大模型预训练深度解析:从基座构建到目标设计
深入探讨大模型能力的源泉——预训练过程及其核心引擎"预训练目标"
在当今席卷全球的大模型浪潮中,我们惊叹于ChatGPT的对话流畅度,震撼于Claude的复杂推理能力,也享受着Midjourney带来的视觉创造力。然而,这些令人瞩目的上层应用,其磅礴力量的源泉都指向一个共同的、至关重要的基础阶段——预训练。
如果说微调和对齐是教会模型“如何与人交谈”的礼仪课,那么预训练就是赋予模型“知识与智慧”的通识教育。它是在万亿级Token的浩瀚语料上,通过海量计算,为模型构建起对整个世界的基本认知与逻辑理解的过程。而在这个过程中,决定模型将获得何种能力、形成何种“思维模式”的核心引擎,便是预训练目标的设计。
本文将深入剖析大模型预训练的“为什么”与“怎么做”。我们将从预训练的基础定位出发,揭示其为何成为所有大模型能力奠定的基石;随后,我们将聚焦于灵魂所在的“预训练目标”,详细解读其核心作用与主流范式——从经典的自回归语言建模到灵活的中间填充,再到推动视觉革命的MIM建模。最后,我们将为您呈现一幅清晰的技术图谱,梳理不同预训练目标与代表性模型(如GPT、BERT、T5、GLM等)的对应关系。
我们可以将大模型的生命周期划分为五个关键阶段,技术全景流程如下。
数据/架构准备 → 预训练(基石) → 监督微调 → 人类反馈强化学习 → 推理部署与应用
为了直观地理解这个流程,以下是大模型从构建到应用的全景流程图:
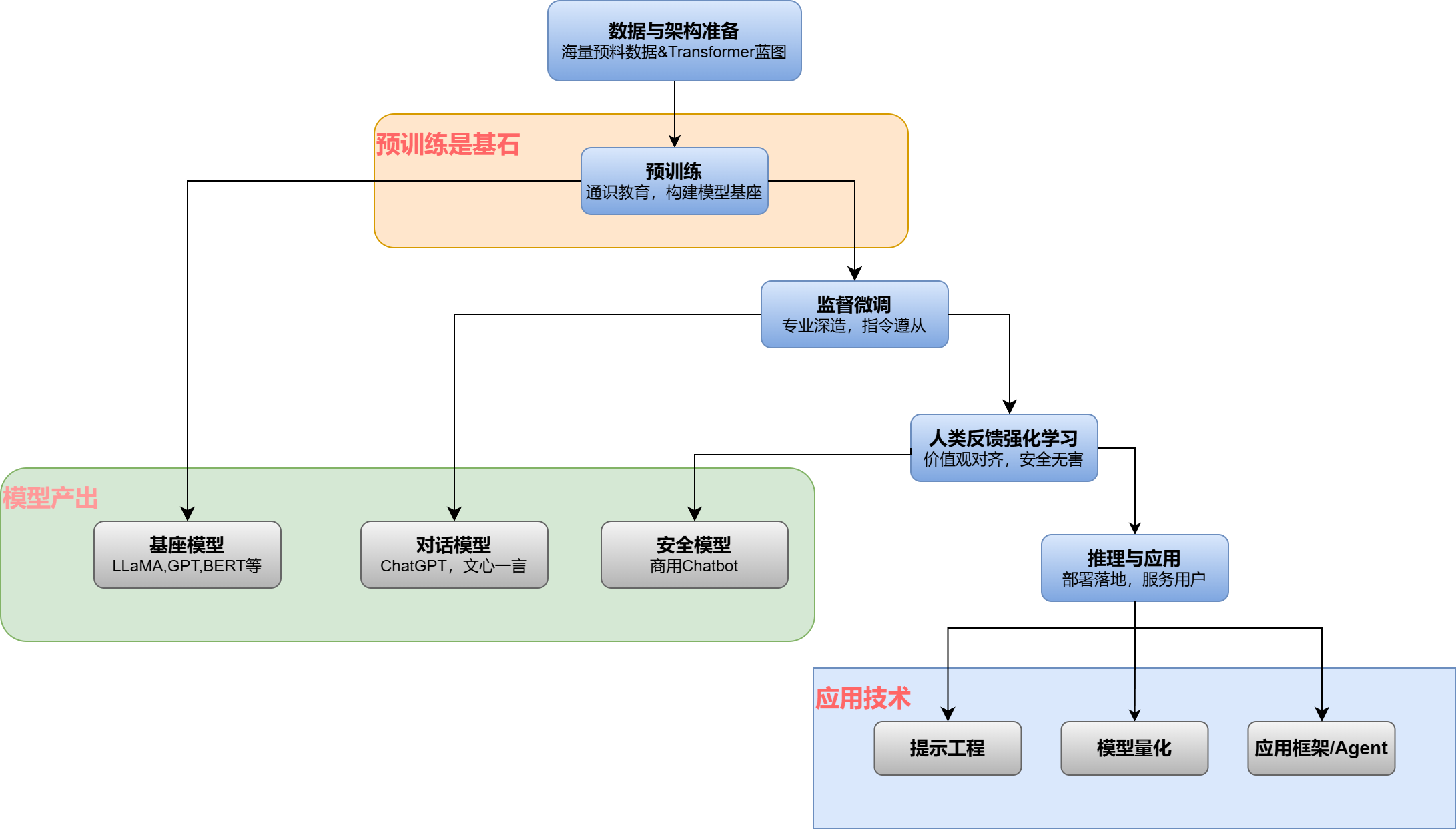
1. 什么是大模型预训练:AI的"通识教育"阶段
大模型预训练是指在一个大规模、无标注的文本数据集上,训练一个具有海量参数(通常达数十亿甚至万亿级别)的神经网络模型,使其学习并掌握语言内在规律、知识结构和世界知识的过程。
核心特征:
- 数据规模:训练数据可达TB级别,涵盖网页、书籍、代码等多领域文本
- 模型架构:基于Transformer架构,参数数量是模型能力的物理基础
- 学习范式:采用自监督学习,训练目标从原始数据自动生成
- 产出结果:得到一个"基座模型",具备通用语言能力但未针对特定任务优化
这个过程可以类比为让模型完成从"学前班"到"通识教育"的跨越,构建起对世界的基本认知框架。
2. 为什么预训练如此重要:能力涌现的基石
2.1 知识与表示的压缩存储
预训练过程本质上是将分布式、非结构化的互联网信息压缩编码到模型的数百亿参数中。模型参数成为了存储语法、事实、推理逻辑的"知识库",实现了知识的分布式表征。
2.2 通用语言表示的习得
通过大规模数据学习,模型能够提取词汇、短语、句子的高质量向量表示。这些表示能够捕捉语义、语法和上下文信息,为所有下游NLP任务提供统一的表示基础。
2.3 强大的先验知识提供
预训练后的模型已经对语言组织和世界运作有了坚实基础。面对新任务时,我们不再从"空白大脑"开始,而是在这个"知识渊博"的基础上进行微调,极大降低数据需求并提升性能。
2.4 泛化与涌现能力的源泉
只有在大规模预训练后,模型才会展现出惊人的零样本/少样本学习能力。复杂的思维链推理等高级能力也是在模型达到一定规模后涌现出来的。
3. 预训练目标:模型能力的"塑造者"
3.1 核心概念解析
预训练目标是一个数学上的损失函数,它精确定义了模型在预训练阶段需要优化的核心问题。可以将其理解为给"AI大脑"在学前班阶段布置的"家庭作业"——这套作业的设计直接决定了大脑会发展出什么样的思维方式和核心能力。
从技术角度看,预训练目标的核心妙处在于通过巧妙的规则从无标注数据自身生成监督信号,将原始文本转化为无数个"习题-答案"对。
3.2 预训练目标的核心作用
3.2.1 定义学习信号:从无序中创造有序
在互联网原始文本这类无标注数据中,预训练目标通过规则(如"随机遮盖词语")自动生成监督信号,解决了海量数据标注的世纪难题。
3.2.2 塑造模型能力偏向
不同的目标导向不同的能力发展:
- 自回归目标强制单向注意力,完美匹配文本生成过程
- 自编码目标允许双向上下文,支持深度语义理解
- 混合目标寻求理解与生成的平衡
3.2.3 作为知识"压缩算法"
预训练过程通过优化目标函数,将海量非结构化知识压缩编码到模型参数中。目标设计决定了知识压缩的效率和质量。
3.2.4 奠定后续技术基础
预训练阶段形成的"世界观"决定了模型后续的发展路径,包括微调效果和高级能力的涌现可能性。
4. 预训练目标分类与技术演进
4.1 自回归语言建模(标准语言建模)
核心机制:给定前文,预测下一个词(Token)
数学表达: P(词i | 词1, 词2, ..., 词i-1)
特点:
- 严格单向上下文
- 天然适合开放式文本生成
- 训练与推理过程一致
代表性模型:GPT系列、LLaMA系列、Bloom
4.2 自编码语言建模(掩码语言建模)
核心机制:随机遮盖输入中的部分词元,根据双向上下文预测被遮盖的原始词
数学表达: P(被遮盖的词 | 上下文左 + 上下文右)
特点:
- 利用双向上下文信息
- 更适合深度语义理解任务
- 不适合直接进行序列生成
代表性模型:BERT、RoBERTa
4.3 混合与演进目标
4.3.1 中间填充
核心机制:随机选择连续文本片段进行遮盖,要求模型基于双向上下文恢复完整片段
技术价值:
- 突破严格自回归限制
- 增强模型编辑和修复能力
- 支持"先读后写"的复杂推理
代表性模型:T5、GLM
4.3.2 去噪自编码
核心机制:对输入进行多种破坏(遮盖、删除、置换等),要求模型恢复原始文本
技术特点:比简单MLM要求更高,促进更强的理解和生成能力
代表性模型:BART、T5
4.3.3 前缀语言建模
核心机制:将序列分为前缀和生成部分,前缀允许双向注意力,生成部分保持自回归
技术优势:巧妙平衡理解与生成需求
代表性模型:GLM
4.3.4 对比学习
核心机制:学习区分正负样本对,拉近相似样本表示距离,推远不相似样本
应用场景:学习高质量句子级别表示,适合语义相似度计算
代表性模型:SimCSE
4.4 跨模态迁移:MIM建模
核心思想:将MLM成功范式迁移到视觉领域,随机遮盖图像块并预测被遮盖内容
技术影响:推动CV领域进入大规模自监督预训练时代
代表性模型:BEiT、MAE、SimMIM
5. 代表性模型与目标映射全景图
预训练目标 | 核心机制 | 代表性模型 | 能力特点与应用场景 |
|---|---|---|---|
自回归语言建模 | 单向下一词预测 | GPT系列, LLaMA, Bloom | 生成能力极致,适合对话、创作、代码生成,当前主流大模型基座 |
掩码语言建模 | 双向遮盖词预测 | BERT, RoBERTa | 理解能力深厚,适合情感分析、问答、信息抽取,需进一步微调 |
中间填充 | 连续片段修复 | T5, GLM | 灵活编辑能力,适合文档修订、代码补全,理解与生成平衡 |
去噪自编码 | 多噪声文本重建 | BART, T5 | 强健的文本理解,适合翻译、摘要等序列到序列任务 |
前缀语言建模 | 前缀双向+后缀自回归 | GLM | 兼顾理解与生成,ChatGLM系列模型基座 |
对比学习 | 表示相似性优化 | SimCSE, DeBERTa变体 | 高质量句子表示,适合语义匹配、检索任务 |
6. 技术趋势与展望
当前预训练技术呈现三个明显趋势:
6.1 规模化继续推进
模型和数据规模持续扩大,探索能力边界,激发更强的涌现能力。
6.2 多模态融合深化
预训练目标从纯文本扩展到视觉、音频等多模态数据,如CLIP(图文对比学习)、SpeechT5等。
6.3 目标设计精细化
除了基础语言建模,开始融入代码、数学、科学知识等结构化数据,进行专业化预训练以提升特定领域能力。
7. 结语
预训练目标作为大模型能力的"塑造者"和"引擎",其设计直接决定了模型的认知架构和能力边界。从早期的单一语言建模到如今的多样化混合目标,这一领域的演进体现了我们对智能本质理解的不断深化。
对于高级开发人员而言,深入理解不同预训练目标的技术特点和应用场景,不仅有助于正确选择和使用现有模型,更能为自定义模型训练和领域适配提供坚实的理论基础。在这个快速发展的领域中,掌握预训练目标的精髓,就是掌握了大模型能力的金钥匙。