【自然语言处理】文本表示知识点梳理与习题总结
目录
一、词向量表示方法
1. 独热编码(One-Hot Encoding)
2. 词 - 词共现矩阵(Word-Word Co-occurrence Matrix)
3. 静态词嵌入(以 word2vec 为例)
总结:三种词表示方法对比
二、word2vec 之 skip-gram 模型
1. 模型目标与核心逻辑
2. 条件概率计算
3. 优化:负采样(Negative Sampling)
4. 似然计算
三、TF-IDF
1. 核心公式与含义
2. 对高频词的抑制作用
3. 应用场景
四、习题总结
五、习题解答
习题1解答:
选项分析:
习题2解答:
选项分析:
习题3解答:
关键逻辑:
语料 “我爱 NLP” 的分析(词序列:[我,爱,NLP]):
总似然:
习题4解答:
分析:
六、总结
一、词向量表示方法
词向量是将自然语言中的词转化为数值向量的技术,是 NLP 任务(如文本分类、相似度计算)的基础。常见方法包括独热编码、词 - 词共现矩阵、静态词嵌入(如 word2vec) 等,核心差异体现在 “是否能表示语义关联”“是否与上下文相关” 等特性上。
1. 独热编码(One-Hot Encoding)
- 定义:为词表中每个词分配一个唯一索引,向量长度等于词表大小,仅对应索引位置为 1,其余为 0(如词表
{我, 爱, NLP}中,“我” 的向量为[1,0,0],“爱” 为[0,1,0])。 - 核心特性:
- 稀疏性:向量维度等于词表大小(若词表 10 万,向量长度 10 万),存储成本高;
- 无语义关联:任意两个不同词的向量点积为 0(余弦相似度为 0),无法表示 “医生 - 医院”“猫 - 狗” 等语义相关性;
- 固定性:每个词的向量唯一且固定,与上下文无关(如 “苹果” 在 “吃苹果” 和 “苹果手机” 中向量相同)。
2. 词 - 词共现矩阵(Word-Word Co-occurrence Matrix)
- 定义:通过统计 “词与词在固定窗口内共同出现的频率” 构建矩阵,行和列均为词,矩阵值为共现次数(如窗口大小为 2 时,“我爱 NLP” 中 “我” 与 “爱” 共现 1 次,“爱” 与 “NLP” 共现 1 次)。
- 核心特性:
- 语义关联性:共现频率高的词向量更相似(如 “电脑” 与 “键盘” 共现频繁,向量余弦相似度高),可间接表示语义关联;
- 高频词干扰:高频词(如 “的”“the”)与多数词共现,导致不同词的向量差异被稀释(如 “学生” 和 “老师” 的向量因都频繁与 “的” 共现而变得相似),降低区分度;
- 固定性:向量由全局共现统计决定,与上下文无关(如 “苹果” 的向量在任何语境中相同);
- 高维度与稀疏性:维度等于词表大小,多数位置为 0(低频共现),需通过 PCA 等降维方法优化。
3. 静态词嵌入(以 word2vec 为例)
- 定义:通过神经网络学习低维稠密向量(如 100-300 维),向量值通过训练优化,使语义相关的词向量更接近(如 “国王 - 男人 + 女人≈女王”)。
- 核心特性:
- 稠密性:低维度(远小于词表大小),存储成本低;
- 语义关联性:向量距离(如余弦相似度)可直接反映语义关联(如 “猫” 与 “狗” 的向量比 “猫” 与 “汽车” 更接近);
- 固定性:属于静态词嵌入,每个词的向量唯一且固定,与上下文无关(动态词嵌入如 BERT 会随上下文变化);
- 优势:克服独热编码的语义缺失和共现矩阵的高维稀疏问题,是现代 NLP 的基础词表示方法。
总结:三种词表示方法对比
| 方法 | 维度特性 | 语义关联性 | 上下文相关性 | 典型问题 |
|---|---|---|---|---|
| 独热编码 | 高维稀疏 | 无 | 无关 | 无法表示相似度 |
| 词 - 词共现矩阵 | 高维稀疏 | 有(间接) | 无关 | 高频词降低区分度 |
| word2vec(静态) | 低维稠密 | 有(直接) | 无关 | 无法处理一词多义 |
二、word2vec 之 skip-gram 模型
word2vec 是 2013 年提出的静态词嵌入模型,包含CBOW和skip-gram两种架构,核心是通过 “预测上下文” 学习词向量。其中 skip-gram 因在小语料上表现更优而被广泛使用。
1. 模型目标与核心逻辑
- 目标:学习 “给定中心词,预测其上下文词” 的条件概率(与 CBOW 的 “用上下文预测中心词” 相反)。
- 示例:对于句子 “猫爱吃鱼”,若中心词为 “爱”,窗口大小为 2,则上下文词为 “猫”“吃”“鱼”,模型需优化 “猫爱”“吃爱”“鱼爱” 的概率。
2. 条件概率计算
- 向量表示:每个词有两个向量:
- 中心词向量(
):当词作为中心词时使用;
- 上下文词向量(
):当词作为上下文词时使用。
- 中心词向量(
- 点积与 softmax:给定中心词c,预测上下文词o的概率为:
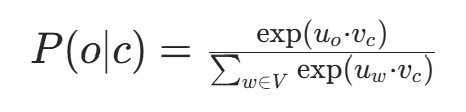
- 其中,
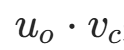 是上下文词o与中心词c的向量点积(衡量关联强度),softmax 函数将点积归一化为概率。
是上下文词o与中心词c的向量点积(衡量关联强度),softmax 函数将点积归一化为概率。
3. 优化:负采样(Negative Sampling)
- 原始问题:softmax 计算需遍历整个词表V(复杂度O(V)),当V为 10 万级时,计算成本极高。
- 负采样逻辑:
- 对每个正例(中心词c和真实上下文词o),采样k个负例(与c无关的词,如随机从词表选);
- 用二分类逻辑回归近似替代多分类 softmax,仅计算正例和负例的概率,复杂度降至O(k)(k通常取 5-20),避免遍历词表。
4. 似然计算
- 似然定义:整个语料的似然是 “所有中心词预测其上下文词的条件概率乘积”。
- 窗口大小影响:窗口大小k表示中心词左右各考虑k个词(若边界词无左侧 / 右侧词,则仅计算存在的一侧)。
- 示例分析(语料 “我爱 NLP”,窗口大小 = 1):词序列为我爱,逐个词作为中心词:
- 中心词 “我”:右侧 1 个上下文词 “爱”→ 概率爱我;
- 中心词 “爱”:左侧 1 个上下文词 “我”,右侧 1 个上下文词 “NLP”→ 概率我爱爱;
- 中心词 “NLP”:左侧 1 个上下文词 “爱”→ 概率爱;总似然:爱我我爱爱爱。
三、TF-IDF
TF-IDF 是一种用于评估 “词在文档中重要性” 的加权方法,广泛用于文本检索、特征选择等任务,核心是 “抑制高频词,突出重要词”。
1. 核心公式与含义
TF-IDF 由两部分组成:
-
TF(词频,Term Frequency):某词在文档中出现的频率,衡量词在单篇文档中的 “局部重要性”:
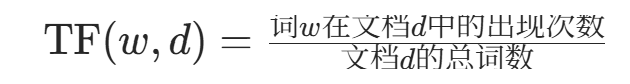
-
IDF(逆文档频率,Inverse Document Frequency):衡量词在 “所有文档” 中的 “全局重要性”,抑制在多数文档中出现的高频词:

- 若词w在多数文档中出现(
≈N),则IDF(w)≈0(如 “的”“the”);
- 若词w仅在少数文档中出现(
- 若词w在多数文档中出现(
-
TF-IDF:两者的乘积,综合局部和全局重要性:
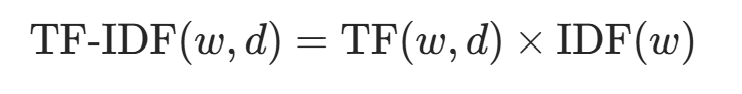
2. 对高频词的抑制作用
过于高频的词(如 “the”“it”“的”)在多数文档中出现(接近N),导致IDF(w)值极低(甚至趋近于 0)。即使其 TF 值较高,TF-IDF 权重仍会被显著降低,从而减少对文本表示的影响(符合 “高频词信息少” 的特性)。
3. 应用场景
- 文本检索:计算查询词与文档的 TF-IDF 相似度,返回最相关文档;
- 特征选择:过滤 TF-IDF 值过低的词(如高频无意义词),简化模型输入;
- 文本分类:作为词的权重,提升重要词对分类结果的影响。
四、习题总结
1.选择以下所有正确的叙述。
A. 独热编码的词向量无法表示词的相似度
B. 词 - 词共现矩阵能够表示词的相似度
C. 词 - 词共现矩阵的向量表示可能会缺乏区分度,这是由大量存在的高频词导致的
D. 词 - 词共现矩阵、独热编码词向量、word2vec 词嵌入都给每个词赋予一个独立于上下文的固定词嵌入
2.选择以下所有正确的叙述。
A. word2vec 的 skip - gram 模型学习使用上下文词预测中心词
B. skip - gram 模型中通过向量点乘和 softmax 函数计算条件概率
C. skip - gram 模型可以使用负采样方法来避免计算 softmax 函数时遍历整个词表
D. skip - gram 模型中每个词需要两个向量,一个表示该词作为上下文词,另一个表示该词作为中心词
3.假设有一个极小的语料 “我爱 NLP”(仅包含 3 个词,其中 NLP 可视为一个词)。当使用 word2vec 方法的 skip - gram 模型时,以下哪个式子正确计算了该语料的似然?假设窗口大小为 1,当没有左(右)侧上下文时,只需要包含预测右(左)侧上下文的概率。
A. P(爱∣我)×P(NLP∣我)×P(我∣爱)×P(NLP∣爱)×P(爱∣NLP)×P(我∣NLP)
B. P(爱∣我)×P(我∣爱)×P(NLP∣爱)×P(爱∣NLP)
C. P(我)×P(爱∣我)×P(NLP∣我,爱)
D. P(爱∣我)×P(NLP∣我)×P(爱∣NLP)×P(我∣NLP)E. P(我)×P(爱∣我)×P(NLP∣爱)
4.判断对错:TF - IDF 减少了过于高频词(如 “the”“it”“they”)的影响,因为这些词所包含的信息往往并不多。
五、习题解答
习题1解答:
题目核心:考查不同词向量表示方法(独热编码、词 - 词共现矩阵、word2vec)的特性。
选项分析:
-
A. 独热编码的词向量无法表示词的相似度独热编码中,每个词对应一个稀疏向量(仅一个位置为 1,其余为 0)。任意两个不同词的向量点积为 0,余弦相似度也为 0,无法反映词之间的语义关联(如 “医生” 与 “医院” 的相关性)。因此,A 正确。
-
B. 词 - 词共现矩阵能够表示词的相似度词 - 词共现矩阵中,每个词的向量是其与其他词的共现频率。若两个词在语料中频繁共同出现(如 “电脑” 与 “键盘”),它们的向量会更相似(通过余弦相似度等指标可量化),从而间接反映语义关联。因此,B 正确。
-
C. 词 - 词共现矩阵的向量表示可能会缺乏区分度,这是由大量存在的高频词导致的高频词(如中文的 “的”、英文的 “the”)在大多数词的共现向量中都有较高值,导致不同词的向量差异被稀释(例如 “学生” 和 “老师” 的共现向量可能因都频繁与 “的” 共现而变得相似),降低区分度。因此,C 正确。
-
D. 词 - 词共现矩阵、独热编码词向量、word2vec 词嵌入都给每个词赋予一个独立于上下文的固定词嵌入
- 独热编码和词 - 词共现矩阵:每个词的向量是固定的,与上下文无关(如 “苹果” 在 “吃苹果” 和 “苹果手机” 中向量相同)。
- word2vec:属于静态词嵌入,每个词对应一个固定向量,不考虑上下文差异(动态词嵌入如 BERT 才会根据上下文调整向量)。因此,三者均为固定词嵌入,D 正确。
答案:ABCD
习题2解答:
题目核心:考查 word2vec 中 skip-gram 模型的原理。
选项分析:
-
A. word2vec 的 skip-gram 模型学习使用上下文词预测中心词skip-gram 模型的核心是 “用中心词预测其上下文词”(如已知中心词 “猫”,预测上下文 “小”“可爱”);而 CBOW 模型才是 “用上下文词预测中心词”。因此,A 错误。
-
B. skip-gram 模型中通过向量点乘和 softmax 函数计算条件概率skip-gram 中,中心词向量与上下文词向量的点积表示两者的关联强度,再通过 softmax 函数将点积转换为概率(即 “给定中心词,出现某上下文词的概率”)。因此,B 正确。
-
C. skip-gram 模型可以使用负采样方法来避免计算 softmax 函数时遍历整个词表原始 softmax 计算需遍历所有词(复杂度为 O (V),V 为词表大小),计算成本极高。负采样通过采样少量负例(不相关词)近似计算,避免遍历整个词表,降低复杂度。因此,C 正确。
-
D. skip-gram 模型中每个词需要两个向量,一个表示该词作为上下文词,另一个表示该词作为中心词skip-gram 训练时,每个词有两个向量:当词作为中心词时使用 “中心词向量”,作为上下文词时使用 “上下文词向量”,两者在训练中分别更新。因此,D 正确。
答案:BCD
习题3解答:
题目核心:考查 skip-gram 模型的似然计算逻辑(中心词预测上下文词,窗口大小为 1)。
关键逻辑:
- skip-gram 模型的似然是 “给定每个中心词,预测其上下文词的概率乘积”。
- 窗口大小为 1:每个中心词仅考虑左右各 1 个词(若存在)。
语料 “我爱 NLP” 的分析(词序列:[我,爱,NLP]):
-
中心词 “我”:
- 左侧无词,右侧窗口 1 个词为 “爱”(上下文词)。
- 需计算:P(爱∣我)。
-
中心词 “爱”:
- 左侧窗口 1 个词为 “我”,右侧窗口 1 个词为 “NLP”(均为上下文词)。
- 需计算:P(我∣爱) 和 P(NLP∣爱)。
-
中心词 “NLP”:
- 右侧无词,左侧窗口 1 个词为 “爱”(上下文词)。
- 需计算:P(爱∣NLP)。
总似然:
所有概率的乘积为:P(爱∣我)×P(我∣爱)×P(NLP∣爱)×P(爱∣NLP),对应选项 B。
答案:B
习题4解答:
题目核心:考查 TF-IDF 的原理(是否减少高频词影响)。
分析:
- TF(词频):某词在文档中出现的频率,高频词 TF 值高。
- IDF(逆文档频率):
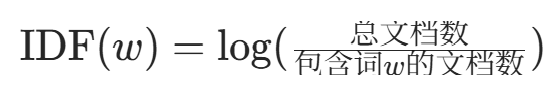 过于高频的词(如 “the”“it”)在多数文档中出现,导致包含词w的文档数接近总文档数,IDF 值极低(甚至趋近于 0)。
过于高频的词(如 “the”“it”)在多数文档中出现,导致包含词w的文档数接近总文档数,IDF 值极低(甚至趋近于 0)。 - TF-IDF = TF × IDF:高频词因 IDF 值低,其 TF-IDF 权重被显著降低,从而减少对结果的影响(符合 “高频词信息少” 的特点)。
结论:该陈述正确。
答案:对
六、总结
本文系统介绍了自然语言处理中的词向量表示方法,包括独热编码、词-词共现矩阵和静态词嵌入(word2vec)等核心技术的原理与特性。重点剖析了word2vec的skip-gram模型架构。