[linux仓库]肝爆进程通信:匿名管道、命名管道、进程池核心原理与实战【万字长文】
🌟 各位看官好,我是egoist2023!
🌍 Linux == Linux is not Unix !
🚀 今天来学习进程通信的相关内容:匿名管道、命名管道、进程池。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享更多人哦!

进程通信的产生
如果未来进程之间要协同,一个进程要把自己的数据交给另一个进程!或者一个进程要命令另外一个进程做其他事!
但是呢,由于进程之间是具有独立性的 ! 如果想把一个进程的数据交给另一个进程….基本不可能!
由此诞生出如何进程通信.
如何做到进程通信
进程之间是有独立性的?还需要保证这两之间可以进行通信,由此我们被迫使用第三者,他可以对这两进程通信起来.那他是谁呢?无疑我们第一个想到的便是操作系统.
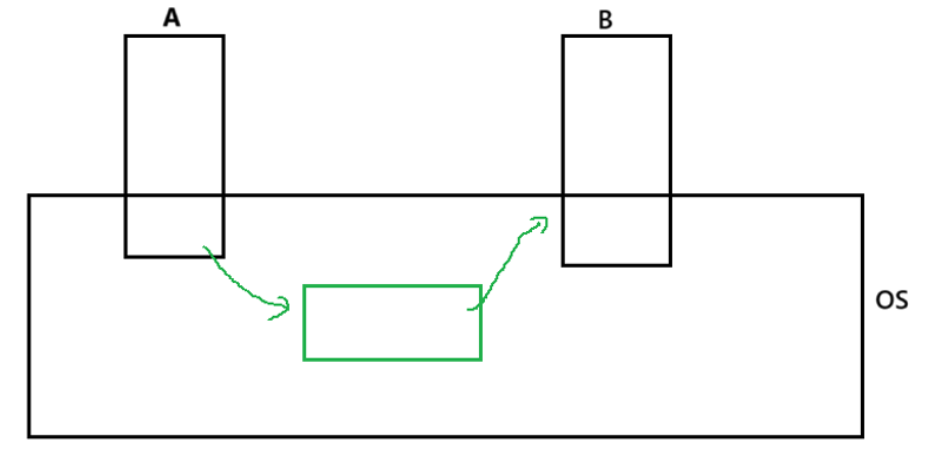
结论:进程间通信的前提:让不同的进程看到同一份资源.这份资源由OS提供,而资源一定是某种形式的内存空间!
进程通信目的
- 数据传输:⼀个进程需要将它的数据发送给另⼀个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:⼀个进程需要向另⼀个或⼀组进程发送消息,通知它(它们)发⽣了某种事件(如进程终⽌时要通知⽗进程)。
- 进程控制:有些进程希望完全控制另⼀个进程的执⾏(如Debug进程),此时控制进程希望能够拦截另⼀个进程的所有陷⼊和异常,并能够及时知道它的状态改变
进程通信分类及发展背景
既然有了对进程通信概念理解,那么让进程实现通信就落实到资源这一块问题了
进程通信分类如图所示:

我们前面有接触过管道,但是并没有谈及具体含义,现在就可以来解决这个问题了.
大火都清楚,我们程序员是非常"偷懒"的,有可以复用的代码绝不会多写一遍,实际上这也是一种"巧智",从某方面提高了可维护性.
管道就是一种"取巧"的方式,它是基于文件的通信方法.
但是随着时代的发展,大家发现管道并不能解决所有问题,由于一批新问题的产生导致程序员必须创造一个真正的资源,供进程间通信,由此产生了System V标准和消息队列等...
System V进程间通信 --> 单独设计通信模块 -->窊定标准了 -->只能进行本地通信(自己的电脑)
这里谈及下System V的生态问题:
System V 标准并非由单一公司定制,而是由AT&T(美国电话电报公司) 主导开发的一套 UNIX 操作系统标准。
实际上定标准 和 实现标准对应的代码 是两批人.
一般定标准的人都是不需要定标准的,而是有另一层进行代码编写.那为什么另一层凭什么听从定标准的人呢?因为定标准的人在技术上一定是处于技术领先的地位 --> 这意味着他的产品领先 --> 我所定下的标准,时代会跟着走.如果你不跟着我的标准走,那么你就被时代淘汰,就会没落.反之,如果你跟着我定的方向走,就能继续发展. --> 从而使你被迫听从定标准的这批人.
管道概念
我们把从⼀个进程连接到另⼀个进程的⼀个数据流称为⼀个“管道” :
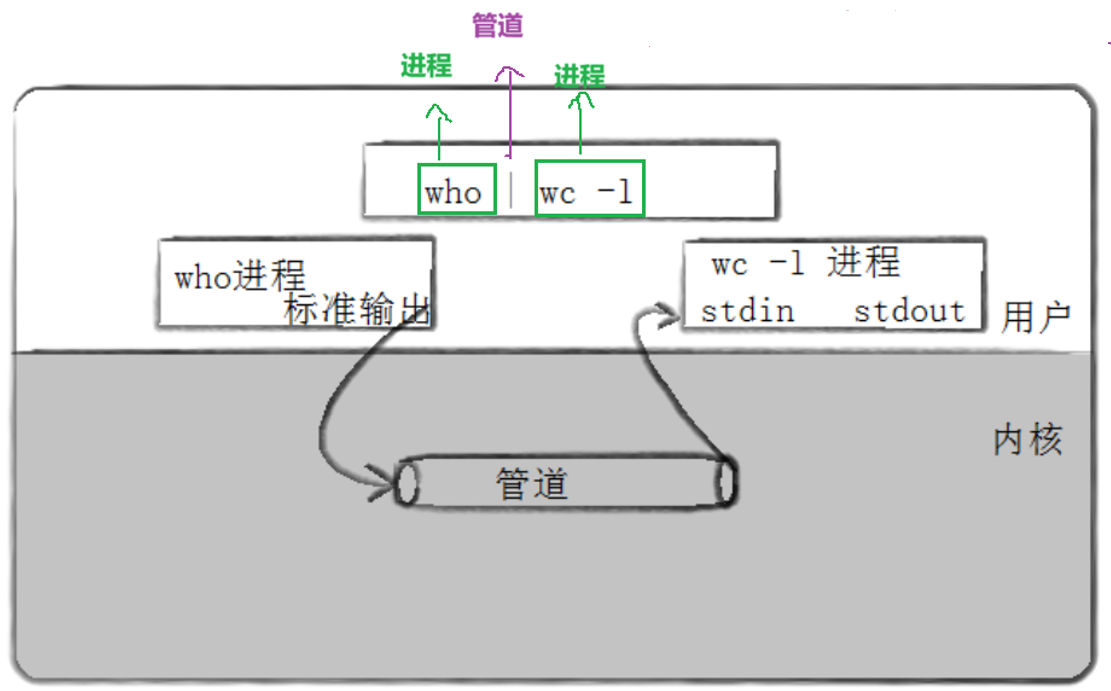
如何证明 | 两边都是进程呢?
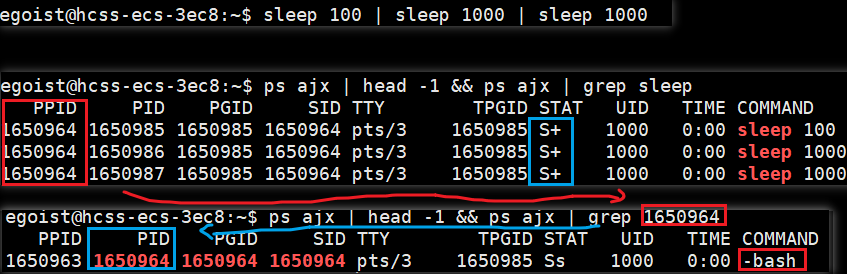
- 在 Linux 系统中,每个进程都有唯一的进程号PID ,通过ps工具确实观察到有三个进程,且有唯一的进程号.
- 它们的状态都为S+,表明是正在运行的进程.
- 既然它们的父进程都相同,打印父进程发现是bash shell,说明三者是并发执行的.
匿名管道
fork共享管道原理
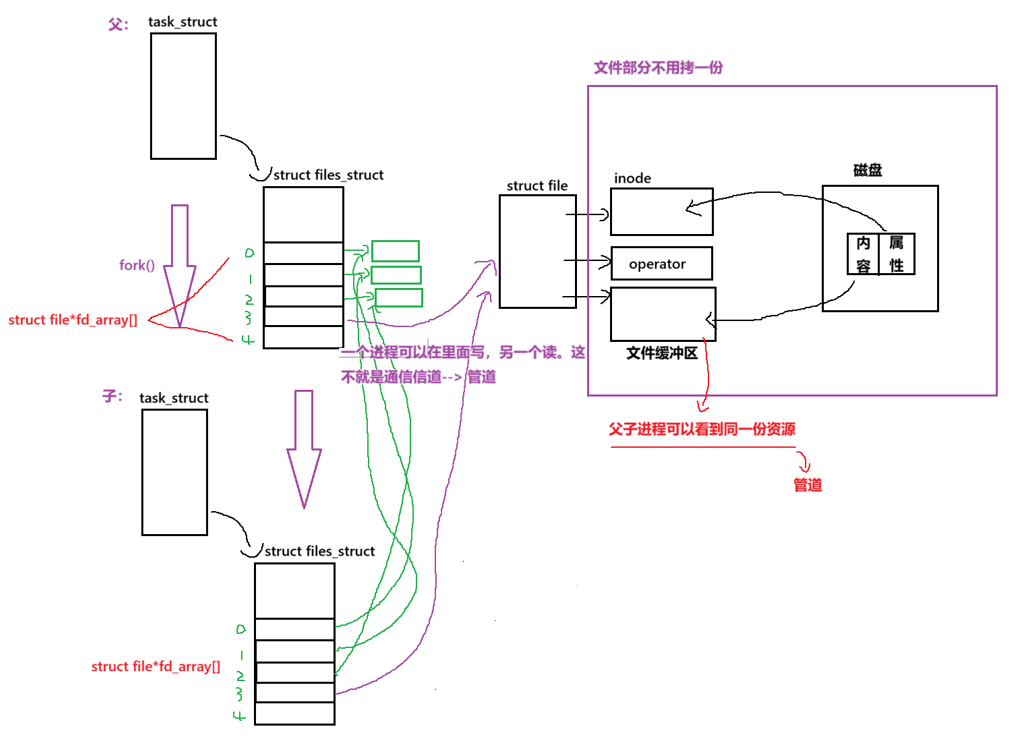
我们之前写过让父子进程同时向显示器进行打印内容,这是如何做到的呢?
让父子进程看到了同一份资源.在上图中,父进程创建子进程,子进程会以拷贝父进程的内核数据结构,此时父子都指向一个struct file,那么struct file里是什么呢?里面不是有个文件缓冲区吗?这不意味着父子看到了同一份资源?那么就可以基于这个原理进行进程的通信.
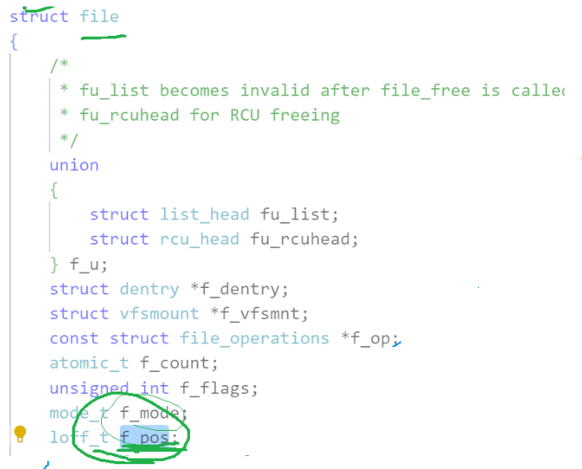
文件描述符角度 - 理解管道
父子进程可以看到同一份资源了,但是会出现一个问题:如果父进程写到101位置时,此时位置是停留在101这个位置的,此时子进程读是往101后读,因此会读到空内容。为了实现父子进程之间的通信,我们不得不让struct file也拷贝一份,这样便能实现父子进程间的通信.实际上,这便是管道的设计原理.
管道的定义:管道是一个基于文件系统的一个内存级的单向通信的文件,主要用来进程间通信(IPc.>Inter-Process Communication)的
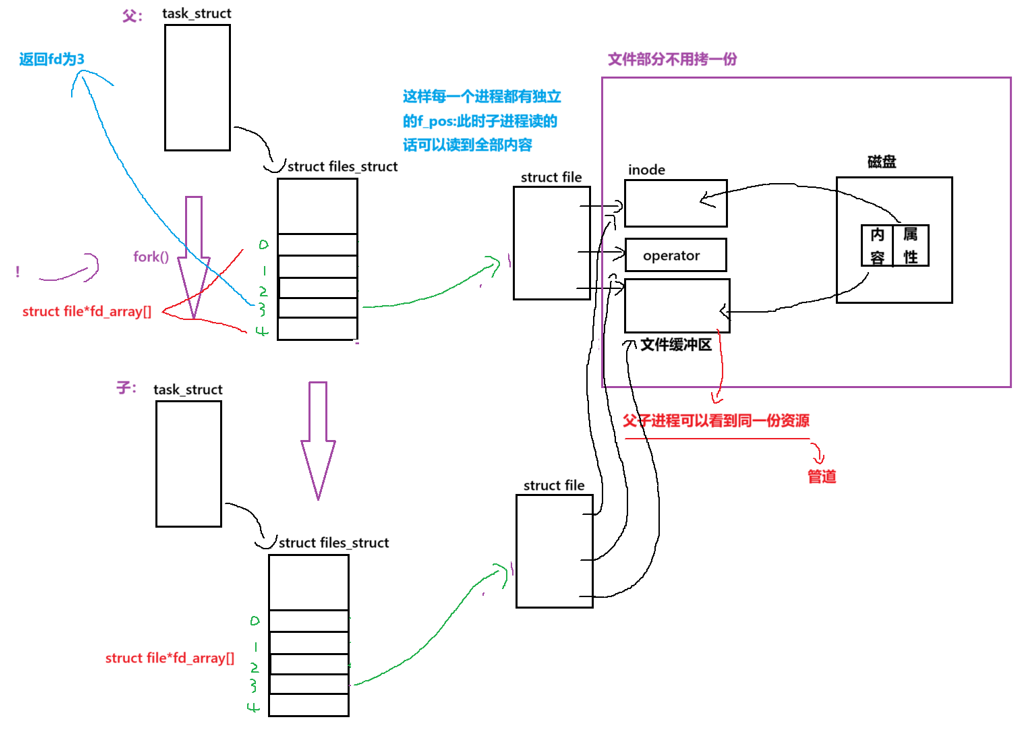
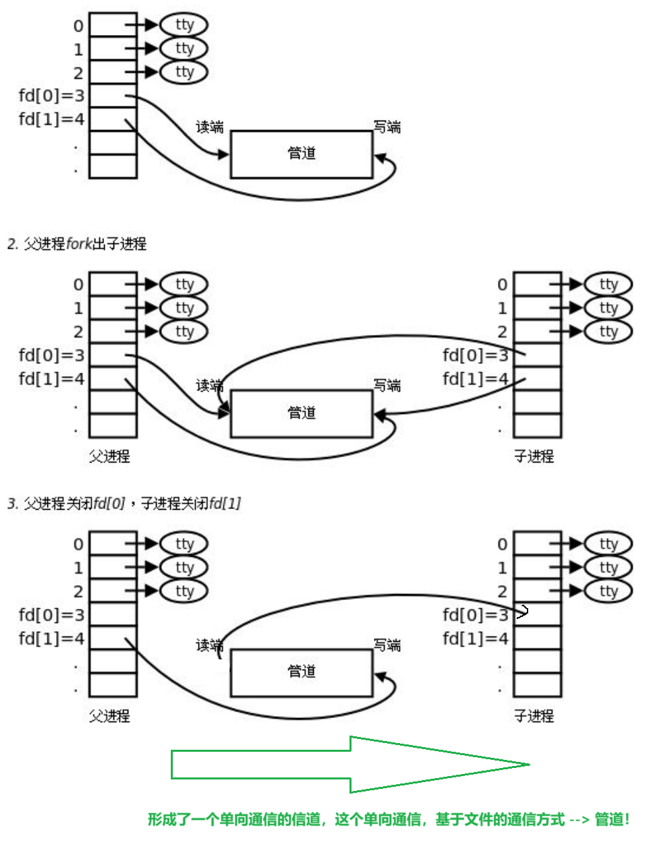
父进程要以“读写”两种方式 打开 同一个 管道文件
1.为什么要读写打开? --> 如果只打开读,那么子只能继承读,写也同理 --> 让子进程,也继承rw方式
如果是父写子读,那么要关闭对应的读写端
2.为什么要关闭读写端? --> 管道只需要单向通信 --> 定位:简单快速易上手(不关闭也可以,但建议 --> 防止误操作!)
3.如果要让两个进程互相通信呢? --> 创建两个管道!
内核角度 - 管道本质
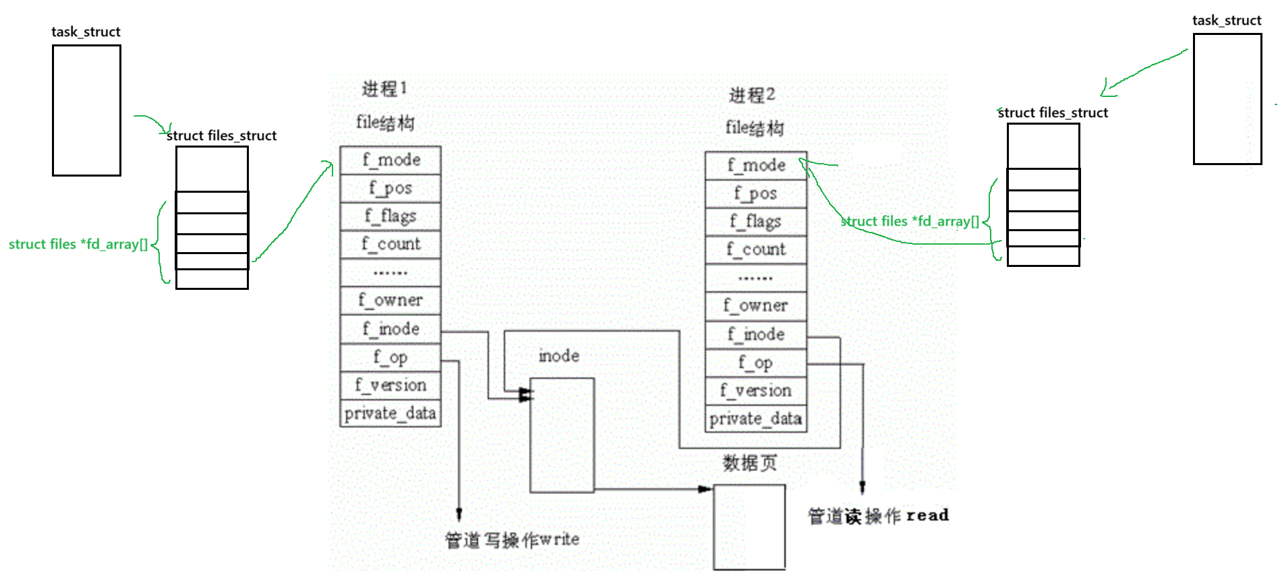
看待管道,就如同看待⽂件⼀样!管道的使⽤和⽂件⼀致,迎合了“Linux⼀切皆⽂件思想”。
管道实操
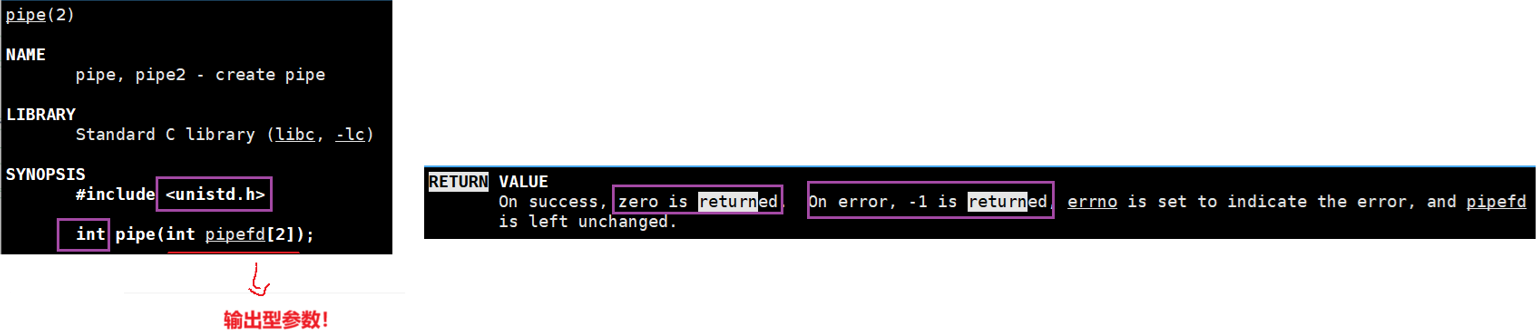

- 创建匿名管道
- [0]表示:读fd , [1]表示:写fd
- 成功返回0,失败返回错误代码
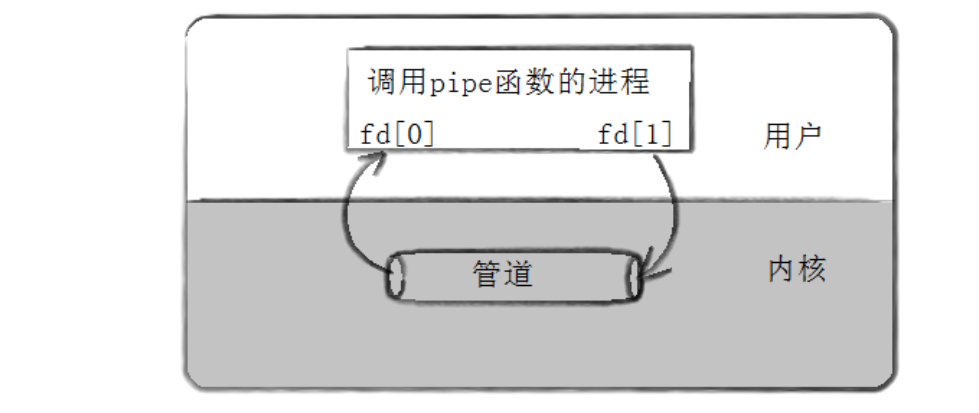
- 打开父进程的读写端
- 父进程创建子进程,子进程能继承父进程读写方式
- 这里实现父读子写,因此父关闭1,子关闭0.
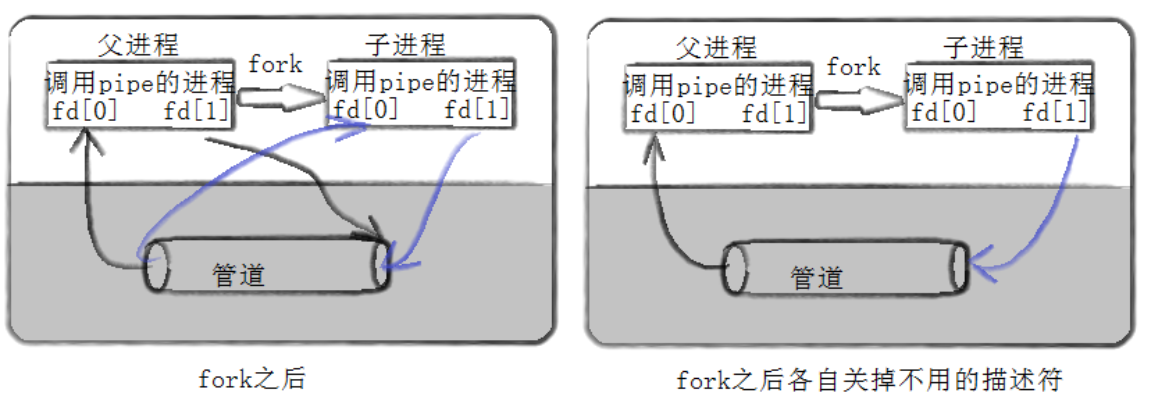
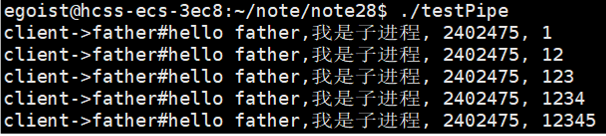
父子进程打开了这个文件,同时可以实现读写功能.但是,我们的这个文件是没有文件名的啊!这说明该文件是内存级文件! 没有名字 --> 称为匿名管道
既然是内存级文件,那么就不存在所谓的向磁盘刷新的概念,因此也不需要路径,文件名概念.
实际上,这种通信方式存在一定的缺陷:
父进程定义全局数据,本来就可以被子进程所看到啊!!!但子进程定义的缓冲区父进程看不到,进行不了通信。如果要对数据进行修改呢,如何做呢?所以说管道是一种单向通信.
管道4种情况、5大特性
5大特性:
- 常用于具有血缘关系的进行,进行IPC,常用于父子
- 单向通信
- 管道的生命周期进程
- 面向字节流 --> 网络讲
- 管道自带同步机制! --> 多线程讲
4种情况
写端不关,写端不写
管道里面没有数据,读端就会被阻塞!

读端不关,读端不读
管道被写满了的话,就不在写入了!
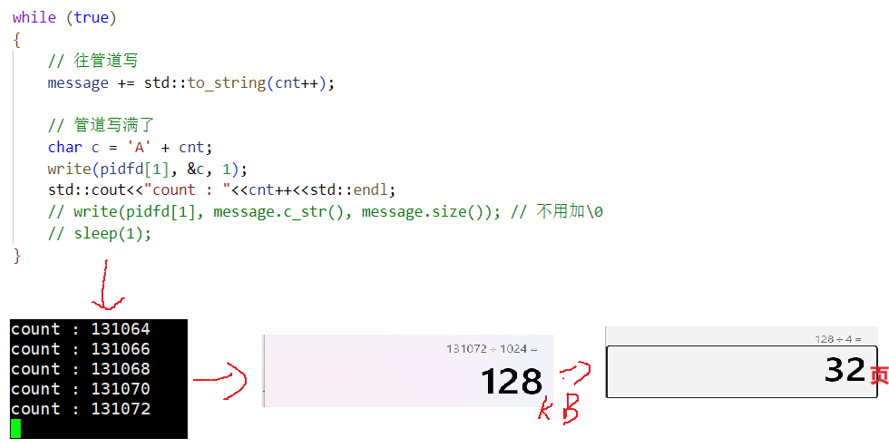
写端不写,写端关闭
read会读到返回值为0,表示读到文件结尾!
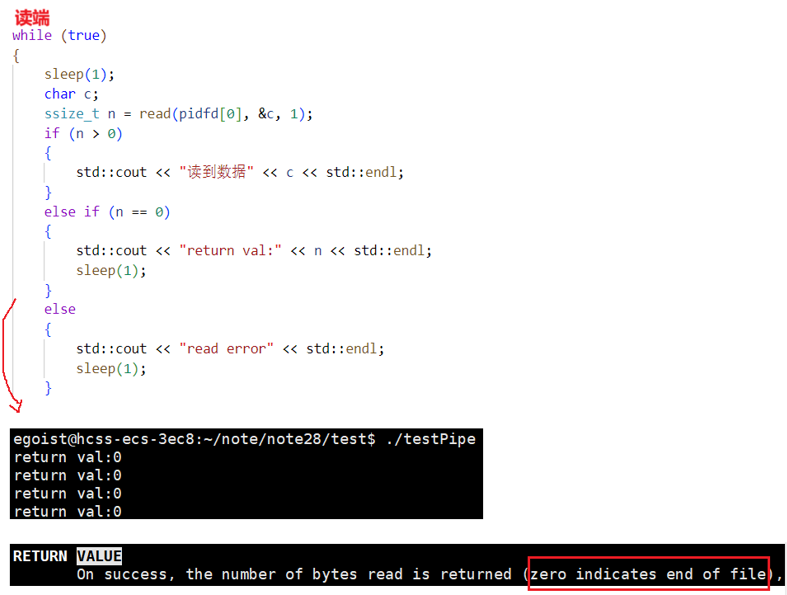
读端关闭,写端正常
OS会自动杀掉写进程!为什么这样做呢?OS不会做无效动作,不会做浪费时间的事!

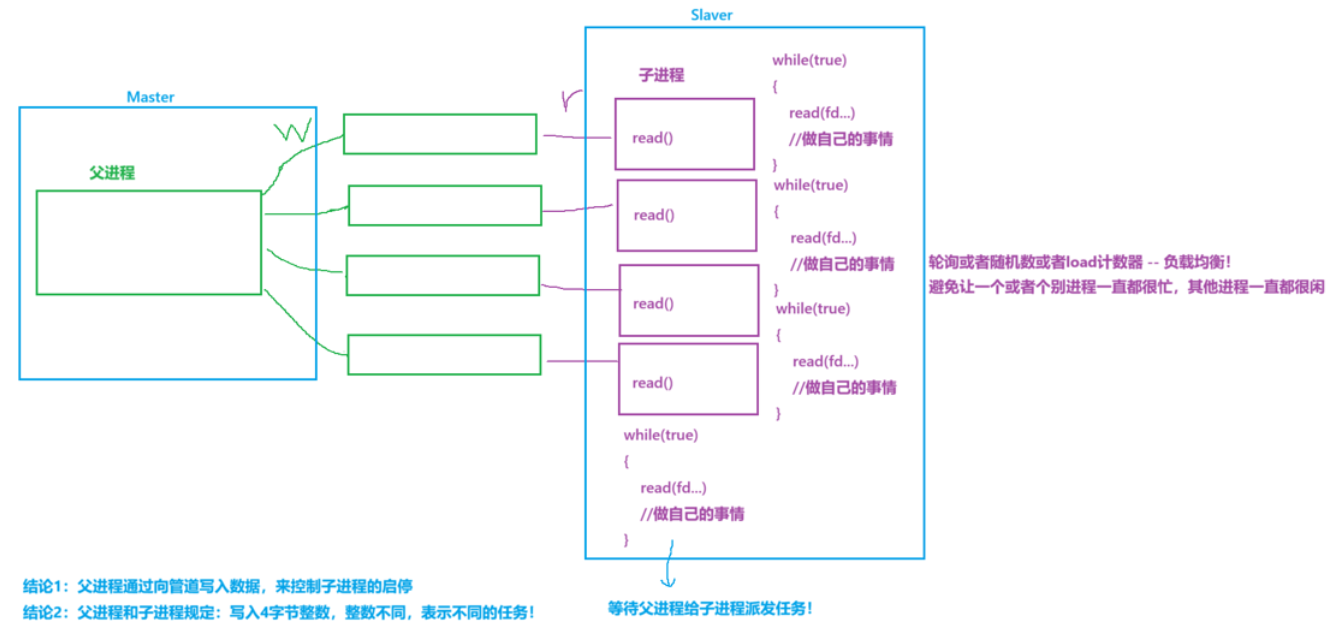
进程池
生活中,我们常常会听遣父母的安排,母亲对大儿说:最近工作有些累,帮母亲锤下背;对二女说:劳烦女儿今天扫扫地,倒下垃圾;对三孩说:再过一会要炒菜了,把刚买的白菜清洗下.三个孩子都等待着父母给他们派发任务.而在计算机中,匿名管道也可以实现这种需求.
Task.hpp
#pragma once#include <iostream>
#include <string>
#include <vector>
#include <functional>
// 4种任务
// task_t[4];using task_t = std::function<void()>;void Download()
{std::cout << "我是一个downlowd任务" << std::endl;
}void MySql()
{std::cout << "我是一个 MySQL 任务" << std::endl;
}void Sync()
{std::cout << "我是一个数据刷新同步的任务" << std::endl;
}void Log()
{std::cout << "我是一个日志保存任务" << std::endl;
}std::vector<task_t> tasks; // 任务表class Init
{
public:Init(){tasks.push_back(Download);tasks.push_back(MySql);tasks.push_back(Sync);tasks.push_back(Log);}
};Init ginit;
ProcessPool.hpp
#ifndef __PROCESS_POOL_HPP__
#define __PROCESS_POOL_HPP__#include <iostream>
#include <cstdlib>
#include <string>
#include <vector>
#include <functional>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <ctime>
#include "Task.hpp"const int gdefault_process_num = 5;
// typedef std::function<void (int fd)> func_t;
using callback_t = std::function<void(int fd)>;// 先描述
class Channel
{
public:Channel(){}Channel(int fd, const std::string &name, pid_t id) : _wfd(fd), _name(name), _sub_target(id){}void DebugPrint(){printf("channel name: %s, wfd: %d, target pid: %d\n", _name.c_str(), _wfd, _sub_target);}~Channel() {}int Fd() { return _wfd; }std::string Name() { return _name; }pid_t Target() { return _sub_target; }void Close() { close(_wfd); }void Wait(){pid_t rid = waitpid(_sub_target, nullptr, 0);(void)rid;}private:int _wfd;std::string _name;pid_t _sub_target; // 目标子进程是谁// int _load; //
};class ProcessPool
{
private:void CtrlSubProcessHelper(int &index){// 1. 选择一个通道(进程)int who = index;index++;index %= _channels.size();// 2. 选择一个任务,随机int x = rand() % tasks.size(); // [0, 3]// 3. 任务推送给子进程std::cout << "选择信道: " << _channels[who].Name() << ", subtarget : " << _channels[who].Target() << std::endl;write(_channels[who].Fd(), &x, sizeof(x));sleep(1);}public:ProcessPool(int num = gdefault_process_num) : _processnum(num){srand(time(nullptr) ^ getpid() ^ 0x777);}~ProcessPool(){}bool InitProcessPool(callback_t cb){for (int i = 0; i < _processnum; i++){sleep(1);// 1. 创建了管道int pipefd[2] = {0};int n = pipe(pipefd);if (n < 0)return false;// 2. 创建子进程pid_t id = fork();if (id < 0)return false;if (id == 0){// child, read// 3. 关闭不需要的rw端,形成信道close(pipefd[1]);// 子进程应该干什么事情啊??cb(pipefd[0]);exit(0);}// father, writeclose(pipefd[0]);std::string name = "channel-" + std::to_string(i);_channels.emplace_back(pipefd[1], name, id);}return true;}// 2. 控制唤醒指定的一个子进程,让该子进程完成指定任务// 2.1 轮询选择一个子进程(选择一个信道) -- 负载均衡void PollingCtrlSubProcess(){int index = 0;while (true){CtrlSubProcessHelper(index);}}void PollingCtrlSubProcess(int count){if (count < 0)return;int index = 0;while (count){CtrlSubProcessHelper(index);count--;}}void RandomCtrlSubProcess(){}void LoadCtrlSubProcess(){}void ProcessPoolPrintFd(){std::cout << "进程池wfd list: ";for(auto &c : _channels)std::cout << c.Fd() << " ";std::cout << std::endl;}// 我们的代码,其实是有一个bug 的!void WaitSubProcesses(){// for(int end = _channels.size()-1; end >= 0; end--)// {// _channels[end].Close();// _channels[end].Wait();// }for (auto &c : _channels){c.Close();c.Wait();}// // 1. 先让所有子进程结束// for (auto &c : _channels)// {// c.Close();// }// // 2. 你在回收所有的子进程僵尸状态// for (auto &c : _channels)// {// c.Wait();// std::cout << "回收子进程: " << c.Target() << std::endl;// }}private:// 在组织std::vector<Channel> _channels; // 所有信道int _processnum; // 有多少个子进程
};
main.cc
#include "ProcessPool.hpp"int main()
{// 1. 创建进程池ProcessPool pp(5);// 2. 初始化进程池pp.InitProcessPool([](int fd){while(true){int code = 0;//std::cout << "子进程阻塞: " << getpid() << std::endl;ssize_t n = read(fd, &code, sizeof(code));if(n == sizeof(code)) // 任务码{std::cout << "子进程被唤醒: " << getpid() << ", fd: " << fd << std::endl;if(code >= 0 && code < tasks.size()){tasks[code]();}else{std::cerr << "父进程给我的任务码是不对的: " << code << std::endl;}}else if(n == 0){std::cout << "子进程应该退出了: " << getpid() << std::endl;break;}else{std::cerr << "read fd: " << fd << ", error" << std::endl;break;}}});pp.ProcessPoolPrintFd();// 3. 控制进程池pp.PollingCtrlSubProcess(10);// 4. 结束线程池pp.WaitSubProcesses();std::cout << "父进程控制子进程完成,父进程结束" << std::endl;return 0;
}Bug问题
// 1. 先让所有子进程结束
for (auto &c : _channels)
{c.Close();
}
// 2. 你在回收所有的子进程僵尸状态
for (auto &c : _channels)
{c.Wait();std::cout << "回收子进程: " << c.Target() << std::endl;
}在回收子进程的时候,我们让子进程的读端关闭,此时写端是正常写的,但是OS不会做浪费时间的事,因此会杀掉该进程,而我们利用这一情况,将所有子进程的读端全部关闭,再全部进行回收.
但实际上,我们会发现这两者是可以合并在一起的啊!!!可以边关闭对应的子进程的读端,边进行回收,完全是可以放在一个循环体里的.
for (auto &c : _channels)
{c.Close();c.Wait();
}但是回收子进程却发现报错了,这是为什么?实际上这个原因很难发现,因为要对底层细节剖析的非常明白才能解决,接下来小编说明出bug的原因:
- 创建管道父进程打开读写端,即3和4下标被占,创建子进程.父进程关闭fd为3的下标,即关闭读端口;子进程关闭fd为4的下标,即关闭写端口.
- 再次创建管道,由于此时3位置为空了,所以fd为3的下标为读端口,fd为5的下标为写端口.创建子进程,再次关闭父子对应的读写端口.
- 在这里我们就会发现一个问题,子进程不仅继承了fd为3和5的下标,还继承了fd为4的下标,指向了第一个信道;
- 由此循环下去,只有最后一个管道由子进程连着.
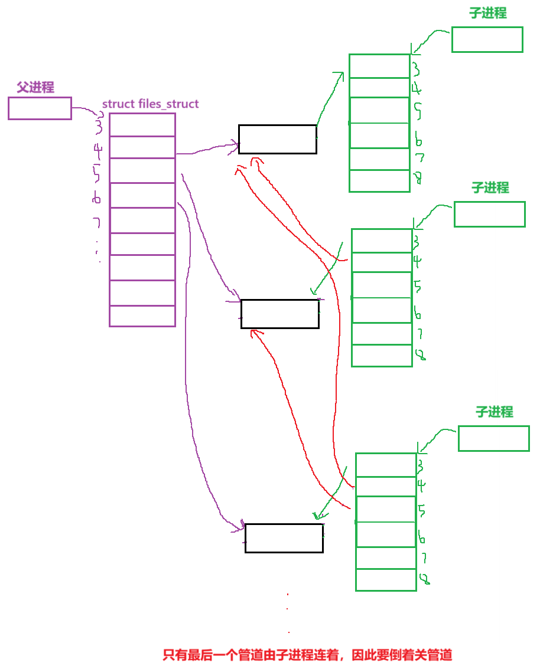
既然最后一个管道由子进程连着,那么我们倒着关管道,同时回收子进程不就可以了?
for(int end = _channels.size()-1; end >= 0; end--)
{_channels[end].Close();_channels[end].Wait();
}但是这种实现方式不太符合逻辑,且实现的不够优雅,实在想正着回收子进程,该如何做呢?
// 子进程除了要关闭自己的w,同时也要关闭,自己从父进程哪里继承下来的所有的之前进程w端
//我的子进程,要关闭的,从父进程哪里继承下来的wfd都在哪里??
// _channels本身是被子进程继承下去的.
// 1. 子进程不要担心,父进程会影响自己的_channels.
// 2. fork之后,当前进程,只会看到所有的历史进程的wfd,并不受后续父进程emplace_backd的影响
std::cout << "进程:" << getpid() << ", 关闭了: ";
for(auto &c : _channels)
{std::cout << c.Fd() << " ";c.Close();
}
std::cout <<"\n";命名管道
- 管道应⽤的⼀个限制就是只能在具有共同血缘关系的进程间通信。
- 如果我们想在不相关的进程之间交换数据,可以使⽤FIFO⽂件来做这项⼯作,它经常被称为命名管道。
- 命名管道是⼀种特殊类型的文件.
打开规则:
如果当前打开操作是为读⽽打开FIFO时:
- O_NONBLOCK disable:阻塞直到有相应进程为写⽽打开该FIFO
- O_NONBLOCK enable:⽴刻返回成功
如果当前打开操作是为写⽽打开FIFO时:
- O_NONBLOCK disable:阻塞直到有相应进程为读⽽打开该FIFO
- O_NONBLOCK enable:⽴刻返回失败,错误码为ENXIO
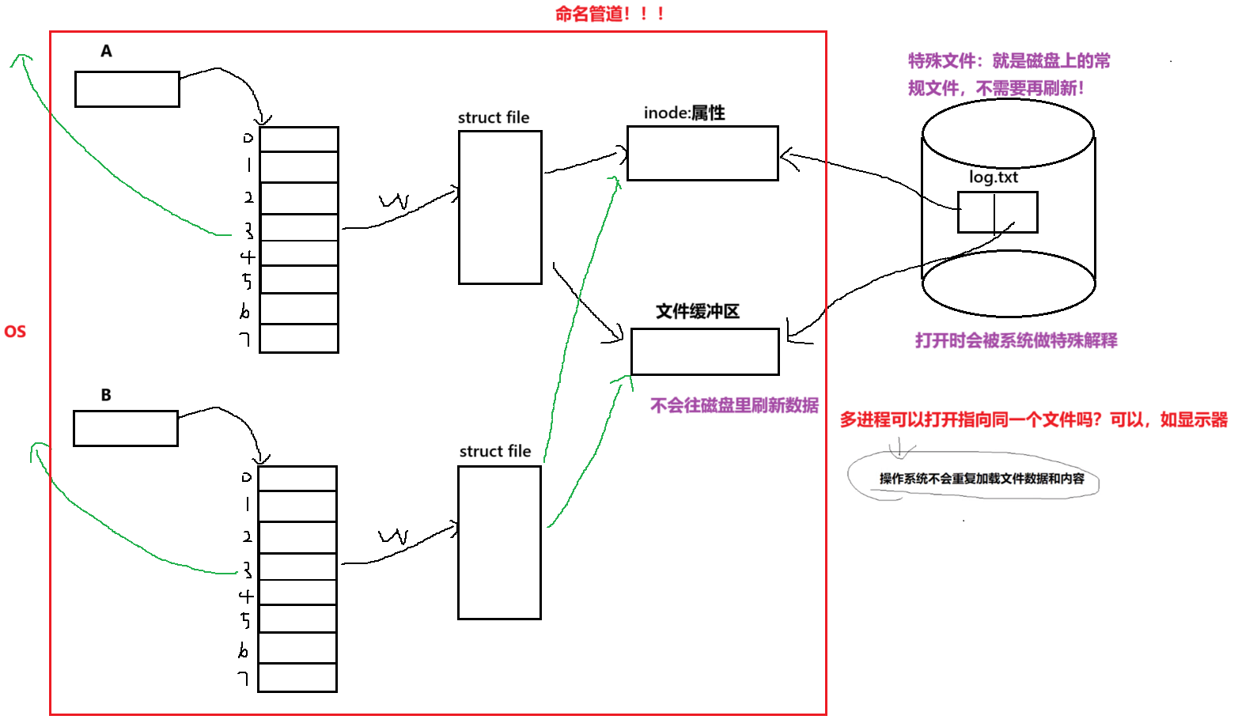
原理
匿名管道是在内存级进行申请资源的特殊处理,而命名管道则是在磁盘上申请的特殊文件.当该文件被打开时会被系统做特殊处理,其表现是这个文件不需要往磁盘上刷新.
实操文件拷贝
int mkfifo(const char *pathname, mode_t mode);
1.client和server是如何看到同一份资源的?--> Linux的路径是唯一的!路径+文件名是本质 -->唯一的inode
2.为什么mkfifo叫命名管道 -->因为文件就是有名字哇!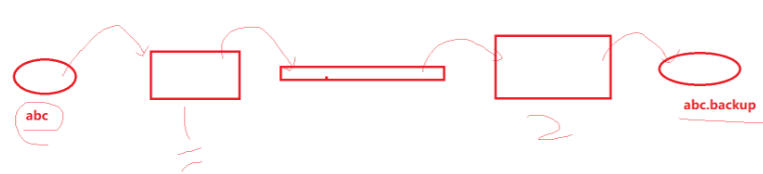
clinet创建管道 tp , 往abc文件读取内容,打开管道往管道里面写入内容;server端打开管道并进行读取内容,再往abc.backup写入内容,完成文件之间的拷贝.
client.cpp
//读取管道,写入命名管道
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include"common.hpp"#define ERR_EXIT(m) \do \{ \perror(m); \exit(EXIT_FAILURE); \} while (0)int main(int argc, char *argv[])
{mkfifo("tp", 0644);int infd;infd = open("abc", O_RDONLY);if (infd == -1)ERR_EXIT("open");int outfd;outfd = open("tp", O_WRONLY);if (outfd == -1)ERR_EXIT("open");char buf[1024];int n;while ((n = read(infd, buf, 1024)) > 0){write(outfd, buf, n);}close(infd);close(outfd);return 0;
}
server.cpp
//读取管道,写入目标文件
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include"common.hpp"#define ERR_EXIT(m) \do \{ \perror(m); \exit(EXIT_FAILURE); \} while (0)int main(int argc, char *argv[])
{int outfd;outfd = open("abc.bak", O_WRONLY | O_CREAT | O_TRUNC, 0644);if (outfd == -1)ERR_EXIT("open");int infd;infd = open("tp", O_RDONLY);if (outfd == -1)ERR_EXIT("open");char buf[1024];int n;while ((n = read(infd, buf, 1024)) > 0){write(outfd, buf, n);}close(infd);close(outfd);unlink("tp");return 0;
}server&client通信
common.hpp
#ifndef __COMMON_HPP__
#define __COMMON_HPP__#include<iostream>
#include <cstdio>
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>const std::string fifoname = "fifo";
mode_t mode = 0666;
//int size = 128;在Linux是能这样的
#define SIZE 128#endifNamePipe.hpp
#pragma once#include "common.hpp"const int defaultfd = -1;class NamedPipe
{
public:NamedPipe(const std::string &name) : _name(name), _fd(defaultfd){}~NamedPipe(){}bool Create(){int n = mkfifo(_name.c_str(), mode);if (n == 0){std::cout << "mkfifo success" << std::endl;}else{std::cout << "mkfifo failed" << std::endl;perror("mkfifo");return false;}return true;}void Close(){if (_fd == defaultfd)return;elseclose(_fd);}bool OpenForRead(){_fd = open(_name.c_str(), O_RDONLY);if (_fd < 0){perror("open");return false;}std::cout << "open file success" << std::endl;return true;}bool OpenForWrite(){_fd = open(_name.c_str(), O_WRONLY);if (_fd < 0){perror("open");return false;}return true;}// 输入参数:const &// 输出参数:*// 输入输出参数:&bool Read(std::string *out){char buffer[SIZE] = {0};ssize_t num = read(_fd, buffer, sizeof(buffer) - 1);if (num > 0){buffer[num] = 0;*out = buffer;}else if (num == 0){return false;}else{return false;}return true;}void Write(const std::string &in){write(_fd, in.c_str(), in.size());}void Remove(){int m = unlink(_name.c_str());(void)m;}private:// std::string _path;//path+namestd::string _name;int _fd;// std::string who;
};client.cpp
#include "NamedPipe.hpp"int main()
{NamedPipe named_pipe(fifoname);named_pipe.OpenForWrite();while (true){std::cout << "Please Enter# ";std::string line;std::getline(std::cin, line);named_pipe.Write(line);}named_pipe.Close();return 0;
}server.cpp
#include "NamedPipe.hpp"int main()
{NamedPipe pp(fifoname);pp.Create();pp.OpenForRead();std::string message;while (true){bool res = pp.Read(&message);if (!res)break;std::cout << "client say@" << message << std::endl;}// 归还资源pp.Close();pp.Remove();return 0;
}
因此,命名管道主要解决的是毫无关系的进程之间,进行文件级进程通信!!!

客户端关闭,写端还在读,返回值为0.
指令扩展:

总结
进程通信基础
- 必要性:进程独立性导致直接通信困难,需通过操作系统提供的共享资源实现
- 目的:数据传输、资源共享、事件通知、进程控制
- 分类:发展从管道到SystemV标准(消息队列等),再到现代通信方式
管道技术
-
匿名管道
- 特点:内存级单向通信,用于父子进程通信
- 原理:通过fork共享文件描述符实现
- 四种读写情况及五大特性
-
命名管道(FIFO)
- 特点:磁盘特殊文件,允许无关进程通信
- 实现:通过mkfifo创建,遵循特定打开规则
- 应用:文件拷贝、客户端-服务器通信
进程池实现
- 通过管道实现任务分发
- 子进程管理及资源回收机制
- 实际应用中的bug分析与解决方案
技术对比
- 匿名管道:简单快速,限于血缘关系进程
- 命名管道:更灵活,支持无关进程通信
