UIUC 提出视频虚拟试穿生成方法 DressDance,可直接生成高质量的5 秒 24 帧 1152×720 分辨率的虚拟试穿视频。
UIUC 提出的 Dress&Dance 框架是一个通用的视频生成框架,其条件输入范围广泛,包括文本、布局、稀疏姿势序列和多模态组合。该方法没有构建特定任务的架构,而是采用了一种统一的条件机制 CondNet,它将不同的模态处理到共享空间中。这使得单个视频生成器无需重新训练即可支持多种控制信号。
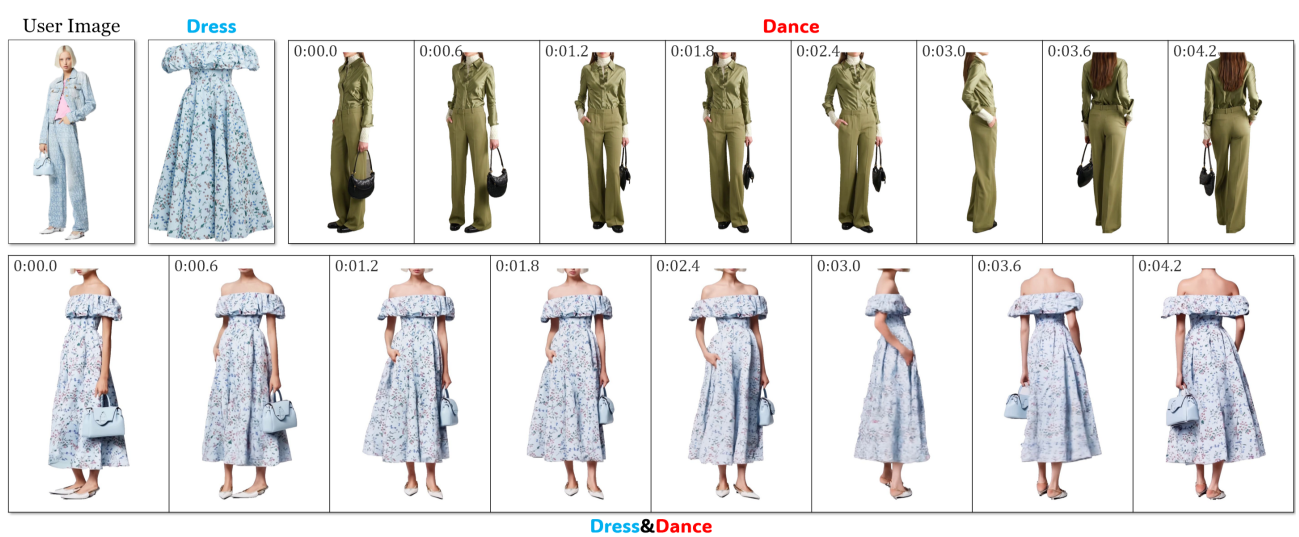
在一系列示例中(包括随附视频中展示的示例),该方法生成了 时间连贯且逼真的结果,通常能够捕捉到细微的动态,并与输入提示保持高度一致。同一模型在各个任务中具有良好的泛化能力,展现出强大的组合性和对各种条件输入的响应能力。

效果展示
单件服装

同时生产多件服装

相关链接
论文:https://arxiv.org/pdf/2508.21070
项目:https://immortalco.github.io/DressAndDance/
论文阅读

论文名:Dress&Dance: Dress up and Dance as You Like It Technical Preview
论文推出了一个视频扩散框架Dress&Dance,它可以生成高质量的5秒24帧/秒虚拟试穿视频,分辨率为1152×720,视频中用户穿着自己想要的服装,并根据给定的参考视频进行移动。该方法只需要一张用户图像,并支持多种上衣、下装和连体衣的试穿,以及一次性同时试穿上衣和下装。我们框架的关键是CondNet,这是一个新颖的调节网络,它利用注意力机制来统一多模态输入(文本、图像和视频),从而增强服装配准和运动保真度。CondNet基于异构训练数据进行训练,将有限的视频数据和更大、更容易获取的图像数据集以多阶段渐进的方式进行组合。Dress&Dance的性能优于现有的开源和商业解决方案,并能够提供高质量且灵活的试穿体验。

给定一张用户图像、一件想要的服装和一段指定的参考视频,我们通过 GPT 提取详细的文本描述,如第一行所示。(a) 单图像试穿方法 TPD、OOTD 和 GP-VTON 难以生成有意义的试穿,而当通过 CogVideoX 应用运动时,会发生错误传播。(b) 最先进的商业模型,例如 Kling,能够执行试穿,但仍然难以捕捉细微的运动描述,因为仅靠文本不足以描述运动。即使在使用 Kling 进行试穿的情况下,当使用 Ray2 进行运动生成时,这一点也很明显。此外,由于用户的右手遮住了部分服装,视频生成模型会丢失被遮盖图案的信息,导致当手在视频中移动时,对于 (a) 和 (b) 中的所有基线,服装外观都是不正确的。(c) 我们的 Dress&Dance 能够生成高质量的虚拟试穿效果,即使手移开,也能通过精确的动作忠实地保留服装和用户的外观。

Dress&Dance 支持通过分割将服装从另一幅给定图像中迁移出来,而无需考虑该图像的姿态。值得注意的是,我们的 Dress&Dance 生成了 1152 × 720 的高分辨率视频,外观清晰,细节丰富,而基线 Fashion-VDM [12] 则出现了色彩褪色,并生成了 512 × 384 的低分辨率视频。
方法概述
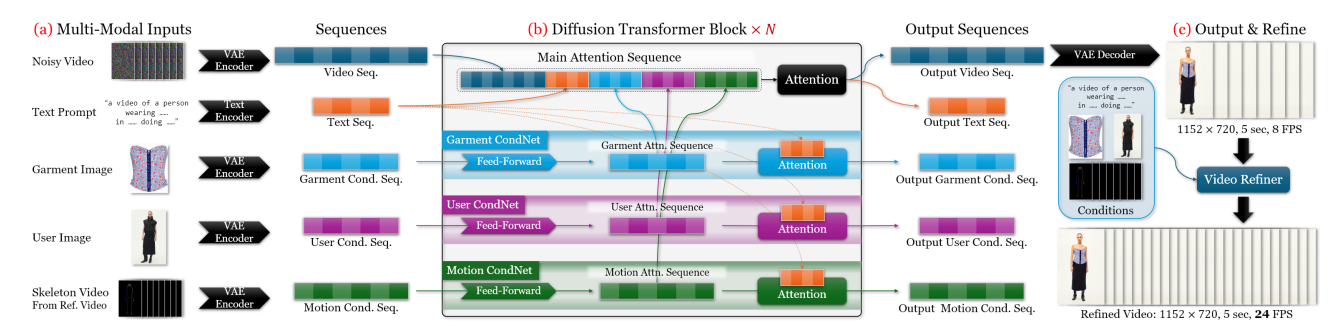
Dress&Dance 通过我们基于注意力机制的统一 CondNets 架构支持多模态条件反射。在一代中,主扩散模型生成 8 FPS 的视频,然后精炼模型将其上采样至 24 FPS,同时去除伪影。

Dress&Dance 有多种用途:(a) Dress&Dance 可以生成复杂的舞蹈动作;(b) Dress&Dance 可以同时对上衣和下装进行虚拟试穿;(c) Dress&Dance 可以输入其他用户穿着的服装。
实验结果

Dress&Dance 的表现显著优于现有的视频虚拟试穿方法,其纹理更加细致、精确,并且对透明服装的支持也更好。
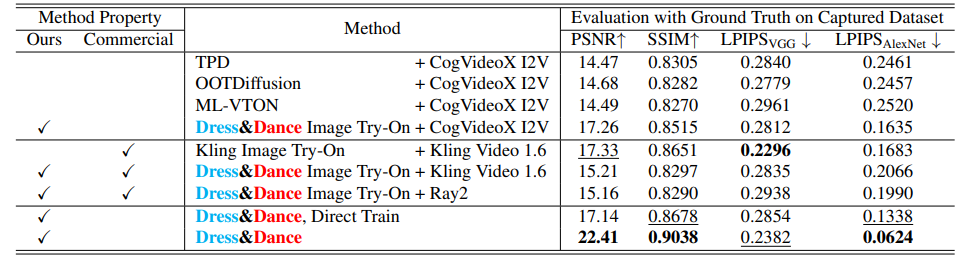
在定量评估中,Dress&Dance 在大多数指标下都显著优于开源基线, 同时实现了与商业模型 Kling AI 和 Ray2 相当甚至更好的质量指标。粗体数字表示每个指标中的最佳值,带下划线的数字表示第二好的值。

Dress&Dance 支持同时试穿一套上衣和下装,无需明确标注即可正确理解和呈现两件衣服。相反,Kling AI 会将裤子误认为是裙子。
结论
论文推出了一个全新的视频扩散框架Dress&Dance,它能够实现服装试穿和时间一致性运动生成。作为首个实现高分辨率(1152 × 720)视频虚拟试穿的成果,该框架能够创建高质量的视频,展示用户穿着目标服装的画面,并通过示例视频引导动作。Dress&Dance解决了几个关键挑战,包括保留用户和服装的相似性,以及以最小的误差传播生成复杂的运动。通过利用具有交叉注意力机制的统一条件网络,我们能够有效地处理异构输入,改进服装配准,并支持各种服装捕捉方法。此外高效的数据训练策略,结合合成三元组数据生成和多阶段渐进式方法,能够生成伪影较少的高分辨率视频。