Video-of-Thought论文阅读

2024.5
1.摘要
background
现有的视频理解研究在处理复杂视频时,难以实现深入的理解和推理。这主要源于两大瓶颈:一是在感知层面,缺乏对时空细节的细粒度(fine-grained)感知和定位能力;二是在认知层面,缺乏对视频场景的深层语义理解和常识推理能力。现有模型通常只能进行浅层的、直接的视频内容识别,而无法像人一样进行多步推理,例如解释事件原因或预测未来结果。
innovation
为了解决上述问题,论文提出了两个核心创新点:
1.MotionEpic模型: 这是一个新颖的视频多模态大语言模型(MLLM)。它的核心创新在于集成了时空场景图(Spatial-temporal Scene Graph, STSG)。通过学习将视频内容解析为结构化的STSG(包含物体、关系、动作及其时序变化),MotionEpic能够实现像素级别的精准时空定位和关系理解。这直接解决了细粒度感知不足的问题。
2.Video-of-Thought (VoT)推理框架: 这是本文最主要的贡献。VoT是一个借鉴了语言模型中思维链(Chain-of-Thought, CoT)思想的、专门为视频设计的分步式推理框架。它将一个复杂的视频问答任务分解为从低阶感知到高阶认知的五个连续步骤:目标识别 -> 物体追踪 -> 行为分析 -> 排序问答 -> 答案验证。
2. 方法 Method
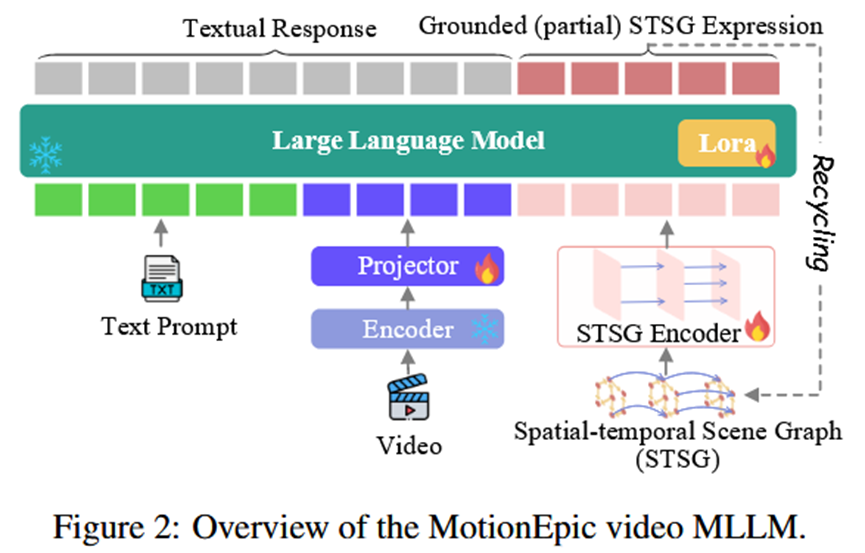
论文的方法可以分为作为核心引擎的MotionEpic模型和作为顶层设计的VoT推理框架。
总体 Pipeline (VoT框架):
VoT框架将复杂的视频问答任务分解为严格的五步,每一步都通过向MotionEpic模型提问来完成。
输入: 一个视频 + 一个复杂问题。
输出: 一个经过验证的、合理的答案。
Pipeline详解:
1.Step-1: 任务定义与目标识别 (Task Definition and Target Identification):
输入: 原始视频和问题。
任务: 分析问题,识别出需要在视频中重点关注的关键目标(如“红色的卡车”、“穿蓝色衣服的男人”)。
输出: 文本形式的目标列表。
2.Step-2: 物体追踪 (Object Tracking):
输入: 视频和上一步识别出的目标。
任务: 利用MotionEpic的细粒度定位能力,生成这些目标在视频中的时空轨迹,以部分STSG的形式表示。
输出: 描述目标时空位置和关系的STSG片段(作为后续步骤的“视觉证据”)。
3.Step-3: 行为分析 (Action Analyzing):
输入: 上一步生成的STSG轨迹和相关的场景信息。
任务: 结合STSG提供的结构化信息和LLM内置的常识知识,对目标的行为及其潜在意图进行深入分析和描述。
输出: 对目标行为和场景含义的详细文本描述(例如,“白色的卡车正在社区里收集垃圾”)。
4.Step-4: 排序问答 (Question Answering via Ranking):
输入: 原始问题、候选答案以及上一步生成的行为分析。
任务: 模型对每个候选答案进行打分(1-10分),并给出打分的理由。最后根据分数高低选出最合理的答案。(对于开放式问题,会先让模型生成几个候选答案)。
输出: 最终选择的答案。
5.Step-5: 答案验证 (Answer Verification):
输入: 上一步选出的答案和整个推理过程的信息。
任务: 从两个维度对答案进行“反思验证”:1)感知层面:答案是否与视频中的客观事实(像素证据)相符?2)认知层面:答案中蕴含的常识逻辑是否与之前的行为分析一致,有无矛盾?
输出: 确认答案正确,或如果发现矛盾则返回上一步重新选择。
核心模型 (MotionEpic):MotionEpic是实现VoT框架的基础。
输入: 文本、视频、STSG。
架构: 由一个LLM主干(Vicuna-7B)、一个视频编码器(ViT-L/14 + Q-Former)和一个用于编码STSG的图 Transformer 组成。
关键能力: 通过专门的细粒度 grounding-aware 微调,使MotionEpic不仅能理解视频,还能根据视频自主地解析(parse)出STSG。这种将视频像素内容与结构化语义符号(STSG)双向关联的能力,是其能够完成精确追踪和分析的关键。
3. 实验 Experimental Results
数据集:
复杂视频问答(微调): VLEP, STAR, IntentQA, Social-IQ, Causal-VidQA, NExT-QA等8个基准。
零样本问答: MSR-VTT, ActivityNet。
Grounding能力预训练: Action Genome (人工标注的STSG), WebVid (自动解析的STSG)。
实验结论:
1.主要性能对比: 在所有复杂视频问答基准上,MotionEpic + VoT框架的性能显著超过了所有现有的SOTA模型,也远优于在同样模型上使用标准CoT提示的方法。这证明了VoT框架在处理复杂推理上的巨大优势。
2.零样本性能: 在零样本场景下,VoT相比标准CoT的提升更为明显,这表明该框架具有很强的泛化能力,能够处理未见过的数据集上的复杂认知任务。
3.Grounding能力探究: 实验证明MotionEpic在STSG解析任务(如物体定位、关系分类、动作定位)上达到了与专用SOTA模型相当甚至接近人类的水平,这证实了其具备VoT框架所需要的坚实感知基础。
4.消融实验: 对比移除VoT中的验证步骤,性能会下降,证明了验证环节的必要性。同时,对 grounding-aware 微调的各项任务进行消融,也证明了这些细粒度训练目标对模型能力的提升至关重要。
4. 总结 Conclusion
这篇论文的核心信息是,通过显式地将复杂视频推理过程分解为从感知到认知的多个步骤(VoT框架),并依赖一个具备强大细粒度时空定位能力的新模型(MotionEpic),可以显著提升机器对复杂视频的深度理解和推理能力,达到新的SOTA水平。这为解决视频理解领域的认知瓶颈提供了一个非常有效且符合人类直觉的解决方案。