【提示工程】Ch3-最佳实践(Best Practices)
目录
- 提供示例(Provide examples)
- 设计以简洁为原则(Design with simplicity)
- 关于输出的具体性(Be specific about the output)
- 使用指令而非约束(Use Instructions over Constraints)
- 控制最大token长度(Control the max token length )
- 在提示中使用变量(Use variables in prompts )
- 尝试不同的输入格式和写作风格(Experiment with input formats and writing styles)
- 对于少样本提示中的分类任务,混合类别(For few-shot prompting with classification tasks, mix up the classes)
- 适应模型更新(Adapt to model updates)
- 尝试输出格式(Experiment with output formats)
- JSON 修复(JSON Repair)
- 使用 Schema(Working with Schemas)
- 与其他提示工程师一起实验(Experiment together with other prompt engineers)
- CoT 最佳实践(CoT Best practices)
- 记录各种提示尝试(Document the various prompt attempts)
- 总结(Summary)
提供示例(Provide examples)
最重要最佳实践是提供提示中的(单次/少次)示例。这非常有效,因为它充当一个强大的教学工具。这些示例展示期望的输出或类似响应,让模型从中学习并相应调整其生成。就像给模型一个参考点或目标一样,以提高其响应的准确性、风格和语气,使其更好地符合您的期望。
设计以简洁为原则(Design with simplicity)
提示应简洁、清晰,易于您和模型理解。作为经验法则,如果您觉得提示已经令人困惑,那么模型很可能也会觉得困惑。尽量不要使用复杂的语言,也不要提供不必要的信息。
示例:
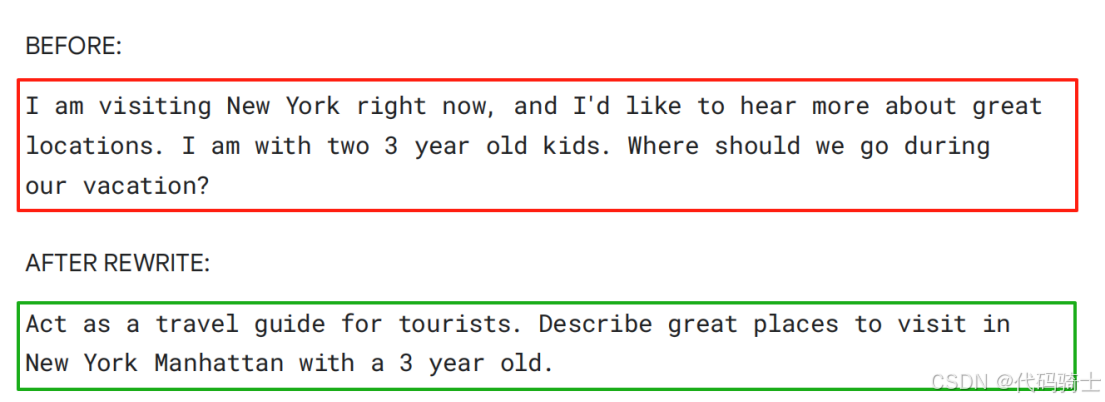
尝试使用描述动作的动词。以下是一组示例:

关于输出的具体性(Be specific about the output)
请对所需的输出做出具体说明。一个简洁的指令可能不足以指导LLM,或者过于笼统。提供具体的细节(通过系统或上下文提示)可以帮助模型专注于相关内容,从而提高整体准确性。
示例:

使用指令而非约束(Use Instructions over Constraints)
指令和约束用于通过提示引导LLM的输出。
指令提供了关于所需格式、风格或内容的明确指导。它指导模型应做什么或生成什么。
约束是一组对响应的限制或边界。它限制模型不应做什么或避免什么。
日益增长的研究表明,关注提示中的积极指令可能比过多依赖约束更有效。这种方法与人类更倾向于积极指令而非“不要做什么”的清单相符。
指令直接传达期望的成果,而约束可能让模型猜测什么是允许的。指令在定义的边界内提供了灵活性和创造力,而约束可能限制模型的潜力。此外,约束清单还可能相互冲突。
约束在某些情况下仍有价值,例如防止模型生成有害或有偏见的内容,或当需要严格的输出格式或风格时。
如果可能,使用积极指令:与其告诉模型不要做什么,不如告诉它要做什么。这可以避免混淆并提高输出的准确性。
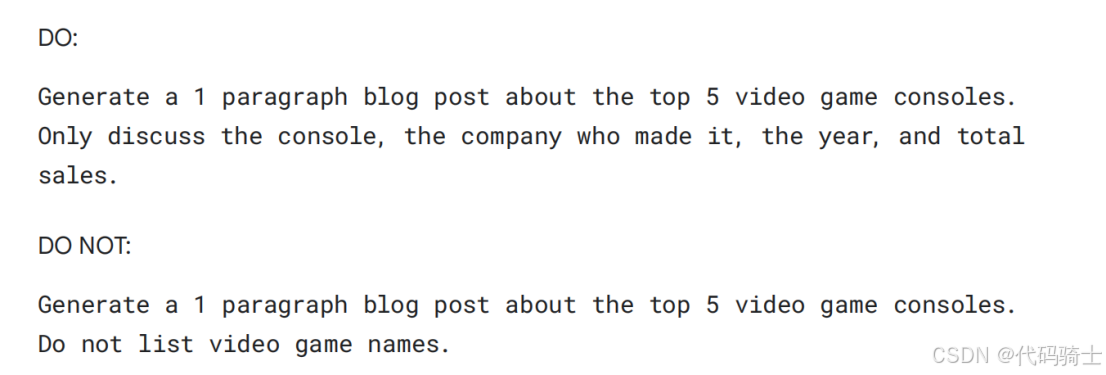
最佳实践是从优先考虑指令开始,明确说明你希望模型做什么,仅在必要时为安全、清晰或具体要求使用约束。实验并迭代,测试不同指令和约束组合,以找到最适合你特定任务的方法,并记录这些。
控制最大token长度(Control the max token length )
要控制生成LLM响应的长度,可以在配置中设置最大token限制,或在提示中明确请求特定长度。例如:
“用推文长度解释量子物理学。”
在提示中使用变量(Use variables in prompts )
要重用提示并使其更动态,可在提示中使用变量,这些变量可根据不同输入进行更改。例如,如表20所示,一个提示提供有关城市的事实,而不是在提示中硬编码城市名称,使用变量。变量可以节省时间和精力,允许你避免重复自己。如果需要多次使用同一信息,可以将其存储在变量中,然后在每个提示中引用该变量。这在将提示集成到你自己的应用中时非常有意义。

尝试不同的输入格式和写作风格(Experiment with input formats and writing styles)
不同模型、模型配置、提示格式、词语选择和提交方式可能会产生不同的结果。因此,尝试不同的提示属性(如风格、词语选择和提示类型(零样本、少样本、系统提示))非常重要。
例如,一个旨在生成关于革命性视频游戏主机Sega Dreamcast的提示,可以以问题、陈述或指令的形式表述,产生不同的输出:
问题:Sega Dreamcast是什么,它为何如此具有革命性?
陈述:Sega Dreamcast是世嘉于1999年发布的一款第六代视频游戏主机。…
指令:撰写一段描述Sega Dreamcast主机并解释其为何革命性的文字。
对于少样本提示中的分类任务,混合类别(For few-shot prompting with classification tasks, mix up the classes)
一般来说,少样本示例的顺序影响不大。然而,在进行分类任务时,请确保混合可能的响应类别。这是因为如果你不这样做,可能会过度拟合特定示例的顺序。通过混合可能的响应类别,可以确保模型学习识别每个类别的关键特征,而不仅仅是记住示例的顺序。这将导致更健壮且更具泛化能力的性能,适用于未见过的数据。
一个好的经验法则是从6个少样本示例开始,并从那里开始测试准确性。
适应模型更新(Adapt to model updates)
保持关注模型架构变化、添加数据和新能力很重要。尝试使用较新模型版本,并调整提示以更好地利用新模型功能。工具如Vertex AI Studio非常适合存储、测试和记录各种提示版本。
尝试输出格式(Experiment with output formats)
除了提示输入格式外,考虑尝试不同的输出格式。对于非创造性任务,如提取、选择、解析、排序、排名或分类数据,尝试让输出以结构化格式(如JSON或XML)返回。
从提示中提取数据的JSON对象有一些好处。在现实世界应用中,我无需手动创建JSON格式,模型已能按排序顺序返回数据(处理日期时间对象时非常方便),但最重要的是,提示使用JSON格式会迫使模型创建结构并限制幻觉。
总结,使用JSON作为输出的好处:
始终以相同风格返回
专注于你想接收的数据
减少幻觉的发生机会
使其具有关系意识
获取数据类型
您可以对其进行排序
Table 4 在 few-shot 提示部分展示了一个如何返回结构化输出的示例。
JSON 修复(JSON Repair)
以 JSON 格式返回数据具有众多优势,但也并非没有缺点。JSON 的结构化性质虽然对解析和应用有益,但相比纯文本需要显著更多的令牌,从而导致增加的处理时间和更高成本。此外,JSON 的冗长性很容易耗尽整个输出窗口,当生成因令牌限制而突然中断时尤其成问题。这种截断往往导致无效的 JSON,缺少关键的闭合括号或方括号,使输出无法使用。幸运的是,像 json-repair 库(可在 PyPI 上获得)这样的工具在这些情况下非常有用。该库能够智能地尝试自动修复不完整或格式错误的 JSON 对象,这在处理 LLM 生成的 JSON 尤其是面临潜在截断问题时尤为关键。
使用 Schema(Working with Schemas)
使用结构化 JSON 作为输出是一个很好的解决方案,正如我们在本文中多次看到的那样。但输入呢?虽然 JSON 对于结构化 LLM 生成的输出非常出色,它也可以非常有用地用于结构化您提供的输入。这就是 JSON Schema 发挥作用的地方。JSON Schema 定义了您 JSON 输入的预期结构和数据类型。通过提供一个 schema,您为 LLM 提供了一个清晰的蓝图,说明它应该期望的数据,从而帮助它将注意力集中在相关信息上,减少误解输入的风险。此外,schema 还可以帮助建立数据之间的关系,甚至通过包括具有特定格式的日期或时间戳字段,使 LLM 具备“时间感知”能力。
简单示例:
假设您想使用 LLM 为电子商务目录中的产品生成描述。不是仅仅提供产品的自由文本描述,您可以使用 JSON Schema 来定义产品的属性:

然后,你可以提供符合此模式的实际产品数据作为JSON对象:
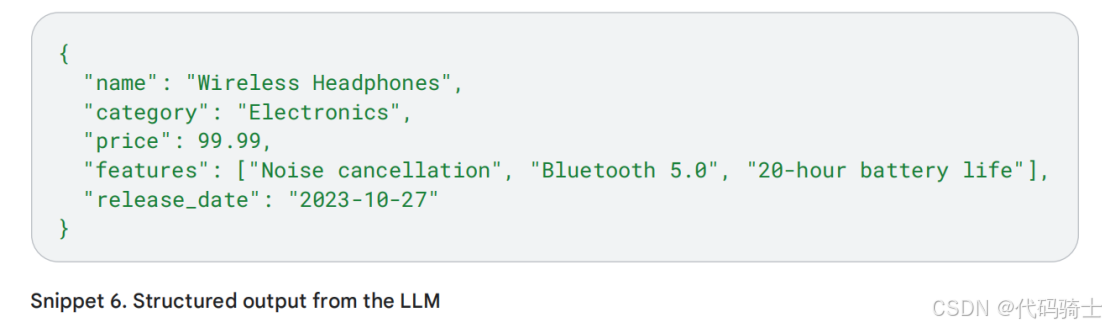
通过预处理您的数据,而不是仅提供完整文档,而是同时提供 schema 和数据,您为 LLM 提供了一个清晰的关于产品属性的理解,包括其发布日期,从而使其更有可能生成准确且相关的描述。这种结构化输入方法,引导 LLM 关注相关字段,在处理大数据量或将 LLM 集成到复杂应用程序中时尤为宝贵。
与其他提示工程师一起实验(Experiment together with other prompt engineers)
如果您处于需要尝试制定一个好提示的情况下,您可能希望找多个人一起尝试。当每个人都遵循本章列出的最佳实践时,您将在所有不同提示尝试之间看到性能的差异。
CoT 最佳实践(CoT Best practices)
对于 CoT 提示,将答案放在推理之后是必要的,因为生成推理会改变模型在预测最终答案时获取的令牌。
使用 CoT 和自我一致性时,您需要能够从提示中提取最终答案,并与推理分开。
对于 CoT 提示,将温度设置为 0。
思维链提示基于贪婪解码,通过预测序列中基于语言模型分配的最高概率的下一个词。通常来说,使用推理来得出最终答案时,很可能只有一个正确答案。因此,温度应始终设置为 0。
记录各种提示尝试(Document the various prompt attempts)
最后一个建议在本章中之前已提及,但我们无法强调其重要性:记录您的提示尝试的全部细节,以便您可以随着时间了解哪些有效,哪些无效。
提示输出可能因模型、采样设置甚至同一模型的不同版本而有所不同。此外,即使对同一模型使用完全相同的提示,输出句子格式和词语选择也可能出现细微差异。(例如,如前所述,如果两个token具有相同的预测概率,平局可能随机打破。这可能影响后续预测的token。)
我们建议创建带有 Table 21 的 Google Sheet 作为模板。这种方法的优点是您可以完整记录,当您不可避免地需要重新审视提示工作时(您会惊讶即使只是短暂中断后您会忘记多少),以便在未来拾起;在不同模型版本上测试提示性能;以及帮助调试未来的错误。
除了此表中的字段外,跟踪提示的版本(迭代)也很有帮助,一个字段来记录结果是 OK/NOT OK/SOMETIMES OK,以及一个字段来记录反馈。如果您有幸使用 Vertex AI Studio,请保存您的提示(使用与文档中列出的相同名称和版本),并在表中跟踪保存提示的超链接。这样,您始终只需点击一下即可重新运行提示。
在处理检索增强生成系统时,您还应该记录 RAG 系统影响提示中插入内容的具体方面,包括查询、块设置、块输出和其他信息。
一旦您感觉提示接近完美,将其整合到您的项目代码库中。在代码库中,将提示保存在单独文件中,以便于维护。最后,理想情况下,您的提示应是操作化系统的一部分,作为提示工程师,您应该依靠自动化测试和评估程序来了解提示在任务上的泛化能力。
提示工程是一个迭代过程。创建并测试不同提示,分析并记录结果。根据模型的性能优化您的提示。持续实验,直到达到理想输出。当您更换模型或模型配置时,回顾并继续使用之前使用的提示进行实验。

总结(Summary)
本文探讨了提示工程。我们学习了各种提示技术,例如:
零提示(zero shot prompting)
少样本提示(few shot prompting)
系统提示(system Prompting)
角色提示(role Prompting)
上下文提示(contextual prompting)
逐步回溯提示(step-back prompting)
思维链(chain of thought)
自我一致性(self consistent)
思维树(tree of thought)
我们还研究了如何自动化您的提示。
本文随后讨论了生成式 AI 的挑战,例如当您的提示不足时可能出现的问题。我们以如何成为更好的提示工程师的最佳实践结束。