【JVM】——实战篇
JVM性能调优与故障排查实战指南
作为Java开发者,深入理解JVM是迈向高级阶段的关键一步。本文将从参数设置、常用参数、调优工具到两大经典故障(内存泄漏和CPU飙高)的排查思路,为您提供一份完整的实战指南。
一、JVM调优参数设置位置
JVM参数并非在代码中设置,而是在Java应用程序启动时通过命令行指定。根据不同的部署和运行环境,主要有以下设置方式:

1、在war包中设置
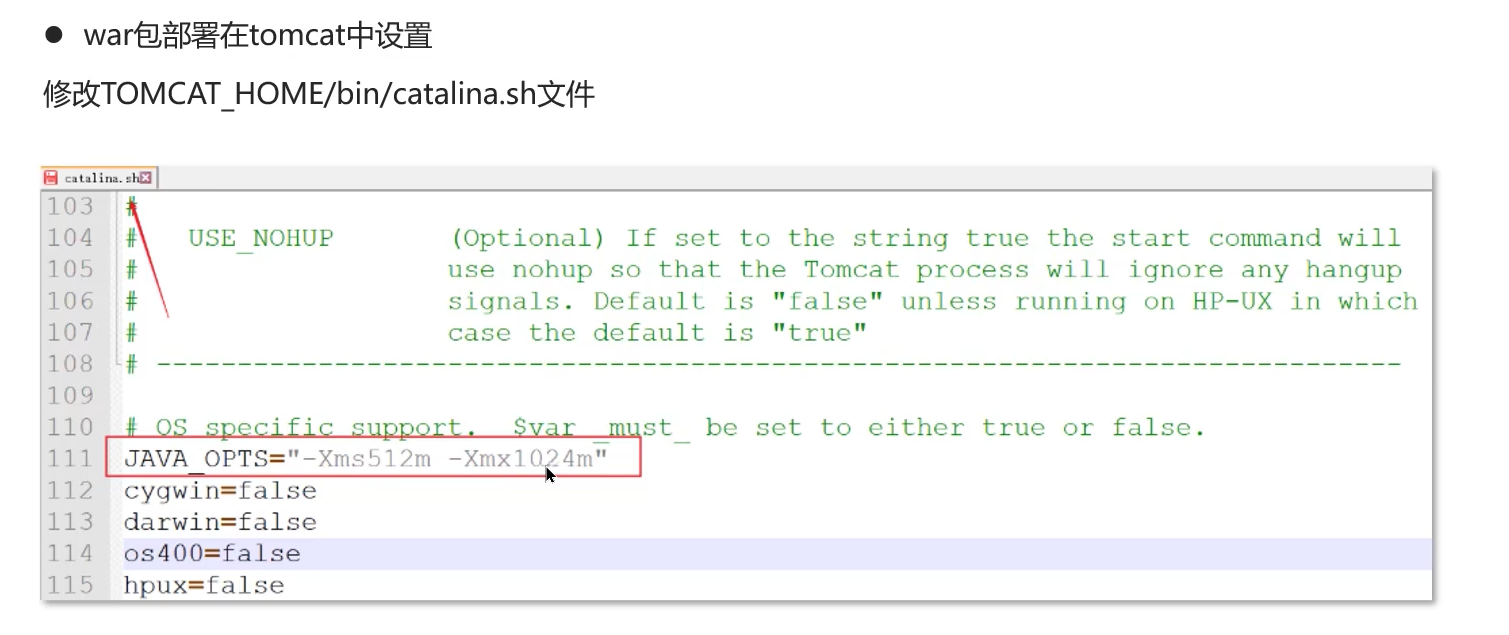
-Xms:初始化大小 -Xmx:最大容量
2、使用jar包运行

小结:

本地开发环境(IDE)
- IntelliJ IDEA: 在运行配置(Run/Debug Configurations)中,找到
VM options输入框进行设置。 - Eclipse: 在运行配置(Run Configurations)中的
Arguments标签页,在VM arguments框中设置。
- IntelliJ IDEA: 在运行配置(Run/Debug Configurations)中,找到
传统服务器环境(Tomcat, JBoss等)
- Tomcat: 修改
bin/catalina.sh(Linux/macOS)或bin/catalina.bat(Windows)文件。- 找到
JAVA_OPTS或CATALINA_OPTS环境变量进行设置。 - 更推荐的做法是创建
bin/setenv.sh(或setenv.bat)文件,并在其中设置,这样做便于管理和升级。
- 找到
- Tomcat: 修改
# 示例 setenv.shexport JAVA_OPTS="-Xms2g -Xmx2g -XX:+UseG1GC"* 其他应用服务器(如 WildFly, WebLogic)都有其特定的配置文件,通常位于 `bin/` 目录下。
3. 容器化环境(Docker/Kubernetes)
* Dockerfile: 在 ENTRYPOINT 或 CMD 指令中直接指定 java 命令和参数。
FROM openjdk:11-jre...CMD ["java", "-Xms512m", "-Xmx512m", "-jar", "/app/app.jar"]* **Kubernetes**: * **Deployment YAML**: 在容器规约(Container Spec)中的 `args` 字段里设置。
containers:- name: my-appimage: my-app:latestargs: ["-Xms512m", "-Xmx512m", "-XX:+UseContainerSupport", "-jar", "/app.jar"]* **重要提示**:在容器中运行务必加上 `-XX:+UseContainerSupport`(JDK 8u191+ 和 JDK 10+ 默认开启),并配合 `-XX:MaxRAMPercentage` 使用,让JVM根据容器内存限制自动分配堆大小,而不是使用物理机内存。
4. 命令行直接启动 * 最简单直接的方式,适用于任何环境。
java -Xms1024m -Xmx1024m -XX:+PrintGC -jar application.jar二、常用的JVM调优参数
JVM参数分为标准参数(-开头)、非标准参数(-X开头)和非稳定参数(-XX开头)。调优主要涉及后两者。

1、堆空间大小设置
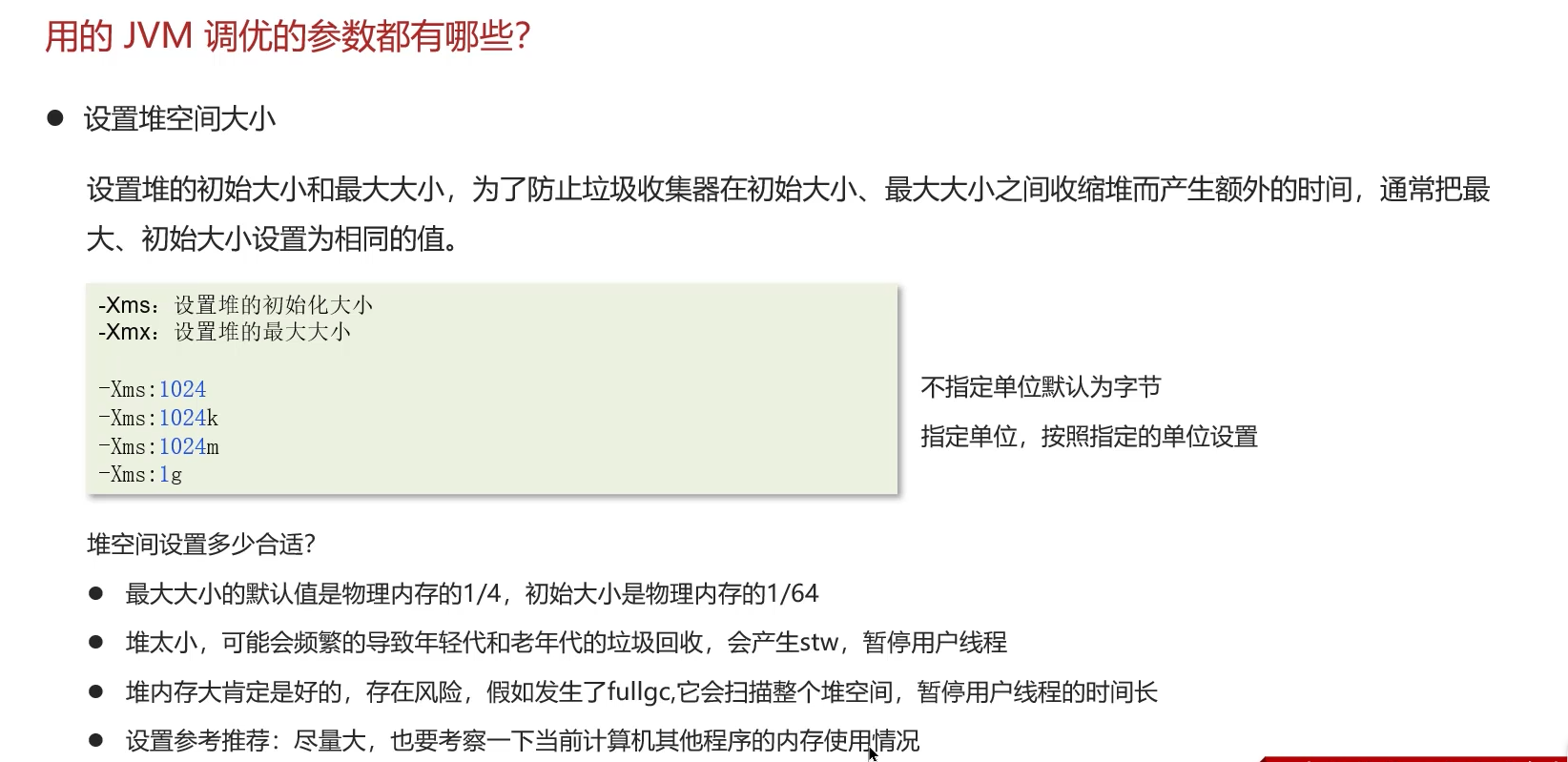
2、虚拟机栈大小设置

3、年轻代中Eden区和幸存者区(Survivor)设置
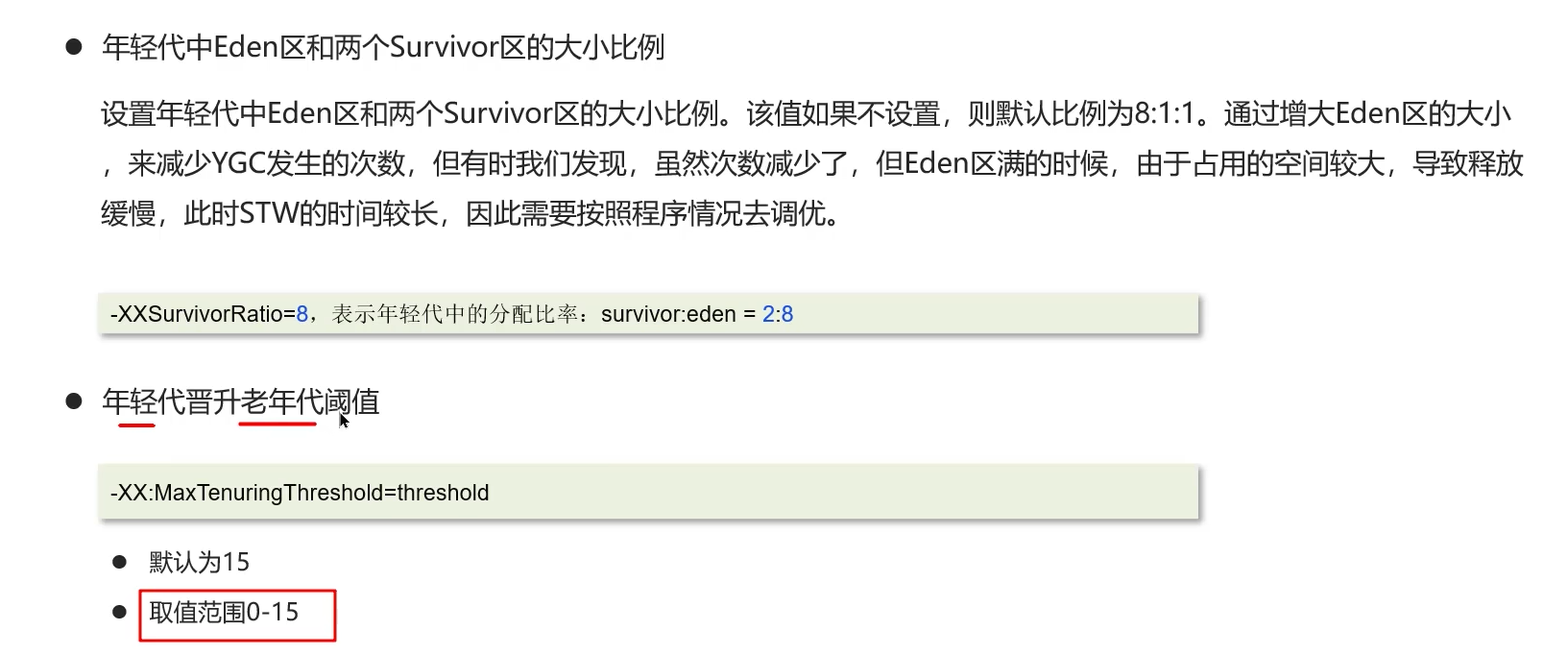
4、垃圾回收器设置
| 类别 | 参数 | 说明 |
|---|---|---|
| 堆内存 | -Xms | 初始堆大小,如 -Xms2g,通常设置成和 -Xmx 相同以避免扩容带来的性能波动。 |
-Xmx | 最大堆大小,如 -Xmx2g,这是控制内存最重要的参数。 | |
-Xmn | 年轻代大小。官方推荐设置为整个堆的 1/4 到 1/2。 | |
-XX:MetaspaceSize | 元空间初始大小。 | |
-XX:MaxMetaspaceSize | 元空间最大大小,默认不限,建议设置以防无限膨胀。 | |
| 垃圾回收器 | -XX:+UseG1GC | 启用G1垃圾回收器(JDK9+默认)。 |
-XX:+UseConcMarkSweepGC | 启用CMS回收器(JDK9已废弃,JDK14移除)。 | |
-XX:+UseZGC | 启用ZGC(低延迟,JDK15开始正式版)。 | |
-XX:+UseShenandoahGC | 启用ShenandoahGC(低延迟,RedHat贡献)。 | |
| GC日志 | -XX:+PrintGC / -verbose:gc | 打印简要GC信息(已过时)。 |
-XX:+PrintGCDetails | 打印详细的GC信息(推荐)。 | |
-XX:+PrintGCDateStamps | 在GC日志上增加日期时间戳。 | |
-Xloggc:<file> | 将GC日志输出到文件。 | |
-XX:+UseGCLogFileRotation | 开启GC日志文件滚动。 | |
-XX:NumberOfGCLogFiles=5 | 滚动保留的GC日志文件数。 | |
-XX:GCLogFileSize=10M | 每个GC日志文件的大小。 | |
| 异常处理 | -XX:+HeapDumpOnOutOfMemoryError | 在发生OOM时自动生成堆转储文件(必备!)。 |
-XX:HeapDumpPath=./java_pid<pid>.hprof | 指定堆转储文件的路径。 | |
| 其他调优 | -XX:MaxTenuringThreshold | 对象晋升老年代的年龄阈值。 |
-XX:SurvivorRatio | Eden区和Survivor区的比例。 |
三、JVM调优工具
工欲善其事,必先利其器。JDK自带了一系列强大的监控调试工具。

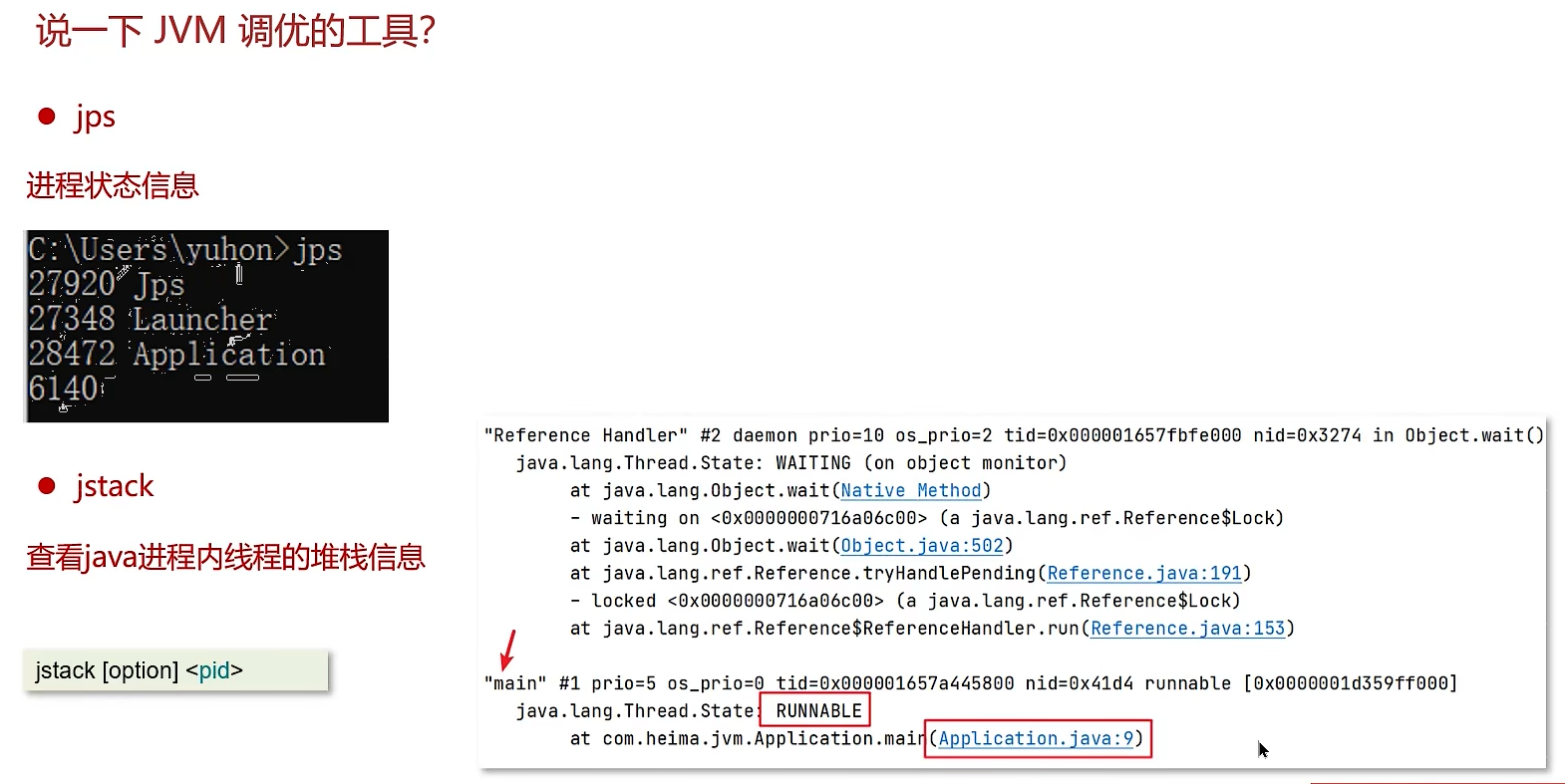

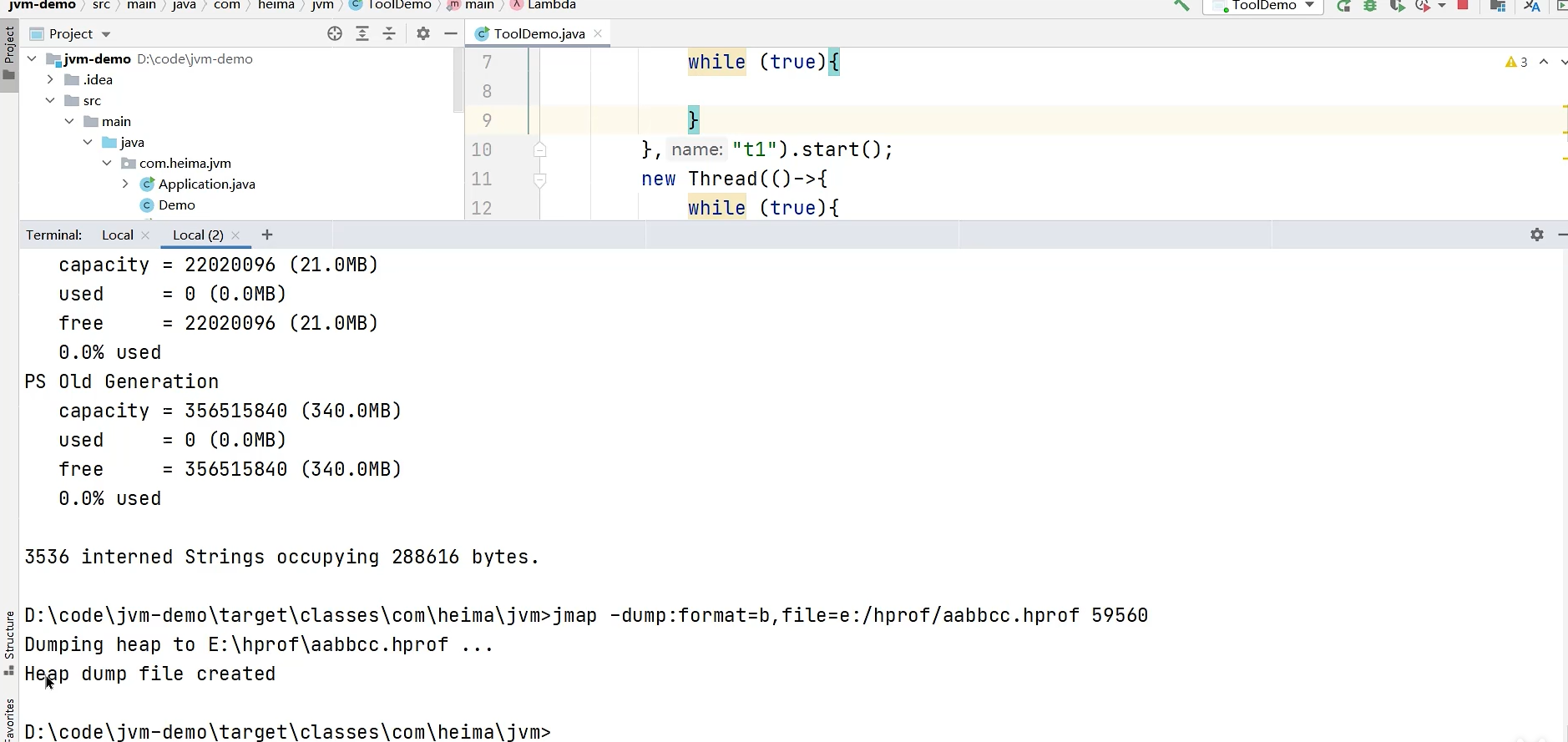
jmap的信息:
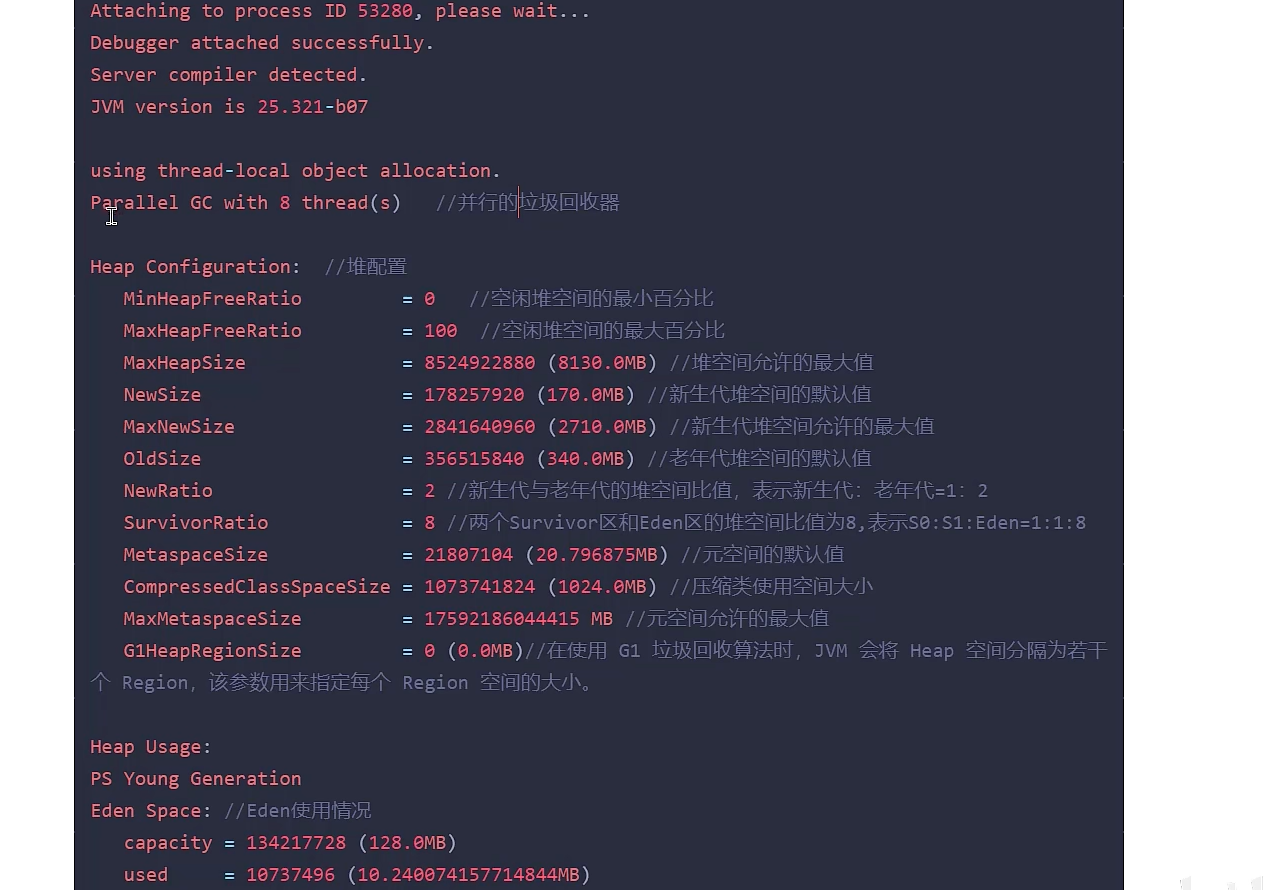
2、可视化工具
VisualVM只在java8里有
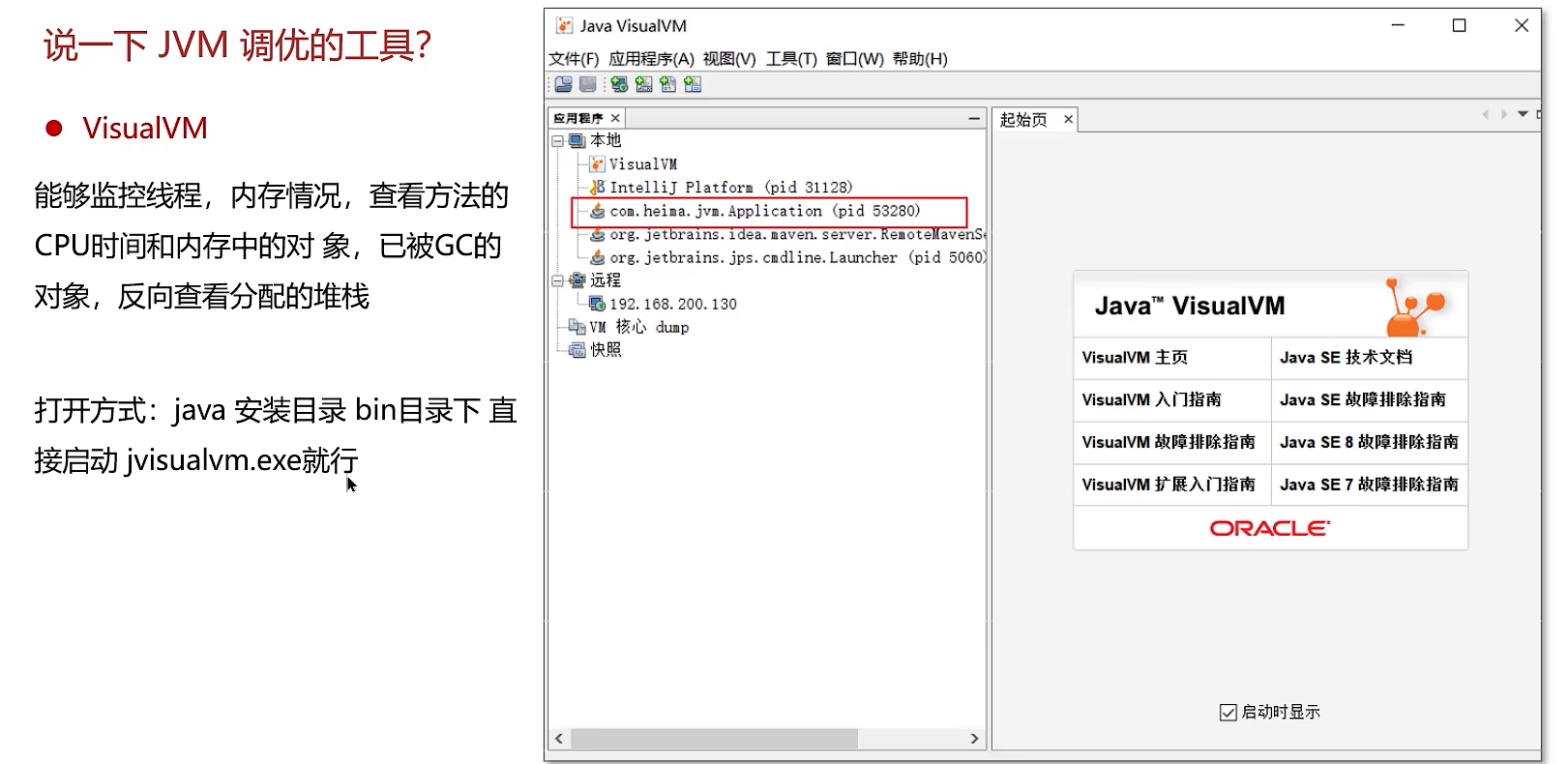
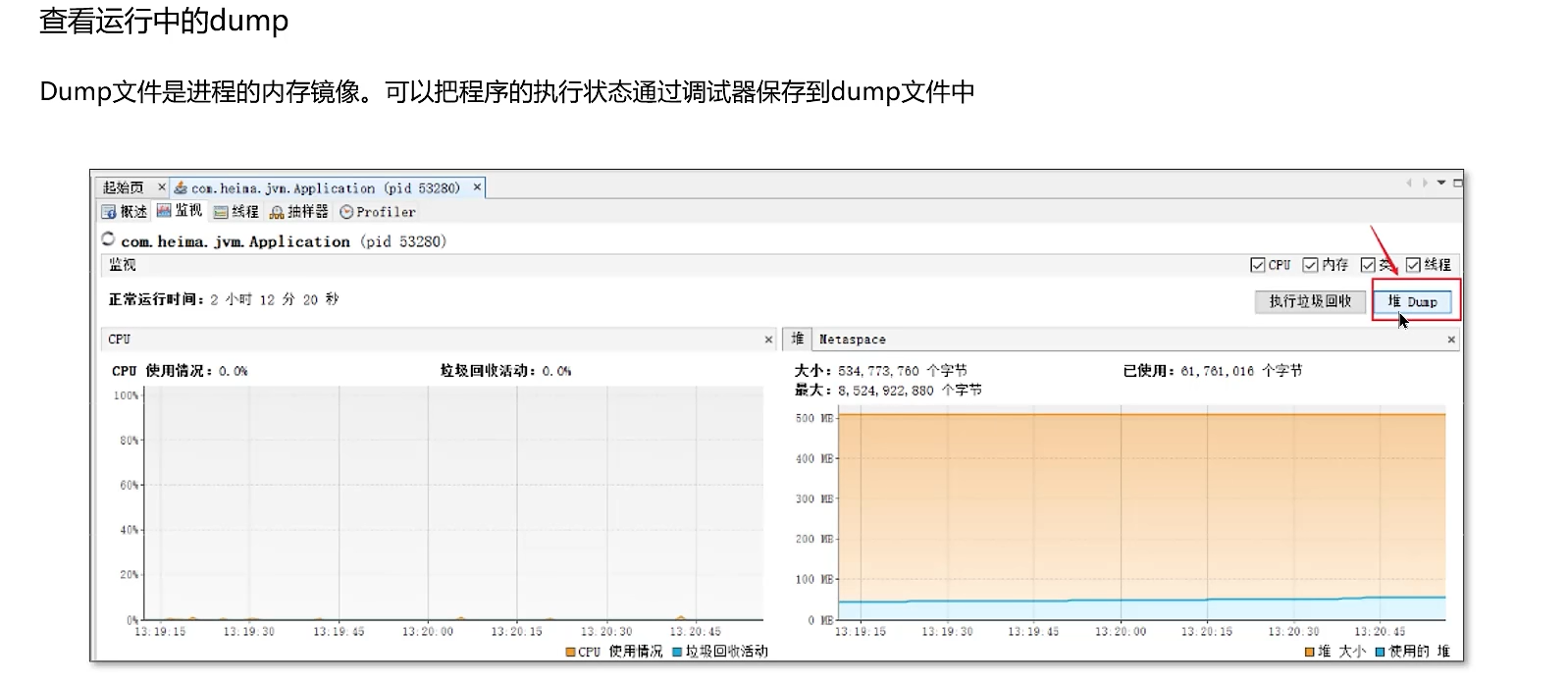
通过VisualVM可以查看Jmap快照的文件
| 工具名称 | 主要功能 | 特点 |
|---|---|---|
jps | JVM进程状态工具 | 列出当前用户下的所有Java进程的PID和主类名。排查第一步:找PID。 |
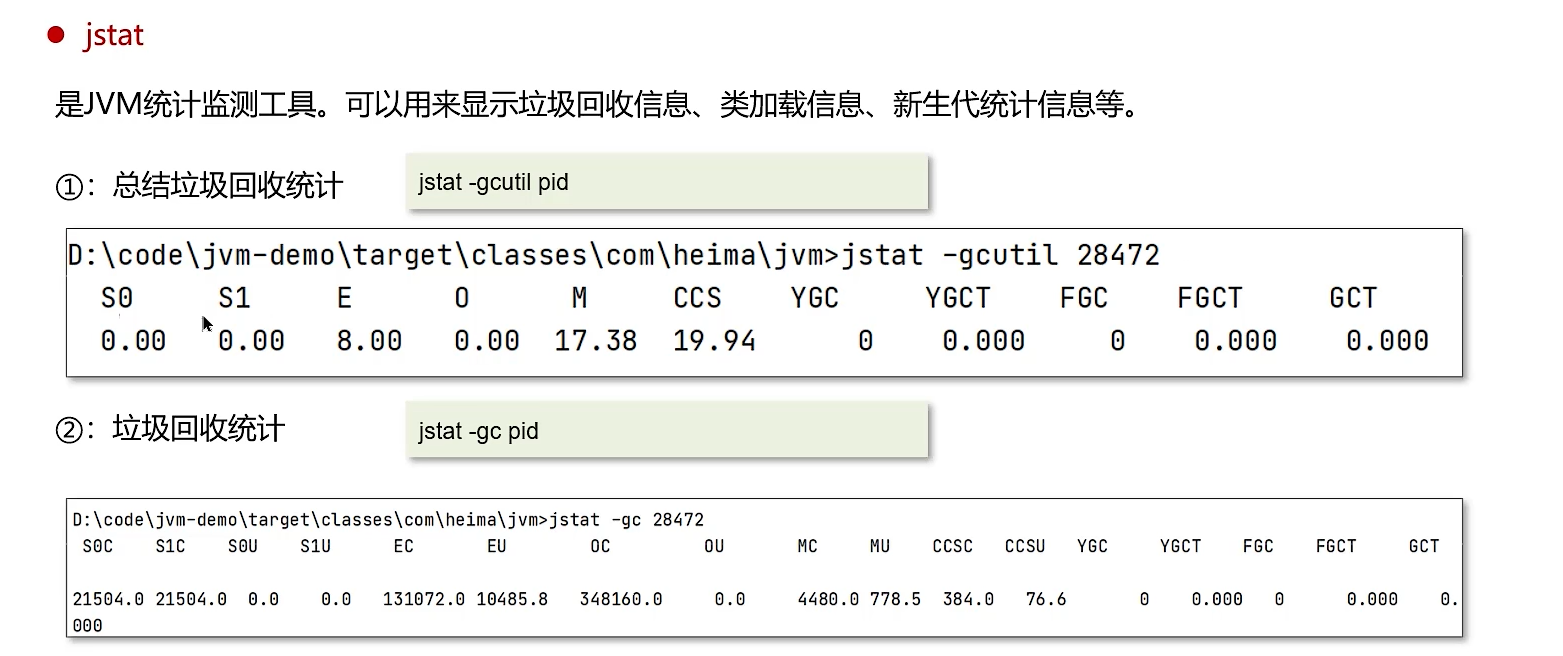
jstat | JVM统计监控工具 | 查看类加载、内存、垃圾回收、JIT编译等运行数据。jstat -gc <pid> 1s 每秒查看GC情况。 |
jinfo | JVM配置信息工具 | 查看和调整JVM参数的实时值。 |
jmap | JVM内存映像工具 | 生成堆转储快照(Heap Dump)。jmap -dump:format=b,file=heap.hprof <pid> |
jstack | JVM堆栈跟踪工具 | 生成JVM当前时刻的线程快照(Thread Dump)。排查CPU高、死锁的利器。jstack <pid> |
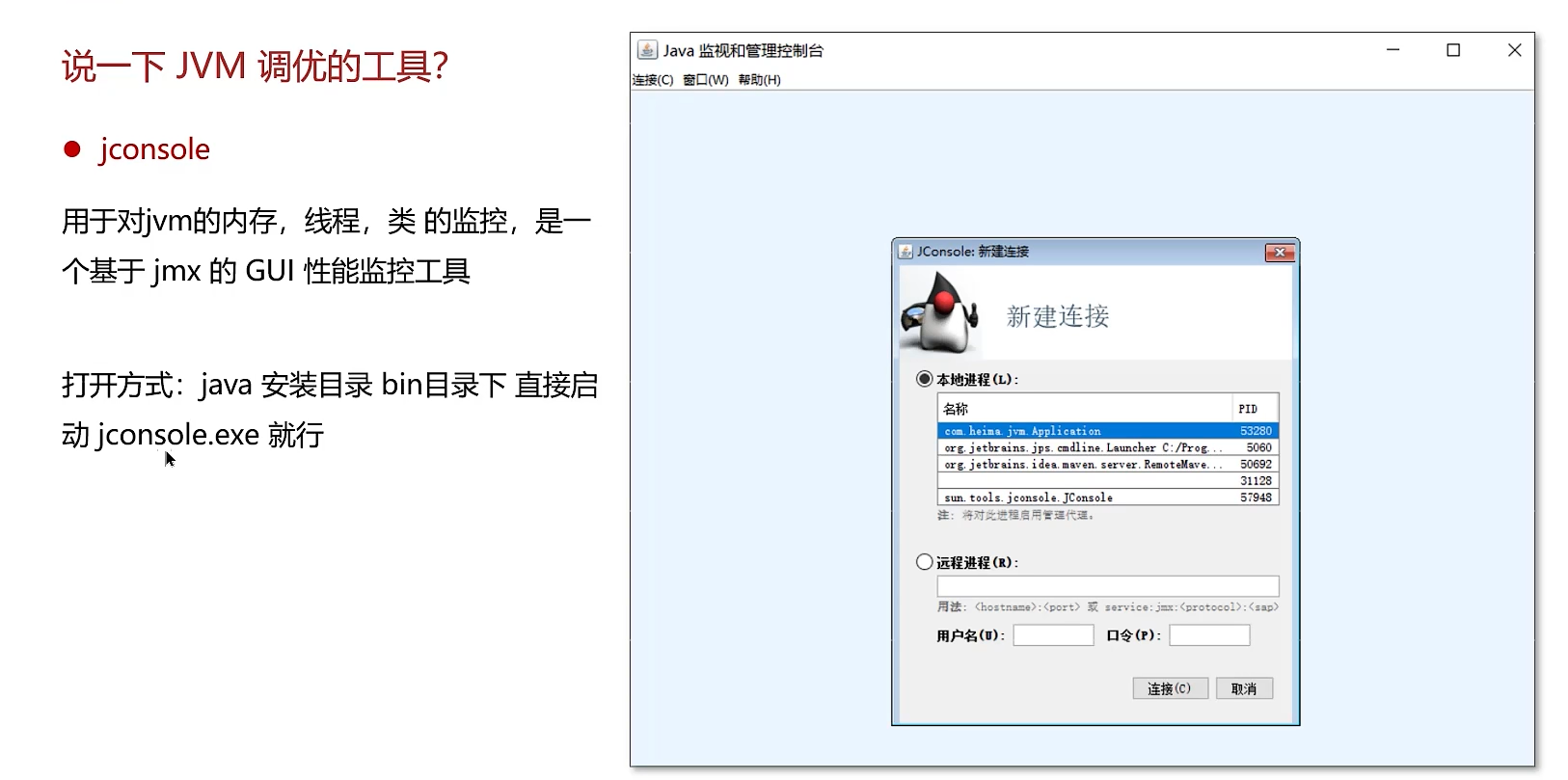
jconsole | 图形化监控工具 | 可视化查看堆内存、线程、类、MBean等信息。适合初步观察。 |
VisualVM | 功能强大的图形化监控/剖析工具 | JDK8及之前自带,后来独立发展。功能极其强大,可安装插件,支持CPU、内存采样,离线分析堆转储和线程转储文件。 |
Java Flight Recorder (JFR) & Java Mission Control (JMC) | 飞行记录仪与监控中心 | Oracle JDK商业版特性(JDK11及之后,个人开发/开发环境免费)。生产环境 profiling 首选,性能开销极低(通常<1%),能记录非常详细的事件信息(方法调用、IO、锁等)。 |
Arthas | 阿里开源的线上诊断神器 | 强烈推荐。无需重启应用,动态跟踪代码,诊断性能问题。功能包括:查看加载的类、方法执行耗时、监控方法调用、反编译类、生成火焰图等。 |
四、Java内存泄漏的排查思路
内存泄漏的本质是:对象无用了,但却被错误的引用(GC Roots)持有,导致GC无法回收它们。
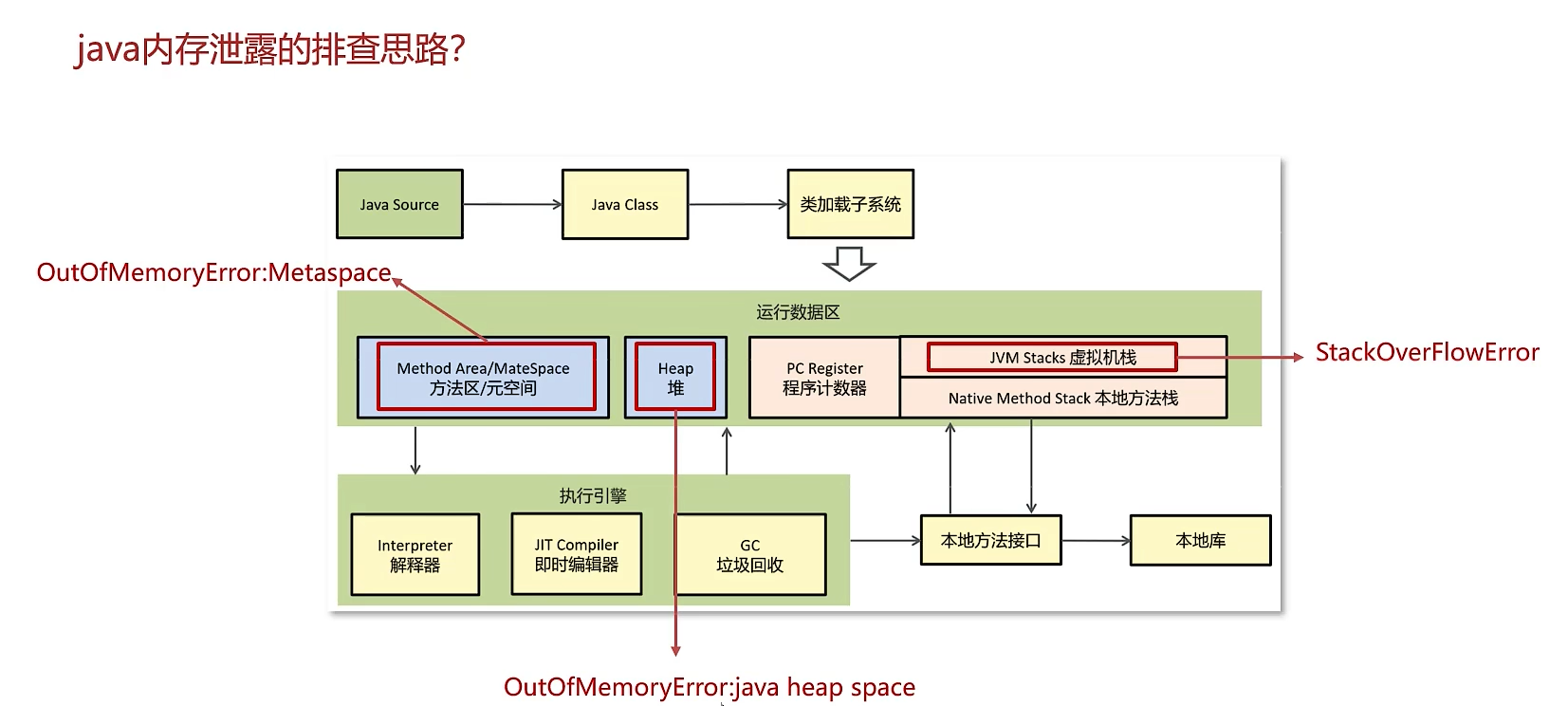
排查步骤:
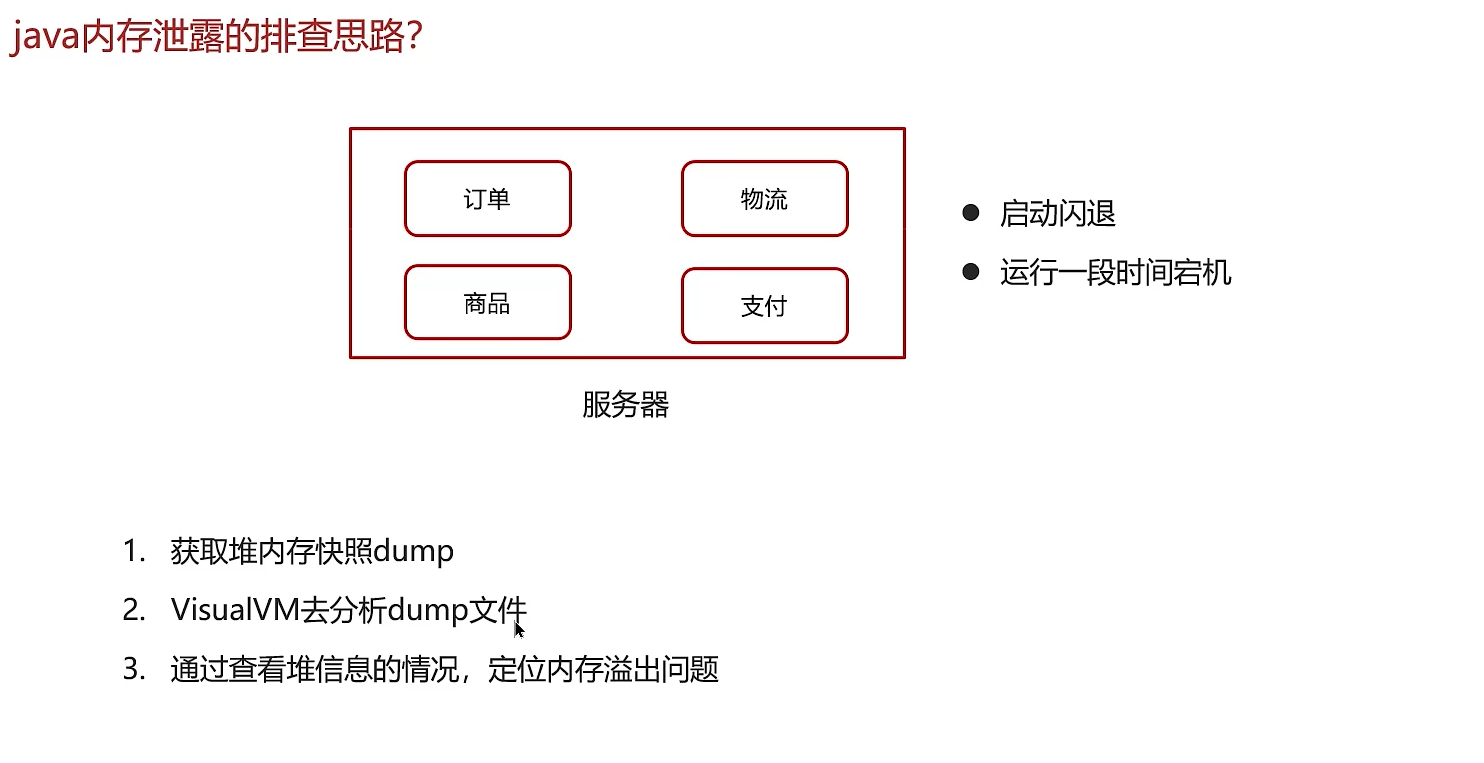
确认现象:
- 应用长时间运行后响应变慢,且频繁Full GC。
- 监控平台(如Prometheus+Grafana)显示老年代或堆内存使用率持续上升,即使Full GC后也不下降。
- 最终抛出
java.lang.OutOfMemoryError: Java heap space错误。
获取证据:
- 务必在启动参数中加上
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/save,让JVM在OOM时自动生成堆转储文件(Heap Dump)。 - 如果没有自动生成,可以在怀疑的时间点,使用
jmap -dump:format=b,file=heap.hprof <pid>手动生成。 
- 务必在启动参数中加上
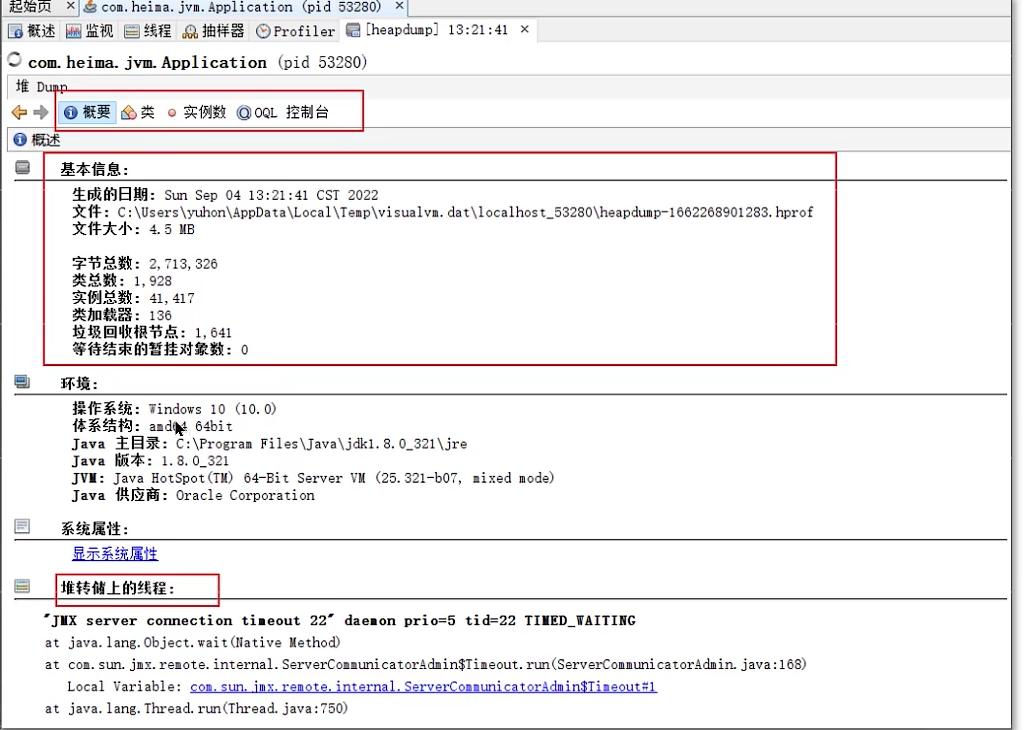
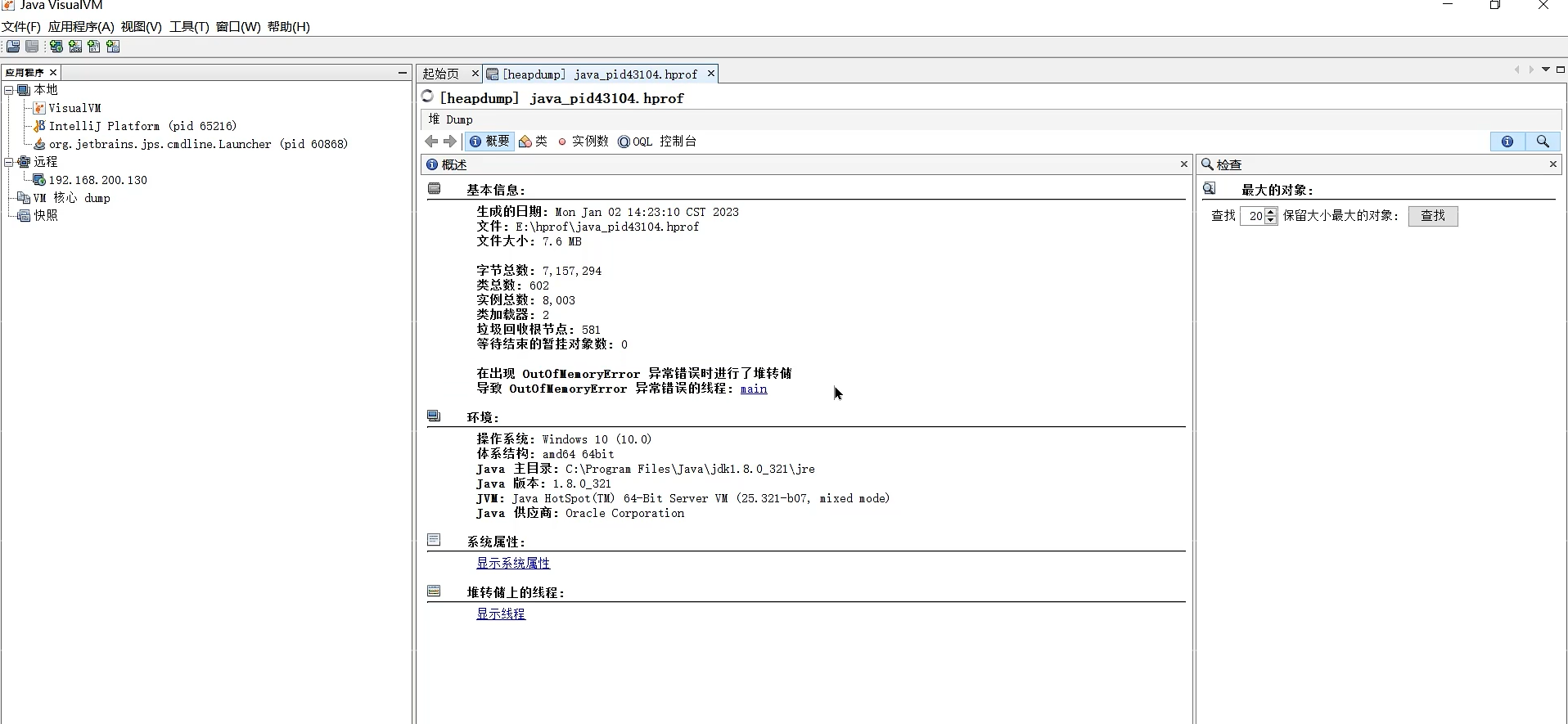
分析堆转储:
- 使用 VisualVM、Eclipse MAT(Memory Analyzer Tool) 或 JProfiler 等工具加载
.hprof文件。 - 关键分析步骤:
- 查看直方图(Histogram):查看哪个类的实例数量最多、占用内存最大。关注自定义类或第三方库类。
- 执行Leak Suspects Report(泄漏怀疑报告):MAT会自动生成一个报告,给出可能发生泄漏的点和对象引用链。
- 查看支配树(Dominator Tree):找到内存中最大的对象块,看是谁在持有它们。
- 分析引用链:对可疑的类,查看从GC Roots到这些对象的完整引用路径(这是找到“错误持有者”的关键)。常见原因包括:
- 静态集合类(如static Map)持有了业务对象。
- 未取消注册的监听器(Listener)或回调(Callback)。
- 线程池中堆积的任务对象。
- 数据库连接、网络连接、文件流等未关闭。
- 使用 VisualVM、Eclipse MAT(Memory Analyzer Tool) 或 JProfiler 等工具加载
修复与验证:
- 根据分析结果,修改代码,切断错误的引用链(例如使用弱引用、及时从集合中移除对象、关闭资源等)。
- 修复后,在预发环境或通过压力测试重现场景,持续监控内存变化,确认问题已解决。
小结:

五、CPU飙高的排查方案及思路
CPU使用率持续过高,通常是某个或多个线程在长时间执行计算密集型操作(如死循环、频繁GC、复杂的正则匹配等)。
排查步骤:
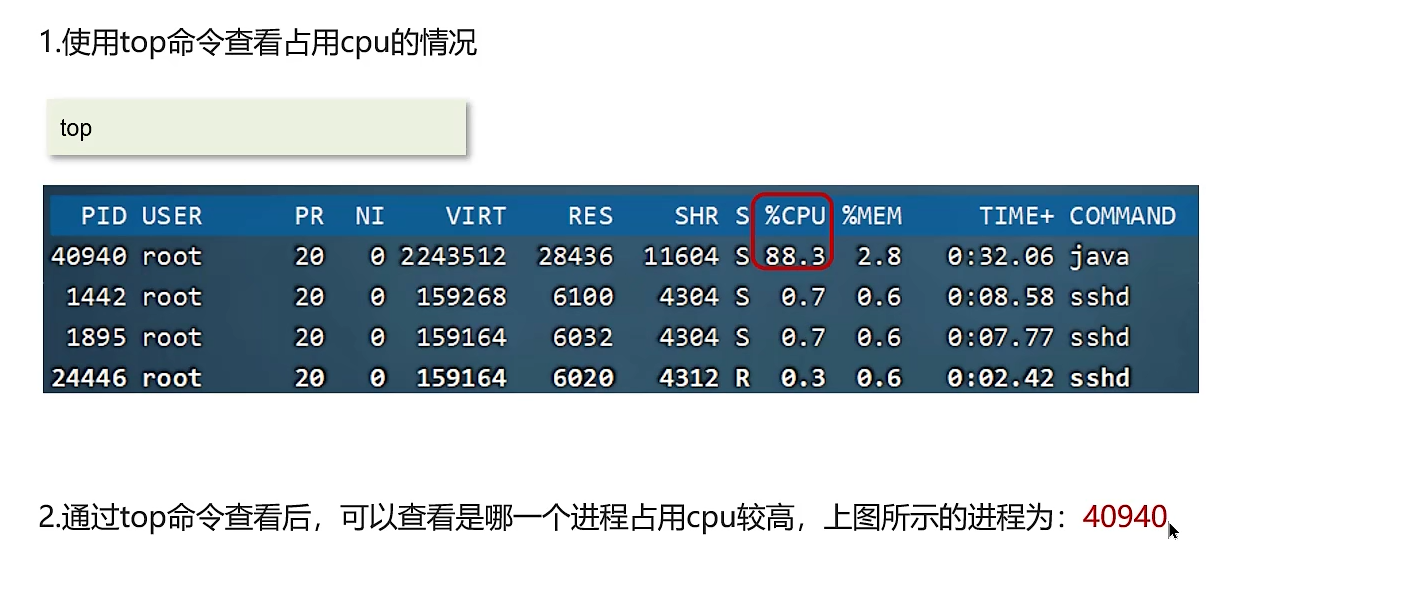
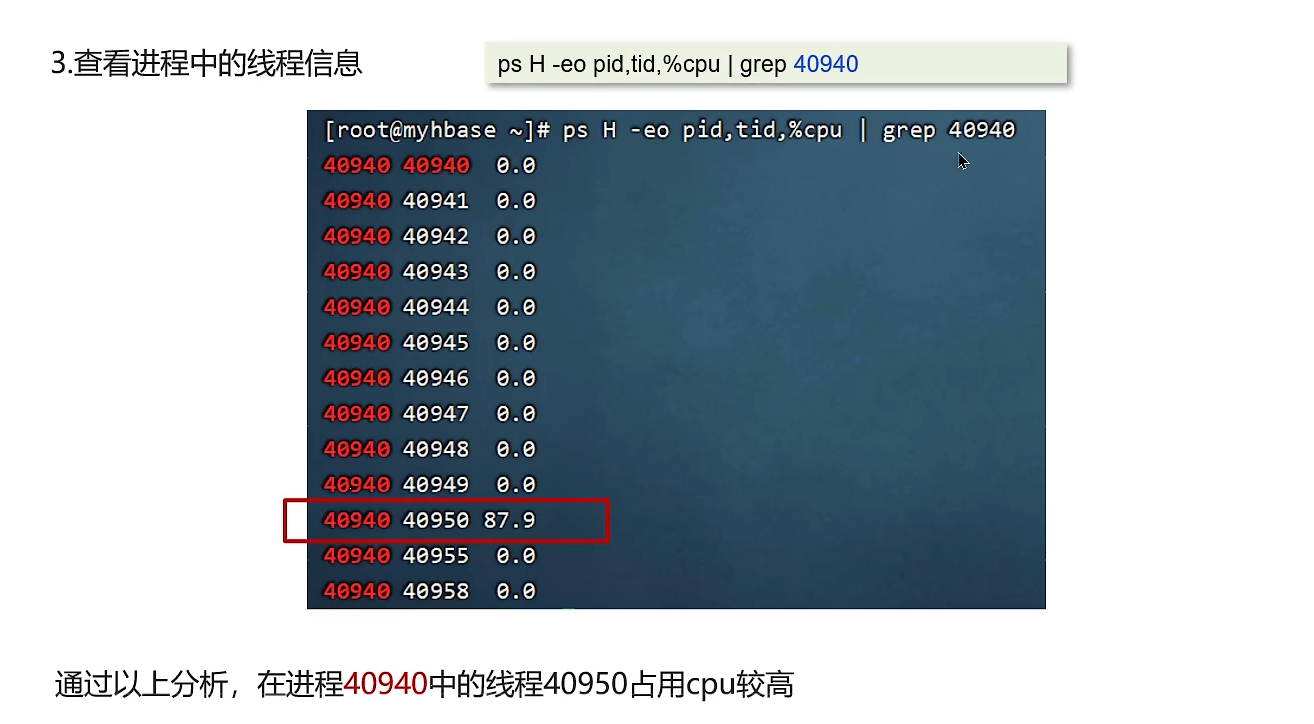
定位高CPU进程和线程:
- 第一步:使用
top命令(Linux/macOS)或任务管理器(Windows),找到CPU占用率最高的进程,记下其PID。 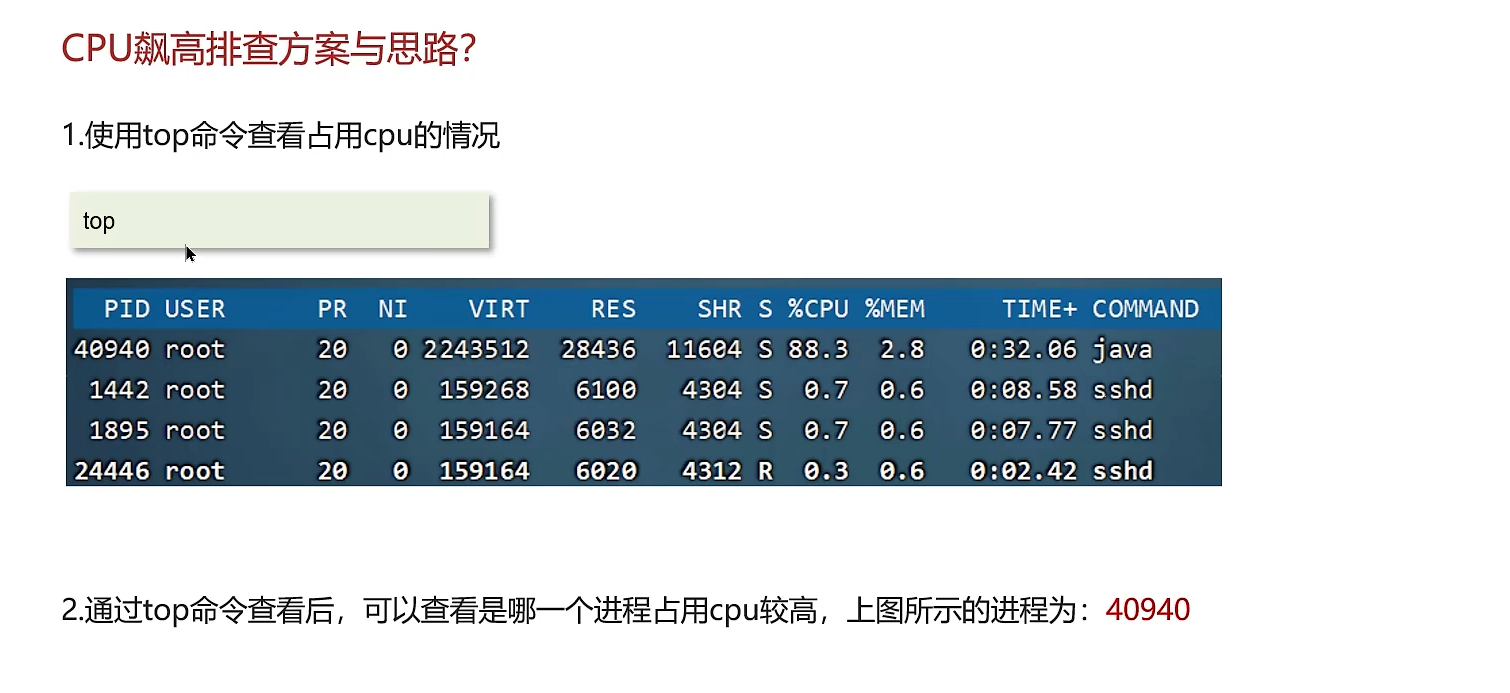
- 第二步:
top -Hp <pid>,查看该进程内所有线程的CPU占用情况。找到占用最高的那个线程ID(TID),并将其转换为16进制(printf "%x\n" <tid>),以备后续使用。
- 第一步:使用
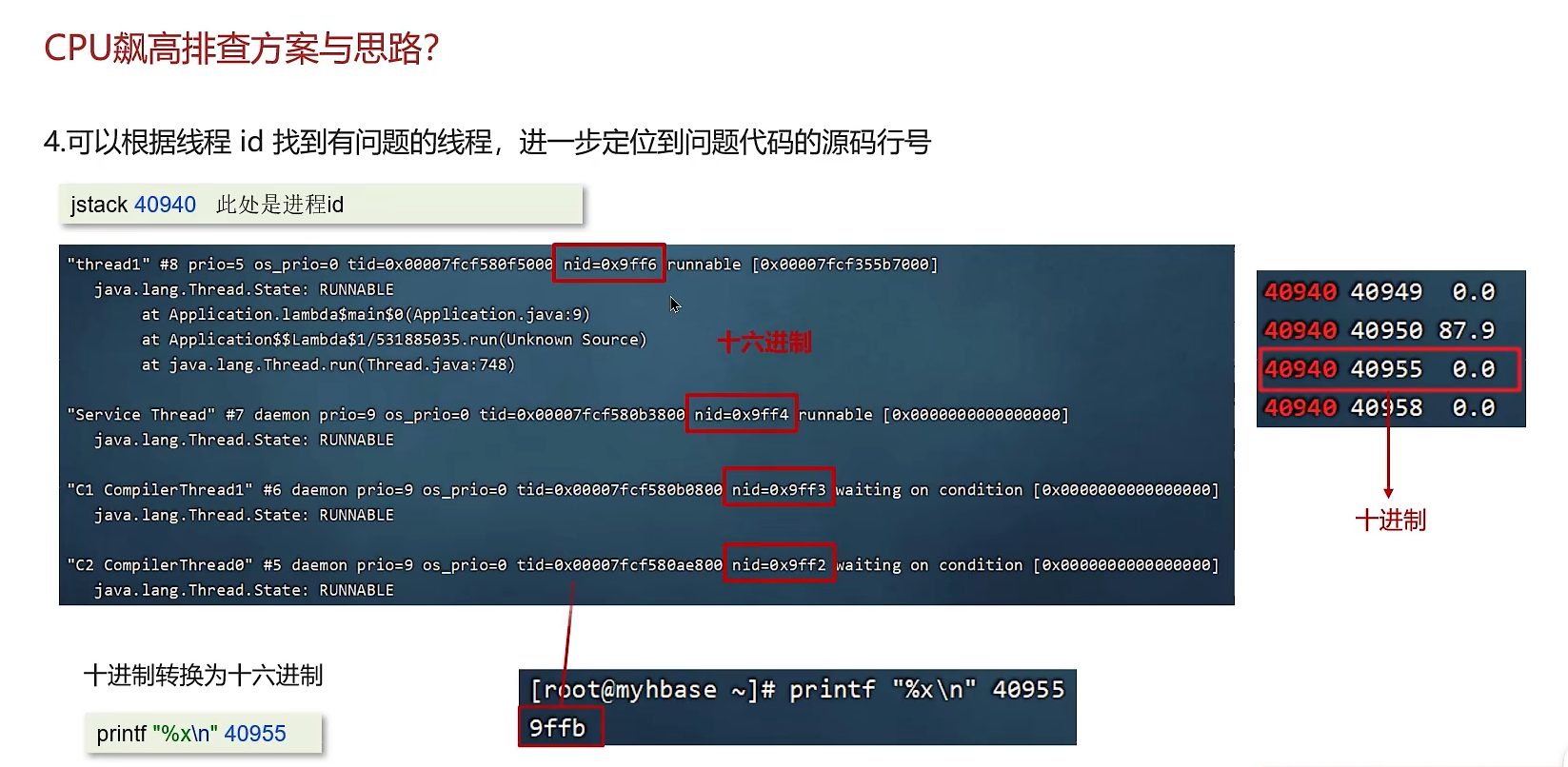
获取线程快照:
- 使用
jstack <pid>命令,获取当前JVM的线程快照(Thread Dump)。 - 可以多次执行(如间隔5-10秒)并保存,以对比线程状态的变化。
- 使用
分析线程快照:
- 在得到的线程快照文件中,查找之前在第二步中转换得到的16进制线程ID(nid)。
- 找到对应的线程,查看它的线程状态(如RUNNABLE) 和堆栈跟踪(Stack Trace)。
- 堆栈信息直接告诉你这个线程正在执行什么代码,这是定位问题的直接证据。
- 常见原因:
- 业务逻辑问题:如死循环、无限递归、低效的算法。
- 频繁的GC:如果线程是
GC task thread,说明垃圾回收频繁,可能是内存问题引起的连锁反应。 - 锁竞争:大量线程处于
BLOCKED状态,等待获取某个锁。 - 其他:如频繁的JNI调用、序列化/反序列化操作。
高级诊断(使用Profiler):
- 如果问题无法通过线程快照直接定位(例如,CPU高是由许多线程轻微开销累积导致的),可以使用 Arthas 的
profiler命令或 Async-Profiler 生成火焰图(Flame Graph)。 - 火焰图可以非常直观地显示CPU时间在哪些方法调用上被消耗,是分析性能瓶颈的终极利器。
- 如果问题无法通过线程快照直接定位(例如,CPU高是由许多线程轻微开销累积导致的),可以使用 Arthas 的
总结思路流程图: top -> top -Hp <pid> -> printf “%x\n” <tid> -> jstack <pid> | grep <nid> -> 分析对应线程的堆栈
方法2:
1、java运行导致CPU飙高,可以先定位到导致CPU飙高的线程:
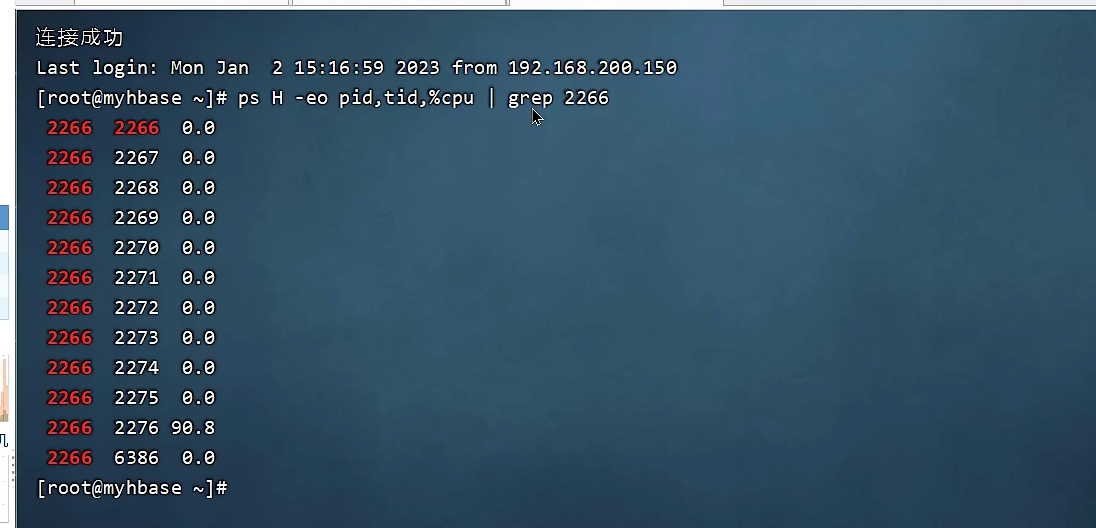
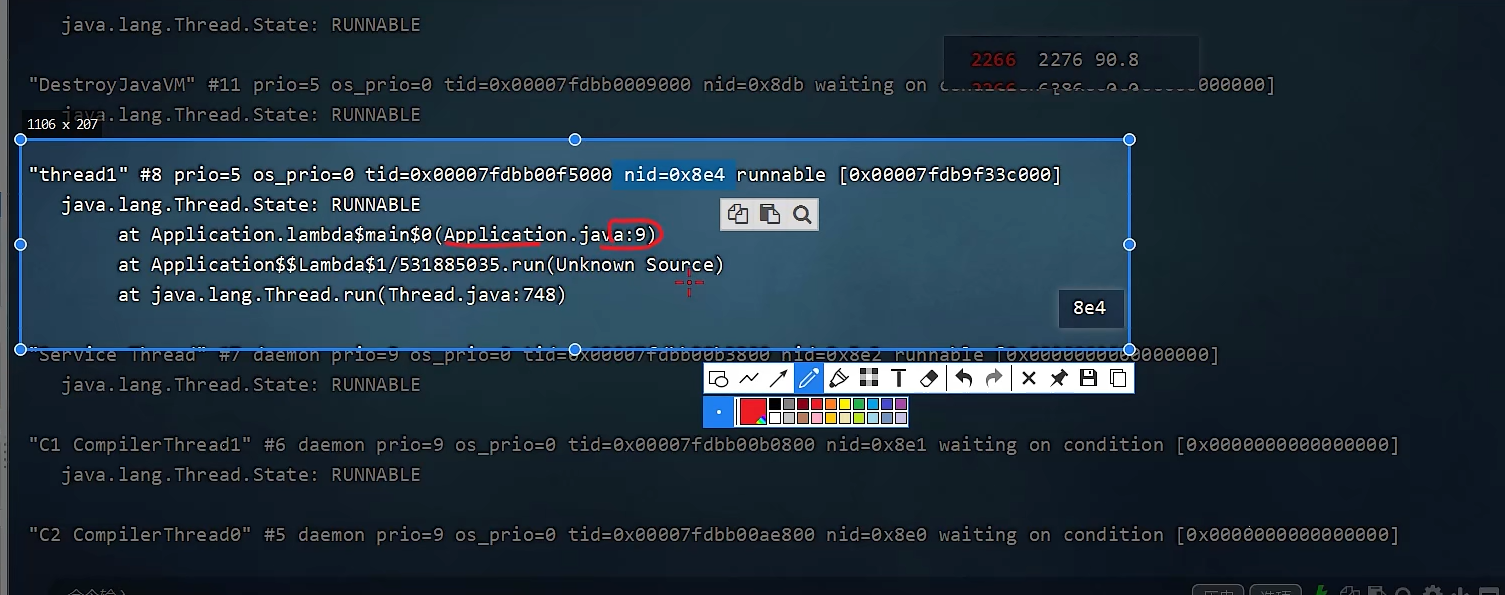
2、通过jstack查看线程信息。由于jvm显示的线程是16进制的,而Linux显示的线程是10进制的,需要先把10进制转为16进制进行查找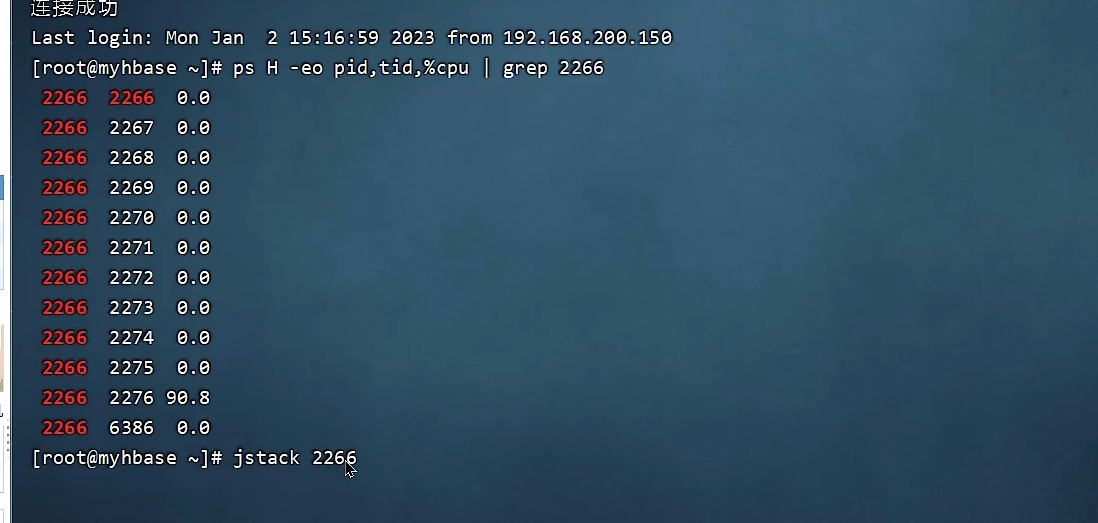

然后定位到java报错行数
3、查看报错代码:

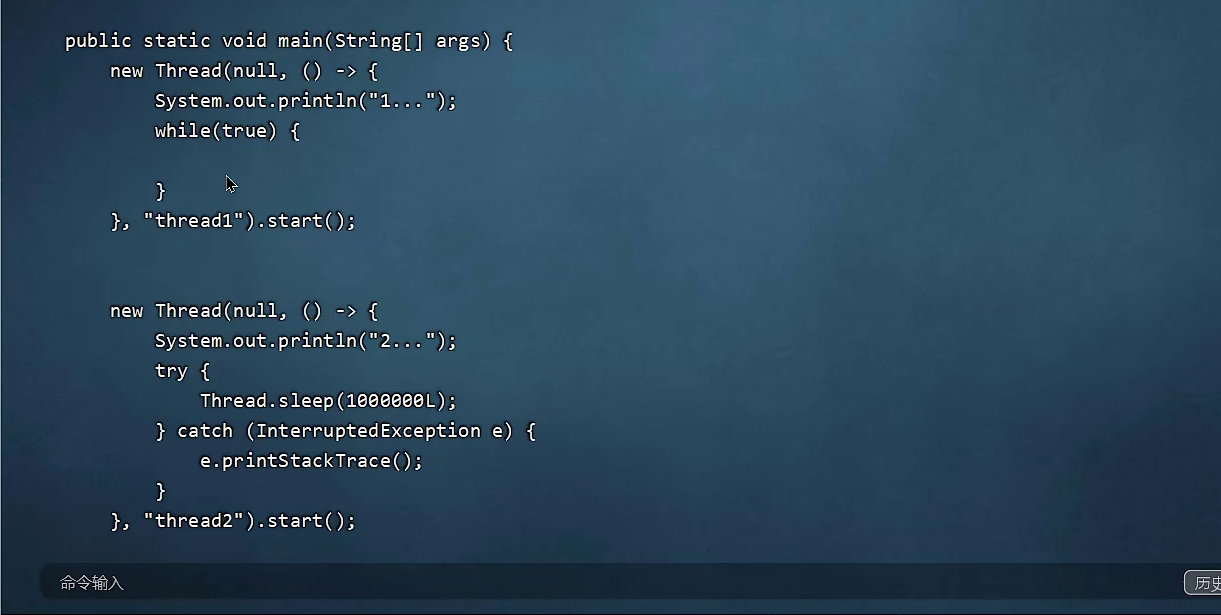
因为thread1有一个死循环导致CPU占用飙升。
小结:

总结: JVM调优和故障排查是一个系统性工程,需要理论、工具和实践经验的结合。掌握参数设置、熟悉常用工具链、并拥有清晰的内存和CPU问题排查思路,是保障Java应用稳定高性能运行的基石。建议在开发环境中多使用 VisualVM、Arthas 等工具进行探索,积累经验。