Linux 缓冲区与glibc库
一.缓冲区
1、再谈重定向:标准错误
要讲缓冲区,我们首先从标准错误的输入讲起。首先我们写一段程序,并指明重定向位置。
#include<cstdio>
#include<iostream>int main()
{std::cout<<"hello cout"<<std::endl;printf("hello printf\n");std::cerr<<"hello cerr"<<std::endl;fprintf(stderr,"hello stderr\n");return 0;}
编译运行,我们手动将输出流由标准输入的文件标识符从1改为文件log。此时我们发现一个很奇怪的现象:我们明明指定了重定向目标文件为log,为什么错误信息还是被打印到了屏幕?为什么只有普通的非错误信息被成功重定向?
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream 1> log.txt
hello cerr
hello stderr
wujiahao@VM-12-14-ubuntu:~/file_test$ ls
log.txt Makefile stream stream.cc
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello cout
hello printf
带着问题,我们再重新进行一次重定向操作,这次,我们将标准输出和标准错误都重定向到log.normal。结果发现更为奇怪的现象:这时log中只有错误信息,而标准输出的信息不知所踪。
这是因为:每次进行重定向都会清空文件内容,我们使用追加重定向即可解决。
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream 1>log.normal 2>log.normal
wujiahao@VM-12-14-ubuntu:~/file_test$ ls
log.normal Makefile stream stream.cc
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.normal
hello cerr
hello stderrwujiahao@VM-12-14-ubuntu:~/file_test$ ./stream 1>>log.txt 2>>log.txt
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello cout
hello printf
hello cerr
hello stderr
我们可以使用正确的重定向,使得标准错误和标准输出的内容都能正确回显到文件中。
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream 1>log.txt 2>&1
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello cout
hello printf
hello cerr
hello stderr
♦♦现象揭秘
1.标准输出和标准错误原本都指向同一个显示器文件,重定向改变的是标准输出的指向,因为重定向只做了printf和stdout的处理 。
2.如果我们想要对标准错误重定向,就需要做上面的那个例子。
3.标准错误存在的意义是为了将常规信息和错误信息分离,指定错误信息的输出方便日志的形成。
2、再探files_struct
由上章讲解我们知道,在操作系统角度来看:用户(进程)每打开一个文件,都会对应创建一个由files_struct文件描述符表管理的结构体file,并且对应管理文件自己的内核文件缓冲区。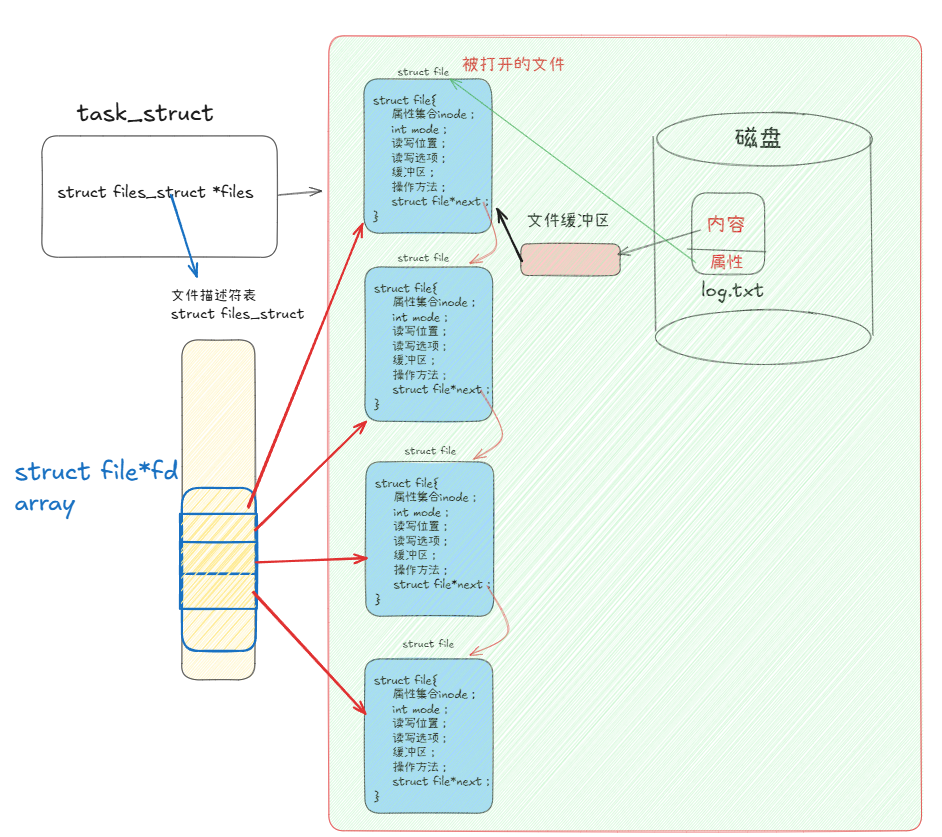
我们通过源码查看files_struct的成员:其中定义了一个指针数组fd_array用于存放文件描述符和管理对应的file结构体。我们在使用open、write等系统调用时用fd找到唯一标识的file结构体,并进一步找到对应的打开文件的实体。
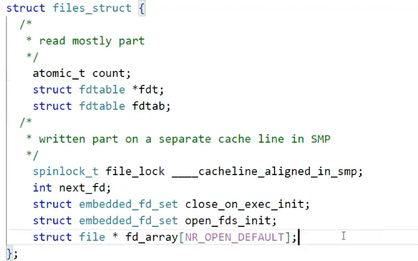
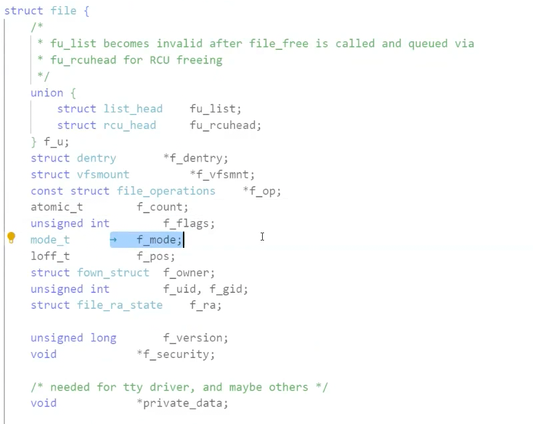
我们可以再对file结构体的成员进行探秘:其中有一些成员值得我们关注,比如f_mode,指明了打开文件的打开方式;f_pos指明了当前文件的读写位置。
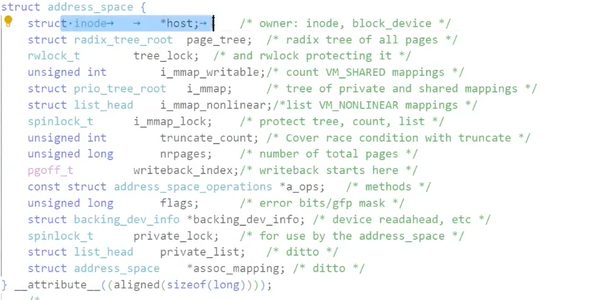
每个被打开的文件的file结构体,又会管理一个内核文件缓冲区,我们也可以对这个所谓的文件缓冲区进行探秘:可以看到,这个address_space结构体中也有大量的数据,其中较为重要的就是inode:文件的硬属性,以及assoc_mapping,就是所谓的内核文件缓冲区本尊。
3、理解一切皆文件
1、在Linux中,有一个不同于Windows系统的点:那就是一切皆文件。这是什么意思呢?Windows中是文件的,在Linux中当然是文件;在Windows中不是文件的——例如各种IO设备,在Linux中依然以文件形式进行管理。本节我们针对这个特性深入探讨这个核心概念。
2、由常识我们很容易想清楚,不同外设之间的读写差异非常大,例如键盘、磁盘、鼠标等等的读写方式各有千秋。而所有的外设都具有读写的需求。在之前的章节中我们也提到过,一切皆文件在Linux的一个重要体现,就是将外设也看做文件,并通过先描述,再组织的方法对不同设备进行管理。
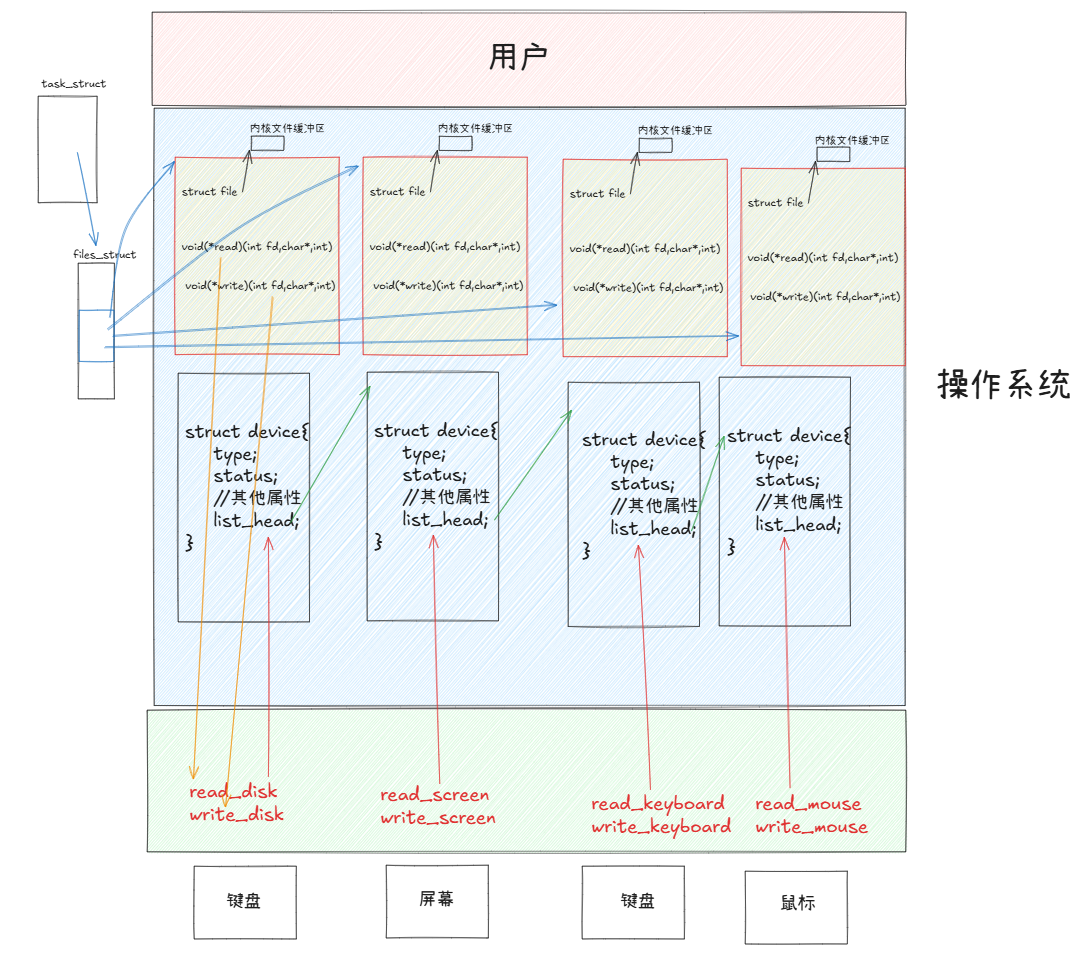
3、struct file在被打开时会存储函数指针,分别指向设备的读写方法。也就是说,设备的读写都是通过函数指针访问的,函数指针类型命名,参数全都一样,屏蔽了底层硬件差异。骗过进程,让进程认为一切皆文件,那么在用户角度看就是一切皆文件。
4、虚拟文件系统:在访问任何设备时,最终只要提供文件描述符,就可以忽略底层硬件差异,直接使用struct file内部的函数指针进行设备读写。
5、Linux使用C语言编写,无法在struct中实现函数,但可以传入函数指针,换句话说,这里的struct file利用这个特性实现了C语言的多态,而struct file就是那个基类,不同的设备文件就是衍生的子类。
6、任何软件问题都可以通过加一层软件层解决,所以就体现出越靠近上层,抽象程度越高(基类)。我们可以直观感受一下file结构体中的函数指针(十分庞大):
struct file_operations {struct module *owner;
//指向拥有该模块的指针;loff_t (*llseek) (struct file *, loff_t, int);
//llseek ⽅法⽤作改变⽂件中的当前读/写位置, 并且新位置作为(正的)返回值.ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
//⽤来从设备中获取数据. 在这个位置的⼀个空指针导致 read 系统调⽤以 -EINVAL("Invalid argument") 失败. ⼀个⾮负返回值代表了成功读取的字节数( 返回值是⼀个
"signed size" 类型, 常常是⽬标平台本地的整数类型).ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
//发送数据给设备. 如果 NULL, -EINVAL 返回给调⽤ write 系统调⽤的程序. 如果⾮负,
返回值代表成功写的字节数.ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long,loff_t);
//初始化⼀个异步读 -- 可能在函数返回前不结束的读操作.ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
//初始化设备上的⼀个异步写.int (*readdir) (struct file *, void *, filldir_t);
//对于设备⽂件这个成员应当为 NULL; 它⽤来读取⽬录, 并且仅对**⽂件系统**有⽤.unsigned int (*poll) (struct file *, struct poll_table_struct *);int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);long (*compat_ioctl) (struct file *, unsigned int, unsigned long);int (*mmap) (struct file *, struct vm_area_struct *);
//mmap ⽤来请求将设备内存映射到进程的地址空间. 如果这个⽅法是 NULL, mmap 系统调⽤
返回 -ENODEV.int (*open) (struct inode *, struct file *);
//打开⼀个⽂件int (*flush) (struct file *, fl_owner_t id);
//flush 操作在进程关闭它的设备⽂件描述符的拷⻉时调⽤;int (*release) (struct inode *, struct file *);
//在⽂件结构被释放时引⽤这个操作. 如同 open, release 可以为 NULL.int (*fsync) (struct file *, struct dentry *, int datasync);
//⽤⼾调⽤来刷新任何挂着的数据.int (*aio_fsync) (struct kiocb *, int datasync);int (*fasync) (int, struct file *, int);int (*lock) (struct file *, int, struct file_lock *);
//lock ⽅法⽤来实现⽂件加锁; 加锁对常规⽂件是必不可少的特性, 但是设备驱动⼏乎从不实现它.ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *,int);unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned,long, unsigned long, unsigned long);int (*check_flags)(int);int (*flock) (struct file *, int, struct file_lock *);ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t*, size_t, unsigned int);ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *,size_t, unsigned int);int (*setlease)(struct file *, long, struct file_lock **);
}4、缓冲区
我们从三方面讲解缓冲区:
1、缓冲区是什么
2、为什么需要缓冲区
3、如何实现缓冲区结构
1、缓冲区是内存的一块空间,我们可以把它想成学校的驿站,快递员再给我们打电话之后,如果我们不能及时签收可以先放在快递站暂存,节省了快递员的时间,提高了快递员的工作效率,也方便了我们的取件。正因为缓冲区的存在,使得我们的输入输出数据得以缓冲。
2、为什么引入缓冲区?提高效率,尤其是用户的使用效率。
3、我们口中的缓冲区是什么?用一个例子来说明。
1 #include<cstdio>2 #include<iostream>3 #include <cstring>4 #include <unistd.h>5 #include <sys/types.h>6 #include <sys/stat.h>7 #include <fcntl.h>8 9 int main()10 {11 close(1);12 //fd==113 int fd=open("log.txt",O_CREAT|O_WRONLY|O_APPEND,0666); 14 15 printf("fd:%d\n",fd);16 printf("hello printf!\n");17 printf("hello printf!\n");18 printf("hello printf!\n");19 20 const char*msg="hello write!\n";21 write(fd,msg,strlen(msg));22 23 24 close(fd);25 return 0;26 27 }
此时的运行结果只有我们write的结果:
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream
wujiahao@VM-12-14-ubuntu:~/file_test$ ls
log.txt Makefile stream stream.cc
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello write!
4、printf是库函数,write为系统函数,也就是说:最后执行关闭,影响的只有库函数写入的结果,而不影响系统调用,那这个现象是为什么?
5、当我们在使用C标准库的printf,fprintf等函数写入一个字符串如aaa时,并不是直接写入文件内核缓冲区的,而是到用户级的语言层缓冲区。当用户强制刷新或刷新条件满足或进程退出时,由C标准库根据文件描述符将数据刷新到对应的文件内核缓冲区,用户层的操作结束,然后是操作系统的工作。那么C标准库是如何将数据拷贝到文件内核缓冲区的呢?fd+系统调用(比如write)。
6、刷新条件:立即刷新——无缓冲,写透刷新WT;缓冲区满——全缓冲;行刷新——行缓冲。为什么C语言要提供自己的缓冲区?系统调用是有成本的。如果频繁地调用系统调用,系统的效率会降低(vector中的扩容也是这个逻辑)。为了提高效率,在语言层设计缓冲区:比如我们有1MB语言层缓冲,写十几次写满了才使用系统调用拷贝到内核级缓冲区,也就是说把多次printf的结果一次write进去。这样就降低了系统调用的频率。
操作系统的刷新方案包括但不限于以上方法,并且刷新方案是交给操作系统根据实际进行选择的。我们可以认为:只要把数据交给操作系统,就相当于交给(拷贝)了硬件。数据的流动,本质上都是拷贝。
7、从刚刚的代码来看,printf写入的不是内核级缓冲区;当调用close(fd)时,进程未退出;也就是说,上面我们说的刷新条件都不满足,数据一直待在用户的语言层缓冲区中;close了fd,将文件描述符关掉后进程退出,语言层缓冲区开始刷新,结果fd关闭,无法找到对应的内核文件缓冲区,数据自然无法从语言层缓冲区刷新到内核级缓冲区了。
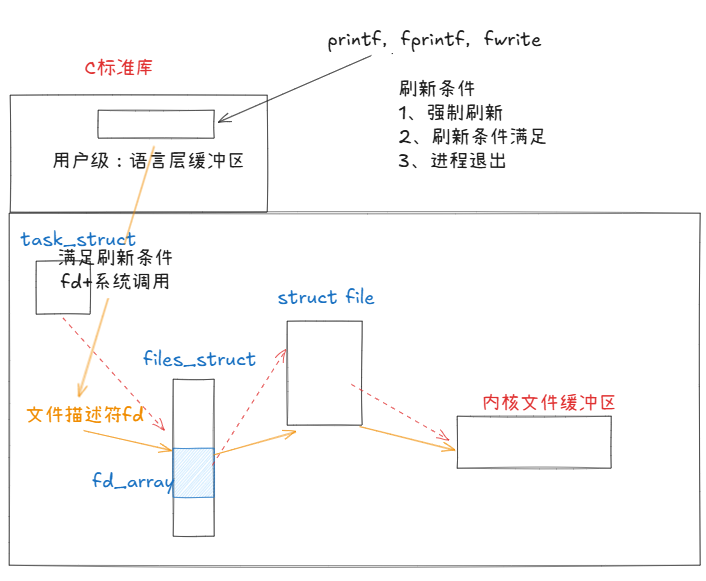
8、我们再回到上面的代码,想要让代码正常显示也很简单,只需要在fd关闭前将语言层缓冲区内容刷新到内核级缓冲区即可,使用fflush函数。
printf("hello printf!\n");printf("hello printf!\n");printf("hello printf!\n");fflush(stdout); 结果可以正常显示。
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
fd:1
hello printf!
hello printf!
hello printf!
hello write!
9、C标准库提供的语言层缓冲区在哪?
我们查看C标准的接口fopen
#include <stdio.h>FILE *fopen(const char *pathname, const char *mode);FILE *fdopen(int fd, const char *mode);FILE *freopen(const char *pathname, const char *mode, FILE *stream);
发现fopen的返回值是FILE *类型。
FILE:C语言提供的一个struct,封装了fd和一些指针,这些指针维护缓冲区。
我们可以在系统中查看:/usr/include/x86_64-linux-gnu/bits/types/struct_FILE.h看FILE有什么。
struct _IO_FILE29 {30 int _flags; /* High-order word is _IO_MAGIC; rest is flags. */31 32 /* The following pointers correspond to the C++ streambuf protocol. */33 char *_IO_read_ptr; /* Current read pointer */34 char *_IO_read_end; /* End of get area. */35 char *_IO_read_base; /* Start of putback+get area. */36 char *_IO_write_base; /* Start of put area. */37 char *_IO_write_ptr; /* Current put pointer. */38 char *_IO_write_end; /* End of put area. */39 char *_IO_buf_base; /* Start of reserve area. */40 char *_IO_buf_end; /* End of reserve area. */41 42 /* The following fields are used to support backing up and undo. */43 char *_IO_save_base; /* Pointer to start of non-current get area. */44 char *_IO_backup_base; /* Pointer to first valid character of backup area */45 char *_IO_save_end; /* Pointer to end of non-current get area. */46 47 struct _IO_marker *_markers;48 49 struct _IO_FILE *_chain; 50 51 int _fileno;52 int _flags2;53 __off_t _old_offset; /* This used to be _offset but it's too small. */54 55 /* 1+column number of pbase(); 0 is unknown. */56 unsigned short _cur_column;57 signed char _vtable_offset;58 char _shortbuf[1];59 60 _IO_lock_t *_lock;61 #ifdef _IO_USE_OLD_IO_FILE62 };
10、理解格式化输出:本质上是将数据按字符串输出放到C标准库缓冲区,然后满足条件后再刷新到内核缓冲区。
实践验证:
int main()10 {11 //库函数12 printf("hello printf!\n");13 fprintf(stdout,"hello fprintf!\n");14 15 const char*s="hello fwrite!\n";16 fwrite(s,strlen(s),1,stdout);17 18 //系统调用19 const char *ss="hello write!!\n";20 write(1,ss,strlen(ss));21 22 23 return 0;24 25 }
输出:
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream
hello printf!
hello fprintf!
hello fwrite!
hello write!!
wujiahao@VM-12-14-ubuntu:~/file_test$ rm -f log*
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream >log.txt
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello write!!
hello printf!
hello fprintf!
hello fwrite!
此时我们在输入输出的代码后写一个fork创建子进程:
int main()
{//库函数printf("hello printf!\n");fprintf(stdout,"hello fprintf!\n");const char*s="hello fwrite!\n";fwrite(s,strlen(s),1,stdout);//系统调用const char *ss="hello write!!\n";write(1,ss,strlen(ss));fork();return 0;}
输出还是和上面类似,因为我们在代码结尾时fork子进程,此时的库函数和系统调用都已经将数据刷新到了内核的文件缓冲区。
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream
hello printf!
hello fprintf!
hello fwrite!
hello write!!
但是,此时我们采用重定向:为什么库函数的信息被输出了两次?
wujiahao@VM-12-14-ubuntu:~/file_test$ ./stream >log.txt
wujiahao@VM-12-14-ubuntu:~/file_test$ cat log.txt
hello write!!
hello printf!
hello fprintf!
hello fwrite!
hello printf!
hello fprintf!
hello fwrite!
这里的主要原因是:重定向改变了库函数的刷新方式!
当标准输出连接到终端(terminal)时,它是行缓冲的(line-buffered),这意味着遇到换行符
\n时会刷新缓冲区。当标准输出被重定向到文件或管道时,它变成全缓冲的(fully-buffered),这意味着只有当缓冲区满或显式刷新(fflush)时才会输出,或者程序正常结束时会刷新所有缓冲区。
也就是说,当我们采用重定向时,printf等库函数由原先的行缓冲变为全缓冲,此时fork时库函数的信息还在缓冲区,而write的信息已经刷新到内核文件缓冲区。我们知道fork创建子进程时会对父进程的数据进行拷贝,那么C标准库的文件缓冲区也会被拷贝一份,因此最终输出两次库函数的信息。
11、缓冲区的存在,提供了使用者的效率,对于读文件,可以实现预加载的效果。
二.模拟封装简单的glibc文件接口
在本节,我们可以通过封装简单的glibc接口,进一步理解我们之前说的:库函数本质是对系统调用的不同程度封装的意义。
1、头文件
描述一个被打开的文件,在库级别叫做struct FILE,也是先描述,再组织。因此在头文件中,我们自定义自己的IO_FILE,其中有文件描述符fileno,打开方式flag,文件缓冲区outbuffer,刷新策略method等重要属性。
#pragma once#include <stdio.h>//模仿系统调用open的二进制传参
#define MAX 1024
#define NONE_FLUSH (1<<0)
#define LINE_FLUSH (1<<1)
#define FULL_FLUSH (1<<2)typedef struct IO_FILE
{int fileno;int flag;char outbuffer[MAX];int bufferlen;int flush_method;
}MyFile;//打开,关闭,写,刷新
MyFile *MyFopen(const char *path, const char *mode);
void MyFclose(MyFile *);
int MyFwrite(MyFile *, void *str, int len);
void MyFFlush(MyFile *);2、实现
1、由于自定义的fopen返回值为FILE结构体,我们需要一个创建结构体并初始化的方法Buyfile。
#include "mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>static MyFile *BuyFile(int fd, int flag)
{MyFile *f = (MyFile*)malloc(sizeof(MyFile));if(f == NULL) return NULL;f->bufferlen = 0;f->fileno = fd;f->flag = flag;f->flush_method = LINE_FLUSH;memset(f->outbuffer, 0, sizeof(f->outbuffer));return f;
}
2、然后我们实现fopen,最主要的就是实现打开方式。大致分为覆盖写w,追加写a,以及只读r。既然要封装系统调用,我们将对应逻辑下的具体实现用对应的open不同方式打开即可。
MyFile *MyFopen(const char *path, const char *mode)
{int fd = -1;int flag = 0;if(strcmp(mode, "w") == 0){flag = O_CREAT | O_WRONLY | O_TRUNC;fd = open(path, flag, 0666);}else if(strcmp(mode, "a") == 0){flag = O_CREAT | O_WRONLY | O_APPEND;fd = open(path, flag, 0666);}else if(strcmp(mode, "r") == 0){flag = O_RDWR;fd = open(path, flag);}else{//TODO}if(fd < 0) return NULL;return BuyFile(fd, flag);
}3、然后是fclose的模拟实现。主要就是对资源的各种回收:刷新缓冲区,按文件描述符fileno关闭文件,然后释放结构体。
void MyFclose(MyFile *file)
{if(file->fileno < 0) return;MyFFlush(file);close(file->fileno);free(file);
}4、接着是fwrite方法。由上面的讲解我们知道,write就是将C标准库的文件缓冲区数据拷贝到内核的文件缓冲区。那么fwrite就是将str的数据拷贝到我们模拟的库缓冲区outbuffer中。
int MyFwrite(MyFile *file, void *str, int len)
{// 1. 拷贝memcpy(file->outbuffer+file->bufferlen, str, len);file->bufferlen += len;// 2. 尝试判断是否满足刷新条件!if((file->flush_method & LINE_FLUSH) && file->outbuffer[file->bufferlen-1] == '\n'){MyFFlush(file);}return 0;
}5、最后是fflush方法。将缓冲区outbuffer的数据写到内核文件缓冲区。
void MyFFlush(MyFile *file)
{if(file->bufferlen <= 0) return;// 把数据从用户拷贝到内核文件缓冲区中int n = write(file->fileno, file->outbuffer, file->bufferlen);(void)n;fsync(file->fileno);file->bufferlen = 0;
}