生物化学Learning Track(9)核酸的结构和功能
(本笔记基于杨荣武教授主编的《生物化学》第四版,配图若无说明也源于教材)
我们在上一节介绍了核苷酸的各组成成分的结构,这里我们将基于我们上一节所介绍的结构,来组装成更高级的结构DNA和RNA。
学过生物的同学都知道,DNA是生命的遗传物质,其一级结构(可以理解为核苷酸序列,后者简单理解为碱基序列)储存着生命的遗传信息,其二级结构和三级结构有助于DNA的复制、转录和修补等生命活动。而相对于DNA,RNA的结构常常以单链形式存在,这种存在形式也给予了RNA以极大的空间自由性,书上其实反复强调一点“RNA的三级结构的复杂性不亚于蛋白质”,其实这也可以解释为什么在生命早期认为RNA承担了蛋白质的功能了。
那么我们开始进入本节的学习,首先我们学习核酸的基本结构和分类
核酸的基本结构和分类
DNA和RNA的主要区别在最基本的结构上主要体现在戊糖和碱基组成上。
对于DNA的戊糖即脱氧核糖,在2'的C脱去了羟基连接一个氢原子,但是对于RNA的戊糖即核糖,在2'位的C仍然保留了羟基,所以也正因为此RNA很难形成B型的双螺旋结构(注意这里我说的事B型螺旋不易形成,其实是有利于形成A型螺旋的)
同时碱基的组成也是有差别的,这里我们在高中也已经强调了很多遍了,但是我们这里需要强调一点,其实这个并不意味在细胞DNA当中就不存在尿嘧啶了,只是说含量很低,细胞将其作为异常碱基处理并且进行剪切(但是有些细胞不进行处理,后面会提到原因)。
但是这里我们需要想这样一个问题,为什么DNA不用尿嘧啶,RNA不使用胸腺嘧啶?
这里我们需要首先明确进化的顺序将这个问题简化,DNA出现是晚于RNA的,那么其实我们可以这么发问,为什么DNA要将U改为T?其实是因为一个C会自发脱氨基反应,这样会使得C会自动转变为U,所以我们想,如果细胞DNA仍然使用U,那么如果我们不考虑配对时,细胞如何区分是C变为的U还是本身就作为遗传物质的U呢?哪怕是考虑到配对原子的,遗传物质发生复制错误的可能性会大大增加。所以细胞会选择用T作为使用的碱基,这样但凡DNA上出现了U就说明这是异常情况,而不需要像前者一般需要判断。那么实际上,细胞当中参入U主要有两种原因,一方面就是之前所述的C自发脱氨基变为U,还有一种是细胞中存在少量的dUTP可以被DNA聚合酶使用,那么其实这里对修复出现一个小小的问题,我该怎么修复呢,是修复到T还是C呢?这里修复的酶会根据这个碱基所在的序列进行判断,同时也可以用配对的碱基辅助配对(比如在GC富集的序列出现U,那么很有可能就会将其修复为C)(切除U 的是尿嘧啶-DNA糖苷酶)
那么我们再考虑这样一个问题,为什么RNA也不直接使用T呢,既然C有这么大的缺陷?这里是由RNA和DNA的功能定位决定的。由于DNA是遗传物质,要求其的序列结构应当是高度保守的,但是对于RNA,由于它一般作为功能分子,所以一般存在的时间较短即会被降解,所以C发生脱氨基的可能性大大降低,那么即使发生了,对于mRNA由于具有较高容错性,所以不会产生很严重的后果,那么即使产生严重后果或者发生在存在时间较长的RNA上,细胞当中也会有相应的蛋白和酶可以降解(如泛素和蛋白酶体)。其实我认为还有一个原因,RNA对于碱基替换的容错性是高于DNA的,除了mRNA,其实对于其他有比较复杂结构的RNA来说,就像蛋白质的二级结构,对于参与形成α螺旋和β折叠的残基其实如果疏水性差别不大,对蛋白质的结构可能没有影响。这对RNA的高级结构也是一样的,很多碱基参与的是“茎”的形成,这些碱基是没有很高的保守度的,因为体现活性的更多是环状和壁等结构。
(RNA也会存在部分的T,这里的T可能可能是U发生甲基化产生的,也有可能是甲基化的C自发脱氨基反应产生,但是前一种是有生物功能的,在后面的高级结构有应用,但是后一种是错误,是需要修复(细胞中存在RNA修复机制)或者降解的)
但是部分生命会“故意掺入”U在DNA中,也就是提高dUTP含量(在正常细胞当中dUTP一般是会被相关酶降解的以防止参入DNA中)或者是抑制编码尿嘧啶-DNA糖苷酶(UDG)活性。比如对于部分噬菌体,其本身DNA就是用U代替了T,同时它会抑制宿主细胞当中降解dUTP酶的活性和UDG活性,那么就会使得复制出来的DNA可以参入大量的U,会逃过细菌或古菌的限制性内切酶的剪切(内切指的是酶的结合位点在DNA序列中间而非“外切”从5'或者3'一个一个切下核苷酸,限制性主要指的是此酶的主要作用就是对抗噬菌体侵入),从而有利于病毒遗传物质的复制。
同时对于有些完全变态的昆虫而言,对于幼体阶段在成虫不需要的细胞当中,会沉默编码UDG的基因,从而使得在这些细胞当中的DNA中存在较多的U,所以这会作为一个特点使得该细胞凋亡。
其中对于我们高等动物而言,可以利用修复U这一机制,对B细胞前体的编码抗体基因进行突变处理(超突变)(激活细胞中胞嘧啶脱氢酶,催化C更快地转变为U,那么B细胞的修复系统就可能会将新的片段带入该基因(修复机制并没有那么精确)),从而形成抗体的多样性。
(回到核糖保留了2'的羟基)
由于核糖保留了2'的羟基,所以在碱性条件下可以作为亲核试剂攻击磷酸基团当中的磷原子,所以会发生脱碱基反应,但是DNA在碱性条件下耐受程度会更强。但是换一个角度想,RNA本身就不作为遗传物质,所以容易水解可以使得这种功能分子在需要的时候就可以被合成,但是在不需要的时候就可以被迅速降解。另外,RNA也可以作为核酶,那么此时处于2'位的羟基就可以作为活性中心起到催化作用。但是,对于需要保持一定的稳定性的RNA,比如tRNA和rRNA,这时候RNA的2'的羟基一般会被甲基化修饰。
同时也正好是因为戊糖的2'端的羟基通过稳定 C3'-endo 构象,直接推动螺旋参数向 A 型靠拢,同时如果形成B型螺旋,会因为羟基的空间位阻效应使得B型构象能量很高。
下面对RNA进行简单分类(因为DNA只有一个功能——遗传物质),我们把编码蛋白质的RNA称作coding RNA(主要是mRNA和tmRNA(可以行使mRNA和tRNA的功能)),对于不编码蛋白质的RNA称之为non-coding RNA(ncRNA),进一步我们可以把ncRNA进一步分类为housekeeping RNA(管家RNA),在某种生物体所有细胞当中都表达的,是细胞生命活动所必须的,和调控RNA,其的表达需要受到外部刺激或者生物体到达一定发育阶段才会激活。
(这里对RNA的定义和DNA是类似的,但是注意这里的house-keeping是针对某一生物体的,不是所有生命都表达的才叫house-keeping)
核酸的一级结构
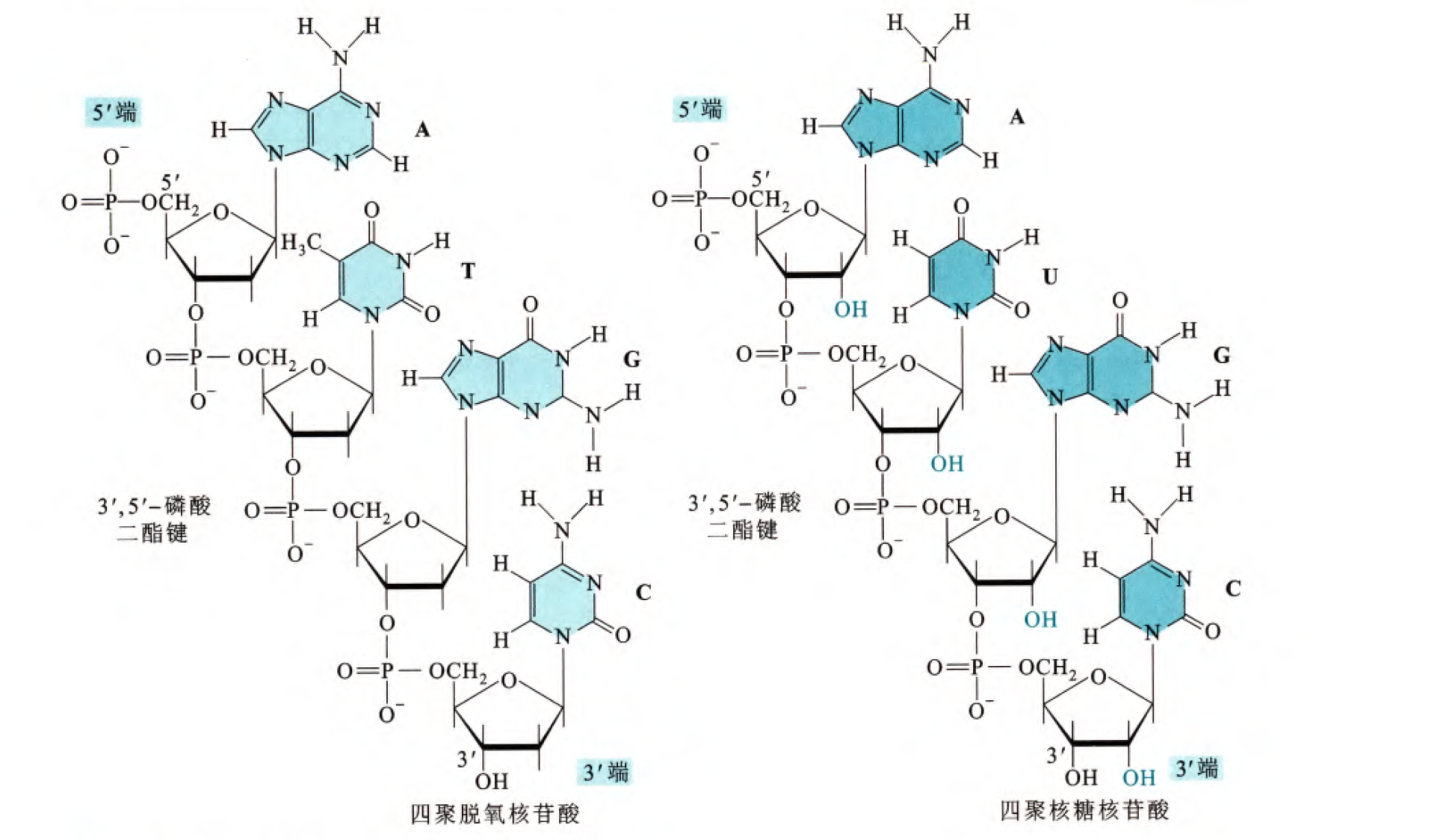
不论是核酸还是脱氧核酸都是通过磷酸二酯键连接的,连接在5'端的磷氧键是5'磷酸二酯键,同理连接在3'端的磷氧键是3'磷酸二酯键,那么其实理论上磷酸也可以和核糖的2'端形成磷酸二酯键,但是在自然界当中这种情况很少存在。
另外,我们注意到在此图上部有一个未结合的磷酸的羟基(这里电离了),此末端称之为5'端;在此图下部有一个未结合的3'的羟基,我们称之为3'端,那么对于没有环化(5'端和3'端相连)的核酸(脱氧核酸),我们称这种不对称性为极性(很多时候极性已经不是我们说的负电中心和正电中心没有重合的定义了,而是根据不同问题有其他的定义,在这种生物大分子中有些时候指的就是这种单体连接方向,又比如在β角蛋白折叠当中,β片层当中β股的残基的指向方向是否一致又称为极性和反极性)
同时在生理条件下,磷酸基团一般处于电离状态,那么如果不考虑5'端存在两个负电荷,其实对于每一个核苷酸都带有一个负电荷,那么其实核酸(脱氧核酸)的基本骨架是带有负电的,这是一个非常非常重要的特点,对于DNA双螺旋的结构形成和变化,核酸和蛋白质的结合有很大的作用。
核酸的二级结构
1. DNA的二级结构
DNA的二级结构主要是各种各样的双螺旋结构,我们首先介绍最最著名的B型双螺旋结构,也就是Watson和Crick提出的DNA结构,其次我们讲在细胞中存在A型双螺旋和D型双螺旋结构
B型双螺旋
这是小编自己设置的一段序列的B型DNA三维结构示意
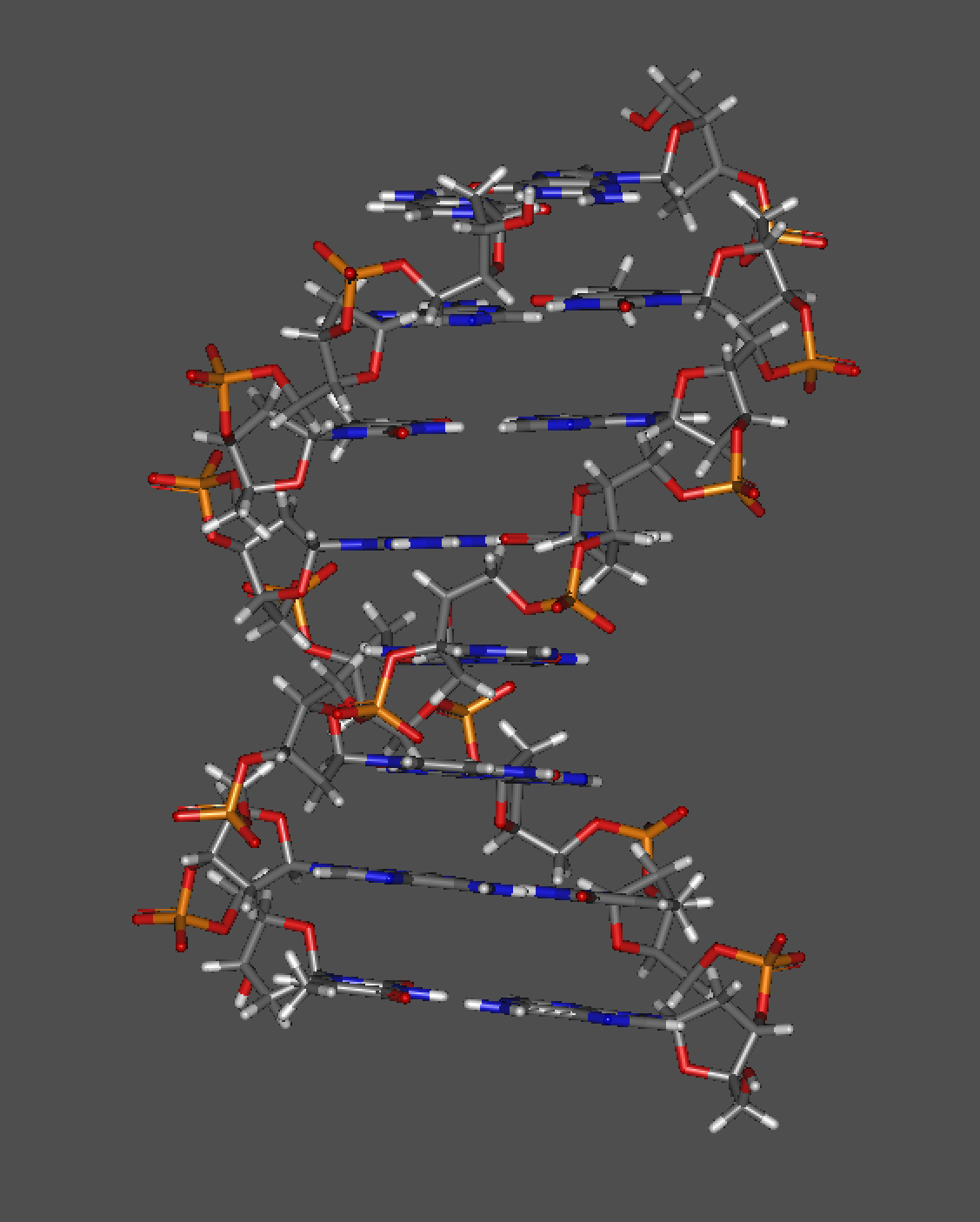
我们先从这张图片中提取信息:
首先碱基平面是接近平行的,对于不同碱基会存在略微的倾角(对于AT接近-7°,对于GC接近-3°,这里的负号表示接近小沟),但是整体上还是垂直于旋转轴的。
其次我们看一个特殊同时重要的特点,大沟和小沟的存在,实际上这是因为虽然碱基平面是平行的,但是对于每个碱基对而言,彼此中轴线会存在一定的角度,也可以理解为pair的糖苷键的角度,这个角度为120°,所以导致在螺旋上升的时候会存在一个间隙较大的沟(大沟),一个间隙较小的沟(小沟)。那么假设碱基正好是正对着的,那么就会形成一个圆柱而且两边的间隙应当是相同的。
那么再来继续谈一下参数,螺旋的直径是20A(AT对会略大一点20.5A),每个碱基对螺旋36度上升0.33nm,所以一个螺距就是3.3nm(实际3.32nm),接近10个碱基对(实际10.4-10.6个),大沟间隙为2.2nm,小沟间隙为1.2nm。
那么其实我在了解完这些参数之后会想这样一个问题,为什么形成右手双螺旋,为什么恰好是B型?但是这个问题比较复杂,可能需要涉及数学物理知识(小编也不会),但是可以简单说一下,一方面对于这种一般的一级结构而言,各个碱基都是采取反式构型的,所以碱基都是朝向内部的,另外,我们不能被一些示意图迷惑,总有这样一种感觉,是先两条链对齐形成直链然后这个直链再螺旋盘绕,这个根本上违背了键角和其他空间参数的要求。实际选择右手螺旋和糖环的内型(3'-endo还是2'-endo有关)以及糖苷键的顺式还是反式有关,我们在后面会介绍到A型螺旋和Z型螺旋,这些螺旋的结构改变和外部条件以及本身序列特点都有很密切的关系,在这里我们不深究其中的拓扑结构和形成机理。但是我们可以从最基本的理化性质和生物功能分析,这也是后面我们对比各种螺旋的思路。
(这涉及到比较深层次的空间几何,偏离了我们讲述的主线,所以略过(其实也是因为我不会哈哈))
我们从生物功能的角度分析,为什么DNA大部分或者说绝大部分都是以B型存在的。一方面,碱基是疏水的,虽然碱基上存在氢键的受体和供体基团,但是更重要的是存在很大的疏水芳香环,这直接导致碱基暴露在水环境当中是处于高能态的。另外糖环的是较为亲水的,磷酸基团就是非常亲水的,所以一个核苷酸的结构的亲水性是逐渐递增的。那么由此采用双螺旋的结构,可以使得碱基以最大程度远离水,同时也可以实现碱基之间的疏水作用的堆叠,从而在很大程度上稳固了双螺旋的结构。另一方面,B型结构的存在提供恰好的大沟和小沟,有助于在不需要解螺旋的情况下就可以知道碱基结构,有助于DNA的转录同时也有助于DNA的修饰。
紧接着上面内容,我们聊一聊为什么大沟可以揭示碱基序列(这里强烈建议大家也调出DNA螺旋结构来查看),本质上其实也就是不同的pair(AT,TA,CG,GC)在大沟表现出来的性质特异,所以蛋白质才可以加以区分。那么这里的性质可以分为氢键供体(D),氢键受体(A),氢原子的疏水作用(H),和甲基的疏水作用(M),当然甲基的疏水作用仅仅局限在有T参与的。
我们统一是以5'-3'链的横切方向定义序列,在大沟中观察上述四种作用
CG:HDAA
GC:AADH
AT:ADAM
TA:MADA
所以完全可以通过从大沟中读取的信息就直接判断这是什么碱基对,从而识别碱基序列
但是我们看从小沟当中是否可以读取到同样信息呢?
GC:ADA
CG:ADA
TA:AHA
AT:AHA
虽然我们可以从小沟当中读出GC/CG 与 AT/TA 的差别,但是我们无法分清彼此,所以小沟在大部分时候不作为序列读取的方式。另一方面,大沟的空间结构也更有利于蛋白质的结合。
A型双螺旋
A型双螺旋主要存在于相对湿度较低的地方(低于75%),那么A型双螺旋的参数如下:
碱基之间彼此垂直距离是0.23nm,每一个螺旋接近11bp,螺距2.46nm,直径2.6nm,每个碱基偏离水平面(以轴作为竖直线)约19°,大沟窄而深,小沟宽而浅。
那么实际上细胞是处于一个水环境,所以很难使得细胞的相对湿度降到那么低,但是对于一些芽孢(在恶劣环境下产生)可以极大降低水含量,从而将B螺旋变为A螺旋,同时对于与DNA聚合酶结合的3bp的碱基范围也是以A型双螺旋呈现的(因为DNA聚合酶活性中心是疏水氨基酸,水含量会有所降低,同时其内部的结构如正电金属离子也有助于A型螺旋的产生)
对于芽孢将B转为A型螺旋的原因是,A型螺旋由于碱基之间的距离缩短,所以碱基之间的堆积力更强,所以结构更加稳定不易水解或者解旋,同时由于大沟间隙缩短,所以使得A型螺旋的碱基不易受到紫外线和氧化剂等有害物质接触,所以碱基序列更加稳定保守。同时A型螺旋紧凑的结构不仅使得稳定性提升,同时也使得DNA聚合酶等不易结合(对于第二个例子是DNA聚合酶先结合B型双螺旋在催化过程中将B型转为A型所以并不冲突),这正好符合细胞对低能耗的需求。那么等到细胞需要重新恢复功能的时候,仅仅需要吸水就可以使得DNA结构恢复为活性更大的B型。
对于第二个例子,更多是由于酶的空间结构和疏水性质的要求导致B型向A型的转变,同时也因为碱基堆叠更加紧密,所以在修复或者复制过程当中,DNA结构会更加稳定。
其实我们仔细看这样一个转变,其实发现非常的精妙,仅仅利用水的含量就可以较大程度改变DNA结构以适应一定生命功能,那么同时当需要恢复原状的时候,再调节水含量上升或者疏水基团远离即可。
Z型双螺旋
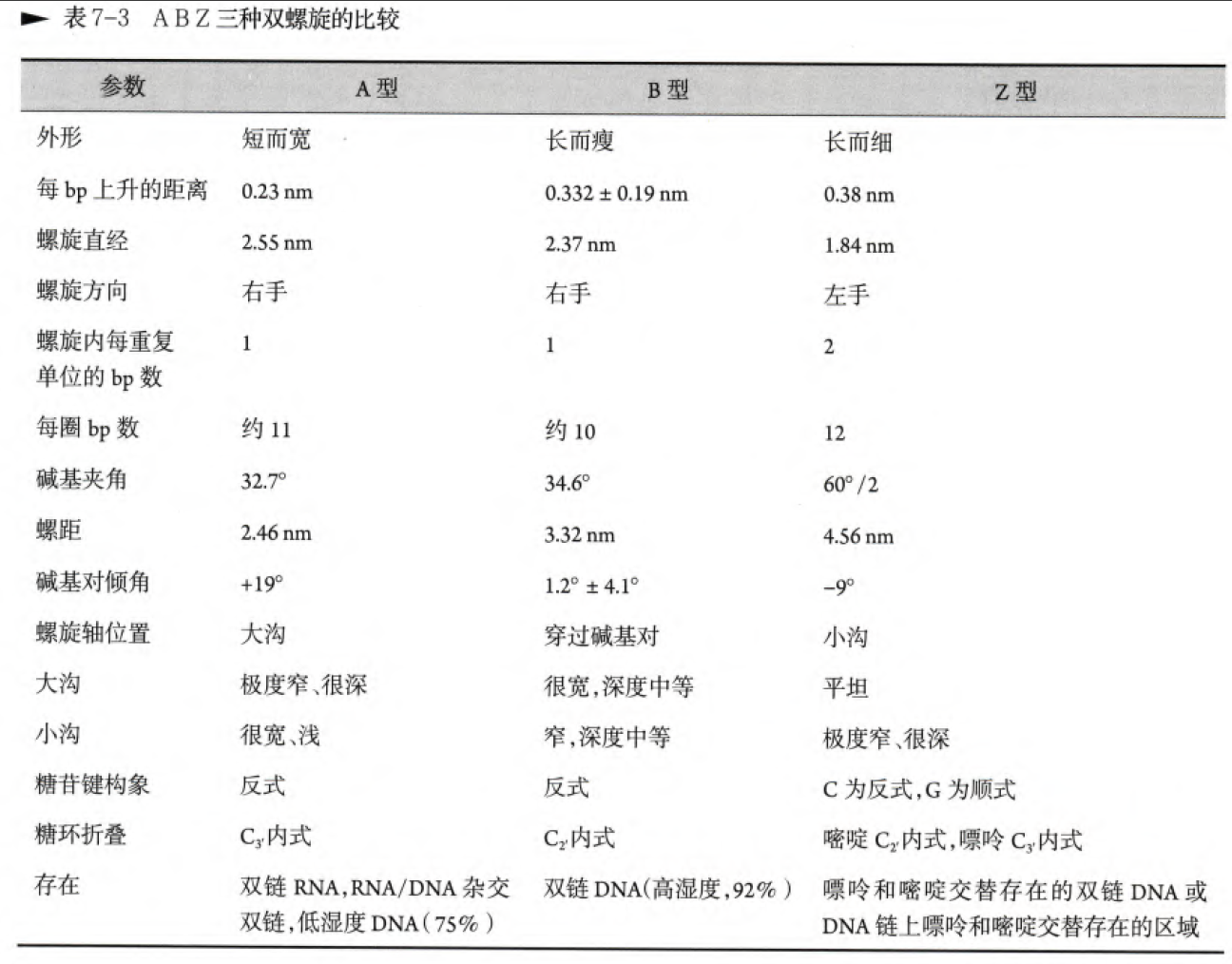
Z型双螺旋相较于前两种螺旋,其的结构差异非常明显:
1. C仍然采取反式构象,但是G采取顺式构象
2. 不同于A型C3'内式和B型C2'内式,Z型嘧啶采取C2'内式,嘌呤采取C3'内式
3. 碱基移向分子外表面,中轴移向小沟
4. 以左手螺旋形式而非右手螺旋
这是书上整理的表格
由于Z型双螺旋磷酸链靠的更近,磷酸链在高盐浓度下磷酸基团之间的作用力可以被正电离子稀释,同时如果嘧啶有甲基修饰认为是有助于Z型形成的(因为在B型中如果有甲基修饰(可以以T为例),甲基实际上是露在大沟的,也就是亲水环境中,但是Z型会将甲基向内即螺旋内部转移,所以稳定性会有所提高,同时也有利于形成“疏水补丁”)
至于为什么在这些条件下就可以发生这样的构象差异我们不深究,我们重点关注这样的转变在哪里发生,又有什么生物学意义:
那么虽然Z螺旋的形成条件较为严苛(高盐浓度,嘌呤和嘧啶相间排列),但是在细胞生理条件下在某些蛋白质和基团的辅助下仍然可以形成。比如在精胺和亚精胺带有正电可以中和磷酸基团负电作用,有助于Z型形成,同时对于有些蛋白质其活性中心带有正电,同时可以创造出局部的高盐环境,有助于Z型形成。另外,负超螺旋的形成有助于Z型螺旋形成。
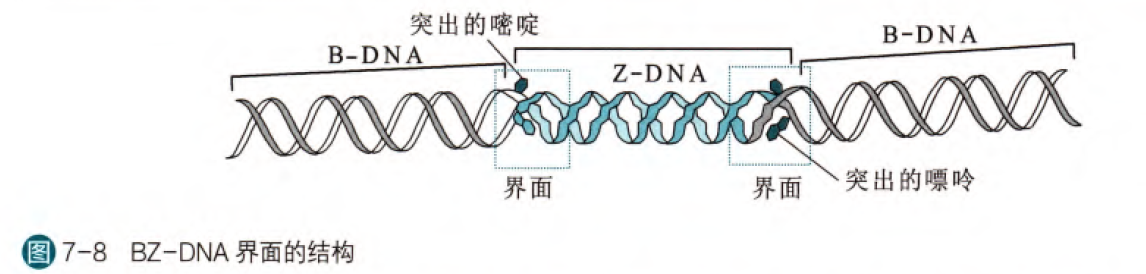
那么从B型向Z型的转变过程由于螺旋方向的变化,会出现碱基的突出。那么在细胞当中,Z型螺旋的存在可能起着调控基因表达的作用,研究发现有利于Z螺旋的序列常常出现在基因的启动子序列,同时有些蛋白可以与Z螺旋结合改变基因的表达。我们熟知的甲基化修饰的作用机理也有可能和Z螺旋的形成有关,既然甲基化有利于Z螺旋形成同时又发挥着基因表达调控的作用
那么这里我们对三种基本的螺旋结构介绍至此,这也是DNA常见的二级结构但是从中我们可以看到,DNA对于外部条件的改变也是有灵敏的反应的,那么也许不同于我们之前所想的,基因表达仅仅是转录因子等蛋白的作用调控的,可能DNA结构的转变在DNA转录表达上也发挥着非常非常重要的作用,只是我们还没有理解清楚。
维持螺旋结构的作用
1. 氢键:之所以把氢键放在第一个不是因为氢键是最主要的作用力,而是氢键是决定结合特异性的重要作用(甚至可以说是不是最主要的作用,可能决定碱基特异性配对的更重要的作用是空间结构的互补,书上有一个例子,如果用一种结构类似于T但是不能形成氢键的分子仍然可以和A配对)
另外,碱基的旋转也是非常重要的层面,如果氢键接近排布在一条直线上,那么只要剪切力的方向使用,DNA的结构很容易就可以被破坏,但是碱基旋转(B螺旋每一个碱基旋转36°使得氢键的作用力分布在各个方向上,这也使得双螺旋的结构更加稳定)
2. 碱基的堆积作用:这个其实在前面已经有过铺垫了,我们讲A型螺旋为什么稳定,没有讲氢键但是反复提及的是碱基堆叠更加紧密,这是因为碱基的堆叠作用是维持螺旋结构的主要作用力。
由于碱基是疏水大基团,那么碱基之间的堆叠就类似于蛋白质内部的疏水核心一般,以范德华力和疏水作用来维持结构的稳定。碱基的堆积作用与上下碱基平面重叠的面积成正比,所以嘌呤-嘌呤>嘌呤-嘧啶>嘧啶-嘧啶,同时甲基的引入也有利于增大堆积作用
3. 离子键:这需要回顾我们在之前提到的一点,DNA的骨架是带有负电的,所以负电骨架之间会存在相互排斥的作用,那么这一个作用会使得DNA的结构趋向不稳定,实际上细胞当中会存在一定浓度的正电离子如镁离子来中和负电基团形成离子键,维持DNA结构稳定。
(这里突然有一些感慨,其实生物体的分子机制也存在一些“缺陷”,比如为什么要选择会自发脱氨基的C,为什么要用带负电的磷酸基团构建基本骨架,然后围绕这些缺陷又会有一定的修复机制,但是换一个角度看,这些缺陷又在很多方面体现了优越性,比如自发脱氨基这一特点可以促使抗体多样性,是细胞自主调节基因突变的手段;正是因为磷酸骨架带有负电,才可以和核小体结合实现聚合和解聚的灵活调动,一切一切似乎都处于一种非常精巧的平衡当中,当你怀疑生命的创造的时候,它会用另外一种方式向你证明正确性,magically~)
DNA的非标准二级结构
1. 弯曲:
弯曲可以有很多种情况,一种是序列特点导致的,如果在一段DNA当中存在连续的A(4-6bp),同时每间隔10bp就又出现这样一个连续序列,那么此时DNA会发生一定程度的完全。这里其实10bp的作用恰好是一个螺旋,所以A的作用可以叠加,同时4-6个碱基又保持了A存在在螺旋一半边,形成一个非对称分布。那么又由于A-T碱基对本身强度会低于GC,同时就存在较大的碱基平面偏角(-7°)所以在这一段序列当中就可以形成弯曲的结构。
当然除了本身的序列特点导致的弯曲结构,还有可能是因为蛋白质的作用或者是碱基错配等方式导致的。
这样的弯曲结构可能有助于蛋白质对DNA的结合,有助于异常序列的识别或者是有利于压缩DNA。
2. 十字形
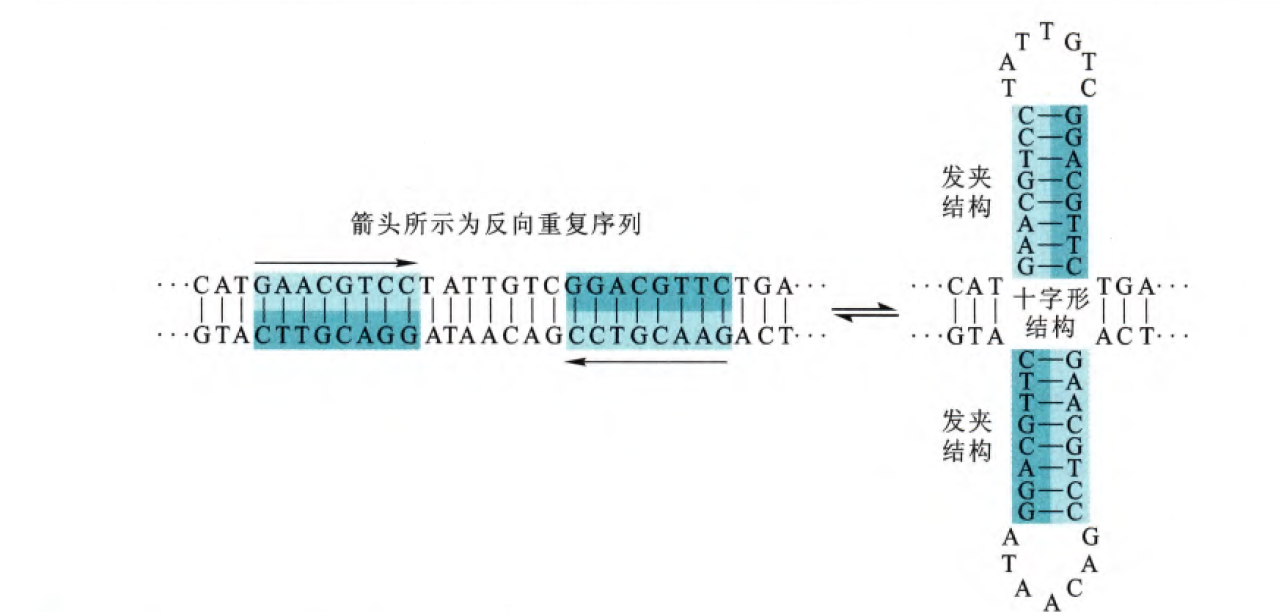
此二级结构的特点是存在反向重复序列,这样就可以在各自链形成互补配对,其中有一段序列无法配对形成环状。但是这种结构并不稳定(从环状结构可以看出)
细胞中出现这种序列一般是在DNA的复制起始区或者是转录调控区,这种十字形的形成或许与DNA的转录和复制有关。
3. 碱基翻转:
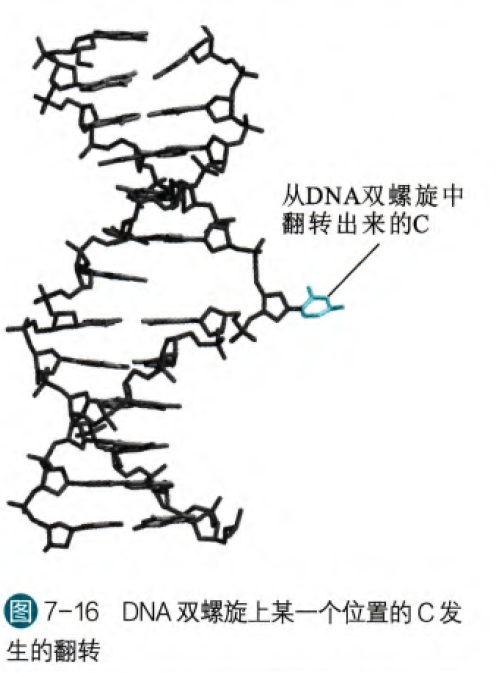
有些时候某一个碱基会打破配对,从双螺旋结构翻转出来,此翻转也会影响到周围序列的结构。事实上,在特定情况这种结构是必要的,比如在对碱基进行修饰的时候或者剪除的时候,需要碱基翻转才可以落入酶的活性中心。
4. 滑移错配(见图就懂~)
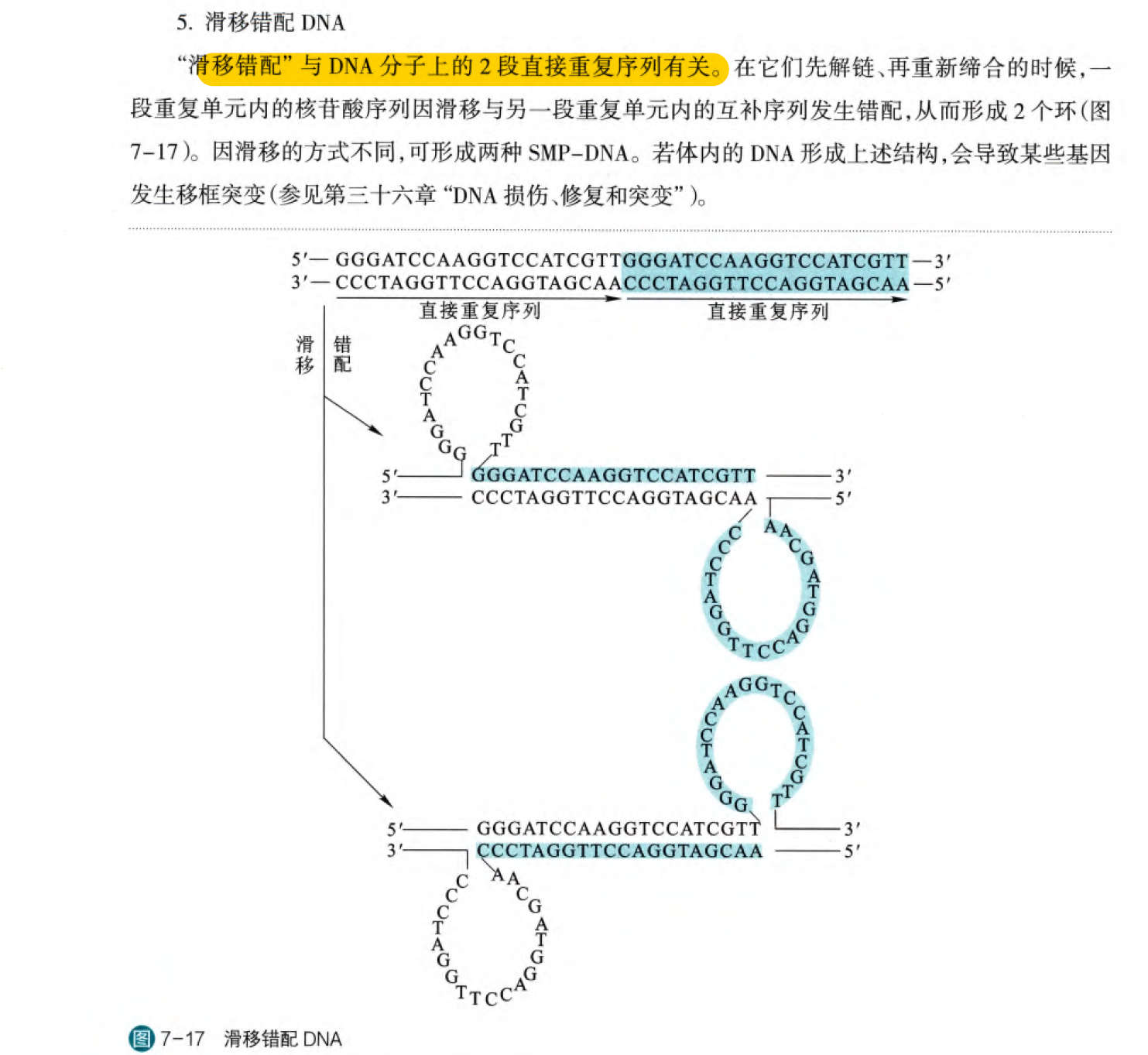
(注意下这是直接重复序列介导的,有两种可能的形式)
5. 三螺旋
(书上本来是放在第三个的,但是这个有点复杂所以放在这里再讲)
回顾一下,我们对大沟的介绍,在大沟当中会露出一定的结构特征,其本质也就是基团,可以和蛋白质结合从而发挥识别作用。那么这里其实是更进一步,我们去着重观察嘌呤,会发现除了在与嘧啶结合的氢键受体供体之外,还存在着其他的氢键供体和受体,那么这一部分就可以成为潜在的氢键结合位点。事实上三螺旋结构也正是基于这样的特点形成的。
除了我们之前一直介绍的Watson-Crick配对,其实还有一种配对方式是Hogsteen配对,这种配对要求DNA的一条链全部都是嘌呤或者绝大部分都是嘌呤,那么这条链就会在咪唑以及嘧啶环上仍有连续的氢键受体和供体,借助这个特点,另一条DNA单链就可以卡在大沟位点与这一条嘌呤链形成氢键作用,具体是平行于这条链还是反平行具体要看序列特点。三螺旋结构的形成由于占据了大沟的位置,所以可以调控DNA的复制、转录以及蛋白质结合等过程。
同时需要注意的是,既然这不是标准结构的螺旋,所以对于Hogsteen碱基对之间的距离可以存在差异,因此允许GG配对和AA配对。
(其实我认为这里我们需要理解的就是Hogsteen配对是如何形成的,还有形成这种二级结构的序列特点是什么,至于空间结构如何可以暂不深究)
除了单独的第三条DNA单链形成三螺旋,分子内也可以形成三螺旋,这个对序列的要求是存在镜像重复序列,这样相当于对于某一段区域,一条链与另一条链的两段序列同时形成配对,那么这就会使得两条链都存在多余的无法配对的碱基,所以结构并不是很稳定。
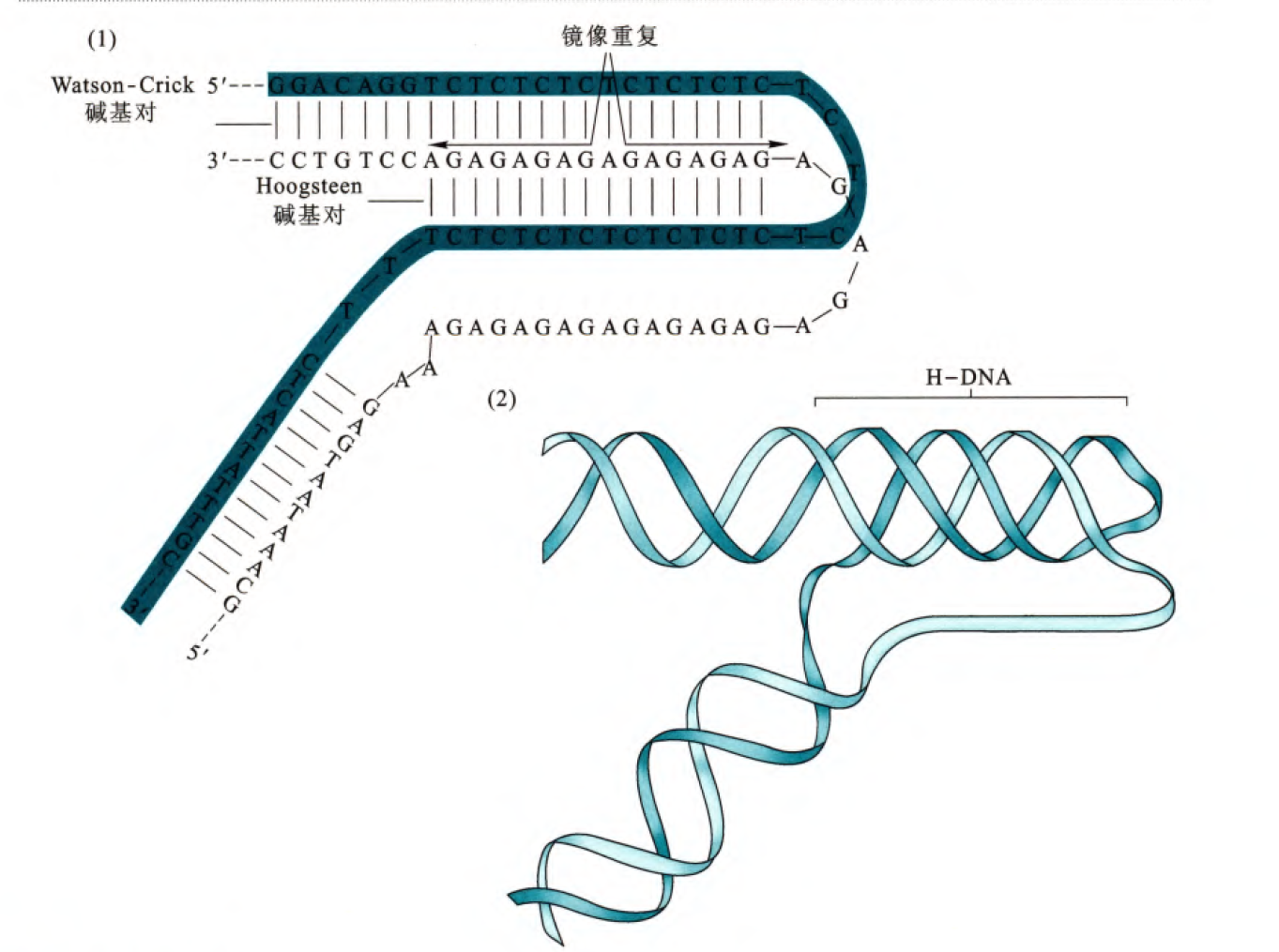
除了无法配对的碱基,三螺旋(分子内或者分子间)都会因为磷酸骨架的靠近而不稳定,那么如果在较高盐浓度的作用下有利于稳固三螺旋的结构。
书上也提到了三螺旋对于基因表达可能存在的调控机制(不知道发现没有,都是以特定的序列来推测的可能形成如此结构,再对于这一段序列的作用,进一步推测这个结构和功能的对应关系),同时也说如果我们可以合成一段DNA单链与DNA目标双链结合,也许可以抑制表达。但是这需要建立在DNA目标区段满足先前我们介绍的序列特点的基础上,但是既然这个序列特点存在于基因转录重组调控序列,这一种调控手段也许可以发挥作用。
6. 四联体:
这种四连体也是基于Hogsteen配对和Watson-Crick配对共同构建的,其能够形成需要基于一定的碱基序列如GT重复序列,此序列在端粒中存在,所以端粒DNA可能以四联体形式存在,同时存在可以与四联体结合的蛋白,可以辅助端粒结构的稳定(至于结构细节不再多提)
RNA的二级结构
在生物体内的大多数RNA是单链,双链RNA或者是单链RNA内部配对碱基形成部分双链,这些双链都是以A型螺旋存在的,包括DNA和RNA复合体也是以A型螺旋存在的。之所以RNA无法形成B型结构,是因为核糖2'的羟基的空间位阻的影响。
指导RNA折叠的方式遵循这样一个基本原则:RNA的折叠仍然是由其以及结构决定的,那么首先应该是让链内部可以形成配对的配对,然后无法配对的碱基形成环、弯曲或者其他的二级结构
那么在RNA当中,GU也可以形成配对,只是只能形成2个氢键,稳定性没有GC强,但是这一种配对方式提供了更多的灵活性,有助于二级结构的灵活组配
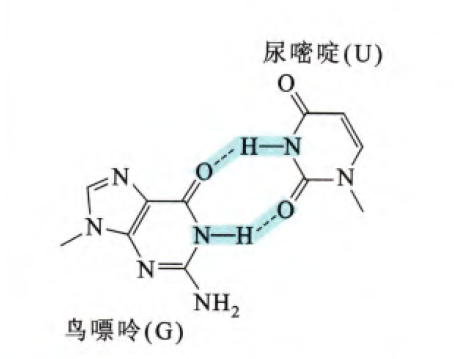
RNA双螺旋也存在Z型构象,同样与Z型DNA一致,嘌呤-嘧啶的重复序列容易形成Z型螺旋,其中GC重复序列最容易形成。细胞当中存在一个编辑MRNA的酶,作用于RNA的腺苷脱氢酶1,其Zα结构域可以特异性高效识别Z型RNA螺旋结构,特别的是,这种酶针对的是结构而不是某特定的序列。已知Z型RNA构象对I型干扰素反应的负调节至关重要。
另外RNA的一级结构决定了其的二级结构,所以可以利用一级结构对而二级结构进行一个推测。
书上还提到最常见的一种RNA的二级结构就是发卡结构,其实就是一段碱基,在两端可以配对,中间存在部分碱基(一般4个最为稳定)无法配对,形成一个环状。RNA的发卡结构是否可以维持稳定主要取决于环状结构是否可以稳定,那么书上也提到了几种常见的稳定的四碱基序列:UNCG、GNRA或者CUYC(N表示任何碱基,R表示嘌呤,Y表示嘧啶)
tRNA的二级结构
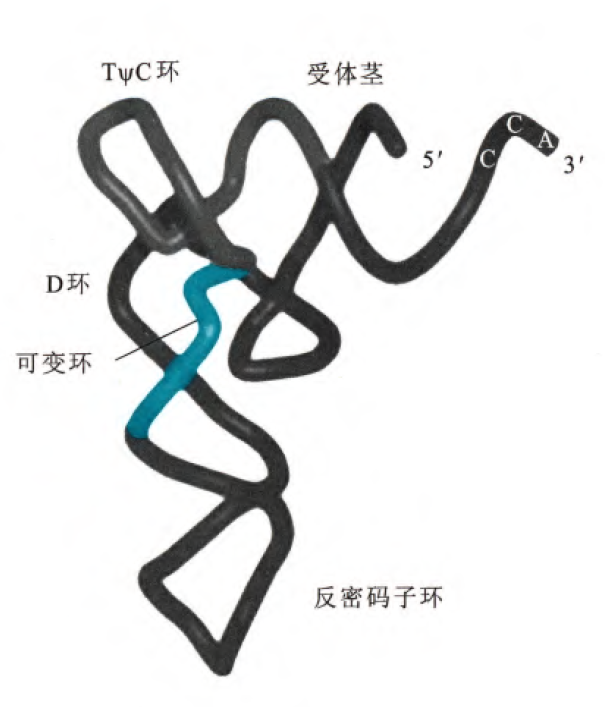
之前提到过,对于tRNA和rRNA需要稳定存在的RNA,其2'的羟基一般是发生了甲基化修饰的。tRNA内大多数的碱基通过氢键配对,但是有一个很重要的点是几乎所有tRNA上保守序列到时再非配对的单链区,所以这里可以初步判定,其实茎部分更多的作为稳固tRNA结构的部分,类似于稳固结构的蛋白质的二级结构,这一步对碱基特异性要求不高。
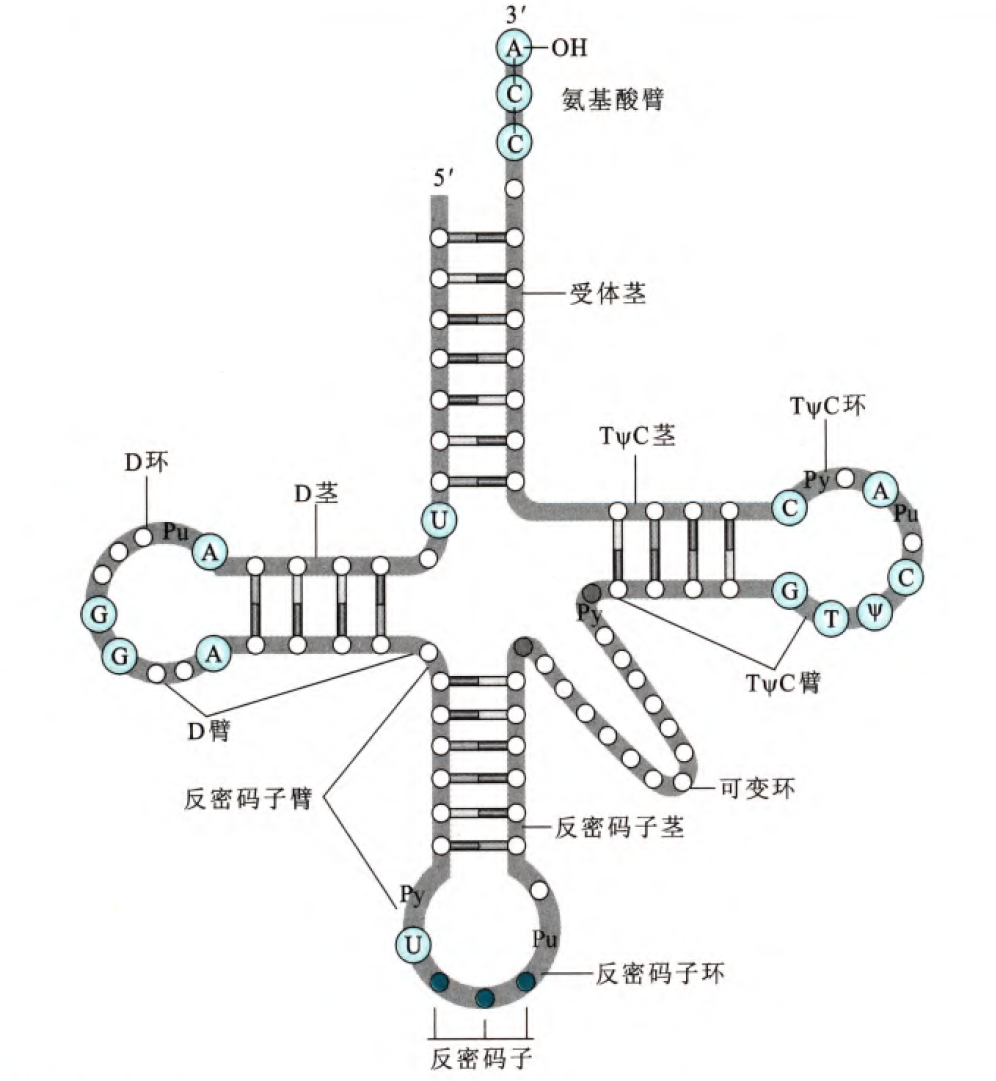
tRNA分子的结构要素有环、茎和臂,茎就是配对碱基部分,环就是没有配对突出的部分,臂就是紧接着茎但是没有配对也没有突出的部分,所有的tRNA在3'端最后三个核苷酸总是CCA,这三个核苷酸和第四个核苷酸一起没有配对,但是构成了接受氨基酸的臂,氨基酸通过3'末端的羟基与tRNA结合。反密码子环的碱基是识别mRNA密码子的重要碱基序列,即称为反密码子。紧靠反密码子的5'端总是U,紧靠反密码子的3'端总是嘌呤核苷酸。可变环对于不同种类的tRNA分子长度会有变化,因此可以用词结构区分不同的tRNA。TψC环有7个碱基(最开始的CG是臂),包括特征TψC序列(ψ是假尿苷(不形成糖苷键而是形成CC单键)),rRNA和tRNA的结合依赖于对TψC环的识别。
rRNA的二级结构
根据沉降系数(沉降系数越大,那么RNA分子量越大,但是这两量仅仅呈现正相关,不是正比关系)可以将rRNA分为多种,在原核细胞当中有5S rRNA、16S rRNA、23S rRNA,在真核细胞当中有5S rRNA、5.85S rRNA、18S rRNA和28S rRNA。在所有rRNA分子上都发现了大量支持链内互补的序列,所以rRNA是高度折叠的。同时,rRNA在不同物种中呈现出高度的保守的二级结构,一级结构可能有较大差别,但是二级结构往往十分类似,这说明rRNA的进化选择作用在二级结构而不是特定序列。
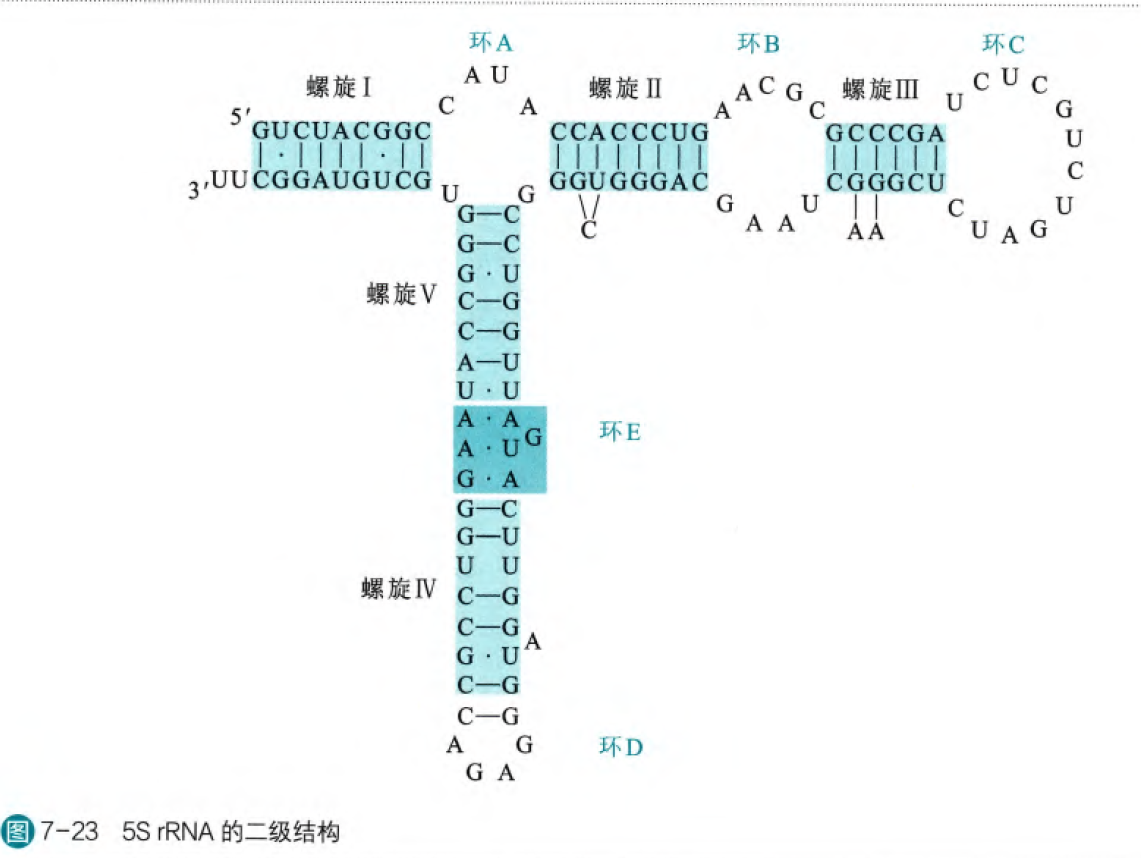
(环E没有突出是因为Hogsteen配对)
mRNA的二级结构
我们更加关心的其实是mRNA的一级结构,但是mRNA的两端二级结构可能会对基因表达产生一定影响。
核酸的三级结构
核酸的三级结构是在其二级结构的基础上形成的包括所有原子在内的三维立体结构。
对DNA来说,其三级结构就是在双螺旋基础上形成的超螺旋。
DNA的三级结构
在正常状态下,DNA是以正常的B型双螺旋形式存在,每一圈10bp,这个时候双螺旋的能量最低。当某种作用施加时,使得DNA双螺旋每一圈小于或者是多于10bp,将会导致DNA双螺旋过度缠绕或者缠绕不足。如果两端固定,或者本来就是共价闭环DNA(cccDNA)(也就是5’端和3'端形成磷酸二酯键),那么会因为张力无法释放而自发形成超螺旋结构。
那么如果是过度缠绕,我们称之为正超螺旋,如果是缠绕不足我们称之为负超螺旋。我们之前有提到过,负超螺旋有利于Z型DNA的形成,同时负超螺旋叶容易在DNA的转录调控位点形成。(但是不论是正还是负超螺旋,DNA的基本螺旋方式仍然是B型)
负超螺旋是两条链的缠绕不足导致的,所以更有利于解链,由此有利于DNA的复制、重组和转录,所以绝大多数生物体内的DNA在没有复制的时候,都是以负超螺旋的形式存在,那么如果DNA开始复制、重组、转录,那么会随着解链的深入(如果两端是固定的,比如说部分解链),那么负超螺旋会逐渐消耗,逐渐向正超螺旋转变,与负超螺旋相反,正超螺旋会因为螺旋结构过于紧密,使得DNA的解旋变得困难,但是细胞中存在的DNA拓扑异构酶有助于清除正超螺旋
(与碱基大小相近的多环芳香族分子(如溴乙锭和吖啶橙)可以插入在DNA双螺旋的两个相邻碱基对之间,促进形成正超螺旋,是强烈的致癌分子)
RNA的三级结构
RNA三级结构的形成和蛋白质三级结构的形成有一定的相似度。我们先回忆蛋白质三级结构是如何形成的:首先蛋白质的规则残基序列会形成一定的二级结构比如α螺旋和β折叠等,这些二级结构一般作为构成蛋白质基本骨架的关键组件,然后再根据侧链基团的相互作用,形成一定的模体和结构域,最终构成蛋白质的三级结构。那么对于RNA来说也是类似的,首先如前面所介绍的,RNA会根据内部碱基的互补配对性形成发夹等二级结构,然后同时也会有部分没有配对的单链残留,那么这些单链就类似于蛋白质的R,可以彼此或者和双链RNA相互作用使得RNA形成三级结构。那么更具有类比性的是,我们在蛋白质折叠当中说到存在Hsp家族中存在很多分子伴侣可以帮助复杂的蛋白质折叠,在RNA当中也是一样的,我们把帮助RNA折叠的分子伴侣称之为RNA伴侣。
那么在RNA二级结构构成三级结构的过程中,螺旋之间的碱基共轴堆积可以形成疏水作用和范德华力,同时由于RNA的骨架是带有高度负电的,所以RNA三级结构的形成经常设计金属离子如镁离子,这种带正电荷的例子可以中和吸引不同区域的磷酸核糖骨架,发生近距离的接触和包装。(甚至这种金属离子可能会成为折叠的中心)
那么类比于蛋白质三级结构的建立过程,我们在这里也介绍两种常见的三级结构:
1. 假节结构:(以H假节为例)假节结构可以理解为是发夹结构的进一步折叠形成的,茎结构外的单链与环形成配对,配对形成的螺旋堆叠在茎结构上,形成共轴碱基堆叠,这一结构可以提高稳定性。那这样就形成了两个茎结构和两个环结构,环结构暴露的碱基可以和其他部位的茎或者单链形成氢键作用。那么假节结构出现在很多的核酶活性中心,有证据显示,端粒酶RNA中有一个高度保守的假节结构是端粒酶活性所必需的。
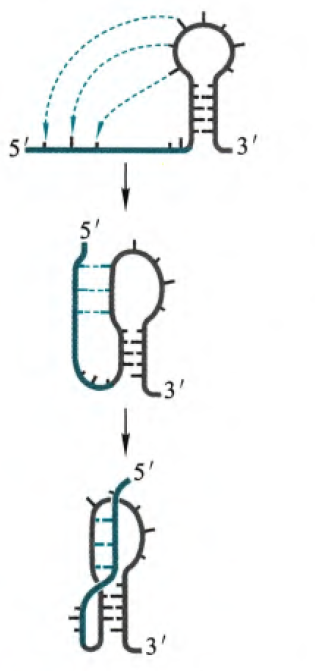
2. 吻式发夹结构
吻式发夹结构也是基于发夹结构形成的,是两个发夹结构的环碱基可以彼此配对,所以就形成了最左侧的结构,然后进一步,因为共轴螺旋的结构更加稳定,所以驱动着进一步折叠,最后会出现两侧碱基突出的情况。
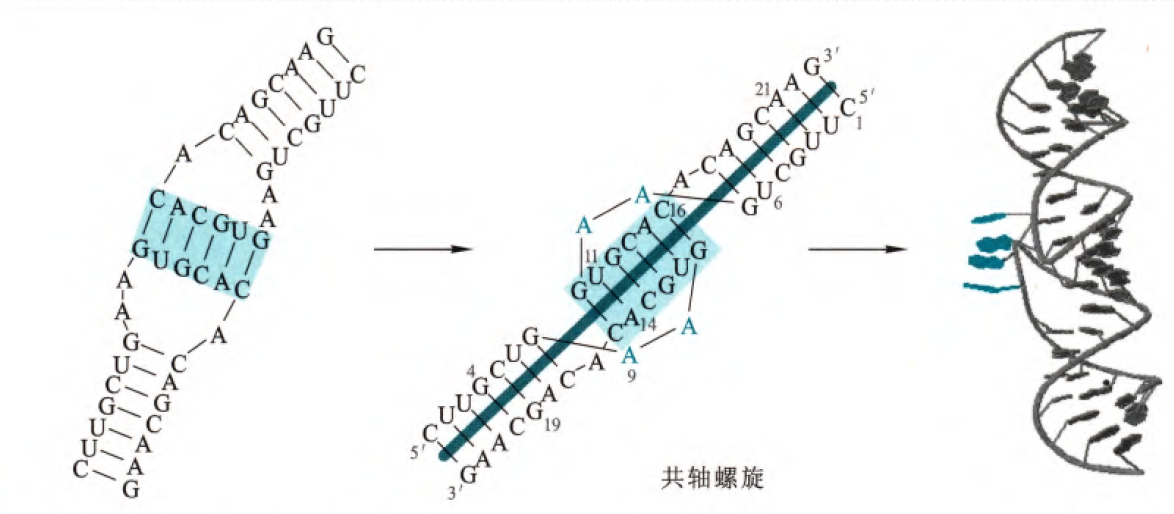
对于tRNA的三级结构而言,D环与TψC环上的碱基形成氢键,使得两结构靠近,同时碱基尽可能保持平行以形成堆叠的疏水作用(这也是仅次于氢键构成三级结构的作用),形成了如下图所示的L型结构,其中反密码子和氨基酸臂在L型结构的两侧分开
其实核糖体的整体构象是由rRNA决定的,核糖体大小亚基只是位于RNA螺旋之间起稳固作用等
核酸和蛋白质的相互作用
细胞当中的核酸很少是游离的,通常会与胞内特定的蛋白质通过非共价键发生相互作用。那么如果是永久性的相互作用,那么意味着蛋白质和核酸的结合就是不可逆的,一旦形成就是稳定的紧密复合物,由此形成的复合物称为核酸蛋白颗粒。(对于核糖核酸蛋白暂不介绍)
脱氧核糖核酸蛋白颗粒
真核生物的核小体结构
在细胞核中的DNA会和组蛋白结合形成核小体,核小体是构成染色质的基本结构,核小体之间的DNA称为连线DNA,连线DNA由于不参与构成核小体,所以容易暴露被水解,H1组蛋白可以和连线DNA结合,但是如果抑制H1表达,不会影响核小体形成(因为连线DNA不参与构成核小体)
我们知道核小体是带有正电的(也就是组成核小体的组蛋白富集碱性残基),可以通过和DNA负电骨架的静电作用结合。
核小体是八聚体,由两个H3-H4异源二聚体和两个H2A-H2B异源二聚体构成,那么H4的保守性最高,其次H3,H2A和H2B,由前所述H1的作用有限(主要是将核小体组成更高级紧缩的结构),所以保守性较低。那么在核小体三维结构上,四种组蛋白都会存在一个N端尾巴,这一个尾巴会穿过DNA超螺旋的缝隙,成为潜在的修饰位点,可以调节DNA和核小体的结构,从而对基因表达进行调控,而C端会形成组蛋白特有的结构模体(组蛋白折叠),N端和C端的尾巴也会与相邻的核小体接触。DNA双螺旋小沟面向蛋白质表面,与Arg侧链接触,DNA大沟朝外,从而允许序列识别并结合。核小体表面的DNA卷曲略显不足,以负超螺旋的形式存在。
一个核小体表面环绕大约146bp的DNA双螺旋,可以将DNA长度压缩6~7倍(核小体宽度10nm,146*0.34/5nm(短轴)+连线DNA大约是这个值)
由于DNA和组蛋白结合,所以DNA的转录与复制受到组蛋白结构的影响,从而对基因表达起着调控作用。
(2)古菌中的核小体结构
古菌中的组蛋白结构相对于真核生物而言就相对简单,仅仅可以形成四聚体核心,也没有伸出来的 N端和C端的尾巴,所以也不可以被化学修饰。
(3)细菌中的拟核
细菌是没有组蛋白,所以没有核小体结构,但是有一些小的碱性蛋白可以和DNA结合,形成高度浓缩的拟核或者是类核结构。