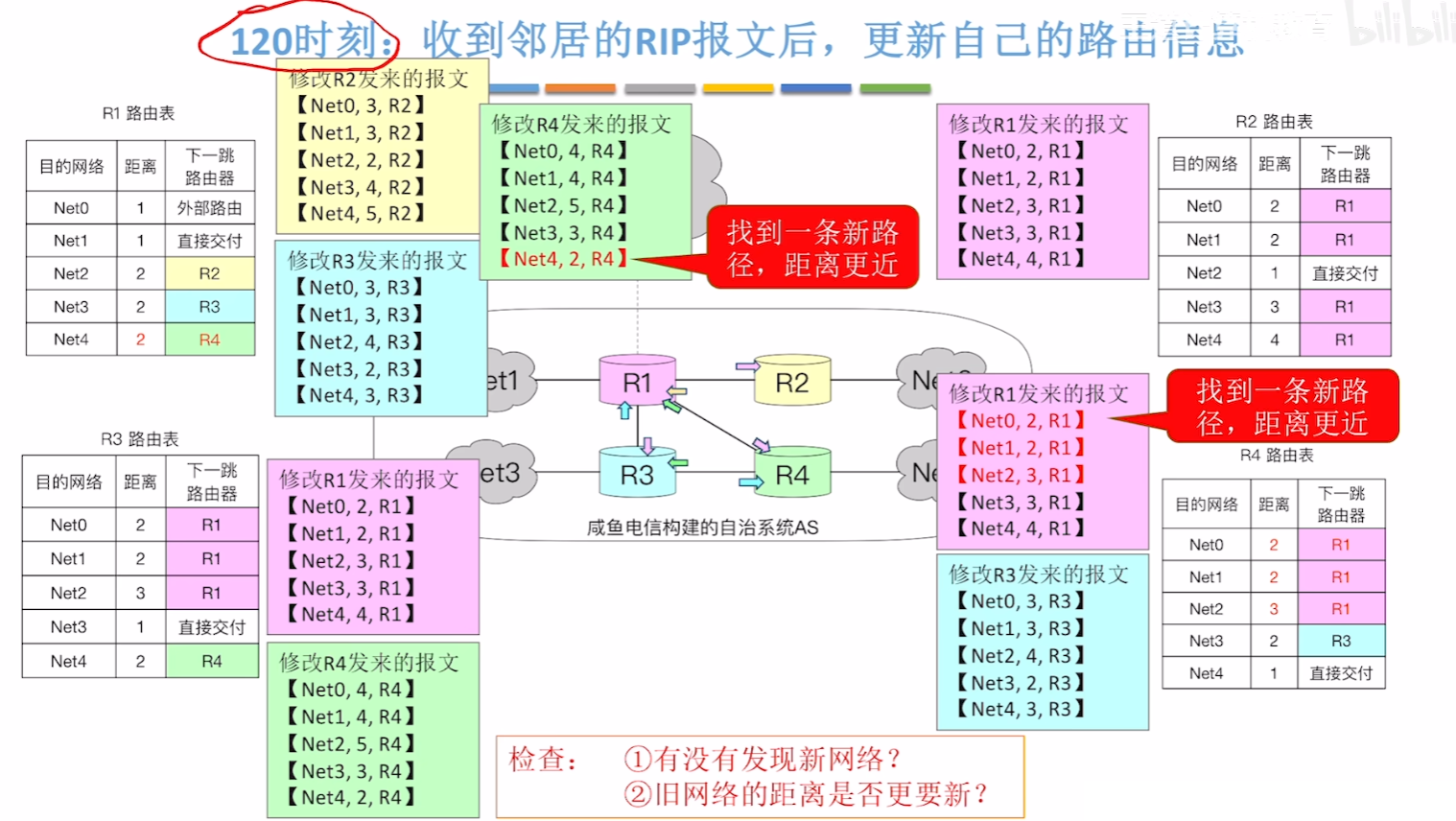
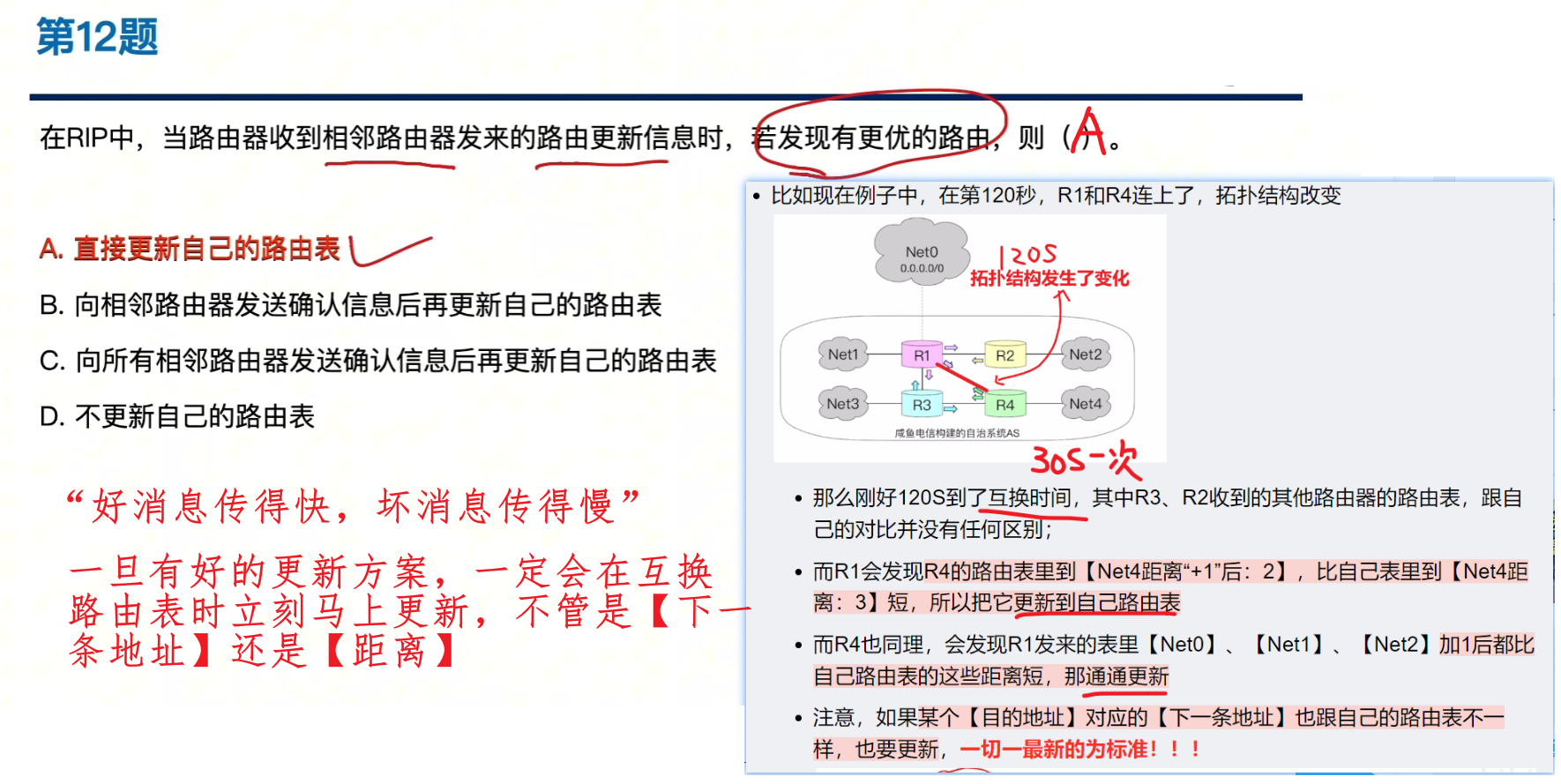
- 比如现在例子中,在第120秒,R1和R4连上了,拓扑结构改变
- 那么刚好120S到了互换时间,其中R3、R2收到的其他路由器的路由表,跟自己的对比并没有任何区别;
- 而R1会发现R4的路由表里到【Net4距离“+1”后:2】,比自己表里到【Net4距离:3】短,所以把它更新到自己路由表
- 而R4也同理,会发现R1发来的表里【Net0】、【Net1】、【Net2】加1后都比自己路由表的这些距离短,那通通更新
- 注意,如果某个【目的地址】对应的【下一条地址】也跟自己的路由表不一样,也要更新,一切一最新的为标准!!!
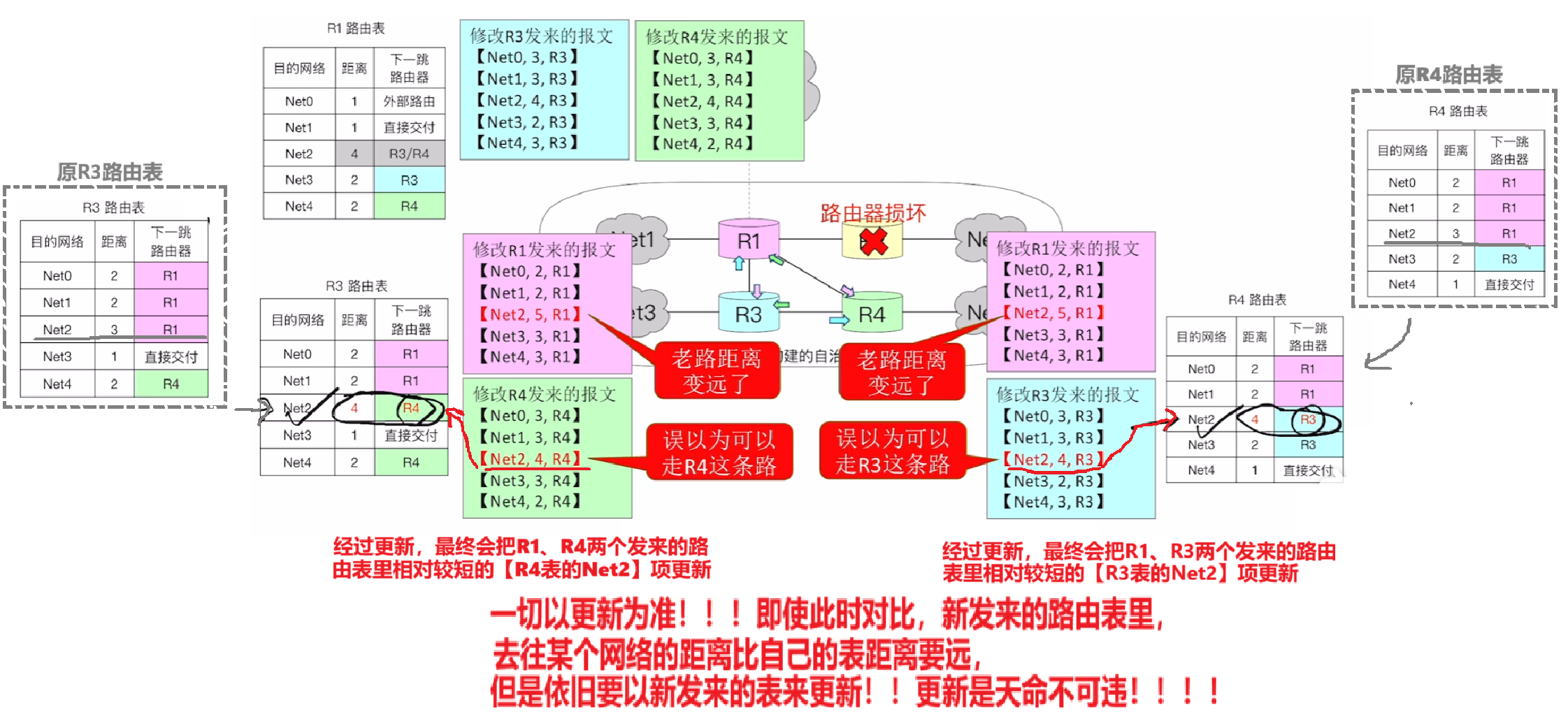
【故障坏消息情况(坏消息传得慢)】
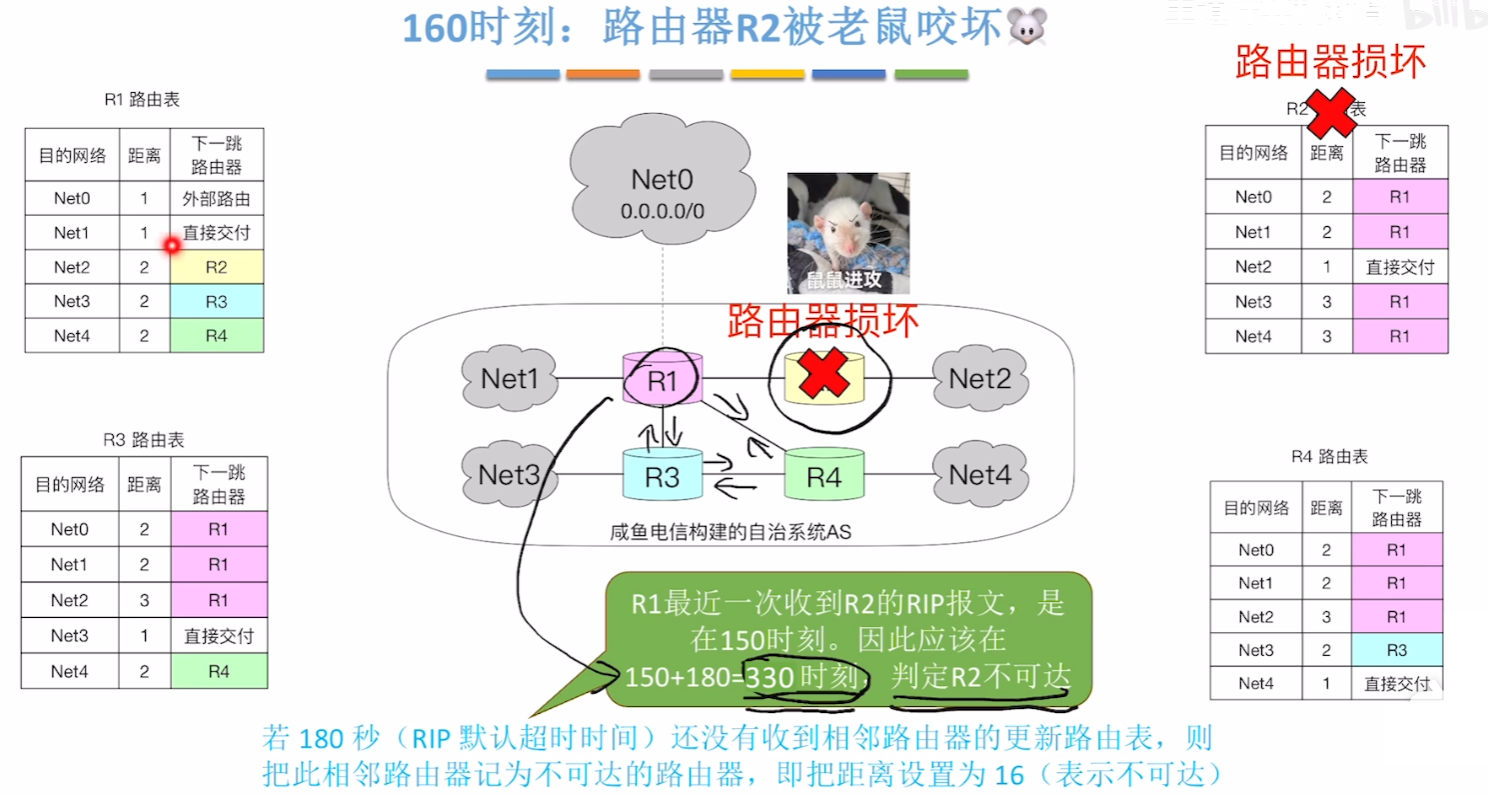
- 由于节点故障等原因,会导致没法及时更新路由表,此时IP数据报可能会陷入循环错误发送
- 例如图例中,R2节点损坏了,而R1上一次收到R2信息是在150S时刻
- 那么RIP【默认180S】为超时时间,
- 也就 [160S - 330S) 时刻,到了要每30S互换信息的时刻,但是R2没办法发送自己的路由表,R1收不到R2的路由表不着急,仍会抱有幻想
- 直到330S那一刻满了180S,R1才会发现出问题了
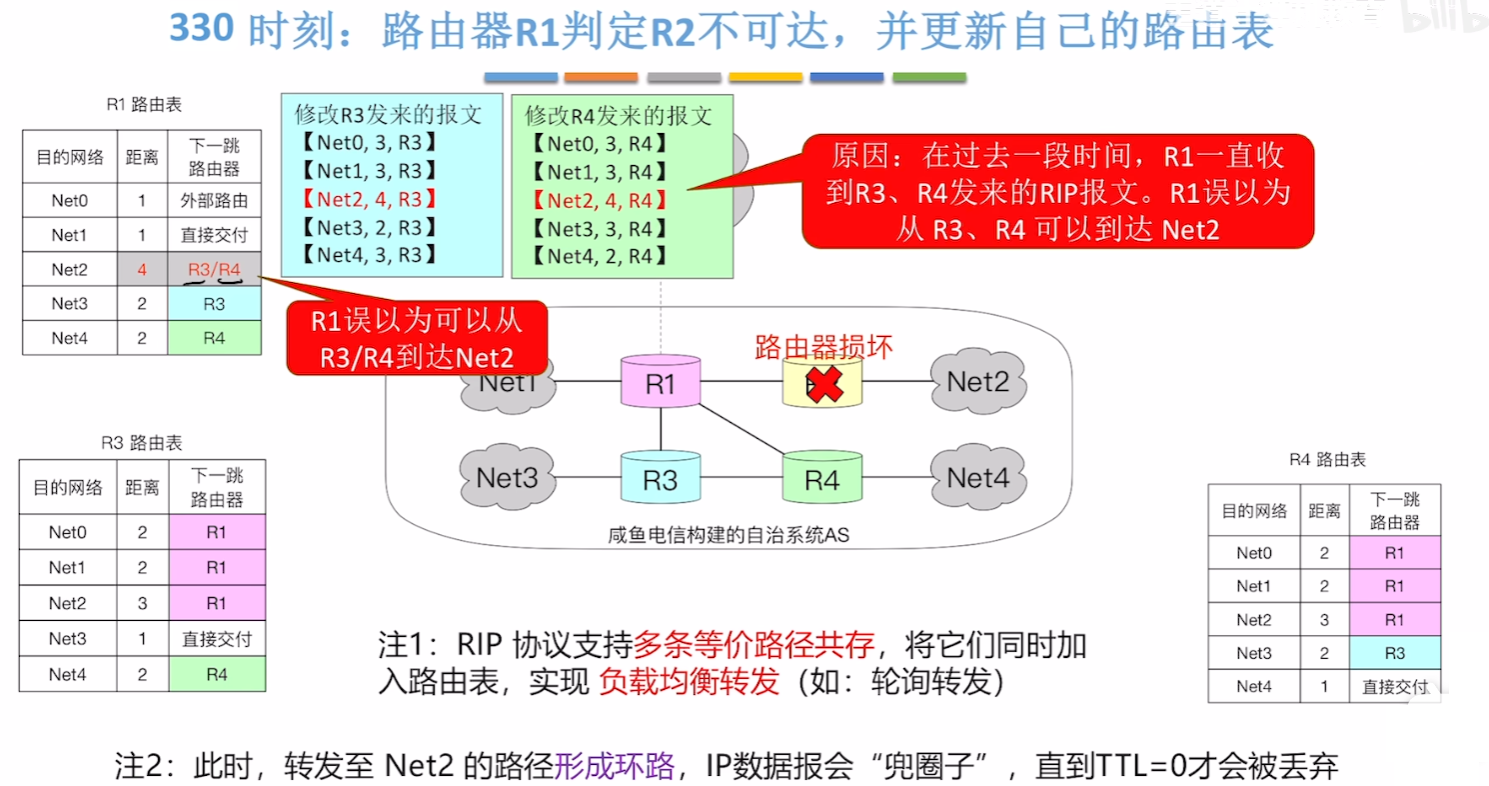
- 而R1发现有问题后,第一时间是修改【R2对应】的【路由表里Net2的 “下一跳”】
- 但是因为在每30S互换信息的时候,R1依旧能收到R3、R4的信息,因此他会误认为R3、R4既然没坏就应该能从那他们那到达【Net2】
- 因此把去往【Net2】的【下一跳】改为【R3或R4】
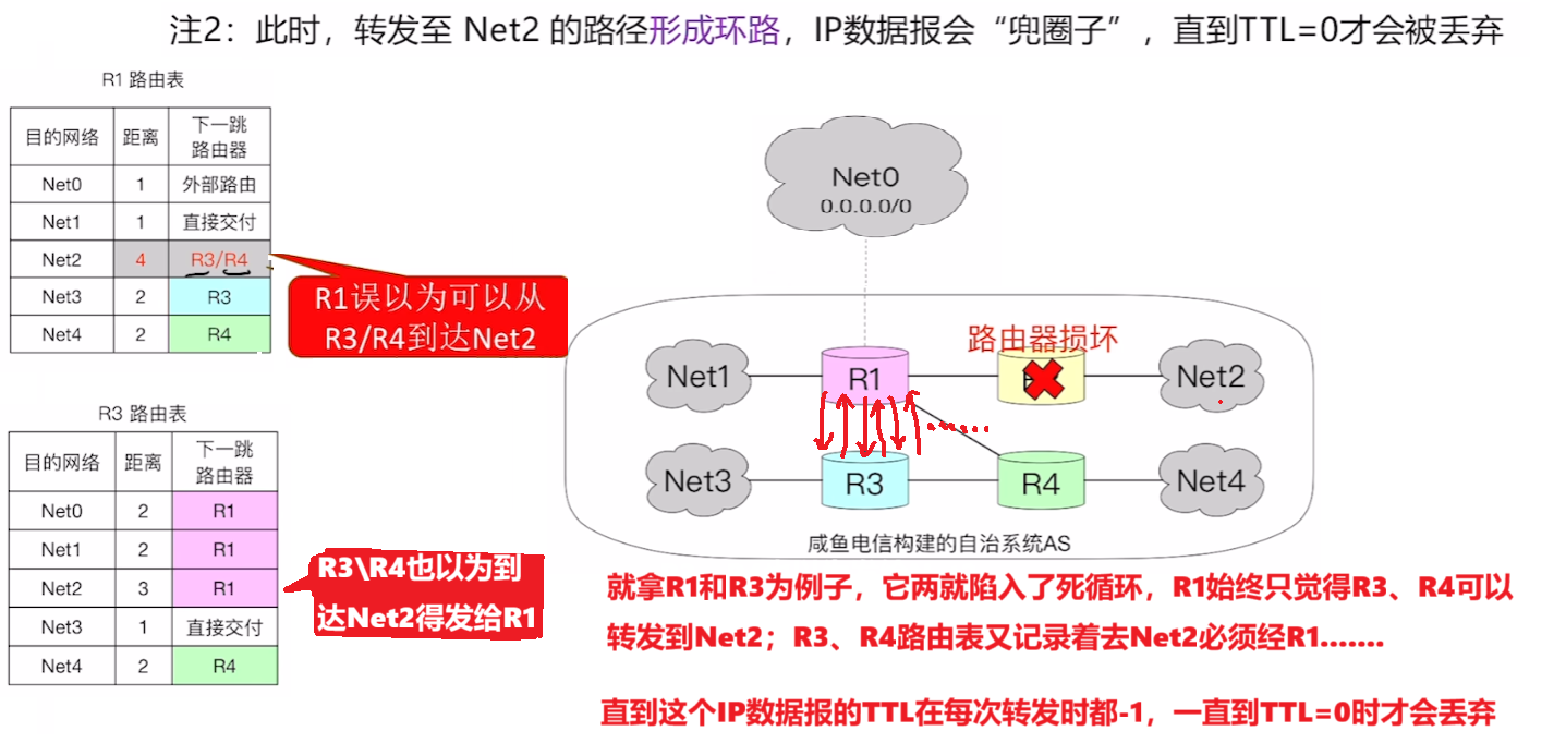
- 然而这种情况只会导致R1和R3\R4在各自的 “信息茧房” 里都误认为,去Net2的路径应该是发给对方,导致双方不停的循环互发,直到IP数据报里设置的TTL=0了才丢弃
- 这就导致了因为路由表没更新而【发送IP数据报】出问题
- 因此RIP协议要求:此时即使R1发现了有设备故障,依旧给老子【互相更新路由表】
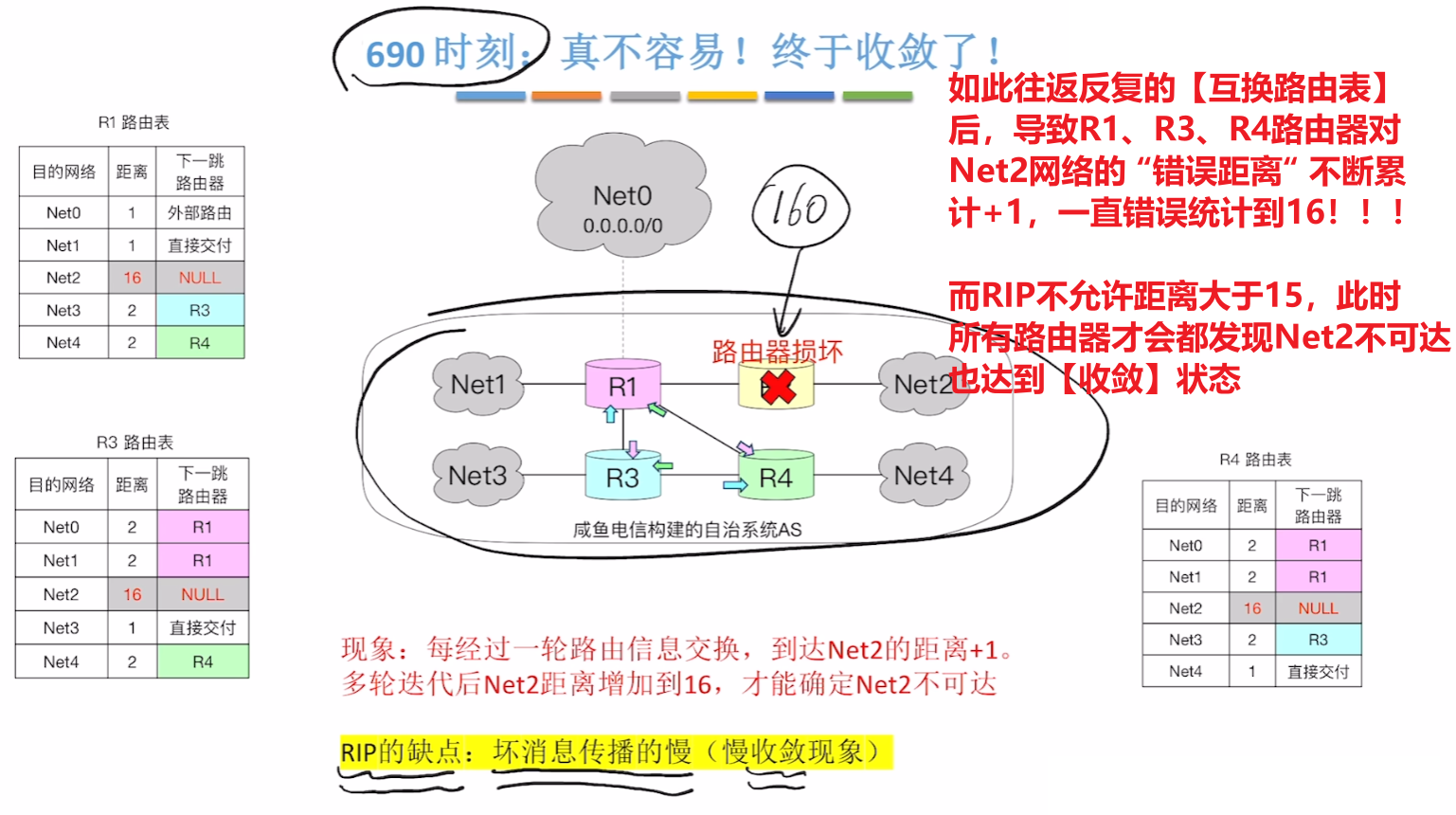
- 而且各个路由器对比收到的路由表后,即使发现距离变远了,依旧【以更新路由表为最高命令!!!】
- 在这个机制下,各个路由器会在一次次互换路由表中累计【错误的距离】,直到【距离=16】的时候,违反RIP要求的合法路径距离,因此所有路由器才会在【Net2】的【下一跳】标记为NULL,也就是【该路不可达】
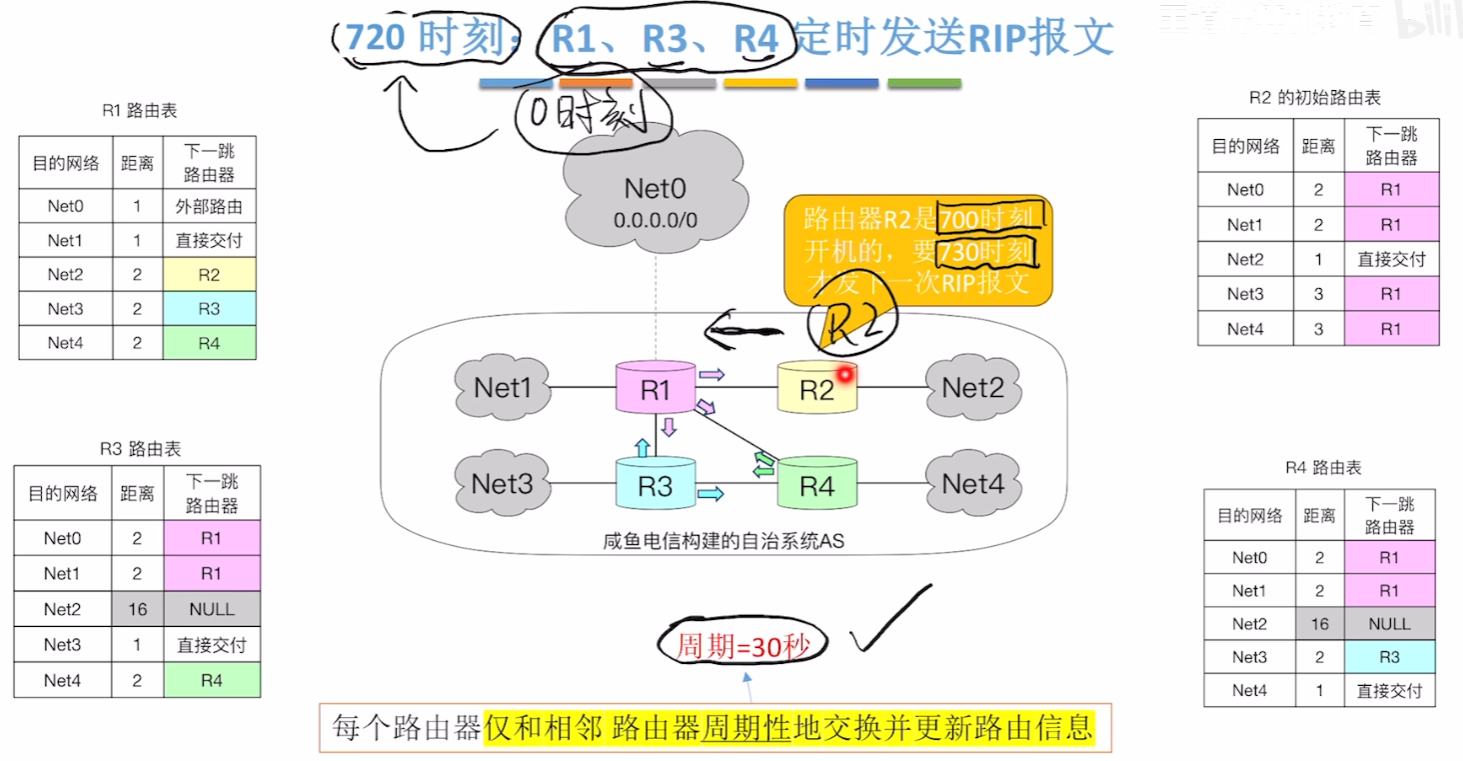
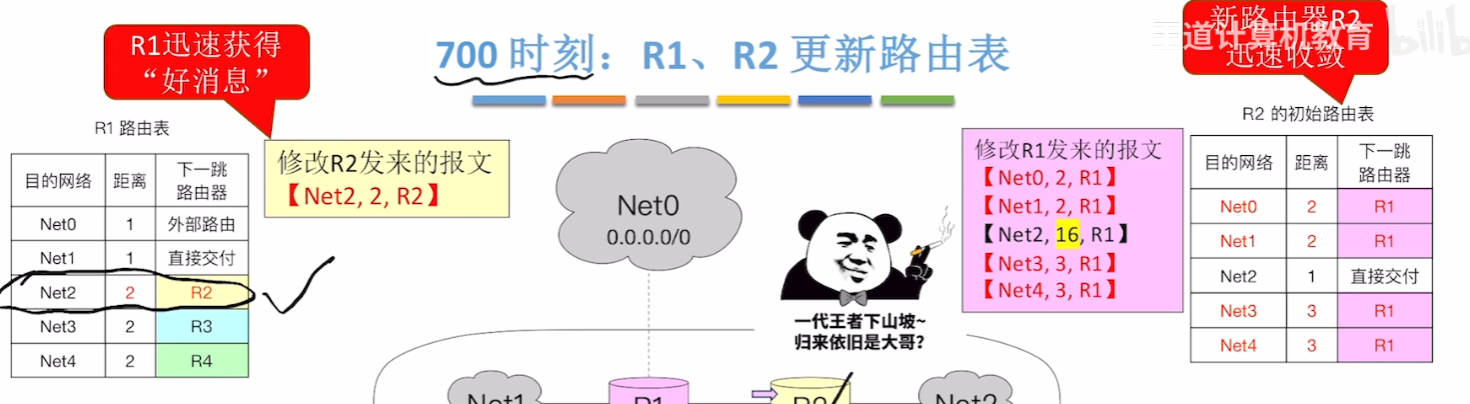
【网络恢复、新节点接入(好消息传得快)】
- 而当故障网络恢复正常、或接入一个新节点时,通过RIP每30S互换路由表的机制,这个信息能够很快更新到各个路由器
- 首先记住一点:每一个路由器有自己的计时周期,固定每30S一次
- 比如图例R1、R4、R3都是从0S开始更新路由表的,按更新周期在720S应该更新一次;而接入的恢复正常的R2在700S才第一次更新,那么它下一次更新应该是730S,而不是跟大伙一起720S更新
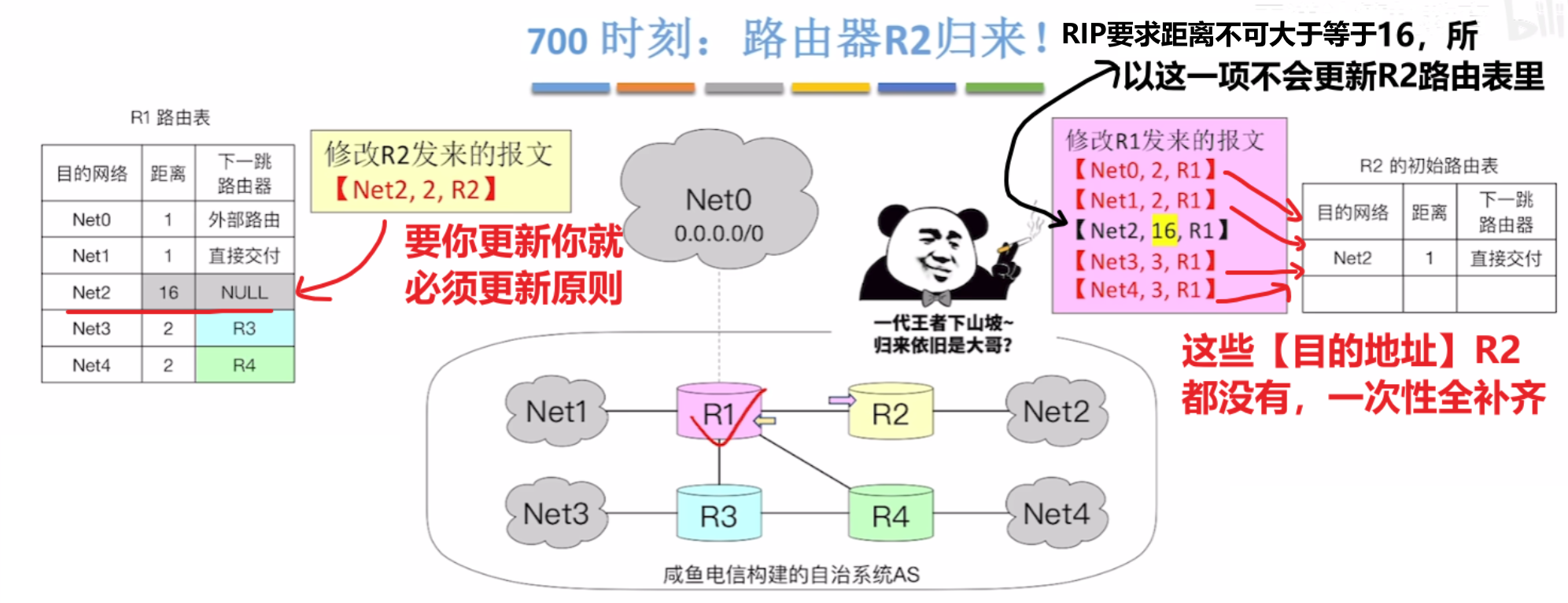
- 那么回到例子,当第700S,R2接入网络中并【初始化路由表(只记录直连网络距离)】,并马上给相邻路由器互换路由表
- 那么R1路由器秉着【必更新】原则,把Net2重新改为正常的路径、距离
- 而R2也秉着【必更新】原则,把R1的信息更新进自己路由表,但是值得注意的是因为RIP要求距离不可大于等于16,所以对R1发来的表的Net2距离也没办法+1,因此这种情况才不会被更新进路由表里
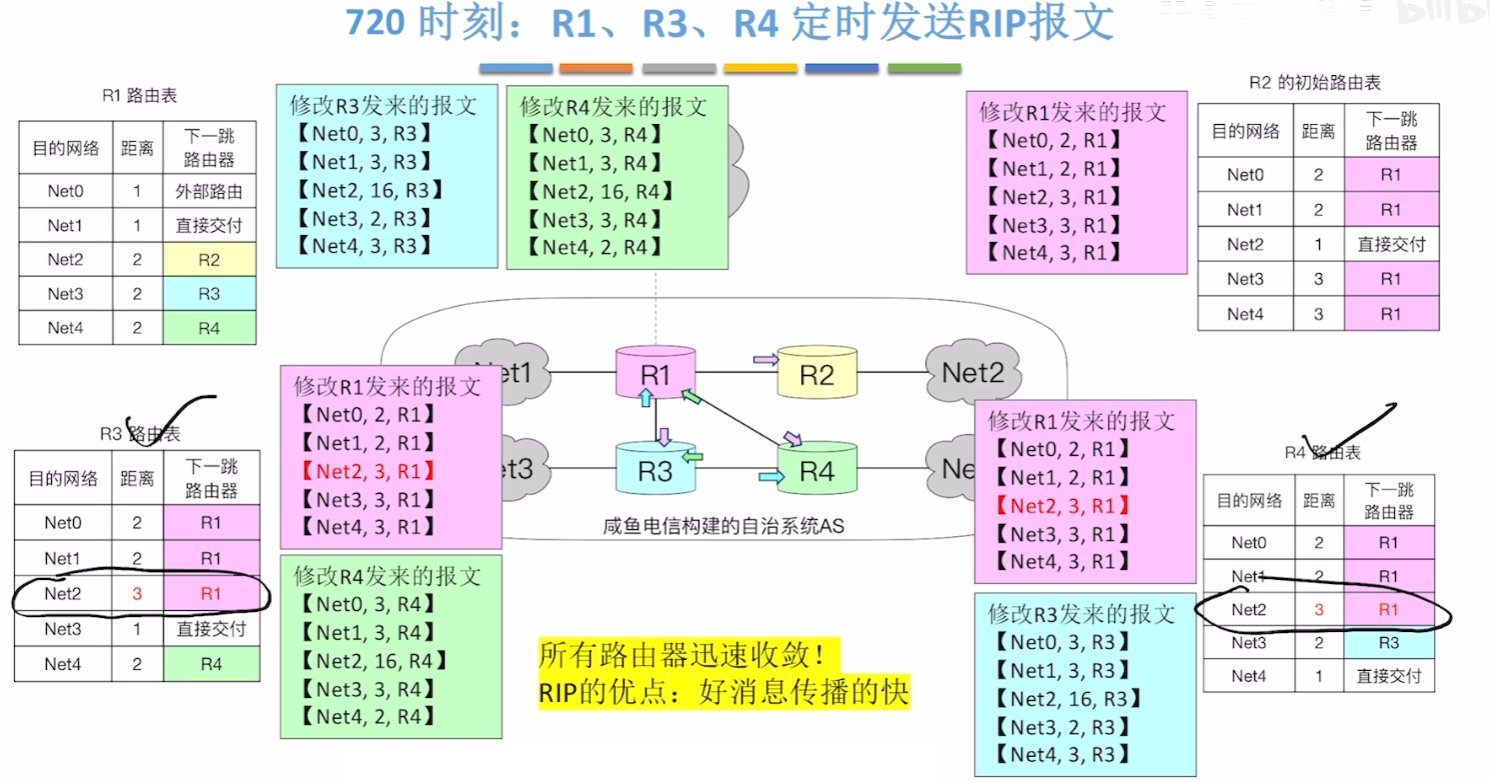
- R1以最快的方式收到了“好消息”、R2以最快方式达到【收敛状态】
- 随后720S,R1、R3、R4的更新周期到,互发路由表,最终在这个时间段完成【收敛状态】



4、RIP的【优点】、【缺点】
这种算法机制下,可以很明显发现,特点是当出现更好、更优的路径时,各个路由器会很快互相传达给对方,使得整个网络的路由器都能快速更新【最佳路径的路由表】;
而这个机制也导致了更新网络信息需要靠不断地N次地互换路由表,那当网络故障时,也只能不停接着互换路由表,直到路由表里某个距离到达16,而每交换一次都需要隔30S
因此RIP地优缺点总结如下:


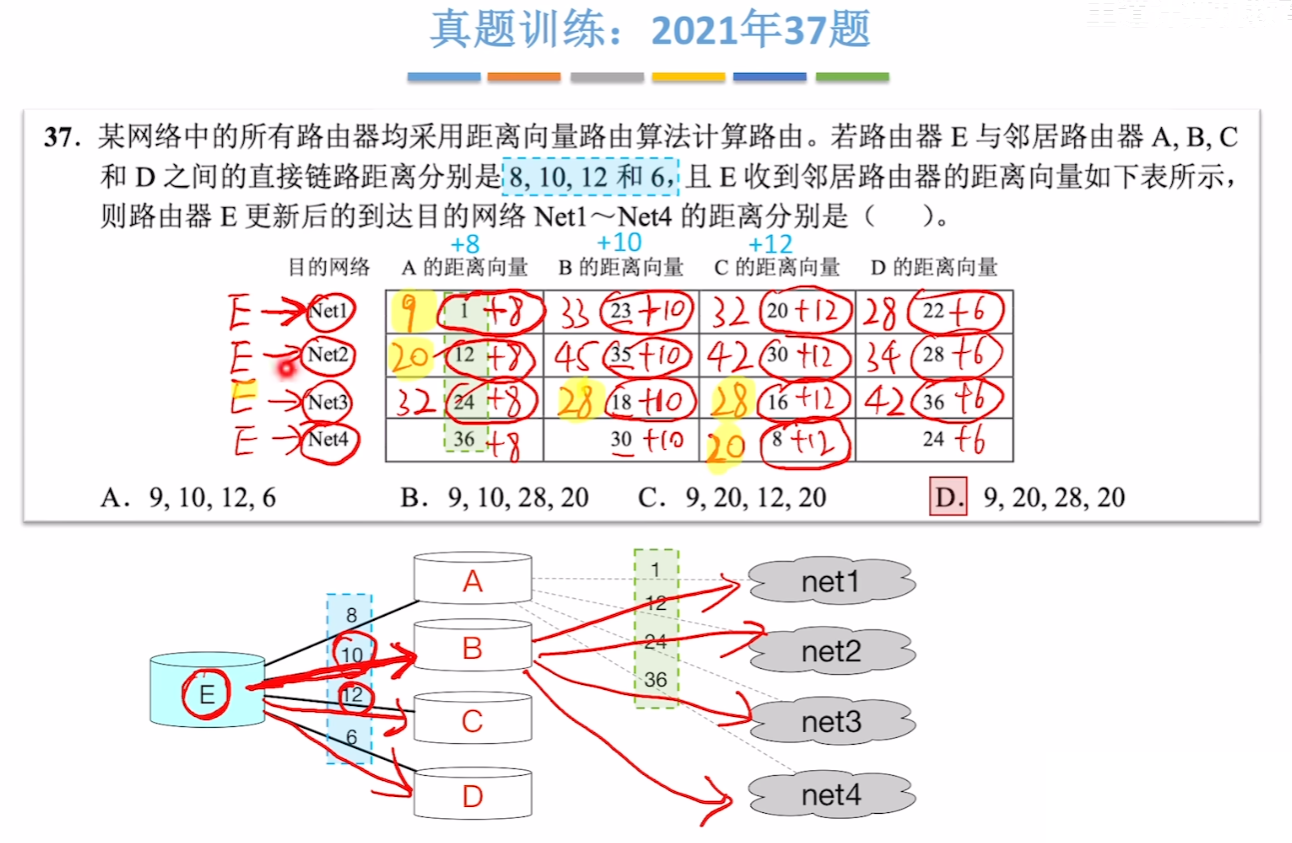
5、【例题】




四、开放最短路径优先协议OSPF(Open Shortest Path First)
1、【OSPF】属于【网络层】
通过【IP数据报】传输它的协议信息
因此IP首部的【协议字段】会设定为【89】
至于OSFP的Type值先简单了解一下,后面会学

2、OSPF原理 和 特点
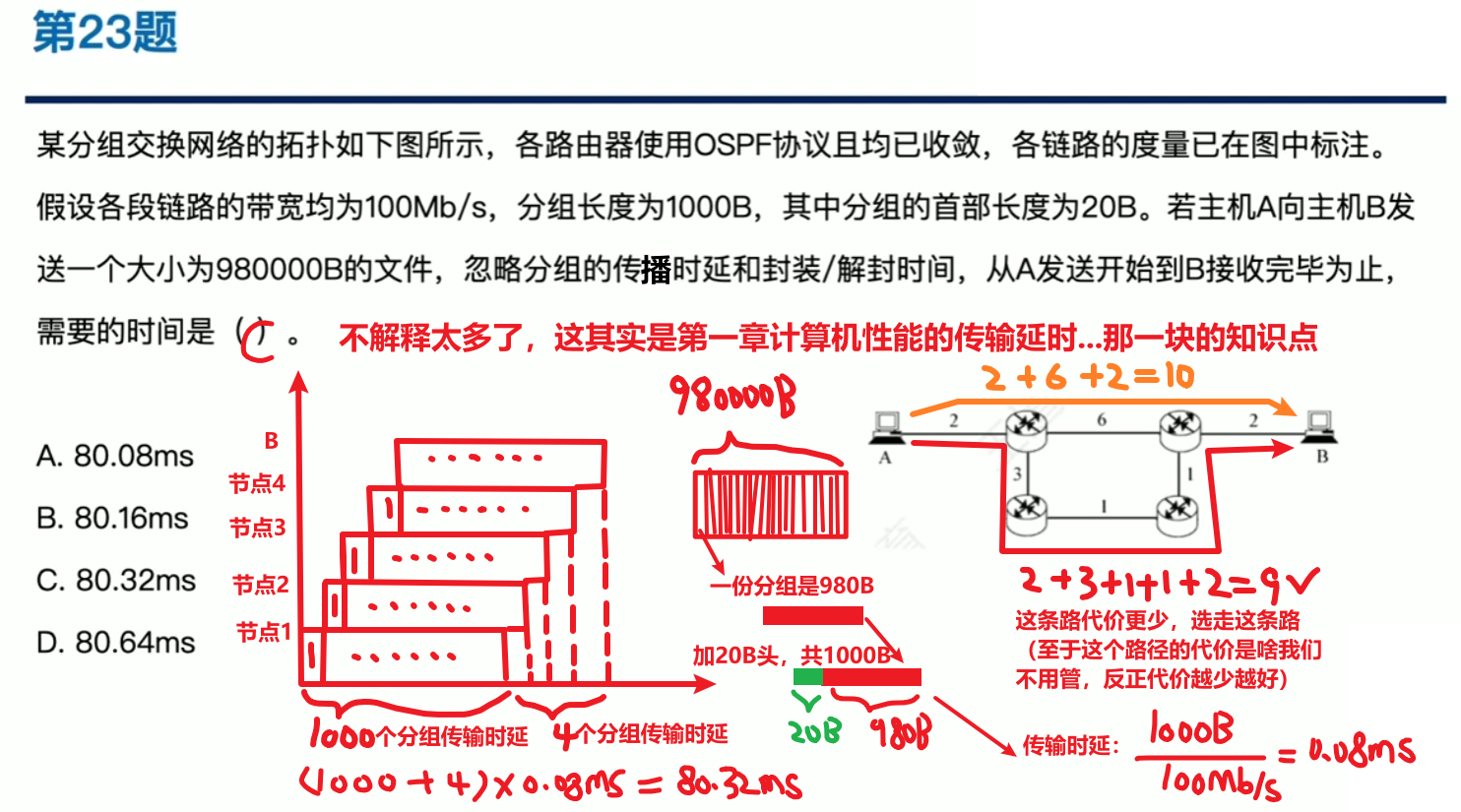
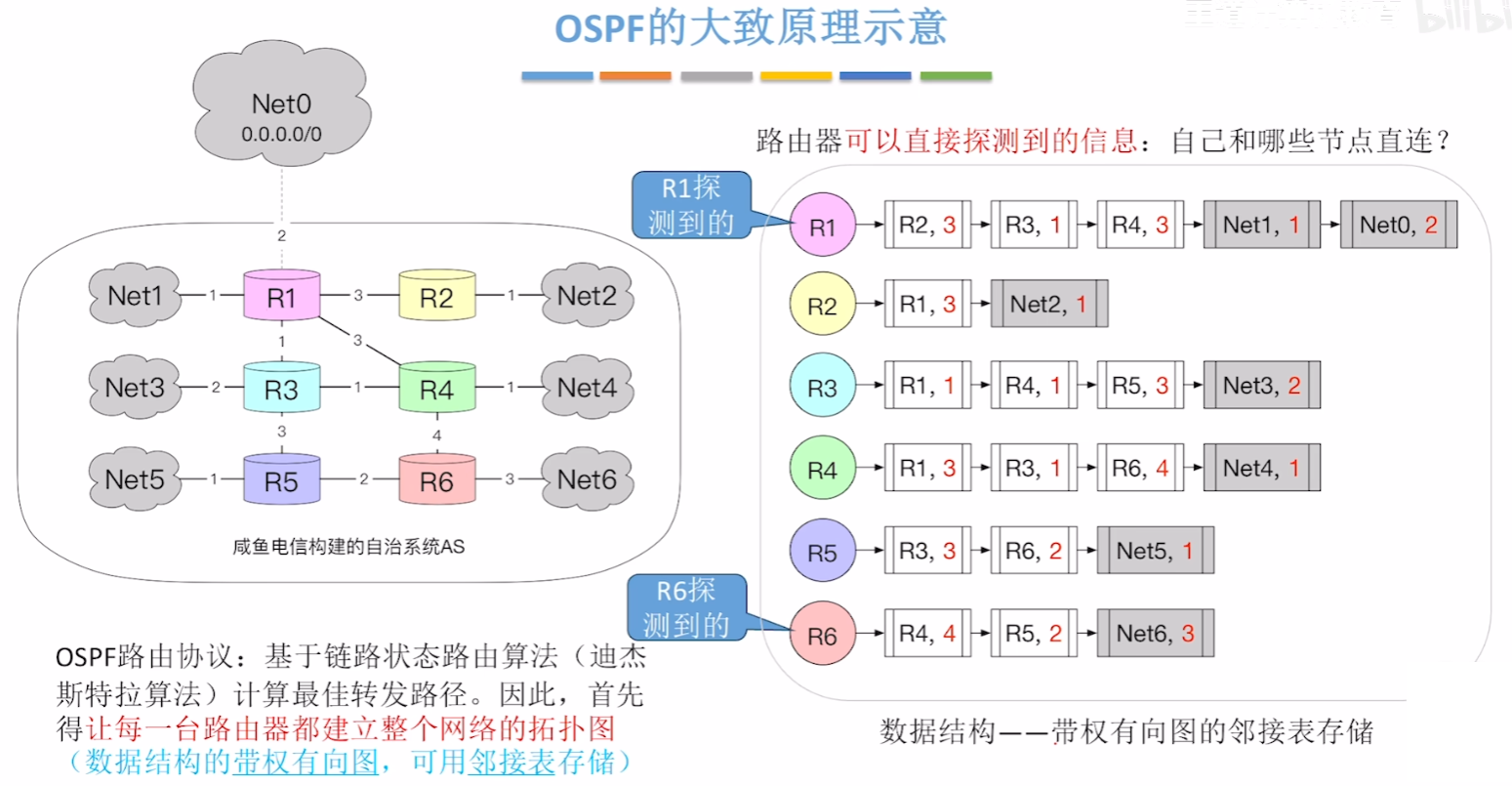
首先OSFP采用【链路状态算法】,基本原理就是【带权有向图的迪杰斯特拉算法】
- 带权就是每个线路都用有一个值,代表【代价(比如带宽、距离...)】
- 做法就是:每个路由器都记录下它【连接的所有链路】以及【权值】,合起来像链表一样
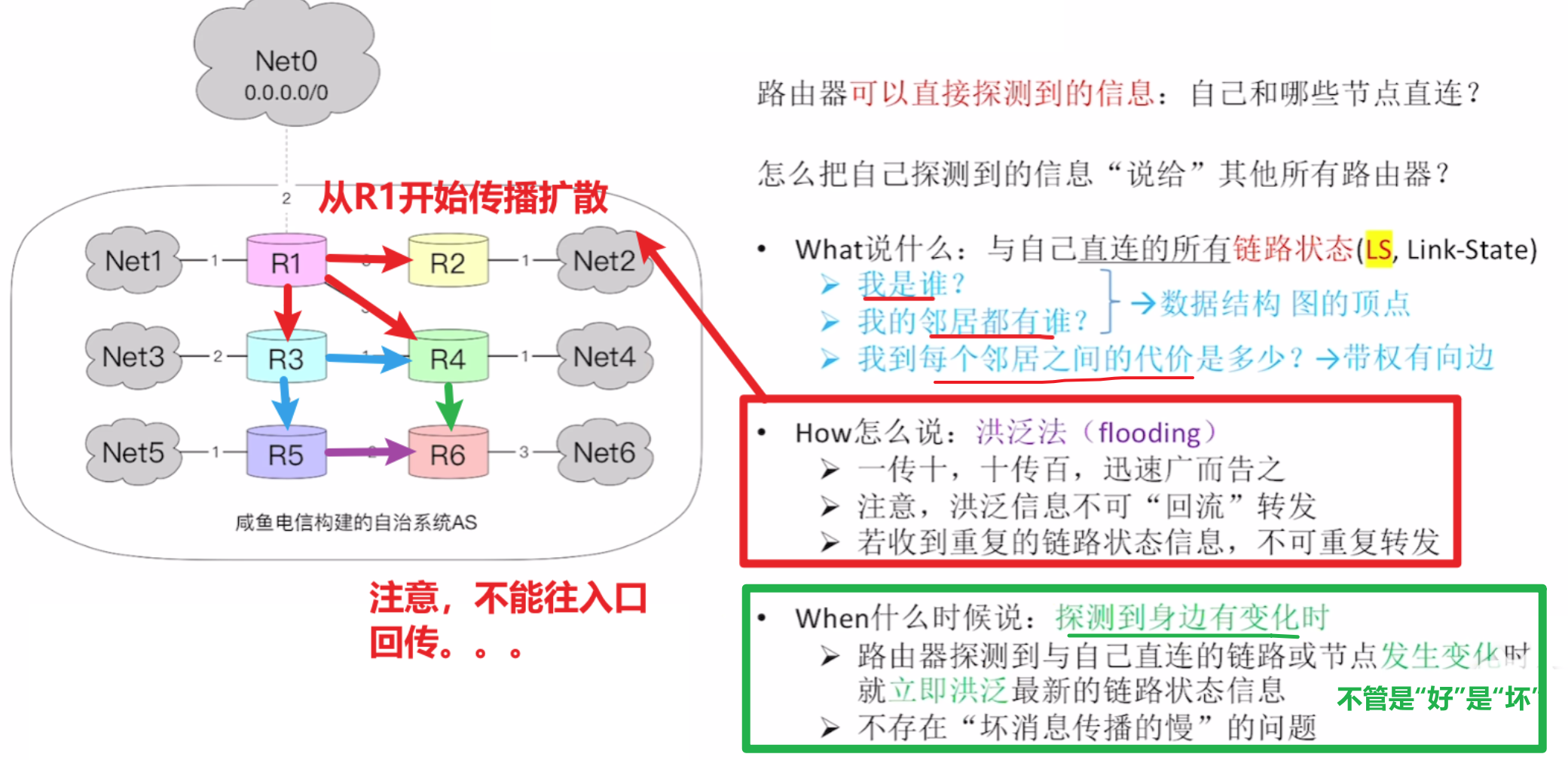
- 然后【OSFP】要求每个路由器去把自己记录的信息,主动沿链路告诉所有人
- 这个模式叫【泛洪法】:
- 一个路由器将自己的【链路状态信息】递归形式发给整个网络所有路由器
- 他传给邻近的路由器,再由他们向其他人传播
- 回忆跟【RIP】的区别:
- 【RIP】是所有路由器大家一起互相交换信息;【OSPF】是谁链路状态改变了就主动跟所有人说
- 而且【RIP】是固定30S发一次,好消息传得快、坏消息传得慢;而【OSPF】不管什么变化、信息,都立刻马上广播!!
;
【OSPF的五大特点】
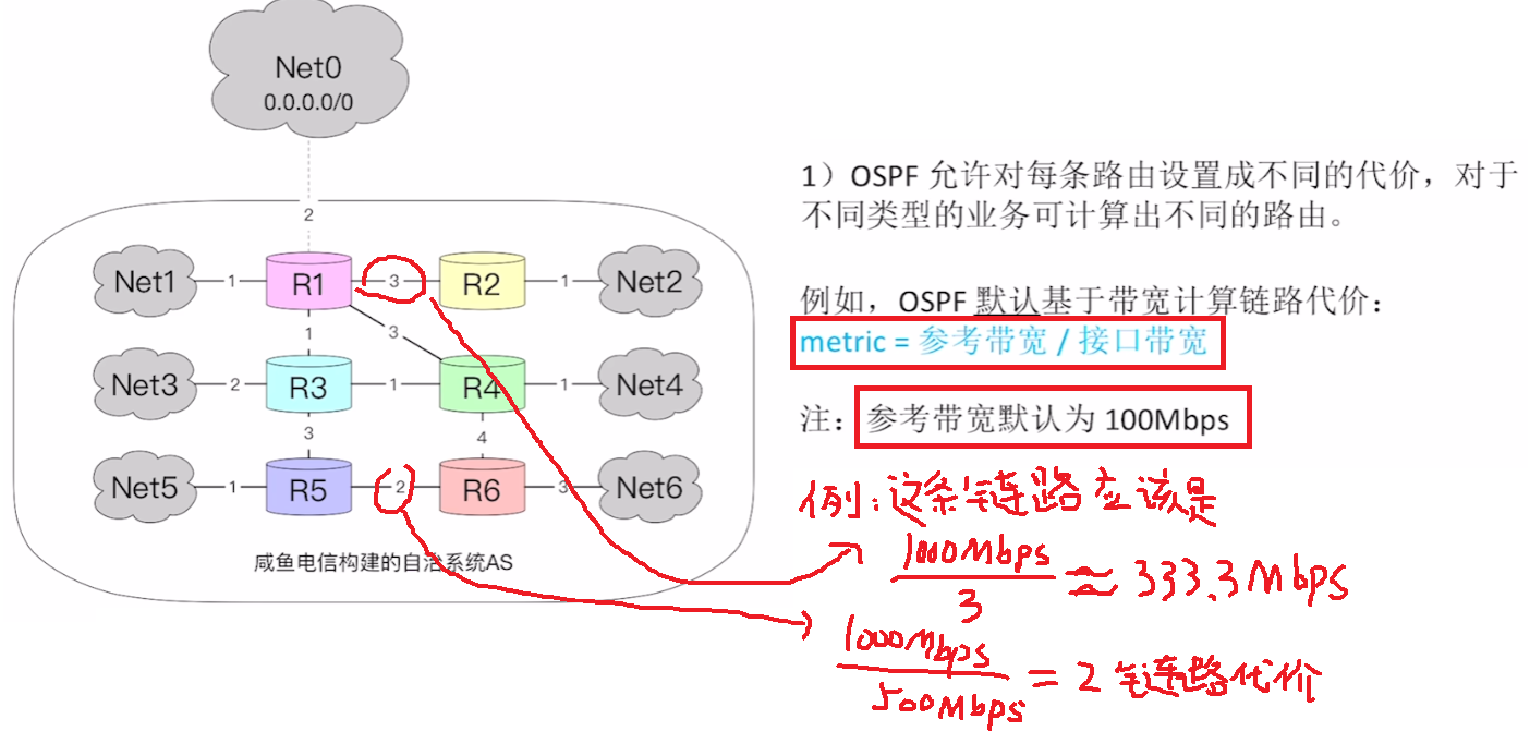
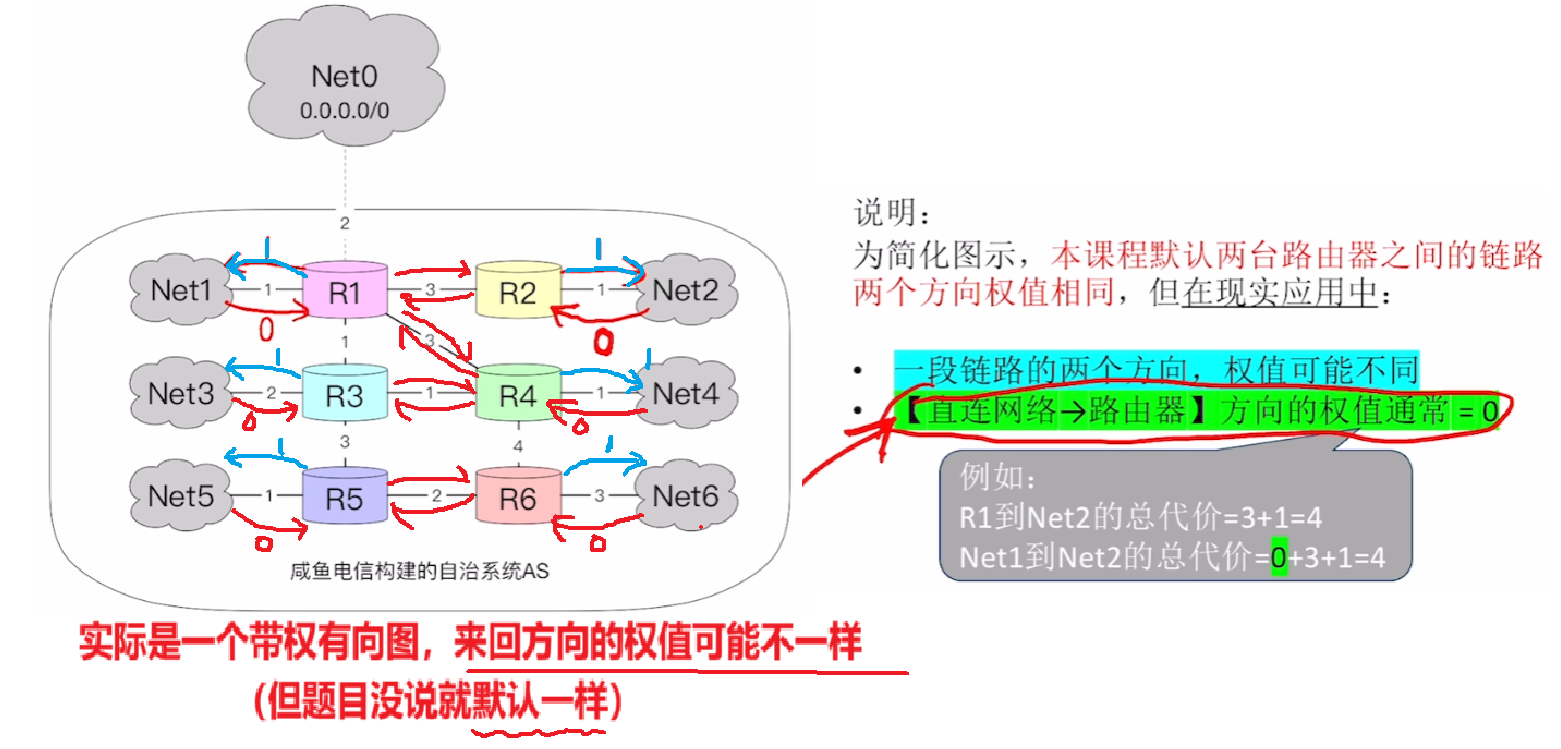
- 1、每条链路的【代价】通过不同的业务计算方式,转化成简单的【权值】
- 注意:每个链路若没有特别说明,可以当成【无向图(来回方向的权重都一样)】,但是实际是【有向图】,来回方向权值不一样
- 而且是【有向图】情况的时候,【直连网络(回)路由器】是0、【路由器(去)直连网络】是1
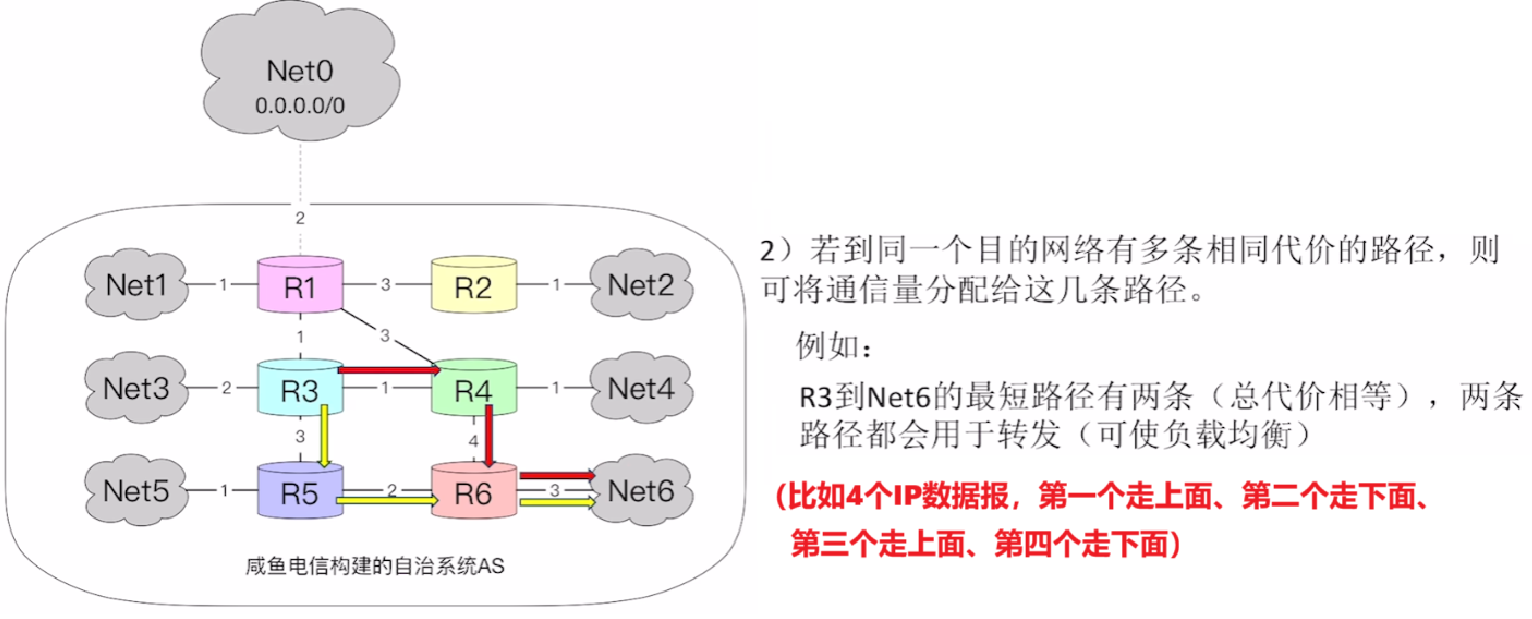
- 2、存在【相同代价】的多条路径,并且这些路径都可以选,以负载均衡
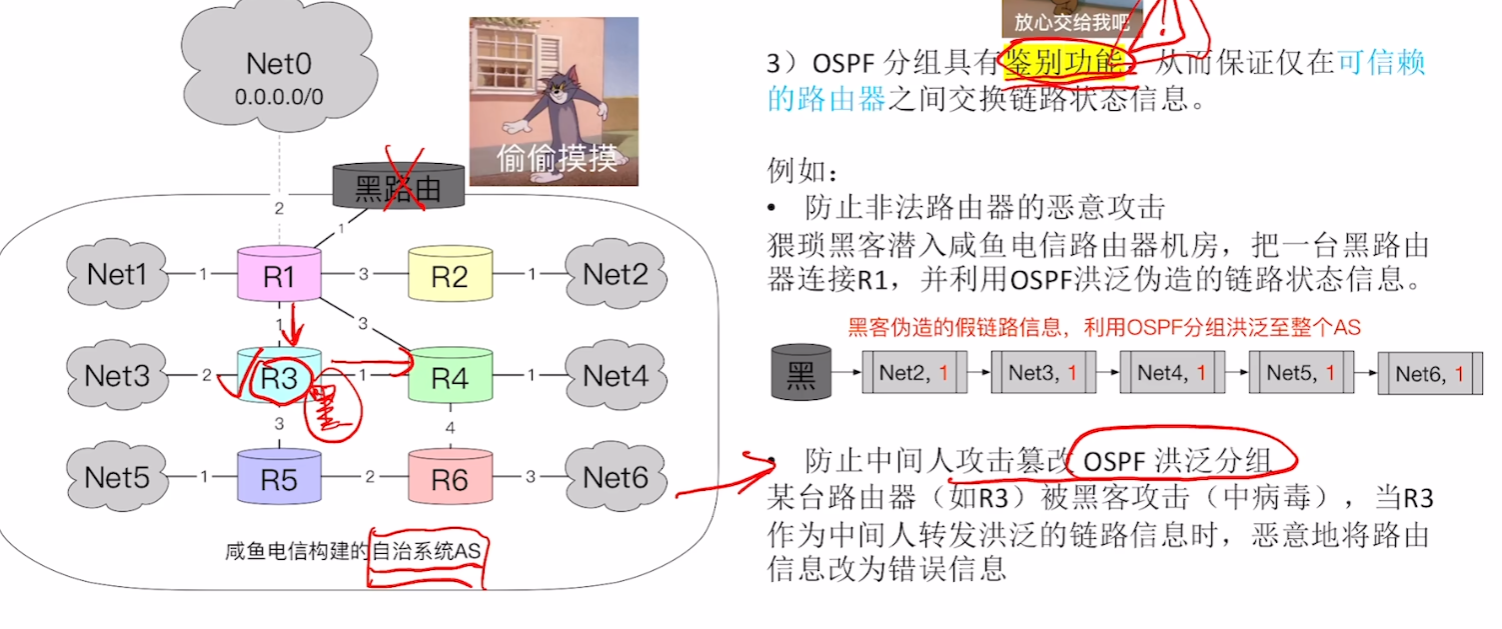
- 3、OSPF具有鉴别功能,能防黑客(不重要)
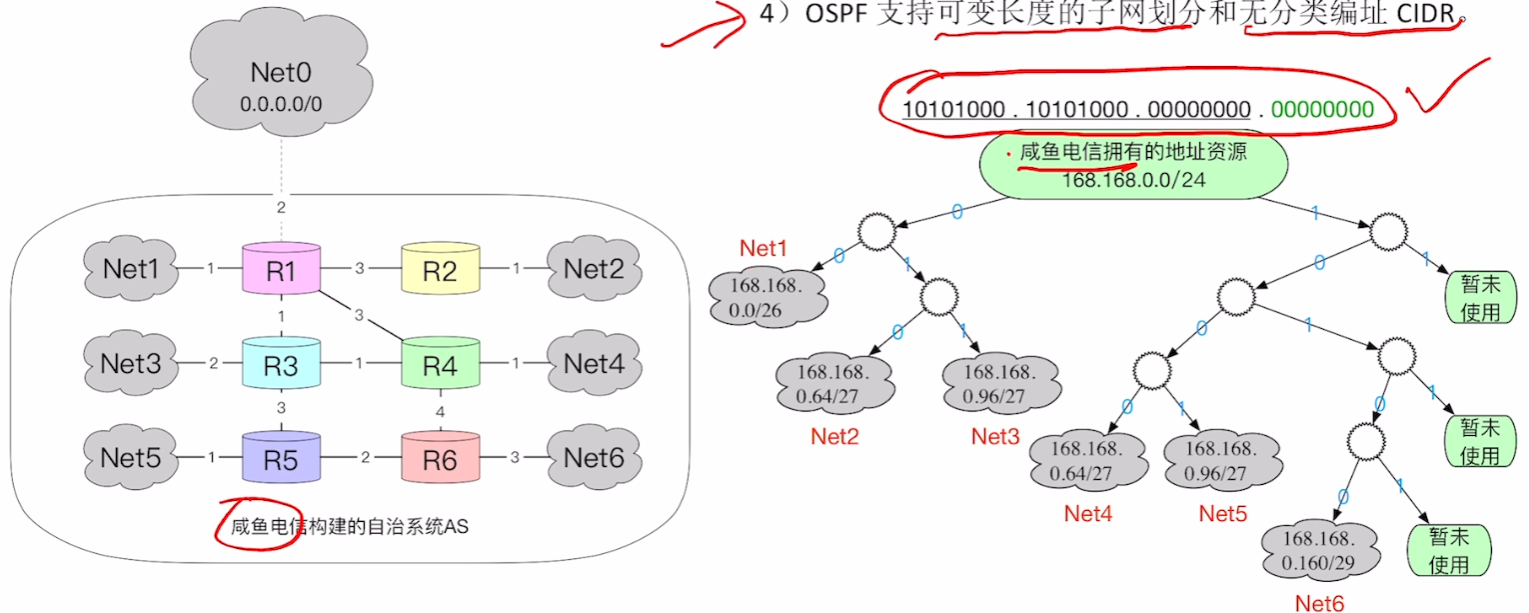
- 4、OSPF支持【可变长子网划分】和【无分类编址CIDR】(不重要)
- 5、每个链路状态都会带上一个【序号】,每次更新状态,序号【+1】
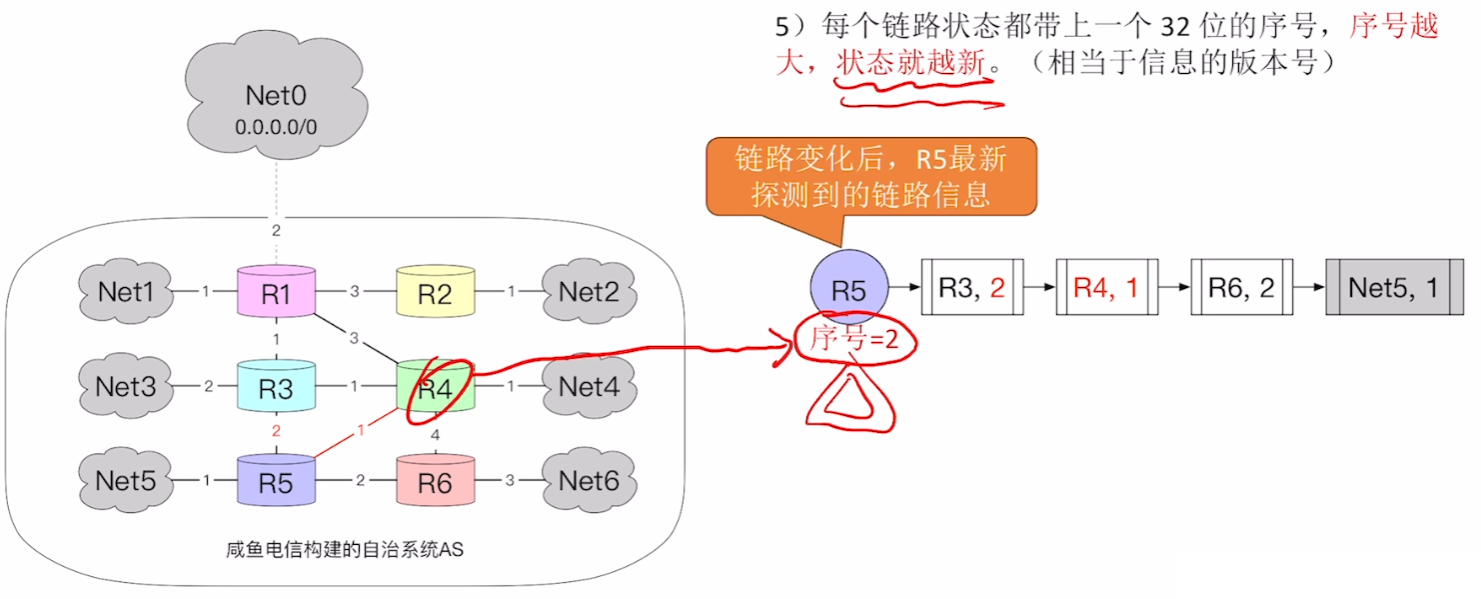
3、OSPF工作流程
【思维导图】
各路由器用于交换的【链路状态】结构
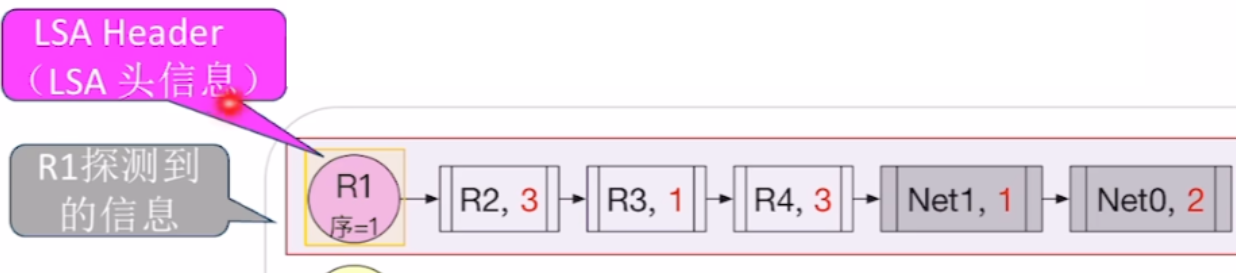
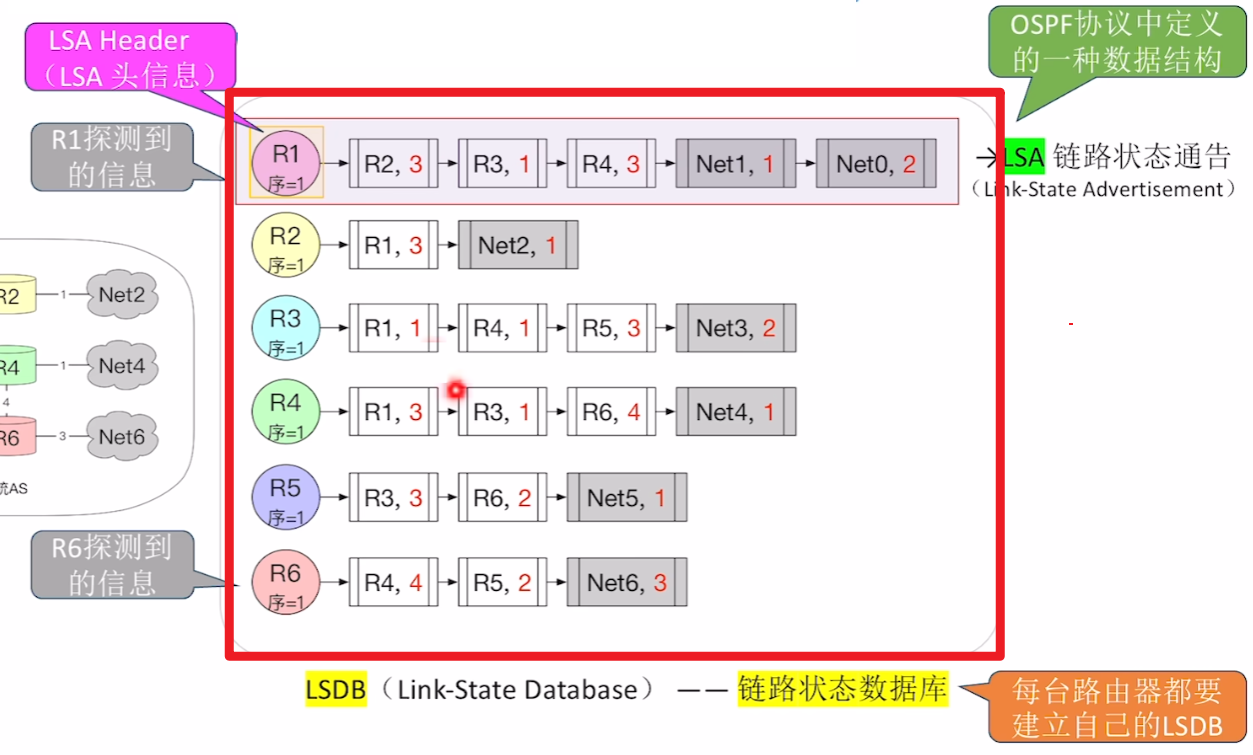
- 【LSA链路状态通告】:一个路由器记录的自己的链路信息
- 是【LSDB】里的【一条数据项】
- 【LSA Header】:【LSA】的【头信息】
- 包括【是哪个路由器?】、【更新的序号版本】
- 【LSDB链路状态数据库】:也称路由器的【拓扑数据】
- 所有路由器的【LSA】的集合,类似一整张excel表格
- 收敛状态下,所有路由器的【LSDB】都要一模一样,涵盖所有路由器的【LSA】
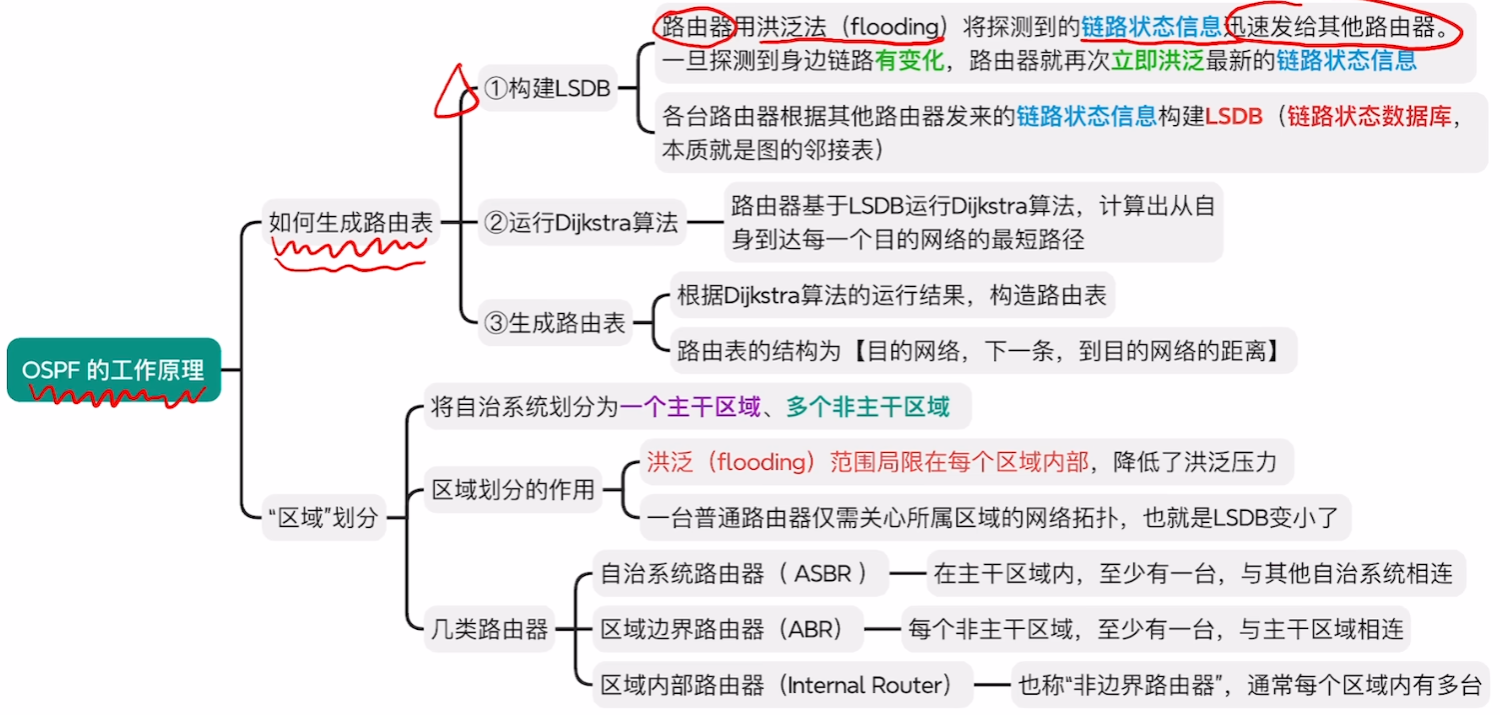
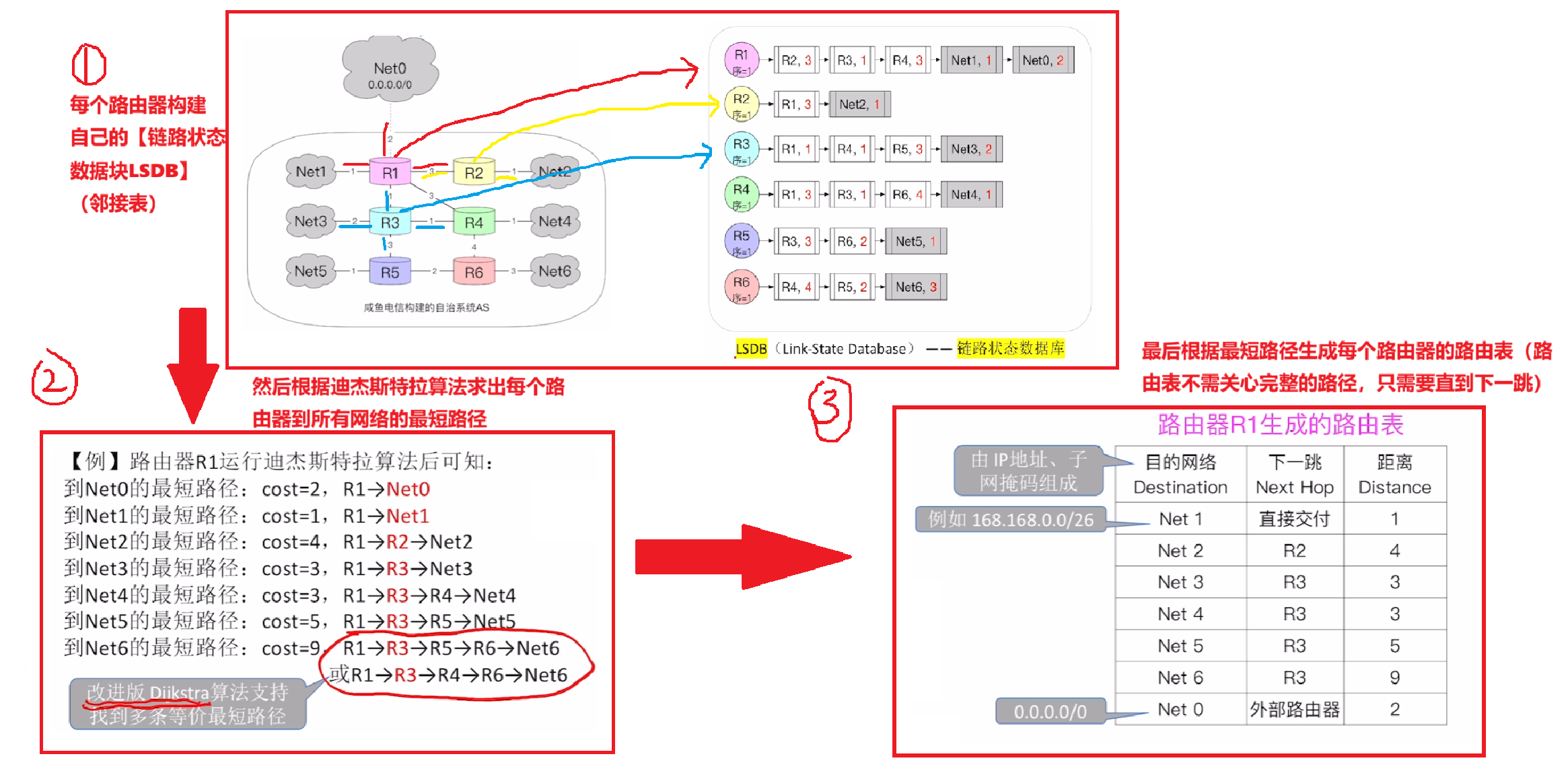
【宏观的链路状态算法流程】
宏观上看整体上就3个流程:
- 1、首先每个路由器通过【洪泛法】让所有路由器都生成一个【LSDB链路状态数据库】
- 2、然后每个路由器根据【迪杰斯特拉算法】求出自己到【所有网络】的【最短路径】
- 而且是比普通数据结构的迪杰斯推算法更高级:可以求得【不止一条最佳路径】
- 3、最后路由器根据求得的【最佳路径】,生成自己的【路由表】
- 【路由表】不需要像【最佳路径】那么完整记录整个路径,只需要记录【到某个网络的下一跳】

4、OSPF分区
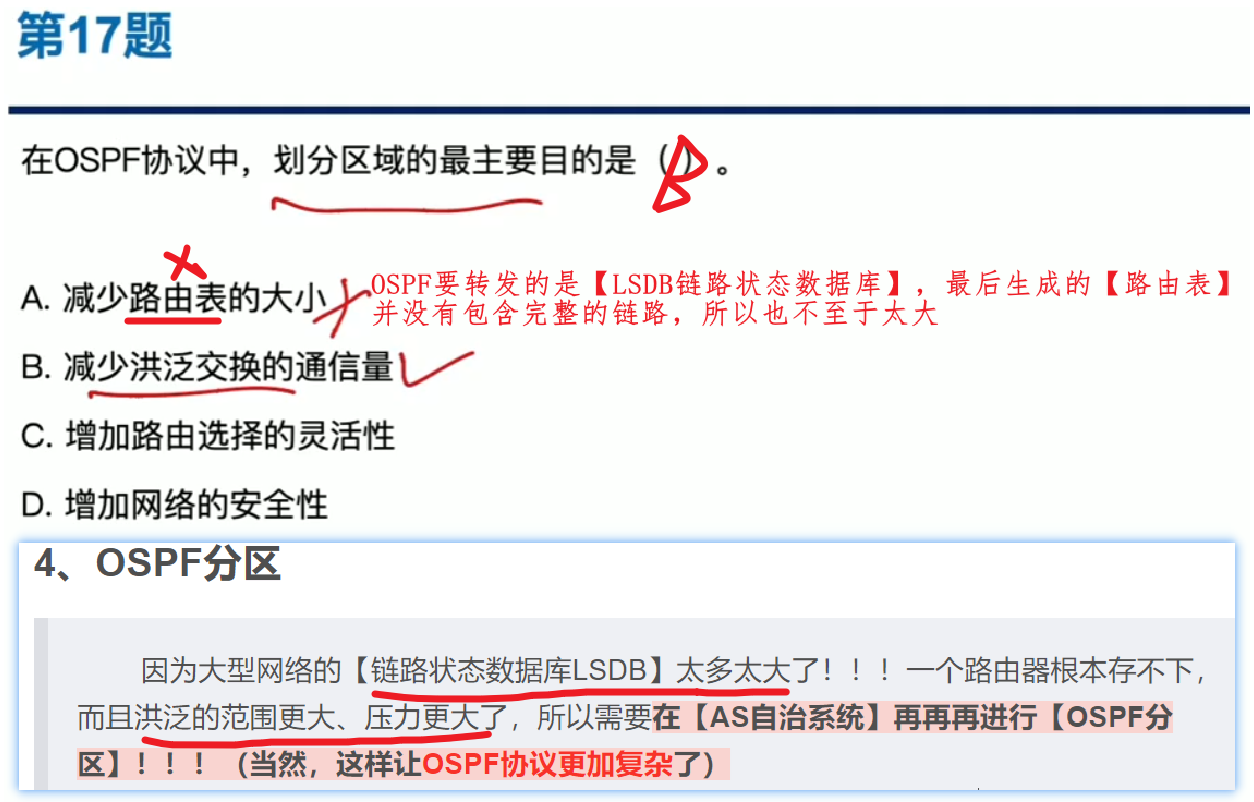
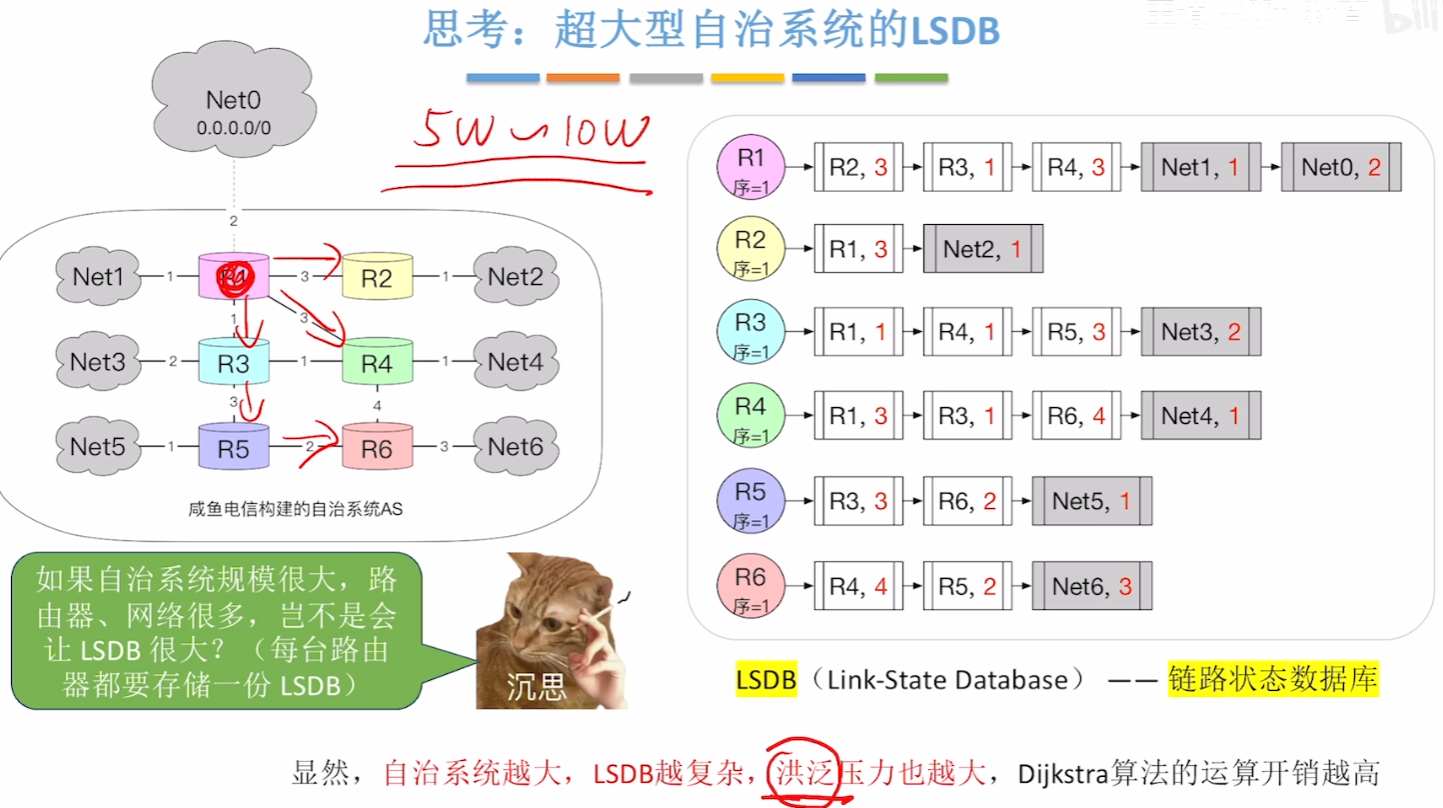
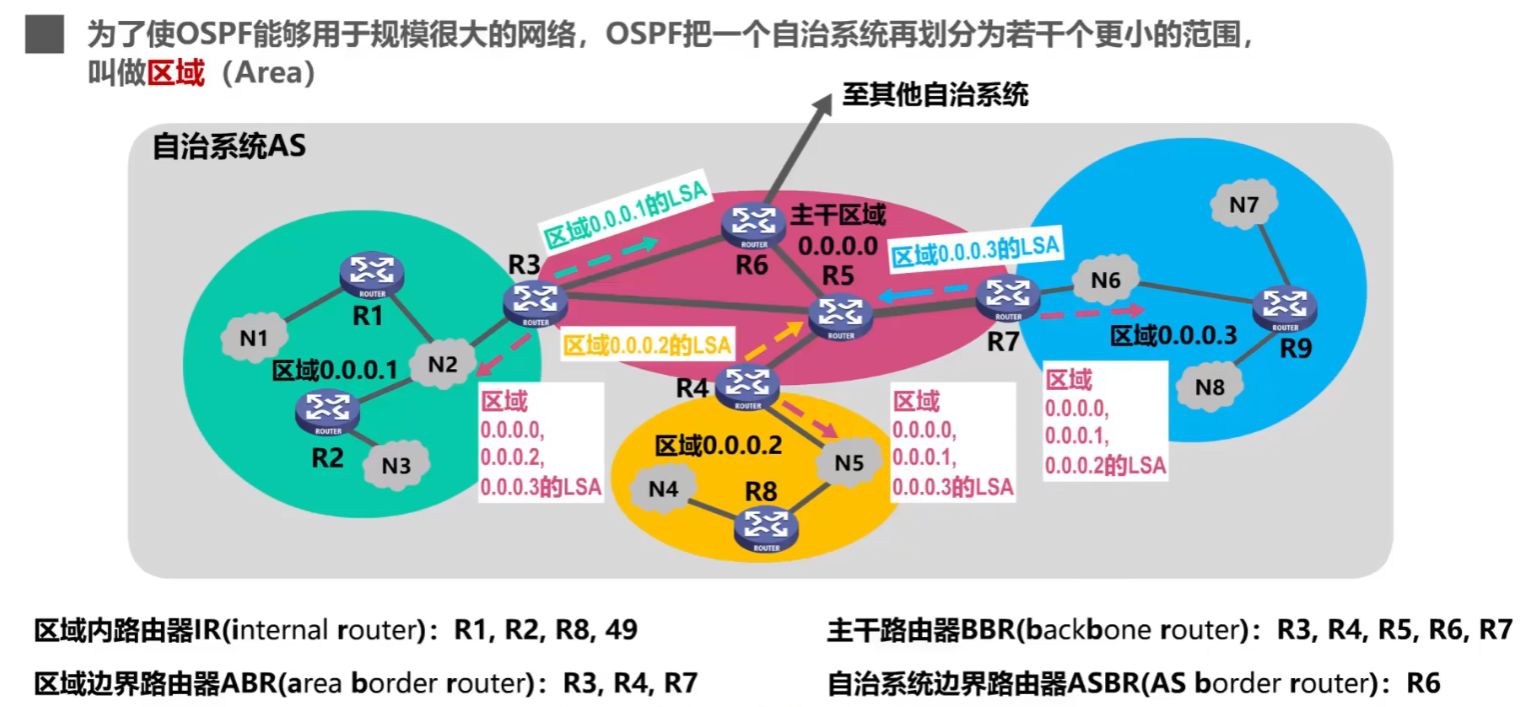
因为大型网络的【链路状态数据库LSDB】太多太大了!!!一个路由器根本存不下,而且洪泛的范围更大、压力更大了,所以需要在【AS自治系统】再再再进行【OSPF分区】!!!(当然,这样让OSPF协议更加复杂了)
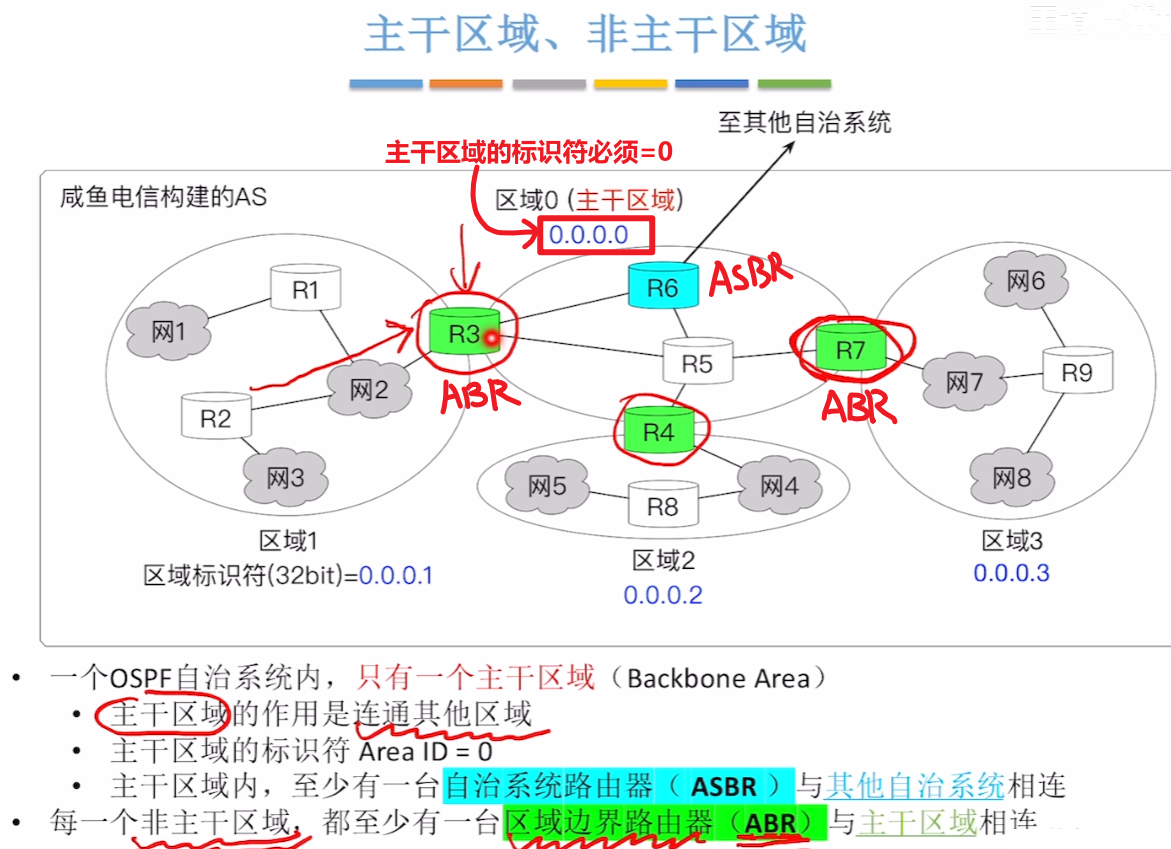
【分区规则】
- 其中一个OSPF自治系统里,只能有一个【主干区域Backbone Area】
- 【标识符Area ID】是:0
- 有一个【自治系统路由器ASBR】与外界链接
- 有多个【非主干区域】
- 都有各自的【标识符Area ID】
- 各个区域内 “洪泛” 信息不影响其他区域、整个自治系统
- 每个【非主干区域】至少一个跟主干区域连接的【区域边界路由器ABR】
- 其中各个【路由器】的职责
- 一共就4类(下图中省略了【主干路由器】):
- 【区域内路由器】、【区域边界路由器】、【主干路由器】、【自治系统边界路由器】
另外注意:看到图中,主干区域和非主干区域交接的【区域边界路由器】,也可以属于【主干路由器】
- 注意:【主干路由器】不等于【区域内路由器】,“区域内” 这个词特指 “非主干区域”,“主干路由器” 特指 “主干区域内的”
5、OSPF的【Type值】五类型
这里我对比了湖工大和咸鱼两人的讲述,发现湖工大解释的能马上理解OSPF五种类型的IP分组有什么意义,但是缺乏很多做题要会的细节;咸鱼讲得太多细节,全是讲例子流程然后开始念经,直接听根本听不下去,但是很细很细,所以我将从【宏观】到【微观】两个层面总结!!
- 首先,总共下面5种类型:

【宏观流程】
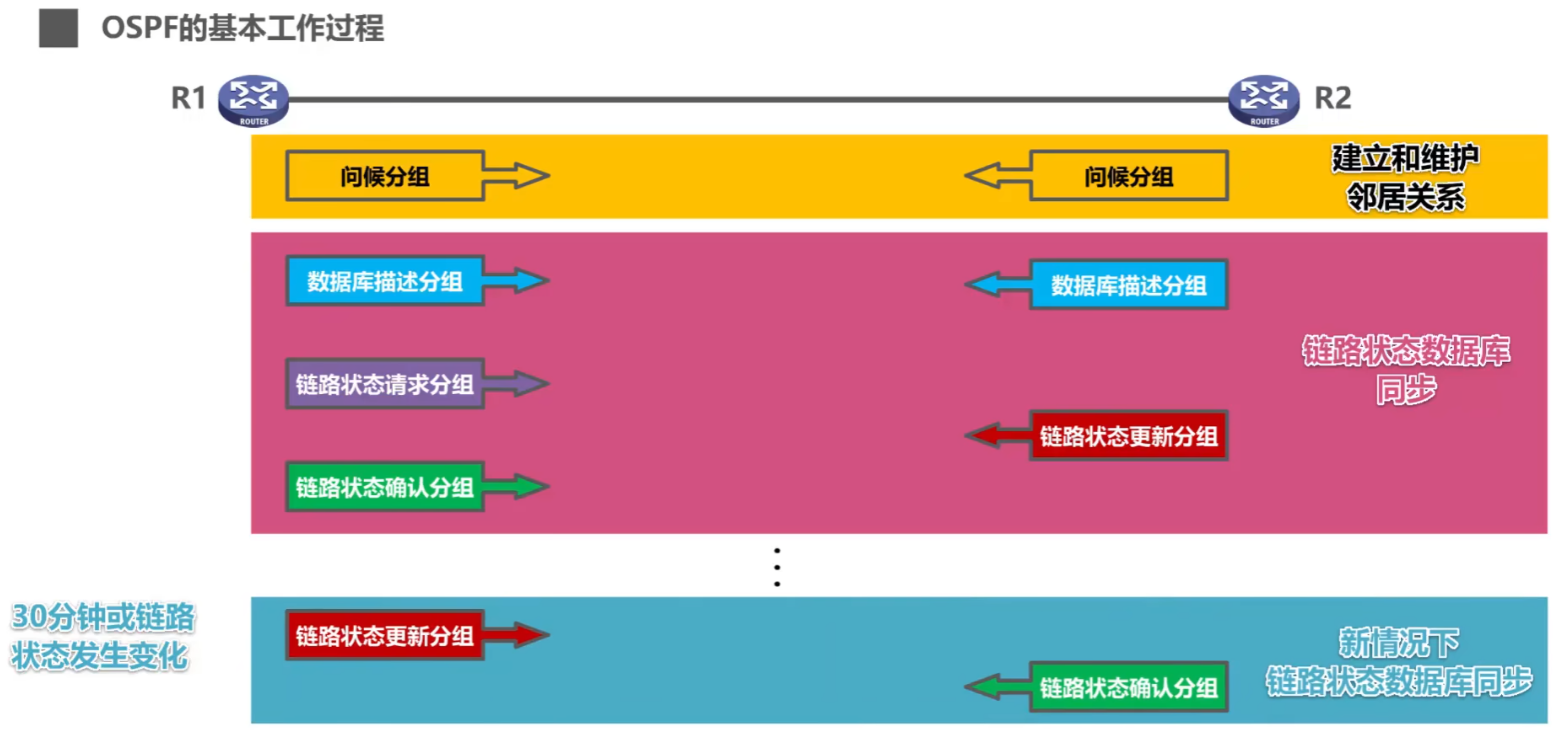
各自在OSPF工作流程的作用:(类似数据链路层的可靠传输的ACK机制一样)
- 【问候(hello)分组】:两个相邻路由器互相发送【问候分组】,以此建立邻居关系
- 【数据库描述(DD)分组】:两个邻居路由器互相告知对方自己的【LSDB】里有哪些【LSA】
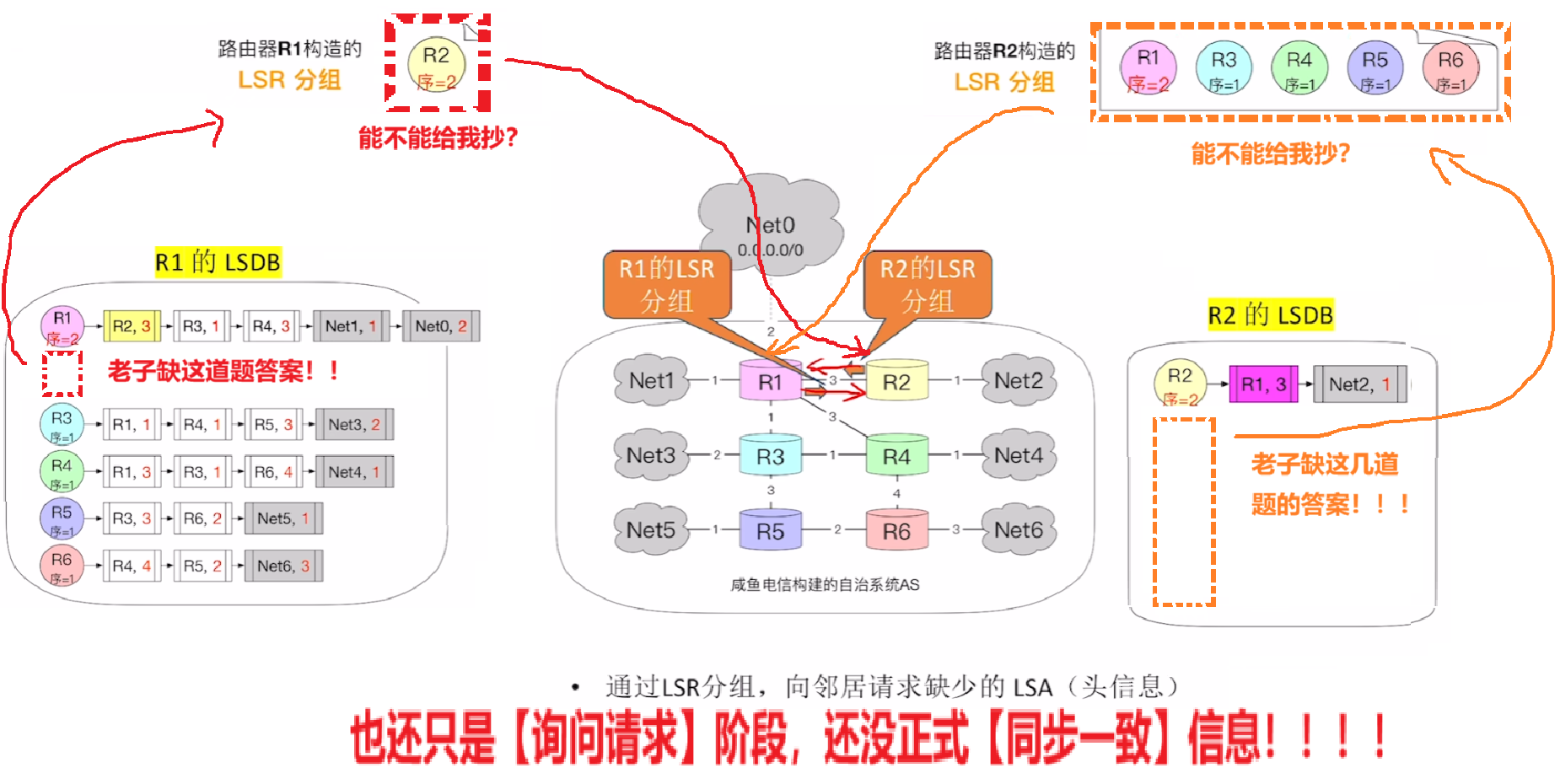
- 【链路状态请求(LSR)分组】:当收到【DD分组】后发现,自己的【LSDB】跟对方的比起来缺少部分【LSA】,就会向对方发出【LSR分组】请求补齐数据
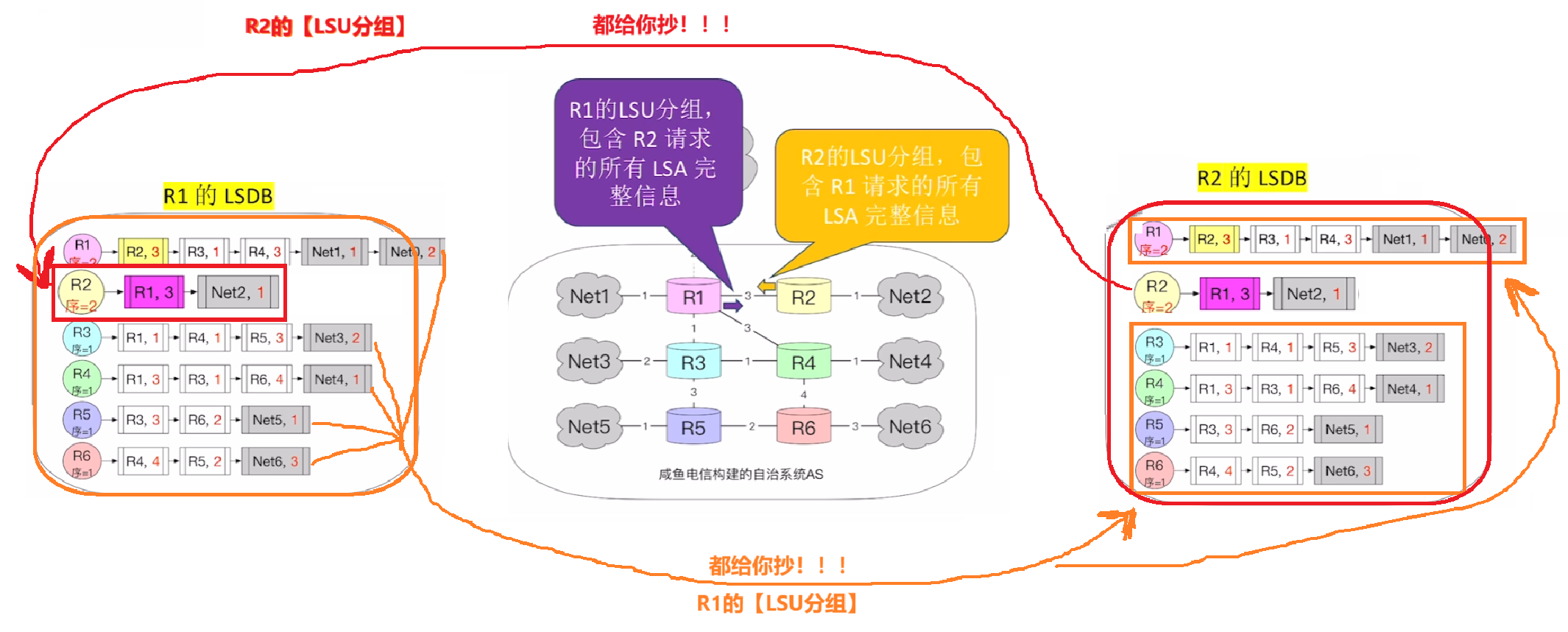
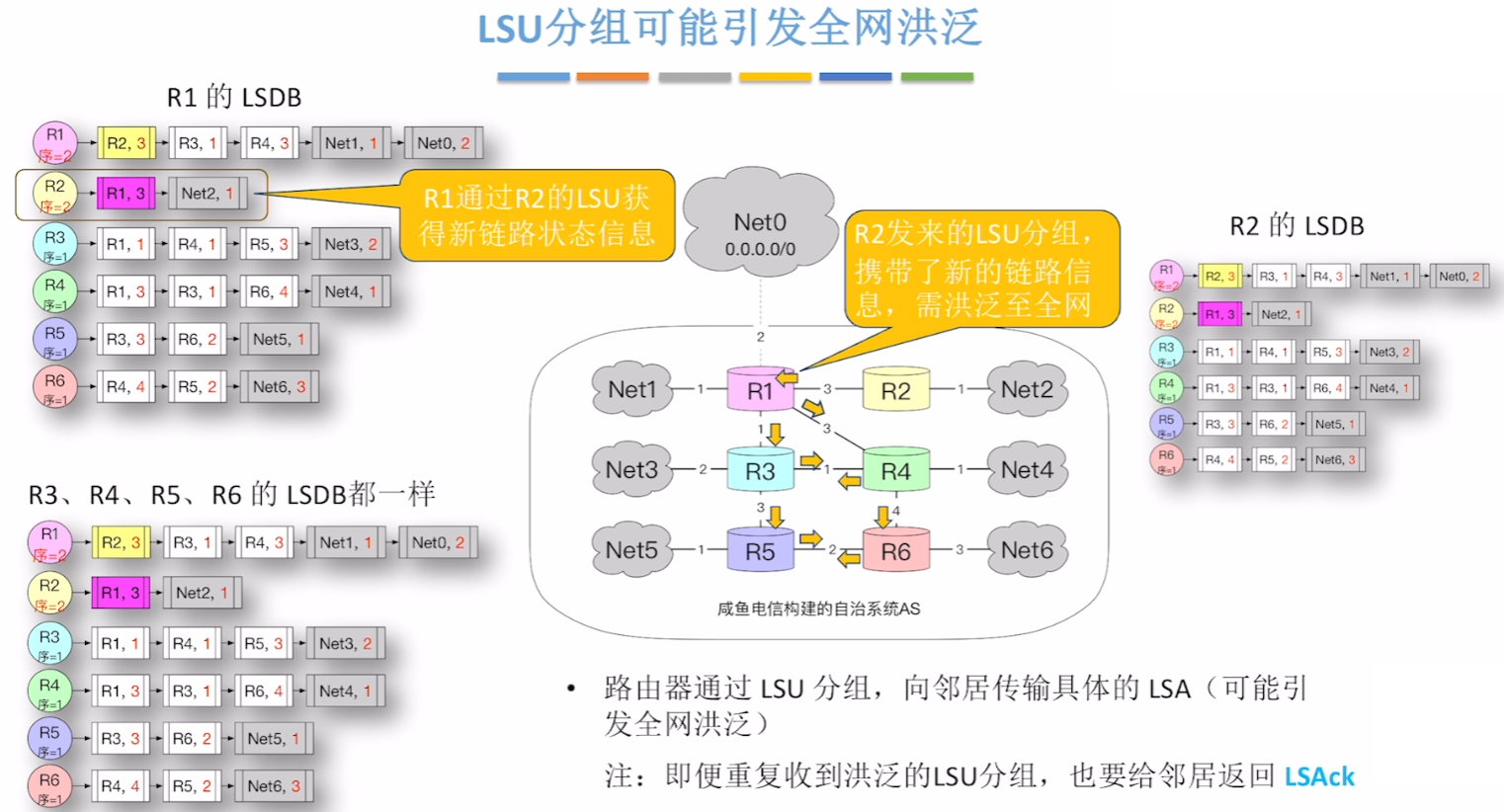
- 【链路状态更新(LSU)分组】:收到【LSR分组】的一方,会把对方所缺失、希望更新补齐的【LSA】数据项,封装在【LSU分组】返回响应
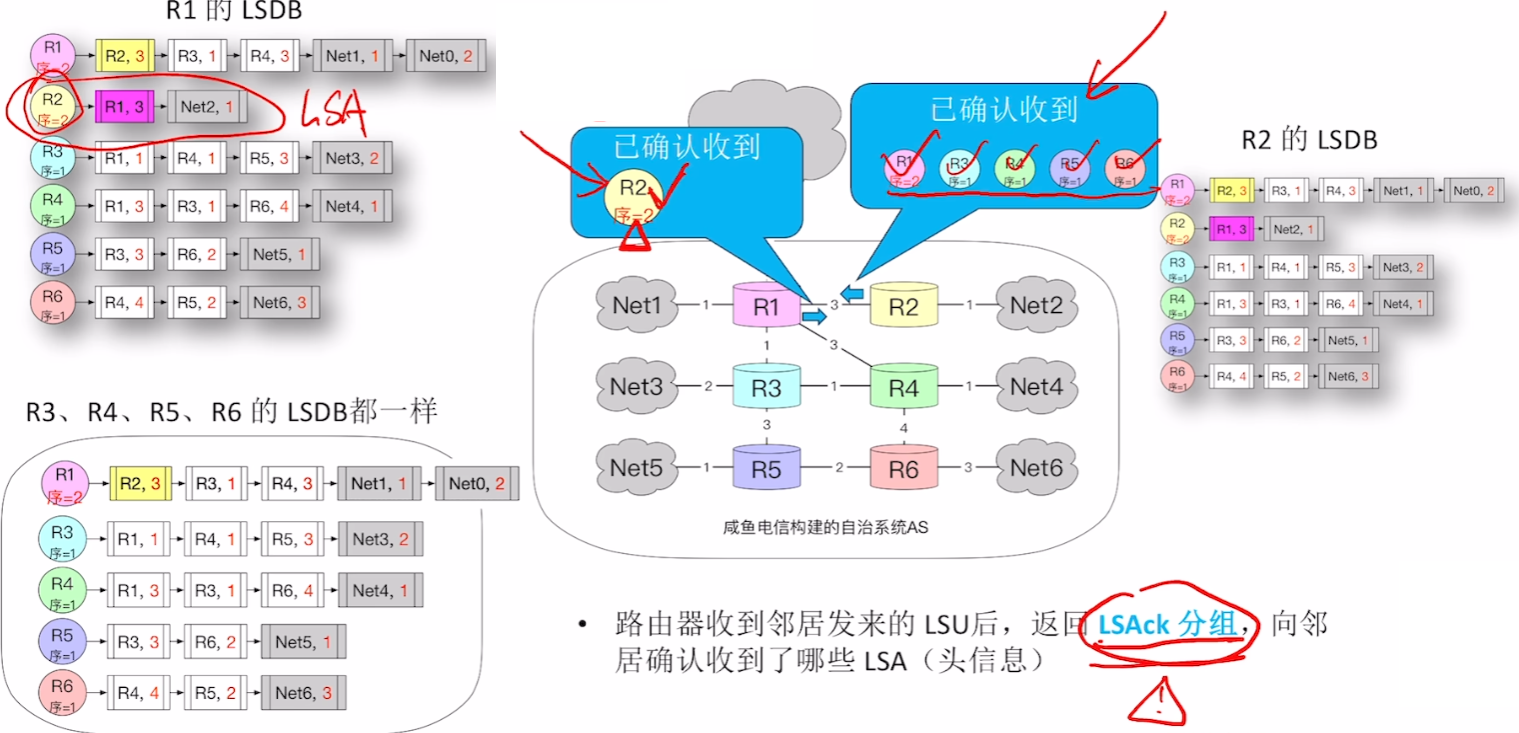
- 【链路状态确认(LSAck)分组】:收到【LSU分组】响应的一方拿到更新数据,补齐自己的【LSDB】,然后就会发出【LSAck分组】告知对方:“老子更新完毕,谢谢你!!”————此时双方的【LSDB(拓扑数据)】都达到一直同步!!!
- 而后期更新的阶段,则只需要发送【LSU】+【LSA】一来一回的分组了
- 【LSU】就是各个路由器采用【洪泛法】向其他邻居路由器发【自己更新的数据】,让各个路由器更新
- 【LSA】就是各个路由器返回:“收到”
【微观流程】
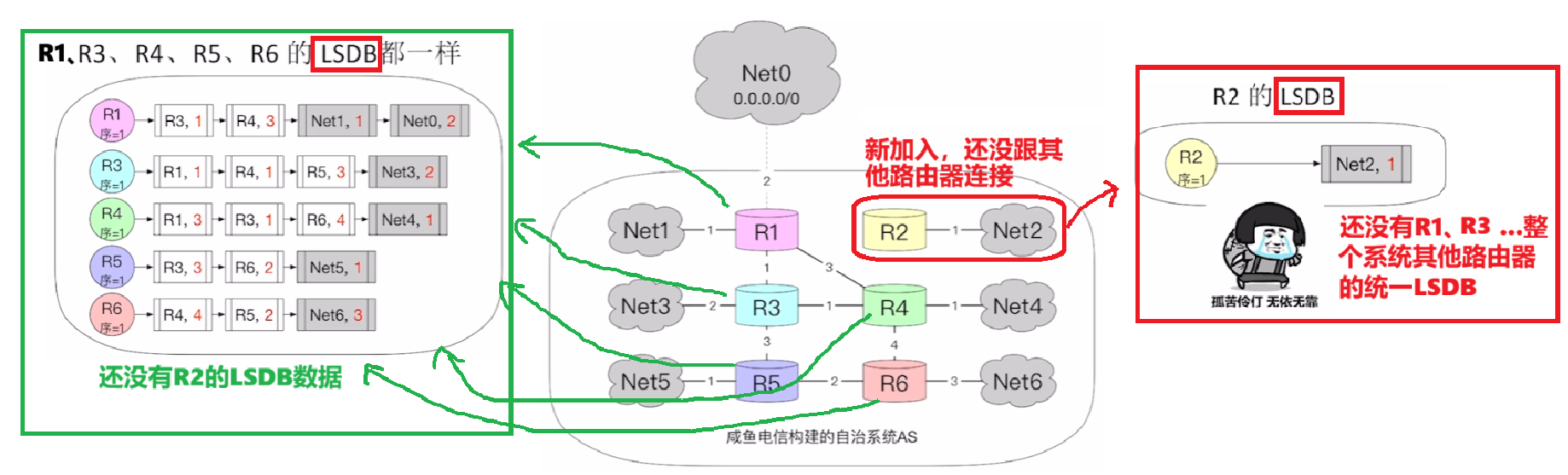
例子:一开始R1、R3、R4、R4、R5、R6都是已经达到收敛状态,大家的LSDB都完整一致包含整个系统的链路信息;而R2是新加入的路由器,还只有它自己的链路信息的LSDB
- 【Hello分组】
- 首先Hello分组的【运行机制】是:
- 1、【每隔10秒】各个路由器自动向邻居路由器发“问候Hello分组”
- 2、如果【超过40秒】没收到邻居的“问候Hello分组”,自动认定此邻居不可达,在LSDB里对应自己的那条LSA里删掉此邻居节点
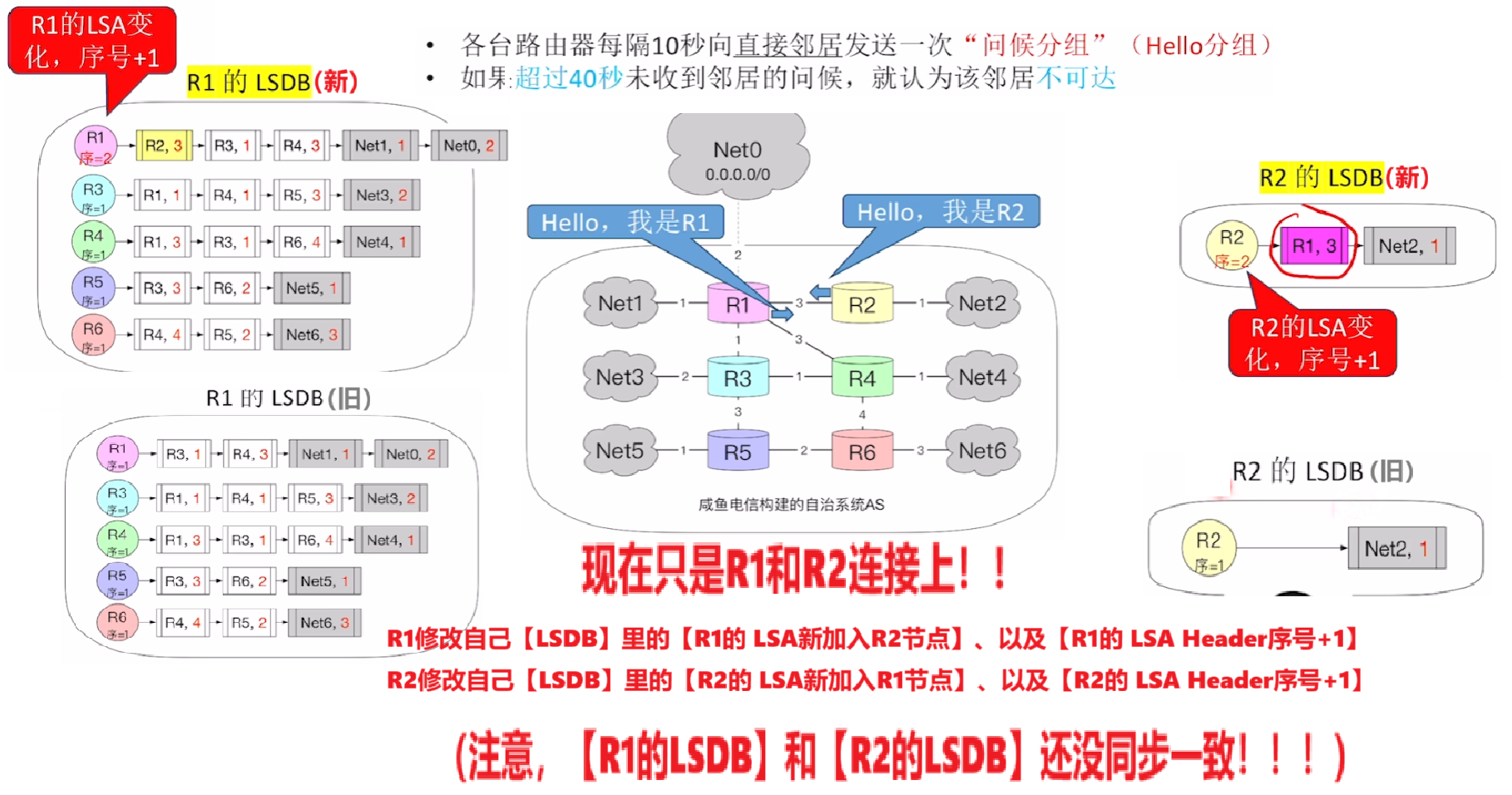
- 那么现在R1和R2连接上
- R1修改自己【LSDB】里的【R1的 LSA新加入R2节点】、以及【R1的 LSA Header序号+1】
- R2修改自己【LSDB】里的【R2的 LSA新加入R1节点】、以及【R2的 LSA Header序号+1】
- (注意,【R1的LSDB】和【R2的LSDB】还没同步一致!!!)
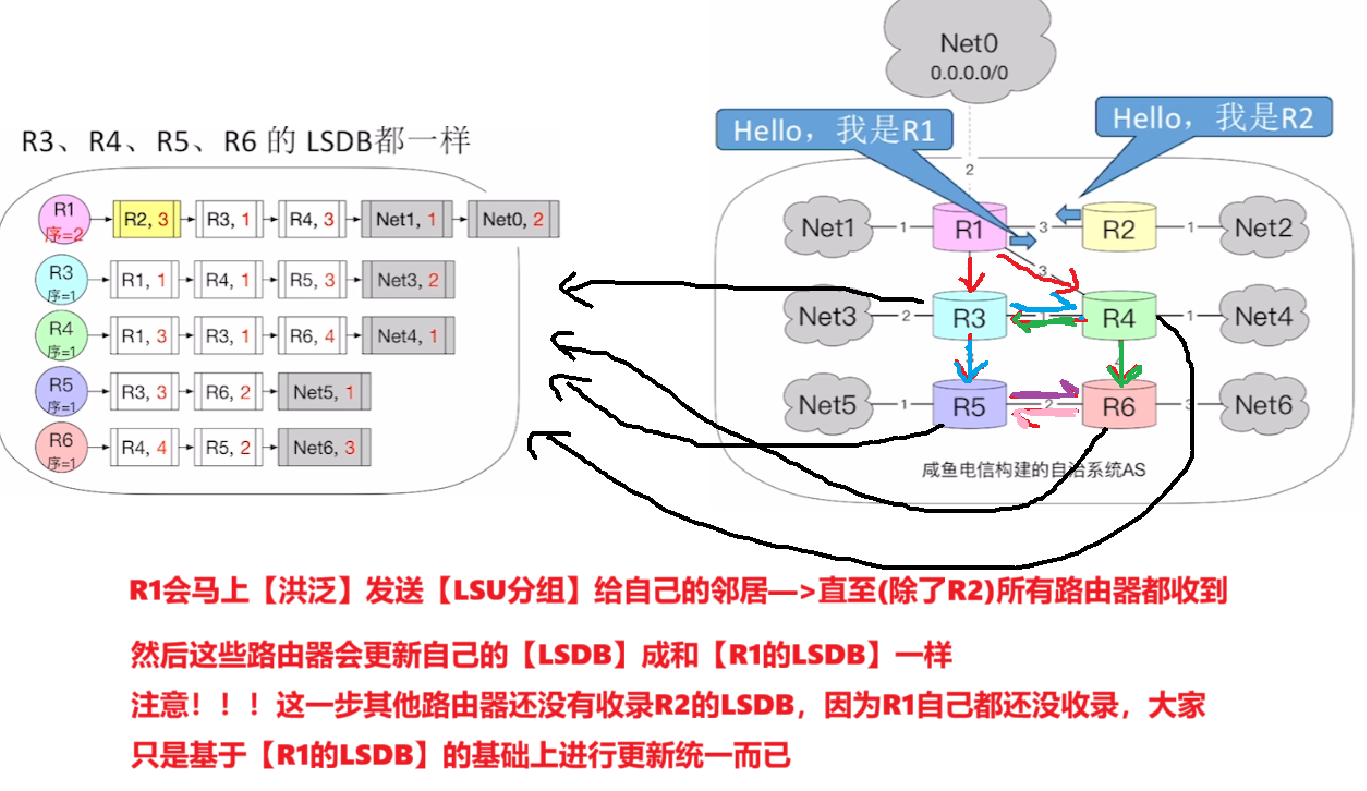
- 然后【R1】还会洪泛【LSU链路状态更新分组】给除了R2的所有路由器,为了让所有路由器把【LSDB】马上更新和【R1的LSDB】一模一样
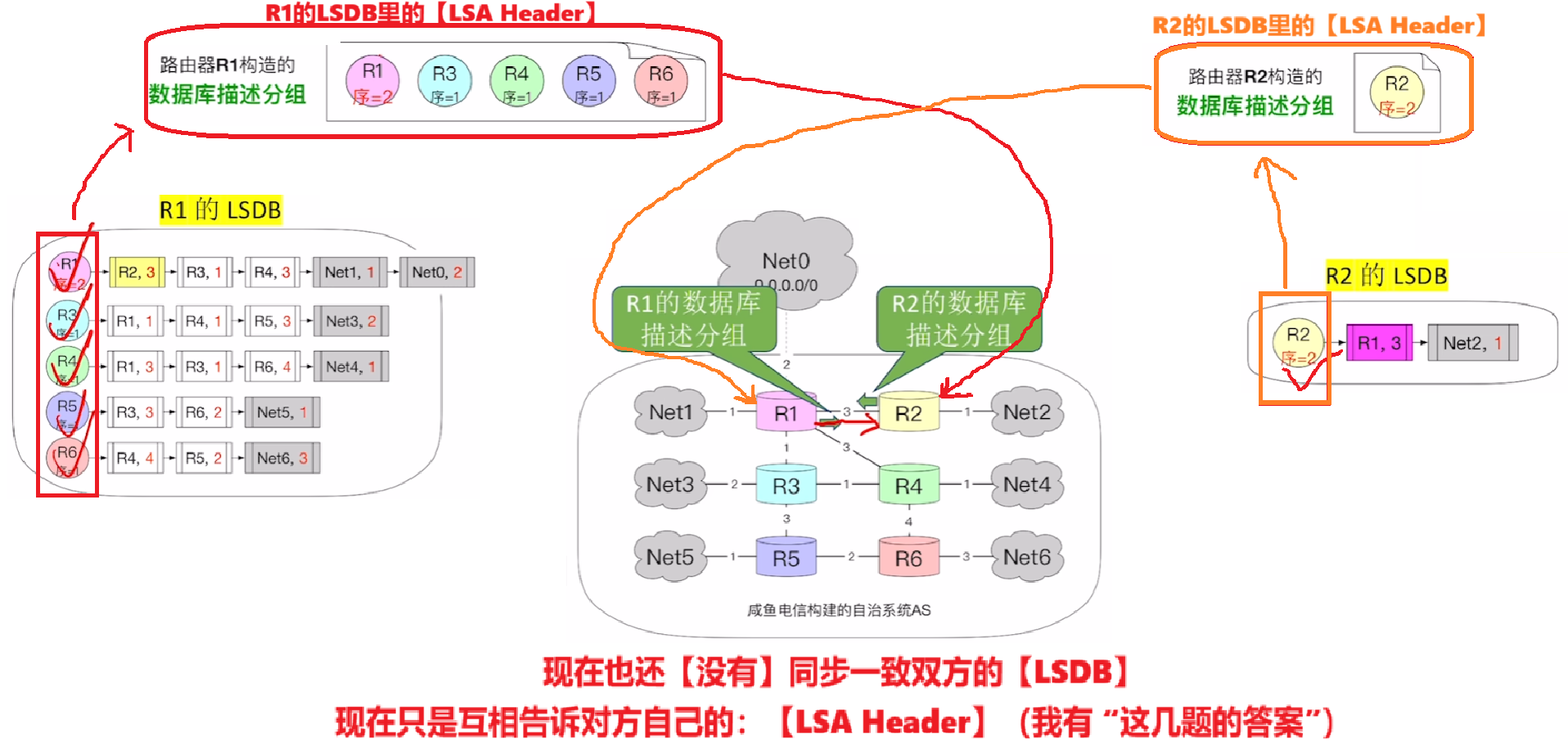
- 【DD分组】
- 现在是两个路由器【对比各自LSDB里的LSA Header是否一致,】
- 要互传的信息:
- 自己【LSDB】里的【LSA Header(LSA头信息)】
- 就是类似大家互相抄作业,A告诉B我有哪几题答案,B告诉A我有哪几题答案,彼此对比一下对方会的题里自己有没有缺的(但这个时候还没开始抄!!!)
- 【LSR分组】
- 现在是两个路由器【向对方索要自己LSDB里缺的LSA】
- 要互传的信息:
- 自己【LSDB】里没有、但是对方LSDB里有的【LSA Header(LSA头信息)】
- 【LSU分组】
- 所有路由器正式开始【同步一致LSDB】
- 要互传的信息:
- 把刚刚对方在【LSR分组】请求的:【自己有、对方缺的LSA】全给对方
- 而只要更新了【LSDB】的路由器,一定一定会马上从(除了入口的)其他所有出口发出【LSDB】,
- 从而实现一传十,十传百的现象,通过洪泛使得整个网络所有路由器迅速实现【LSDB的同步统一】,也就是【收敛】!!!
- 【LSAck分组】
- 收到【LSU】的路由器,返回【LSAck分组】意思是“收到了!”
- 如果长时间没收到【LSAck】,可以重新再发【LSU】,至于发几次才认定这个路由器坏了我们不用学
- 注意:就算收到重复的【LSU】,也必须回复响应【LSAck】