【MySQL】深分页的性能优化,游标方案和覆盖索引+延迟回表方案
一、先明确两个SQL的核心问题
SELECT * FROM t ORDER BY create_time DESC LIMIT 1000000, 100
SELECT * FROM t WHERE id < 4155423 ORDER BY create_time DESC LIMIT 100
1. 第一个SQL:SELECT * FROM t ORDER BY create_time DESC LIMIT 1000000, 100
- 问题本质:深分页导致的“全表/全索引扫描+排序”开销
MySQL执行此查询时,会先对全表(或create_time索引)进行降序排序,然后跳过前100万个记录,再取100条。当OFFSET(100万)极大时,排序和磁盘I/O的开销会急剧上升,甚至可能导致数据库卡顿。 - 执行流程(以InnoDB为例):
① 若create_time无索引:全表扫描→临时文件排序(Filesort)→跳过100万条→返回100条;
② 若create_time有索引:索引扫描→按索引顺序排序(无需额外排序)→跳过100万条→回表取数据(若SELECT *则需回表)。
无论哪种情况,OFFSET越大,性能越差。
2. 第二个SQL:SELECT * FROM t WHERE id < 4155423 ORDER BY create_time DESC LIMIT 100
- 问题本质:利用
id条件缩小范围,减少排序数据量
假设id是自增主键(常见设计),则id < 4155423意味着筛选出“比某条记录更早的所有记录”。结合ORDER BY create_time DESC,相当于“取比某条记录更早的100条最新记录”。 - 执行流程:
① 用id索引快速定位到id < 4155423的记录(范围扫描);
② 对这些记录按create_time降序排序(若有联合索引可避免排序);
③ 取前100条。
相比第一个SQL,减少了需要排序的数据量(仅筛选部分记录而非全表),性能显著优于前者。
口述改进:select时不用*而是把要查的字段写明,
order by 字段可以改成id,或者建立联合索引,
二、推荐改进方案与详细实现
方案 A:游标分页
想象成:用“书签”标记上一页的末尾,下一页直接从“书签”往后找,不用把前面所有内容再翻一遍。
原理:用「排序字段 + 唯一列(防止排序字段重复时顺序乱)」当“书签(游标)”,只取“书签之后”的内容,避免把前面大量无关内容都扫描一遍。
SQL 模板(假设按 create_time 倒序排,时间相同就按 id 倒序)
- 初始页(第一页):
SELECT id, col1, col2, create_time
FROM t
ORDER BY create_time DESC, id DESC
LIMIT 100;
注解:第一次查,直接取最新的 100 条,按“时间从新到旧,时间一样就 id 从大到小”排。
- 下一页(用上次最后一行的
最后时间和最后id当“书签”):
SELECT id, col1, col2, create_time
FROM t
WHERE (create_time < :last_time)OR (create_time = :last_time AND id < :last_id)
ORDER BY create_time DESC, id DESC
LIMIT 100;
注解:下一次查时,只找“时间比上次最后一条更早,或者时间相同但 id 更小”的内容,再取 100 条。相当于从“书签”位置往后翻,前面的内容完全不碰。
建索引(MySQL 8+)
-- 让排序和查询能直接走索引,不用全表扫
CREATE INDEX idx_create_time_id ON t (create_time, id);
注解:索引就像“目录”,数据库查的时候,直接看“目录”找数据,不用把整本书(表)翻一遍。这里把
create_time和id一起做目录,排序和过滤时能直接用目录,特别快。
这里本质上是对SELECT * FROM t WHERE id < 4155423 ORDER BY create_time DESC LIMIT 100的改进,但是为什么要新加一个id排序?
假设表中有以下数据(
create_time有重复):
| id | create_time | 其他字段 |
|---|---|---|
| 105 | 2023-10-01 12:00:00 | … |
| 103 | 2023-10-01 12:00:00 | … |
| 101 | 2023-10-01 12:00:00 | … |
| 99 | 2023-10-01 11:59:00 | … |
第一页 SQL:
SELECT * FROM t ORDER BY create_time DESC LIMIT 2
结果可能是 id=105、103,也可能是 id=105、102,如果是后者,那么查第二页数据时,就会漏掉103
关键原因:MySQL 对 “重复排序字段” 的排序是 “不稳定” 的
- 当
ORDER BY create_time DESC时,create_time相同的行(105、103、101)的相对顺序是不确定的(除非有第二个排序字段)。
单一排序字段如果不唯一,结果顺序在数据库层面是“不稳定”的。分页时就会出现“重复/漏掉”的情况
解决方案:加一个唯一且有序的字段(通常是主键 id)做二次排序。
Go 示例(简化版;游标用 base64 编码,把“书签”打包成一串字符)
// 注意:示例省略了错误处理与上下文管理,生产代码需完善。
package mainimport ("database/sql""encoding/base64""encoding/json""fmt"_ "github.com/go-sql-driver/mysql" // MySQL 驱动,让 Go 能连 MySQL"time"
)// 定义“书签”的结构:存上次最后一条的时间和id
type Cursor struct {LastTime time.Time `json:"t"` // 上次最后一条的创建时间LastID int64 `json:"i"` // 上次最后一条的id
}// 把“书签”转成 base64 字符串(方便传递,比如作为 URL 参数)
func encodeCursor(c Cursor) string {b, _ := json.Marshal(c) // 先转成 JSON 字节return base64.RawURLEncoding.EncodeToString(b) // 再转成 base64
}// 把 base64 字符串转回“书签”结构
func decodeCursor(token string) (Cursor, error) {var c Cursorb, err := base64.RawURLEncoding.DecodeString(token) // 先解 base64if err != nil {return c, err}err = json.Unmarshal(b, &c) // 再转成 JSON 结构return c, err
}// 查某一页数据,返回“数据列表”和“下一页的书签”
func fetchPage(db *sql.DB, limit int, token string) ([]map[string]interface{}, string, error) {var rows *sql.Rowsvar err error// 如果没有书签(token 为空),查第一页if token == "" {q := `SELECT id, col1, col2, create_time FROM tORDER BY create_time DESC, id DESC LIMIT ?`rows, err = db.Query(q, limit)} else {// 有书签,先解析出上次的“最后时间”和“最后id”c, err2 := decodeCursor(token)if err2 != nil {return nil, "", err2}// 只查“时间更早,或时间相同但id更小”的内容q := `SELECT id, col1, col2, create_time FROM tWHERE (create_time < ?) OR (create_time = ? AND id < ?)ORDER BY create_time DESC, id DESC LIMIT ?`rows, err = db.Query(q, c.LastTime, c.LastTime, c.LastID, limit)}if err != nil {return nil, "", err}defer rows.Close() // 用完数据库连接要关闭cols := make([]map[string]interface{}, 0, limit) // 存查询结果var last Cursor // 记录这一页最后一条的“书签”(供下一页用)// 逐行读取数据for rows.Next() {var id int64var col1 stringvar col2 stringvar ct time.Timeif err := rows.Scan(&id, &col1, &col2, &ct); err != nil {return nil, "", err}// 把每行数据存起来cols = append(cols, map[string]interface{}{"id": id, "col1": col1, "col2": col2, "create_time": ct})// 更新“最后一条的书签”last.LastID = idlast.LastTime = ct}nextToken := ""// 如果这一页刚好取了 limit 条,说明可能有下一页,生成下一页的书签if len(cols) == limit {nextToken = encodeCursor(last)}return cols, nextToken, nil
}func main() {// 实际项目中要写数据库连接代码,这里省略fmt.Println("示例完成,重点看 fetchPage 函数的逻辑~")
}
优点
- 不管翻多少页,速度都很稳定(不像传统分页,翻到后面越来越慢),适合“无限滚动”(比如朋友圈、微博刷新加载)。
- 响应时间不会因为“页码大”而变慢,只和每次取多少条(limit)有关。
注意点
- 不能直接跳转到“第 100 页”,只能“一页一页往后翻”。如果业务需要跳页,得额外处理。
- 排序的字段(比如
create_time)如果有重复,必须加个唯一的列(比如id),否则顺序会乱。 - “书签”字符串(token)最好加密,防止别人瞎改 URL 乱翻数据。
方案 B:覆盖索引 + 延迟回表(减少随机 IO)
想象成:如果只需要“书名”,直接看“目录”就行;但如果需要“书的全文”,才翻到对应页。通过“先看目录找位置,再翻页”减少工作量。
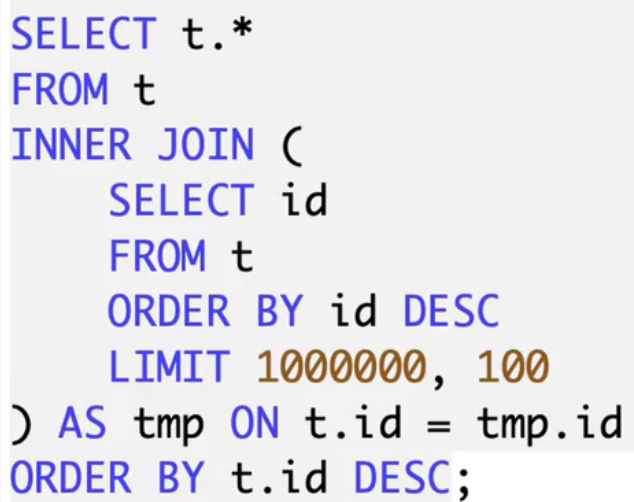
如果业务必须查所有列(SELECT *),可以这样优化:
1. 优先只查需要的列
SELECT id, title, create_time
FROM t
ORDER BY create_time DESC
LIMIT 100;
-- 建索引,让查询直接走“目录”,不用翻整本书
CREATE INDEX idx_cover ON t (create_time, id, title);
注解:如果只需要
id、title、create_time,就把这几个列做成“目录(索引)”,查的时候直接看目录,不用把表中其他无关列(比如内容、作者)都读出来,速度更快。
2. 延迟回表(分两步查,减少无效工作)
当必须查很多列,但又不想因为“翻页跳过大量数据”导致慢时:
- 第一步:只通过“目录(索引)”找目标数据的
id(这一步很快,因为只看目录)。 - 第二步:用找到的
id去表中捞完整数据(只捞需要的几条,不是全部)。
-- 步骤1:只通过索引找目标 id(即使 offset 大,看目录也比翻整本书快)
SELECT id
FROM t
ORDER BY create_time DESC
LIMIT 1000000, 100; -- 步骤2:用这些 id 去表中查完整数据
SELECT t.*
FROM t
JOIN (-- 步骤1查到的 id 集合SELECT id FROM t ORDER BY create_time DESC LIMIT 1000000, 100
) ids USING(id)
ORDER BY create_time DESC;
注解:步骤 1 虽然
LIMIT 1000000, 100还是慢,但只需要看“目录”里的id,不用把表中所有列都读出来;步骤 2 只需要捞 100 条的完整数据,不是百万条,所以整体比直接SELECT *快。