Netflix 推荐系统 | 从百万美元挑战赛到个性化体验升级的技术演进
注:注:本文为 “Netflix 推荐系统” 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
If You Liked This, You’re Sure to Love That
如果你喜欢这个,你一定会喜欢那个
By Clive Thompson
Nov. 21, 2008
THE “NAPOLEON DYNAMITE” problem is driving Len Bertoni crazy. Bertoni is a 51 - year - old “semiretired” computer scientist who lives an hour outside Pittsburgh. In the spring of 2007, his sister - in - law e - mailed him an intriguing bit of news: Netflix, the Web - based DVD - rental company, was holding a contest to try to improve Cinematch, its “recommendation engine.” The prize: $1 million.
《纳波莱恩·达奈特》问题让伦·贝尔托尼抓狂 。贝尔托尼是一位 51 岁的“半退休”计算机科学家,住在匹兹堡以北一小时车程的地方。2007 年春天,他的嫂子给他发来了一条有趣的新闻:基于网络的 DVD 租赁公司 Netflix 正在举办一场竞赛,试图改进其“推荐引擎”Cinematch。奖金:100 万美元。
Cinematch is the bit of software embedded in the Netflix Web site that analyzes each customer’s movie - viewing habits and recommends other movies that the customer might enjoy. (Did you like the legal thriller “The Firm”? Well, maybe you’d like “Michael Clayton.” Or perhaps “A Few Good Men.”) The Netflix Prize goes to anyone who can make Cinematch’s predictions 10 percent more accurate. One million dollars might sound like an awfully big prize for such a small improvement. But in fact, Netflix’s founders tried for years to improve Cinematch, with only incremental results, and they knew that a 10 percent bump would be a challenge for even the most deft programmer. They also knew that, as Reed Hastings, the chief executive of Netflix, told me recently, “getting to 10 percent would certainly be worth well in excess of $1 million” to the company. The competition was announced in October 2006, and no one has won yet, though 30,000 hackers worldwide are hard at work on the problem. Each day, teams submit their updated solutions to the Netflix Prize Web page, and Netflix instantly calculates how much better than Cinematch they are. (There’s even a live “leader board” ranking the top contestants.)
Cinematch 是嵌入在 Netflix 网站中的一段软件,它分析每个客户的观影习惯,并推荐其他客户可能喜欢的电影。(你喜欢法律惊悚片《大公司》吗?也许你会喜欢《迈克尔·克莱顿》。或者《义海雄风》呢?)Netflix 奖将授予任何能使 Cinematch 预测准确度提高 10%的人。一百万美元听起来像是对这么小的改进的巨额奖金。但实际上,Netflix 的创始人多年来一直在努力改进 Cinematch,但只取得了微小的成果,他们知道即使是技术最熟练的程序员,要实现 10%的提升也是一项挑战。他们还知道,正如 Netflix 首席执行官里德·哈斯廷斯最近告诉我的那样,“达到 10%的增长肯定值超过 100 万美元”。这场竞赛于 2006 年 10 月宣布,至今还没有人获胜,尽管全球有 30000 名黑客正在努力解决这个问题。每天,团队都会将他们的最新解决方案提交到 Netflix 奖网页上,Netflix 会立即计算它们比 Cinematch 好多少。(甚至还有一个实时的“排行榜”,对顶尖参赛者进行排名。)
In March 2007, Bertoni decided he wanted to give it a crack. So he downloaded a huge set of data that Netflix put online: an enormous list showing how 480,189 of the company’s customers rated 17,770 Netflix movies. When Netflix customers log into their accounts, they can rate any movie from one to five stars, to help “teach” the Netflix system what their preferences are; the average customer has rated around 200 movies, so Netflix has a lot of information about what its customers like and don’t like. (The data set doesn’t include any personal information — names, ages, __polct and gender have been stripped out.) So Bertoni began looking for patterns that would predict customer behavior — specifically, an algorithm that would guess correctly the number of stars a given user would apply to a given movie. A year and a half later, Bertoni is still going, often spending 20 hours a week working on it in his home office. His two children — 12 and 13 years old — sometimes sit and brainstorm with him. “They’re very good with mathematics and algebra,” he told me, chuckling. “And they think of interesting questions about your movie - watching behavior.” For example, one day the kids wondered about sequels: would a Netflix user who liked the first two “Matrix” movies be just as likely to enjoy the third one, even though it was widely considered to be pretty dreadful?
2007 年 3 月,贝尔托尼决定试一试。于是他下载了 Netflix 发布在网上的一组庞大数据:一份庞大的列表,显示了该公司的 480189 名客户对 17770 部 Netflix 电影的评分。当 Netflix 的客户登录他们的账户时,他们可以对任何电影从一星到五星进行评分,以帮助“教育”Netflix 系统他们的偏好;平均每个客户已经对大约 200 部电影进行了评分,因此 Netflix 对其客户喜欢和不喜欢的内容有大量信息。(数据集不包括任何个人信息——姓名、年龄、__polct 和性别已被删除。)因此,贝尔托尼开始寻找能够预测客户行为的模式——具体来说,就是一种算法,能够准确猜测出一个用户会给一部电影评多少星。一年半后,贝尔托尼仍在继续,每周经常在家庭办公室花费 20 个小时来研究这个问题。他的两个孩子——12 岁和 13 岁——有时会坐下来和他一起头脑风暴。他笑着对我说:“他们在数学和代数方面非常出色。而且他们会对你的观影行为提出一些有趣的问题。”例如,有一天孩子们想知道关于续集的问题:一个喜欢前两部《黑客帝国》电影的 Netflix 用户,是否会同样喜欢第三部,尽管它被认为相当糟糕?
Each time he or his kids think of a new approach, Bertoni writes a computer program to test it. Each new algorithm takes on average three or four hours to churn through the data on the family’s “quad core” Gateway computer. Bertoni’s results have gradually improved. When I last spoke to him, he was at No. 8 on the leader board; his program was 8.8 percent better than Cinematch. The top team was at 9.44 percent. Bertoni said he thought he was within striking distance of victory.
每次他或他的孩子们想到一种新方法,贝尔托尼就会编写一个计算机程序来测试它。每个新算法平均需要三到四个小时才能在家庭的“四核”Gateway 计算机上处理完数据。贝尔托尼的结果逐渐得到了改善。当我最后一次和他交谈时,他在排行榜上排名第 8;他的程序比 Cinematch 好 8.8%。排名第一的团队达到了 9.44%。贝尔托尼说,他认为自己离胜利只有一步之遥。
But his progress had slowed to a crawl. The more Bertoni improved upon Netflix, the harder it became to move his number forward. This wasn’t just his problem, though; the other competitors say that their progress is stalling, too, as they edge toward 10 percent. Why?
但他的进展已经变得非常缓慢。贝尔托尼对 Netflix 的改进越多,就越难推动他的数字向前发展。不过,这不仅仅是他的问题;其他竞争对手也表示,当他们接近 10%时,他们的进展也停滞不前。为什么呢?
Bertoni says it’s partly because of “Napoleon Dynamite,” an indie comedy from 2004 that achieved cult status and went on to become extremely popular on Netflix. It is, Bertoni and others have discovered, maddeningly hard to determine how much people will like it. When Bertoni runs his algorithms on regular hits like “Lethal Weapon” or “Miss Congeniality” and tries to predict how any given Netflix user will rate them, he’s usually within eight - tenths of a star. But with films like “Napoleon Dynamite,” he’s off by an average of 1.2 stars.
贝尔托尼说,部分原因是 2004 年的一部独立喜剧《纳波莱恩·达奈特》,它获得了邪典地位,并在 Netflix 上变得非常受欢迎。贝尔托尼和其他人发现,要确定人们会有多喜欢这部电影是非常令人头疼的。当贝尔托尼对像《致命武器》或《美丽小姐》这样的热门电影运行他的算法,并试图预测任何 Netflix 用户会如何评价它们时,他通常在八分之一个星以内。但对于像《纳波莱恩·达奈特》这样的电影,他的预测平均相差 1.2 颗星。
The reason, Bertoni says, is that “Napoleon Dynamite” is very weird and very polarizing. It contains a lot of arch, ironic humor, including a famously kooky dance performed by the titular teenage character to help his hapless friend win a student - council election. It’s the type of quirky entertainment that tends to be either loved or despised. The movie has been rated more than two million times in the Netflix database, and the ratings are disproportionately one or five stars.
贝尔托尼说,原因是《纳波莱恩·达奈特》非常奇特,也非常两极分化。它包含了许多夸张的、讽刺的幽默,包括由主角——一个十几岁的少年——表演的著名怪异舞蹈,以帮助他那个可怜的朋友赢得学生会选举。这种古怪的娱乐方式往往是被人喜爱或厌恶。这部电影在 Netflix 数据库中已经被评价了超过两百万次,而评分大多是一星或五星。
Worse, close friends who normally share similar film aesthetics often heatedly disagree about whether “Napoleon Dynamite” is a masterpiece or an annoying bit of hipster self - indulgence. When Bertoni saw the movie himself with a group of friends, they argued for hours over it. “Half of them loved it, and half of them hated it,” he told me. “And they couldn’t really say why. It’s just a difficult movie.”
更糟糕的是,通常有着相似电影审美的密友,往往会激烈地争论《纳波莱恩·达奈特》究竟是杰作还是令人讨厌的文艺青年自我陶醉之作。当贝尔托尼和一群朋友一起观看这部电影时,他们为此争论了数小时。“他们中有一半人喜欢它,另一半人讨厌它,”他告诉我。“他们也说不出为什么。这只是一部难以捉摸的电影。”
Mathematically speaking, “Napoleon Dynamite” is a very significant problem for the Netflix Prize. Amazingly, Bertoni has deduced that this single movie is causing 15 percent of his remaining error rate; or to put it another way, if Bertoni could anticipate whether you’d like “Napoleon Dynamite” as accurately as he can for other movies, this feat alone would bring him 15 percent of the way to winning the $1 million prize. And while “Napoleon Dynamite” is the worst culprit, it isn’t the only troublemaker. A small subset of other titles has caused almost as much bedevilment among the Netflix Prize competitors. When Bertoni showed me a list of his 25 most - difficult - to - predict movies, I noticed they were all similar in some way to “Napoleon Dynamite” — culturally or politically polarizing and hard to classify, including “I Heart Huckabees,” “Lost in Translation,” “Fahrenheit 9/11,” “The Life Aquatic With Steve Zissou,” “Kill Bill: Volume 1” and “Sideways.”
从数学角度来看,《纳波莱恩·达奈特》对 Netflix 奖来说是一个非常重要的问题。令人惊讶的是,贝尔托尼推断出这部电影单独造成了他剩余错误率的 15%;换句话说,如果贝尔托尼能够像预测其他电影那样准确地预测你是否会喜欢《纳波莱恩·达奈特》,这一成就本身将使他朝着赢得 100 万美元奖金的方向迈进 15%。尽管《纳波莱恩·达奈特》是最糟糕的罪魁祸首,但它并不是唯一的麻烦制造者。一小部分其他电影标题也在 Netflix 奖竞争者中造成了几乎同样多的困扰。当贝尔托尼向我展示他最难预测的 25 部电影的列表时,我注意到它们在某种程度上都与《纳波莱恩·达奈特》相似——在文化或政治上具有两极分化性,难以归类,包括《我爱哈卡比》、《迷失翻译》、《华氏 911》、《与史蒂夫·茨索的水下生活》、《杀死比尔:第一卷》和《杯酒人生》。
So this is the question that gently haunts the Netflix competition, as well as the recommendation engines used by other online stores like Amazon and iTunes. Just how predictable is human taste, anyway? And if we can’t understand our own preferences, can computers really be any better at it?
因此,这个问题温和地萦绕着 Netflix 竞赛,以及亚马逊和 iTunes 等其他在线商店使用的推荐引擎。人类的品味到底有多可预测呢?如果我们自己都无法理解自己的偏好,计算机真的能做得更好吗?
IT USED TO BE THAT if you wanted to buy a book, rent a movie or shop for some music, you had to rely on flesh - and - blood judgment — yours, or that of someone you trusted. You’d go to your local store and look for new stuff, or you might just wander the aisles in what librarians call a stack search, to see if anything jumped out at you. You might check out newspaper reviews or consult your friends; if you were lucky, your local video store employed one of those young cinéastes who could size you up in a glance and suggest something suitable.
过去,如果你想买书、租电影或购买音乐,你必须依靠有血有肉的判断力——你自己的,或者你信任的某个人的。你会去当地的商店寻找新东西,或者你可能会在图书馆员所说的“堆叠搜索”中漫步浏览通道,看看是否有任何东西吸引你。你可能会查看报纸评论,或者咨询你的朋友;如果你运气好的话,你当地的视频店会雇用那些年轻的电影迷,他们可以一眼就看透你,并推荐一些合适的东西。
The advent of online retailing completely upended this cultural and economic ecosystem. First of all, shopping over the Web is not a social experience; there are no clever clerks to ask for advice. What’s more, because they have no real space constraints, online stores like Amazon or iTunes can stock millions of titles, making a stack search essentially impossible. This creates the classic problem of choice: how do you decide among an effectively infinite number of options?
在线零售的出现完全颠覆了这种文化和经济生态系统。首先,网上购物不是一种社交体验;没有聪明的店员可以咨询建议。更重要的是,由于没有实际的空间限制,像亚马逊或 iTunes 这样的在线商店可以库存数百万个标题,使得“堆叠搜索”基本上不可能。这就创造了选择的经典问题:当你面对几乎无限多的选择时,如何做出决定?
But Web sites have this significant advantage over brick - and - mortar stores: They can track everything their customers do. Every page you visit, every purchase you make, every item you rate — it is all recorded. In the early ’90s, scientists working in the field of “machine learning” realized that this enormous trove of data could be used to analyze patterns in people’s taste. In 1994, Pattie Maes, an M.I.T. professor, created one of the first recommendation engines by setting up a Web site where people listed songs and bands they liked. Her computer algorithm performed what’s known as collaborative filtering. It would take a song you rated highly, find other people who had also rated it highly and then suggest you try a song that those people also said they liked.
但网站比实体店有一个显著的优势:它们可以跟踪客户的每一个举动。你访问的每一个页面,你进行的每一次购买,你评价的每一件商品——所有这些都被记录下来。在 20 世纪 90 年代初,从事“机器学习”领域的科学家们意识到,这些海量数据可以用来分析人们的品味模式。1994 年,麻省理工学院教授帕蒂·梅斯创建了第一个推荐引擎,她建立了一个网站,让人们列出他们喜欢的歌曲和乐队。她的计算机算法执行了所谓的协同过滤。它会找到一首你高度评价的歌曲,找到其他也高度评价这首歌的人,然后建议你尝试那些人也说他们喜欢的歌曲。
“We had this realization that if we gathered together a really large group of people, like thousands or millions, they could help one another find things, because you can find patterns in what they like,” Maes told me recently. “It’s not necessarily the one, single smart critic that is going to find something for you, like, ‘Go see this movie, go listen to this band!’ ”
“我们意识到,如果我们聚集起一个真正庞大的人群,比如成千上万甚至数百万,他们可以帮助彼此找到东西,因为你可以发现他们喜欢的东西中的模式,”梅斯最近告诉我。“这并不一定是一个聪明的评论家会为你找到的东西,比如‘去看这部电影,去听这个乐队的音乐!’”
In one sense, collaborative filtering is less personalized than a store clerk. The clerk, in theory anyway, knows a lot about you, like your age and profession and what sort of things you enjoy; she can even read your current mood. (Are you feeling lousy? Maybe it’s not the day for “Apocalypse Now.”) A collaborative - filtering program, in contrast, knows very little about you — only what you’ve bought at a Web site and whether you rated it highly or not. But the computer has numbers on its side. It may know only a little bit about you, but it also knows a little bit about a huge number of other people. This lets it detect patterns we often cannot see on our own. For example, Maes’s music - recommendation system discovered that people who like classical music also like the Beatles. It is an epiphany that perhaps makes sense when you think about it for a second, but it isn’t immediately obvious.
从某种意义上说,协同过滤不如店员个性化。理论上,店员对你了解很多,比如你的年龄、职业以及你喜欢什么类型的东西;她甚至可以读懂你的情绪。(你感觉不舒服吗?也许今天不适合看《现代启示录》。)相比之下,协同过滤程序对你的了解非常少——只知道你在网站上购买了什么以及你是否给了高评价。但计算机有数据作为支撑。它可能只对你了解一点点,但它还对大量其他人都有一点了解。这使得它能够发现我们自己通常看不到的模式。例如,梅斯的音乐推荐系统发现,喜欢古典音乐的人也喜欢披头士乐队。当你仔细思考时,这可能说得通,但并不是显而易见的。
Soon after Maes’s work made its debut, online stores quickly understood the value of having a recommendation system, and today most Web sites selling entertainment products have one. Most of them use some variant of collaborative filtering — like Amazon’s “Customers Who Bought This Item Also Bought” function. Some setups ask you to actively rate products, as Netflix does. But others also rely on passive information. They keep track of your everyday behavior, looking for clues to your preferences. (For example, many music - recommendation engines — like the Genius feature on Apple’s iTunes, Microsoft’s Mixview music recommender or the Audioscrobbler program at Last.fm — can register every time you listen to a song on your computer or MP3 player.) And a few rare services actually pay people to evaluate products; the Pandora music - streaming service has 50 employees who listen to songs and tag them with descriptors — “upbeat,” “minor key,” “prominent vocal harmonies.”
在梅斯的工作首次亮相后不久,在线商店很快就明白了拥有推荐系统的价值,如今大多数销售娱乐产品的网站都有这样的系统。其中大多数使用了某种形式的协同过滤——比如亚马逊的“购买此商品的顾客还购买了”功能。一些设置会要求你积极评价产品,就像 Netflix 那样。但其他一些则依赖于被动信息。它们会跟踪你的日常行为,寻找你偏好的线索。(例如,许多音乐推荐引擎——比如苹果 iTunes 的 Genius 功能、微软的 Mixview 音乐推荐器或 Last.fm 的 Audioscrobbler 程序——可以在你用电脑或 MP3 播放器听歌时记录下来。)还有一些罕见的服务会付钱让人来评估产品;潘多拉音乐流媒体服务有 50 名员工,他们听歌曲并用描述性标签标记它们——“节奏明快”“小调”“突出的和声”。
Netflix came late to the party. The company opened for business in 1997, but for the first three years it offered no recommendations. This wasn’t such a big problem when Netflix stocked only 1,000 titles or so, because customers could sift through those pretty quickly. But Netflix grew, and today, it stocks more than 100,000 movies. “I think that once you get beyond 1,000 choices, a recommendation system becomes critical,” Hastings, the Netflix C.E.O., told me. “People have limited cognitive time they want to spend on picking a movie.”
Netflix 来得有点晚。该公司于 1997 年开始营业,但在最初的三年里并没有提供任何推荐。当 Netflix 只有大约 1000 个标题时,这并不是一个大问题,因为客户可以很快地筛选这些内容。但 Netflix 不断发展壮大,如今它拥有超过 10 万部电影。“我认为,一旦你的选择超过 1000 个,推荐系统就变得至关重要了,”Netflix 首席执行官哈斯廷斯告诉我。“人们花在挑选电影上的认知时间是有限的。”
Cinematch was introduced in 2000, but the first version worked poorly — “a mix of insightful and boneheaded recommendations,” according to Hastings. His programmers slowly began improving the algorithms. They could tell how much better they were getting by trying to replicate how a customer rated movies in the past. They took the customer’s ratings from, say, 2001, and used them to predict their ratings for 2002. Because Netflix actually had those later ratings, it could discern what a “perfect” prediction would look like. Soon, Cinematch reached the point where it could tease out some fairly nuanced — and surprising — connections. For example, it found that people who enjoy “The Patriot” also tend to like “Pearl Harbor,” which you’d expect, since they’re both history - war - action movies; but it also discovered that they like the heartstring - tugging drama “Pay It Forward” and the sci - fi movie “I, Robot.”
Cinematch 于 2000 年推出,但第一个版本效果不佳——用哈斯廷斯的话说,“这些建议既有深刻的见解,也有一些愚蠢的建议”。他的程序员们开始逐步改进算法。他们通过尝试重现客户过去对电影的评分来判断自己取得了多大的进步。他们会取客户在 2001 年的评分,用这些数据来预测他们在 2002 年的评分。由于 Netflix 实际上拥有这些后来的评分,因此可以判断出“完美”预测是什么样子的。很快,Cinematch 达到了一个可以揭示出一些相当微妙——而且令人惊讶——的联系的水平。例如,它发现喜欢《爱国者》的人也倾向于喜欢《珍珠港》,这并不奇怪,因为它们都是历史战争动作片;但它还发现这些人也喜欢催人泪下的剧情片《 Pay It Forward》和科幻电影《 I, Robot》。
Cinematch has, in fact, become a video - store roboclerk: its suggestions now drive a surprising 60 percent of Netflix’s rentals. It also often steers a customer’s attention away from big - grossing hits toward smaller, independent movies. Traditional video stores depend on hits; just - out - of - the - theaters blockbusters account for 80 percent of what they rent. At Netflix, by contrast, 70 percent of what it sends out is from the backlist — older movies or small, independent ones. A good recommendation system, in other words, does not merely help people find new stuff. As Netflix has discovered, it also spurs them to consume more stuff.
事实上,Cinematch 已经成为了一个视频店的机器人店员:它的建议如今推动了 Netflix 60%的租赁业务。它还经常将客户的注意力从票房大片转移到较小的独立电影上。传统的视频店依赖于大片;刚刚上映的热门电影占到了他们租赁业务的 80%。相比之下,在 Netflix,它发出的 70%的影片来自旧片——老电影或小众独立电影。换句话说,一个好的推荐系统不仅仅帮助人们找到新东西。正如 Netflix 所发现的那样,它还促使人们消费更多的东西。
For Netflix, this is doubly important. Customers pay a flat monthly rate, generally $16.99 (although cheaper plans are available), to check out as many movies as they want. The problem with this business model is that new members often have a couple of dozen movies in mind that they want to see, but after that they’re not sure what to check out next, and their requests slow. And a customer paying $17 a month for only one movie every month or two is at risk of canceling his subscription; the plan makes financial sense, from a user’s point of view, only if you rent a lot of movies. (My wife and I once quit Netflix for precisely this reason.) Every time Hastings increases the quality of Cinematch even slightly, it keeps his customers active.
对于 Netflix 来说,这一点至关重要。客户每月支付固定的费用,通常为 16.99 美元(尽管也有更便宜的套餐),以租借他们想要的任意多的电影。这种商业模式的问题在于,新会员通常会想到一些他们想要看的电影,但在看完这些之后,他们就不确定接下来要租什么了,他们的需求也逐渐减少。每月支付 17 美元,却只租借一两部电影的客户,可能会取消他们的订阅;从用户的角度来看,只有当你租借大量电影时,这种计划才有经济意义。(我的妻子和我就是因为这个原因而取消了 Netflix 的订阅。)每次哈斯廷斯哪怕只是稍微提高了 Cinematch 的质量,都能让他的客户保持活跃。
But by 2006, Cinematch’s improving performance had plateaued. Netflix’s programmers couldn’t go any further on their own. They suspected that there was a big breakthrough out there; the science of recommendation systems was booming, and computer scientists were publishing hundreds of papers each year on the subject. At a staff meeting in the summer of 2006, Hastings suggested a radical idea: Why not have a public contest? Netflix’s recommendation system was powered by the wisdom of crowds; now it would tap the wisdom of crowds to get better too.
但到了 2006 年,Cinematch 不断改善的性能已经达到了一个平台期。Netflix 的程序员们已经无法凭借自己的能力再进一步了。他们怀疑有一个重大的突破就在眼前;推荐系统的科学正在蓬勃发展,计算机科学家们每年都在这个领域发表数百篇论文。在 2006 年夏天的一次员工会议上,哈斯廷斯提出了一个激进的想法:为什么不举办一场公开竞赛呢?Netflix 的推荐系统依靠的是群体的智慧;现在它将利用群体的智慧来进一步提升自己。
AS HASTINGS HOPED, the contest has galvanized nerds around the world. The Top 10 list for the Netflix Prize currently includes a group of programmers in Austria (who are at No. 2), a trained psychologist and Web consultant in Britain who uses his teenage daughter to perform his calculus (No. 9), a lone Ph.D. candidate in Boston who calls himself My Brain and His Chain (a reference to a Ben Folds song; he’s at No. 6) and Pragmatic Theory — two French - Canadian guys in Montreal (No. 3). Nearly every team is working on the prize in its spare time. In October, when I dropped by the house of Martin Chabbert, a 32 - year - old member of the Pragmatic Theory duo, it was only 8:30 at night, but we had to whisper: his four children, including a 2 - month - old baby, had just gone to bed upstairs. In his small dining room, a laptop sat open next to children’s books like “Les Robots: Au Service de L’homme” and a “Star Wars” picture book in French.
正如哈斯廷斯所希望的那样 ,这场竞赛激发了全世界的极客们的热情。目前 Netflix 奖的前十名榜单包括:来自奥地利的一组程序员(排名第二)、一位在英国的受过训练的心理学家兼网络顾问,他让自己的十几岁的女儿帮他做微积分(排名第九)、一位来自波士顿的孤独的博士研究生,他自称为“我的大脑和他的链条”(这是对本·福尔兹一首歌的引用;他排名第六)以及实用主义理论——来自蒙特利尔的两名法裔加拿大人(排名第三)。几乎每个团队都在业余时间努力争取这个奖项。十月份,当我拜访实用主义理论二人组成员之一、32 岁的马丁·沙伯特的家时,尽管当时才晚上八点半,但我们不得不压低声音说话:他的四个孩子,包括一个两个月大的婴儿,刚刚在楼上睡着。在他的小餐厅里,一台笔记本电脑开着,旁边放着一些儿童书籍,比如《机器人:为人类服务》和一本法语版的《星球大战》绘本。
“This is where I do everything,” Chabbert said. “After the kids are asleep and I’ve packed the lunches for school, I come down at 9 in the evening and work until 11 or 12. It was very exciting in the beginning!” He laughed. “It still is, but with the baby now, going to bed at midnight is not a good idea.”
“我就在这儿做所有的事情,”沙伯特说。“孩子们睡着后,我准备好第二天上学的午餐,晚上 9 点下来工作,一直工作到 11 点或 12 点。一开始的时候非常令人兴奋!”他笑着说。“现在依然很有趣,但有了孩子后,午夜才睡觉可不是个好主意。”
Pragmatic Theory formed last spring, when Chabbert’s longtime friend Martin Piotte — a 43 - year - old electrical and computer engineer — heard about the Netflix Prize. Like many of the amateurs trying to win the $1 million, they had no relevant expertise. (“Absolutely no background in statistics that was useful,” Piotte told me ruefully. “Two guys, absolutely no clue.”) But they soon discovered that the Netflix competition is a fairly collegial affair. The company hosts a discussion board devoted to the prize, and competitors frequently help one another out — discussing algorithms they’ve tried and publicly brainstorming new ways to improve their work, sometimes even posting reams of computer code for anyone to use. When someone makes a breakthrough, pretty soon every other team is aware of it and starts using it, too. Piotte and Chabbert soon learned the major mathematical tricks that had propelled the leading teams into the Top 10.
实用主义理论团队是在去年春天成立的,当时沙伯特的长期好友、43 岁的电气和计算机工程师马丁·皮奥特听说了 Netflix 奖。像许多试图赢得 100 万美元奖金的业余爱好者一样,他们没有任何相关的专业知识。(“我们确实没有有用的统计学背景,”皮奥特无奈地告诉我。“两个家伙,完全摸不着头脑。”)但他们很快发现,Netflix 竞赛是一个相当友好合作的活动。该公司有一个专门讨论这个奖项的论坛,参赛者们经常互相帮助——讨论他们尝试过的算法,公开头脑风暴改进工作的新方法,有时甚至发布大量的计算机代码,供任何人使用。当有人取得突破时,很快其他团队也会知道并开始使用。皮奥特和沙伯特很快学会了那些将领先团队推进前十名的主要数学技巧。
The first major breakthrough came less than a month into the competition. A team named Simon Funk vaulted from nowhere into the No. 4 position, improving upon Cinematch by 3.88 percent in one fell swoop. Its secret was a mathematical technique called singular value decomposition. It isn’t new; mathematicians have used it for years to make sense of prodigious chunks of information. But Netflix never thought to try it on movies.
竞赛开始不到一个月,就出现了第一个重大突破。一个名为西蒙·芬克的团队从无名小卒一跃升至第四名,一次性将 Cinematch 的性能提高了 3.88%。他们的秘诀是一种名为奇异值分解的数学技术。这种技术并不新鲜;数学家们多年来一直用它来处理大量的信息。但 Netflix 从未想过将其应用于电影。
Singular value decomposition works by uncovering “factors” that Netflix customers like or don’t like. Say, for example, that “Sleepless in Seattle” has been rated by 200,000 Netflix users. In one sense, this is just a huge list of numbers — user No. 452 gave it two stars; No. 985 gave it five stars; and so on. But you could also think of those ratings as individual reactions to various aspects of the movie. “Sleepless in Seattle” is a “chick flick,” a comedy, a star vehicle for Tom Hanks; each customer is reacting to how much — or how little — he or she likes “chick flicks,” comedies and Tom Hanks. Singular value decomposition takes the mass of Netflix data — 17,770 movies, ratings by 480,189 users — and automatically sorts the films. The programmers do not actively tell the computer what to look for; they just run the algorithm until it groups together movies that share qualities with predictive value.
奇异值分解通过揭示 Netflix 用户喜欢或不喜欢的“因素”来工作。例如,假设有 20 万 Netflix 用户对《西雅图夜未眠》进行了评分。从某种意义上说,这只是一长串数字——452 号用户给了它两颗星;985 号用户给了它五颗星;等等。但你也可以把这些评分看作是对电影各个方面的个人反应。《西雅图夜未眠》是一部“爱情片”,一部喜剧,一部汤姆·汉克斯主演的电影;每个顾客都在根据他或她对“爱情片”、喜剧和汤姆·汉克斯的喜爱程度——或者不喜欢的程度——做出反应。奇异值分解处理 Netflix 的海量数据——17770 部电影,480189 名用户的评分——并自动对电影进行分类。程序员并没有告诉计算机要寻找什么;他们只是运行算法,直到它把具有预测价值的相似特质的电影归为一组。
Sometimes when you look at the clusters of movies, you can deduce the connections. Chabbert showed me one list: at the top were “Sleepless in Seattle,” “Steel Magnolias” and “Pretty Woman,” while at the bottom were “Star Trek” movies. Clearly, the computer recognized some factor that suggests that someone who likes the romantic aspect of “Pretty Woman” will probably like “Sleepless in Seattle” and dislike “Star Trek.” Chabbert showed me another cluster: this time DVD collections of the TV show “Friends” all clustered at the top of the list, while action movies like “Reindeer Games” and thrillers like “Hannibal” clustered at the bottom. Most likely, the computer had selected for “comic” content here. Other lists appear to group movies based on whether they lean strongly to the ideological right or left.
有时,当你查看电影的聚类时,你可以推断出它们之间的联系。沙伯特给我看了一张列表:在最上面的是《西雅图夜未眠》《钢木兰花》和《漂亮女人》,而在最下面的是《星际迷航》系列电影。显然,计算机识别出了某种因素,表明喜欢《漂亮女人》的浪漫元素的人可能会喜欢《西雅图夜未眠》,而不会喜欢《星际迷航》。沙伯特又给我看了另一个聚类:这一次,《老友记》的 DVD 合集都聚集在列表的最上面,而像《驯鹿游戏》这样的动作电影和《汉尼拔》这样的惊悚片则聚集在最下面。很可能,计算机在这里选择了“喜剧”内容。其他列表似乎根据电影是否明显倾向于意识形态的右翼或左翼来对电影进行分组。
As programmers extract more and more values, it becomes possible to draw exceedingly sophisticated correlations among movies and hence to offer incredibly nuanced recommendations. “We’re teasing out very subtle human behaviors,” said Chris Volinsky, a scientist with AT & T in New Jersey who is one of the most successful Netflix contestants; his three - person team held the No. 1 position for more than a year. His team relies, in part, on singular value decomposition. “You can find things like ‘People who like action movies, but only if there’s a lot of explosions, and not if there’s a lot of blood. And maybe they don’t like profanity,’ ” Volinsky told me when we spoke recently. “Or it’s like ‘I like action movies, but not if they have Keanu Reeves and not if there’s a bus involved.’ ”
随着程序员们提取出越来越多的值,他们能够在电影之间建立极其复杂的关联,从而提供非常细致的建议。“我们正在揭示非常微妙的人类行为,”新泽西州 AT&T 的科学家克里斯·沃林斯基说,他是最成功的 Netflix 参赛者之一;他所在的三人团队曾连续一年多占据排行榜首位。他的团队部分依赖于奇异值分解。“你可以发现类似这样的事情:‘喜欢动作片的人,但前提是有很多爆炸场面,而不是有很多血腥场景。也许他们不喜欢脏话,’”沃林斯基在我们最近交谈时告诉我。“或者说‘我喜欢动作片,但不要有基努·里维斯,也不要涉及公交车。’”
MOST OF THE LEADING TEAMS competing for the Netflix Prize now use singular value decomposition. Indeed, given how quickly word of new breakthroughs spreads among the competitors, virtually every team in the Top 10 makes use of similar mathematical ploys. The only thing that separates their scores is how skillfully they tweak their algorithms. The Netflix Prize has come to resemble a drag race in which everyone drives the same car, with only tiny modifications to the fuel injection. Yet those tweaks are crucial. Since the top teams are so close — there is less than a tenth of a percent between each contender — even tiny improvements can boost a team to the top of the charts.
如今,大多数角逐 Netflix 奖的领先团队都在使用奇异值分解。事实上,鉴于新的突破在参赛者之间传播的速度之快,前十名的团队几乎都使用了类似的数学技巧。唯一能区分他们得分的是他们对算法的调整技巧。Netflix 奖如今变得像一场直线加速赛,每个人都驾驶着同一款汽车,只是对燃油喷射系统做了微小的调整。然而,这些调整至关重要。由于顶尖团队之间的差距非常小——每个竞争者之间不到十分之一个百分点——即使是微小的改进也能使一个团队跃居排行榜首位。
These days, the competitors spend much of their time thinking deeply about the math and psychology behind recommendations. For example, the teams are grappling with the problem that over time, people can change how sternly or leniently they rate movies. Psychological studies show that if you ask someone to rate a movie and then, a month later, ask him to do so again, the rating varies by an average of 0.4 stars. “The question is why,” Len Bertoni said to me. “Did you just remember it differently? Did you see something in between? Did something change in your life that made you rethink it?” Some teams deal with this by programming their computers to gradually discount older ratings.
如今,参赛者们花费大量时间深入思考推荐背后的数学和心理学原理。例如,各团队正在努力解决这样一个问题:随着时间的推移,人们评价电影的严格程度或宽松程度会发生变化。心理学研究表明,如果你请某人对一部电影进行评分,然后一个月后再请他评分,平均评分差异为 0.4 星。“问题是为什么,”伦·贝尔托尼对我说,“是你对它的记忆不同了吗?还是你在中间又看了其他东西?还是你生活中的某些变化让你重新思考了这部电影?”一些团队通过编程让计算机逐渐降低旧评分的权重来解决这个问题。
Another common problem is identifying overly punitive raters. If you’re a really harsh critic and I’m a much more easygoing one, your two - star rating may be equal to my four - star rating. To compensate, an algorithm might try to detect when a Netflix customer tends to hand out only one - or two - star ratings — a sign of a strict, pursed - lip customer — and artificially boost his or her ratings by a half - star or so. Then there’s the problem of movie raters who simply aren’t consistent. They might be evenhanded most of the time, but if they log into Netflix when they’re in a particularly bad mood, they might impulsively decide to rate a couple of dozen movies harshly.
另一个常见问题是识别过于严厉的评分者。如果你是一个非常苛刻的评论家,而我是一个比较随和的人,那么你给出的两星评分可能相当于我给出的四星评分。为了弥补这一点,一个算法可能会试图检测出 Netflix 用户是否倾向于只给出一星或两星的评分——这是严格、挑剔的顾客的标志——然后人为地将其评分提高半星左右。还有电影评分者不一致的问题。他们大多数时候可能都很公平,但如果他们在心情特别糟糕的时候登录 Netflix,他们可能会冲动地决定给几十部电影打低分。
TV shows, which are hot commodities on Netflix, present yet another perplexing issue. Customers respond to TV series much differently than they do to movies. People who loved the first two seasons of “The Wire” might start getting bored during the third but keep on watching for a while, then stop abruptly. So when should Cinematch stop recommending “The Wire”? When do you tell someone to give up on a TV show?
在 Netflix 上备受欢迎的电视剧又提出了另一个令人困惑的问题。客户对电视剧的反应与对电影的反应大不相同。喜欢《火线》前两季的人可能在第三季开始觉得无聊,但还是会继续看一段时间,然后突然停止。那么,Cinematch 应该在什么时候停止推荐《火线》呢?什么时候该告诉一个人放弃一部电视剧呢?
Interestingly, the Netflix Prize competitors do not know anything about the demographics of the customers whose taste they’re trying to predict. The teams sometimes argue on the discussion board about whether their predictions would be better if they knew that customer No. 465 is, for example, a 23 - year - old woman in Arizona. Yet most of the leading teams say that personal information is not very useful, because it’s too crude. As one team pointed out to me, the fact that I’m a 40 - year - old West Village resident is not very predictive. There’s little reason to think the other 40 - year - old men on my block enjoy the same movies as I do. In contrast, the Netflix data are much richer in meaning. When I tell Netflix that I think Woody Allen’s black comedy “Match Point” deserves three stars but the Joss Whedon sci - fi film “Serenity” is a five - star masterpiece, this reveals quite a lot about my taste. Indeed, Reed Hastings told me that even though Netflix has a good deal of demographic information about its users, the company does not currently use it much to generate movie recommendations; merely knowing who people are, paradoxically, isn’t very predictive of their movie tastes.
有趣的是,Netflix 奖的参赛者们对他们试图预测其品味的客户的任何人口统计数据一无所知。各团队有时会在讨论板上争论,如果他们知道客户 465 号是一位 23 岁的亚利桑那州女性,他们的预测是否会更准确。然而,大多数领先的团队表示,个人信息并没有多大用处,因为它太粗糙了。正如一个团队向我指出的那样,我是一个 40 岁的西村居民这一事实并没有多大的预测价值。没有理由认为我所在街区的其他 40 岁男性会喜欢和我一样的电影。相比之下,Netflix 的数据在意义上要丰富得多。当我告诉 Netflix,我认为伍迪·艾伦的黑色喜剧《赛点》值得三颗星,而乔斯·韦登的科幻电影《宁静》是一部五星级的杰作时,这就能很好地反映我的品味。事实上,里德·哈斯廷斯告诉我,尽管 Netflix 拥有大量关于其用户的人口统计数据,但该公司目前并没有用它来生成电影推荐;矛盾的是,仅仅知道人们的身份,并不能很好地预测他们的电影品味。
As the teams have grown better at predicting human preferences, the more incomprehensible their computer programs have become, even to their creators. Each team has lined up a gantlet of scores of algorithms, each one analyzing a slightly different correlation between movies and users. The upshot is that while the teams are producing ever - more - accurate recommendations, they cannot precisely explain how they’re doing this. Chris Volinsky admits that his team’s program has become a black box, its internal logic unknowable.
随着各团队在预测人类偏好方面变得越来越擅长,他们的计算机程序也变得越来越难以理解,即使是对其创作者来说也是如此。每个团队都排出了数十种算法,每一种都在分析电影和用户之间略有不同的相关性。结果是,尽管各团队正在产生越来越准确的推荐,但他们无法准确解释他们是如何做到的。克里斯·沃林斯基承认,他们团队的程序已经变成了一个黑箱,其内部逻辑无法知晓。
There’s a sort of unsettling, alien quality to their computers’ results. When the teams examine the ways that singular value decomposition is slotting movies into categories, sometimes it makes sense to them — as when the computer highlights what appears to be some essence of nerdiness in a bunch of sci - fi movies. But many categorizations are now so obscure that they cannot see the reasoning behind them. Possibly the algorithms are finding connections so deep and subconscious that customers themselves wouldn’t even recognize them. At one point, Chabbert showed me a list of movies that his algorithm had discovered share some ineffable similarity; it includes a historical movie, “Joan of Arc,” a wrestling video, “W.W.E.: SummerSlam 2004,” the comedy “It Had to Be You” and a version of Charles Dickens’s “Bleak House.” For the life of me, I can’t figure out what possible connection they have, but Chabbert assures me that this singular value decomposition scored 4 percent higher than Cinematch — so it must be doing something right. As Volinsky surmised, “They’re able to tease out all of these things that we would never, ever think of ourselves.” The machine may be understanding something about us that we do not understand ourselves.
他们的计算机结果有一种令人不安的、外星般的特质。当团队们查看奇异值分解是如何将电影归类时,有时它们是有意义的——比如当计算机突出显示一批科幻电影中似乎带有某种极客气质时。但现在许多分类如此晦涩难懂,以至于他们无法理解其背后的逻辑。也许这些算法正在发现如此深奥、如此潜意识的联系,以至于连顾客自己都无法察觉。在某个时刻,沙伯特给我看了一张电影列表,他的算法发现这些电影之间有一种难以言喻的相似之处;其中包括一部历史电影《圣女贞德》,一部摔跤视频《WWE:2004 年夏日狂潮》,一部喜剧《非你莫属》以及查尔斯·狄更斯的《荒凉山庄》的一个版本。我实在想不出它们之间可能有什么联系,但沙伯特向我保证,这种奇异值分解的得分比 Cinematch 高出 4%,所以它一定有它的道理。正如沃林斯基所推测的那样,“它们能够揭示出我们自己永远也想不到的东西。”机器可能正在理解一些连我们自己都不理解的东西。
Competitors in the Netflix $1 million challenge share their strategies for designing a program that will know your movie taste. (Nov. 23, 2008)
Netflix 100 万美元挑战赛的参赛者分享了他们设计程序的策略,这些程序将了解你的电影品味。(2008 年 11 月 23 日)
Yet it’s clear that something is still missing. Volinsky’s momentum has slowed down significantly, as everyone else’s has. There’s some X factor in human judgment that the current bunch of algorithms isn’t capturing when it comes to movies like “Napoleon Dynamite.” And the problem looms large. Bertoni is currently at 8.8 percent; he says that a small group of mainly independent movies represents more than half of the remaining errors in the way of winning the prize. Most teams suspect that continuing to tweak existing algorithms won’t be enough to get to 10 percent. They need another breakthrough — some way to digitally replicate the love / hate dynamic that governs hard - to - pigeonhole indie films.
然而,很明显,仍然缺少了一些东西。沃林斯基的进展速度已经大幅放缓,就像其他人的进展一样。在像《纳波莱恩·达奈特》这样的电影上,目前的算法并没有捕捉到人类判断中的某种 X 因素。而这个问题相当突出。贝尔托尼目前达到了 8.8%;他说,一组主要是独立电影的小群体代表了赢得奖金道路上剩余错误的一半以上。大多数团队怀疑,继续调整现有的算法将不足以达到 10%。他们需要另一个突破——某种方法来数字复制那些难以归类的独立电影所遵循的爱/恨动态。
“This last half - percent really is the Mount Everest,” Volinsky said. “It’s going to take one of these ‘aha’ moments.”
“这最后的半个百分点才是真正珠穆朗玛峰,”沃林斯基说。“这将需要一个‘啊哈’时刻。”
SOME COMPUTER SCIENTISTS think the “Napoleon Dynamite” problem exposes a serious weakness of computers. They cannot anticipate the eccentric ways that real people actually decide to take a chance on a movie.
一些计算机科学家认为,《大人物拿破仑》问题暴露了计算机的一个严重弱点。它们无法预测现实中人们决定冒险看一部电影时的古怪方式。
The Cinematch system, like any recommendation engine, assumes that your taste is static and unchanging. The computer looks at all the movies you’ve rated in the past, finds the trend and uses that to guide you. But the reality is that our cultural tastes evolve, and they change in part because we interact with others. You hear your friends gushing about “Mad Men,” so eventually — even though you have never had any particular interest in early - ’60s America — you give it a try. Or you go into the video store and run into a particularly charismatic clerk who persuades you that you really, really have to give “The Life Aquatic With Steve Zissou” a chance.
像任何推荐引擎一样,Cinematch 系统假设你的品味是静态且一成不变的。计算机查看你过去评价过的所有电影,找出趋势,并用它来指导你。但现实是,我们的文化品味在不断发展,部分原因是我们在与他人互动。你听到朋友们热烈谈论《广告狂人》,所以最终——尽管你从未对 20 世纪 60 年代初的美国特别感兴趣——你还是尝试了一下。或者你走进录像店,遇到了一个特别有魅力的店员,他说服你,你真的、真的必须给《与史蒂夫·茨索的水下生活》一个机会。
As Gavin Potter, a Netflix Prize competitor who lives in Britain and is currently in ninth place, pointed out to me, a computerized recommendation system seeks to find the common threads in millions of people’s recommendations, so it inherently avoids extremes. Video - store clerks, on the other hand, are influenced by their own idiosyncrasies. Even if they’re considering your taste to make a suitable recommendation, they can’t help relying on their own sense of what’s good and bad. They’ll make more mistakes than the Netflix computers — but they’re also more likely to have flashes of inspiration, like pointing you to “Napoleon Dynamite” at just the right moment.
正如目前排名第九、居住在英国的 Netflix 奖竞争者加文·波特向我指出的那样,计算机化的推荐系统试图在数百万人的推荐中寻找共同点,因此它本质上避免了极端情况。另一方面,录像店店员会受到他们自身个性的影响。即使他们在考虑你的品味以做出合适的推荐时,他们也无法避免依赖于自己对好坏的判断。他们比 Netflix 的计算机犯更多的错误——但他们也更有可能灵光一现,比如在恰好的时刻向你推荐《纳波莱恩·达奈特》。
“If you use a computerized system based on ratings, you will tend to get very relevant but safe answers,” Potter says. “If you go with the movie - store clerk, you will get more unpredictable but potentially more exciting recommendations.”
“如果你使用基于评分的计算机化系统,你往往会得到非常相关但安全的答案,”波特说。“如果你选择电影店店员,你会得到更不可预测但可能更令人兴奋的建议。”
Another critic of computer recommendations is, oddly enough, Pattie Maes, the M.I.T. professor. She notes that there’s something slightly antisocial — “narrow - minded” — about hyperpersonalized recommendation systems. Sure, it’s good to have a computer find more of what you already like. But culture isn’t experienced in solitude. We also consume shows and movies and music as a way of participating in society. That social need can override the question of whether or not we’ll like the movie.
另一位对计算机推荐持批评态度的人,有点讽刺的是,麻省理工学院的教授帕蒂·梅斯。她指出,过度个性化的推荐系统有点反社会——“狭隘”。当然,让计算机找到更多你已经喜欢的东西是好事。但文化并不是在孤独中体验的。我们也通过观看节目、电影和音乐来参与社会。这种社会需求可能会压倒我们是否会喜欢这部电影的问题。
“You don’t want to see a movie just because you think it’s going to be good,” Maes says. “It’s also because everyone at school or work is going to be talking about it, and you want to be able to talk about it, too.” Maes told me that a while ago she rented a “Sex and the City” DVD from Netflix. She suspected she probably wouldn’t really like the show. “But everybody else was constantly talking about it, and I had to know what they were talking about,” she says. “So even though I would have been embarrassed if Netflix suggested ‘Sex and the City’ to me, I’m glad I saw it, because now I get it. I know all the in - jokes.”
“你不想去看一部电影,只是因为你认为它会很好看,”梅斯说。“也是因为学校或工作中的每个人都会谈论它,而你也想参与讨论。”梅斯告诉我,不久前她在 Netflix 上租了一张《欲望都市》的 DVD。她怀疑自己可能不会真的喜欢这个节目。“但其他人都在不断地谈论它,我必须知道他们在谈论什么,”她说。“所以即使我如果 Netflix 向我推荐《欲望都市》,我会感到尴尬,我很高兴我看了它,因为现在我明白了。我知道所有的内部笑话。”
Maes suspects that in the future, computer - based reasoning will become less important for online retailers than social - networking tools that tap into the social zeitgeist, that let customers see, in Facebook fashion, for example, what their close friends are watching and buying. (Potter has an even more intriguing idea. He says he thinks that a recommendation system could predict cultural microtrends by monitoring news events. His research has found, for example, that people rent more movies about Wall Street when the stock market drops.) In the world of music, there are already several innovative recommendation services that try to analyze buzz — by monitoring blogs for repeated mentions of up - and - coming bands, or by sifting through millions of people’s playlists to see if a new band is suddenly getting a lot of attention.
梅斯怀疑,在未来,基于计算机的推理对于在线零售商来说,将不如能够捕捉社会潮流的社交网络工具重要,这些工具可以让客户像在 Facebook 上一样,看到他们的密友正在观看和购买什么。(波特有一个更有趣的想法。他说,他认为一个推荐系统可以通过监测新闻事件来预测文化微观趋势。他的研究发现,例如,当股市下跌时,人们会租借更多关于华尔街的电影。)在音乐领域,已经有一些创新的推荐服务试图通过分析博客中对新兴乐队的反复提及,或者筛选数百万用户的播放列表来看是否有新乐队突然受到大量关注,来分析热门趋势。
Of course, for a company like Netflix, there’s a downside to pushing exciting - but - risky movie recommendations on viewers. If Netflix tries to stretch your taste by recommending more daring movies, it also risks annoying customers. A bad movie recommendation can waste an evening.
当然,对于像 Netflix 这样的公司来说,在向观众推荐令人兴奋但有风险的电影时也存在弊端。如果 Netflix 试图通过推荐更具冒险性的电影来拓展你的品味,它也可能会惹恼顾客。一部糟糕的电影推荐可能会浪费一个晚上。
Is there any way to find a golden mean? When I put the question to Reed Hastings, the Netflix C.E.O., he told me he suspects that there won’t be any simple answer. The company needs better algorithms; it needs breakthrough techniques like singular value decomposition, with the brilliant but inscrutable insights it enables. But Hastings also says he thinks Maes is right, too, and that social - networking tools will become more useful. (Netflix already has one, in fact — an application that lets users see what their family and peers are renting. But Hastings admits it hasn’t been as valuable as computerized intelligence; only a very small percentage of rentals are driven by what friends have chosen.) Hastings is even considering hiring cinephiles to watch all 100,000 movies in the Netflix library and write up, by hand, pages of adjectives describing each movie, a cloud of tags that would offer a subjective view of what makes films similar or dissimilar. It might imbue Cinematch with more unpredictable, humanlike intelligence.
有没有办法找到一个平衡点呢?当我把这个问题抛给 Netflix 首席执行官里德·哈斯廷斯时,他告诉我,他认为不会有一个简单的答案。公司需要更好的算法;它需要像奇异值分解这样的突破性技术,以及它所带来的出色但难以理解的见解。但哈斯廷斯也说,他认为梅斯说得对,社交网络工具将变得更有用。(事实上,Netflix 已经有一个了——一个可以让用户看到他们的家人和同龄人在租什么的应用程序。但哈斯廷斯承认,它并没有计算机化智能那么有价值;只有极小一部分租赁是受朋友选择的驱动。)哈斯廷斯甚至在考虑聘请电影爱好者观看 Netflix 资料库中的全部 10 万部电影,并手工编写描述每部电影的形容词页面,一个提供主观观点的标签云,以表明电影之间的相似之处或不同之处。这可能会使 Cinematch 更具不可预测性,更像人类的智能。
“Human beings are very quirky and individualistic, and wonderfully idiosyncratic,” Hastings says. “And while I love that about human beings, it makes it hard to figure out what they like.”
“人类是非常古怪、个性化的,有着奇妙的怪癖,”哈斯廷斯说。“尽管我喜欢人类的这些特质,但这也使得很难弄清楚他们到底喜欢什么。”
Clive Thompson, a contributing writer for the magazine, writes frequently about technology.
《纽约时报》杂志的特约撰稿人克里夫·汤普森经常撰写有关技术的文章。
The $1 Million Netflix Challenge
Netflix 百万美元挑战赛
VP Jim Bennett discusses how recommendation systems suggest your next movie and the challenges of building a better one.
副总裁 Jim Bennett 探讨了推荐系统如何为用户推荐下一部电影,以及构建更优质推荐系统所面临的挑战。
By Kate Greene
October 6, 2006
Earlier this week, Netflix, the online movie rental service, announced it will award $1 million to anyone who can come up with an algorithm that improves the accuracy of its movie recommendation service.
本周早些时候,在线电影租赁服务提供商 Netflix 宣布,将向任何能开发出可提高其电影推荐服务准确性的算法的人颁发 100 万美元奖金。
Netflix’ star rating system helps determine personalized movie recommendations. Now the company is looking to outside developers to improve those recommendations.
Netflix 的星级评分系统有助于确定个性化的电影推荐。如今,该公司正寻求外部开发者来改进这些推荐功能。
In doing so, the company is putting out a call to researchers who specialize in machine learning–the type of artificial intelligence used to build systems that recommend music, books, and movies. The entrant who can increase the accuracy of the Netflix recommendation system, which is called Cinematch, by 10 percent by 2011 will win the prize.
为此,该公司正向机器学习领域的研究人员发出呼吁。机器学习是一种人工智能技术,可用于构建音乐、书籍和电影等推荐系统。凡能在 2011 年前将 Netflix 名为 Cinematch 的推荐系统的准确性提高 10% 的参赛者,均可获得该奖项。
Recommendation systems such as those used by Netflix, Amazon, and other Web retailers are based on the principle that if two people enjoy the same product, they’re likely to have other favorites in common too.
Netflix、亚马逊及其他网络零售商所使用的推荐系统,均基于这样一个原理:若两个人喜欢同一款产品,他们很可能还拥有其他共同喜爱的产品。
But behind this simple premise is a complex algorithm that incorporates millions of user ratings, tens of thousands of items, and ever-changing relationships between user preferences.
但在这个简单前提的背后,是一套复杂的算法。该算法整合了数百万条用户评分、数万件商品信息,以及用户偏好之间不断变化的关联关系。
To deal with this complexity, algorithms for recommendation systems are “trained” on huge datasets. One dataset used in Netflix’s system contains the star ratings–one to five–that Netflix customers assign to movies. Using this initial information, good algorithms are able to predict future ratings, and therefore can suggest other films that an individual might like.
为应对这种复杂性,推荐系统的算法需要在海量数据集上进行“训练”。Netflix 系统中使用的一个数据集包含了其用户对电影给出的 1 至 5 星评分。优秀的算法可利用这些初始信息预测用户未来的评分,进而推荐该用户可能喜欢的其他电影。
Because access to such a dataset is critical to improving the quality of its recommendation systems, the company also released 100 million recommendations–stripped of any personal identifying information–according to Jim Bennett, vice president of recommendations systems at Netflix.
Netflix 推荐系统副总裁 Jim Bennett 表示,由于获取此类数据集对提高推荐系统质量至关重要,该公司还公开了 1 亿条推荐数据——且已去除所有个人身份识别信息。
We spoke with Bennett this week about how recommendation systems work–and the challenges of building a better one.
本周,我们就推荐系统的工作原理以及构建更优质推荐系统所面临的挑战,与 Bennett 进行了对话。
Technology Review: Before building a better recommendation system, it would be useful to understand your current approach. How does Cinematch work?
《技术评论》: 在构建更优质的推荐系统之前,了解贵公司当前的方法会很有帮助。Cinematch 是如何运作的?
Jim Bennett: First, you collect 100 million user ratings for about 18,000 movies. Take any two movies and find the people who have rated both of them. Then look to see if the people who rate one of the movies highly rate the other one highly, if they liked one and not the other, or if they didn’t like either movie. Based on their ratings, Cinematch sees whether there’s a correlation between those people. Now, do this for all possible pairs of 65,000 movies.
Jim Bennett: 首先,我们会收集用户对约 1.8 万部电影的 1 亿条评分数据。任意选取两部电影,找出对这两部电影都进行过评分的用户,然后观察这些用户的评分情况:是对其中一部电影给出高分的同时也对另一部给出高分,还是喜欢一部而不喜欢另一部,亦或是两部都不喜欢。Cinematch 会根据这些用户的评分,判断他们之间是否存在关联。接下来,我们会对全部 6.5 万部电影的所有可能组合都执行上述操作。
TR: So Cinematch would recommend movies to me based on the evaluations of people who rated movies the way I did. Does that method work for all movies at Netflix?
《技术评论》: 这么说,Cinematch 会根据与我评分习惯相似的用户的评价,为我推荐电影。这种方法对 Netflix 平台上的所有电影都有效吗?
JB: A lot of the really obscure discs, for instance, the “How to Mow a Lawn” DVDs, don’t have very many ratings and this method doesn’t work as well. For movies with a large number of ratings, you do substantially well. But to make it work, there needs to be a lot of data-tuning because people can sometimes have interesting rating patterns.
Jim Bennett: 很多非常冷门的影碟,比如《如何修剪草坪》这类 DVD,没有太多评分数据,所以这种方法对它们效果不佳。而对于评分数量较多的电影,这种方法的效果会好很多。但要让该方法有效运作,还需要进行大量的数据调优,因为人们有时会呈现出一些特殊的评分模式。
TR: Like what?
《技术评论》: 比如哪些模式?
JB: For example, there are many people who rate a movie with only one star or five stars. And there are some people who just rate everything with three stars. What you’re looking for is an interesting spread of opinions because you’re trying to capture correlations. That’s the core of the engine.
Jim Bennett: 例如,很多人给电影评分时只打 1 星或 5 星;还有一些人则对所有内容都打 3 星。我们需要的是多样化的评价分布,因为我们要从中捕捉关联关系,这正是该推荐引擎的核心所在。
TR: How do you quantitatively measure the accuracy of your system?
《技术评论》: 你们如何定量衡量系统的准确性?
JB: We trained Cinematch on 100 million ratings and asked it to predict what the other 3 million would be. We compared ours with the actual answers. We do that every day. We get about 2 million ratings per day and we track the daily fluctuations of the system. We expect to measure submissions to the contest [the same way]. The actual prize dataset is 103 million ratings, but we only released 100 million of them.
Jim Bennett: 我们先用 1 亿条评分数据对 Cinematch 进行训练,然后让它预测另外 300 万条评分的结果,并将预测结果与实际评分进行对比。我们每天都会这样操作:每天会获取约 200 万条新评分,并跟踪系统准确性的每日波动情况。我们计划采用同样的方式来评估参赛算法。此次挑战赛的实际 prize 数据集包含 1.03 亿条评分,但我们只公开了其中的 1 亿条。
TR: In order to win the $1 million prize, a new algorithm needs to improve the accuracy of recommendations by 10 percent over Cinematch. You’re also rewarding a $50,000 “progress” prize each year for the algorithm that shows the most improvement over the previous year’s best algorithm, by at least 1 percent. What will these percentage improvements mean to a Netflix customer?
《技术评论》: 要赢得 100 万美元奖金,新算法需将推荐准确性较 Cinematch 提高 10%。此外,你们每年还会颁发 5 万美元的“进步奖”,授予那些较上一年最佳算法的准确性至少提高 1% 的算法开发者。这些百分比的提升对 Netflix 用户来说意味着什么?
JB: If you go to the website and rate 100 movies for us, the red stars shown under each movie are personalized for you. We use these ratings to adjust the prediction away from the average recommendation, according to your taste. A three-percent difference, for instance, might make a difference of one-quarter star. We have millions of people rating millions of DVDs, and that quarter-star difference helps us sort the list. The individual movie recommendation might not get so much better, but, overall, the set of recommended movies is very different. Move a battleship a little bit, and it makes a huge difference.
Jim Bennett: 如果你在我们的网站上为 100 部电影评分,那么每部电影下方显示的红色星级评分都是为你个性化定制的。我们会根据这些评分,结合你的喜好,将推荐结果从平均推荐水平调整为更符合你口味的内容。例如,3% 的准确性提升可能会带来 0.25 星的评分预测差异。我们有数百万人在为数百万张 DVD 评分,而这 0.25 星的差异能帮助我们更好地对推荐列表进行排序。虽然单部电影的推荐可能不会有太大改善,但总体来看,整个推荐影片组合会有显著不同。这就好比调整战舰的航向,哪怕只是微调,也会带来巨大的变化。
TR: Why are recommendation systems so hard to improve?
《技术评论》: 为什么推荐系统的改进如此困难?
JB: One of the reasons is there are no datasets. Many of the machine-learning applications require fairly substantial datasets that easily have millions of data points. There are lots of different approaches to solving the problem, but they all need large datasets. And as with many datasets, once we’ve applied the techniques to those datasets, there’s no place to go.
Jim Bennett: 原因之一是缺乏可用的数据集。许多机器学习应用都需要规模庞大的数据集——通常包含数百万个数据点。虽然解决推荐问题的方法有很多,但所有方法都离不开海量数据集的支持。而且,对于许多数据集而言,一旦我们将现有技术应用于这些数据,就很难再通过这些数据实现进一步的突破。
TR: So you’re looking for an algorithm that tackles the problem in a completely different way than Cinematch?
《技术评论》: 所以你们在寻找一种与 Cinematch 完全不同的问题解决思路的算法?
JB: Correct. As far as we know, there are many good ideas out in the field. We just can’t test them all. We know that there are people who are really on top of the literature who know the ins and outs of [recommendation systems] and we’d really like to know which ones would be better.
Jim Bennett: 没错。据我们所知,该领域内有很多不错的想法,只是我们无法逐一测试。我们知道有些研究者非常熟悉相关文献,对推荐系统的来龙去脉了如指掌,而我们很想知道哪些想法会更有效。
TR: What are some approaches, discussed in the literature, which could work, but haven’t been tested with movie recommendations yet?
《技术评论》: 文献中有没有讨论过一些可能可行,但尚未在电影推荐领域测试过的方法?
JB: It’s hard to say. There was an article in Science a few months ago [July 28, 2006] that used an interesting combination of two types of neural networks [a computational method that sorts data similar to the human brain]. One neural network supervises the machine learning and the other steers that learning. At Netflix, we look at correlations between ratings, and that’s a linear model. Not all knowledge can be represented by a linear combination of features. This particular model in Science uses a nonlinear approach. I think that technique could be quite good.
Jim Bennett: 这很难一概而论。几个月前(2006 年 7 月 28 日),《科学》(Science)杂志上发表过一篇文章,文中采用了一种有趣的方法——将两种神经网络(一种类似人类大脑的数据分类计算方法)结合起来。其中一个神经网络负责监督机器学习过程,另一个则引导学习方向。而在 Netflix,我们目前主要关注评分之间的关联关系,这属于线性模型的范畴。但并非所有信息都能通过特征的线性组合来表示,而《科学》杂志中提到的这种特定模型采用了非线性方法,我认为该技术可能会有很好的效果。
TR: Are there any other pressing technical challenges at Netflix that might be solved by offering a prize?
《技术评论》: Netflix 是否还有其他紧迫的技术难题,可以通过设立奖项的方式来解决?
JB: I wouldn’t want to speculate on more contests. Are there other technical challenges? Absolutely. Beyond the systems challenge of keeping the recommendation engines up and running with an increasing customer base, we also have a huge number of challenges within the company–like trying to ship two millions discs a day to people. And there are interesting challenges ahead as we get ready for the download world [where people can download movies via the Internet]. The company’s filled with tremendous challenges.
Jim Bennett: 我不想对是否举办更多比赛进行猜测。但 Netflix 确实存在其他技术难题吗?答案是肯定的。除了随着用户数量增长,需确保推荐引擎持续正常运行这一系统层面的挑战外,公司内部还面临诸多难题——例如,每天要向用户配送 200 万张影碟。此外,在我们为电影下载时代(用户可通过互联网下载电影)做准备的过程中,还会遇到许多新的有趣挑战。整个公司始终面临着大量艰巨的挑战。
Netflix paid men $1 million after challenging world to beat its recommendation algorithm
Netflix 设下“击败推荐算法”挑战,最终向获胜者支付 100 万美元
Updated 15:12 7 Jun 2024 GMT+1
Published 15:13 7 Jun 2024 GMT+1
The 2006 Netflix Prize competition was one of the most interesting business ideas for the company ahead of its move to streaming
2006 年举办的“Netflix 奖”竞赛,是该公司在转向流媒体业务前最具创意的商业举措之一
Dylan Murray
Dylan Murray
While many know Netflix for innovating the modern streaming model that has revolutionized how we watch film and television, few know much about the company’s history before it began streaming in 2007.
尽管许多人知晓 Netflix 是因为其革新了现代流媒体模式——这种模式彻底改变了我们观看影视内容的方式,但很少有人了解该公司在 2007 年推出流媒体服务之前的历史。
Before Netflix streaming became a thing, the company focused on being a video rental company that sent DVDs to their monthly subscribers through the mail.
在 Netflix 流媒体服务问世之前,该公司的核心业务是视频租赁:通过邮寄方式,向月度订阅用户寄送 DVD。
Yep, remember those discs we used to watch films on?
没错,还记得那些我们过去用来观看电影的光盘吗?
Anyway, during this time, they still had their now-famous recommendation system. This algorithm recognizes the things you’ve seen and enjoyed using Netflix and gives you tailored suggestions of what to watch next.
无论如何,在这一时期,该公司已拥有如今广为人知的推荐系统。该算法会识别用户在 Netflix 上已观看且喜爱的内容,并为用户量身推荐接下来可观看的内容。
A year before the company’s streaming service finally began, Netflix wanted to get an outside perspective on the algorithm.
在流媒体服务正式推出的前一年,Netflix 希望从外部视角对其推荐算法进行优化。
Thus, the Netflix Challenge began, with the company offering $1 million to anyone who could improve their algorithm substantially - by 10 percent or more by the time 2011 came around.
于是,“Netflix 挑战”应运而生:公司承诺,截至 2011 年,若有人能将其算法的性能大幅提升 10% 或以上,即可获得 100 万美元奖金。
The challenge was widespread, with 50,000 participants from across the world attempting to win the cash prize over years the contest was held.
这项挑战影响力甚广:在竞赛举办的数年里,全球共有 50,000 名参赛者试图赢得这笔现金大奖。
The idea was highly praised by many business experts, with the idea of crowdsourcing such a task being viewed as the way of the future in the late 2000s.
这一举措受到众多商业专家的高度评价:在 21 世纪初,通过众包模式完成此类任务的理念被视为未来的发展方向。
Eventually, winners were crowned, and it didn’t even take the full five years.
最终,获奖者脱颖而出,且整个过程甚至未用满原定的五年时间。
Netflix streaming has completely changed the way we consume media in the modern era. (Pexels/cottonbro studio)
Netflix 流媒体已彻底改变了现代社会中我们消费媒体内容的方式。(图片来源:Pexels/cottonbro studio)
In 2009, a group of individuals that called themselves BellKor’s Pragmatic Chaos won the $1 million prize, as they had improved Netflix’s algorithm by a full 10.05 percent.
2009 年,一个自称为“BellKor’s Pragmatic Chaos”的团队赢得了 100 万美元奖金,因为他们将 Netflix 算法的性能整整提升了 10.05%。
But shockingly, Netflix wound up never using the contest winners’ most successful algorithm.
但令人惊讶的是,Netflix 最终从未使用过竞赛获胜者研发的这套最成功的算法。
In a blog post by the company back in 2012, they explained the two primary reasons they had not implemented the algorithm despite paying out a million dollars to the winners.
在 2012 年该公司发布的一篇博文中,Netflix 解释了尽管已向获胜者支付百万奖金,却仍未采用该算法的两个主要原因。
“The additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment,” the blog post read, “Also, our focus on improving Netflix personalization had shifted to the next level by then.”
博文写道:“我们评估后发现,算法额外提升的准确率,并不足以支撑将其投入生产环境所需的工程成本;此外,截至当时,我们在优化 Netflix 个性化服务方面的重心已转向更高层面。”
This ‘next level’ they were referring to was the global streaming model, which had begun taking the world by storm by the time the contest came to an end and Netflix’s team began work on implementing the winning algorithm.
他们所提及的“更高层面”,指的是全球流媒体模式——在竞赛结束、Netflix 团队着手准备采用获胜算法时,该模式已开始在全球范围内迅速崛起。

(Jason Kempin/Getty Images for Sunshine Sachs)
The blog post continued: “Streaming has not only changed the way our members interact with the service, but also the type of data available to use in our algorithms.”
博文进一步指出:“流媒体不仅改变了用户使用我们服务的方式,也改变了我们算法可调用的数据类型。”
“Streaming members are looking for something great to watch right now; they can sample a few videos before settling on one, they can consume several in one session, and we can observe viewing statistics such as whether a video was watched fully or only partially.”
“流媒体用户希望立即找到优质内容观看:他们可以在确定观看某一视频前试看多个片段,也可以在一次使用中观看多部内容;此外,我们还能获取观看统计数据,例如用户是完整观看了某视频,还是仅观看了部分内容。”
However, the contest wasn’t all for naught, as the research and development that the company was able to crowdsource meant that they had already improved their original algorithm by 8.43% before handing out the million dollars.
不过,这场竞赛并非毫无意义:通过众包模式开展的研发工作,使得 Netflix 在发放百万奖金之前,已将其原始算法的性能提升了 8.43%。
Netflix Recommendations: Beyond the 5 stars (Part 1)
Netflix 推荐系统:不止于五星评分(第一部分)
Netflix Technology Blog
Apr 6, 2012
by Xavier Amatriain and Justin Basilico (Personalization Science and Engineering)
作者:Xavier Amatriain 与 Justin Basilico(个性化科学与工程团队)
In this two-part blog post, we will open the doors of one of the most valued Netflix assets: our recommendation system. In Part 1, we will relate the Netflix Prize to the broader recommendation challenge, outline the external components of our personalized service, and highlight how our task has evolved with the business. In Part 2, we will describe some of the data and models that we use and discuss our approach to algorithmic innovation that combines offline machine learning experimentation with online AB testing. Enjoy… and remember that we are always looking for more star talent to add to our great team, so please take a look at our jobs page.
在这篇分为两部分的博客文章中,我们将揭开 Netflix 最宝贵的资产之一——推荐系统的神秘面纱。在第一部分,我们将把 Netflix 挑战赛(Netflix Prize)与更广泛的推荐难题联系起来,概述个性化服务的外部构成,并强调我们的任务如何随业务发展而演变。在第二部分,我们将介绍所使用的部分数据与模型,并探讨算法创新的方法——该方法结合了离线机器学习实验与在线 A/B 测试。
The Netflix Prize and the Recommendation Problem
Netflix 挑战赛与推荐难题
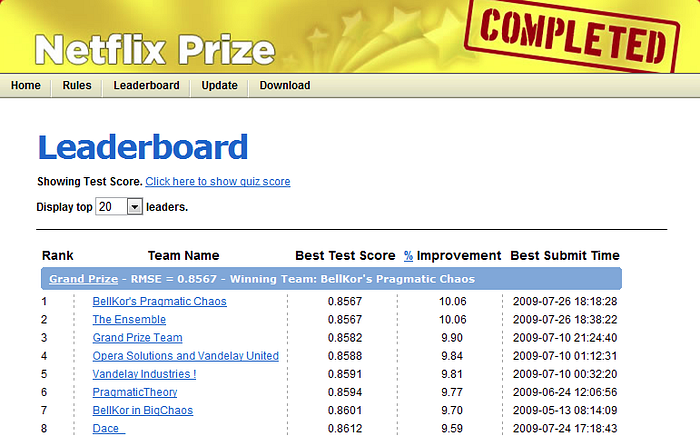
In 2006 we announced the Netflix Prize, a machine learning and data mining competition for movie rating prediction. We offered $1 million to whoever improved the accuracy of our existing system called Cinematch by 10%. We conducted this competition to find new ways to improve the recommendations we provide to our members, which is a key part of our business. However, we had to come up with a proxy question that was easier to evaluate and quantify: the root mean squared error (RMSE) of the predicted rating. The race was on to beat our RMSE of 0.9525 with the finish line of reducing it to 0.8572 or less.
2006 年,我们宣布启动 Netflix 挑战赛——这是一场围绕电影评分预测展开的机器学习与数据挖掘竞赛。我们承诺,凡能将现有系统 Cinematch 的准确性提高 10% 的参赛者,均可获得 100 万美元奖金。举办此次竞赛的目的,是为了寻找改进会员推荐服务的新方法,而推荐服务正是我们业务的核心组成部分。不过,我们需要设定一个更易于评估和量化的替代指标:预测评分的均方根误差(Root Mean Squared Error, RMSE)。竞赛的目标很明确:击败我们当时 0.9525 的 RMSE 数值,将其降至 0.8572 或更低。
A year into the competition, the Korbell team won the first Progress Prize with an 8.43% improvement. They reported more than 2000 hours of work in order to come up with the final combination of 107 algorithms that gave them this prize. And, they gave us the source code. We looked at the two underlying algorithms with the best performance in the ensemble: Matrix Factorization (which the community generally called SVD, Singular Value Decomposition) and Restricted Boltzmann Machines (RBM). SVD by itself provided a 0.8914 RMSE, while RBM alone provided a competitive but slightly worse 0.8990 RMSE. A linear blend of these two reduced the error to 0.88. To put these algorithms to use, we had to work to overcome some limitations, for instance that they were built to handle 100 million ratings, instead of the more than 5 billion that we have, and that they were not built to adapt as members added more ratings. But once we overcame those challenges, we put the two algorithms into production, where they are still used as part of our recommendation engine.
竞赛开展一年后,Korbell 团队以 8.43% 的改进幅度赢得了首个 进步奖。据他们透露,为了最终整合出 107 种算法并获奖,团队投入了超过 2000 小时的工作。此外,他们还向我们提供了源代码。我们重点研究了该算法组合中表现最佳的两种核心算法:矩阵分解(Matrix Factorization,业界通常称之为奇异值分解 SVD,即 Singular Value Decomposition)与受限玻尔兹曼机(Restricted Boltzmann Machines, RBM)。单独使用 SVD 时,RMSE 为 0.8914;单独使用 RBM 时,RMSE 为 0.8990——虽具有竞争力,但略逊于前者。将两种算法线性融合后,误差降至 0.88。要实际应用这些算法,我们必须克服一些局限性:例如,这些算法最初设计用于处理 1 亿条评分数据,而我们的实际数据量已超过 50 亿条;且它们无法随会员新增评分而实时调整。不过,在攻克这些难题后,我们已将这两种算法投入生产环境,至今它们仍是推荐引擎的重要组成部分。
If you followed the Prize competition, you might be wondering what happened with the final Grand Prize ensemble that won the $1M two years later. This is a truly impressive compilation and culmination of years of work, blending hundreds of predictive models to finally cross the finish line. We evaluated some of the new methods offline but the additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment. Also, our focus on improving Netflix personalization had shifted to the next level by then. In the remainder of this post we will explain how and why it has shifted.
如果您关注过这场竞赛,可能会好奇两年后赢得 100 万美元大奖的最终 冠军算法组合 后续发展如何。该组合确实令人惊叹,是多年研究的结晶——融合了数百个预测模型,最终才达到竞赛目标。我们已通过离线方式评估了其中部分新方法,但发现其带来的额外准确性提升,并不足以支撑将其投入生产环境所需的工程成本。此外,当时我们对 Netflix 个性化服务的优化重点已转向新的层面。在本文后续内容中,我们将解释这一转变的原因与具体方向。
From US DVDs to Global Streaming
从美国 DVD 租赁到全球流媒体服务
One of the reasons our focus in the recommendation algorithms has changed is because Netflix as a whole has changed dramatically in the last few years. Netflix launched an instant streaming service in 2007, one year after the Netflix Prize began. Streaming has not only changed the way our members interact with the service, but also the type of data available to use in our algorithms. For DVDs our goal is to help people fill their queue with titles to receive in the mail over the coming days and weeks; selection is distant in time from viewing, people select carefully because exchanging a DVD for another takes more than a day, and we get no feedback during viewing. For streaming members are looking for something great to watch right now; they can sample a few videos before settling on one, they can consume several in one session, and we can observe viewing statistics such as whether a video was watched fully or only partially.
推荐算法的优化重点发生转变,原因之一是 Netflix 整体业务在过去几年发生了巨大变革。2007 年,也就是 Netflix 挑战赛启动一年后,我们推出了即时流媒体服务。流媒体不仅改变了会员与服务的互动方式,也改变了算法可使用的数据类型。在 DVD 租赁业务中,我们的目标是帮助用户在队列中添加未来几天或几周内将通过邮件收到的影片;影片选择与观看存在时间差,且由于更换 DVD 需耗时一天以上,用户会谨慎选择,同时我们无法在用户观看过程中获取反馈。而在流媒体服务中,会员希望立即找到优质内容观看;他们可以在最终选定前试看多部影片,也可以在一次使用中观看多部内容,此外我们还能获取观看统计数据(如影片是完整观看还是部分观看)。
Another big change was the move from a single website into hundreds of devices. The integration with the Roku player and the Xbox were announced in 2008, two years into the Netflix competition. Just a year later, Netflix streaming made it into the iPhone. Now it is available on a multitude of devices that go from a myriad of Android devices to the latest AppleTV.
另一重大变革是,服务载体从单一网站扩展到数百种设备。2008 年(Netflix 挑战赛开展两年后),我们宣布与 Roku 播放器 和 Xbox 实现集成。仅一年后,Netflix 流媒体服务便登陆 iPhone。如今,从各类 Android 设备 到最新款 AppleTV,众多设备均可使用我们的服务。
Two years ago, we went international with the launch in Canada. In 2011, we added 43 Latin-American countries and territories to the list. And just recently, we launched in UK and Ireland. Today, Netflix has more than 23 million subscribers in 47 countries. Those subscribers streamed 2 billion hours from hundreds of different devices in the last quarter of 2011. Every day they add 2 million movies and TV shows to the queue and generate 4 million ratings.
两年前,我们通过在 加拿大推出服务,开启了国际化进程。2011 年,我们将服务扩展到 43 个拉丁美洲国家和地区。就在最近,我们又在 英国和爱尔兰 推出了服务。如今,Netflix 在 47 个国家拥有超过 2300 万订阅用户。2011 年第四季度,这些用户通过数百种不同设备观看了总计 20 亿小时的流媒体内容。每天,他们会向队列中添加 200 万部电影和电视节目,并生成 400 万条评分。
We have adapted our personalization algorithms to this new scenario in such a way that now 75% of what people watch is from some sort of recommendation. We reached this point by continuously optimizing the member experience and have measured significant gains in member satisfaction whenever we improved the personalization for our members. Let us now walk you through some of the techniques and approaches that we use to produce these recommendations.
我们已针对这一新场景调整了个性化算法,如今用户观看的内容中,有 75% 来自各类推荐。这一成果源于我们对会员体验的持续优化——我们发现,每当个性化服务得到改进,会员满意度都会显著提升。接下来,我们将为您介绍生成这些推荐所使用的部分技术and approaches.
及方法。
Everything is a Recommendation
万物皆可为推荐
We have discovered through the years that there is tremendous value to our subscribers in incorporating recommendations to personalize as much of Netflix as possible. Personalization starts on our homepage, which consists of groups of videos arranged in horizontal rows. Each row has a title that conveys the intended meaningful connection between the videos in that group. Most of our personalization is based on the way we select rows, how we determine what items to include in them, and in what order to place those items.
多年来我们发现,将推荐融入 Netflix 的各个环节以实现最大化个性化,能为订阅用户带来巨大价值。个性化体验从首页便已开启:首页由多组横向排列的视频内容构成,每一行都有一个标题,用于表明该行视频之间预期的关联意义。我们的个性化工作主要围绕三方面展开:如何选择行、如何确定每行应包含的内容,以及如何排列这些内容的顺序。
Get Netflix Technology Blog’s stories in your inbox
订阅获取 Netflix 技术博客内容
Take as a first example the Top 10 row: this is our best guess at the ten titles you are most likely to enjoy. Of course, when we say “you”, we really mean everyone in your household. It is important to keep in mind that Netflix’ personalization is intended to handle a household that is likely to have different people with different tastes. That is why when you see your Top10, you are likely to discover items for dad, mom, the kids, or the whole family. Even for a single person household we want to appeal to your range of interests and moods. To achieve this, in many parts of our system we are not only optimizing for accuracy, but also for diversity.
以“Top 10”行为例:这是我们对您最可能喜欢的 10 部作品的最佳预测。当然,这里的“您”实际上指的是您整个家庭的成员。需要注意的是,Netflix 的个性化设计旨在满足家庭成员口味各异的需求。因此,当您查看“Top 10”列表时,可能会发现适合父亲、母亲、孩子或全家共同观看的内容。即便对于单身用户,我们也希望推荐能覆盖您不同的兴趣领域和情绪状态。为实现这一目标,我们系统的多个环节不仅会优化推荐准确性,还会注重多样性。

Another important element in Netflix’ personalization is awareness. We want members to be aware of how we are adapting to their tastes. This not only promotes trust in the system, but encourages members to give feedback that will result in better recommendations. A different way of promoting trust with the personalization component is to provide explanations as to why we decide to recommend a given movie or show. We are not recommending it because it suits our business needs, but because it matches the information we have from you: your explicit taste preferences and ratings, your viewing history, or even your friends’ recommendations.
Netflix 个性化服务的另一重要元素是透明度。我们希望会员了解系统是如何根据其口味进行调整的。这不仅能增强会员对系统的信任,还能鼓励他们提供反馈,进而优化推荐效果。通过个性化组件建立信任的另一种方式,是为推荐某部电影或剧集提供理由说明。我们推荐某一内容,并非出于商业利益考量,而是因为它与我们获取的您的信息相匹配——包括您明确表达的口味偏好与评分、观看历史,甚至是朋友的推荐。
On the topic of friends, we recently released our Facebook connect feature in 46 out of the 47 countries we operate — all but the US because of concerns with the VPPA law. Knowing about your friends not only gives us another signal to use in our personalization algorithms, but it also allows for different rows that rely mostly on your social circle to generate recommendations.
谈及朋友,我们近期已在运营业务的 47 个国家中的 46 个推出了 Facebook 关联功能——仅美国因《视频隐私保护法案》(VPPA)相关顾虑暂未推出。了解您朋友的偏好,不仅能为个性化算法提供额外信号,还能生成主要基于您社交圈的专属推荐行。
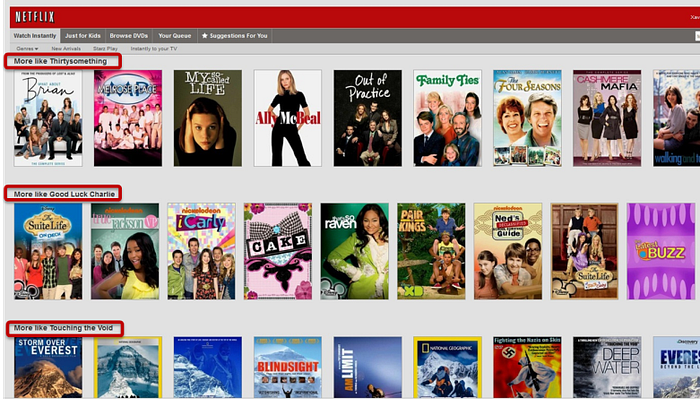
Some of the most recognizable personalization in our service is the collection of “genre” rows. These range from familiar high-level categories like “Comedies” and “Dramas” to highly tailored slices such as “Imaginative Time Travel Movies from the 1980s”. Each row represents 3 layers of personalization: the choice of genre itself, the subset of titles selected within that genre, and the ranking of those titles. Members connect with these rows so well that we measure an increase in member retention by placing the most tailored rows higher on the page instead of lower. As with other personalization elements, freshness and diversity is taken into account when deciding what genres to show from the thousands possible.
我们服务中最易识别的个性化元素之一,是一系列“类型”推荐行。这些类型既包括“喜剧”“剧情”等常见的大类,也有“20 世纪 80 年代奇幻时空旅行电影”这类高度定制化的细分类型。每一行都体现了三层个性化设计:类型的选择、该类型下具体内容的筛选,以及内容的排序。会员对这些推荐行的接受度很高——我们发现,将最贴合会员口味的推荐行置于页面更上方而非下方时,会员留存率会有所提升。与其他个性化元素一样,在从数千种可能的类型中选择展示内容时,我们会同时考虑时效性和多样性。
We present an explanation for the choice of rows using a member’s implicit genre preferences — recent plays, ratings, and other interactions — , or explicit feedback provided through our taste preferences survey. We will also invite members to focus a row with additional explicit preference feedback when this is lacking.
我们会根据会员的隐性类型偏好(近期观看记录、评分及其他互动行为),或通过口味偏好调查收集的显性反馈,为推荐行的选择提供说明。当某类偏好反馈不足时,我们还会邀请会员提供更多显性偏好反馈,以优化对应推荐行。
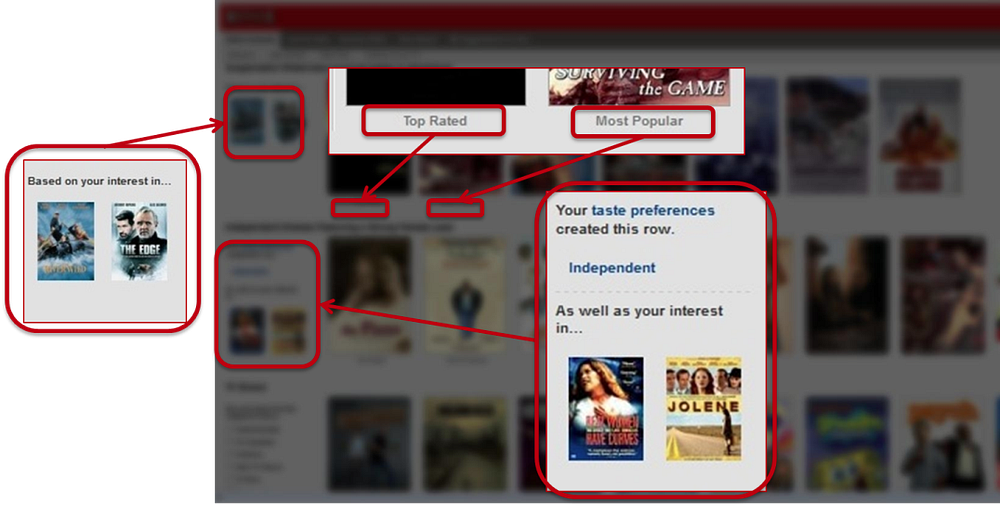
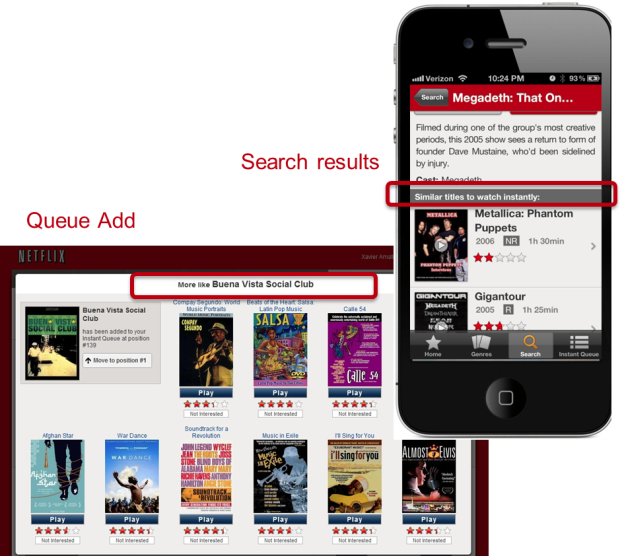
Similarity is also an important source of personalization in our service. We think of similarity in a very broad sense; it can be between movies or between members, and can be in multiple dimensions such as metadata, ratings, or viewing data. Furthermore, these similarities can be blended and used as features in other models. Similarity is used in multiple contexts, for example in response to a member’s action such as searching or adding a title to the queue. It is also used to generate rows of “adhoc genres” based on similarity to titles that a member has interacted with recently. If you are interested in a more in-depth description of the architecture of the similarity system, you can read about it in this past post on the blog.
相似度也是我们服务中个性化的重要来源。我们对“相似度”的定义极为宽泛:既可以是影片之间的相似度,也可以是会员之间的相似度;维度也多种多样,包括元数据、评分、观看数据等。此外,这些相似度数据可被整合,并作为特征应用于其他模型中。相似度在多种场景中发挥作用,例如响应用户的搜索行为或“添加至队列”操作。它还可用于根据会员近期互动过的内容,生成“临时类型”推荐行。
In most of the previous contexts — be it in the Top10 row, the genres, or the similars — ranking, the choice of what order to place the items in a row, is critical in providing an effective personalized experience. The goal of our ranking system is to find the best possible ordering of a set of items for a member, within a specific context, in real-time. We decompose ranking into scoring, sorting, and filtering sets of movies for presentation to a member. Our business objective is to maximize member satisfaction and month-to-month subscription retention, which correlates well with maximizing consumption of video content. We therefore optimize our algorithms to give the highest scores to titles that a member is most likely to play and enjoy.
在上述多数场景中——无论是“Top 10”行、类型推荐行还是相似度推荐行——排序(即确定行内内容的展示顺序)对提供优质个性化体验至关重要。我们的排序系统旨在特定场景下,为会员实时找到一组内容的最佳展示顺序。我们将排序过程拆解为评分、排序和筛选三个环节,最终向会员呈现影片列表。我们的业务目标是最大化会员满意度和月度订阅留存率,而这与最大化视频内容消费量高度相关。因此,我们会优化算法,为会员最可能观看并喜爱的内容赋予最高评分。
Now it is clear that the Netflix Prize objective, accurate prediction of a movie’s rating, is just one of the many components of an effective recommendation system that optimizes our members enjoyment. We also need to take into account factors such as context, title popularity, interest, evidence, novelty, diversity, and freshness. Supporting all the different contexts in which we want to make recommendations requires a range of algorithms that are tuned to the needs of those contexts. In the next part of this post, we will talk in more detail about the ranking problem. We will also dive into the data and models that make all the above possible and discuss our approach to innovating in this space.
如今显而易见的是,Netflix 挑战赛的目标(精准预测影片评分),只是构建有效推荐系统(以优化会员观影体验)的众多环节之一。我们还需考虑场景、内容热度、会员兴趣、推荐依据、新颖性、多样性和时效性等多种因素。要在各类推荐场景中提供支持,就需要一系列针对不同场景需求调整的算法。在本文的下一部分,我们将更详细地探讨排序问题,深入介绍实现上述所有功能的数据与模型,并讨论我们在该领域的创新方法。
Netflix Recommendations: Beyond the 5 stars (Part 2)
Netflix 推荐系统:不止于五星评分(第二部分)
Jun 20, 2012
by Xavier Amatriain and Justin Basilico (Personalization Science and Engineering)
In part one of this blog post, we detailed the different components of Netflix personalization. We also explained how Netflix personalization, and the service as a whole, have changed from the time we announced the Netflix Prize.
在本博客文章的第一部分中,我们详细介绍了 Netflix 个性化服务的各个组成部分,并阐述了自 Netflix 挑战赛宣布以来,个性化服务及整体业务发生的变化。
One of the most valued Netflix assets is our recommendation system
Netflix 最宝贵的资产之一便是我们的推荐系统
The $1M Prize delivered a great return on investment for us, not only in algorithmic innovation, but also in brand awareness and attracting stars (no pun intended) to join our team. Predicting movie ratings accurately is just one aspect of our world-class recommender system. In this second part of the blog post, we will give more insight into our broader personalization technology. We will discuss some of our current models, data, and the approaches we follow to lead innovation and research in this space.
100 万美元的挑战赛奖金为我们带来了丰厚的投资回报:不仅推动了算法创新,还提升了品牌知名度,并吸引了优秀人才(此处“stars”无双关意)加入团队。精准预测影片评分只是我们世界级推荐系统的一个方面。在本文的第二部分,我们将深入介绍更广泛的个性化技术,探讨当前使用的部分模型、数据,以及在该领域引领创新与研究的方法。
Ranking
排序
The goal of recommender systems is to present a number of attractive items for a person to choose from. This is usually accomplished by selecting some items and sorting them in the order of expected enjoyment (or utility). Since the most common way of presenting recommended items is in some form of list, such as the various rows on Netflix, we need an appropriate ranking model that can use a wide variety of information to come up with an optimal ranking of the items for each of our members.
推荐系统的目标是向用户呈现一系列具有吸引力的内容供其选择。这通常通过筛选内容,并按预期喜爱度(或效用)排序来实现。由于推荐内容最常见的呈现形式是列表(如 Netflix 上的各类横向推荐行),我们需要合适的排序模型——该模型需能利用多种信息,为每位会员生成内容的最优排序。
If you are looking for a ranking function that optimizes consumption, an obvious baseline is item popularity. The reason is clear: on average, a member is most likely to watch what most others are watching. However, popularity is the opposite of personalization: it will produce the same ordering of items for every member. Thus, the goal becomes to find a personalized ranking function that is better than item popularity, so we can better satisfy members with varying tastes.
若想设计一个优化内容消费量的排序函数,“内容热度”是一个显而易见的基准。原因很简单:平均而言,会员最可能观看的内容,往往是大多数人正在观看的内容。但“热度”与“个性化”恰好相反——它为所有会员生成的内容排序完全相同。因此,我们的目标是找到一个优于“热度排序”的个性化排序函数,以更好地满足不同口味会员的需求。
Recall that our goal is to recommend the titles that each member is most likely to play and enjoy. One obvious way to approach this is to use the member’s predicted rating of each item as an adjunct to item popularity. Using predicted ratings on their own as a ranking function can lead to items that are too niche or unfamiliar being recommended, and can exclude items that the member would want to watch even though they may not rate them highly. To compensate for this, rather than using either popularity or predicted rating on their own, we would like to produce rankings that balance both of these aspects. At this point, we are ready to build a ranking prediction model using these two features.
要记住,我们的目标是推荐会员最可能观看且喜爱的内容。实现这一目标的一个直观方法,是将会员对各内容的预测评分作为“内容热度”的补充指标。若仅将预测评分作为排序依据,可能会导致推荐内容过于小众或陌生,同时也可能遗漏那些会员虽不会给出高分、但仍愿意观看的内容。为弥补这一缺陷,我们不会单独依赖“热度”或“预测评分”,而是希望生成能平衡这两个维度的排序结果。至此,我们已准备好利用这两个特征构建排序预测模型。
There are many ways one could construct a ranking function ranging from simple scoring methods, to pairwise preferences, to optimization over the entire ranking. For the purposes of illustration, let us start with a very simple scoring approach by choosing our ranking function to be a linear combination of popularity and predicted rating. This gives an equation of the form frank(u,v)=w1p(v)+w2r(u,v)+bfrank(u,v) = w_1 p(v) + w_2 r(u,v) + bfrank(u,v)=w1p(v)+w2r(u,v)+b, where uuu=user, vvv=video item, ppp=popularity and rrr=predicted rating. This equation defines a two-dimensional space like the one depicted below.
构建排序函数的方法有很多,从简单的评分法、成对偏好比较法,到对整个排序结果的优化法,不一而足。为便于说明,我们先从一种非常简单的评分方法入手:将排序函数设定为“热度”与“预测评分”的线性组合。由此可得到如下公式:frank(u,v)=w1p(v)+w2r(u,v)+bfrank(u,v) = w_1 p(v) + w_2 r(u,v) + bfrank(u,v)=w1p(v)+w2r(u,v)+b,其中 uuu 代表用户,vvv 代表视频内容,ppp 代表热度,rrr 代表预测评分。该公式对应一个二维空间,如下图所示。
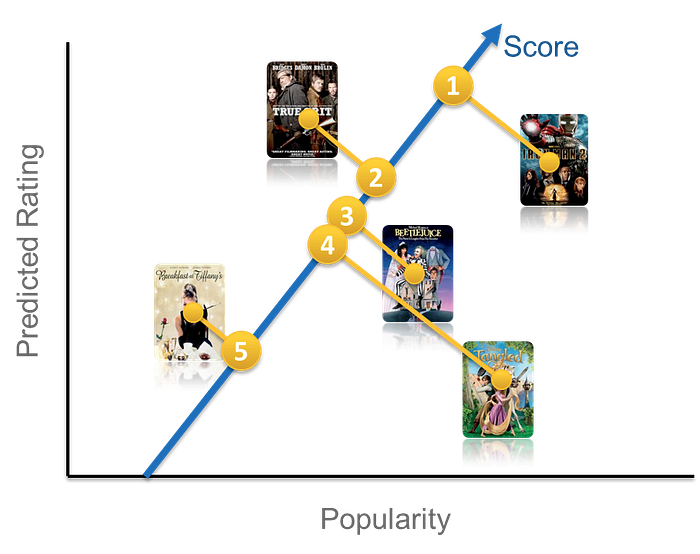
Once we have such a function, we can pass a set of videos through our function and sort them in descending order according to the score. You might be wondering how we can set the weights w1w_1w1 and w2w_2w2 in our model (the bias bbb is constant and thus ends up not affecting the final ordering). In other words, in our simple two-dimensional model, how do we determine whether popularity is more or less important than predicted rating? There are at least two possible approaches to this. You could sample the space of possible weights and let the members decide what makes sense after many A/B tests. This procedure might be time consuming and not very cost effective. Another possible answer involves formulating this as a machine learning problem: select positive and negative examples from your historical data and let a machine learning algorithm learn the weights that optimize your goal. This family of machine learning problems is known as “Learning to rank” and is central to application scenarios such as search engines or ad targeting. Note though that a crucial difference in the case of ranked recommendations is the importance of personalization: we do not expect a global notion of relevance, but rather look for ways of optimizing a personalized model.
有了这样的函数后,我们可以将一组视频输入函数,根据输出分数按降序排序。您可能会好奇,我们如何确定模型中的权重 w1w_1w1 和 w2w_2w2(偏置项 bbb 为常数,不影响最终排序结果)?换句话说,在这个简单的二维模型中,如何判断“热度”与“预测评分”的重要性高低?至少有两种可行方法:一种是对可能的权重组合进行抽样,通过大量 A/B 测试,由会员反馈决定最优权重——但这种方法耗时且成本较高;另一种方法是将其转化为机器学习问题:从历史数据中选取正例和负例,让机器学习算法自主学习能优化目标的权重。
这类机器学习问题被称为“排序学习”(Learning to Rank),是搜索引擎、广告定向等场景的核心技术。但需注意,排序推荐与这些场景的关键区别在于“个性化”的重要性:我们不需要全局统一的“相关性”定义,而是要优化个性化模型。
As you might guess, apart from popularity and rating prediction, we have tried many other features at Netflix. Some have shown no positive effect while others have improved our ranking accuracy tremendously. The graph below shows the ranking improvement we have obtained by adding different features and optimizing the machine learning algorithm.
正如您可能猜到的,除了“热度”和“预测评分”,我们在 Netflix 还尝试了许多其他特征。其中部分特征未产生积极效果,但也有部分特征显著提升了排序准确性。下图展示了通过添加不同特征并优化机器学习算法后,我们在排序效果上取得的提升。
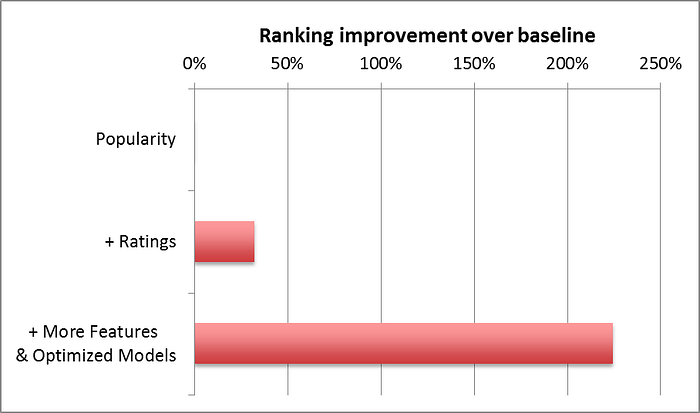
Many supervised classification methods can be used for ranking. Typical choices include Logistic Regression, Support Vector Machines, Neural Networks, or Decision Tree-based methods such as Gradient Boosted Decision Trees (GBDT). On the other hand, a great number of algorithms specifically designed for learning to rank have appeared in recent years such as RankSVM or RankBoost. There is no easy answer to choose which model will perform best in a given ranking problem. The simpler your feature space is, the simpler your model can be. But it is easy to get trapped in a situation where a new feature does not show value because the model cannot learn it. Or, the other way around, to conclude that a more powerful model is not useful simply because you don’t have the feature space that exploits its benefits.
许多有监督分类方法都可用于排序任务,典型选择包括逻辑回归(Logistic Regression)、支持向量机(Support Vector Machines)、神经网络(Neural Networks),以及基于决策树的方法(如梯度提升决策树 GBDT,Gradient Boosted Decision Trees)。此外,近年来还出现了许多专为排序学习设计的算法,如 RankSVM 和 RankBoost。对于特定的排序问题,没有简单的方法能直接确定哪种模型表现最佳:特征空间越简单,所需的模型也越简单;但容易出现“新特征因模型无法学习而无法体现价值”的情况,反之,也可能因缺乏能发挥模型优势的特征空间,而误判“高性能模型无用”。
Data and Models
数据与模型
The previous discussion on the ranking algorithms highlights the importance of both data and models in creating an optimal personalized experience for our members. At Netflix, we are fortunate to have many relevant data sources and smart people who can select optimal algorithms to turn data into product features. Here are some of the data sources we can use to optimize our recommendations:
前文对排序算法的讨论表明,在为会员打造最优个性化体验的过程中,数据和模型都至关重要。在 Netflix,我们有幸拥有众多相关数据源,以及能够选择最优算法将数据转化为产品功能的专业人才。以下是我们用于优化推荐的部分数据源:
-
We have several billion item ratings from members. And we receive millions of new ratings a day.
我们拥有会员提供的数十亿条内容评分数据,且每天还会新增数百万条评分。 -
We already mentioned item popularity as a baseline. But, there are many ways to compute popularity. We can compute it over various time ranges, for instance hourly, daily, or weekly. Or, we can group members by region or other similarity metrics and compute popularity within that group.
我们之前已将内容热度作为基准指标,但热度的计算方法有很多:可按不同时间范围(如每小时、每天、每周)计算,也可按地区或其他相似性指标对会员分组,在组内计算热度。
-
We receive several million stream plays each day, which include context such as duration, time of day and device type.
我们每天会收到数百万条流媒体观看记录,其中包含观看时长、观看时段、设备类型等场景信息。 -
Our members add millions of items to their queues each day.
会员每天会向其队列中添加数百万条内容。 -
Each item in our catalog has rich metadata: actors, director, genre, parental rating, and reviews.
我们内容库中的每一项内容都配有丰富的元数据:演员、导演、类型、家长指导评级、评论等。 -
Presentations: We know what items we have recommended and where we have shown them, and can look at how that decision has affected the member’s actions. We can also observe the member’s interactions with the recommendations: scrolls, mouse-overs, clicks, or the time spent on a given page.
推荐展示数据:我们知晓向会员推荐了哪些内容、在何处展示了这些内容,并能追踪该推荐决策对会员行为的影响;同时还能观察会员与推荐内容的互动,如滚动浏览、鼠标悬停、点击、在特定页面的停留时间等。 -
Social data has become our latest source of personalization features; we can process what connected friends have watched or rated.
社交数据已成为我们最新的个性化特征来源:我们可处理会员关联好友的观看记录和评分数据。 -
Our members directly enter millions of search terms in the Netflix service each day.
会员每天在 Netflix 服务中直接输入数百万个搜索关键词。 -
All the data we have mentioned above comes from internal sources. We can also tap into external data to improve our features. For example, we can add external item data features such as box office performance or critic reviews.
上述所有数据均来自内部来源,我们还可利用外部数据优化特征,例如添加电影票房、专业影评等外部内容数据。 -
Of course, that is not all: there are many other features such as demographics, __polct, language, or temporal data that can be used in our predictive models.
当然,不止于此:还有许多其他特征可用于预测模型,如人口统计数据、地区政策、语言、时间数据等。
So, what about the models? One thing we have found at Netflix is that with the great availability of data, both in quantity and types, a thoughtful approach is required to model selection, training, and testing. We use all sorts of machine learning approaches: From unsupervised methods such as clustering algorithms to a number of supervised classifiers that have shown optimal results in various contexts. This is an incomplete list of methods you should probably know about if you are working in machine learning for personalization:
那么,模型方面的情况如何?我们在 Netflix 发现,面对数量庞大、类型多样的可用数据,模型的选择、训练和测试都需要审慎的方法。我们使用各类机器学习方法:从聚类算法等无监督学习方法,到在不同场景中表现最优的多种有监督分类器。若您从事个性化领域的机器学习工作,以下是您可能需要了解的部分方法(非完整列表):
-
Linear regression
线性回归 -
Logistic regression
逻辑回归 -
Elastic nets
弹性网络 -
Singular Value Decomposition
奇异值分解 -
Restricted Boltzmann Machines
受限玻尔兹曼机 -
Markov Chains
马尔可夫链 -
Latent Dirichlet Allocation
潜在狄利克雷分配 -
Association Rules
关联规则 -
Gradient Boosted Decision Trees
梯度提升决策树 -
Random Forests
随机森林 -
Clustering techniques from the simple k-means to novel graphical approaches such as Affinity Propagation
聚类技术(从简单的 k-均值算法到亲和传播等新型图论方法) -
Matrix factorization
矩阵分解
Consumer Data Science
消费者数据科学
The abundance of source data, measurements and associated experiments allow us to operate a data-driven organization. Netflix has embedded this approach into its culture since the company was founded, and we have come to call it Consumer (Data) Science. Broadly speaking, the main goal of our Consumer Science approach is to innovate for members effectively. The only real failure is the failure to innovate; or as Thomas Watson Sr, founder of IBM, put it: “If you want to increase your success rate, double your failure rate.” We strive for an innovation culture that allows us to evaluate ideas rapidly, inexpensively, and objectively. And, once we test something we want to understand why it failed or succeeded. This lets us focus on the central goal of improving our service for our members.
丰富的源数据、测量数据及相关实验,使我们能够成为数据驱动型组织。自成立以来,Netflix 便将这种方法融入企业文化,并将其命名为“消费者(数据)科学”(Consumer (Data) Science)。从广义上讲,消费者科学方法的核心目标是为会员有效创新。真正的失败只有一种,那就是创新的失败;正如 IBM 创始人托马斯·沃森(Thomas Watson Sr)所言:“若想提高成功率,就将失败率翻倍。”我们致力于打造一种创新文化,能够快速、低成本且客观地评估各类想法。并且,在测试后,我们会深入分析成功或失败的原因,从而始终聚焦于“为会员改进服务”这一核心目标。
So, how does this work in practice? It is a slight variation over the traditional scientific process called A/B testing (or bucket testing):
那么,这在实际中如何运作?它是对传统科学方法的微调,即 A/B 测试(又称桶测试):
1. Start with a hypothesis
提出假设
- Algorithm/feature/design X will increase member engagement with our service and ultimately member retention
算法/特征/设计 X 将提高会员对服务的参与度,并最终提升会员留存率
2. Design a test
设计测试
-
Develop a solution or prototype. Ideal execution can be 2X as effective as a prototype, but not 10X.
开发解决方案或原型(理想的最终实现效果可能是原型的 2 倍,但不会达到 10 倍)。 -
Think about dependent & independent variables, control, significance…
明确因变量与自变量、控制组、统计显著性等要素。
3. Execute the test
执行测试
4. Let data speak for itself
让数据说话
When we execute A/B tests, we track many different metrics. But we ultimately trust member engagement (e.g. hours of play) and retention. Tests usually have thousands of members and anywhere from 2 to 20 cells exploring variations of a base idea. We typically have scores of A/B tests running in parallel. A/B tests let us try radical ideas or test many approaches at the same time, but the key advantage is that they allow our decisions to be data-driven. You can read more about our approach to A/B Testing in this previous tech blog post or in some of the Quora answers by our Chief Product Officer Neil Hunt.
在执行 A/B 测试时,我们会追踪多种指标,但最终以会员参与度(如观看时长)和留存率作为核心判断标准。测试通常覆盖数千名会员,设置 2 至 20 个测试组,以探索同一基础想法的不同变体。我们通常会有数十个 A/B 测试同时进行。A/B 测试不仅让我们能够尝试激进想法或同时验证多种方案,更关键的是,它使我们的决策具备数据支撑。如需了解更多关于我们 A/B 测试方法的信息,可阅读往期技术博客文章《我们如何判断产品成功与否》,或我们的首席产品官尼尔·亨特(Neil Hunt)在 Quora 上关于A/B 测试的部分回答。
How We Determine Product Success
我们如何判断产品成功与否
At Netflix we engage in what we call consumer science.
在 Netflix,我们践行所谓的“消费者科学”。
An interesting follow-up question that we have faced is how to integrate our machine learning approaches into this data-driven A/B test culture at Netflix. We have done this with an offline-online testing process that tries to combine the best of both worlds. The offline testing cycle is a step where we test and optimize our algorithms prior to performing online A/B testing. To measure model performance offline we track multiple metrics used in the machine learning community: from ranking measures such as normalized discounted cumulative gain, mean reciprocal rank, or fraction of concordant pairs, to classification metrics such as accuracy, precision, recall, or F-score. We also use the famous RMSE from the Netflix Prize or other more exotic metrics to track different aspects like diversity. We keep track of how well those metrics correlate to measurable online gains in our A/B tests. However, since the mapping is not perfect, offline performance is used only as an indication to make informed decisions on follow up tests.
我们面临的一个重要后续问题是:如何将机器学习方法融入 Netflix 这种数据驱动的 A/B 测试文化中?我们通过“离线-在线”两阶段测试流程解决了这一问题,力求兼顾两种测试模式的优势。其中,离线测试阶段是在进行在线 A/B 测试前,对算法进行测试和优化的关键步骤。为衡量模型的离线性能,我们会跟踪机器学习领域常用的多种指标:既有排序指标(如归一化折损累积增益、平均 reciprocal 排名、一致性对比例),也有分类指标(如准确率、精确率、召回率、F 值);同时,我们还会使用 Netflix 挑战赛中知名的 RMSE 指标,或其他更“特殊”的指标(如用于追踪多样性的指标)。我们会持续关注这些离线指标与 A/B 测试中可衡量的在线收益之间的相关性,但由于这种相关性并非绝对完美,离线性能仅作为后续测试决策的参考依据,而非唯一标准。

Once offline testing has validated a hypothesis, we are ready to design and launch the A/B test that will prove the new feature valid from a member perspective. If it does, we will be ready to roll out in our continuous pursuit of the better product for our members. The diagram below illustrates the details of this process.
当离线测试验证了假设的可行性后,我们便会设计并启动 A/B 测试,从会员视角验证新功能的有效性。若测试通过,我们将正式推出该功能,持续为会员打造更优质的产品。下图详细展示了这一流程。
An extreme example of this innovation cycle is what we called the Top10 Marathon. This was a focused, 10-week effort to quickly test dozens of algorithmic ideas related to improving our Top10 row. Think of it as a 2-month hackathon with metrics. Different teams and individuals were invited to contribute ideas and code in this effort. We rolled out 6 different ideas as A/B tests each week and kept track of the offline and online metrics. The winning results are already part of our production system.
“Top10 马拉松”(Top10 Marathon)是这一创新周期的典型案例。这是一项为期 10 周的专项工作,旨在快速测试数十个用于改进“Top10”推荐行的算法思路,可将其理解为一场“带数据指标的两个月黑客马拉松”。我们邀请了不同团队和个人贡献想法与代码,每周将 6 个不同的思路以 A/B 测试形式上线,并跟踪其离线与在线指标。最终,测试中表现最优的方案已被纳入我们的生产系统。

Conclusion
结论
The Netflix Prize abstracted the recommendation problem to a proxy question of predicting ratings. But member ratings are only one of the many data sources we have and rating predictions are only part of our solution. Over time we have reformulated the recommendation problem to the question of optimizing the probability a member chooses to watch a title and enjoys it enough to come back to the service. More data availability enables better results. But in order to get those results, we need to have optimized approaches, appropriate metrics and rapid experimentation.
Netflix 挑战赛将推荐问题简化为“评分预测”这一替代问题,但会员评分仅是我们众多数据源之一,评分预测也只是解决方案的一部分。随着时间推移,我们已将推荐问题重新定义为:如何最大化“会员选择观看某内容,且因喜爱该内容而持续使用服务”的概率。更多的可用数据固然能带来更优结果,但要实现这一目标,还需要优化的方法、合适的指标以及快速的实验验证。
To excel at innovating personalization, it is insufficient to be methodical in our research; the space to explore is virtually infinite. At Netflix, we love choosing and watching movies and TV shows. We focus our research by translating this passion into strong intuitions about fruitful directions to pursue; under-utilized data sources, better feature representations, more appropriate models and metrics, and missed opportunities to personalize. We use data mining and other experimental approaches to incrementally inform our intuition, and so prioritize investment of effort. As with any scientific pursuit, there’s always a contribution from Lady Luck, but as the adage goes, luck favors the prepared mind. Finally, above all, we look to our members as the final judges of the quality of our recommendation approach, because this is all ultimately about increasing our members’ enjoyment in their own Netflix experience.
要在个性化创新领域脱颖而出,仅靠系统化的研究是不够的——可供探索的空间几乎是无限的。在 Netflix,我们热爱挑选和观看电影与剧集,并将这份热情转化为对“有价值研究方向”的敏锐直觉,从而聚焦研究重点:未被充分利用的数据源、更优的特征表示、更合适的模型与指标,以及被遗漏的个性化机会。我们通过数据挖掘和其他实验方法,逐步验证并完善这些直觉,进而优先分配资源投入关键方向。正如任何科学探索一样,运气固然会发挥作用,但正如谚语所说:“机会总是留给有准备的人。”最重要的是,我们始终将会员视为推荐系统质量的最终评判者——因为这一切的核心,都是为了提升会员在 Netflix 平台上的观影体验。
Originally published at techblog.netflix.com on June 20, 2012.
via:
-
If You Liked This, Sure to Love That - Winning the Netflix Prize - The New York Times
http://www.nytimes.com/2008/11/23/magazine/23Netflix-t.html -
The $1 Million Netflix Challenge | MIT Technology Review
https://www.technologyreview.com/2006/10/06/273459/the-1-million-netflix-challenge/ -
Netflix Recommendations: Beyond the 5 stars
https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429
https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-2-d9b96aa399f5 -
Netflix viewers think long-running series ‘is losing its magic’ after ‘awful’ last two episodes
https://www.unilad.com/film-and-tv/netflix/netflix-untold-episodes-review-382072-20250527 -
netflix-recommendations | Echo’s blog
https://echohhhhhh.github.io/2020/10/27/Netflix推荐系统/