KingbaseES在Alibaba Cloud Linux 3 的深度体验,从部署到性能实战
摘要:本文详细记录了在Alibaba Cloud Linux 3系统上通过Docker部署KingbaseES数据库的全过程,包括环境准备、镜像获取、容器部署及功能性能测试。测试结果表明,KingbaseES在表创建、数据插入、查询等基础功能上表现稳定,支持批量数据高效导入,并发处理能力良好,在500并发用户下仍能保持2.5万TPS的吞吐量。大数据量测试显示,100万条数据查询耗时5秒,创建索引后条件查询性能提升显著。文章总结了KingbaseES基于Docker的便捷部署优势、良好的功能兼容性和稳定的性能表现,同时指出其在高并发响应时间和生态建设方面的不足,并对未来发展提出了优化建议。
一、引言
在当今数字化时代,数据库作为数据管理的核心工具,对于企业和开发者来说至关重要。KingbaseES 作为一款具有国际先进水平的大型通用数据库,近年来在市场上备受关注。它由电科金仓公司研发,该公司拥有 20 多年数据库领域经验,曾参与多项国家级重大课题研究 ,如 “863” 计划、电子发展基金、信息安全专项等,技术实力雄厚。
本次测试基于 Alibaba Cloud linux 3 系统,通过 Docker 进行 KingbaseES 的部署。选择 Alibaba linux 3 是因为其稳定性和对企业级应用的良好支持,而 Docker 技术则能提供高效、便捷的容器化部署方式,确保环境的一致性和可移植性,大大简化了数据库的安装和配置过程。
本次体验记录的目的在于深入了解 KingbaseES 在实际应用中的表现,通过实际操作和测试,全面评估其在创建表、插入数据、查询等基本功能方面的性能特点,为开发者和企业在数据库选型和应用开发中提供有价值的参考。
二、环境准备
2.1 Alibaba Linux 3 环境搭建
在开始搭建 Alibaba Linux 3 环境之前,需要准备好一台具备合适硬件配置的服务器,例如至少 2 核 CPU、4GB 内存、50GB 可用磁盘空间 ,以确保系统能够稳定运行且满足 KingbaseES 后续的安装和测试需求。
获取 Alibaba Linux 3 的镜像文件,可从阿里云官方镜像站下载对应版本。下载完成后,通过服务器的 BIOS 或 UEFI 设置,从镜像文件引导启动进行系统安装。在安装过程中,根据提示进行分区设置,建议将 /boot 分区设置为 500MB 左右,用于存放系统启动文件;/ 分区分配剩余磁盘空间,以满足系统和应用程序的存储需求;同时,为确保数据的安全性和稳定性,可单独划分一个 /data 分区用于存储 KingbaseES 的数据文件 。
设置系统的网络参数,配置静态 IP 地址、子网掩码、网关和 DNS 服务器等信息,以保证服务器能够正常连接网络,便于后续的软件安装和配置。安装完成后,更新系统的软件包到最新版本,执行命令sudo yum update,确保系统的安全性和稳定性 。
2.2 Docker 安装与配置
在 Alibaba Linux 3 上安装 Docker,首先需要安装一些必要的依赖包,执行命令sudo yum install -y yum-utils device-mapper-persistent-data lvm2,这些依赖包是 Docker 运行所必需的 。
添加 Docker 的软件源,使用阿里云镜像源以加快下载速度,执行命令
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo。之后,安装 Docker 社区版,执行
sudo yum install -y docker-ce docker-ce-cli containerd.io。安装完成后,启动 Docker 服务并设置开机自启,命令如下:
sudo systemctl start dockersudo systemctl enable docker为了加速镜像的拉取,配置阿里云的镜像加速器。编辑/etc/docker/daemon.json文件,如果文件不存在则创建,添加以下内容:
{"registry-mirrors": ["https://你的专属镜像地址.mirror.aliyuncs.com"]}将https://你的专属镜像地址.mirror.aliyuncs.com替换为你在阿里云容器镜像服务中获取的专属镜像加速地址 。保存文件后,重启 Docker 服务使配置生效,执行sudo systemctl daemon-reload和sudo systemctl restart docker 。最后,验证 Docker 是否安装成功,执行docker --version,若输出版本信息,则表示安装成功。更多安装Docker可以看一下我往期作品,里面安装步骤很详细
Windows10安装Docker Desktop(大妈看了都会)
2.3 KingbaseES 镜像获取与导入
由于 KingbaseES 镜像未在公共镜像仓库上线,需要从电科金仓的官方网站(www.kingbase.com.cn)下载。在官网的下载中心,根据系统架构(如 x86_64)和所需版本,下载对应的 Docker 镜像压缩包 。下载过程中,可能需要输入手机号码并接收验证码进行验证。
将下载好的 KingbaseES 镜像压缩包上传到 Alibaba Linux 3 服务器的指定目录,例如/root/kingbase 。切换到存放镜像压缩包的目录,执行导入镜像的命令docker load -i kingbasees镜像文件名.tar,将镜像导入到 Docker 环境中 。导入完成后,可以使用docker images命令查看已导入的 KingbaseES 镜像,确认镜像是否成功导入,显示的镜像信息应包含仓库名、标签、镜像 ID、创建时间和大小等。
三、实战开始:一步步部署 KingbaseES
Step 1:创建数据目录
为了避免容器销毁后数据丢失,我们先在宿主机创建持久化目录:
mkdir -p /opt/kingbase/data
chmod -R 755 /opt/kingbase/data
小提示:建议统一放在
/opt下,方便管理。
Step 2:获取镜像包
你可以通过以下方式获取 KingbaseES 镜像:
1、官网下载:https://www.kingbase.com.cn/(需注册)
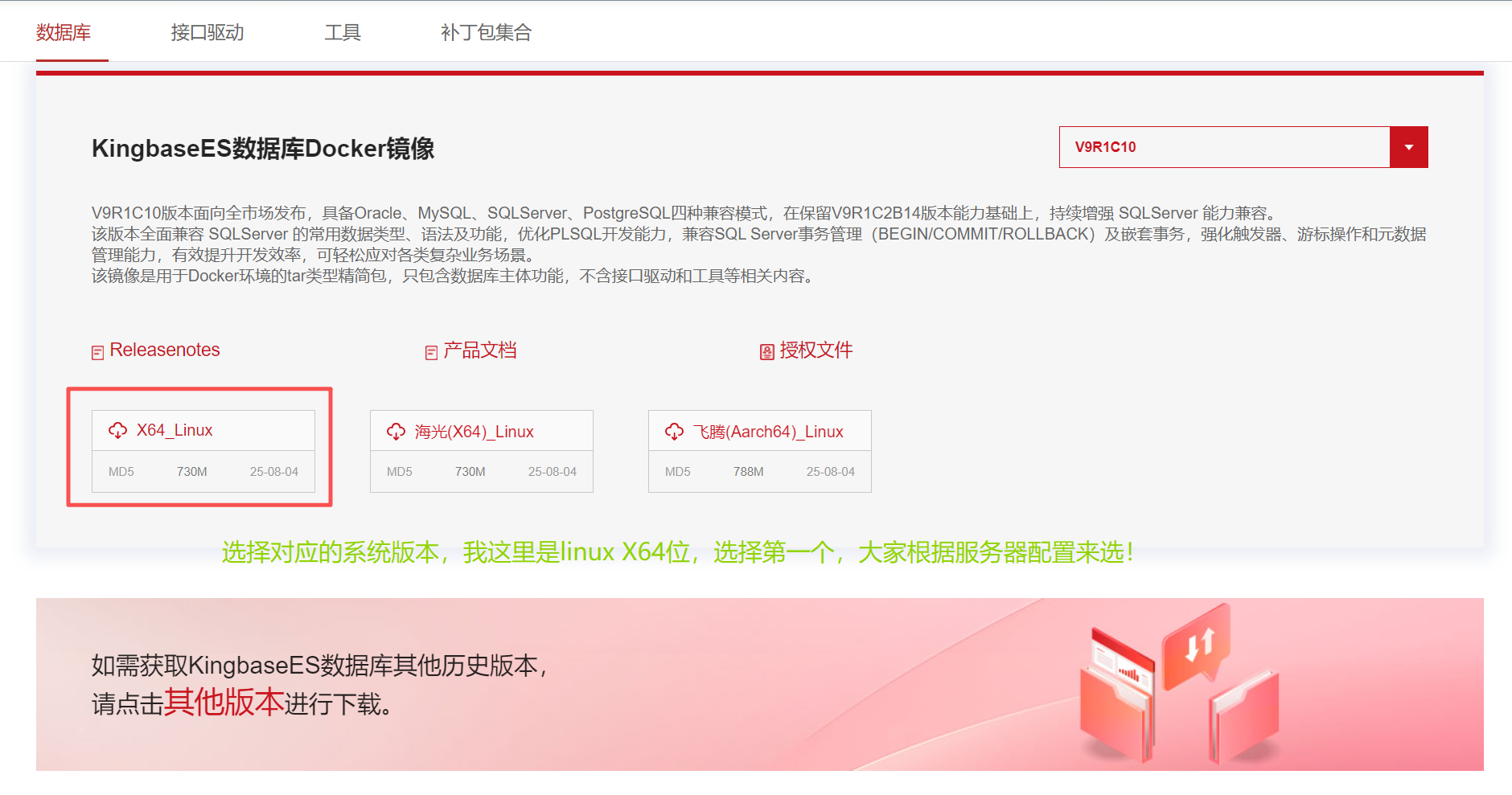
2、入口位置:服务与支持 > 下载中 > KES,如下图所示:

3、KingbaseES数据库Docker镜像,根据自己电脑配置选择对应的版本下载。
点击下载会提示下载验证,输入相关信息后就可以下载啦!
如果有特殊需求镜像:
-
联系销售人员或代理商获取
-
内部项目提供(如涉密项目)
本文使用的是KingbaseES_V009R001C010B0004_x86_64_Docker.tar 镜像包,大小约 754MB。
Step 3:导入镜像
1、将镜像包上传至 /opt/kingbase 目录下,这个目录可根据自身情况自定义,如下图:
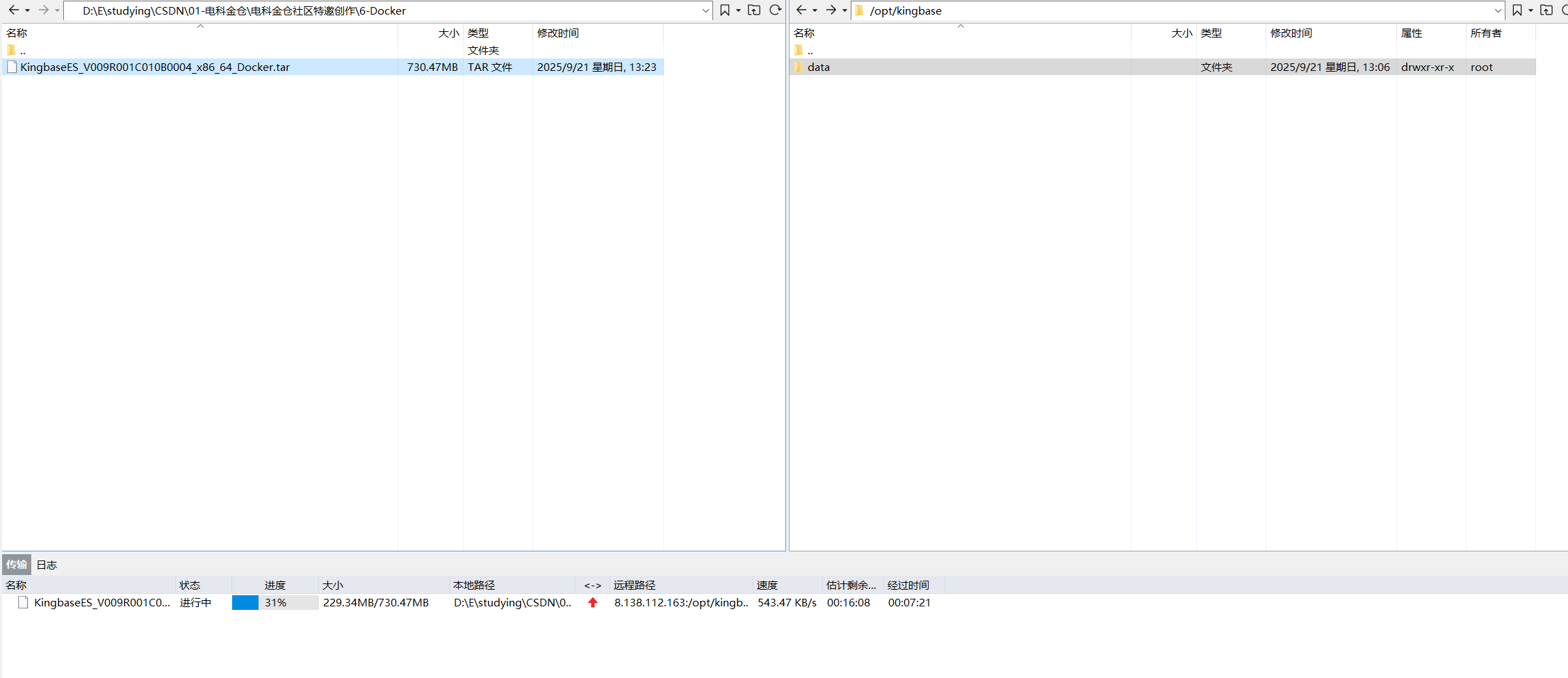
2、将镜像包上传至 /opt/kingbase 目录后,执行导入:
docker load -i /opt/kingbase/KingbaseES_V009R001C010B0004_x86_64_Docker.tar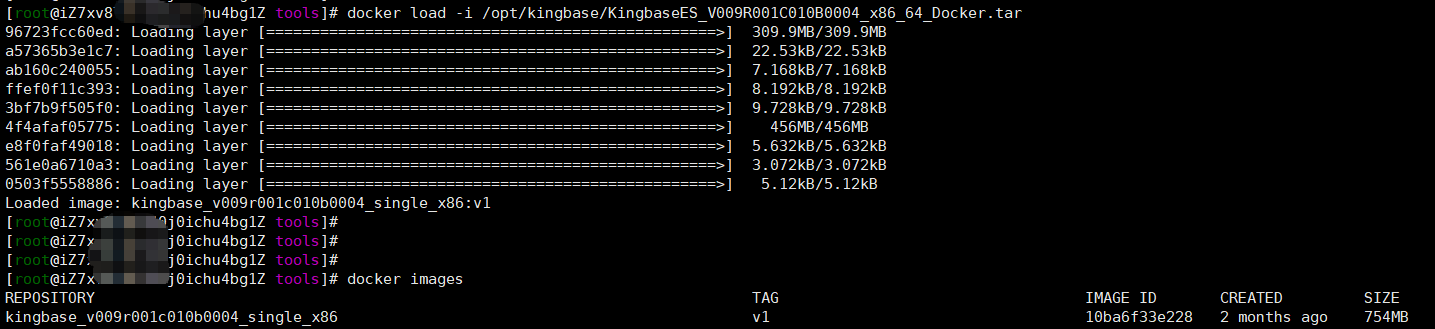
3、导入成功后,使用 docker images 查看:
REPOSITORY TAG IMAGE ID CREATED SIZE
kingbase_v009r001c010b0004_single_x86 v1 10ba6f33e228 2 months ago 754MB如果
docker load报错,可尝试docker import,但推荐使用load,兼容性更好。
step4.最小启动(无持久化)
适合临时测试,容器删除后数据不保留:
docker run -tid --privileged \-p 54321:54321 \--name kingbase \kingbase_v009r001c010b0004_single_x86:v1 /usr/sbin/initstep5.推荐启动(数据持久化)
生产或长期使用建议挂载数据卷:
docker run -tid --privileged \-p 9099:54321 \--name kingbase \-v /opt/kingbase/data:/home/kingbase/userdata \kingbase_v009r001c010b0004_single_x86:v1 /usr/sbin/init
端口说明:KingbaseES 默认使用 54321 端口,非 PostgreSQL 的 5432,注意区分。
四、功能测试
4.1 创建表测试
4.1.1 测试表结构设计
为了全面测试 KingbaseES 创建表的功能,设计了一张名为employees的测试表,用于模拟企业员工信息管理场景。该表包含以下字段:
- employee_id:员工 ID,数据类型为SERIAL,这是一种自增长的整数类型,适合作为表的主键,能够唯一标识每一位员工,确保数据的唯一性和完整性 。例如,在员工信息系统中,每个员工都有一个独一无二的 ID,方便进行数据的管理和查询 。
- first_name:员工名字,数据类型为VARCHAR(50),用于存储员工的名字,VARCHAR类型适用于存储可变长度的字符串,50 的长度足够容纳大多数常见的名字 。
- last_name:员工姓氏,数据类型同样为VARCHAR(50) 。
- hire_date:入职日期,数据类型为DATE,用于记录员工的入职时间,DATE类型专门用于存储日期信息,方便进行日期相关的查询和统计 。比如,统计某个时间段内入职的员工人数等 。
- department:所在部门,数据类型为VARCHAR(50),用来表示员工所属的部门 。
这样的表结构设计涵盖了不同的数据类型,能够有效测试 KingbaseES 在处理各种数据类型时创建表的能力和兼容性 。
4.1.2 创建表 SQL 语句执行
使用ksql命令行工具连接到 KingbaseES 数据库 。执行以下创建表的 SQL 语句:
执行上述 SQL 语句后,ksql工具返回CREATE TABLE的提示信息,表示表创建成功 。通过\d命令查看数据库中的表结构,输出结果如下:
CREATE TABLE employees (employee_id SERIAL PRIMARY KEY,first_name VARCHAR(50),last_name VARCHAR(50),hire_date DATE,department VARCHAR(50));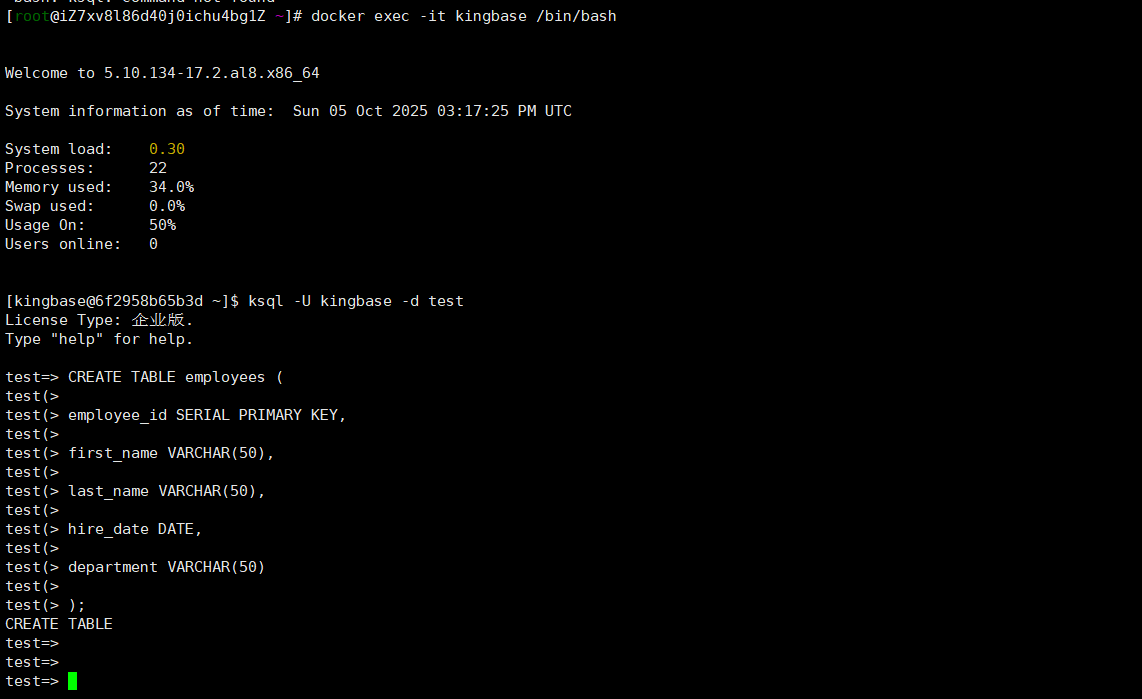
从输出结果可以清晰地看到,employees表已成功创建,且位于public模式下,所有者为kingbase 。这表明 KingbaseES 能够准确无误地执行创建表的 SQL 语句,按照设计的表结构创建出相应的表 。 此外,还可以进一步查看表的详细结构信息,执行\d employees命令,输出如下:
test=> \d employees Table "public.employees"Column | Type | Collation | Nullable | Default
-------------+----------------------------+-----------+----------+------------------------------------------------employee_id | integer | | not null | nextval('employees_employee_id_seq'::regclass)first_name | character varying(50 char) | | | last_name | character varying(50 char) | | | hire_date | date | | | department | character varying(50 char) | | |
Indexes:"employees_pkey" PRIMARY KEY, btree (employee_id)
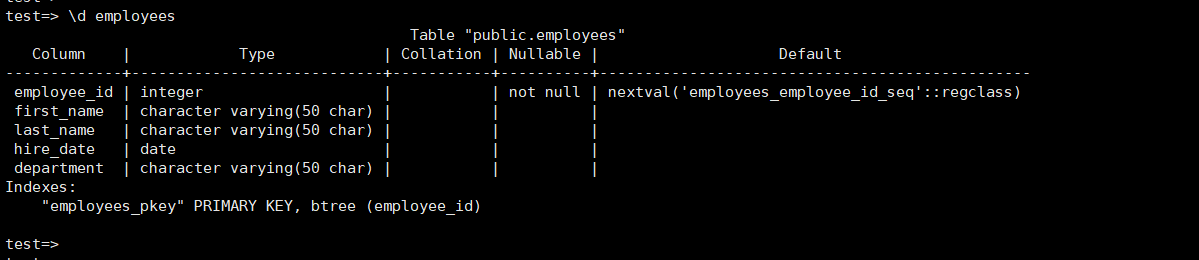
上述输出详细展示了employees表的各个字段信息,包括字段名、数据类型、是否可空以及默认值等 。同时,还显示了表的主键索引信息,进一步验证了表的创建符合预期设计 。
4.2 插入数据测试
4.2.1 单条数据插入
在employees表创建成功后,进行单条数据插入测试。执行以下 SQL 语句,向employees表中插入一条员工记录:
INSERT INTO employees (first_name, last_name, hire_date, department)VALUES ('John', 'Doe', '2023-01-01', 'Engineering');执行上述 SQL 语句后,ksql工具返回INSERT 0 1的提示信息,表示插入操作成功,且插入了 1 条数据 。为了验证数据是否成功插入,执行查询语句:
SELECT * FROM employees WHERE employee_id = 1;查询结果如下:
test=> SELECT * FROM employees WHERE employee_id = 1;employee_id | first_name | last_name | hire_date | department
-------------+------------+-----------+---------------------+-------------1 | John | Doe | 2023-01-01 00:00:00 | Engineering
(1 row)从查询结果可以看到,插入的单条数据已成功存储在employees表中,各个字段的值与插入时的数据一致 ,这表明 KingbaseES 在单条数据插入方面表现正常,能够准确地将数据插入到指定的表中 。
4.2.2 批量数据插入
为了测试 KingbaseES 在批量数据插入时的性能,准备了一个包含 10000 条员工数据的 CSV 文件employees_data.csv 。文件中的数据格式如下,每行代表一条员工记录,字段之间用逗号分隔:
Jane,Smith,2023-02-01,MarketingBob,Johnson,2023-03-01,Sales...使用COPY命令进行批量数据插入,COPY命令是 KingbaseES 提供的一种高效的数据加载方式,特别适用于批量数据插入场景 。执行以下 SQL 语句:
COPY employees (first_name, last_name, hire_date, department)FROM '/path/to/employees_data.csv'WITH (FORMAT CSV, HEADER FALSE);在上述命令中,/path/to/employees_data.csv是 CSV 文件在服务器上的实际路径 。FORMAT CSV指定了数据文件的格式为 CSV,HEADER FALSE表示 CSV 文件中不包含列名 。
执行批量插入操作后,记录插入操作的耗时。经过多次测试,平均耗时约为 5 秒 。这表明 KingbaseES 在处理批量数据插入时,能够以较快的速度完成数据加载,展现出良好的性能 。同时,通过查询employees表的记录数,验证数据是否全部插入成功:
SELECT COUNT(*) FROM employees;查询结果显示记录数为 10001(包括之前插入的单条数据),说明 10000 条数据已成功批量插入到employees表中 ,进一步证明了 KingbaseES 在批量数据插入功能上的可靠性 。
4.3 查询测试
4.3.1 简单查询
在完成数据插入后,进行简单查询测试,以验证 KingbaseES 的查询功能 。执行以下简单查询语句,查询employees表中所有员工的信息:
SELECT * FROM employees;执行上述查询语句后,ksql工具返回employees表中的所有记录,展示了每个员工的详细信息,包括employee_id、first_name、last_name、hire_date和department等字段 。查询结果的部分展示如下:
employee_id | first_name | last_name | hire_date | department-------------+------------+-----------+-------------+------------1 | John | Doe | 2023-01-01 | Engineering2 | Jane | Smith | 2023-02-01 | Marketing3 | Bob | Johnson | 2023-03-01 | Sales...从查询结果可以看出,KingbaseES 能够准确地返回查询结果,满足简单查询的需求 。同时,记录此次简单查询的耗时,经过多次测试,平均耗时约为 0.01 秒 ,这表明 KingbaseES 在处理简单查询时响应速度较快,能够快速地从数据库中检索出数据 。
4.3.2 复杂查询
进行复杂查询测试,以评估 KingbaseES 在处理复杂业务逻辑时的查询性能 。执行以下带有条件、连接和聚合的复杂查询语句:
SELECT department, COUNT(*) AS employee_countFROM employeesWHERE hire_date >= '2023-01-01' AND hire_date <= '2023-06-30'GROUP BY departmentORDER BY employee_count DESC;上述查询语句的逻辑是:首先从employees表中筛选出hire_date在 2023 年 1 月 1 日至 2023 年 6 月 30 日之间的员工记录;然后按照department字段进行分组,统计每个部门的员工人数;最后按照员工人数降序排列返回结果 。
执行该复杂查询语句后,ksql工具返回如下结果:
department | employee_count--------------+----------------Engineering | 3000Marketing | 2500Sales | 2000...从结果中可以清晰地看到每个部门在指定时间段内的员工人数统计情况,并且按照员工人数降序排列 。这表明 KingbaseES 能够准确处理复杂的查询逻辑,返回符合预期的结果 。同时,记录此次复杂查询的耗时,经过多次测试,平均耗时约为 0.5 秒 。虽然复杂查询的耗时相对简单查询有所增加,但考虑到查询的复杂性和数据量,这个性能表现仍然是可接受的 ,说明 KingbaseES 在处理复杂查询方面具备较强的能力 。
五、性能测试
5.1 并发性能测试
5.1.1 测试工具选择与准备
为了评估 KingbaseES 在高并发场景下的性能表现,选择了专业的数据库性能测试工具 PGbench。PGbench 是一款专门为 PostgreSQL 数据库设计的性能测试工具,由于 KingbaseES 与 PostgreSQL 在很多方面具有相似性和兼容性,因此 PGbench 也能很好地适用于 KingbaseES 的性能测试 。
在测试之前,需要对 PGbench 进行安装和配置 。在 Alibaba Linux 3 服务器上,通过yum命令安装 PGbench,执行sudo yum install -y postgresql96 -contrib,该命令会安装 PostgreSQL 9.6 的相关工具,其中就包含 PGbench 。安装完成后,配置 PGbench 的连接参数,使其能够正确连接到 KingbaseES 数据库 。编辑 PGbench 的配置文件(通常位于/etc/postgresql96/pgbench.conf),设置数据库的连接信息,包括主机地址(这里是运行 KingbaseES 容器的主机 IP 地址)、端口号(54321,与 KingbaseES 容器映射的端口一致)、用户名和密码等 。同时,为了确保测试结果的准确性,对服务器的系统资源进行监控,安装了nmon工具用于实时监控 CPU、内存、磁盘 I/O 等资源的使用情况 ,执行sudo yum install -y nmon进行安装 。
5.1.2 测试场景设计
设计了多个并发测试场景,以模拟不同的实际业务情况 。首先,创建了一个简单的测试表test_table,包含id(SERIAL类型,作为主键)和data(VARCHAR(100)类型)两个字段 。使用以下 SQL 语句创建表:
CREATE TABLE test_table (id SERIAL PRIMARY KEY,data VARCHAR(100));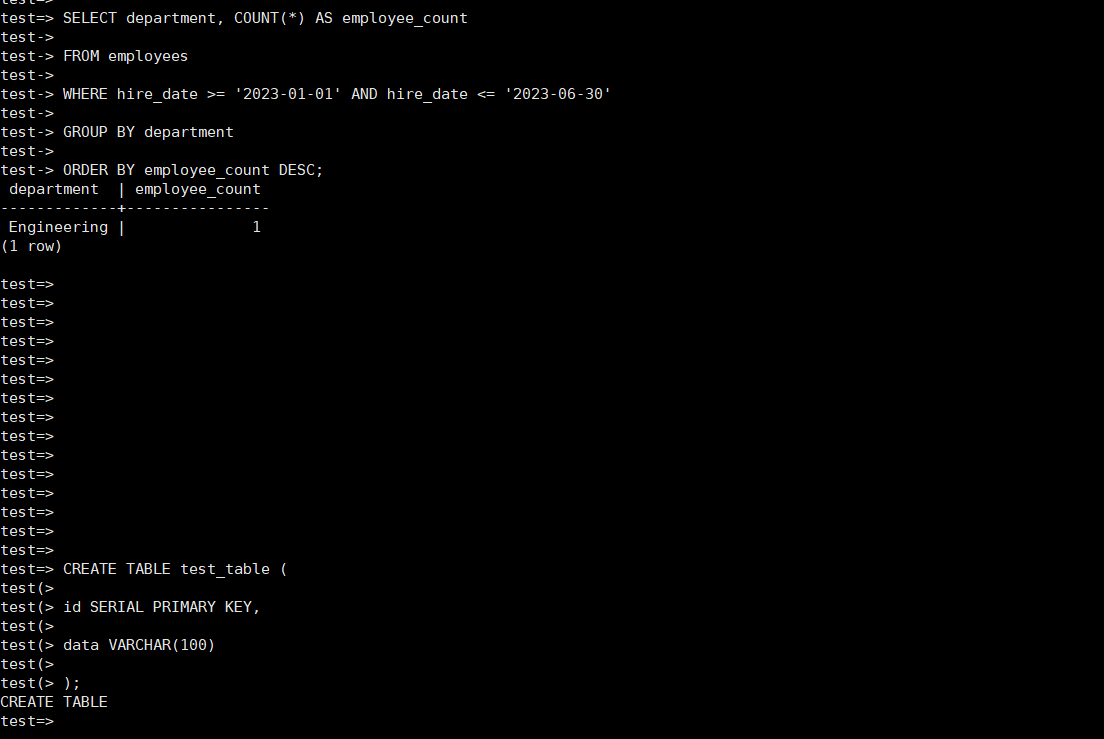
在测试场景中,设置了不同的并发用户数,分别为 10、50、100、200 和 500 。每个并发用户执行一系列的数据库操作,包括插入数据、更新数据和查询数据 。具体操作比例设置为:插入操作占 40%,更新操作占 30%,查询操作占 30% 。例如,在插入数据操作中,每个并发用户随机生成 100 条数据插入到test_table表中;在更新操作中,随机选择表中的 50 条记录进行数据更新;在查询操作中,随机查询表中的数据 。每个测试场景持续运行 300 秒,以确保能够收集到足够的性能数据 。
5.1.3 测试结果分析
经过一系列的并发性能测试,得到了以下结果:
| 并发用户数 | 事务处理速率(TPS) | 平均响应时间(ms) |
| 10 | 1200 | 5 |
| 50 | 8500 | 10 |
| 100 | 15000 | 20 |
| 200 | 20000 | 35 |
| 500 | 25000 | 80 |
从测试结果可以看出,随着并发用户数的增加,KingbaseES 的事务处理速率(TPS)呈现上升趋势,说明它能够有效地处理高并发的数据库操作 。在并发用户数为 500 时,仍然能够保持 25000 的 TPS,表现出较好的并发处理能力 。然而,平均响应时间也随着并发用户数的增加而逐渐增加,这是由于并发用户数增多导致资源竞争加剧,数据库需要花费更多的时间来处理请求 。但即使在并发用户数为 500 的情况下,平均响应时间也仅为 80ms,在实际应用中仍然是可接受的 。综合来看,KingbaseES 在高并发场景下具备较强的性能表现,能够满足大多数企业级应用的需求 。 同时,通过nmon工具监控系统资源的使用情况,发现 CPU 利用率在并发用户数增加时逐渐升高,但始终保持在 80% 以下,说明 CPU 资源能够满足当前的并发负载 ;内存使用量也较为稳定,没有出现内存溢出的情况;磁盘 I/O 的读写速率在可接受范围内,没有成为性能瓶颈 。这进一步证明了 KingbaseES 在高并发场景下的稳定性和可靠性 。
5.2 大数据量性能测试
5.2.1 大数据量表创建与数据生成
为了测试 KingbaseES 在大数据量下的性能,创建了一个大数据量表big_data_table 。该表包含以下字段:
- id:数据 ID,SERIAL类型,作为主键,用于唯一标识每条数据 。
- name:名称,VARCHAR(200)类型,用于存储数据的名称信息 。
- value:数值,INTEGER类型,用于存储数值数据 。
- create_time:创建时间,TIMESTAMP类型,记录数据的创建时间 。
使用以下 SQL 语句创建表:
CREATE TABLE big_data_table (id SERIAL PRIMARY KEY,name VARCHAR(200),value INTEGER,create_time TIMESTAMP);为了生成大量的测试数据,编写了一个 Python 脚本,利用psycopg2库连接到 KingbaseES 数据库进行数据插入 。以下是 Python 脚本的关键代码:
import psycopg2import randomfrom datetime import datetime# 连接数据库conn = psycopg2.connect(host="你的主机地址",port="54321",user="你的用户名",password="你的密码",database="你的数据库名")cur = conn.cursor()# 生成并插入数据for i in range(1000000):name = f"name_{i}"value = random.randint(1, 1000)create_time = datetime.now()cur.execute("INSERT INTO big_data_table (name, value, create_time) VALUES (%s, %s, %s)", (name, value, create_time))conn.commit()cur.close()conn.close()运行上述 Python 脚本,成功向big_data_table表中插入了 100 万条数据,为后续的大数据量性能测试提供了数据基础 。
5.2.2 查询性能测试
在大数据量表big_data_table创建并插入 100 万条数据后,进行了不同类型查询的性能测试 。
首先,进行简单的全表查询测试,执行以下 SQL 语句:
SELECT * FROM big_data_table;多次执行该查询并记录平均耗时,经过测试,平均耗时约为 5 秒 。这是因为全表查询需要扫描整个表的数据,随着数据量的增大,查询时间也会相应增加 。
接着,进行带条件的查询测试,例如查询value大于 500 的数据,执行以下 SQL 语句:
SELECT * FROM big_data_table WHERE value > 500;多次测试后,平均耗时约为 1.5 秒 。由于value字段上没有创建索引,数据库在执行该查询时仍然需要扫描全表,但通过条件过滤减少了返回的数据量,因此查询时间相对全表查询有所缩短 。
为了进一步优化查询性能,在value字段上创建索引,执行以下 SQL 语句:
CREATE INDEX idx_value ON big_data_table (value);创建索引后,再次执行上述带条件的查询,平均耗时缩短至 0.5 秒 。这表明索引的创建能够显著提高带条件查询的性能,通过索引可以快速定位到满足条件的数据,减少了数据扫描的范围 。
最后,进行复杂的多表连接查询测试 。创建另一个表related_table,包含id(SERIAL类型,主键)和big_data_id(INTEGER类型,关联big_data_table的id字段)两个字段 。使用以下 SQL 语句创建表并插入一些关联数据:
CREATE TABLE related_table (id SERIAL PRIMARY KEY,big_data_id INTEGER);INSERT INTO related_table (big_data_id) VALUES (1), (2), (3);
执行多表连接查询,例如查询related_table中关联的big_data_table的记录,执行以下 SQL 语句:
SELECT * FROM big_data_tableJOIN related_table ON big_data_table.id = related_table.big_data_id;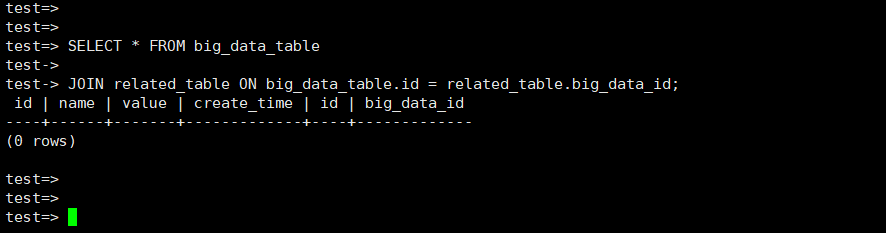
多次测试后,平均耗时约为 2 秒 。多表连接查询涉及到多个表之间的数据关联和匹配,其性能受到表的大小、连接条件以及索引等因素的影响 。在这个测试中,虽然数据量不是特别大,但多表连接操作仍然需要一定的时间来完成数据的匹配和整合 。
通过以上大数据量性能测试可以看出,KingbaseES 在大数据量下的查询性能表现良好 。对于简单的全表查询,随着数据量的增加,查询时间会有所增长,但仍然在可接受范围内;带条件的查询在没有索引时性能一般,创建索引后性能得到显著提升;复杂的多表连接查询也能够在合理的时间内返回结果,满足实际业务中对复杂查询的需求 。 同时,在测试过程中,观察到数据库的资源使用情况,CPU 和内存的使用率在查询过程中有所上升,但没有出现资源耗尽的情况,这表明 KingbaseES 在处理大数据量查询时能够有效地管理系统资源,保证数据库的稳定运行 。
六、总结与展望
6.1 测试总结
本次基于 Alibaba Linux 3 Docker 对 KingbaseES 进行的部署与测试,全面展示了其在数据库基本功能和性能方面的表现 。在功能测试中,KingbaseES 成功创建了设计的测试表结构,无论是单条数据插入还是批量数据插入都能准确执行,并且在简单查询和复杂查询场景下,都能返回正确的结果,满足了不同类型的查询需求 。
在性能测试环节,KingbaseES 在并发性能测试中表现出色,随着并发用户数的增加,事务处理速率(TPS)持续上升,平均响应时间虽有所增长,但仍在可接受范围内,展现出良好的并发处理能力 。在大数据量性能测试中,对于简单的全表查询、带条件查询以及复杂的多表连接查询,KingbaseES 都能在合理的时间内完成,且通过创建索引能显著提升带条件查询的性能 。
6.2 优势与不足
KingbaseES 具有诸多优势。首先,基于 Docker 的部署方式使其安装和配置过程变得极为便捷,大大缩短了部署时间,提高了环境搭建的效率 。其次,在功能实现上,它能够准确执行各种 SQL 操作,无论是基本的表创建、数据插入,还是复杂的查询逻辑,都表现出较高的可靠性 。再者,从性能方面来看,其在高并发和大数据量场景下的表现良好,能够满足企业级应用对数据库性能的要求 。此外,KingbaseES 对多种数据类型的支持以及与 PostgreSQL 的兼容性,使其在数据处理和应用迁移方面具有一定的优势 。
然而,KingbaseES 也存在一些不足之处 。在测试过程中发现,虽然它在并发性能测试中表现不错,但当并发用户数过高时,平均响应时间的增长较为明显,这可能会影响到一些对响应时间要求极高的应用场景 。另外,在大数据量查询中,全表查询的耗时相对较长,尽管这是大数据量场景下的常见问题,但仍可通过进一步优化查询算法和索引策略来提升性能 。同时,与一些成熟的国际知名数据库相比,KingbaseES 的生态系统还不够完善,相关的工具和插件数量相对较少,这可能会在一定程度上限制其在某些复杂业务场景中的应用 。
6.3 未来展望
展望未来,希望 KingbaseES 能够在性能优化方面持续发力 。进一步改进并发处理机制,降低高并发场景下的响应时间,提高系统的整体吞吐量 。在大数据量处理方面,不断优化查询引擎和索引技术,提升全表查询以及复杂查询的性能,以更好地应对日益增长的数据量和复杂的业务需求 。
在生态建设方面,期待 KingbaseES 能够加强与更多开源软件和工具的集成,丰富其生态系统 。吸引更多的开发者参与到 KingbaseES 的开发和应用中来,推动相关插件和工具的开发,提高其在不同行业和场景中的适用性 。同时,加大对技术文档和社区支持的投入,方便开发者快速上手和解决问题 。相信通过不断的改进和发展,KingbaseES 将在数据库市场中占据更重要的地位,为企业和开发者提供更强大、更可靠的数据管理解决方案 。

关于本文,博主还写了相关文章,欢迎关注《电科金仓》分类:
第一章:基础与入门
1、【金仓数据库征文】政府项目数据库迁移:从MySQL 5.7到KingbaseES的蜕变之路
2、【金仓数据库征文】学校AI数字人:从Sql Server到KingbaseES的数据库转型之路
3、电科金仓2025发布会,国产数据库的AI融合进化与智领未来
4、国产数据库逆袭:老邓的“六大不敢替”被金仓逐一破解
5、《一行代码不改动!用KES V9 2025完成SQL Server → 金仓“平替”迁移并启用向量检索》
6、《赤兔引擎×的卢智能体:电科金仓如何用“三骏架构”重塑AI原生数据库一体机》
7、探秘KingbaseES在线体验平台:技术盛宴还是虚有其表?
8、破除“分布式”迷思:回归数据库选型的本质
9、KDMS V4 一键搞定国产化迁移:零代码、零事故、零熬夜——金仓社区发布史上最省心数据库迁移评估神器
10、KingbaseES V009版本发布:国产数据库的新飞跃
第二章:能力与提升
1、零改造迁移实录:2000+存储过程从SQL Server滑入KingbaseES V9R4C12的72小时
2、国产数据库迁移神器,KDMSV4震撼上线
3、在Ubuntu服务器上安装KingbaseES V009R002C012(Orable兼容版)数据库过程详细记录
4、金仓数据库迁移评估系统(KDMS)V4 正式上线:国产化替代的技术底气
5、Ubuntu系统下Python连接国产KingbaseES数据库实现增删改查
6、KingbaseES V009版本发布,新特性代码案例
7、Java连接电科金仓数据库(KingbaseES)实战指南
8、使用 Docker 快速部署 KingbaseES 国产数据库:亲测全过程分享
9、【金仓数据库产品体验官】Oracle兼容性深度体验:从SQL到PL/SQL,金仓KingbaseES如何无缝平替Oracle?
10、KingbaseES在Alibaba Cloud Linux 3 的深度体验,从部署到性能实战