RT调度器
RT RunQ
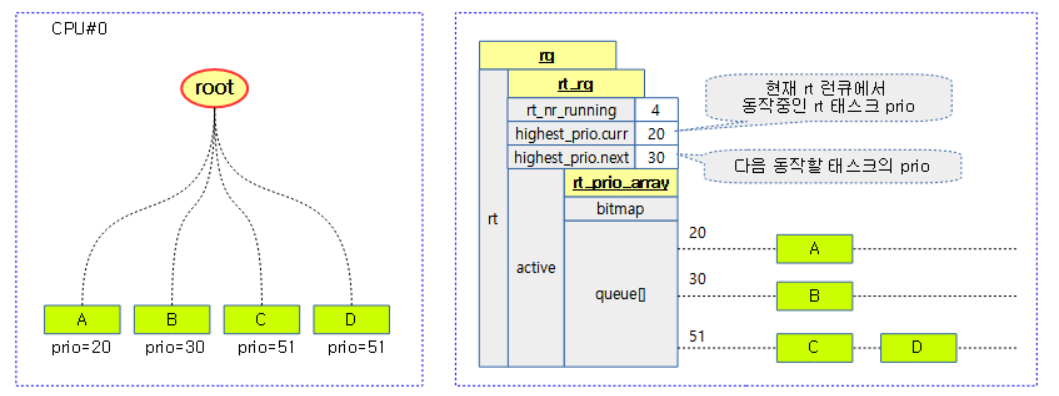
每个物理cpu会有一个RT的runqueue。RT进程的优先级范围为0~99,数值越大,优先级越高。rq->rt_rq结构中,会为每个优先级创建一个链表头: rt_prio_array.queue[MAX_RT_PRIO]。
RT任务的运行
一旦一个RT任务开始运行,要让它停下来,有以下几种场景:
1、有更高优先级的调度器(stop、dl)准备好
2、RT任务自己睡眠:schedule(), yield(), msleep(), etc.
3、在preemtible 内核中,有更高优先级的rt任务准备就绪。
4、如果是RR调度器,则还可能在相同优先级的rt任务之间切换
5、Throttle due to rt bandwidth
6、Terminate rt task
对于相同优先级的RT进程,SCHED_FIFO会让先运行的RT进程运行到结束,才会切换到后面ready的RT进程;而SCHED_RR则会按照一个period time(默认是100ms),轮流的将RT进程加入queue尾部。
RT任务的切换,依赖于抢占时机(或叫调度点)。像中断、异常,任务enqueue,返回用户态等都会触发抢占调度。
RT组调度
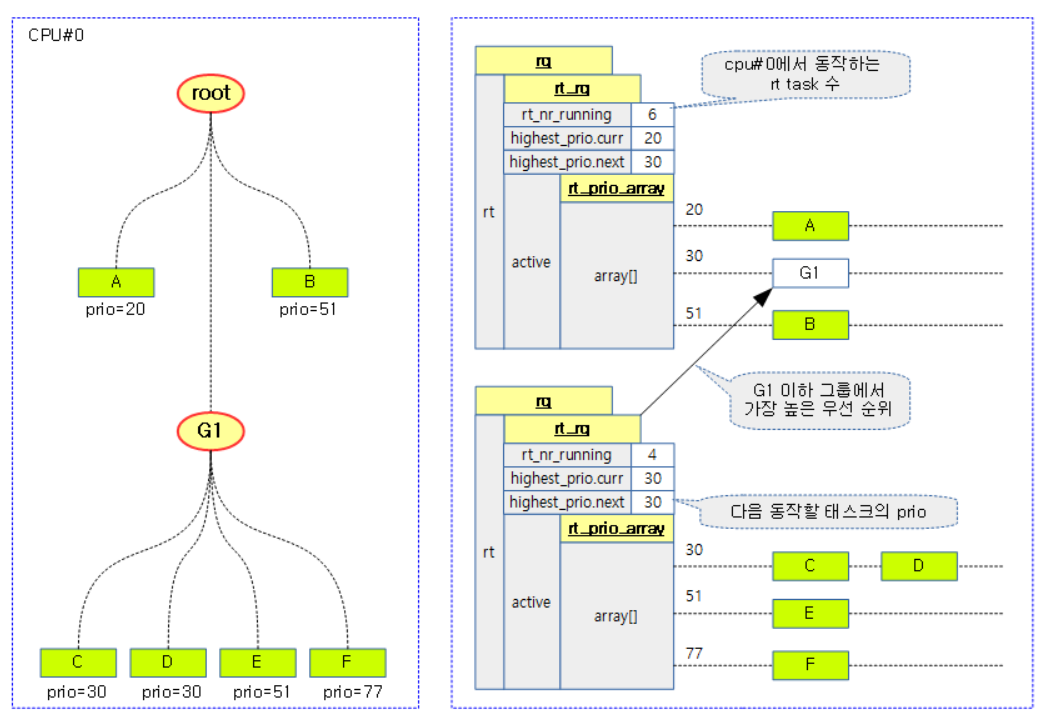
对于RT组调度,如果只看优先级,还是跟没用组调度一样。根据子组的最高优先级,挂入父组的对应queue。运行完后,摘下,重新挂下一个需要调度的优先级RT任务到父组对应优先级的queue中。因为组调度是hierarchical的,所以需要一层一层的挂。
还有一个需要注意的是RT bindwidth,这是按group来的,也是hierarchical的。比如,这里有三层group:A——》B——》C,假设bindwidth都是80%,分配给A的时间是100ms,则分配给B的时间只有80ms,分配给C的就只有64ms了!是否是这样??待确认!!
RT bandwith有层级,但是并不是按比例相乘的结果。而是,下一层级所有子cgroup的RT runtime的和不能超过parent cgroup!
下面是同一优先级任务的组调度例子:
Repeat the cycle: A1 -> R1 -> A2 -> R1
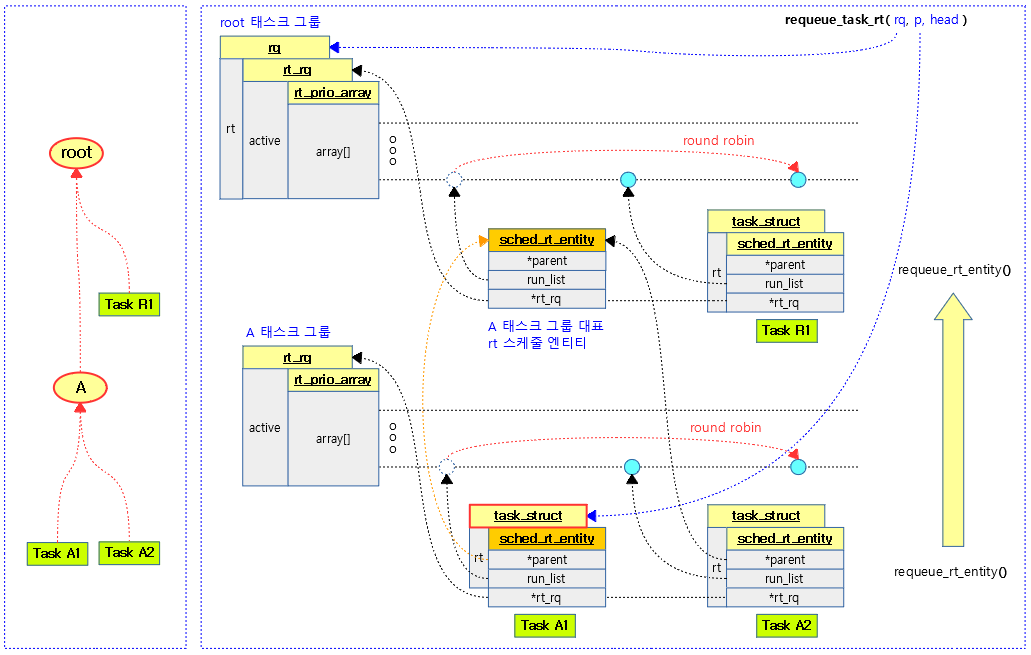
可以看出,调度组嵌套越深的任务,对其运行机会越不利!调度组A的任务运行一遍时,父组任务R1已经运行了两次!
RT Bandwidth
Global RT Bandwidth
全局的RT带宽限制是默认开启的,默认值如下:
- sysctl_sched_rt_runtime
- Default value: 950,000 us (0.95 seconds)
- “ /proc/sys/kernel/sched_rt_runtime_us “
- sysctl_sched_rt_period
- Default value: 1,000,000 us (1 second)
- “ /proc/sys/kernel/sched_rt_period_us “
Group RT Bandwidth
如果内核开启了CONFIG_RT_GROUP_SCHED 选项,则cgroup中可以进一步限制group内的rt进程的带宽:
- rt_runtime_us
- Default value for subtask group: 0 us (disable)
- Default value for root task group: 950,000 us (0.95 seconds)
- “ /sys/fs/cgroup/cpu/<task group>/rt_runtime_us “
- rt_period_us
- Default value: 1,000,000 us (1 second)
- “ /sys/fs/cgroup/cpu/<task group>/rt_period_us “
注意:
这里全局RT带宽和cgroup的top RT带宽有什么区别和联系呢?
首先,在没有使能cgroup的cpuctl子系统的情况下,系统会按照全局的RT带宽来进行限制。
其次,如果使能了cgroup的cpuctl子系统。其top RT带宽设置仍然受全局RT带宽限制(不能超过全局RT带宽设定,参见“tg_rt_schedulable”函数实现)。
最后,在cgroup的hierarchical中,所有同一层级的子cgroup的RT runtime之和不能大于parent cgroup的RT runtime!
比如,全局和top RT带宽都设置为950000us/1000000us。top cgroup下有三个子组A、B、C。假设A的RT带宽设置为500000us/1000000us,B的RT带宽设置为400000us/1000000us,则C的RT带宽最多只能设置为50000us/1000000us(95-50-40 = 5)!
RT_RUNTIME_SHARE
RT调度有个feature——RT_RUNTIME_SHARE,使能之后,正在运行的RT Runqueue可以从neighbours cpu借时间!
该标志默认是false,可以从如下sysfs路径获知:
# cat /sys/kernel/debug/sched_features
GENTLE_FAIR_SLEEPERS START_DEBIT NO_NEXT_BUDDY LAST_BUDDY CACHE_HOT_BUDDY WAKEUP_PREEMPTION NO_HRTICK NO_DOUBLE_TICK NONTASK_CAPACITY TTWU_QUEUE NO_SIS_AVG_CPU SIS_PROP NO_WARN_DOUBLE_CLOCK RT_PUSH_IPI NO_RT_RUNTIME_SHARE NO_LB_MIN ATTACH_AGE_LOAD WA_IDLE WA_WEIGHT WA_BIAS UTIL_EST UTIL_EST_FASTUP ALT_PERIOD BASE_SLICE
该功能(RT_RUNTIME_SHARE)体现在sched_rt_runtime_exceeded()——>balance_runtime()函数中。如果当前cpu的RT runqueue的运行时间rt_time,超过了用户设置的rt_runtime(如前面讲的0.95s)。如果未使能(RT_RUNTIME_SHARE)feature,那么就设置rt_rq->rt_throttled = 1,并主动让出cpu;相反,如果使能了该feature, 那么就尝试从其他cpu借时间。
从哪些cpu借?
root_domain->span
如何借?
通过for_each_cpu(i, rd->span)接口,依次从neighbour cpu的剩余runtime借:
diff = iter->rt_runtime - iter->rt_time;
neighbour cpu能借多少?
neighbour cpu并不是将剩余的所有rt时间都借给你,而是最多借1/n * diff,n表示root_domain的cpu数目!
iter->rt_runtime -= diff;
当前cpu借多少才够?
if (rt_rq->rt_runtime == rt_period)
break;
rt_rq->rt_runtime += diff;
也就是,当前cpu的rt_runtime可以达到rt_period!也即是可以100%占用当前cpu!
以4cpu系统为例,假设用户(或系统)设定的rt bandwidth为90ms/100ms,cpu0在某次调度信息更新的事件中,发现自己已经运行了92ms;同时,假设cpu1~cpu3都只运行了74ms,也就是都还剩余16ms的rt运行带宽。这时候,cpu0通过balance_runtime()函数,会依次从cpu1借4ms(16/4),cpu2借4ms。并不会对cpu3借时间,因为,cpu0借了cpu1和cpu2的时间后,已经达到100ms的period时间了!
这之后,cpu0 rt_rq->rt_runtime为100ms,cpu1 rt_rq->rt_runtime为86ms,cpu2 rt_rq->rt_runtime也为86ms,cpu3 rt_rq->rt_runtime没变,仍然为90ms!
我们看到,cpu0的RT进程通过借时间方式,达到了100%的cpu占用。这会导致cfs任务的starving!所以,默认RT_RUNTIME_SHARE feature是关闭的,参见:https://github.com/torvalds/linux/commit/2586af1ac187f6b3a50930a4e33497074e81762d
Dequeue and enqueue of top RT runqueue
dequeue_top_rt_rq()
enqueue_top_rt_rq()
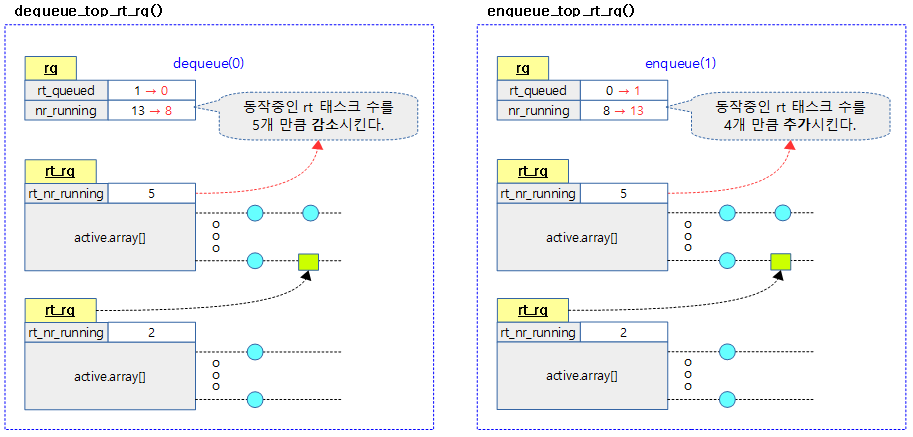
注意:
上图中,rt_queued成员在rt_rq结构中,表示有实时进程入队;nr_running在rq结构中,表示该runqueue总共有多少进程ready、等待调度(包含rt、dl、cfs三个子队列)!rt_rq中也有一个对应的rt_nr_running成员,表示该rt_rq队列有多少ready的实时进程等待调度!
static void sched_rt_rq_dequeue(struct rt_rq *rt_rq)
{
struct sched_rt_entity *rt_se;
int cpu = cpu_of(rq_of_rt_rq(rt_rq));
rt_se = rt_rq->tg->rt_se[cpu];
if (!rt_se) {
dequeue_top_rt_rq(rt_rq, rt_rq->rt_nr_running);
/* Kick cpufreq (see the comment in kernel/sched/sched.h). */
cpufreq_update_util(rq_of_rt_rq(rt_rq), 0);
}
else if (on_rt_rq(rt_se))
dequeue_rt_entity(rt_se, 0);
}
代码中,rt_se为null,则说明该rt_rq不属于某个调度实体(即没有嵌套的调度组),而是直接对应于top实时运行队列(rq.rt)!
Enqueue & Dequeue RT entities
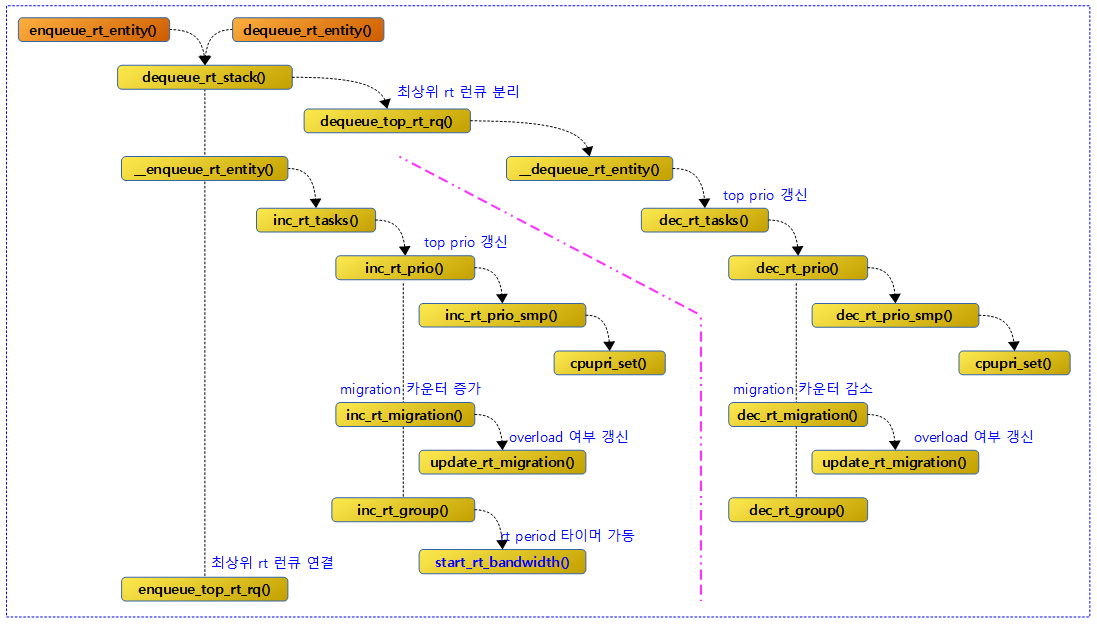
我们看到,dequeue和enqueue一个rt_entity,都需要先通过dequeue_rt_stack()函数,自顶向下的移出全部的rt_entity,why?
/*
* Because the prio of an upper entry depends on the lower
* entries, we must remove entries top - down.
*/
Enqueue & Dequeue RT Tasks
enqueue_task_rt()调用enqueue_rt_entity()函数实现主要功能。
dequeue_task_rt()调用dequeue_rt_entity()函数实现主要功能。
pushable task list
pushable_tasks 是一个 plist_head 类型的链表,用于管理实时调度器(RT Scheduler)中可被推送到其他 CPU 的任务。它的主要作用是在多核系统中实现实时任务的负载均衡(load balancing),即将某些实时任务从一个 CPU 推送到另一个 CPU,以优化任务调度和资源利用。
在enqueue_task_rt()函数中,如果将一个task入队之后,其没有得到执行机会(!task_current(rq, p),说明有更高优先级的任务在运行),并且该task的cpu allow允许迁移到别的cpu(p->nr_cpus_allowed > 1),则会调用enqueue_pushable_task(rq, p);将该task加入rq->rt.pushable_tasks链表中,并设置rq->rt.overloaded = 1;
在合适的时机,会通过push_rt_task()函数,将该实时任务推到其他cpu执行。
plist (Descending-priority-sorted double-linked list)
It is a priority-based sorted dual list. 它甚至比RB tree更高效,因为它的长度被限制为100(prio 0~99)。这里有两个pushable_tasks成员:
struct task_struct {
…
struct plist_node pushable_tasks;
…
}
struct rt_rq {
…
struct plist_head pushable_tasks;
…
}
rt_rq中的是plist_head类型,task_struct中的是plist_node类型,如下:
struct plist_head {
struct list_head node_list;
};
struct plist_node {
int prio;
struct list_head prio_list;
struct list_head node_list;
};
通过plist_add()和plist_del()来进行操作。add的时候,会按照优先级插入。
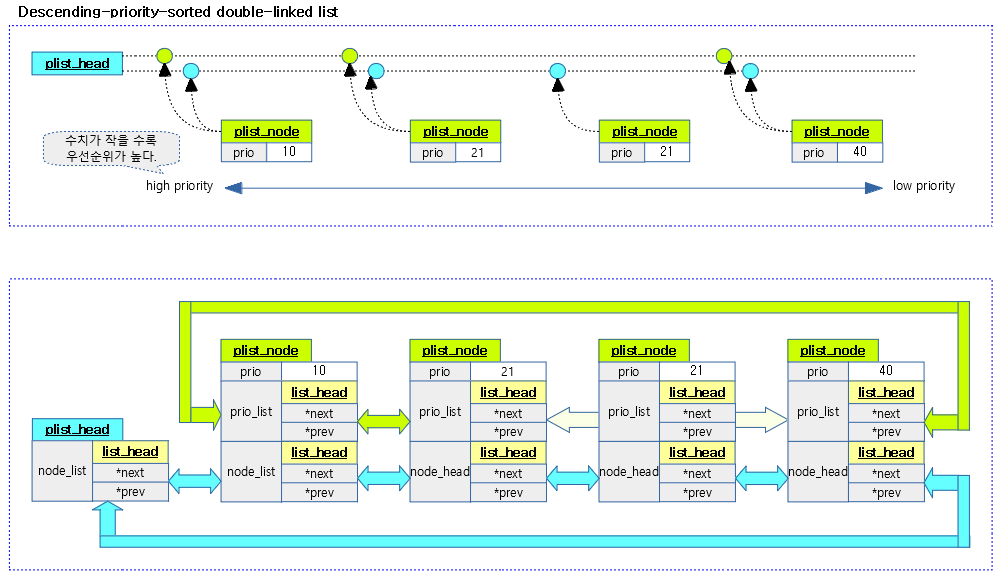
上图中蓝色节点为node_list,绿色节点为prio_list。可以看出,所有task node的node_list都是链接在一起的;但是prio_list则不然,相同优先级的只链接第一个,这也是为了方便高效search。
RT Period Timer
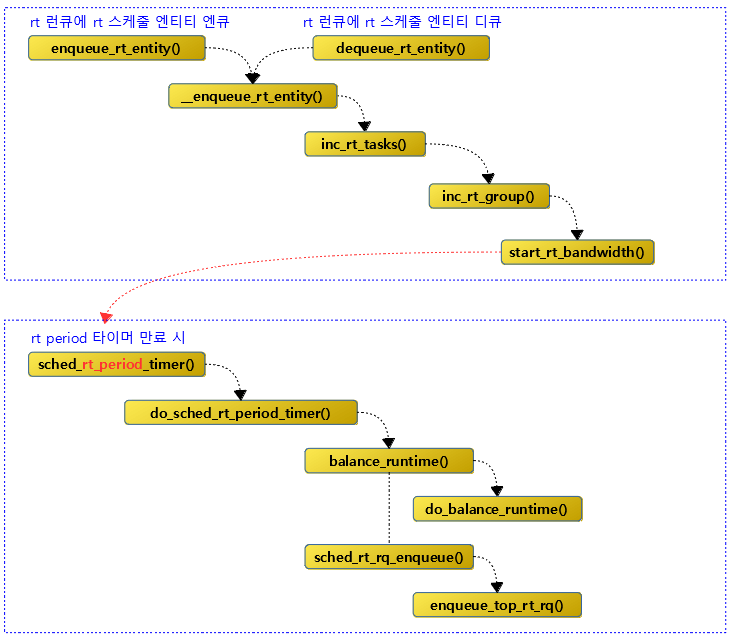
start_rt_bandwidth()函数中会启动rt_bandwidth的timer——>rt_period_timer。 sched_rt_period_timer()是timer回调函数。
do_sched_rt_period_timer()函数是实时调度器中实现带宽控制(Bandwidth Control)的核心部分,用于确保实时任务的公平性和系统的稳定性。其主要作用包括:
- 管理实时任务的运行时间配额,确保任务不会超出分配的运行时间。
- 在新的周期开始时,重置实时任务的运行时间配额。
- 解除对超出运行时间配额的任务的限制。
- 通知调度器重新调度任务。
Pick up next task
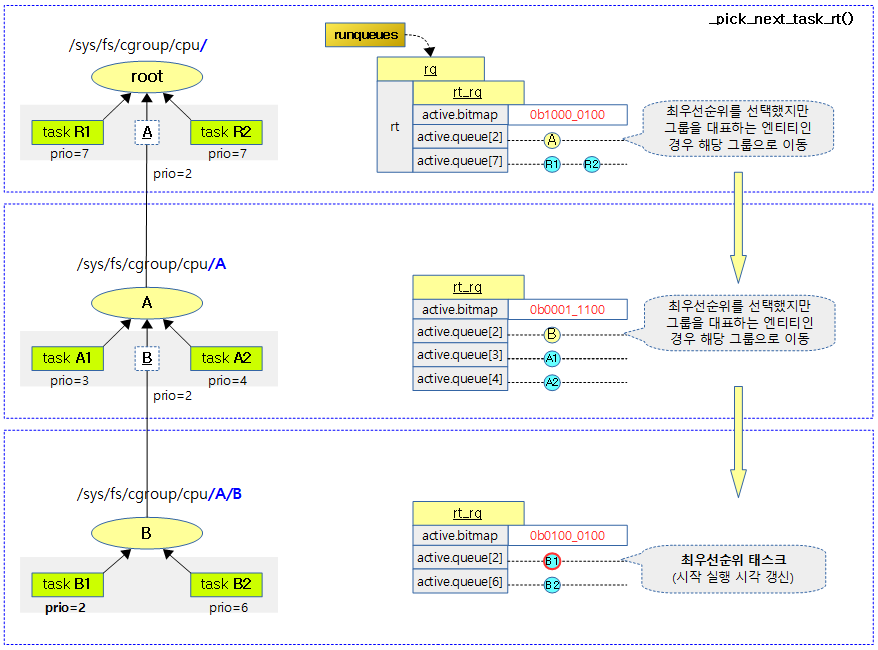
pick_next_task_rt(),新代码中是pick_task_rt().如果使能了CONFIG_RT_GROUP_SCHED,则会递归查找,直到查找到拥有最高优先级的最底层的rt_rq->active中的task的sched_rt_entity对象。如下图,各级rt_rq中关键成员变量值以及搜索过程均呈现出来:
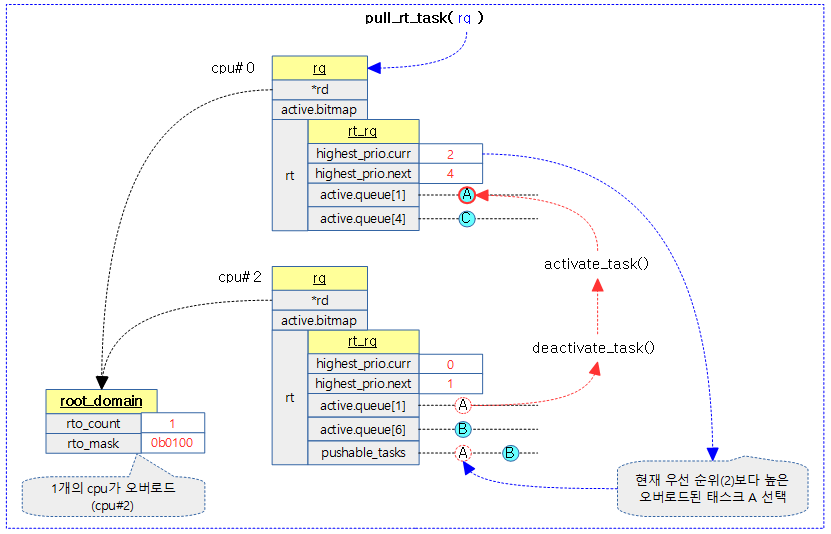
balance
When two or more RT tasks need to run on one CPU, the following management is performed so that all but one RT task can be migrated.
- pushable task list
- Add the rt task that requires migration to the pushable list of the corresponding CPU runqueue.
- rq->pushable_lists
- Add the rt task that requires migration to the pushable list of the corresponding CPU runqueue.
- overload mask
- Set the overload mask for the CPUs that require migration.
- rto_count++, rto_mask setting
- Set the overload mask for the CPUs that require migration.
When an rt task migrates to another CPU, it does so by calling the following function. In addition, in order to find the CPU to migrate to, 102 priorities are updated for each CPU, and the CPUs with the lowest priorities are selected through this.
- balance_rt() – (*balance)
- Call the pull_rt_task() function
- Depending on whether the RT_PUSH_IPI feature is used, either push migration using IPI or direct pull migration is performed.
- When using the RT_PUSH_IPI feature, an IPI is called with an overloaded CPU. After that, the CPU to which the IPI is called finds a CPU with a lower priority and push-migrates the pushable task with the highest priority one by one to a CPU with a lower priority .
- When the RT_PUSH_IPI feature is not used, the current CPU pulls and migrates pushable tasks with a higher priority than the current CPU from the run queue of overloaded CPUs .
- task_woken_rt() – (*task_woken)
- Call the push_rt_tasks() function
- If there is already a task running in the RT run queue, and this RT task is currently pinned to the CPU or has a higher priority than the RT task to be woken up, the CPU directly push-migrates the RT task to be woken up .
- balance_callback() – (*balance_callback)
- At the very end of the __schedule() function , one of the following functions is called to cause the current CPU to directly perform push migration and pull migration for post processing .
- push_rt_tasks()
- pull_rt_task()
- At the very end of the __schedule() function , one of the following functions is called to cause the current CPU to directly perform push migration and pull migration for post processing .
下图是一个示例,展示了从其他overloaded cpu拉取更高优先级的进程来执行的流程: